【計算機設計大賽近年獲獎資訊】資料分析及可視化
- 寫在前面
- 資料讀取及描述
- 資料預處理
- 各年資料集格式化
- 資料合并
- 資料清洗
- 資料分析及可視化
- 各年獎項數量分布
- 各年得獎最多的學校Top10
- 各學校參加次數統計
- 各年參賽學校層次劃分
- 參賽人數與獎項分布
- 獲獎作品名稱熱詞
- 總結
寫在前面
本文通過最近三年 “中國大學生計算機設計大賽” 的獲獎資料(2021結果尚未揭曉),分析挖掘一下該比賽深層的一些內容,主要有以下幾點:
- 各年各獎項的比例分布
- 各年得獎最多的學校 Top10
- 哪些學校多次進入得獎最多 Top10
- 各學校三年中參賽次數統計
- 各級別獎項中學校層次劃分
- 參賽人數與獎項之間的關系
- 獲獎作品名稱熱詞
文中各部分中如果代碼量較多的,為了閱讀體驗,就不進行展示,如需代碼及相關檔案可以私信我,
資料讀取及描述
資料集是大賽官方提供的資料,2018、2019 年資料為.xlsx檔案,2020 年資料為.pdf檔案,先讀取 2018 、2019 年資料,并觀察一下資料集資訊,
import pandas as pd
df_2018 = pd.read_excel('2018年決賽正式結果.xlsx', sheet_name='123等獎')
df_2019 = pd.read_excel('2019年大賽獲獎作品名單公示20190907.xlsx')
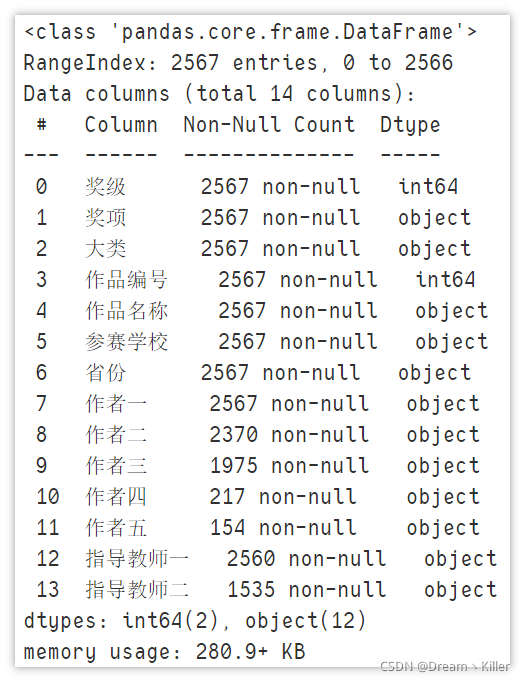
df_2019.info()
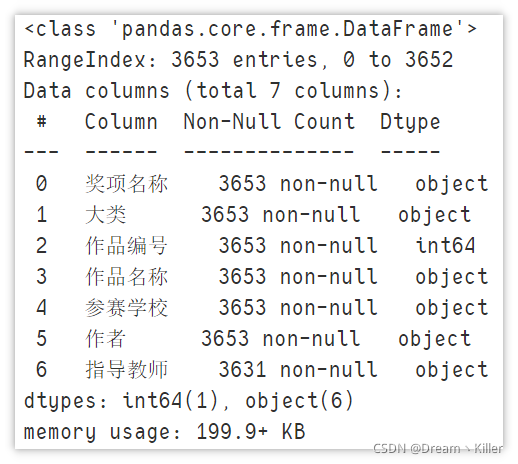
通過上圖中的資訊可以看到,2018 年與 2019 年的資料集格式有挺大的差異,這些在之后合并時需要統一,
由于 2020 年的資料是 .pdf 檔案,我們單獨定義一個函式來讀取,對于讀取時的一些細節問題,都已在代碼中以注釋的形式標出,
import pdfplumber
def read_pdf_2020(read_path):
pdf_2020 = pdfplumber.open(read_path)
result_df = pd.DataFrame()
for page in pdf_2020.pages:
table = page.extract_table()
df_detail = pd.DataFrame(table[1:], columns=table[0])
# 合并每頁的資料集
result_df = pd.concat([df_detail, result_df], ignore_index=True)
# 洗掉值全部是 NaN 的列
result_df.dropna(axis=1, how='all', inplace=True)
# 重置列名
result_df.columns = ['獎項', '作品編號', '作品名稱', '參賽學校', '作者', '指導老師']
return result_df
df_2020 = read_pdf_2020('2020年中國大學生計算機設計大賽參賽作品獲獎名單.pdf')
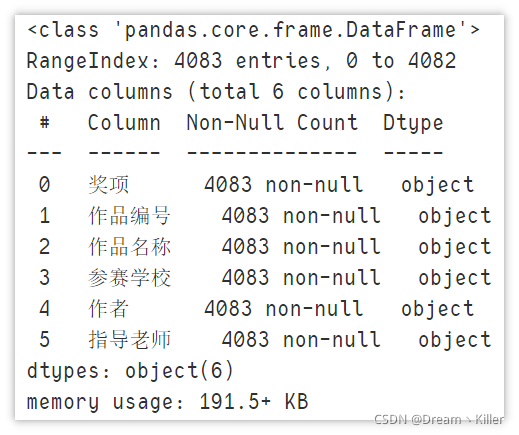
觀察 2020 年的資料,相比于前兩年的資料,它的各列都沒有缺失值,但2020年的獲獎資訊中并沒有包含作品類別這一列,所以我們處理資料集時要將前兩年的類別列進行洗掉,這樣,我們可以按照 2020 資料集的格式作為模板,將前兩年的資料集轉換為相同的格式,再進行合并,
資料預處理
各年資料集格式化
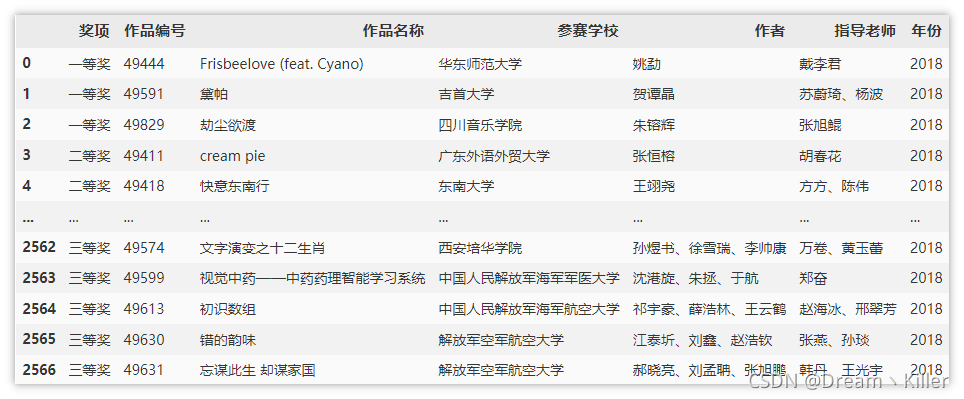
按照 2020 年格式,將 2018 年與 2019 年資料集中部分列進行合并,并更換列名,洗掉多余的列,并添加 “年份” 這一列,
下面是處理后的 2018 年與 2019 年資料,
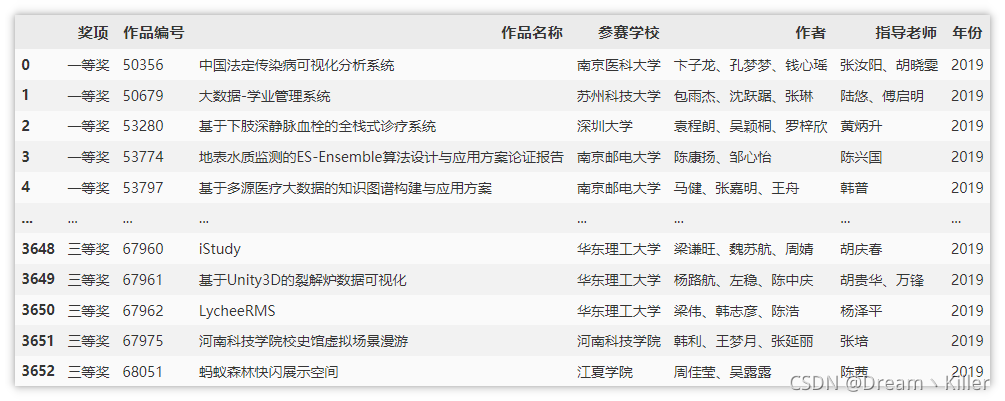
對于 2020 年資料集的處理要注意,資料讀取時是基于每頁資料來讀取的,如果在一頁的最后一行資料較多,需要換行的話,那么下一頁首行資料就會缺失,如下所示,

這種情況就需要先篩選出這些作品編號為空的行,在將資料添加到上一行中,
# 2020年資料集處理
clean_df_2020 = df_2020.copy()
# 部分資訊過長導致在分頁處被分割,分別出現在兩頁上,下面將獎項為空的資料添加到上一條資料的資訊中,
clean_df_2020.iloc[609]['參賽學校'] += '醫大學'
clean_df_2020.iloc[1330]['作品名稱'] += '丹霞'
clean_df_2020.iloc[2121]['作品名稱'] += '現'
clean_df_2020.iloc[2997]['作品名稱'] += '云平臺'
del_index = clean_df_2020.loc[clean_df_2020['獎項'] == ''].index
clean_df_2020.drop(del_index, inplace=True)
clean_df_2020.reset_index(drop=True, inplace=True)
clean_df_2020['年份'] = [2020 for _ in range(len(clean_df_2020))]
資料合并
現在合并三年的資料,合并后資料集如下,
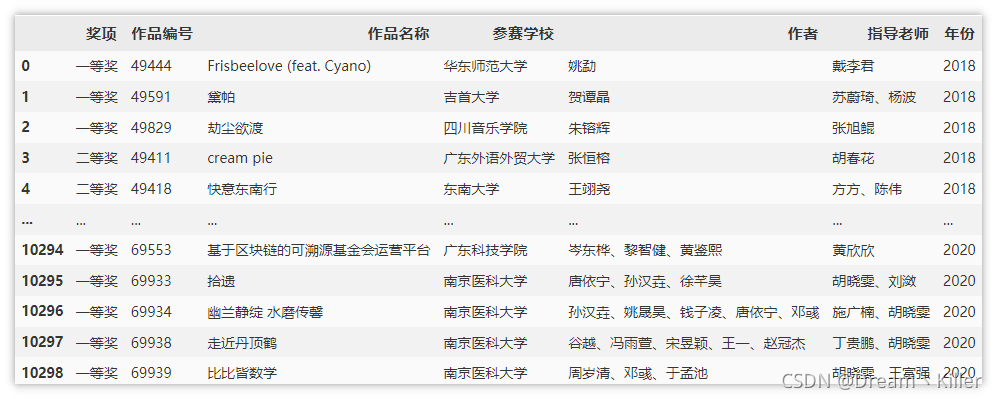
資料清洗
現在我們要對合并后的資料集進行一些處理,以便更好地分析及可視化,由于之后我們要用到全國高校的一些基本資訊,如學校層次(985 211等),所以需要匯入 college_info.csv ,該資料是博主在 6月15日 爬取的,部分高職高專可能并未收錄,對于這部分高校就將對應標簽賦值為 “暫無資料” ,清除參賽學校和作品名稱中的換行符“\n”,之后添加 參賽人數列 來記錄 各作品作者人數 ,指導老師人數列 記錄 該作品指導老師人數,
college_info = pd.read_csv('college_info.csv')
college_name = college_info['學校名稱'].values.tolist()
college_level = []
for college in all_df['參賽學校']:
if college not in college_name:
college_level.append('暫無資料')
else:
college_level.append(college_info['學校層次'][college_name.index(college)])
all_df['學校層次'] = college_level
all_df['參賽學校'] = all_df['參賽學校'].str.replace('\n|\r', '')
all_df['作品名稱'] = all_df['作品名稱'].str.replace('\n|\r', '')
# 洗掉作者為空的列
all_df.dropna(subset=['作者'], axis=0, inplace=True)
# 添加 引數人數 列來記錄各作品作者人數
all_df['參賽人數'] = all_df['作者'].apply(lambda x: len(x.split('、')))
count_list = []
for index, row in all_df.iterrows():
try:
count_list.append(len(row['指導老師'].split('、')))
except:
count_list.append(0)
all_df['指導老師人數'] = count_list
all_df.to_csv('all_df.csv', index=False)
all_df
處理后的資料集如下,

資料分析及可視化
各年獎項數量分布
統計三年中一等獎、二等獎、三等獎的占比,繪制層疊條形圖,
'''
資料統計省略
'''
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add_xaxis([2018, 2019, 2020])
c.add_yaxis("三等獎", list1, stack="stack1", category_gap="70%")
c.add_yaxis("二等獎", list2, stack="stack1", category_gap="70%")
c.add_yaxis("一等獎", list3, stack="stack1", category_gap="70%")
c.set_series_opts(label_opts=opts.LabelOpts(
position="right",
formatter=JsCode(
"function(x){return Number(x.data.percent * 100).toFixed() + '%';}"
),
)
)
c.render("./images/各年獎項數量分布堆疊條形圖.html")
c.render_notebook()
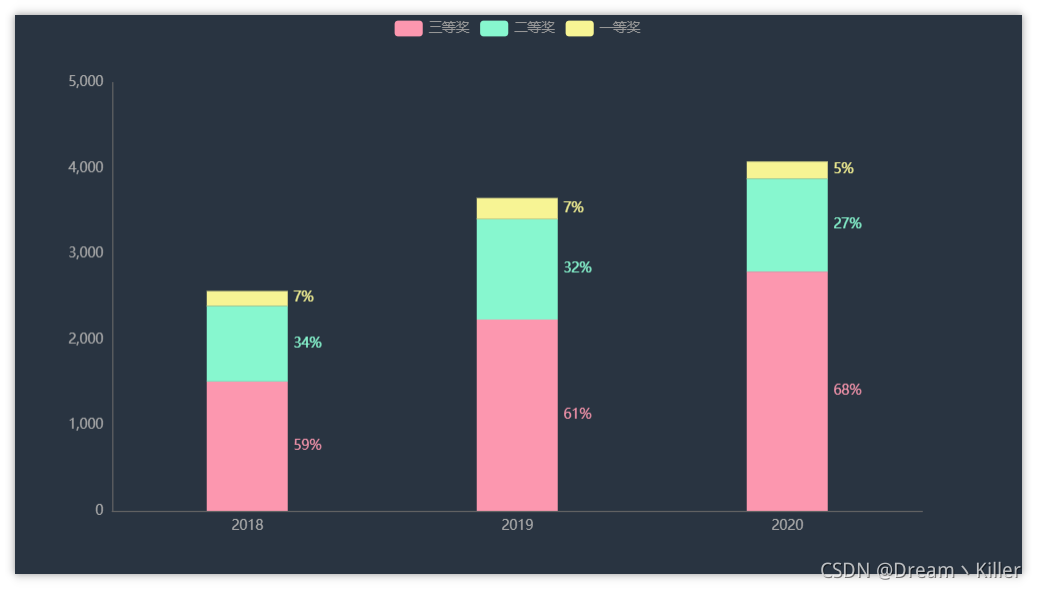
從上圖中觀察發現,隨著時間的推移,一等獎、二等獎的比例開始減少,三等獎比例增加,在 2020 年三等獎比例達到68%,不難看出賽方想要增加一等獎的含金量,
各年得獎最多的學校Top10
統計各年得獎最多的前 10 名學校的各項獎的數目,繪制圖形,
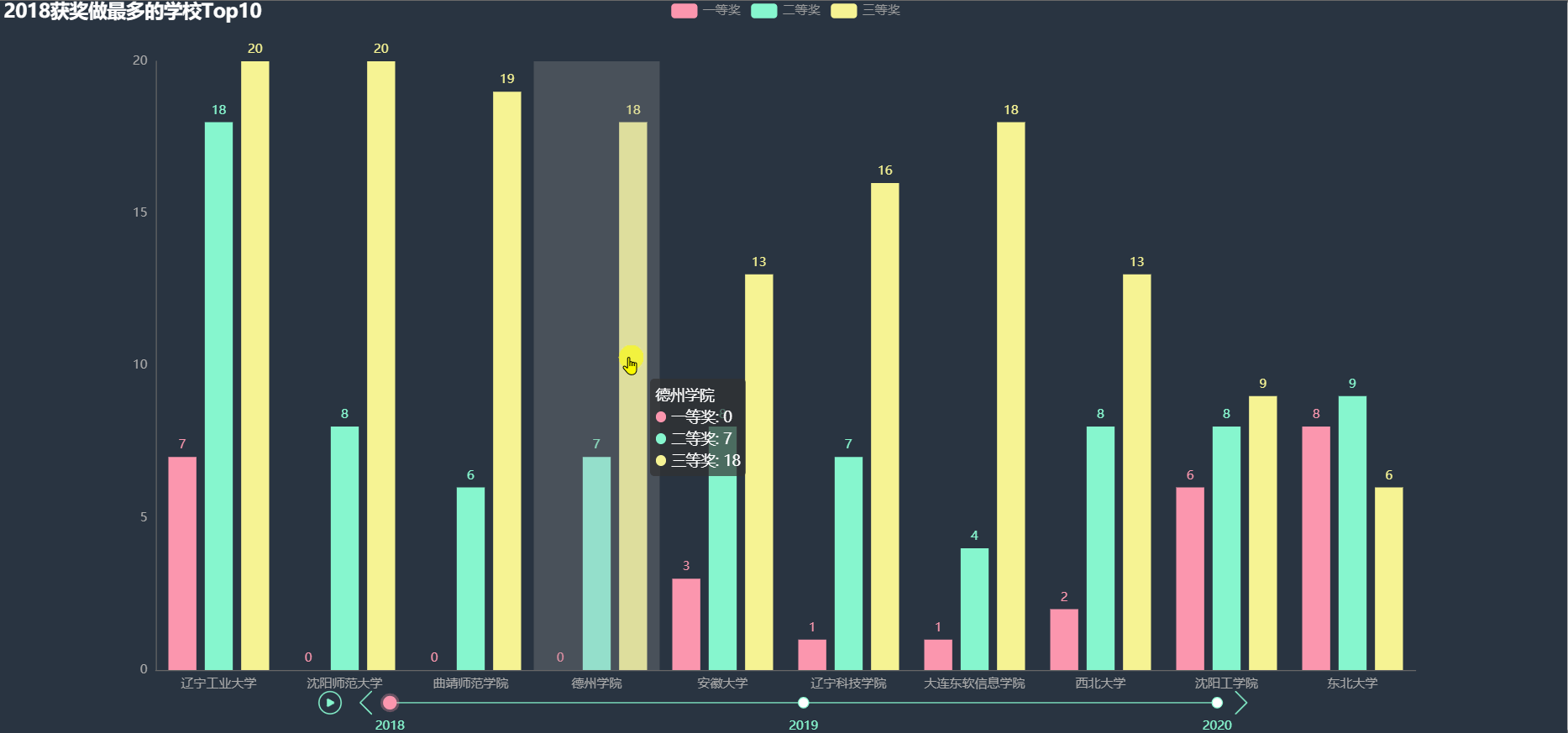
從上圖中大致可以看到很多大學不止一次出現在 Top10 當中,在這些學校中,一部分可能是因為學校比較重視該比賽,
下面使用韋恩圖詳細看一下,哪些學校多次進入得獎最多 Top10,
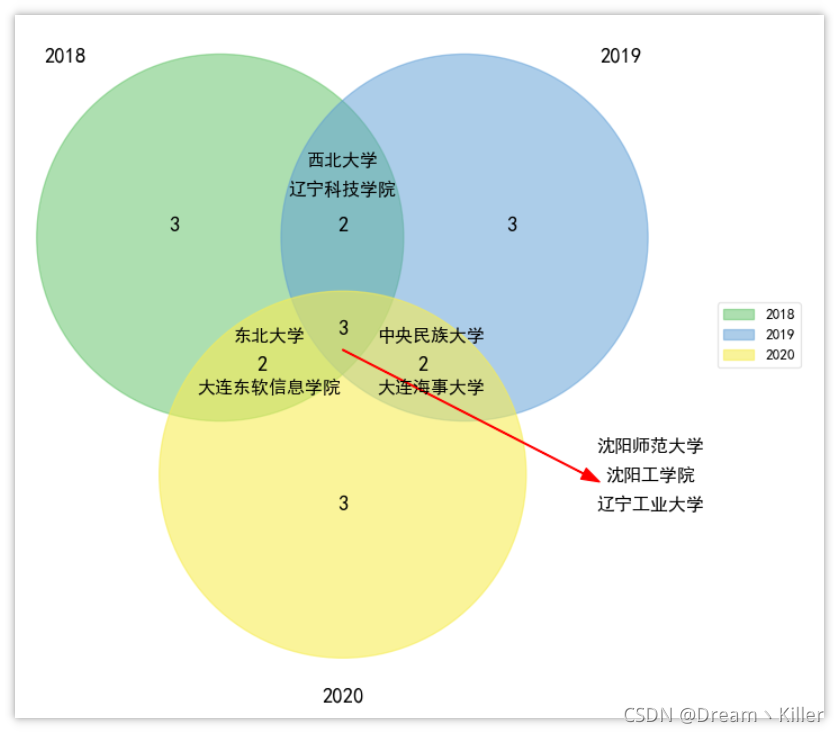
沈陽師范大學、沈陽工學院、遼寧工業大學在三年中都進入 Top10,還有一些其他兩次進入 Top10 的學校, 其中東北部的大學明顯較多,
各學校參加次數統計
現在統計各個學校的參賽次數,并計算各次數的學校數量,
from collections import Counter
all_school = []
for year in [2018, 2019, 2020]:
school_set = set(all_df.loc[all_df['年份'] == year, '參賽學校'].values.tolist())
all_school += list(school_set)
value_count = Counter(all_school)
count_list = ['參賽' + str(n) + '次' for n in value_count.values()]
counter = Counter(count_list)
from pyecharts.charts import Pie
c = Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add("", [list(z) for z in zip(counter.keys(), counter.values())])
c.set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例"))
c.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
c.render("./images/各學校參加次數統計餅圖.html")
c.render_notebook()
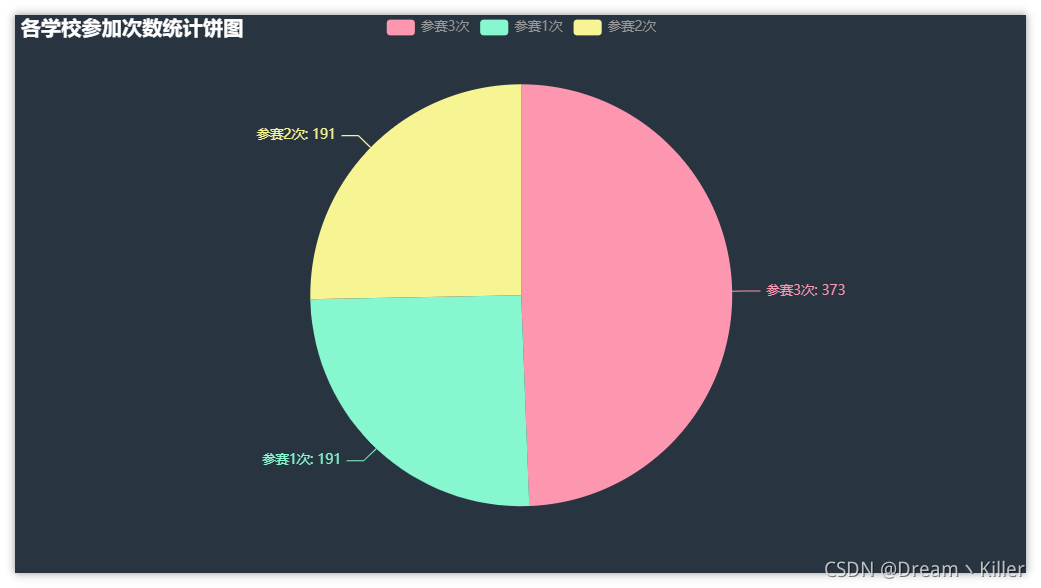
在這三年的參賽學校中,三次參賽的占了一半左右,參賽一次和參賽兩次的各占 25% 左右,這么說,參加比賽的學校還是愿意繼續下一屆繼續去參加,說明該比賽是有吸引學校的地方,
各年參賽學校層次劃分
統計各年參賽學校的層次,觀察參加比賽學校的層次分布,
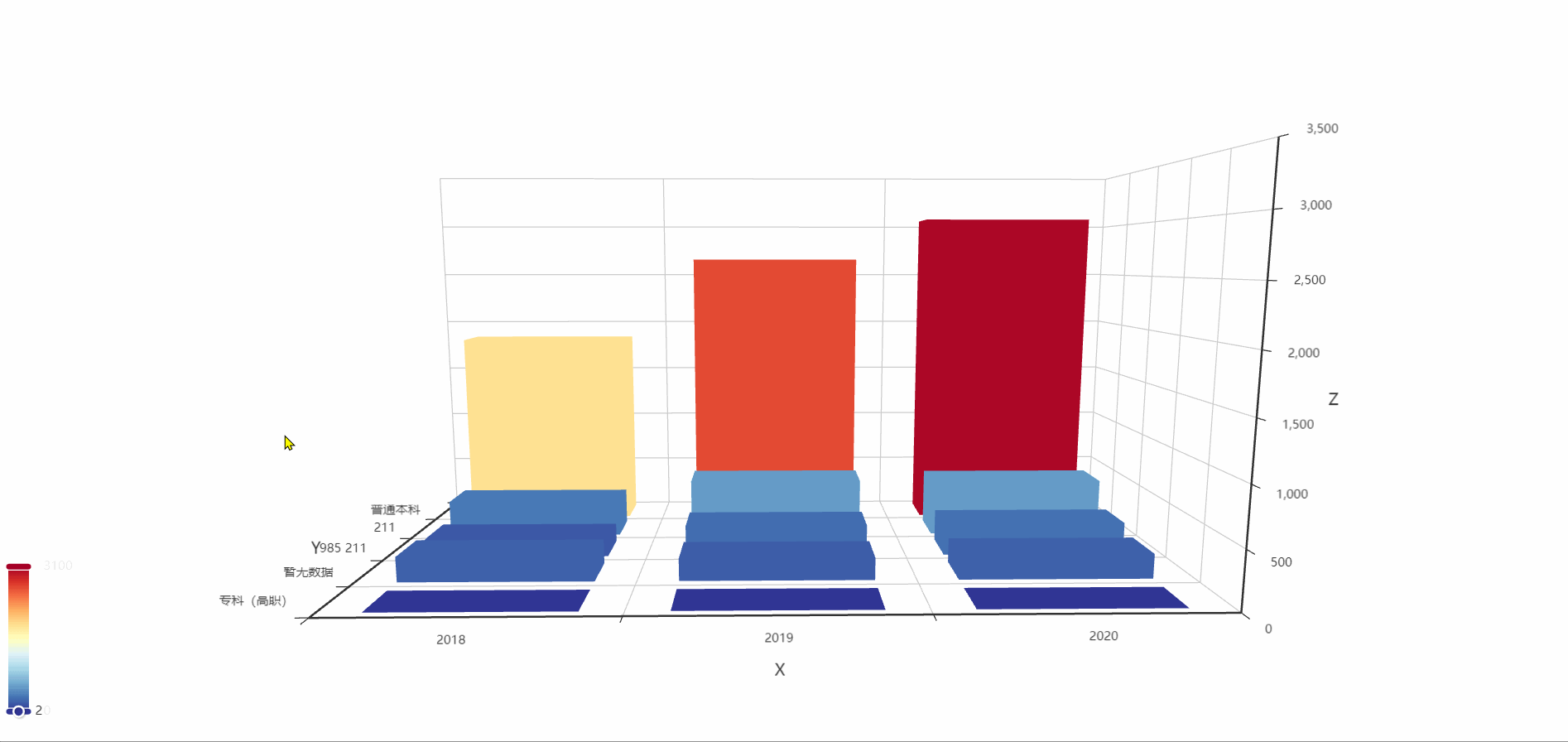
三年中,絕大多數的參賽者來自普通本科,其次為211,并且各層次的學校參賽人數在逐年上升,普通本科最為顯著,可以看到,隨著大賽的宣傳和計算機的普及,越來越多的人關注計算機方面的比賽,(對于暫無資料的那一列部分原因是因為學校的資訊沒有收錄,還有可能是參賽選手填寫學校時出現失誤造成)
參賽人數與獎項分布
根據作者和指導老師的人數進行組合,統計各獎項中出現的次數,繪制如下圖形,
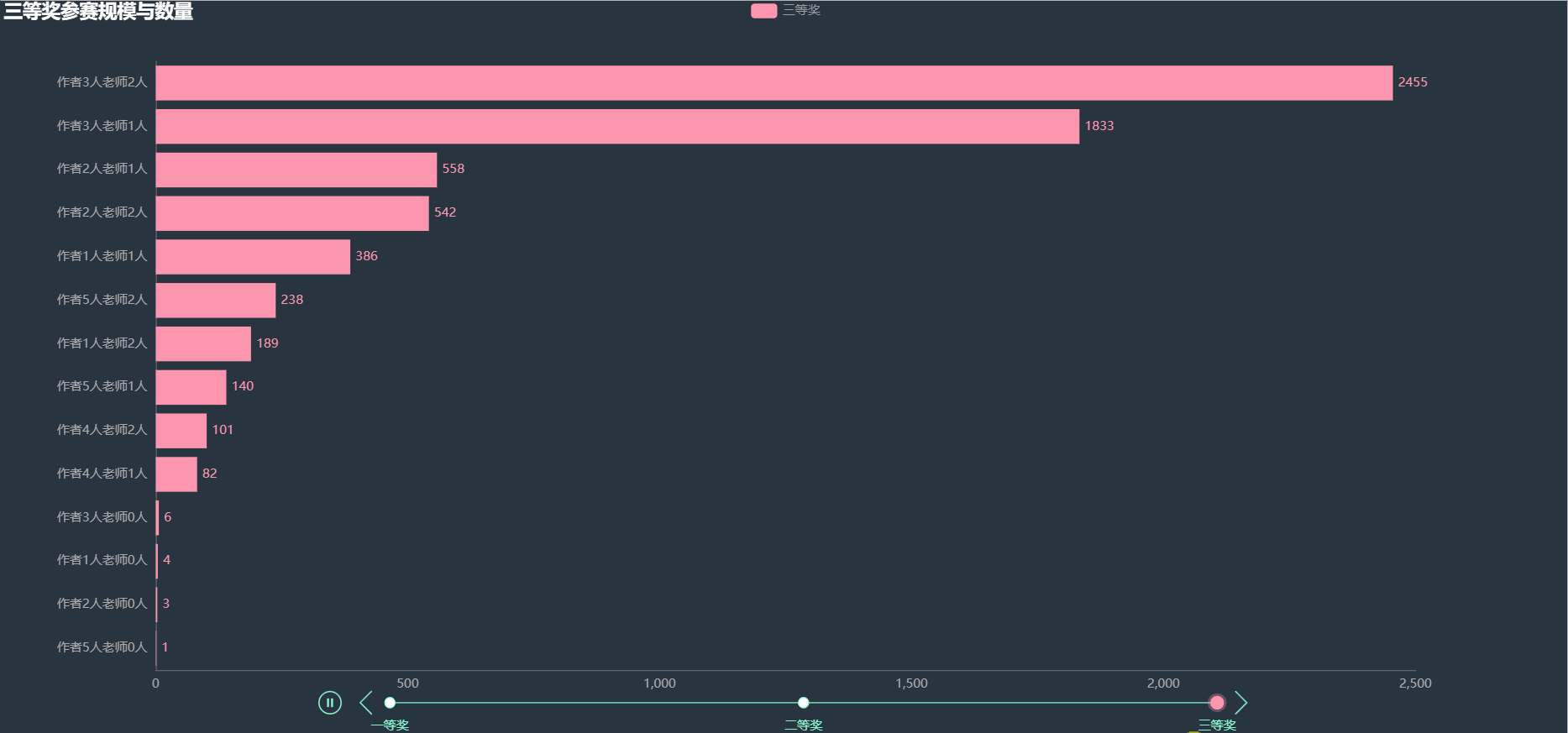
在各項獎項中,獲獎比例最多的都是3名作者2名老師的陣容,其次就是3名作者1名老師,其余的陣容獲獎人數就比較少了,看樣子也不是人數越多獲獎幾率越大,
獲獎作品名稱熱詞
首先定義一個加載停用詞的函式,用于加載本地停用詞,
def load_stopwords(read_path):
'''
讀取檔案每行內容并保存到串列中
:param read_path: 待讀取檔案的路徑
:return: 保存檔案每行資訊的串列
'''
result = []
with open(read_path, "r", encoding='utf-8') as f:
for line in f.readlines():
line = line.strip('\n') # 去掉串列中每一個元素的換行符
result.append(line)
return result
# 加載中文停用詞
stopwords = load_stopwords('wordcloud_stopwords.txt')
統計所有作品名稱中去除停用詞后的詞匯,保存到串列中,
import jieba
# 添加自定義詞典
jieba.load_userdict("自定義詞典.txt")
token_list = []
# 對標題內容進行分詞,并將分詞結果保存在串列中
for name in all_df['作品名稱']:
tokens = jieba.lcut(name, cut_all=False)
token_list += [token for token in tokens if token not in stopwords]
len(token_list)
統計該串列中各詞出現的頻率,取前100作為熱門詞,繪制詞云圖,
from pyecharts.charts import WordCloud
from collections import Counter
token_count_list = Counter(token_list).most_common(100)
new_token_list = []
for token, count in token_count_list:
new_token_list.append((token, str(count)))
c = WordCloud()
c.add(series_name="熱詞", data_pair=new_token_list, word_size_range=[20, 200])
c.set_global_opts(
title_opts=opts.TitleOpts(
title="獲獎作品熱詞", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
c.render("./images/獲獎作品熱詞.html")
c.render_notebook()

觀察上圖,能夠十分清晰的了解目前計算機中熱門的話題,如大資料、人工智能、演算法、可視化、管理系統、機器人等,這些方向一直都是計算機行業的熱門方向,也可以作為我們今后發展的一條道路,
總結
- 近年來,計算機設計大賽一等獎、二等獎的比例減少,三等獎比例增加,這就增加了獲得一、二等獎的難度與含金量,
- 東北部的大學更加關注該賽事,無論從參賽人數還是獲獎人數來看,其中沈陽師范大學、沈陽工學院、遼寧工業大學多次進入獲獎最多 Top10,
- 絕大多數的學校連續參加該比賽,在最近三年中,三次參賽的學校占了獲獎總學校的一半左右,
- 三年中,絕大多數的參賽者來自普通本科,其次為211,并且各層次的學校參賽人數在逐年上升,
- 獲獎的參賽選手中比例最多的是 3名作者2名老師 的陣容,其次就是 3名作者1名老師,(作者最多5人,指導老師2人 共7人)
- 作品中的熱門詞大資料、人工智能、演算法、可視化、管理系統、機器人等,
這就是本文所有的內容了,如果感徑訓不錯的話,? 點個贊再走吧!!!?
后續會繼續分享 資料分析 的文章,如果感興趣的話可以點個關注不迷路哦~,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/296927.html
標籤:其他
下一篇:qsort各種用法大全以及實作