指標 和 陣列 試題決議
小編,在這里想說一下,c語言的最后一節 C預處理,可能還需要一些時間,因為小編,昨天才下載了虛擬機 和 linux 系統,還沒開始安裝,所以無法著手寫,因為 C預處理,vs2013很難表達,也就意味可能會講不清楚,所以這篇文章可能需要點時間,再加上小編初期的文章,是沒有排版的(而且可能有些錯誤,請大家以重置版為準),所以這幾天我就把這些重新寫,有興趣的朋友可以看看,(ps:如果哪一天沒有更新,意味著小編正在努力學習,為了能給大家呈現一片詳細好懂的文章,)
?
?
?
下面直接進入正文
陣列題:
先給你們打個底
1. sizeof(陣列名) ,此時的 陣列名 代表的是 整個陣列,
2. &陣列名,此時的 陣列名 代表的是 整個陣列,
除了以上兩種特殊情況,其它的,幾乎 100% 代表的是首元素地址
?
另外有一點請記住: arr[ i ] == *(arr + i );
arr[ i ][ j ] == *( *(arr + i)+ j)
?
好的,現在就讓我們進入習題中,去磨練這份知識,讓它再我們腦子里扎根
程式一(一維陣列):
一維陣列
#include<stdio.h>
int main()
{
int a[] = {1,2,3,4};
printf("%d\n", sizeof(a));// 16 計算的是整個陣列的記憶體大小
// sizeof(陣列名) 和 &陣列名,此時陣列名,代表的是整個陣列
printf("%d\n", sizeof(a+0));// 輸出為 4 / 8 (地址所占大小只與多少位作業系統有關,4byte【32位】,8byte【64】)
// 因為 sizeof()的括號里放的不是陣列名,而是 首元素地址 + 0,即sizeof(a[0])
printf("%d\n", sizeof(*a));// 4 因為 a 沒有 &(取地址),沒有單獨放在sizeof()里(屬于非特殊情況,陣列名代表首元素地址)
// *a 就是首元素,這里求的是 首元素 的記憶體大小,因為 這是一個整形陣列,里面的每個元素都是 int 型別,即為 4 byte
printf("%d\n", sizeof(a+1));// 4 / 8 與a + 0 的意思是一樣的,只是現在這里跳過一個元素,也就是說現在這是第二個元素的地址,地址的大小無非 就是 4/8 byte(受多少位系統影響,4byte【32位】,8byte【64位】)
printf("%d\n", sizeof(a[1]));// 4 a[1] == *(a+1) 第二個元素的地址對齊解參考找到第二個元素,sizeof(a[1]),就是在求 第二個元素的大小,因為 這是一個整形陣列,里面的每個元素都是 int 型別,即為 4 byte
printf("%d\n", sizeof(&a));// 4 / 8 &a 取出的是陣列的地址,陣列名沒有單獨放在sizeof括號里,而且 &a 取出的是整個陣列的地址,sizeof(&a) 就是在愛求 陣列的地址大小
// 陣列的地址也是地址 ,也受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(*&a));// 16 &a 取出的是陣列的地址,對取其解參考,找到陣列名a,也就是說 * 和 & 相互抵消了,等于就是說 sizeof(陣列名) ,此時陣列名代表的是整個陣列
printf("%d\n", sizeof(&a+1));// 4 / 8 &a,拿出的是陣列a的地址,+1跳過整個陣列,但還是一個地址,受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&a[0]));// 4 / 8 [] 的優先級 比 & 高,a 先和 [] 結合形成一個陣列,在對其取地址,又因為 a[0] == *(a+0),即這里 &a[0],取出的是 首元素的地址,既然是地址,就要受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&a[0]+1));// 4 / 8 [] 的優先級 比 & 高,a 先和 [] 結合形成一個陣列,在對其取地址,又因為 a[0] == *(a+0),即這里 &a[0],取出的是 首元素的地址,此時加一,跳過一個整形,也就是說 此時的地址 是 第二個元素的地址,既然是地址,就要受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
return 0;
}
?
?
?
?
?
?
字符陣列
1. sizeof(陣列名) ,此時的 陣列名 代表的是 整個陣列,
2. &陣列名,此時的 陣列名 代表的是 整個陣列,
除了以上兩種特殊情況,其它的,幾乎 100% 代表的是首元素地址
?
另外有一點請記住: arr[ i ] == *(arr + i );
arr[ i ][ j ] == *( *(arr + i)+ j)
程式二(字符陣列):
#include<stdio.h>
int main()
{
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' };
printf("%d\n",sizeof(arr));// 6 arr是一個字符陣列,每一個元素的記憶體大小為 1 byte,該陣列有 5個 元素,即 6 byte
printf("%d\n", sizeof(arr+0));//4 / 8 arr+0 == 首元素地址,既然是地址,就要受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(*arr));// 1 *arr(對首元素地址進行解參考) == 首元素,此時計算的是首元素的大小,即 1 byte
printf("%d\n", sizeof(arr[1]));// 1 arr[1] == *(arr+1),即第二個元素,即 sizeof 計算的是一個元素的大小,即 1 byte
printf("%d\n", sizeof(&arr));// 4 / 6 &arr 取出的是 陣列的地址,既然是地址,就要受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&arr+1));// 4 / 8 &arr 取出的是陣列的地址,在對其 加一,即跳過整個陣列,此時地址是陣列中不包含的地址,越界了,假設 陣列有 5 個元素,下標0 ~ 4,此時的地址是 下標為 5 的地址,有人肯能會有,那這個不應該是錯的嗎》怎么還有大小?,
//因為 sizeof 是不會真的去訪問越界的位置,只是看看那個位置的資料是什么型別,并不涉及訪問和計算,
//因為是第六個元素的地址,既然是地址,就要受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&arr[0]+1));// 4 / 8 這個就不用我多說了,它就就是一個地址,第二個元素的地址(&arr[0] + 1 == 首元素地址 + 1,即首元素地址 挑過一個 位元組,),既然是地址,就要受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
return 0;
}
?
?
接下我們把 sizeof 換成 strlen ,來看看這些題會發生什么變化?
在開始之前請注意一下內容:
1. strlen 只有 遇到 ‘\0’,才會停止計數,計數個數(不包括 ‘\0’ 這個元素),如果沒有 ‘\0’,strlen 這個函式就會往后面找 ‘\0’,所以 strlen 的回傳值,在沒有 '\0’的情況下,回傳 一個隨機值,
2.strlen(這里要放一個地址),如果不是,會導致程式崩潰
舉個列子:strlen(a),a 的 地址為 97,strlen 就會 以 97 為地址,開始往后 一邊尋找 ‘\0’,一邊計數,很容易形成越界訪問,從而導致程式崩潰
?
程式三(字符陣列):
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' };
printf("%d\n", strlen(arr));// 隨機值, 沒有'\0'·從首元素開始計數,且向后尋找'\0',但是該陣列里沒有'\0'的,所以它會一直往后找'\0',直到找到了才停止計數,所以回傳的是一個隨機值
printf("%d\n", strlen(arr + 0));// 隨機值,還是從首元素開始計數,且向后尋找'\0',但是該陣列里沒有'\0'的,所以它會一直往后找'\0',直到找到了才停止計數,所以回傳的是一個隨機值
//printf("%d\n", strlen(*arr));// *arr == 'a' == 97 strlen(把97當成一個地址),非法訪問,程式崩潰
//printf("%d\n", strlen(arr[1]));// 與上運算式一樣, 非法訪問,程式崩潰
printf("%d\n", strlen(&arr));// 隨機值
printf("%d\n", strlen(&arr + 1));// 隨機值 - 6 ,與上表示式的隨機值 ,相差 6,因為 &arr 讀取的是陣列的地址,加一 等于 跳過一個個陣列,也就是跳過了 6 個元素,也就是說這六個元素,沒有被計入,現在是 第 7 個元素的地址,從第七個元素開始 計數 和 尋找 '\0'
printf("%d\n", strlen(&arr[0] + 1));// 隨機值 - 1,與 上上 運算式的隨機值,相差 1,這里是從 第二個元素,開始 計數 與 尋找'\0',第一個元素沒有計入在內
return 0;
}
?
?
程式四(字符陣列):
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "abcdef";// == "abcdef" == 'a', 'b', 'c', 'd', 'e', 'f', '\0'
printf("%d\n", sizeof(arr));// 7 后面隱藏一個元素 '\0'
printf("%d\n", sizeof(arr + 0));// 4 / 8 是一個地址,
printf("%d\n", sizeof(*arr));// 1 *arr == 首元素,這里計算的是首元素的記憶體大小
printf("%d\n", sizeof(arr[1]));// 1 計算第二個元素的記憶體大小
printf("%d\n", sizeof(&arr));// 4 / 8 ,這是一個地址
printf("%d\n", sizeof(&arr + 1));// 4 / 8 ,這是一個地址
printf("%d\n", sizeof(&arr[0]) + 1);// 4 / 8, 這是一個地址
printf("%d\n", strlen(arr));// 6 遇到'\0'停止計數,'\0'不計入在內
printf("%d\n", strlen(arr + 0));// 6 arr+0 == arr 從首元素開始計數,遇到'\0'停止計數,'\0'不計入在內
printf("%d\n", strlen(*arr));// *arr == a == 97,以97為地址( 從 97 開始計算直到遇到'\0' ),屬于非法訪問,程式崩潰
printf("%d\n", strlen(arr[1]));// arr[1] == b == 98,以98為地址( 從 98 開始計算直到遇到'\0' ),屬于非法訪問,程式崩潰
printf("%d\n", strlen(&arr));// 6 &arr 雖然是陣列的地址,但是對于strlen函式來說,它就只是第一個元素的地址,從該元素開始計數,遇到'\0'停止計數,'\0'不計入在內
printf("%d\n", strlen(&arr + 1));// 隨機值,跳過了一個陣列,從 '\0' 后面 開始計數,直到遇到'\0'停止計數,'\0'不計入在內
printf("%d\n", strlen(&arr[0]) + 1);// 5 從第二個元素開始計數,遇到'\0'停止計數,'\0'不計入在內
return 0;
}
?
程式五(字符陣列):
#include<stdio.h>
#include<string.h>
int main()
{
char* p = "abcdef";// p 存的是 字串的首元素的a的地址
printf("%d\n", sizeof(p));// 4 / 8 a 的地址
printf("%d\n", sizeof(p + 0));// 4 / 8 b 的地址,
printf("%d\n", sizeof(*p));// 1 *arr == 首元素 a,這里計算的是首元素的記憶體大小
printf("%d\n", sizeof(p[0]));// 1 計算第一個元素的記憶體大小 p[0] == *(p+0) == a
printf("%d\n", sizeof(&p));// 4 / 8 把指標變數本身的地址取出來了,是一個地址
printf("%d\n", sizeof(&p + 1));// 4 / 8 取出 指標變數 p的 地址,加上 1,是誰的地址,不知道也不重要,因為它還是一個地址
printf("%d\n", sizeof(&p[0] + 1));// 4 / 8, &(*(p+0)) +1 ,a的地址加上一位元組,改地址是 b 的地址
printf("%d\n", strlen(p));// 6 指標變數 p 存的是 a的地址,從a開始計算,直到遇到'\0'停止,'\0'不計入在內
printf("%d\n", strlen(p + 1));// 5 指標變數 p 存的是 b 的地址,從b開始計算,直到遇到'\0'停止,'\0'不計入在內
printf("%d\n", strlen(*p));// *p == a == 97,以97為地址( 從 97 開始計算直到遇到'\0' ),屬于非法訪問,程式崩潰
printf("%d\n", strlen(p[0]));// p[0] == a == 97,以97為地址( 從 97 開始計算直到遇到'\0' ),屬于非法訪問,程式崩潰
printf("%d\n", strlen(&p));// 隨機值, 這里是指標變數 p 的地址,不是a的地址,而 p 后面什么時候能遇到 '\0',我們不知道,所以回傳一個 隨機值
printf("%d\n", strlen(&p + 1));// 隨機值,這里還是取的 指標變數 p 的地址,對齊加一,跳過一個p,意味著 strlen 少計數 一整個 p 所含的元素
printf("%d\n", strlen(&p[0] + 1));// 5 取出第一個元素的地址加一,到第 二 個元素,從第二個元素計算,直到遇到'\0'停止,'\0'不計入在內
return 0;
}
?
?
?
?
?
?
?
?
二維陣列
1. sizeof(陣列名) ,此時的 陣列名 代表的是 整個陣列,
2. &陣列名,此時的 陣列名 代表的是 整個陣列,
除了以上兩種特殊情況,其它的,幾乎 100% 代表的是首元素地址
?
另外有一點請記住: arr[ i ] == *(arr + i );
arr[ i ][ j ] == *( *(arr + i)+ j)
arr[ i ][ j ] ,arr[ i ] 就是一維陣列的陣列名
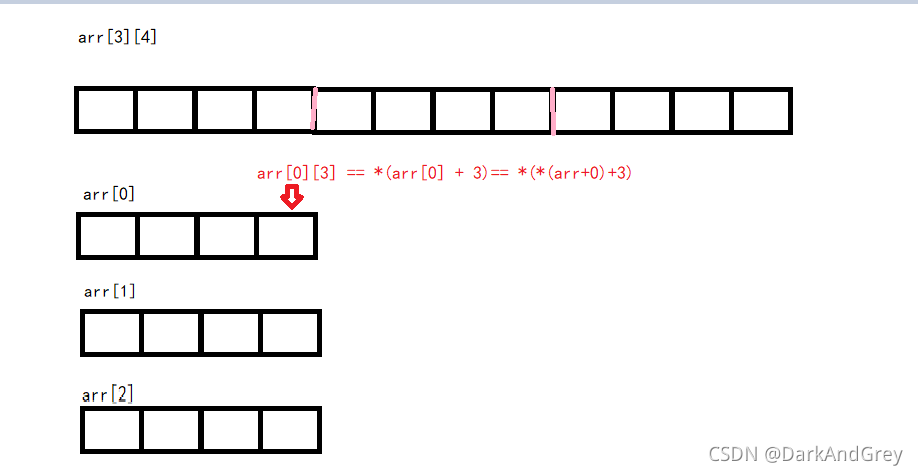
程式六( 二維陣列):
#include<stdio.h>
#include<string.h>
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));// 48 此時 陣列名 a 代表的是整個陣列,意味著 sizeof 計算的是整個陣列的大小; 3*4*4 = 12*4 = 48
printf("%d\n", sizeof(a[0][0]));// 4 第一行第一個元素
printf("%d\n", sizeof(a[0]));// 16 把第0行看成一個一維陣列,a[0]就是一個一維陣列的陣列名,所以計算的整個第 0 行元素的記憶體大小 4 * 4 = 16
printf("%d\n", sizeof(a[0] + 1));// 4 / 8 第0行 第2個元素的地址
printf("%d\n", sizeof(*(a[0] + 1)));// 4 第0行 第2個元素 a[0][1] == *(*(a+0)+1)
printf("%d\n", sizeof(a + 1));// 4 / 8 第1行 的 一維陣列 的 地址,*(a +1) = arr[1],不就是第1行 一維陣列的 陣列名,在對其 &(取地址),既然是一個地址,就要受多少位作業系統影響: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(*(a + 1)));// 16 解參考 第一行的一維陣列的陣列名(首元素)的地址,等于就是找到第一行的一維陣列的陣列名,
//sizeof(第一行 的 陣列名 ),所以計算的是整個第一行元素的記憶體大小
printf("%d\n", sizeof(&a[0] + 1));// 4 / 8 第 1 行(第一行的一維陣列名)的 地址,
printf("%d\n", sizeof(*(&a[0]) + 1));// 16 解參考 第 1 行(第一行的一維陣列名)的 地址,等于找到了 第 1 行的一維陣列的陣列名
//sizeof(第一行 的 陣列名 ),所以計算的是整個第一行元素的記憶體大小
printf("%d\n", sizeof(*a));// 16 a是首元素的地址(第 0 行的陣列地址) ,*a(解參考 a )找到了第0行陣列名,
//計算的是整個第 0 行所有元素的記憶體大小
printf("%d\n", sizeof(a[3]));//16 ,另外 sizeof()括號里運算式不會計算,也就是說不會真的訪問第四行資料,它只是把第四行的陣列名放在這里()
//意思這里有第四行,就意味著 第四行 有 它自己 的 型別 ,其實這里 a[3] 跟 a[0] 一樣的道理,
//a[3] 是第四行的陣列名,那有 第四行嗎?其實沒有,但并不妨礙,因為我們不去訪問
// 而且 sizeof() 括號里的 運算式 是不參與真實運算的 ,只是 根據 它的型別 計算 它的大小
// 所以 a[3] 是一個一維陣列,而且有 4 個整形的一維陣列,sizeof(a[3]) == 4 * 4 == 16
return 0;
}
?
?
?
?
?
?
?
?
指標題
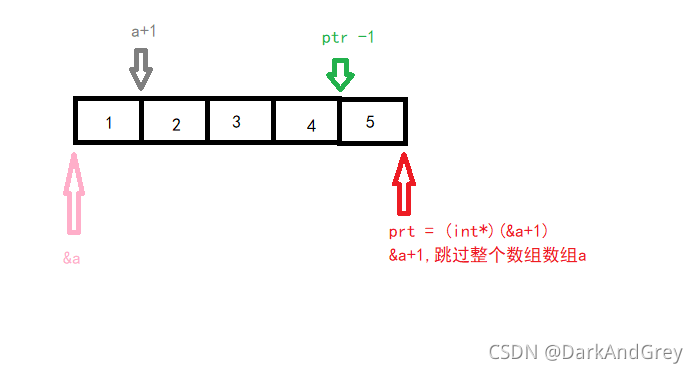
程式七( 指標):
#include<stdio.h>
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);// 陣列的指標型別,不能放進一個整形指標里,所以這里強制型別轉換,但值沒有發生變換,
// 存的值,還是跳過一個陣列的指向的那個值(未知量)
printf("%d,%d\n", *(a + 1), *(ptr - 1));// 整形指標 ptr 減一,指向 5 的 那個位置,再解參考就是5
return 0; // 2 5
}
?
?
程式八( 指標):
include<stdio.h>
struct test
{
int num;
char* pcname;
short s_date;
char cha[2];
short s_ba[4];
}* p;
假設 p 的 值為 0x10 00 00 00,如下運算式分別為多少
已知結構體 test 型別 的 變數 大小為 20個位元組
#include<stdio.h>
int main()
{
p = (struct test*)0x100000;
printf("%p\n", p + 0x1);// 0x1 == 1 這里加1 等于跳過了一個結構體(20位元組)
//0x10 00 00 + 20 ==0x10 00 14 因為 %p(32位)
//列印 0x 00 10 00 14
printf("%p\n", (unsigned long)p + 0x1); // 強制型別轉換 無符號長整形型別,0x100000 轉換為 10 進制 -> 1048576 + 1 = 1048577 -> 0x10 00 01
// %p, 即0x 00 10 00 01
printf("%p\n", (unsigned int*)p + 0x1);//強制型別轉換 無符號整形指標型別 加1 == 就是跳過一個無符號整形 指標(4 byte)
// 即 0x 00 10 00 04
return 0;
}
?
?
?
?
程式九( 指標):
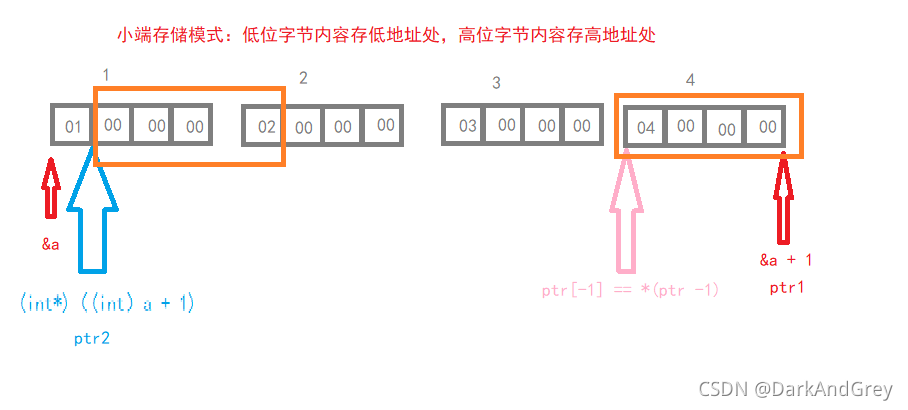
#include<stdio.h>
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);// %x 十六進制數
return 0; // 4 2 000 000
}
// 1 2 3 4
// 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00
// 低地址 高地址(小端 存盤:低位元組存低地址,高位元組存高地址)
// a 是陣列名(首元素地址),指向 1 所在的地址(01前面),這時型別強制轉換 整形,加1(1位元組),
// 再將他轉換為一個地址,在對其解參考 ,此時它(ptr2)指向 01 的后面,又因為ptr2是int 型別
//也就是說它一次訪問 4 個位元組的內容( 00 00 00 02 ) 取出來使反著讀取(從高位開始讀取),02 00 00 00
// 按十六進制 輸出 (0x 02 00 00 00) 即,2 000 000
?
?
程式十( 指標):
#include<stdio.h>
int main()
{ // 1 3 5
int a[3][2] = { ( 0, 1 ), ( 2, 3 ), ( 4, 5) };// a 是一個 3排 2列 的 二維陣列
int* p; //逗號運算式,以最后一個運算式結果為準
// 陣列存盤情況 1 3
// 5 0
// 0 0
p = a[0];
printf("%d\n",p[0]); // 1
return 0;
}
?
?
程式十( 指標):
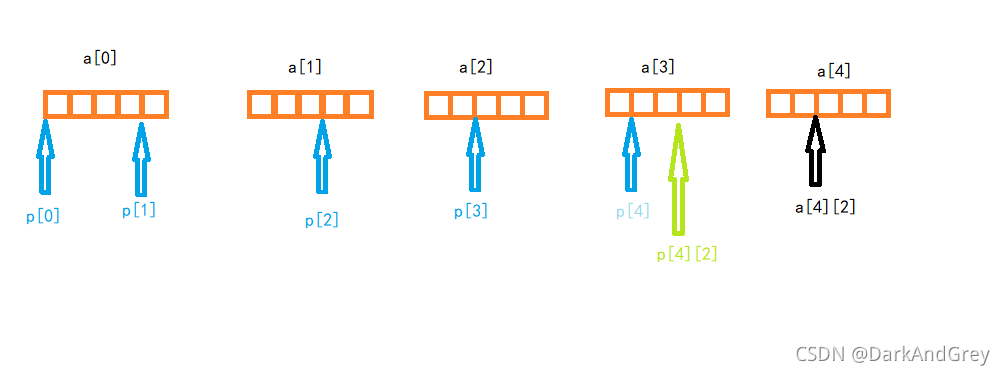
#include<stdio.h>
int main()
{
int a[5][5];
// a[0] a[1] a[2] a[3] a[4]
// 口口口口口 口口口口口 口口口口口 口口口口口 口口口口口
// | | | | | | |
//p[0] p[1] p[2] p[3] p[4] | a[4][2]
// p[4][2]
int(*p)[4];
p = a;// p的型別 int(*)[4] a的型別 int(*)[5]
// p 是一個指向整形陣列的指標,有4個元素
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);// a 先和 [] 集合([]的優先級高)
return 0; // p[4] == *(p+4) p[4][2] == *(*(p + 4) + 2)
// 指標減指標 等于兩個指標之間的元素個數 ,&p[4][2] - &a[4][2] == - 4
}
列印的條件 :%d == - 4
-4 1000 0000 0000 0000 0000 0000 0000 0100 原碼(列印)
1111 1111 1111 1111 1111 1111 1111 1100 補碼(存盤)
%p 認為記憶體上放的是地址,地址就沒有原反補碼的概念(無符號數)
整形在記憶體中,以補碼型別存盤,所以直接以補碼當做地址輸出
1111 1111 1111 1111 1111 1111 1111 1100 原碼符號位不變,其余位按位取反,再加 1
0x f f f f f f f c
所以%p 的輸出結果是 ffff fffc
?
?
程式十一( 指標):
#include<stdio.h>
int main()
{
int a[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&a + 1);//跳過整個二維陣列
int* ptr2 = (int*)(*(a + 1));// 第一行的陣列名
// int aa[5]={0};
// int* p = arr;
// *(aa+2) == a[2] == *(p + 2)
printf("%d,%d\n",*(ptr1 - 1),*(ptr2 - 1));
return 0;// 10 5
}
?
?
程式十二( 指標):
#include<stdio.h>
int main()
{
char* a[] = { "work", "at", "alibaba" };// char *p = "abcdef"; p 存的是字串首元素(a)的地址
//這里也是一樣,字符指標陣列 a ,陣列名 a == 首元素("work")中 'w ' 的地址
char* *pa = a;// *pa(指標),型別 char* ,*pa指向第一個元素(a == 首元素的地址)
// 遺跡指標的地址需要一個二級指標來接收
pa++;//跳過一個char*,指向第二個元素,
printf("%s\n",*pa);// at
return 0;
}
?
?
程式十三( 指標):
#include<stdio.h>
int main()
{
char*c[] = { "ENTER", "NEW", "POINT", "FIRST" };
char* *cp[] = { c + 3, c + 2, c + 1, c };
// FIRST POINT NEW ENTER
// c[] cp
// char* ENTER c+3 char** FIRST -> cpp
// char* NEW c+2 char** POINT
// char* POINT c+1 char** NEW
// char* FIRST c char** ENTER
char** *cpp = cp;
printf("%s\n",* *++cpp); // POINT 此時cpp指向第二個元素(c+2),再對其解參考 POINT 的首元素地址
此時 cpp 指向 c+2(第二個元素) 處,因為 上面 ++cpp 改變 cpp 的指向
printf("%s\n", *--*++cpp + 3); // ER ++ -- 優先級比 + 高,
//所以先加加,此時cpp指向第三個元素,再進行 *(解參考)== 第三個元素(c+1),
//再 -- (第三個元素減一),即 c + 1 - 1 == c ,再進行 *(解參考),此時 等于 ENTER (此時類似于陣列名)
// 最后再加 3 (ENTER + 3),最終指向 "ENTER"中第四個元素 E 的地址 ,然后從 E 開始往后列印,直到遇到'\0'停止,
// 即 最后輸出為 : ER
// 另外 注意 此時 cpp是指向第三個元素 c+1 的,
printf("%s\n", *cpp[-2] + 3); // *cpp[-2] + 3 = *(cpp-2) + 3 ; cpp-2 == cpp[0] ==(c+3)
// 再對其解參考,等于 FIRST
// 再加上三,此時指向(FIRST 此時類似于陣列名),FIRST + 3 第四個元素 S 的地址
// 然后從 S 開始列印,直到遇到'\0'停止,
// 即 最后輸出為:ST
// 注意 此時 cpp 還是指向第三個元素 c+1 的(前面 *cpp[-2],并不會改變其值,它只是加上一個數,然后去訪問,就好比 一個人 站著凳子 去拿柜子上高處的東西,并不會改變自身身高,而前置和后置 ++,自增,也就是說等自己長高了再去拿,此時的身高已經改變了),
printf("%s\n", cpp[-1][-1] + 1);
// == *( *(cpp - 1) -1 ) + 1
// *(cpp - 1) == c + 2
// 再 減 1, c + 2 - 1 = c + 1
// 在對其解參考 等于 NEW
// 再加 1 ,NEW(此時類似于陣列名) +1 ,此時得到了第二個元素(E)的地址
//然后 從 E 這里開始列印,直到遇到'\0'停止,
// 即 最后輸出為 EW
return 0;
}
如果有疑問,歡迎在下面評論,本文至此就全部結束了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/301563.html
標籤:其他
上一篇:【計算機網路】計算機網路概述