●🧑個人主頁:你帥你先說.
●📃歡迎點贊👍關注💡收藏💖
●📖既選擇了遠方,便只顧風雨兼程,
●🤟歡迎大家有問題隨時私信我!
●🧐著作權:本文由[你帥你先說.]原創,CSDN首發,侵權必究,
目錄
- 1.字符指標
- 2.指標陣列
- 3.陣列指標
- 3.1陣列指標的定義
- 3.2陣列指標的使用
- 4.陣列引數、指標引數
- 4.1一維陣列傳參
- 4.2二維陣列傳參
- 4.3一級指標傳參
- 4.4二級指標傳參
- 5.函式指標
- 6.函式指標陣列
- 7.回呼函式
- 7.1qsort函式
- 8.指向函式指標陣列的指標
1.字符指標
在指標的型別中我們知道有一種指標型別為字符指標 char* ,
int main()
{
char ch = 'w';
char * pc = &ch;//pc是指向一個字符變數
const char* p = "hello world";
//"hello world"是一個常量字串-存放在記憶體的常量區
//p里面存的是hello world 的首字母h的地址,通過首元素地址就可以訪問整個字串了
}
接下來我們看一道經典的筆試題
#include <stdio.h>
int main()
{
char str1[] = "hello world.";
char str2[] = "hello world.";
char *str3 = "hello world.";
char *str4 = "hello world.";
if(str1 ==str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if(str3 ==str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}
運行結果

第一個結果如果你錯了,實際上就是陣列名是首元素地址這個觀念還沒深入你的大腦,str1和str2是兩個不同的陣列,所以開辟的空間也是不同的,所以地址不會是相同的,
而第二個雖然是兩個不同的指標,可訪問的都是hello world這個字串,存的都是首元素h的地址,所以地址是相同的,
2.指標陣列
前面我們已經介紹過了指標陣列,指標陣列是一個存放指標的陣列,
我們通過一段代碼來加深理解
#include<stdio.h>
int main()
{
int a = 10;
int b = 20;
int c = 30;
int d = 40;
int* arr2[4] = {&a, &b, &c, &d};//arr2就是整型指標的陣列
int i = 0;
for (i = 0; i < 4; i++)
{
printf("%d ", *arr2[i]);
}//輸出 10 20 30 40
return 0;
}
也可以這樣理解
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
int* parr[] = { arr1, arr2, arr3 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d ", parr[i][j]);
//輸出陣列元素的內容
//p[i] == *(p+i)
//parr[i][j] == *(parr[i]+j)
}
printf("\n");
}
return 0;
}
發現沒,如果在指標陣列里面存陣列就相當于一個二維陣列,
還可以這樣理解
#include<stdio.h>
int main()
{
const char* arr[5] = {"abcdef", "bcdefg", "hehe", "haha", "zhangsan"};
int i = 0;
for (i = 0; i < 5; i++)
{
printf("%s\n", arr[i]);
//輸出所有字串
//注意別寫成*arr[i],*arr[i]是列印一個字符,arr[i]是陣列名存的是首字符的地址,通過首字符的地址訪問其它字符從而列印出字串
}
}
如果仔細觀察你會發現指標陣列的定義方式和一級指標很像,所以指標陣列是用二級指標來存放的,
3.陣列指標
3.1陣列指標的定義
指向陣列的指標,
#include<stdio.h>
int main()
{
int a = 10;
int* pi = &a;//整型的地址存放在整型指標中
char ch = 'w';
char* pc = &ch;//字符的地址存放在字符指標中
int arr[10] = {0};
int* p = arr;// arr是陣列首元素的地址
//int* parr[10]; //這樣寫是陣列
int (*parr)[10] = &arr;//取出的是陣列的地址, 應該存放到陣列指標中
return 0;
}
那陣列指標的型別是什么?要判斷型別我們經常使用的方法是去掉名字,剩下的就是型別,例如int(*parr)[10]的型別就是(*)[10],
看完這個例子,出道題來考考大家是否掌握了
int* arr[10];
該怎樣定義這個陣列指標來存放陣列?
相信很多人想都不想直接
int (*p)[10] =&arr;
你再仔細看看剛剛的例子,我是定義一個int型別的陣列所以用int (*p)[10] =&arr這個陣列指標來存放,而現在我定義了一個 int*的陣列,也應該用相同型別int* (*p)[10] =&arr的陣列指標來存放,
3.2陣列指標的使用
陣列指標的錯誤使用方法
void print3(int (*parr)[10], int sz)//這是一個錯誤的示范
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", parr[i]);//parr[i] == *(parr+i)
}
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(arr[0]);
print(&arr, sz);
return 0;
}
如果這樣去使用陣列指標一定是錯誤的,為什么呢?傳參時你傳的是整個元素的地址,所以當你回圈變數一直增加時跳過的不是一個元素而是一個陣列,就會導致陣列越界,
正確示范
void print(int (*parr)[10], int sz)
{
//*(parr + 0);//parr[0]
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", parr[0][i]);//寫法1
//把這個陣列想象成只有一行的二維陣列進行列印
printf("%d ", (*(parr + 0))[i]);//寫法2
printf("%d ", (*parr)[i]);//寫法3
//(*parr) 相當于 parr指向的陣列的陣列名
}
}
陣列指標的使用場景:
//第一種寫法
void print1(int arr[3][5], int r, int c)
{
int i = 0;
for (i = 0; i < r; i++)
{
int j = 0;
for (j = 0; j < c; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
//第二種寫法
void print2( int(*p)[5], int r, int c)
{
int i = 0;
for (i = 0; i < r; i++)
{
int j = 0;
for (j = 0; j < c; j++)
{
printf("%d ", *(*(p + i) + j));//等價于p[i][j]
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { 1,2,3,4,5, 2,3,4,5,6,3,4,5,6,7 };
//二維陣列傳參
print1(arr, 3, 5);
print2(arr, 3, 5);//arr 是陣列名,陣列名是首元素地址
return 0;
}
學完這些讓我們來鞏固一下
int arr[5];
int *parr1[10];
int (*parr2)[10];
int (*parr3[10])[5];
寫出以下代碼的意思
第一個是一個整型陣列
第二個是一個指標陣列
第三個是一個陣列指標
前三個相信大家都沒有問題,那最后一個是個什么東西?

我們慢慢來分析,首先,parr3是一個陣列,它有10個元素,去掉陣列名剩下是型別,即(*)[5],說明每個元素是個陣列指標,該指標指向的陣列有五個元素,每個元素是int,
圖解
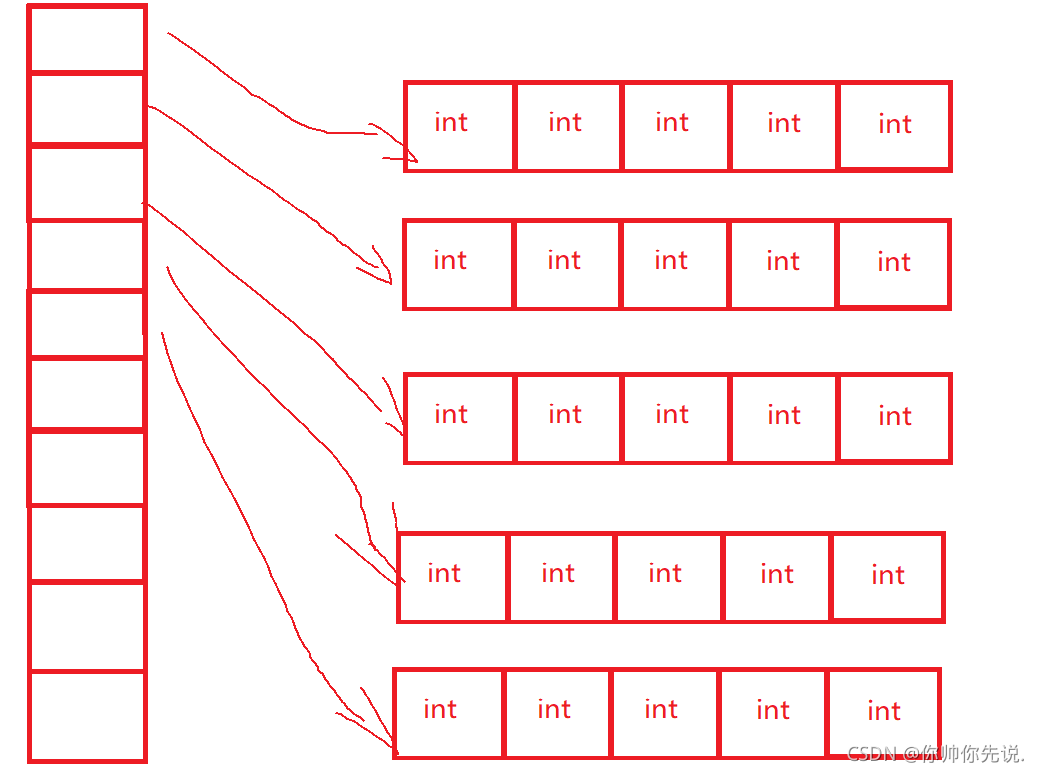
💡:陣列指標步長跳過的是一個陣列不是元素
4.陣列引數、指標引數
4.1一維陣列傳參
#include <stdio.h>
//test()函式傳參的三種寫法
void test(int arr[])//寫法一
{}
void test(int arr[10])//寫法二
{}
//寫法一和寫法二本質上是沒有區別的,[]里數字不管是多少都是一樣的,實際上是不會開辟空間的,
void test(int* arr)//寫法三
{}
//test2()函式傳參的寫法
void test2(int* arr[20])//此種為錯誤寫法,原因見下
{}
void test2(int** arr)//因為傳的arr2是一個int/*的型別的陣列,所以要用int**來接收,
{}
int main()
{
int arr[10] = {0};
int *arr2[20] = {0};
test(arr);
test2(arr2);
}
4.2二維陣列傳參
//test()函式傳參的寫法
void test(int arr[3][5])//寫法一
{}
void test(int arr[][])//錯誤寫法
{}
二維陣列傳參,函式形參的設計只能省略行數,不能省略列數,因為對一個二維陣列,可以不知道有多少行,但是必須知道一行多少元素,
void test(int arr[][5])//寫法二
{}
void test(int *arr)//錯誤寫法
{}
void test(int* arr[5])//錯誤寫法
{}
void test(int (*arr)[5])//寫法三
{}
void test(int **arr)//錯誤寫法
{}
int main()
{
int arr[3][5] = {0};
test(arr);//二維陣列的首元素指的是第一行元素,把二維陣列看成一維陣列,
}
4.3一級指標傳參
#include <stdio.h>
void print(int *p, int sz)
{
int i = 0;
for(i=0; i<sz; i++)
{
printf("%d\n", *(p+i));
}
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9};
int *p = arr;
int sz = sizeof(arr)/sizeof(arr[0]);
//一級指標p,傳給函式
print(p, sz);
return 0;
}
思考一下,當一個函式的引數部分為一級指標的時候,函式能接收什么引數?
int a = 10;
int* q = &a;
int arr[10] = {0};
test(&a);
test(arr);
test(q);
4.4二級指標傳參
#include <stdio.h>
void test(int** ptr)
{
printf("num = %d\n", **ptr);
}
int main()
{
二級指標能接收什么樣的引數?
int n = 10;
int*p = &n;
int **pp = &p;
int* arr[10];
test(&p);//一級指標的地址
test(pp);//二級指標變數,存的是一級指標的地址
test(arr);//int*陣列的地址
return 0;
}
5.函式指標
函式指標變數是用來存放函式的地址,
與陣列名進行比較,陣列名和&陣列名雖然地址一樣,但代表的意義不一樣,而函式名和&函式名地址一樣,意義也是一樣的,是等價的,
函式指標變數存函式地址
test Add(int a,int b)
{
return a+b;
}
int main()
{
int (*pf)(int,int) = &Add
//可以和陣列進行類比
int (*parr)[10] = &arr;
}
pf是個變數,存放地址需要指標變數,所以(*pf),(*pf)指向函式,函式的兩個引數型別是int,
parr是個變數,存放地址需要指標變數,所以(*parr),(*parr)指向的是陣列,陣列有10個元素,
那函式指標的型別是什么呢?
前面說過了,去掉名字即型別,所以int (*)(int,int)就是函式指標的型別,
如何通過指標呼叫函式?
//直接呼叫
int ret = Add(2,3);
//通過指標呼叫
int ret = (*pf)(2,3);
int ret = pf(2,3);
實際上pf前面的*是沒有意義的(就是個擺設,為了讓初學者更好理解),可寫可不寫,
閱讀兩段有趣的代碼
//代碼1
(*(void (*)())0)();
//代碼2
void (*signal(int , void(*)(int)))(int);
看完代碼1,想必你是這樣的

別急,接下來慢慢給你解釋,
剛剛我們說了函式指標變數的型別是int (*)(int,int)我們再看這段代碼,可以發現有相同的結構void (*)(),函式沒有傳參,而給這段代碼加上括號也就是給型別加括號加上強制型別轉換,所以這段代碼的意思就是把0強制型別轉換成void (*)()型別,然后進行解參考呼叫這個函式,被呼叫的函式是無參的,回傳型別是void,
*(void (*)())0可以看成*p,那這段代碼就可以簡化成(*p)(),這不就是剛剛所講的函式指標變數嗎,這下你就能理解了,
緊接著,我們來看看第二段代碼,
void (*signal(int , void(*)(int)))(int);
signal是一個函式,它有兩個引數,一個是int,一個是void(*)(int)函式指標型別,回傳型別依然是void(*)(int),
如果你已經能想出這些,說明第一段代碼你已經理解了,但這段代碼還有個地方要注意,這段代碼實際上是一次函式宣告,宣告的函式名為signal,補上這個解釋就完美了,這段宣告如果這樣寫你可能更好理解,void(*)(int) signal(int,void(*)(int));,雖然這樣說,但別這樣寫,C語言語法不支持,
那這段代碼可以怎么簡化方便理解呢?
我們之前講過typedef可以重定義,例如
typedef int int32;
//int32 就是int的別名
//類似的
typedef void(* pfun_t)(int);
這段代碼就等價于typedef void(*)(int) pfun_t
pfun_t就是別名,只是這種寫法C語言不支持,但你可以這樣理解
//代碼就可以簡化成
pfun_t signal(int,pfun_t);
6.函式指標陣列
陣列是一個存放相同型別資料的存盤空間,那我們已經學習了指標陣列
int *arr[10];
//陣列的每個元素是int*
那要把函式的地址存到一個陣列中,那這個陣列就叫函式指標陣列,那函式指標的陣列如何定義呢?
//假設有add sub mul div 四個函式
int (*pfarr[4])(int,int) = {add,sub,mul,div};
這個時候就有人有疑惑了,函式指標陣列到底有什么用?
舉個🌰
學函式指標前你寫的計算器代碼:
#include<stdio.h>
void menu()
{
printf("**********************************\n");
printf("******* 1.add 2. sub ******\n");
printf("******* 3.mul 4. div ******\n");
printf("******* 0.exit ******\n");
printf("**********************************\n");
}
int Add(int x, int y)//int (*)(int, int)
{
return x + y;
}
int Sub(int x, int y)//int (*)(int, int)
{
return x - y;
}
int Mul(int x, int y)//int (*)(int, int)
{
return x * y;
}
int Div(int x, int y)//int (*)(int, int)
{
return x / y;
}
int main()
{
int input = 0;
do
{
menu();
printf("請選擇:>");
scnaf("%d",&input);
switch (input)
{
case 1:
printf("請輸入2個運算元:>");
scanf("%d %d", &x,&y);
ret = Add(x,y);
printf("ret =%d ",x,y);
break;
case 2:
printf("請輸入2個運算元:>");
scanf("%d %d", &x,&y);
ret = Sub(x,y);
printf("ret =%d ",x,y);
break;
case 3:
printf("請輸入2個運算元:>");
scanf("%d %d", &x,&y);
ret = Mul(x,y);
printf("ret =%d ",x,y);
break;
case 4:
printf("請輸入2個運算元:>");
scanf("%d %d", &x,&y);
ret = Div(x,y);
printf("ret =%d ",x,y);
break;
case 0:
printf("退出計算器\n");
break;
default:
printf("選擇錯誤\n");
break;
}
} while (input);
return 0;
}
學習后你寫的計算器代碼:
#include<stdio.h>
void menu()
{
printf("**********************************\n");
printf("******* 1.add 2. sub ******\n");
printf("******* 3.mul 4. div ******\n");
printf("******* 0.exit ******\n");
printf("**********************************\n");
}
int Add(int x, int y)//int (*)(int, int)
{
return x + y;
}
int Sub(int x, int y)//int (*)(int, int)
{
return x - y;
}
int Mul(int x, int y)//int (*)(int, int)
{
return x * y;
}
int Div(int x, int y)//int (*)(int, int)
{
return x / y;
}
int main()
{
int input = 0;
do
{
int x = 0;
int y = 0;
int ret = 0;
menu();
printf("請選擇:>");//1
scanf("%d", &input);
int (*pfArr[5])(int, int) = {0, Add, Sub, Mul, Div};
//0 1 2 3 4
if (input == 0)
{
printf("退出計算器\n");
}
else if(input>=1 && input<=4)
{
printf("請輸入2個運算元:>");
scanf("%d %d", &x, &y);
ret = pfArr[input](x, y);
printf("%d\n", ret);
}
else
{
printf("選擇錯誤\n");
}
} while (input);
return 0;
}
此時你會發現代碼量有較明顯的減少,
這里邊通過函式指標呼叫其它函式有一種專業術語叫轉移表
7.回呼函式
回呼函式就是一個通過函式指標呼叫的函式,
如果你把函式的指標(地址)作為引數傳遞給另一個函式,當這個指標被用來呼叫其所指向的函式時,我們就說這是回呼函式,回呼函式不是由該函式的實作方直接呼叫,而是在特定的事件或條件發生時由另外的一方呼叫的,用于對該事件或 條件進行回應,
我們還是以計算器的代碼為例:
void menu()
{
printf("**********************************\n");
printf("******* 1.add 2. sub ******\n");
printf("******* 3.mul 4. div ******\n");
printf("******* 0.exit ******\n");
printf("**********************************\n");
}
int Add(int x, int y)//int (*)(int, int)
{
return x + y;
}
int Sub(int x, int y)//int (*)(int, int)
{
return x - y;
}
int Mul(int x, int y)//int (*)(int, int)
{
return x * y;
}
int Div(int x, int y)//int (*)(int, int)
{
return x / y;
}
void Calc(int(*pf)(int, int))
{
int x = 0;
int y = 0;
int ret = 0;
printf("請輸入2個運算元:>");
scanf("%d %d", &x, &y);
ret = pf(x, y);
printf("ret = %d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("請選擇:>");
scanf("%d", &input);
switch (input)
{
case 1:
Calc(Add);
break;
case 2:
Calc(Sub);
break;
case 3:
Calc(Mul);
break;
case 4:
Calc(Div);
break;
case 0:
printf("退出計算器\n");
break;
default:
printf("選擇錯誤\n");
break;
}
} while (input);
return 0;
}
回呼函式是在函式指標的基礎上實作的,沒有函式指標就沒有回呼函式,
7.1qsort函式
可以用來排序各種型別的陣列
引數型別
void qsort( void *base, size_t num, size_t width, int (__cdecl *compare )(const void *elem1, const void *elem2 ) );
第一個引數是void* base,接收的是陣列的地址,void*有一個好處,可以接收任意型別的陣列,這就使得函式更加靈活了,
💡:void*是無具體型別的指標,能夠接收任意型別的地址,但不能對void*型別進行±運算,也不能解參考,
第二個引數是元素的個數
第三個引數是元素的大小
第四個引數是函式,這個函式的作用時排序時用來比較兩個元素,
第四個引數的函式是有要求的,它的回傳值要滿足以下條件

我們以排列int、struct型別為例
int cmp(const void* e1,const void*e2)
{
return *(int*)e1-*(int*)e2;
}
int cmp(const void* e1,const void*e2)
{
//假設已經定義結構體struct Stu
return strcmp(((struct Stu*)e1)->name,((struct Stu*)e2)->name;//這里是以名字為例
}
學完qsort函式,我們來模擬實作qsort函式的功能,
void BubbleSort(void* base, long long num, long long width, int (*cmp)(const void*, const void*))
{
long long int i = 0;
//趟數
for (i = 0; i < num - 1; i++)
{
//比較的對數
long long int j = 0;
for (j = 0; j < num - 1 - i; j++)
{
//base[j] ==> *(base+j)
if (cmp((char*)base+j*width, (char*)base+(j+1)*width)>0)
{
//交換
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
8.指向函式指標陣列的指標
看完這個標題,相信你一定是這樣的,,,

int (*pf)(int,int) = Add;//pf是函式指標
int (* pfArr[5](int,int));//pfArr是一個函式指標的陣列
int (* (*ppfArr)[5])(int,int) = &pfArr;
ppfArr就是一個指向函式指標陣列的指標
如果你能看到這里,說明你已經比別人厲害了,未來可期,
但相信此時的你也已經

離開前,別忘了

這樣的文章 你還不趕快 點贊👍關注💡收藏💖
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/298417.html
標籤:其他
上一篇:【演算法訓練營】(day3)