Redis 基礎知識介紹
NoSql
- 海量用戶+高并發,會造成服務器癱瘓,主要原因就是使用的是關系型資料庫
原因
- 1.性能瓶頸:磁盤IO性能低下
- 關系型資料庫存取資料的時候是要通過磁盤IO的,磁盤的性能本身是比較低的
- 2.擴展瓶頸:資料關系復雜,擴展性差,不便于大規模集群
- 關系型資料庫表與表的關系非常復雜,十分影響查詢效率,這個情況下,進行擴展也是十分困難的
解決思路
- 1.降低磁盤IO次數,越低越好
- 使用記憶體存盤,大大提高效率
- 2.去除資料間的關系,越簡單越好
- 去除關系,只存資料
這就是NoSql
NoSql概念
-
NoSQL:即 Not-Only SQL( 泛指非關系型的資料庫),作為關系型資料庫的補充, 作用:應對基于海量用戶和海量資料前提下的資料處理問題,
-
特征
- 可擴容,可伸縮,大資料量下高性能,直接對記憶體進行操作
- 靈活的資料模型、高可用,自己設計了資料存盤格式,保證效率比較高,
-
常見NoSql資料庫
- Redis、memcache、HBase、MongoDB
Redis
概念
- 概念:Redis (REmote DIctionary Server) 是用 C 語言開發的一個開源的高性能鍵值對(key-value)資料庫,
特征
-
1.資料間沒有必然的關聯關系
-
2.內部采用單執行緒機制進行作業
-
3.高性能,官方提供測驗資料,50個并發執行100000 個請求,讀的速度是110000 次/s,寫的速度是81000次/s,
-
4.多資料型別支持
-
字串型別,string list
-
串列型別,hash set
-
散列型別,zset/sorted_set
-
集合型別
-
有序集合型別
-
-
5.支持持久化,可以進行資料災難恢復
應用場景
- 1.為熱點資料加速查詢(主要場景),如熱點商品,熱點新聞,熱點資訊,推廣類等高訪問量資訊等
- 2.即時資訊查詢,如各類排行榜、各類網站訪問統計、公交到站資訊、在線人數資訊(聊天室、網站)、設備信號等
- 3.時效性資訊控制,如驗證碼控制,投票控制等,
- 4.分布式資料共享,如分布式集群架構中的session分離
- 5.訊息佇列--已經榷訓
Redis的使用
#啟動服務器,默認啟動埠為6379
redis-server
#啟動服務器,指定6380埠啟動
redis-server --port 6380
#啟動客戶端,默認連接6379埠 redis-cli [-h host] [-p port]
redis-cli
#啟動客戶端,指定6380埠連接
redis-cli -p 6380
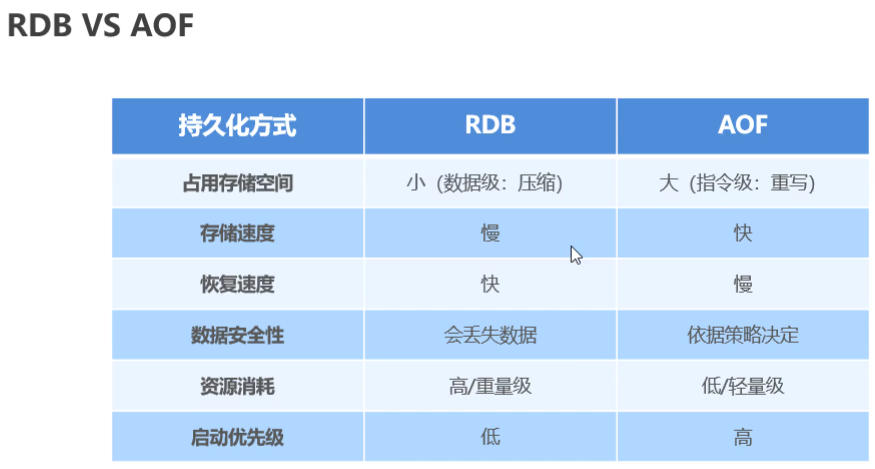
持久化
什么是持久化
- 利用永久性存盤介質將資料進行保存,在特定的時間將保存的資料進行恢復的作業機制成為持久化
- 持久化用于防止資料的意外丟失,確保資料安全性
持久化程序保存什么
- 將當前資料狀態進行保存,快照形式,存盤資料結果,存盤格式簡單,關注點在資料---RDB
- 將資料的操作程序進行保存,日志形式,存盤操作程序,存盤格式復雜,關注點在資料的操作程序---AOF
RDB
-
sava指令
- reids是單執行緒的,多臺客戶端同時操作redis會創建一個任務佇列,save指令的執行會阻塞當前的redis服務器,直到當前RDB程序完成為止,有可能長時間阻塞,線上環境不建議使用
-
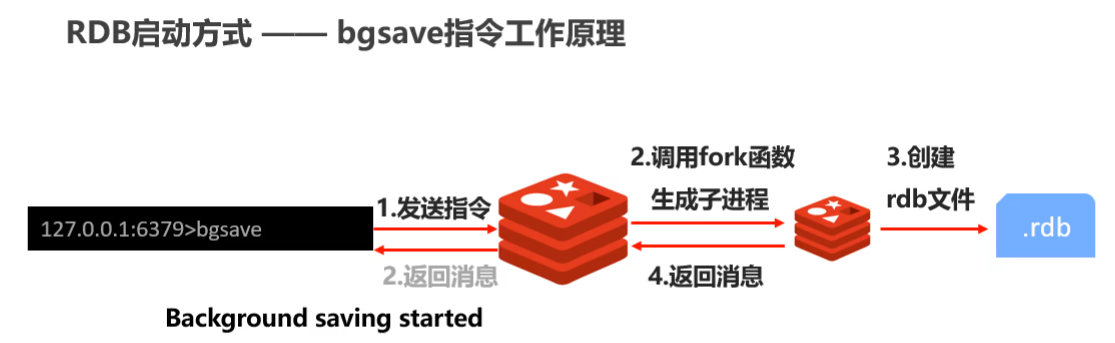
bgsave指令
- 1.指令bgsave指令,會先向redis發送指令
- 2.redis會回傳一個后臺保存開始執行 的訊息
- 3.redis會去呼叫fork函式生成一個子行程
- 4.然后去創建rdb檔案
- 5.最終redis回傳執行結果
- 注意:bgsave命令是針對save阻塞問題做的優化,redis內部所有涉及到RDB的操作都使用bgsave指令進行操作,save命令可以放棄使用
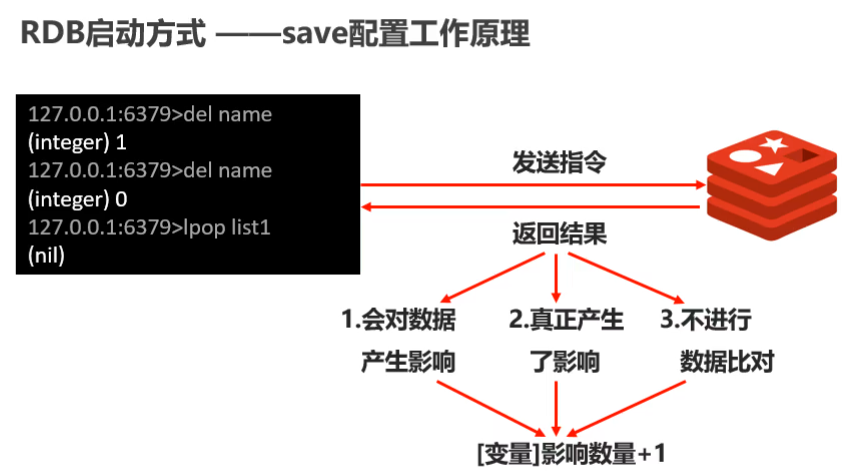
- save配置
- 設定自動持久化的條件,滿足限定時間范圍內key的變化數量達到指定數量即進行持久化
#second:監控時間范圍 changes:監控key的變化量
save second changes
save 10 2
- 從redis啟動開始,如果十秒內key變化2次,在第十秒的時候直接保存操作,后臺也還是bgsave進行保存
- 如果在十秒內變化了一次,那么redis會在變化第二次的時候進行后臺保存操作,第二個周期會在第一次保存的時候開始計時
- 注意:save配置要根據實際業務情況進行設定,頻度過高或者過低都會出現性能問題,結果可能是災難性的,save配置啟動后執行的是bgsave操作
-
RDB特殊啟動形式
- 服務器運行程序中重啟
debug reload- 關閉服務器時指定保存資料
shutdown save -
RDB優點
- RDB是一個緊湊壓縮的二進制檔案,存盤效率較高
- RDB內部存盤的是redis在某個時間點的資料快照,非常適合用于資料備份,全量復制等場景
- RDB恢復資料的速度要比AOF快很多
- 應用:服務器中每X小時會執行bgsave備份,并將RDB檔案拷貝到遠程機器中,用于災難恢復
-
RDB缺點
- RDB方式無論是執行指令還是利用配置,無法做到實時持久化,具有較大的可能性丟失資料
- bgsave指令每次運行要執行fork操作創建子行程,要犧牲一些性能
- redis的眾多版本中未進行RDB檔案格式的版本統一,有可能出現版本服務器之間資料格式無法兼容的現象--解決方案就是 匯出來存到word或者Excel中,再匯入回去即可,
-
RDB存盤的弊端
- 存盤資料量較大,效率較低,基于快照思想,每次讀寫都是全部資料,當資料量巨大時,效率非常低
- 大資料量下的IO性能較低
- 基于fork創建子行程,記憶體產生額外消耗
- 宕機帶來的資料丟失風險
- 解決思路:
- 不寫全資料,僅僅記錄部分資料
- 降低區分資料是否改變的難度,改記錄資料為記錄操作程序
- 對所有操作均進行記錄,排除丟失資料的風險
AOF
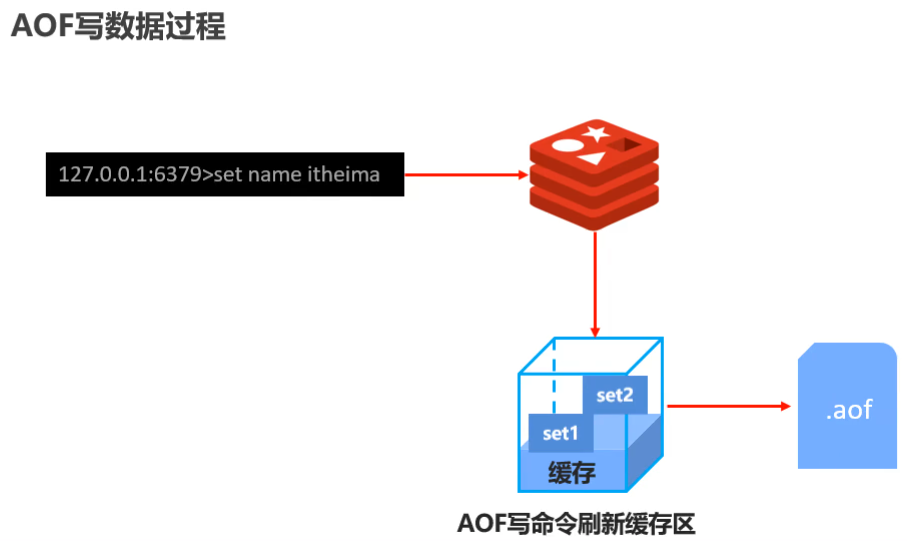
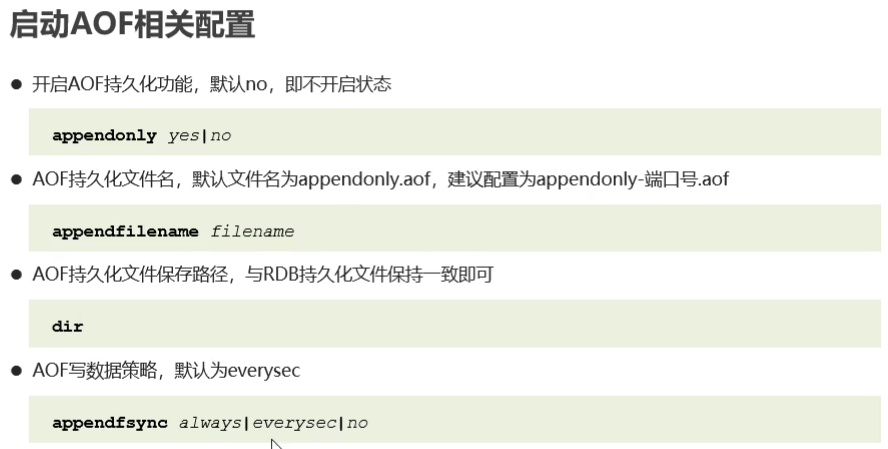
- AOF持久化:以獨立日志的方式記錄每次寫命令,重啟時再重新執行AOF檔案中命令達到恢復資料的目的,與RDB相比可以簡單理解為由記錄資料改為記錄資料變化
- AOF的主要作用就是解決了資料持久化的實時性,目前已經是redis持久化的主流方式

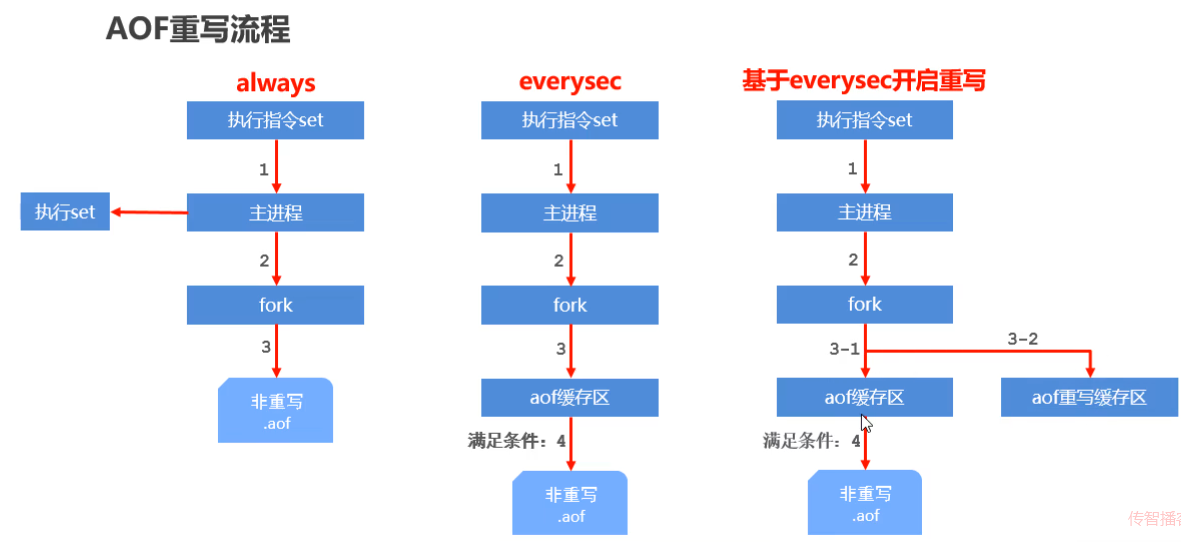
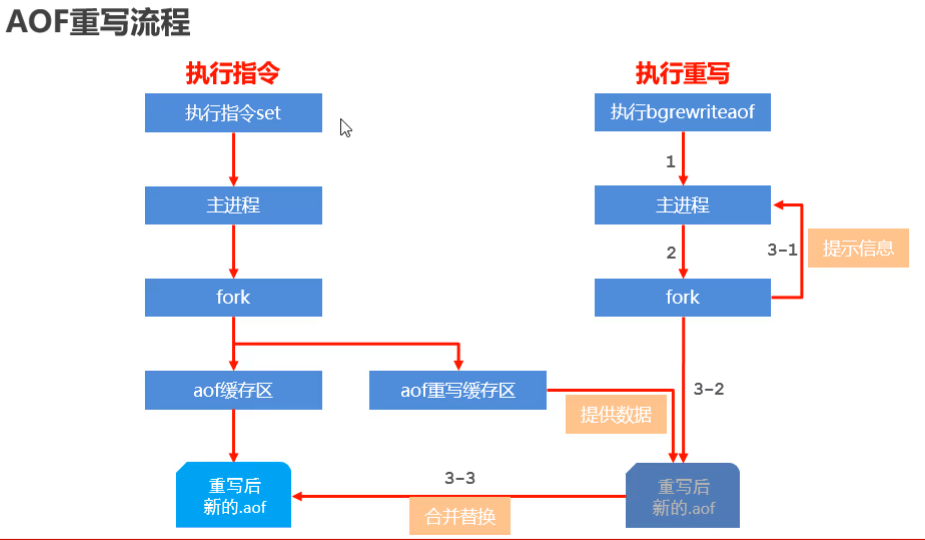
AOF重寫

- 重寫指令
- 存入元素后進行重寫
bgrewriteaof
- 自動重寫

RDB與AOF區別

資料洗掉策略
定時洗掉
- 創建一個定時器,當key設定有過期時間,且過期時間到達時,由定時器任務立即執行對鍵的洗掉操作
- 優點:節約記憶體,到時就洗掉,快速釋放掉不必要的記憶體占用
- 缺點:CPU壓力很大,無論CPU此時負載量多高,均占用CPU,會影響redis服務器回應時間和指令吞吐量
- 總結:用處理器性能換取存盤空間(拿時間換空間)
惰性洗掉
資料到達過期時間,不做處理,等下次訪問該資料時,我們需要判斷
- 如果未過期,回傳資料
- 發現已過期,洗掉,回傳不存在
- 優點:節約CPU性能,發現必須洗掉的時候才洗掉
- 缺點:記憶體壓力很大,出現長期占用記憶體的資料
- 總結:用存盤空間換取處理器性能(拿空間換時間)
定期洗掉
定時洗掉和惰性洗掉這兩種方案都是走的極端,那有沒有折中方案?
我們來講redis的定期洗掉方案:
- Redis啟動服務器初始化時,讀取配置server.hz的值,默認為10
- 每秒鐘執行server.hz次serverCron()-------->databasesCron()--------->activeExpireCycle()
- activeExpireCycle()對每個expires[*]逐一進行檢測,每次執行耗時:250ms/server.hz
- 對某個expires[*]檢測時,隨機挑選W個key檢測
如果key超時,洗掉key
如果一輪中洗掉的key的數量>W*25%,回圈該程序
如果一輪中洗掉的key的數量≤W*25%,檢查下一個expires[*],0-15回圈
W取值=ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP屬性值
- 引數current_db用于記錄activeExpireCycle() 進入哪個expires[*] 執行
- 如果activeExpireCycle()執行時間到期,下次從current_db繼續向下執行
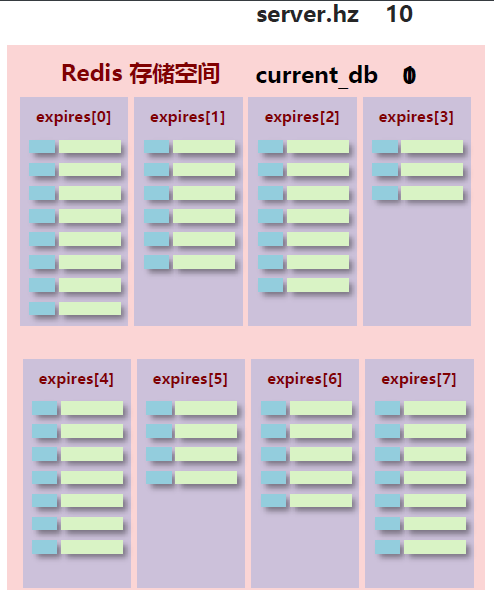
總的來說:定期洗掉就是周期性輪詢redis庫中的時效性資料,采用隨機抽取的策略,利用過期資料占比的方式控制洗掉頻度
- 特點1:CPU性能占用設定有峰值,檢測頻度可自定義設定
- 特點2:記憶體壓力不是很大,長期占用記憶體的冷資料會被持續清理
- 總結:周期性抽查存盤空間(隨機抽查,重點抽查)

資料淘汰策略(逐出演算法)
概述
什么叫資料淘汰策略?什么樣的應用場景需要用到資料淘汰策略?
當新資料進入redis時,如果記憶體不足怎么辦?在執行每一個命令前,會呼叫freeMemoryIfNeeded()檢測記憶體是否充足,如果記憶體不滿足新 加入資料的最低存盤要求,redis要臨時洗掉一些資料為當前指令清理存盤空間,清理資料的策略稱為逐出演算法,
注意:逐出資料的程序不是100%能夠清理出足夠的可使用的記憶體空間,如果不成功則反復執行,當對所有資料嘗試完畢, 如不能達到記憶體清理的要求,將出現錯誤資訊如下
(error) OOM command not allowed when used memory >'maxmemory'
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/298810.html
標籤:架構設計