上一篇介紹了“8.4 智能索引推薦”的相關內容,本篇我們介紹“8.5 指標采集、預測與例外檢測”的相關精彩內容介紹,
8.5 指標采集、預測與例外檢測
資料庫指標監控與例外檢測技術,通過監控資料庫指標,并基于時序預測和例外檢測等演算法,發現例外資訊,進而提醒用戶采取措施避免例外情況造成嚴重后果,
8.5.1 使用場景
用戶操作資料庫的某些行為或某些正在運行的業務發生了變化,都可能會導致資料庫產生例外,如果不及時發現并處理這些例外,可能會導致嚴重的后果,通常,資料庫監控指標(metric,如CPU使用率、QPS等)能夠反映出資料庫系統的健康狀況,通過對資料庫指標進行監控,分析指標資料特征或變化趨勢等資訊,可及時發現資料庫例外狀況,并及時將告警資訊推送給運維管理人員,從而避免造成損失,
8.5.2 實作原理
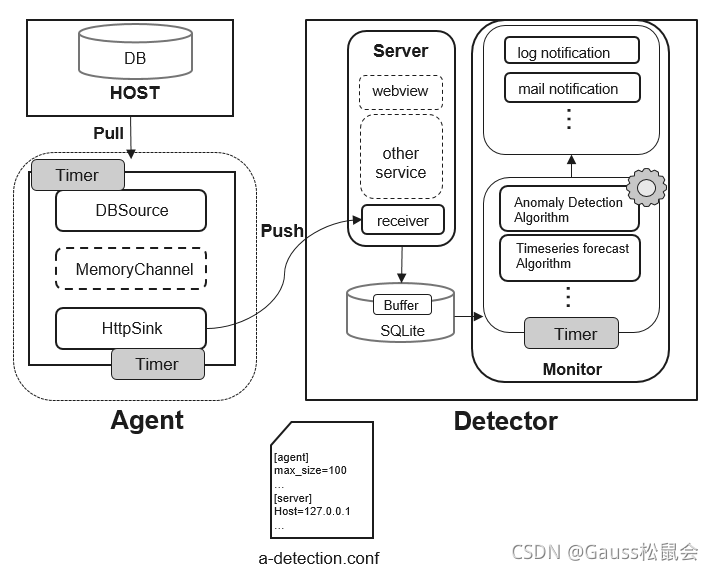
指標采集、預測與例外檢測是通過同一套系統實作的,在openGauss專案中名為Anomaly-Detection,它的結構如圖8-14所示,該工具主要可以分為Agent和Detector兩部分,其中Agent是資料庫代理模塊,負責收集資料庫指標資料并將資料推送到Detector;Detector是資料庫例外檢測與分析模塊,該模塊主要有三個作用,
(1) 收集Agent端采集的資料并進行轉儲,
(2) 對收集到的資料進行特征分析與例外檢測,
(3) 將檢測出來的例外資訊推送給運維管理人員,
1. Agent模塊的組成
Agent模塊負責采集并發送指標資料,該模塊由DBSource、MemoryChannel、HttpSink三個子模塊組成,
(1) DBSource作為資料源,負責定期去收集資料庫指標資料并將資料發送到資料通道MemoryChannel中,
(2) MemoryChannel是記憶體資料通道,本質是一個FIFO佇列,用于資料快取,HttpSink組件消費MemoryChannel中的資料,為了防止MemoryChannel中的資料過多導致OOM(out of Memory,記憶體溢位),設定了容量上限,當超過容量上限時,過多的元素會被禁止放入佇列中,
(3) HttpSink是資料匯聚點,該模塊定期從MemoryChannel中獲取資料,并以Http(s)的方式將資料進行轉發,資料讀取之后從MemoryChannel中清除,
2. Detector 模塊組成
Detector模塊負責資料檢測,該模塊由Server、Monitor兩個子模塊組成,
(1) Server是一個Web服務,為Agent采集到的資料提供接收介面,并將資料存盤到本地資料庫內部,為了避免資料增多導致資料庫占用太多的資源,我們將資料庫中的每個表都設定了行數上限,
(2) Monitor模塊包含時序預測和例外檢測等演算法,該模塊定期從本地資料庫中獲取資料庫指標資料,并基于現有演算法對資料進行預測與分析,如果演算法檢測出資料庫指標在歷史或未來某時間段或時刻出現例外,則會及時的將資訊推送給用戶,
8.5.3 關鍵原始碼決議
1 總體流程決議
智能索引推薦工具的路徑是openGauss-server/src/gausskernel/dbmind/tools/anomaly_detection,下面的代碼詳細展示了程式的入口,
def forecast(args):
…
# 如果沒有指定預測方式,則默認使用’auto_arima’演算法
if not args.forecast_method:
forecast_alg = get_instance('auto_arima')
else:
forecast_alg = get_instance(args.forecast_method)
# 指標預測功能函式
def forecast_metric(name, train_ts, save_path=None):
…
forecast_alg.fit(timeseries=train_ts)
dates, values = forecast_alg.forecast(
period=TimeString(args.forecast_periods).standard)
date_range = "{start_date}~{end_date}".format(start_date=dates[0],
end_date=dates[-1])
display_table.add_row(
[name, date_range, min(values), max(values), sum(values) / len(values)]
)
# 校驗存盤路徑
if save_path:
if not os.path.exists(os.path.dirname(save_path)):
os.makedirs(os.path.dirname(save_path))
with open(save_path, mode='w') as f:
for date, value in zip(dates, values):
f.write(date + ',' + str(value) + '\n')
# 從本地sqlite中抽取需要的資料
with sqlite_storage.SQLiteStorage(database_path) as db:
if args.metric_name:
timeseries = db.get_timeseries(table=args.metric_name, period=max_rows)
forecast_metric(args.metric_name, timeseries, args.save_path)
else:
# 獲取sqlite中所有的表名
tables = db.get_all_tables()
# 從每個表中抽取訓練資料進行預測
for table in tables:
timeseries = db.get_timeseries(table=table, period=max_rows)
forecast_metric(table, timeseries)
# 輸出結果
print(display_table.get_string())
# 代碼遠程部署
def deploy(args):
print('Please input the password of {user}@{host}: '.format(user=args.user, host=args.host))
# 格式化代碼遠程部署指令
command = 'sh start.sh --deploy {host} {user} {project_path}' \
.format(user=args.user,
host=args.host,
project_path=args.project_path)
# 判斷指令執行情況
if subprocess.call(shlex.split(command), cwd=SBIN_PATH) == 0:
print("\nExecute successfully.")
else:
print("\nExecute unsuccessfully.")
…
# 展示當前監控的引數
def show_metrics():
…
# 專案總入口
def main():
…
2. 關鍵代碼段決議
(1) 后臺執行緒的實作,
前面已經介紹過了,本功能可以分為三個角色:Agent、Monitor以及Detector,這三個不同的角色都是常駐后臺的行程,各自執行著不同的任務,Daemon類就是負責運行不同業務流程的容器類,下面介紹該類的實作,
class Daemon:
"""
This class implements the function of running a process in the background."""
def __init__(self):
…
def daemon_process(self):
# 注冊退出函式
atexit.register(lambda: os.remove(self.pid_file))
signal.signal(signal.SIGTERM, handle_sigterm)
# 啟動行程
@staticmethod
def start(self):
try:
self.daemon_process()
except RuntimeError as msg:
abnormal_exit(msg)
self.function(*self.args, **self.kwargs)
# 停止行程
def stop(self):
if not os.path.exists(self.pid_file):
abnormal_exit("Process not running.")
read_pid = read_pid_file(self.pid_file)
if read_pid > 0:
os.kill(read_pid, signal.SIGTERM)
if read_pid_file(self.pid_file) < 0:
os.remove(self.pid_file)
(2) 資料庫相關指標采集程序,
資料庫的指標采集架構,參考了Apache Flume的設計,將一個完整的資訊采集流程拆分為三個部分,分別是Source、Channel以及Sink,上述三個部分被抽象為三個不同的基類,由此可以派生出不同的采集資料源、快取管道以及資料的接收端,
前文提到過的DBSource即派生自Source、MemoryChannel派生自Channel,HttpSink則派生自Sink,下面這段代碼來自metric_agent.py,負責采集指標,在這里將上述模塊串聯起來了,
def agent_main():
…
# 初始化通道管理器
cm = ChannelManager()
# 初始化資料源
source = DBSource()
http_sink = HttpSink(interval=params['sink_timer_interval'], url=url, context=context)
source.channel_manager = cm
http_sink.channel_manager = cm
# 獲取引數檔案里面的功能函式
for task_name, task_func in get_funcs(metric_task):
source.add_task(name=task_name,
interval=params['source_timer_interval'],
task=task_func,
maxsize=params['channel_capacity'])
source.start()
http_sink.start()
(3) 資料存盤與監控部分的實作,
Agent將采集到的指標資料發送到Detector服務器上,并由Detector服務器負責存盤,Monitor不斷對存盤的資料進行檢查,以便提前發現例外,
這里實作了一種通過SQLite進行本地化存盤的方式,代碼位于sqlite_storage.py檔案中,實作的類為SQLiteStorage,該類實作的主要方法如下:
# 通過時間戳獲取最近一段時間的資料
def select_timeseries_by_timestamp(self, table, period):
…
# 通過編號獲取最近一段時間的資料
def select_timeseries_by_number(self, table, number):
…
其中,由于不同指標資料是分表存盤的,因此上述引數table也代表了不同指標的名稱,
例外檢測當前主要支持基于時序預測的方法,包括Prophet演算法(由Facebook開源的工業級時序預測演算法工具)和ARIMA演算法,他們分別被封裝成類,供Forecaster呼叫,
上述時序檢測的演算法類都繼承了AlgModel類,該類的結構如下:
class AlgModel(object):
"""
This is the base class for forecasting algorithms.
If we want to use our own forecast algorithm, we should follow some rules.
"""
def __init__(self):
pass
@abstractmethod
def fit(self, timeseries):
pass
@abstractmethod
def forecast(self, period):
pass
def save(self, model_path):
pass
def load(self, model_path):
pass
在Forecast類中,通過呼叫fit()方法,即可根據歷史時序資料進行訓練,通過forecast()方法預測未來走勢,
獲取到未來走勢后如何判斷是否是例外呢?方法比較多,最簡單也是最基礎的方法是通過閾值來進行判斷,在我們的程式中,默認也是采用該方法進行判斷的,
8.5.4 使用示例
Anomaly-Detection工具有start、stop、forecast、show_metrics、deploy五種運行模式,各模式說明如表8-12所示,
模式名稱 | 說明 |
start | 啟動本地或者遠程服務 |
stop | 停止本地或遠程服務 |
forecast | 預測指標未來變化 |
show_metrics | 輸出當前監控的引數 |
deploy | 遠程部署代碼 |
Anomaly-Detection工具運行模式使用示例如下所示,
① 使用start模式啟動本地collector服務,代碼如下:
python main.py start –role collector
② 使用stop模式停止本地collector服務,代碼如下:
python main.py stop –role collector
③ 使用start模式啟動遠程collector服務,代碼如下:
python main.py start --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
④ 使用stop模式停止遠程collector服務,代碼如下:
python main.py stop --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
⑤ 顯示當前所有的監控引數,代碼如下:
python main.py show_metrics
⑥ 預測io_read未來60秒的最大值、最小值和平均值,代碼如下:
python main.py forecast –metric-name io_read –forecast-periods 60S –save-path predict_result
⑦ 將代碼部署到遠程服務器,代碼如下:
python main.py deploy –user xxx –host xxx.xxx.xxx.xxx –project-path xxx
8.5.5 演進路線
Anomaly-Detection作為一款資料庫指標監控和例外檢測工具,目前已經具備了基本的資料收集、資料存盤、例外檢測、訊息推送等基本功能,但是目前存在以下幾個問題,
(1) Agent模塊收集資料太單一,目前Agent只能收集資料庫的資源指標資料,包IO、磁盤、記憶體、CPU等,后續還需要在采集指標豐富度上作增強,
(2) Monitor內置演算法覆寫面不夠,Monitor目前只支持兩種時序預測演算法,同時針對例外檢測額,也僅支持基于閾值的簡單情況,使用的場景有限,
(3) Server僅支持單個Agent傳輸資料,Server目前采用的方案僅支持接收一個Agent傳過來的資料,不支持多Agent同時傳輸,這對于只有一個主節點的openGauss資料庫暫時是夠用的,但是對分布式部署顯然是不友好的,
因此,針對以上三個問題,未來首先會豐富Agent以便于收集資料,主要包括安全指標、資料庫日志等資訊,其次在演算法層面上,撰寫魯棒性(即演算法的健壯性與穩定性)更強的例外檢測演算法,增加例外監控場景,同時,需要對Server進行改進,使其支持多Agent模式,最后,需要實作故障自動修復功能,并與本功能相結合,
感謝大家學習第8章 AI技術中“8.5 指標采集、預測與例外檢測”的精彩內容,下一篇我們開啟“8.6 AI查詢時間預測”的相關內容的介紹,
敬請期待,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/300034.html
標籤:其他