文章目錄
- 前言
- 例題引入
- 簡單演算法BF
- 經典演算法KMP
- kmp理解難點1
- kmp理解難點2
- kmp最難理解點3
- kmp代碼
前言
對于kmp的鼎鼎大名,不只是博主自己,想必還有更多小伙子們聽說過,也相信都去了解過,博主亦是這樣,但是真正去理解這個程序,確是例外的折磨人,在kmp演算法里面搗鼓了整整3天,博主終于找到了用更好理解的話語進行解釋了,便迫不及待的進行分享.
例題引入
假如有一個文本串T,內容為cadefgdefghp,有一個模式串P,其內容為defgh,請問P是否在T內?如果在,請回傳P在T中的索引位置,如果不在,請回傳-1.
簡單演算法BF
對于此題,我想大部分人都有一個簡單思路,那就是T和P一一匹配,當匹配一個字符后,就挨個匹配后面;如果在中間部分不匹配,那么T講回到最開始匹配字符的下一個字符處,P回到索引為0處.如下圖:

而這種演算法我們稱為樸素演算法(BF),代碼博主會貼在下面:
int BF(char T[], char P[])
{
int i = 0, j = 0;
while (i < strlen(T) && j < strlen(P))
{
if (T[i] == P[j]) //如果相等,就繼續從這往后匹配
{
i++, j++;
}
else
{
i = i - j + 1; //如果不等,i就回傳最開始匹配位置下一個位置(見上圖)
j = 0; //p回傳到索引為0重新開始
}
}
if (j >= strlen(P)) //當匹配成功時,j一定移動到P字串末尾,所以j必須有此條件
return i - j;
else
return -1;
}
經典演算法KMP
為什么有KMP,他的目的就是解決我們重復匹配的問題,比如下圖:
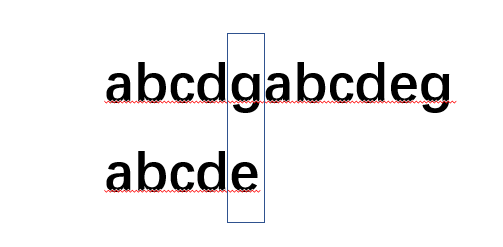
我們發現g和e不匹配了,按照BF演算法,文本串(上方字串)位置會回到b位置,模式串(下方)會重新回到索引為0處然后繼續比對.
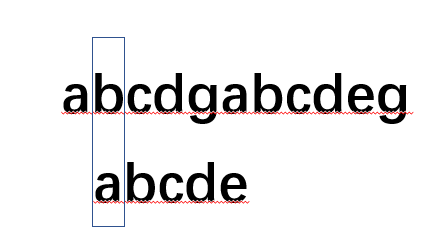
而如果我們按照人的思維會怎樣繼續對比呢?沒錯,我們并不會像BF那樣笨,如果是人,會直接讓文本串不動,直接讓模式串開始重新匹配:
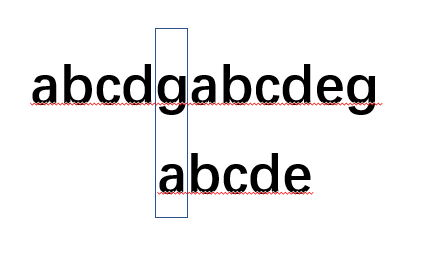
也就是文本串此時索引不動,而模式串索引回到了0,并從此處開始繼續匹配.記住這句話!!!
我們再舉一個例子,假設在文本串efabcabpabcabe中匹配abcabe,如下圖:
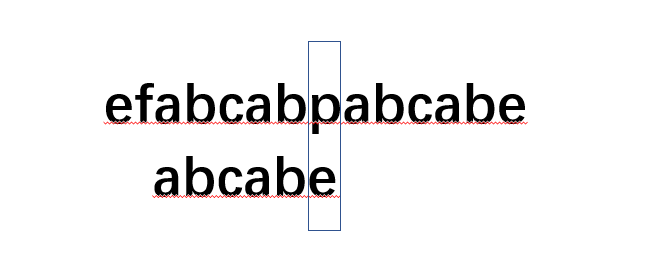
我們先是一個一個的匹配,但是當匹配到p和e時,發現不匹配了,按照BF演算法,文本串會回到索引為3位置,模式串會回到索引為0位置.

但是如果是人呢?會怎樣做?我們會讓模式串索引0位置和文本串索引5位置對齊,因為對齊后都有ab,所以模式串就從索引為2位置繼續進行匹配.
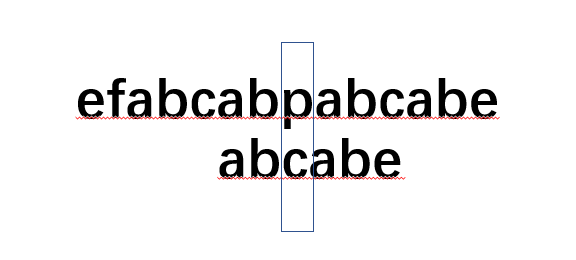
也就是文本串此時不動,而模式串索引回到2,并從此開始繼續匹配.記住這句話!!!
我們最后再舉一個例子:假設有文本串efabcdabcabcabe,模式串abcdabc,然后開始正常匹配
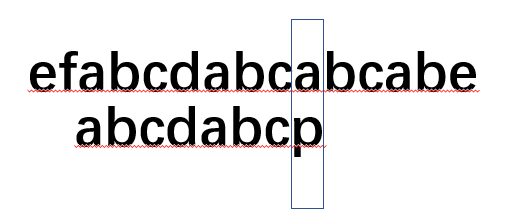
在這里,我們發生了失配,如果按照BF演算法,我們會讓文本串回到索引為3位置處,而模式串回到索引0處:

但是如果是人類呢? 會怎樣做? 沒錯,我們會讓模式串與文本串的索引6位置處對齊,而文本串不動.然后發現對齊以后,文本串和模式串都有abc,所以我們不管abc,而是讓模式串從索引為3處開始和文本串對比:
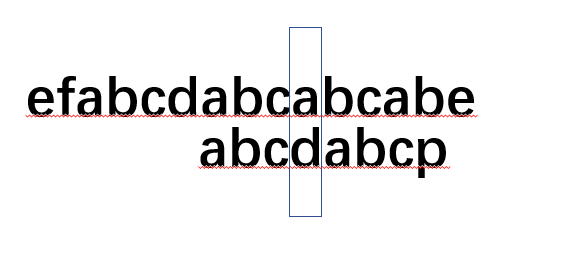
也就是文本串此時不動,而模式串索引回到3,并從此開始繼續匹配.記住這句話!!!
大家分別縱觀上面三個例子,我們都做了什么相同操作?
- 當失配時:
- 文本串位置不動
- 模式串的索引直接從某個位置開始繼續和文本串適配位置進行匹配
我們再來看看規律,
第一個例子: 文本串此時不動,而模式串索引回到0,并從此開始繼續匹配.
- 原因:模式串失配位置前面有0個重復的元素
第二個例子:文本串此時不動,而模式串索引回到2,并從此開始繼續匹配.
- 原因: 模式串失配位置前面有2個重復的元素,即ab
第三個例子:文本串此時不動,而模式串索引回到3,并從此開始繼續匹配.
- 原因: 模式串失配位置前面有3個重復的元素,即abc
也就是說!!!,當在中途匹配程序中發生失敗,我可以不再讓文本串回走很長一段舉例,而是讓模式串進行繼續匹配,至于模式串下一步應該會到哪個位置,取決于匹配失敗字符前的相同前后綴字符(后面會介紹前后綴)長度
我們再試試一個例子,看看是這個規律嗎?比如文本串efacadmp,模式串acabef

此時失配了,模式串失配字符b前面有1個重復的元素a,所以模式串直接從索引為1開始進行繼續匹配,看看是否對:

完全沒問題,因為在模式索引0前有一個字符a,而文本串對應位置也有一個字符a,所以模式串直接從索引為1開始匹配
也就是說一旦發生失配,人類執行時,會按照如下步驟:
- 不動文本串
- 模式串位置直接回到索引為k處(k是失配位置
前面所有字串中最大重復元素數量)
而這些步驟用代碼寫出來就是kmp即kmp演算法不像BF演算法那樣,避免了文本串的索引回傳,而是
直接定位模式串下一個匹配位置.
kmp理解難點1
我們已經清楚了kmp的演算法步驟,而難點1就在于求k
而k就是 字串的最大相同前后綴長度
**前后綴概念: **
-
前綴: 字串中
除了最后一個字符外的所有順序集合- 比如有字串
abcdef,那么他的前綴有a,ab,abc,abcd,abcde
- 比如有字串
-
后綴:字串中
除了第一個字符外的所有順序集合- 比如有字串
abcdef,那么他的后綴有f,ef,def,cdef,bcdef
- 比如有字串
-
最大相同前后綴: 前綴集合和后綴集合的交集中最大長度者
- 比如有字串
ababab,他的前后綴交集有ab,abab,所以最長相同前后綴就是abab
- 比如有字串
kmp理解難點2
我們知道,當模式串與主串不匹配時,而主串不動,模式串的索引跳到k處,k值是b當前不匹配字符前的所有字符中最大
相同前后綴長度
所以我們為了方便處理,便用一個陣列進行儲存一段字串的最大前后綴最長度
假設有字串ababaaaba,則:
| 字串 | a | b | a | b | a | a | a | b | a |
|---|---|---|---|---|---|---|---|---|---|
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| k值 | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 1 |
解釋:
-
在索引為3下,k值是2,代表著[0,3]中的字串中相同前后綴的最大長度為2
-
在索引為6下,k值是1,代表著[0,6]中的字串中相同前后綴的最大長度為1
-
在索引為0下,k值0,代表著[0,0]中的字串,即一個字符是沒有前后綴的,最大長度為0
我們給儲存k值的陣列起名叫做next.這也就是我們kmp演算法中的精華所在
kmp最難理解點3
博主在學習kmp演算法中時候,發現很多文章與視頻都是只給了手動算next陣列方法,對于代碼部分便是一筆跳過,而這才是KMP中最最最難理解的一部分代碼,下面博主用自己的理解給大家分享下自己的拙見
我們還是像介紹kmp演算法一樣,我們還是先用自己的第一思路來處理,然后寫代碼,最后進階精華kmp陣列求法:
- 我們的第一思路是什么? 沒錯,那就是前綴和后綴一對一對的比較,比如有下面一段字串
str:
abbabba
我們用變數i進行指示比的是第幾對,從1開始.
我們用變數count進行計數,當出現一對相同前后綴,則count = i,最后count值就是最大長度
- 當i = 1時候,第一對前綴是
"a",后綴是"a",后綴的位置是strlen(str)-1,前后綴相同,count等于1 - 當i = 2時候,第一對前綴是
"ab",后綴是"ba",后綴的位置是strlen(str)-2,前后綴不同,count不管 - …
- 當i = 4時候,第一對前綴是
"abba",后綴是"abba",后綴的位置是strlen(str)-4,前后綴相同,count等于4 - …
所以大概代碼如下:
int count = 0;
for(int i = 1;i < strlen(str);i++) //i不能等于strlen(str),因為前后綴分別不包含尾字符和首字符
{
if(strncmp(str,str+strlen(str)-i,i) == 0) //如果第幾對前后綴相同,則count等于幾
{ //str+strlen(str)-i 是指標加減整數的意義
count = i;
}
}
而我們是需要求一個陣列,所以我們就把字串拆成更多個小字串,然后又分別求每個小字串的最大前后綴長度,思路和上面一樣
void next(char str[],int next[])
{
int i = 1,j = 1,count = 0;
//i代表第幾對,j代表索引[0,j]的字串,count代表最大長度
next[0] = 0; //首字符一定為0,因為之后一個字符,沒有前后綴
for(j = 1;j<strlen(str);j++)
{
count = 0;
for(int i = 1;i < strlen(str);i++) //i不能等于strlen(str),因為前后綴分別不包含尾字符和首字符
{
if(strncmp(str,str+strlen(str)-i,i) == 0) //如果第幾對前后綴相同,則count等于幾
{ //str+strlen(str)-i 是指標加減整數的意義
count = i;
}
}
next[j] = count;
}
}
我們已經成功的用自己的方法求出來了next陣列,但是大家有沒有發現這樣求解有一個很大的缺陷?
-
那就是我們每次在求解[0,j]中的字串最大相同前后綴時,我們都是從第一對的一個字符,到第j對的j個字符進行對比.
-
而在求解[0,j+1]中的字串最大相同前后綴時,我們又要從第一對的第一個字符,到第j+1對的j+1個字符進行對比.
在比較的程序中我們比較了很多不相同前后綴的字串,那么我們想一想,可不可以換一種思路,不再像上面那樣每次都要從一個字符開始進行匹配,避免多次匹配不相同前后綴字串? 答案是完全可以!!!
下面,請大家一定記住這句話,不要覺得這些話很簡單,后面正是這些話才能明白某些代碼:
相同前后綴 == 相同前綴 == 相同后綴 !!!— --- — --- — --- — --- — --- — --- — --- — --- — --- — --- — --- ---- — --- — ---標號①
如果一段字串存在相同前后綴,那么
相同前綴一定可以在后綴(注意,沒有相同兩字)中找到,并且相同前綴一定是最長后綴末尾,相同前綴的長度一定小于等于最長后綴長度— --- — --- — --- — --- — --- — --- — --- — --- — --- — --- — --- —標號②舉個例子:
有一段字串
ababa.
- 相同前后綴有
a與aba,而后綴有a,ba,aba,baba,這就是這句話— --- —相同前綴一定可以在后綴中找到的意思- 該段字串最長后綴為
baba,相同前綴為a,是最長后綴的末尾,相同前綴為aba,是最長后綴的末尾.
- 所以說— --- —
相同前綴一定是最長后綴末尾- 相同前綴的長度分別是1和3都小于最長后綴的長度4
既然我們目的是為了減少不必要的不同前后綴字串比對,那么我們的方法是什么呢?
答曰: 給最長相同前綴新增一個字符,然后判斷是否在最長后綴中.(請看標號①陳述句)
-
如果不在,我們就判斷
原最長相同前綴是否在最長后綴中… -
如果在,說明此時的字串中最長相同前后綴長度是
原最長相同前后綴長度加1(步驟重復上面)
我們現在要開始清楚一些概念了:
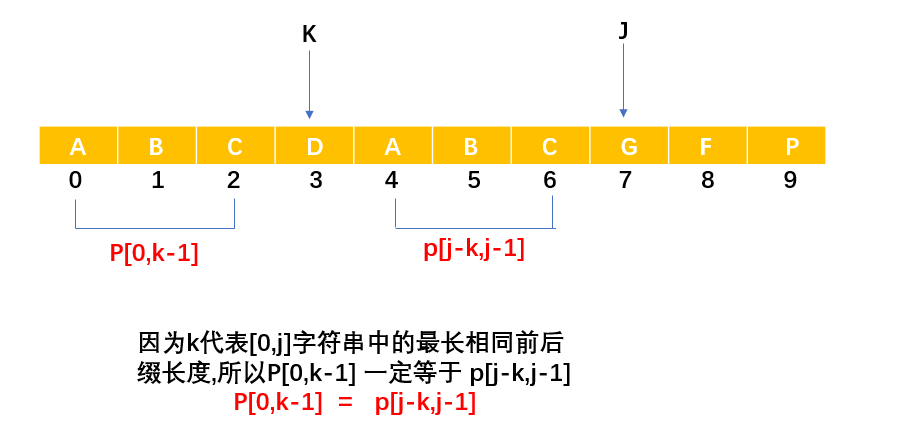
-
我們用j表示一段字串([0,j]的字串)最長后綴的尾巴的索引,j的初始值設為1
-
用k表示字串中最長相同前綴的長度(這句話本身還表達了另一個意思,是最長相同前綴尾巴后一個索引,這個很重要),k初始為0
- 比如有字串ababa,假設此時k等于3,說明此時最長相同前后值長度是3,而索引為3字符卻是最長相同前綴尾末,
-
next陣列存盤的是最長相同前后綴字符長度,則
next[j]表示索引在[0,j]的字串中最長相同前后綴的長度
所以他們一定有下圖關系:
現在大家再看看上面我們說的新的比較方法的步驟,然后下面的代碼結合上面這張圖分析
(下面這些話大家一定要靜下心來想,博主會貼圖再詳細解釋)
如果不存在,怎么判斷?
-
答曰:
-
while(k>0 && p[k] != p[j]) //k為什么大于0,后面會解釋 { k = next[k-1]; //說明給原最長相同前綴加一個字符后,判斷出不等,即[0,k]的字串不在后綴中 } 其實k = next[k-1]大家可能還是不理解,但是大家想想我們的目的,避免比較不相同前后綴,而next陣列裝的就只有相同前后綴長度. 既然[0,k]字串的最長前綴不在后綴中,我們就需要比較[0,k-1]中的最長前綴是否在后綴. 而next[k-1]的意義不就是[0,k-1]中最長相同前后綴字串長度嗎?
給最長相同前綴新增一個字符,如何判斷在最長后綴中?
-
**答曰: **
-
if(p[k] == p[j]) //因為p[0,k-1]等于p[j-k,j-1],而p[0,k-1]就是目前為止最長相同前綴,所以只需要判斷p[k]和p[j]了 { next[j] = k+1; //如果相等,[0,j]中的最長相同前后綴長度等于原最長前后綴長度加一. k++; //更新現在的最長相同前后綴長度 } else //else就是處理當k等于0,且p[k]不等于p[j]時候,說明next[j]應該為0 { next[j] = 0; }
所以最后求next陣列的代碼就是
void get_next(char p[100],int next[100])
{
next[0] = 0;
int j = 1;
int k = 0;
//如果有效前綴增加一個值和新增后綴不等,
for(j = 1; j < strlen(p); j++)
{
while (k>0 && p[k] != p[j])
{
k = next[k - 1];
}
if (p[k] == p[j])
{
next[j] = ++k;
}
else //這一步是索引為1時候,k等于0,且不等的條件
{
next[j] = 0;
}
}
}
kmp代碼
int kmp(char s[100],char p[100])
{
int i = 0, j = 0;
int next[100];
get_next(p,next);
while (i < strlen(s) && j < strlen(p))
{
if (s[i] == p[j])
{
i++, j++;
}
else if (j > 0)
{
j = next[j - 1];
}
else
{
i++;
}
}
if (j >= strlen(p)) return i - j;
else
return -1;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/296653.html
標籤:其他
上一篇:qsort庫函式排序