?演算法系列文章推薦:
- LeetCode通關:聽說鏈表是門檻,這就抬腳跨門而入
- 面試刷演算法,這些api不可不知!
- LeetCode通關:陣列十七連,真是不簡單
- LeetCode通關:連刷三十九道二叉樹,刷瘋了!
大家好,我是老三,一個刷不動演算法的程式員,排序演算法相關題目盡管在力扣中不是很多,但是面試中動不動要手撕一下,接下來,我們看一下十大基本排序,
排序基礎
排序演算法的穩定性
什么是排序演算法的穩定性呢?
當待排序記錄的關鍵字均不相同時,排序結果是惟一的,否則排序結果不惟一[1],
在待排序的檔案中,若存在多個關鍵字相同的記錄,經過排序后這些具有相同關鍵字的記錄之間的相對次序保持不變,該排序方法是穩定的:
若具有相同關鍵字的記錄之間的相對次序發生變化,則稱這種排序方法是不穩定的,
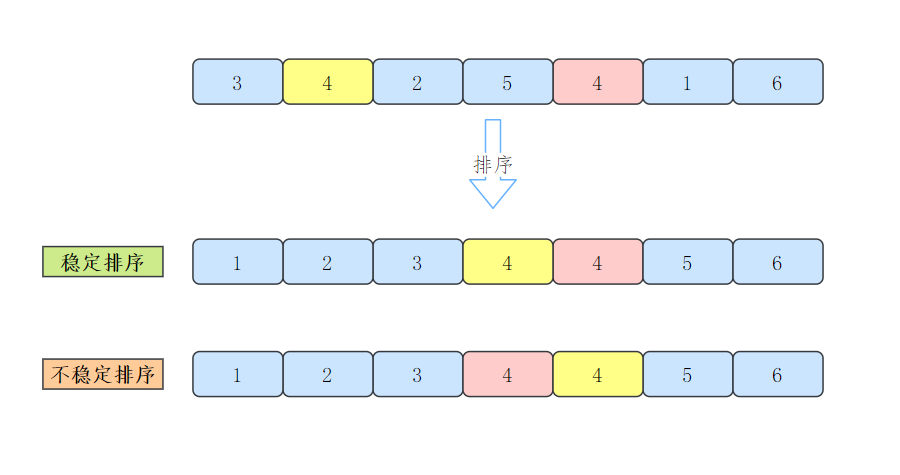
排序演算法的穩定性是針對所有輸入實體而言的,即在所有可能的輸入實體中,只要有一個實體使得演算法不滿足穩定性要求,那么這種排序演算法就是不穩定的,
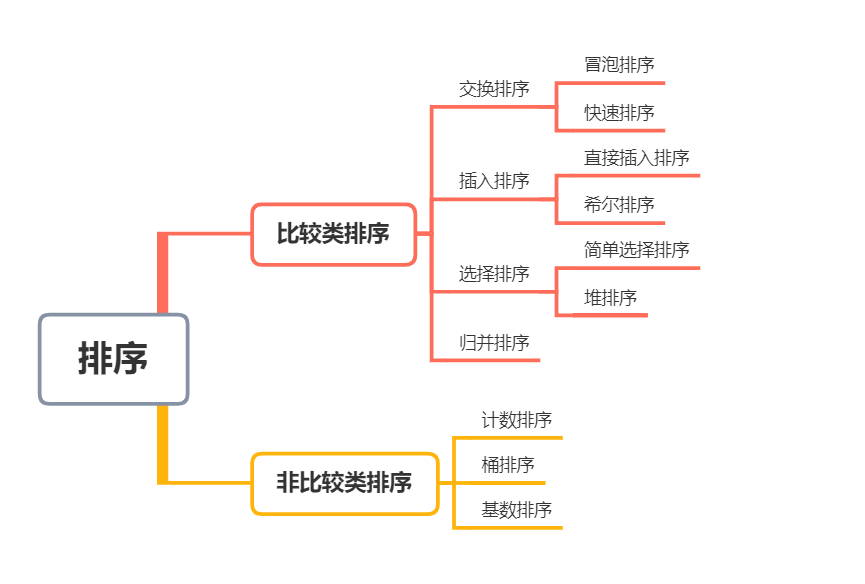
排序的分類
按在排序程序中是否涉及資料的內、外存交換來分類,排序大致分為兩類:內部排序和外部排序,
按照是否通過比較來決定元素間的相對次序,排序可以分為比較類排序和非比較類排序,
冒泡排序
冒泡排序原理
柿子挑軟的捏,先從最簡單的開始,
冒泡排序有著好聽的名字,也有著最好理解的思路,
冒泡排序的基本思想是,從一端到另一端遍歷,兩兩比較相鄰元素的大小,如果是反序則交換,
動圖如下(來源參考[4]):
簡單代碼實作
先簡單實作以下,很簡單,兩層回圈,相鄰元素比較:
public void sort(int[] nums) {
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
//升序
if (nums[i] > nums[j]) {
//交換
int temp = nums[i];
nums[j] = nums[i];
nums[i] = temp;
}
}
}
}
冒泡排序優化
上面的代碼實作還存在一個問題,什么問題呢?
哪怕陣列有序,它還是會接著遍歷,
所以可以用一個標志位來標志陣列是否有序,假如有序,就跳出遍歷,
public void sort(int[] nums) {
//標志位
boolean flag = true;
for (int i = 0; i < nums.length; i++) {
for (int j = 0; j < nums.length - i - 1; j++) {
//升序
if (nums[j] > nums[j + 1]) {
//交換
int temp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = temp;
}
}
//如果是有序的,結束回圈
if (flag) {
break;
}
}
}
冒泡排序性能分析
大小相同的元素沒有交換位置,所以冒泡排序是穩定的,
| 演算法名稱 | 最好時間復雜度 | 最壞時間復雜度 | 平均時間復雜度 | 空間復雜度 | 是否穩定 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n2) | O(n2) | O(1) | 穩定 |
選擇排序
選擇排序原理
選擇排序為什么叫選擇排序?原理是怎么樣的呢?
它的思路:首先在未排序的序列中找到最小或者最大的元素,放到排序序列的起始位置,然后再從未排序的序列中繼繼續尋找最小或者最大元素,然后放到已經排序序列的末尾,以此類推,直到所有元素排序完畢,
動圖如下(來源參考[4]):
來看一個例子,用選擇排序的方式排序陣列[2,5,4,1,3],
- 第一趟,找到陣列中最小的元素1,將它和陣列的第一個元素交換位置,
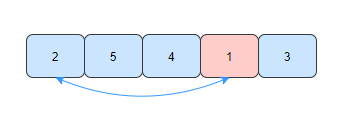
- 第二趟,在未排序的元素中找到最小的元素2,和陣列的第二個元素交換位置,
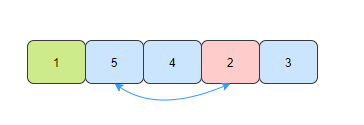
- 第三趟,在未排序的元素中找到最小的元素3,和陣列的第三個元素交換位置,
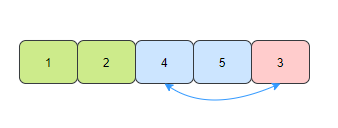
- 第四趟,在未排序的元素中找到最小的元素4,和陣列的第四個元素交換位置,
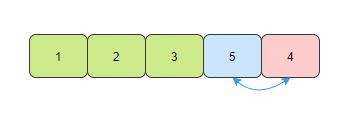
那么到這,我們的陣列就是有序的了,
選擇排序代碼實作
選擇排序的思路很簡單,實作起來也不難,
public void sort(int[] nums) {
int min = 0;
for (int i = 0; i < nums.length - 1; i++) {
for (int j = i + 1; j < nums.length; j++) {
//尋找最小的數
if (nums[j] < min) {
min = j;
}
}
//交換
int temp = nums[i];
nums[i] = nums[min];
nums[min] = temp;
}
}
選擇排序性能分析
選擇排序穩定嗎?
答案是不穩定的,因為在未排序序列中找到最小值之后,和排序序列的末尾元素交換,
| 演算法名稱 | 最好時間復雜度 | 最壞時間復雜度 | 平均時間復雜度 | 空間復雜度 | 是否穩定 |
|---|---|---|---|---|---|
| 選擇排序 | O(n2) | O(n2) | O(n2) | O(1) | 不穩定 |
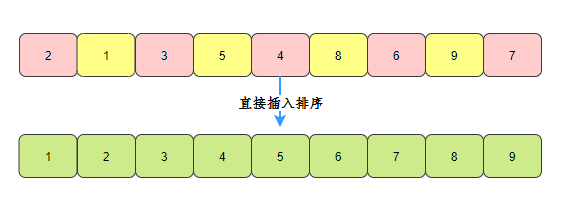
插入排序
插入排序原理
關于插入排序,有一個非常形象的比喻,斗地主——摸到的牌都是亂的,我們會把摸到的牌插到合適的位置,
它的思路:將一個元素插入到已經排好序的有序序列中,從而得到一個新的有序序列,
動圖如下(來源參考3):
還是以陣列[2,5,4,1,3]為例:
- 第一趟:從未排序的序列將元素5插入到已排序的序列的合適位置

- 第二趟:接著從未排序的序列中,將元素4插入到已經排序的序列的合適位置,需要遍歷有序序列,找到合適的位置

- 第三趟:繼續,把1插入到合適的位置

- 第五趟:繼續,把3插入到合適的位置

OK,排序結束,
插入排序代碼實作
找到插入元素的位置,移動其它元素,
public void sort(int[] nums) {
//無序序列從1開始
for (int i = 1; i < nums.length; i++) {
//需要插入有序序列的元素
int value = nums[i];
int j = 0;
for (j = i - 1; j >= 0; j--) {
//移動資料
if (nums[j] > value) {
nums[j + 1] = nums[j];
} else {
break;
}
}
//插入元素
nums[j + 1] = value;
}
}
插入排序性能分析
插入排序智慧移動比插入元素大的元素,所以相同元素相對位置不變,是穩定的,
從代碼里我們可以看出,如果找到了合適的位置,就不會再進行比較了,所以最好情況時間復雜度是O(n),
| 演算法名稱 | 最好時間復雜度 | 最壞時間復雜度 | 平均時間復雜度 | 空間復雜度 | 是否穩定 |
|---|---|---|---|---|---|
| 插入排序 | O(n) | O(n2) | O(n2) | O(1) | 穩定 |
希爾排序
希爾排序原理
希爾排序,名字來自它的發明者Shell,它是直接插入排序的改進版,
希爾排序的思路是:把整個待排序的記錄序列分割成若干個子序列,分別進行插入排序,
我們知道直接插入排序在面對大量無序資料的時候不太理想,希爾排序就是通過跳躍性地移動,來達到陣列元素地基本有序,再接著用直接插入排序,
希爾排序動圖(動圖來源參考[1]):

還是以陣列[2,5,6,1,7,9,3,8,4]為例,我們來看一下希爾排序的程序:
- 陣列元素個數為9,取7/2=4為下標差值,將下標差值為4的元素分為一組

- 組內進行插入排序,構成有序序列
- 再取4/2=2為 下標差值,將下標差值為2的元素分為一組

- 組內插入排序,構成有序序列
- 下標差值=2/2=1,將剩余的元素插入排序
希爾排序代碼實作
可以看看前面的插入排序,希爾排序
只是一個有步長的直接插入排序,
public void sort(int[] nums){
//下標差
int step=nums.length;
while (step>0){
//這個是可選的,也可以是3
step=step/2;
//分組進行插入排序
for (int i=0;i<step;i++){
//分組內的元素,從第二個開始
for (int j=i+step;j<nums.length;j+=step){
//要插入的元素
int value=nums[j];
int k;
for (k=j-step;k>=0;k-=step){
if (nums[k]>value){
//移動組內元素
nums[k+step]=nums[k];
}else {
break;
}
}
//插入元素
nums[k+step]=value;
}
}
}
}
希爾排序性能分析
- 穩定度分析
希爾排序是直接插入排序的變形,但是和直接插入排序不同,它進行了分組,所以不同組的相同元素的相對位置可能會發生改變,所以它是不穩定的,
- 時間復雜度分析
希爾排序的時間復雜度跟增量序列的選擇有關,范圍為 O(n^(1.3-2)) 在此之前的排序演算法時間復雜度基本都是 O(n2),希爾排序是突破這個時間復雜度的第一批演算法之一,
| 演算法名稱 | 時間復雜度 | 空間復雜度 | 是否穩定 |
|---|---|---|---|
| 希爾排序 | O(n^(1.3-2)) | O(1) | 不穩定 |
歸并排序
歸并排序原理
歸并排序是建立在歸并操作上的一種有效的排序演算法,歸并,就是合并的意思,在資料結構上的定義就是把把若干個有序序列合并成一個新的有序序列,
歸并排序是分治法的典型應用,分治什么意思呢?就是把一個大的問題分解成若干個小的問題來解決,
歸并排序的步驟,是把一個陣列切分成兩個,接著遞回,一直到單個元素,然后再合并,單個元素合并成小陣列,小陣列合并成大陣列,
動圖如下(來源參考[4]):
我們以陣列[2,5,6,1,7,3,8,4] 為例,來看一下歸并排序的程序:
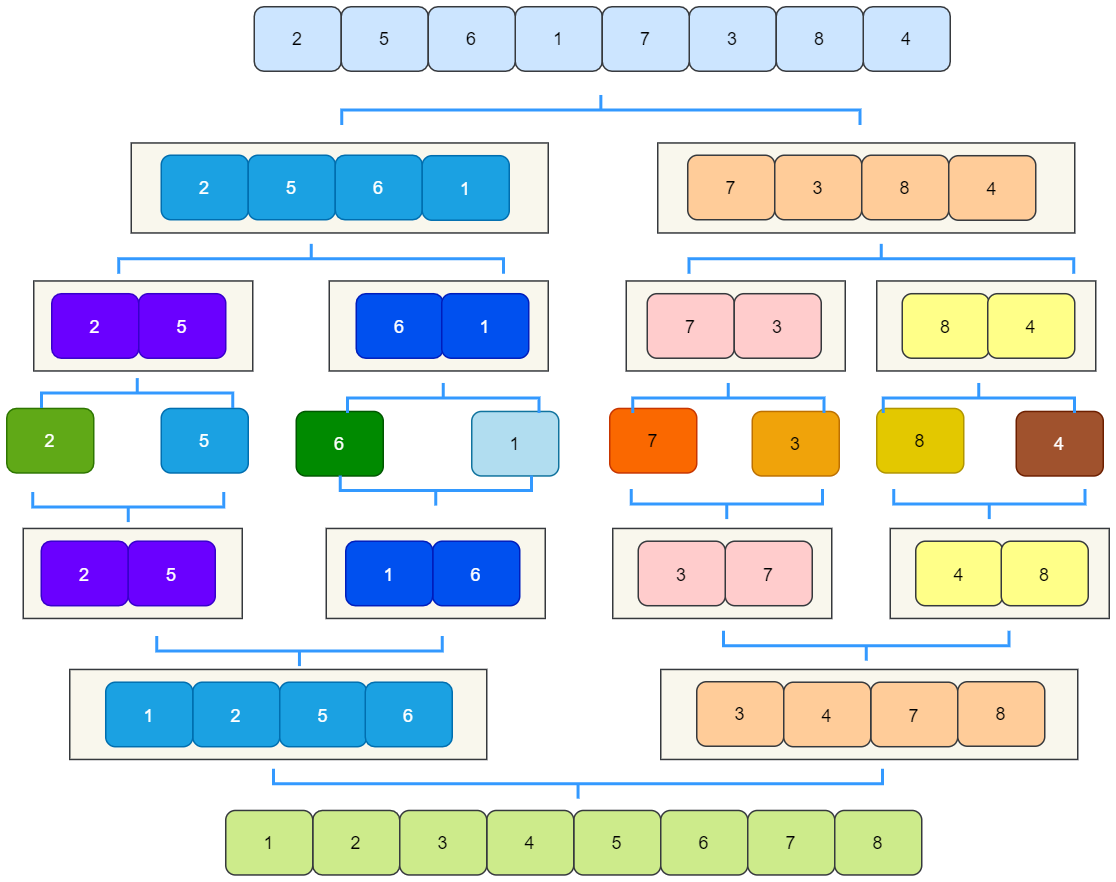
拆分就不用多講了,我們看看怎么合并,
歸并排序代碼實作
這里使用遞回來實作歸并排序:
- 遞回終止條件
遞回起始位置小于終止位置
- 遞回回傳結果
直接對傳入的陣列序列進行排序,所以無回傳值
- 遞回邏輯
將當前陣列分成兩組,分別分解兩組,最后歸并
代碼如下:
public class MergeSort {
public void sortArray(int[] nums) {
sort(nums, 0, nums.length - 1);
}
/**
* 歸并排序
*
* @param nums
* @param left
* @param right
*/
public void sort(int[] nums, int left, int right) {
//遞回結束條件
if (left >= right) {
return;
}
int mid = left + (right - left) / 2;
//遞回當前序列左半部分
sort(nums, left, mid);
//遞回當前序列右半部分
sort(nums, mid + 1, right);
//歸并結果
merge(nums, left, mid, right);
}
/**
* 歸并
*
* @param arr
* @param left
* @param mid
* @param right
*/
public void merge(int[] arr, int left, int mid, int right) {
int[] tempArr = new int[right - left + 1];
//左邊首位下標和右邊首位下標
int l = left, r = mid + 1;
int index = 0;
//把較小的數先移到新陣列中
while (l <= mid && r <= right) {
if (arr[l] <= arr[r]) {
tempArr[index++] = arr[l++];
} else {
tempArr[index++] = arr[r++];
}
}
//把左邊陣列剩余的數移入陣列
while (l <= mid) {
tempArr[index++] = arr[l++];
}
//把右邊剩余的數移入陣列
while (r <= right) {
tempArr[index++] = arr[r++];
}
//將新陣列的值賦給原陣列
for (int i = 0; i < tempArr.length; i++) {
arr[i+left] = tempArr[i];
}
}
}
歸并排序性能分析
- 時間復雜度
一趟歸并,我們需要把遍歷待排序序列遍歷一遍,時間復雜度O(n),
而歸并排序的程序,需要把陣列不斷二分,這個時間復雜度是O(logn),
所以歸并排序的時間復雜度是O(nlogn),
- 空間復雜度
使用了一個臨時陣列來存盤合并的元素,空間復雜度O(n),
- 穩定性
歸并排序是一種穩定的排序方法,
| 演算法名稱 | 最好時間復雜度 | 最壞時間復雜度 | 平均時間復雜度 | 空間復雜度 | 是否穩定 |
|---|---|---|---|---|---|
| 歸并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 穩定 |
快速排序
快速排序原理
快速排序是面試最高頻的排序演算法,
快速排序和上面的歸并排序一樣,都是基于分治思想的,大概程序:
- 選出一個基準數,基準值一般取序列最左邊的元素
- 重新排序序列,比基準值小的放在基準值左邊,比基準值大的放在基準值右邊,這就是所謂的磁區
快速排序動圖如下:
我們來看一個完整的快速排序圖示:
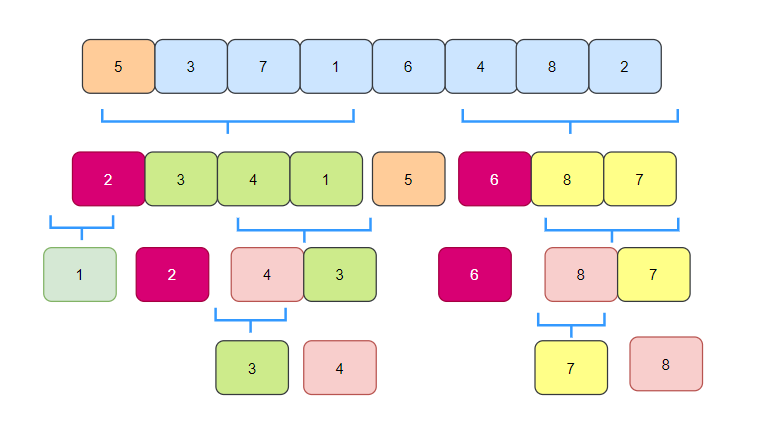
快速排序代碼實作
單邊掃描快速排序
選擇一個數作為基準數pivot,同時設定一個標記 mark 代表左邊序列最右側的下標位置,接下來遍歷陣列,如果元素大于基準值,無操作,繼續遍歷,如果元素小于基準值,則把 mark + 1 ,再將 mark 所在位置的元素和遍歷到的元素交換位置,mark 這個位置存盤的是比基準值小的資料,當遍歷結束后,將基準值與 mark 所在元素交換位置,
public class QuickSort0 {
public void sort(int[] nums) {
quickSort(nums, 0, nums.length - 1);
}
public void quickSort(int[] nums, int left, int right) {
//結束條件
if (left >= right) {
return;
}
//磁區
int partitonIndex = partion(nums, left, right);
//遞回左磁區
quickSort(nums, left, partitonIndex - 1);
//遞回右磁區
quickSort(nums, partitonIndex + 1, right);
}
//磁區
public int partion(int[] nums, int left, int right) {
//基準值
int pivot = nums[left];
//mark標記初始下標
int mark = left;
for (int i = left + 1; i <= right; i++) {
if (nums[i] < pivot) {
//小于基準值,則mark+1,并交換位置
mark++;
int temp = nums[mark];
nums[mark] = nums[i];
nums[i] = temp;
}
}
//基準值與mark對應元素調換位置
nums[left] = nums[mark];
nums[mark] = pivot;
return mark;
}
}
雙邊掃描快速排序
還有另外一種雙邊掃描的做法,
選擇一個數作為基準值,然后從陣列左右兩邊進行掃描,先從左往右找到一個大于基準值的元素,將它填入到right指標位置,然后轉到從右往左掃描,找到一個小于基準值的元素,將他填入到left指標位置,
public class QuickSort1 {
public int[] sort(int[] nums) {
quickSort(nums, 0, nums.length - 1);
return nums;
}
public void quickSort(int[] nums, int low, int high) {
if (low < high) {
int index = partition(nums, low, high);
quickSort(nums, low, index - 1);
quickSort(nums, index + 1, high);
}
}
public int partition(int[] nums, int left, int right) {
//基準值
int pivot = nums[left];
while (left < right) {
//從右往左掃描
while (left < right && nums[right] >= pivot) {
right--;
}
//找到第一個比pivot小的元素
if (left < right) nums[left] = nums[right];
//從左往右掃描
while (left < right && nums[left] <= pivot) {
left++;
}
//找到第一個比pivot大的元素
if (left < right) nums[right] = nums[left];
}
//基準數放到合適的位置
nums[left] = pivot;
return left;
}
}
快速排序性能分析
- 時間復雜度
快速排序的時間復雜度和歸并排序一樣,都是O(nlogn),但是這是最優的情況,也就是每次都能把陣列切分到兩個差不多大小的子陣列,
如果出現極端情況,例如一個有序的序列[5,4,3,2,1] ,選基準值為5,那么需要切分n-1次才能完成整個快速排序的程序,這種情況時間復雜度就退化到了O(n2),
- 空間復雜度
快速排序是一種原地排序的演算法,空間復雜度是O(1),
- 穩定性
快排的比較和交換是跳躍進行的,所以快排是一種不穩定的排序演算法,
| 演算法名稱 | 最好時間復雜度 | 最壞時間復雜度 | 平均時間復雜度 | 空間復雜度 | 是否穩定 |
|---|---|---|---|---|---|
| 快速排序 | O(nlogn) | O(n2) | O(nlogn) | O(1) | 不穩定 |
堆排序
堆排序原理
還記得我們前面的簡單選擇排序嗎?堆排序是簡單選擇排序的一種升級版,
在學習堆排序之前,什么是堆呢?
完全二叉樹是堆的一個比較經典的堆實作,
我們先來了解一下什么是完全二叉樹,
簡答說,如果節點不滿,那它不滿的部分只能在最后一層的右側,
我們來看幾個示例,
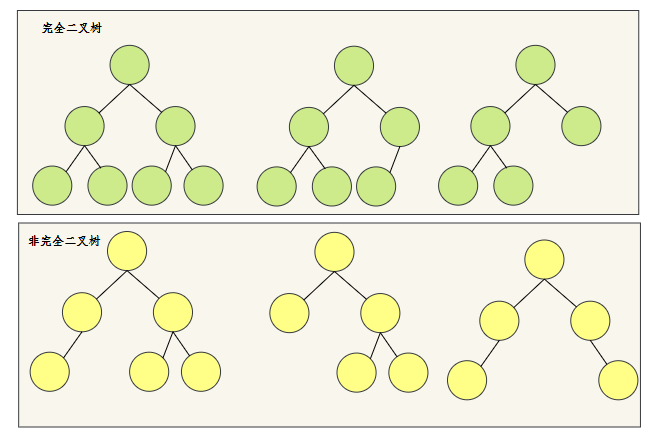
相信看了這幾個示例,就清楚什么是完全二叉樹,什么是非完全二叉樹,
那堆又是什么呢?
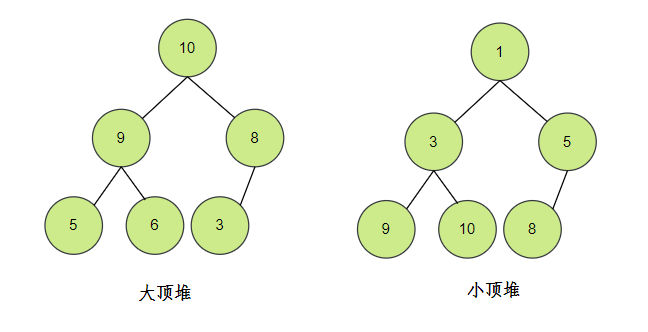
- 必須是完全二叉樹
- 任一節點的值必須是其子樹的最大值或最小值
- 最大值時,稱為“最大堆”,也稱大頂堆;
- 最小值時,稱為“最小堆”,也稱小頂堆,
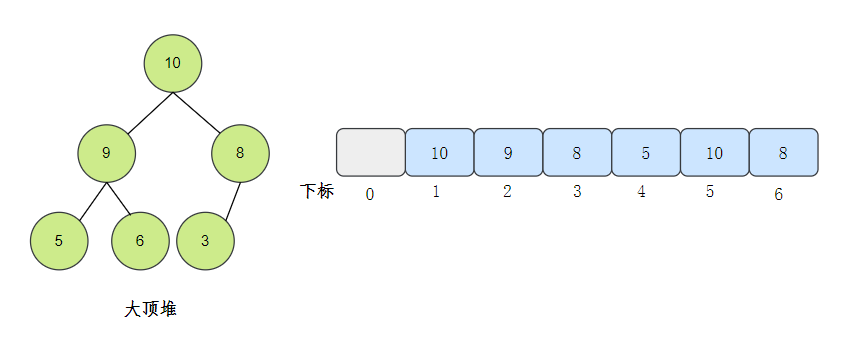
因為堆是完全二叉樹,所以堆可以用陣列存盤,
按層來將元素存盤到陣列對應位置,從下標1開始存盤,可以省略一些計算,
好了,我們現在對堆已經有一些了解了,我們來看一下堆排序是什么樣的呢?[2]
- 建立一個大頂堆
- 將堆頂元素(最大值)插入陣列末尾
- 讓新的最大元素上浮到堆頂
- 重復程序,直到排序完成
動圖如下(來源參考[1]):
![堆排序動圖(來自參考[1])](https://img.uj5u.com/2021/09/06/2621870608443528.gif)
關于建堆,有兩種方式,一種是上浮,一種是下沉,
上浮是什么呢?就是把子節點一層層上浮到合適的位置,
下沉是什么呢?就是把堆頂元素一層層下沉到合適的位置,
上面的動圖,使用的就是下沉的方式,
堆排序代碼實作
public class HeapSort {
public void sort(int[] nums) {
int len = nums.length;
//建堆
buildHeap(nums, len);
for (int i = len - 1; i > 0; i--) {
//將堆頂元素和堆末元素調換
swap(nums, 0, i);
//陣列計數長度減1,隱藏堆尾元素
len--;
//將堆頂元素下沉,使最大的元素浮到堆頂來
sink(nums, 0, len);
}
}
/**
* 建堆
*
* @param nums
* @param len
*/
public void buildHeap(int[] nums, int len) {
for (int i = len / 2; i >= 1; i--) {
//下沉
sink(nums, i, len);
}
}
/**
* 下沉操作
*
* @param nums
* @param index
* @param end
*/
public void sink(int[] nums, int index, int end) {
//左子節點下標
int leftChild = 2 * index + 1;
//右子節點下標
int rightChild = 2 * index + 2;
//要調整的節點下標
int current = index;
//下沉左子樹
if (leftChild < end && nums[leftChild] > nums[current]) {
current = leftChild;
}
//下沉右子樹
if (rightChild < end && nums[rightChild] > nums[current]) {
current = rightChild;
}
//如果下標不相等,證明調換過了
if (current!=index){
//交換值
swap(nums,index,current);
//繼續下沉
sink(nums,current,end);
}
}
public void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
堆排序性能分析
- 時間復雜度
堆排的時間復雜度和快排的時間復雜度一樣,都是O(nlogn),
- 空間復雜度
堆排沒有引入新的空間,原地排序,空間復雜度O(1),
- 穩定性
堆頂的元素不斷下沉,交換,會改變相同元素的相對位置,所以堆排是不穩定的,
| 演算法名稱 | 時間復雜度 | 空間復雜度 | 是否穩定 |
|---|---|---|---|
| 堆排序 | O(nlogn) | O(1) | 不穩定 |
計數排序
文章開始我們說了,排序分為比較類和非比較類,計數排序是一種非比較類的排序方法,
計數排序是一種線性時間復雜度的排序,利用空間來換時間,我們來看看計數排序是怎么實作的吧,
計數排序原理
計數排序的大致程序[4]:
- 找出待排序的陣列中最大和最小的元素
- 統計陣列中每個值為i的元素出現的次數,存入陣列arr的第i項;
- 對所有的計數累加(從arr中的第一個元素開始,每一項和前一項相加);
- 反向填充目標陣列:將每個元素i放在新陣列的第arr(i)項,每放一個元素就將arr(i)減去1,
我們看一下動圖演示(來自參考[4]):
![計數排序動圖,來自參考[4]](https://img.uj5u.com/2021/09/06/2621870608443529.gif)
我們拿一個陣列來看一下完整程序:[6,8,5,1,2,2,3]
- 首先,找到陣列中最大的數,也就是8,創建一個最大下標為8的空陣列arr
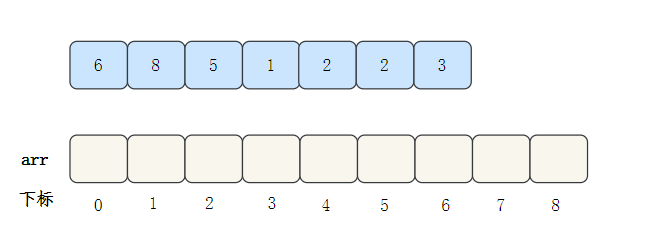
- 遍歷資料,將資料的出現次數填入arr對應的下標位置中
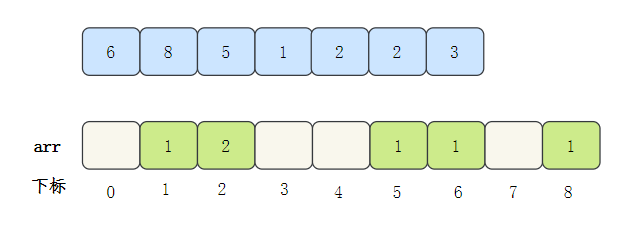
- 然后輸出陣列元素的下標值,元素的值是幾,就輸出幾次
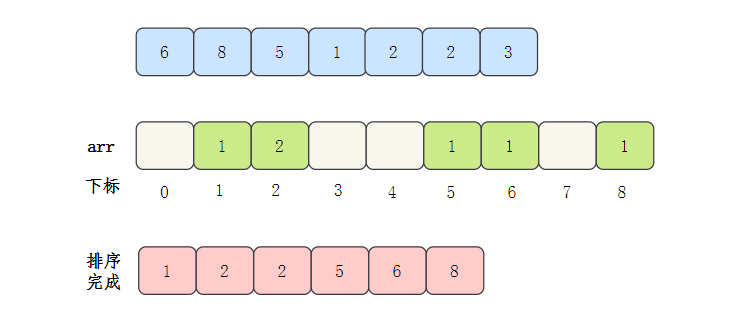
計數排序代碼實作
public class CountSort {
public void sort(int[] nums) {
//查找最大值
int max = findMax(nums);
//創建統計次數新陣列
int[] countNums = new int[max + 1];
//將nums元素出現次數存入對應下標
for (int i = 0; i < nums.length; i++) {
int num = nums[i];
countNums[num]++;
nums[i] = 0;
}
//排序
int index = 0;
for (int i = 0; i < countNums.length; i++) {
while (countNums[i] > 0) {
nums[index++] = i;
countNums[i]--;
}
}
}
public int findMax(int[] nums) {
int max = nums[0];
for (int i = 0; i < nums.length; i++) {
if (nums[i] > max) {
max = nums[i];
}
}
return max;
}
}
OK,乍一看沒啥問題,但是仔細想想,其實還是有些毛病的,毛病在哪呢?
-
如果我們要排序的元素有0怎么辦呢?例如
[0,0,5,2,1,3,4],arr初始都為0,怎么排呢?這個很難解決,有一種辦法,就是計數的時候原陣列先加10,[-1,0,2],排序寫回去的時候再減,但是如果剛好碰到有-10這個元素就涼涼,
-
如果元素的范圍很大呢?例如
[9992,9998,9993,9999],那我們申請一個10000個元素的陣列嗎?這個可以用偏移量解決,找到最大和最小的元素,計算偏移量,例如
[9992,9998,9993,9999],偏移量=9999-9992=7,我們只需要建立一個容量為8的陣列就可以了,
解決第二個問題的版本如下:
public class CountSort1 {
public void sort(int[] nums) {
//查找最大值
int max = findMax(nums);
//尋找最小值
int min = findMin(nums);
//偏移量
int gap = max - min;
//創建統計次數新陣列
int[] countNums = new int[gap + 1];
//將nums元素出現次數存入對應下標
for (int i = 0; i < nums.length; i++) {
int num = nums[i];
countNums[num - min]++;
nums[i] = 0;
}
//排序
int index = 0;
for (int i = 0; i < countNums.length; i++) {
while (countNums[i] > 0) {
nums[index++] = min + i;
countNums[i]--;
}
}
}
public int findMax(int[] nums) {
int max = nums[0];
for (int i = 0; i < nums.length; i++) {
if (nums[i] > max) {
max = nums[i];
}
}
return max;
}
public int findMin(int[] nums) {
int min = nums[0];
for (int i = 0; i < nums.length; i++) {
if (nums[i] < min) {
min = nums[i];
}
}
return min;
}
}
計數排序性能分析
- 時間復雜度
我們整體運算次數是n+n+n+k=3n+k,所以使勁復雜度是O(n+k),
- 空間復雜度
引入了輔助陣列,空間復雜度O(n),
- 穩定性
我們的實作實際上是不穩定的,但是計數排序是有穩定的實作的,可以查看參考[1],
同時我們通過實作也發現,計數排序實際上不適合有負數的,元素偏移值過大的陣列,
桶排序
桶陣列可以看做計數排序的升級版,它把元素分到若干個桶中,每個桶中的元素再單獨排序,
桶排序原理
桶排序大概的程序:
- 設定一個定量的陣列當作空桶;
- 遍歷輸入資料,并且把元素一個一個放到對應的桶里去;
- 對每個不是空的桶進行排序;
- 從不是空的桶里把排好序的資料拼接起來,
桶排序動圖如下(動圖來源參考[1]):
![桶排序動圖(來源參考[1])](https://img.uj5u.com/2021/09/06/2621870608443533.gif)
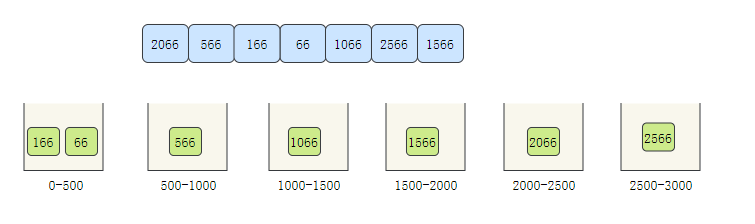
我們上面說了,計數排序不適合偏移量過大的陣列,我們拿一個偏移量非常大的陣列[2066,566,166,66,1066,2566,1566]為例,來看看桶排序的程序,
- 創建6個桶,分別存盤0-500,500-1000,1000-1500,1500-2000,2000-2500,2500-3000的元素
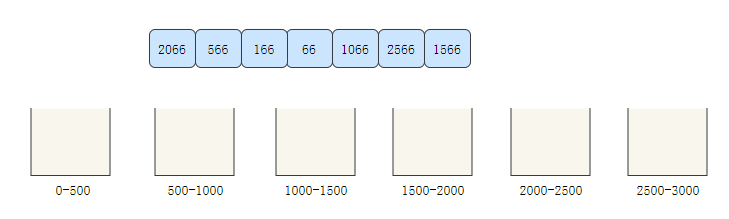
- 遍歷陣列,將元素分別分配到對應的桶中
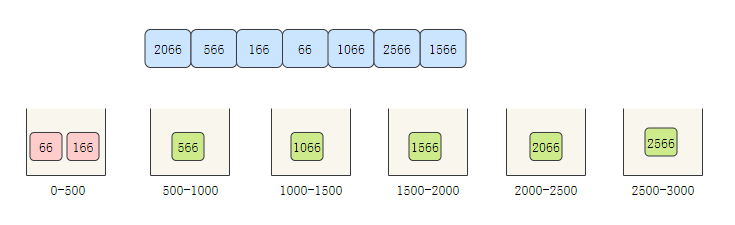
- 桶中元素排序,這里我們明顯只用排序第一個桶
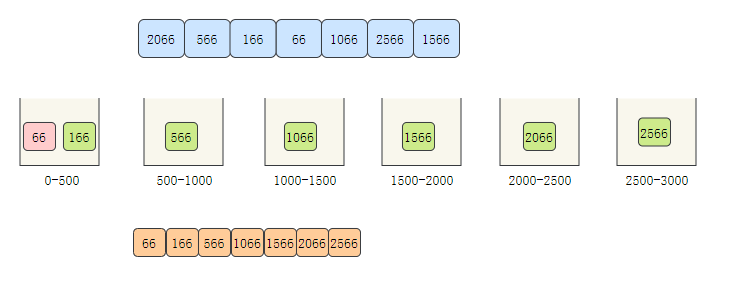
- 將桶中的元素依次取出,取出的元素就是有序的了
桶排序代碼實作
桶排序的實作我們要考慮幾個問題:
- 桶該如何表示?
- 桶的數量怎么確定?
- 桶內排序用什么方法?
我們來看一下代碼:
public class BucketSort {
public void sort(int[] nums) {
int len = nums.length;
int max = nums[0];
int min = nums[0];
//獲取最大值和最小值
for (int i = 1; i < len; i++) {
if (nums[i] > max) {
max = nums[i];
}
if (nums[i] < min) {
min = nums[i];
}
}
//計算步長
int gap = max - min;
//使用串列作為桶
List<List<Integer>> buckets = new ArrayList<>();
//初始化桶
for (int i = 0; i < gap; i++) {
buckets.add(new ArrayList<>());
}
//確定桶的存盤區間
int section = gap / len - 1;
//陣列入桶
for (int i = 0; i < len; i++) {
//判斷元素應該入哪個桶
int index = nums[i] / section - 1;
if (index < 0) {
index = 0;
}
//對應的桶添加元素
buckets.get(index).add(nums[i]);
}
//對桶內的元素排序
for (int i = 0; i < buckets.size(); i++) {
//這個底層呼叫的是 Arrays.sort
// 這個api不同情況下可能使用三種排序:插入排序,快速排序,歸并排序,具體看參考[5]
Collections.sort(buckets.get(i));
}
//將桶內的元素寫入原陣列
int index = 0;
for (List<Integer> bucket : buckets) {
for (Integer num : bucket) {
nums[index] = num;
index++;
}
}
}
}
桶排序性能分析
- 時間復雜度
桶排序最好的情況,就是元素均勻分配到了每個桶,時間復雜度O(n),最壞情況,是所有元素都分配到一個桶中,時間復雜度是O(n2),平均的時間復雜度和技術排序一樣,都是O(n+k),
- 空間復雜度
桶排序,需要存盤n個額外的桶,桶中又要存盤k個元素,所以空間復雜度是O(n+k),
- 穩定性
穩定性得看桶中排序用的什么排序演算法,桶中用的穩定排序演算法,那么就是穩定的,用的不穩定的排序演算法,那么就是不穩定的,
基數排序
基數排序原理
基數排序是一種非比較型的排序方法,
它的基本原理是將元素按照位數切割成不同的數字,然后按照每個位數進行比較,
大概程序:
- 取得陣列中的最大數,并取得位數;
- arr為原始陣列,從最低位開始取每個位組成radix陣列
- 對radix進行計數排序(利用計數排序適用于小范圍數的特點)
動圖圖示如下(來源參考[1]):
![基數排序-來源參考[1]](https://img.uj5u.com/2021/09/06/2621870608443538.gif)
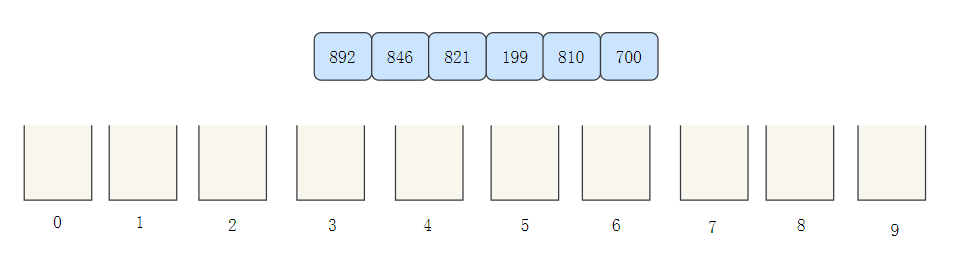
基數排序可以說是桶排序的一個進化,我們以[ 892, 846, 821, 199, 810,700 ]來看一下基數排序的程序:
- 創建十個桶用來存盤元素
- 根據個位數,將元素分別分配到不同的桶中
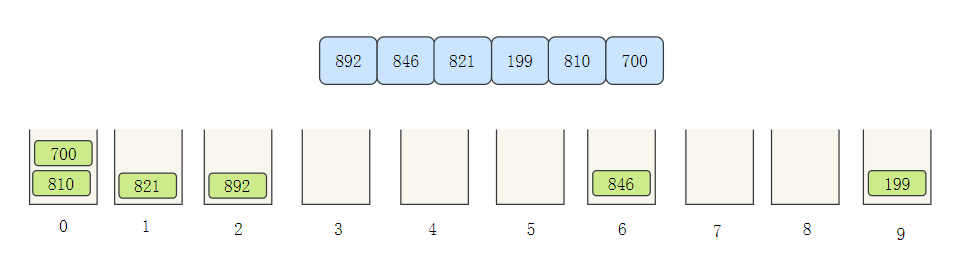
- 然后將桶中的元素依次取出
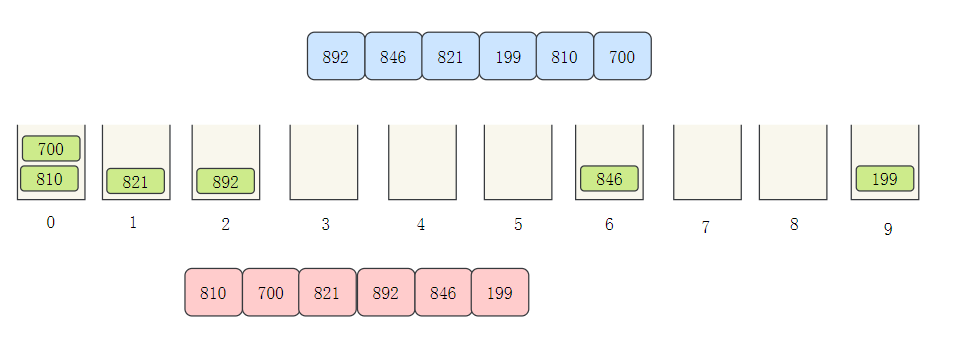
- 接下來排十位數,根據十位數分配桶,再依次取出
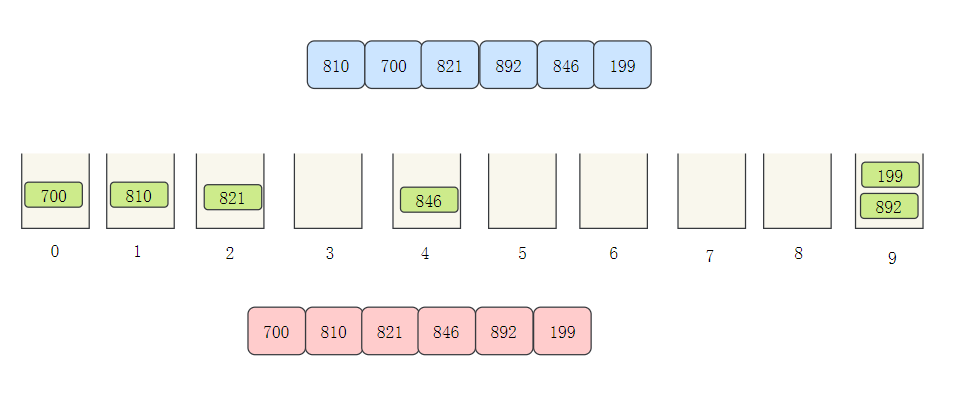
- 接下來百位數
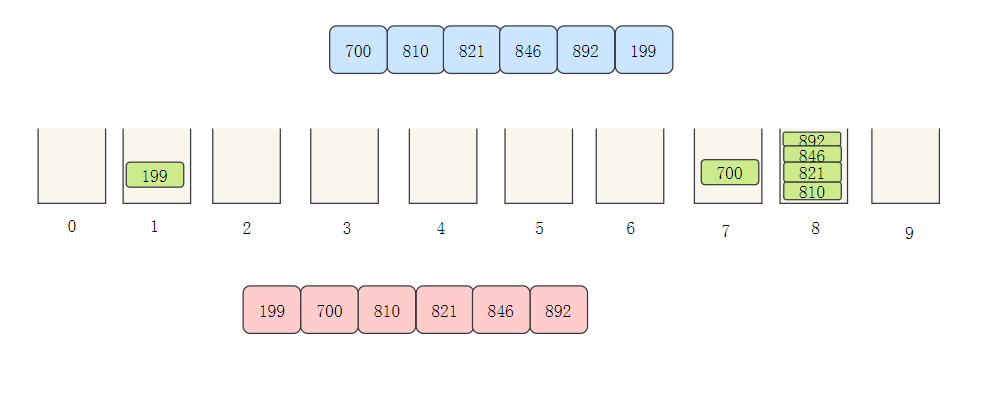
基數排序代碼實作
public class RadixSort {
public void sort(int[] nums) {
int len = nums.length;
//最大值
int max = nums[0];
for (int i = 0; i < len; i++) {
if (nums[i] > max) {
max = nums[i];
}
}
//當前排序位置
int location = 1;
//用串列實作桶
List<List<Integer>> buckets = new ArrayList<>();
//初始化size為10的一個桶
for (int i = 0; i < 10; i++) {
buckets.add(new ArrayList<>());
}
while (true) {
//元素最高位數
int d = (int) Math.pow(10, (location - 1));
//判斷是否排完
if (max < d) {
break;
}
//資料入桶
for (int i = 0; i < len; i++) {
//計算余數 放入相應的桶
int number = ((nums[i] / d) % 10);
buckets.get(number).add(nums[i]);
}
//寫回陣列
int nn = 0;
for (int i = 0; i < 10; i++) {
int size = buckets.get(i).size();
for (int ii = 0; ii < size; ii++) {
nums[nn++] = buckets.get(i).get(ii);
}
buckets.get(i).clear();
}
location++;
}
}
}
基數排序性能分析
- 時間復雜度
時間復雜度O(n+k),其中n陣列元素個數,k為陣列元素最高位數,
- 空間復雜度
和桶排序一樣,因為引入了桶的存盤空間,所以空間復雜度O(n+k),
- 穩定性
因為基數排序程序,每次都是將當前位數是哪個相同數值的元素統一分配到桶中,并不交換位置,所以基數排序是穩定的,
總結
這篇文章,我們學習了十大基本排序,來簡單總結一下,
首先最簡單的冒泡排序:兩層回圈,相鄰交換;
選擇排序:未排序和排序兩分,從未排序序列中尋找最小的元素,放在排序序列末尾;
插入排序:斗地主摸牌思維,把一個元素插入到有序序列合適位置;
希爾排序:插入排序plus,先把序列分割,再分別插入排序;
歸并排序:分治思想第一彈,先將序列切分,再在合并程序排序;
快速排序:分治思想第二彈,基準數磁區原序列,小的放左邊,大的放右邊;
堆排序:選擇排序plus,建立大頂堆,堆頂元素(最大值)插入序列末尾,再讓新的元素上浮,
計數排序:空間換時間第一彈,利用新陣列,統計對應元素出現次數,輸出新陣列下標,原陣列完成排序;
桶排序:空間換時間第二彈,將原陣列的元素分到若干個桶,每個桶單獨排序,再把桶里元素拼起來;
基數排序:空間換時間第三彈,桶排序plus,根據數位,把元素分桶,然后按每個位數比較,
十大基本排序性能匯總:
| 排序方法 | 時間復雜度(平均) | 時間復雜度(最壞) | 時間復雜度(最好) | 空間復雜度 | 穩定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | O(n) | O(1) | 穩定 |
| 選擇排序 | O(n2) | O(n2) | O(n2) | O(1) | 不穩定 |
| 插入排序 | O(n2) | O(n2) | O(n) | O(1) | 穩定 |
| 希爾排序 | O(n^(1.3-2)) | O(n2) | O(n) | O(1) | 不穩定 |
| 歸并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 穩定 |
| 快速排序 | O(nlogn) | O(n2) | O(nlogn) | O(nlogn) | 不穩定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不穩定 |
| 計數排序 | O(n+k) | O(n+k) | O(n+k) | O(n) | 穩定 |
| 桶排序 | O(n+k) | O(n2) | O(n) | O(n+k) | 穩定 |
| 基數排序 | O(n*k) | O(n*k) | O(n*k) | O(n+k) | 穩定 |
簡單的事情重復做,重復的事情認真做,認真的事情有創造性地去做,
我是三分惡,一個能文能武的全堆疊開發,
點贊、關注不迷路,咱們下期見!
參考:
[1].這或許是東半球分析十大排序演算法最好的一篇文章
[2]. https://github.com/chefyuan/algorithm-base
[2].《資料結構與演算法分析》
[3]. 面試高頻:Java常用的八大排序演算法一網打盡!
[4]. 十大經典排序演算法(動圖演示)
[5]. 剖析JDK8中Arrays.sort底層原理及其排序演算法的選擇
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/297890.html
標籤:其他