計算機性能的提升源自公式: 程 序 的 C P U 執 行 時 間 = 指 令 數 × C P I × 時 鐘 周 期 時 間 程式的CPU執行時間=指令數×CPI×時鐘周期時間 程序的CPU執行時間=指令數×CPI×時鐘周期時間
1.功耗問題的引出
實體1:貌似要減少指令數,減小CPI比較困難,而減小時鐘周期可行,于是,從 1978 年 Intel 發布的 8086 CPU 開始,計算機的主頻從 5MHz 開始,不斷提升,1980 年代中期的 80386 能夠跑到 40MHz,1989 年的 486 能夠跑到 100MHz,直到 2000 年的奔騰 4 處理器,主頻已經到達了 1.4GHz,而消費者也在這 20 年里養成了“看主頻”買電腦的習慣,當時已經基本壟斷了桌面 CPU 市場的 Intel 更是夸下了海口,表示奔騰 4 所使用的 CPU 結構可以做到 10GHz,頗有一點“大力出奇跡”的意思,
但是,Intel遇到了CPU的極限問題——功耗,奔騰 4 的CPU主頻從來沒有達到過10GHz,最高只有3.8GHz,而且發現奔騰 4 2.4GHz的CPU性能與奔騰 3 1.6Ghz的CPU性能差不多,這讓AMD獲得了喘息的機會,代表著“主頻時代”的終結,
如今,2019 年的最高配置 Intel i9 CPU,主頻也只不過是 5GHz 而已,相較于 1978 年到 2000 年,這 20 年里 300 倍的主頻提升,從 2000 年到現在的這 19 年,CPU 的主頻大概提高了 3 倍,
實體2:一個 3.8GHz 的奔騰 4 處理器,滿載功率是 130 瓦,這個 130 瓦是什么概念呢?機場允許帶上飛機的充電寶的容量上限是 100 瓦時,如果我們把這個 CPU 安在手機里面,不考慮螢屏記憶體之類的耗電,這個 CPU 滿載運行 45 分鐘,充電寶里面就沒電了,而 iPhone X 使用 ARM 架構的 CPU,功率則只有 4.5 瓦左右,
2. 性能與功耗
CPU是超大規模集成電路(Very Large Scale Integration,簡稱VLSI),要提高CPU計算速度,一方面,在 CPU 里,同樣的面積里面,多放一些晶體管,也就是增加密度;另一方面,要讓晶體管“打開”和“關閉”得更快一點,也就是提升主頻,而這兩者,都會增加功耗,帶來耗電和散熱的問題,就像為了加快作業,要在工廠里多塞點人一樣,
散熱方式:風扇、空調、水冷,但是在CPU內增加晶體管密度和“開關”頻率也是有限的,
功
耗
≈
1
/
2
×
負
載
電
容
×
電
壓
的
平
方
×
開
關
頻
率
×
晶
體
管
數
量
功耗\approx1/2 ×負載電容×電壓的平方×開關頻率×晶體管數量
功耗≈1/2×負載電容×電壓的平方×開關頻率×晶體管數量
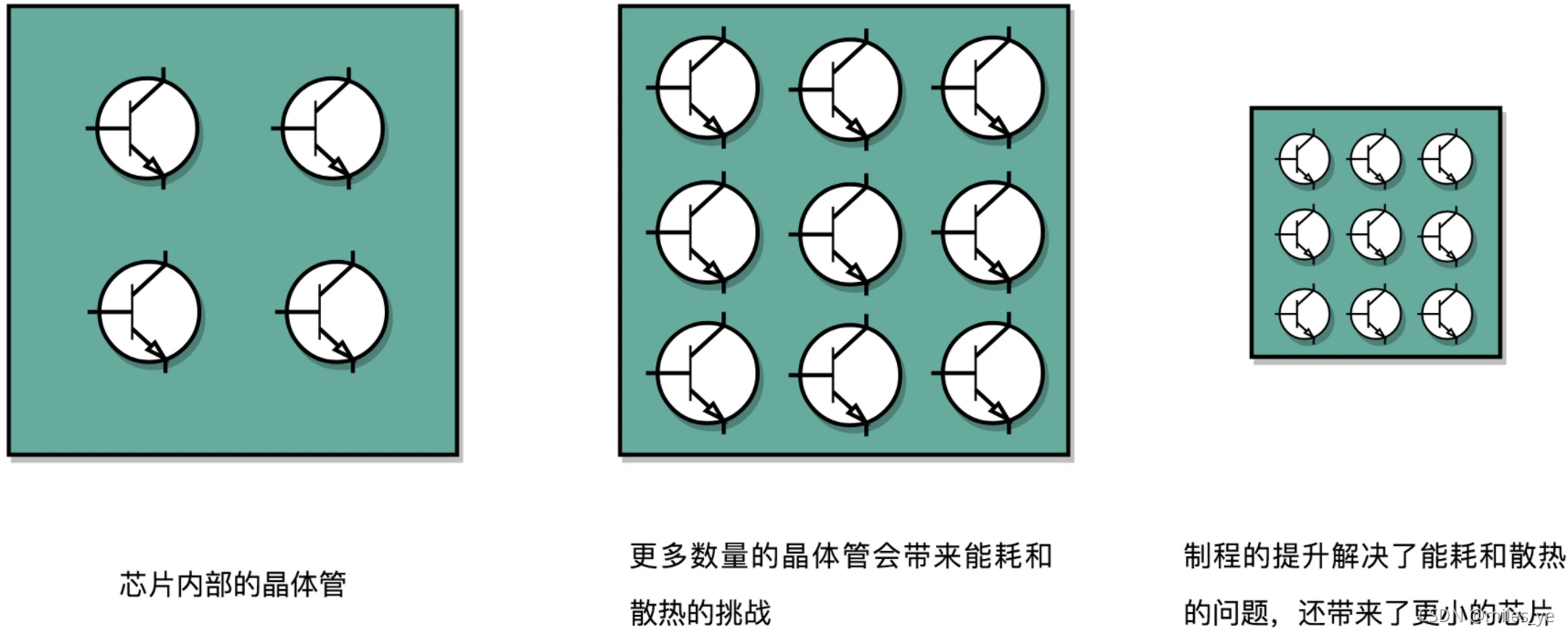
- 增加晶體管數量 --> 多放一點晶體管 --> 將晶體管造的小一點
這就是提升“制程”,目前我國可以達到28nm,而荷蘭ASML可以達到5nm,相當于將晶體管變小到了原來的1/5大小,
- 降低電壓
功耗和電壓的平方是成正比,這意味著電壓下降到原來的 1/5,整個的功耗會變成原來的 1/25,
實體:從 5MHz 主頻的 8086 到 5GHz 主頻的 Intel i9,CPU 的電壓已經從 5V 左右下降到了 1V 左右,這也是為什么我們 CPU 的主頻提升了 1000 倍,但是功耗只增長了 40 倍,微軟Surface Go輕薄筆記本上使用了0.25V 的低電壓 CPU,使得筆記本能有更長的續航時間,
3. 性能與并行優化
在過去的 20 年里,制程的優化和電壓的下降讓CPU性能有所提升,但是從二十世紀90年代至二十一世紀初,軟體工程師所用的“面向摩爾定律編程”的套路越來越行不通了,這種思想就是“寫程式不考慮性能,等明年 CPU 性能提升一倍,到時候性能自然就不成問題了”,
于是,從奔騰 4 開始,Intel 意識到通過提升主頻比較“難”去實作性能提升,就開始推出 Core Duo 這樣的多核 CPU,通過提升“吞吐率”而不是“回應時間”,來達到提升CPU性能的目的**,提升“吞吐率”就是通過并行優化來提升CPU性能**,就好比用多匹馬拉車,而減小“回應時間”就好比用一匹優等馬換一匹劣等馬,
實體3:做機器學習程式的時候,需要計算向量的點積,比如向量 W=[W0?,W1??,W2??,…,W15??] 和向量 X=[X0?,X1??,X2??,…,X15??],W?X=W0???X0??+W1???X1??+ W2???X2??+…+W15???X15??,
這些式子由 16 個乘法和 1 個連加組成,如果一個人用筆來算的話,需要一步一步算 16 次乘法和 15 次加法,如果這個時候把這個任務分配給 4 個人,同時去算 W0??~W3??, W4??~W7??, W8?~W11??, W12?~W15? 這樣四個部分的結果,再由一個人進行匯總,需要的時間就會縮短,

但是,這樣的并行計算需要滿足3個條件:
1)沒有背景關系關聯,或者稱為背景關系解耦,也就說需要進行的計算,本身可以分解成幾個可以并行的任務,好比上面的乘法和加法計算,幾個人可以同時進行,不會影響最后的結果,
2)需要能夠分解好問題,并確保幾個人的結果能夠匯總到一起,
3)在“匯總”這個階段,是沒有辦法并行進行的,還是得順序執行,一步一步計算,
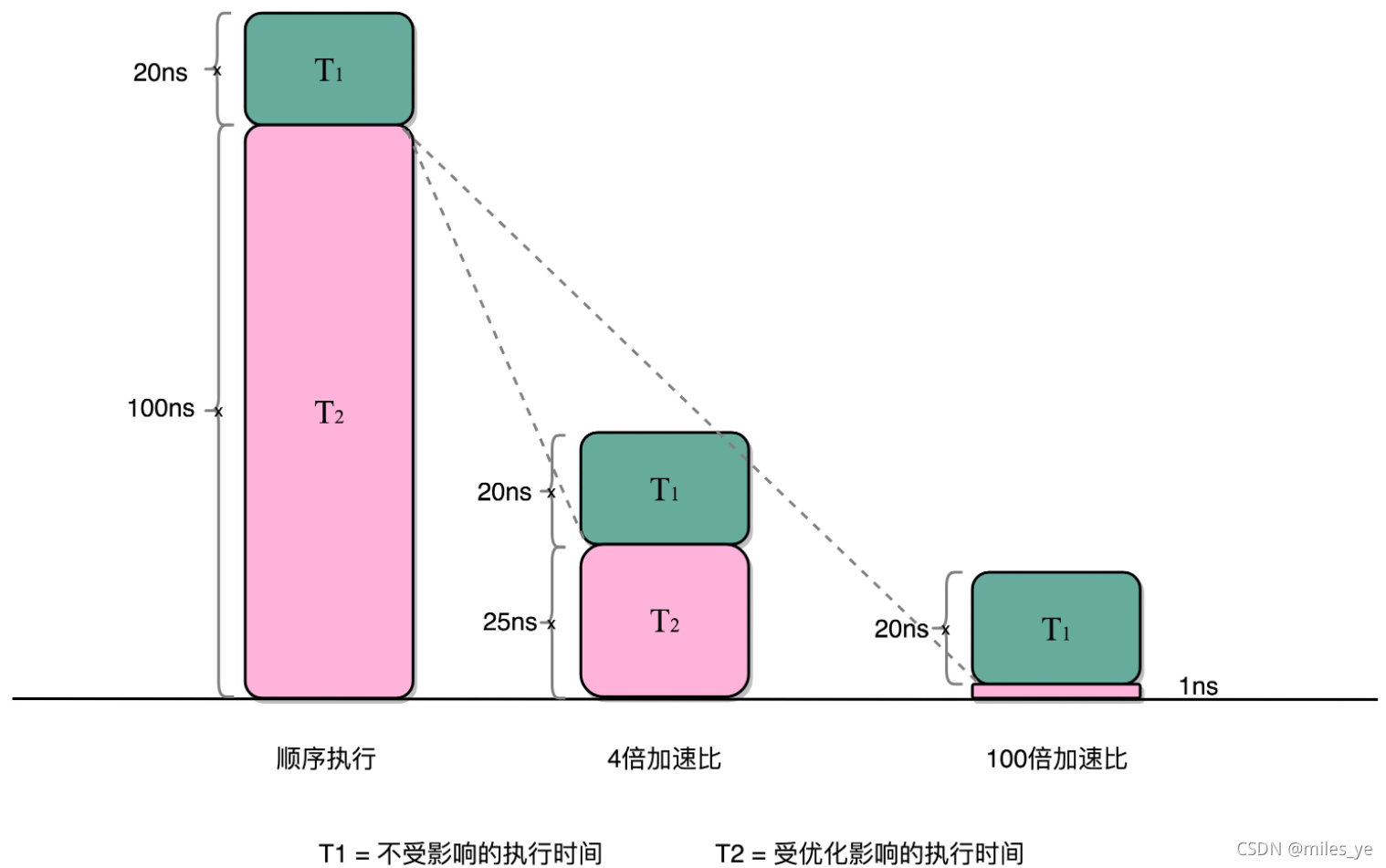
這就引出了在進行性能優化時的一個經驗——阿姆達定律(Amdahl’s Law),對于一個程式進行優化之后,處理器并行運算之后效率提升情況如下列公式所示:
優 化 后 的 執 行 時 間 = 受 優 化 影 響 的 執 行 時 間 / 加 速 倍 數 + 不 受 影 響 的 執 行 時 間 優化后的執行時間 = 受優化影響的執行時間 / 加速倍數 + 不受影響的執行時間 優化后的執行時間=受優化影響的執行時間/加速倍數+不受影響的執行時間
上例中,4 個人同時計算向量的一小段點積,就是通過并行提高了這部分的計算性能,但是,這 4 個人的計算結果,最侄訓是要在一個人那里進行匯總相加,這部分匯總相加的時間,是不能通過并行來優化的,也就是上面的公式里面不受影響的執行時間這一部分,
比如上例的各個向量的一小段的點積,需要 100ns,加法需要 20ns,總共需要 120ns,這里通過并行 4 個 CPU 進行了 4 倍的加速度,那么最終優化后,就有了 100/4+20=45ns,即使我們增加更多的并行度來提供加速倍數,比如有 100 個 CPU,整個時間也需要 100/100+20=21ns,
4. 小結
無論是簡單地通過提升主頻(功耗和散熱問題),還是增加更多的 CPU 核心數量,通過并行來提升吞吐量,達到提升性能的目的(并行部分可以提高,但串行部分提高不了),都會遇到相應的瓶頸,
在“摩爾定律”和“并行計算”之外,在整個計算機組成層面,還有如下幾個原則性的性能提升方法:
1)加速大概率事件,最典型的就是,過去幾年流行的深度學習,整個計算程序中,99% 都是向量和矩陣計算,于是,工程師們通過用 GPU 替代 CPU,大幅度提升了深度學習的模型訓練程序,本來一個 CPU 需要跑幾小時甚至幾天的程式,GPU 只需要幾分鐘就好了,Google 更是不滿足于 GPU 的性能,進一步地推出了 TPU,后面會為講解 GPU 和 TPU 的基本構造和原理,
2)通過流水線提高性能,現代的工廠里的生產線叫“流水線”,我們可以把裝配 iPhone 這樣的任務拆分成一個個細分的任務,讓每個人都只需要處理一道工序,最大化整個工廠的生產效率,類似的,CPU 其實就是一個“運算工廠”,把 CPU 指令執行的程序進行拆分、細化運行,也是現代 CPU 在主頻沒有辦法提升那么多的情況下,性能仍然可以得到提升的重要原因之一,后面也會講到,現代 CPU 里是如何通過流水線來提升性能的,以及反面的,過長的流水線會帶來什么新的功耗和效率上的負面影響,
3)通過預測提高性能,通過預先猜測下一步該干什么,而不是等上一步運行的結果,提前進行運算,也是讓程式跑得更快一點的辦法,典型的例子就是在一個回圈訪問陣列的時候,憑經驗,你也會猜到下一步我們會訪問陣列的下一項,后面要講的“分支和冒險”、“區域性原理”這些 CPU 和存盤系統設計方法,其實都是在利用對于未來的“預測”,提前進行相應的操作,來提升程式性能,
問題:這里介紹了三種常見的性能提升思路,分別是:加速大概率事件、通過流水線提高性能和通過預測提高性能,請你想一下,除了在硬體和指令集的設計層面之外,在軟體開發層面,有用到過類似的思路來解決性能問題嗎?
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/301007.html
標籤:其他