滑動視窗機制
1. 滑動視窗介紹
? 在進行資料傳輸時,如果傳輸的資料比較大,就需要拆分為多個資料包進行發送,TCP 協議需要對資料進行確認后,才可以發送下一個資料包,如圖所示,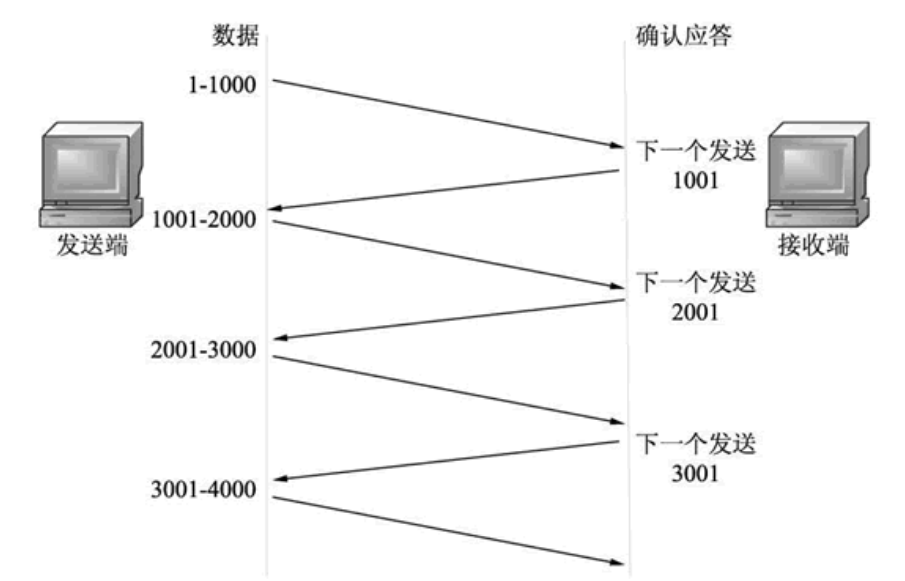
? 從上圖中可以看到,發送端每發送一個資料包,都需要得到接收端的確認應答以后,才可以發送下一個資料包,這種一發一收的方式大大浪費了時間,為了避免這種情況,TCP引入了視窗概念,其可以一次發送多條資料,并接收多條應答,如下圖所示
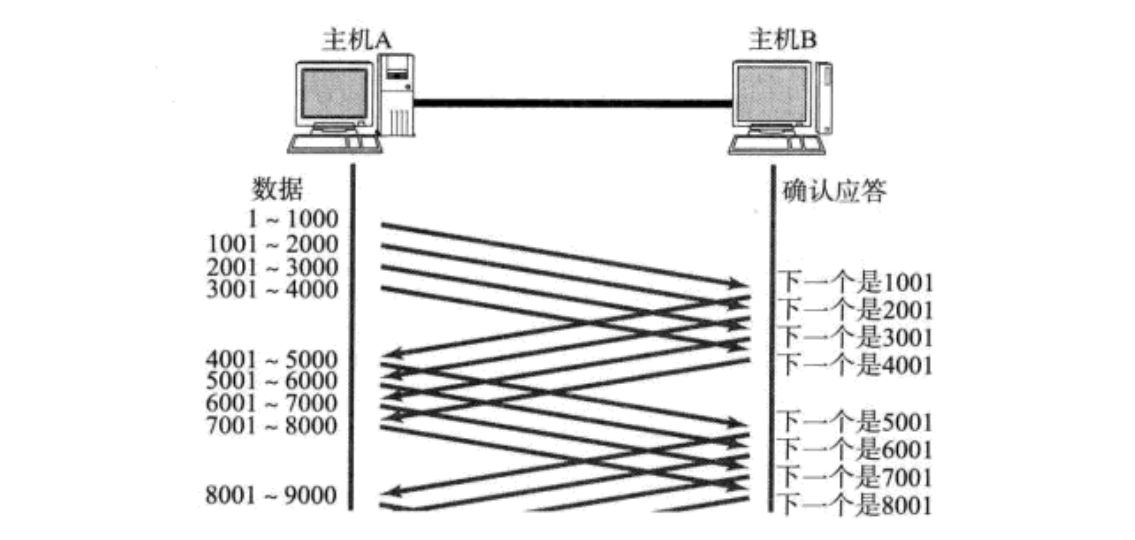
視窗大小指的是不需要等待確認應答包而可以繼續發送資料包的最大值,上圖的視窗大小就是4000個位元組(四個欄位)
發送前四個欄位的時候, 不需要等待任何ACK, 直接發送;
收到第一個ACK后, 滑動視窗向后移動, 繼續發送第五個段的資料; 依次類推;
作業系統內核為了維護這個滑動視窗, 需要開辟 發送緩沖區 來記錄當前還有哪些資料沒有應答; 只有確認
應答過的資料, 才能從緩沖區刪掉;
視窗越大, 則網路的吞吐率就越高;
? 視窗大小指的是可以發送資料包的最大數量,在實際使用中,它可以分為兩部分,第一部分表示資料包已經發送,但未得到確認應答包;第二部分表示允許發送,但未發送的資料包,在進行資料包發送時,當發送了最大數量的資料包(視窗大小資料包),有時不會同時收到這些資料包的確認應答包,而是收到部分確認應答包,
? 那么,此時視窗就通過滑動的方式,向后移動,確保下一次發送仍然可以發送視窗大小的資料包,這樣的發送方式被稱為滑動視窗機制,設定視窗大小為 3,滑動視窗機制原理如圖所示,
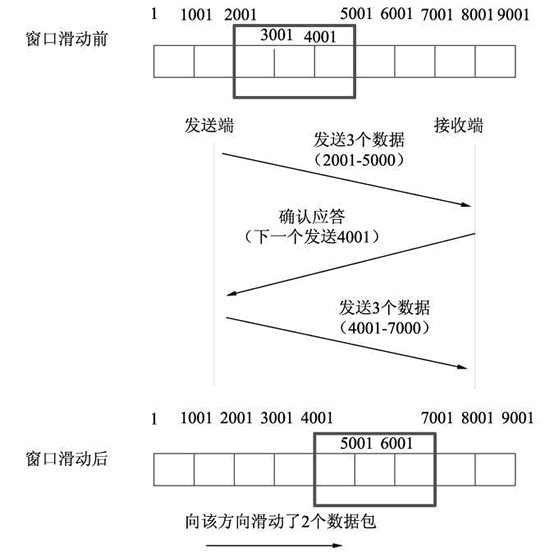
上圖中,每 1000 個位元組表示一個資料包,發送端同時發送了 3 個資料包(2001-5000),接收端回應的確認應答包為“下一個發送4001”,表示接收端成功回應了前兩個資料包,沒有回應最后一個資料包,此時,最后一個資料包要保留在視窗中,
由于視窗大小為 3,發送端除了最后一個包以外,還可以繼續發送下兩個資料包(5001-6000 和 6001-7000),視窗滑動到 7001 處,
2. 資料重發
在進行資料包傳輸時,難免會出現資料丟失情況,這種情況一般分為兩種,
2.1 確認應答包(ACK)丟了
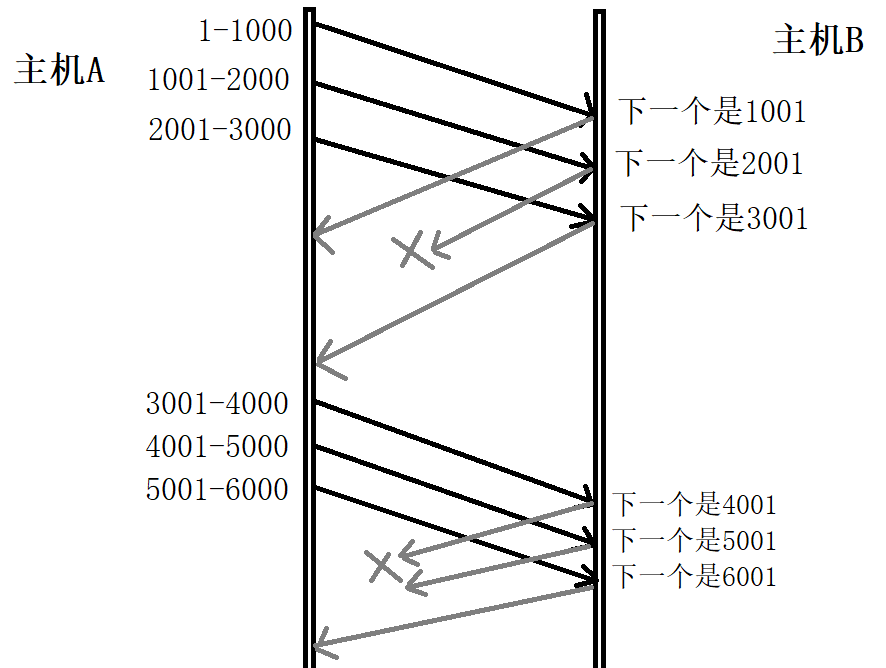
對上圖進行圖解
- 發送端發送資料包(視窗大小為3):同時發送 3 個資料包 1-1000、1001-2000 和 2001-3000,
- 接收端回傳確認應答包:接收端接收到這些資料,并給出確認應答包,資料包 1-1000 和資料包 2001-3000 的確認應答包沒有丟失,但是資料包 1001-2000 的確認應答包丟失了,
- 發送端第 2 次發送資料包:發送端收到接收端發來的確認應答包,雖然沒有收到資料包 1001-2000 的確認應答包,但是收到了資料包 2001-3000 的確認應答包**(下一個是3001)**,于是判斷第一次發送的 3 個資料包都成功到達了接收端,再次發送 3 個資料包 3001-4000、4001-5000 和 5001-6000,
- 接收端回傳確認應答包:接收端接收到這些資料,并給出確認應答包,資料包 3001-4000 和資料包 4001-5000 的確認應答包丟失了,但是資料包 5001-6000 沒有丟失,
- 發送端第 3 次發送資料包:發送端收到接收端發來的確認應答包,查看到資料包 5001-6000 收到了確認應答包**(下一個是6001)**,于是判斷第 2 次發送的 3 個資料包都成功到達了接收端,
? 由于序號是有序的,如果接收到后面資料的ACK,說明前面的資料已經被接收,只是發送的ACK丟包了,這種情況就表示前面的資料包已經成功被接收端接收了,發送端也就不需要重新發送前面的資料包了,
2.2 發送資料包丟失
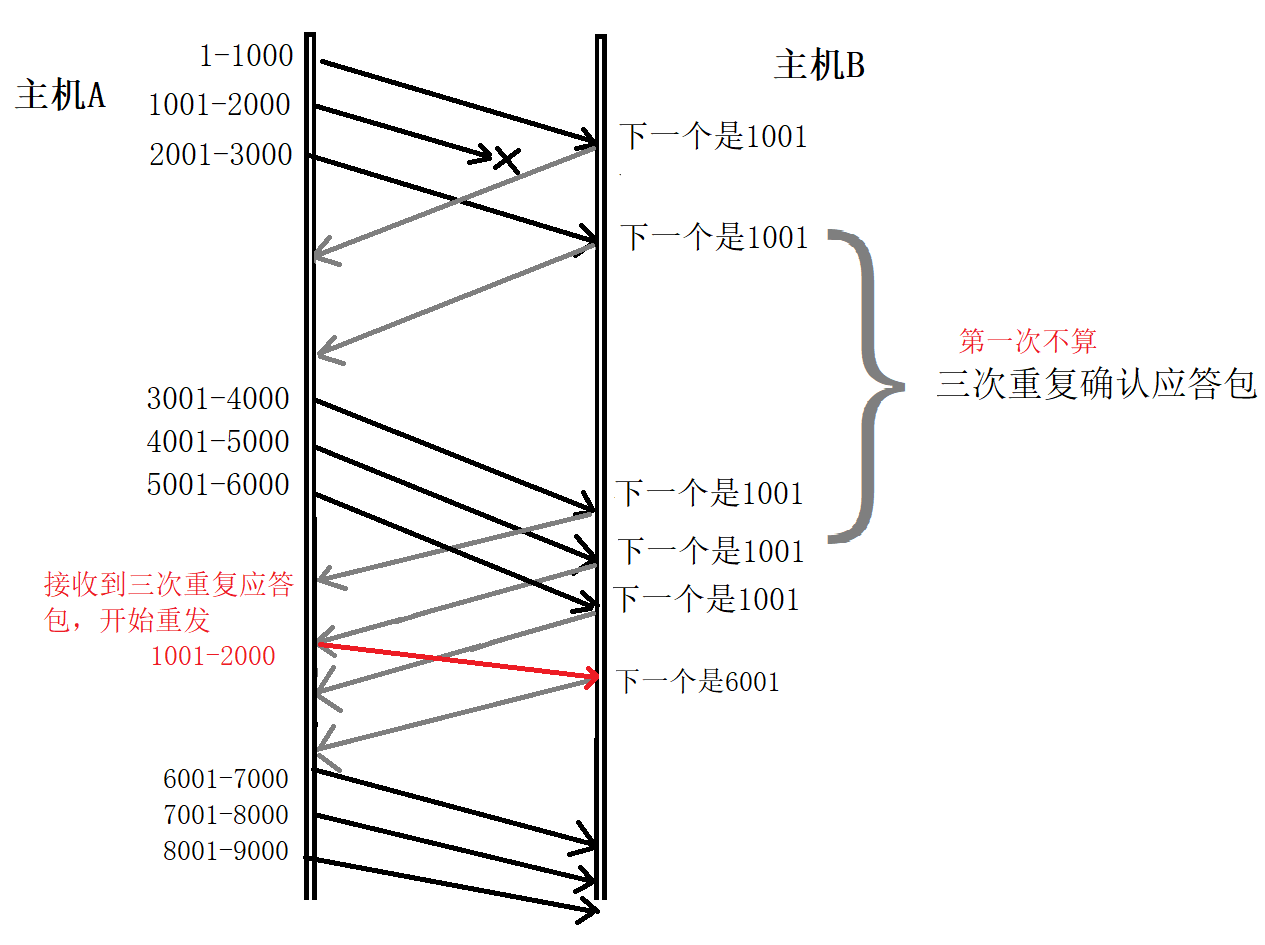
- 發送端發送資料包(視窗大小為3):同時發送 3個資料包,分別為 1-1000、1001-2000 和 2001-3000,
- 接收端回傳確認應答包:接收端接收到這些資料,并給出確認應答包,接收端收到了資料包 1-1000,回傳了確認應答包;但是資料包 1001-2000,在發送程序中丟失了,沒有成功到達接收端,資料包 2001-3000 沒有丟失,成功到達了接收端,但是該資料包不是接收端應該接收的資料包,資料包 1001-2000 才是真正應該接收的資料包,因此收到資料包 2001-3000 以后,接收端第一次回傳下一個是 1001 的確認應答包,
- 發送端發送資料包:發送端仍然繼續向接收端發送 3個資料包,分別為 3001-4000、4001-5000 和 5001-6000,
- 接收端回傳確認應答包:接收端接收到這些資料,并給出確認應答包,當接收端收到資料包 3001-4000 時,發現不是自己應該接收的資料包 1001-2000,第二次回傳下一個是 1001 的確認應答包,當接收端收到資料包 4001-5000 時,仍然發現不是自己應該接收的資料包 1001-2000,第三次回傳**下一個是1001 的確認應答包,以此類推直到接收完所有資料包,接收端都回傳下一個是1001 **的確認應答包,
- 發送端重發資料包:發送端連續 3 次收到接收端發來的**下一個是1001 **的確認應答包,認為資料包 1001-2000 丟失了,就進行重發該資料包,
- 接收端收到重發資料包:接收端收到重發資料包以后,查看這次是自己應該接收的資料包 1001-2000,并回傳確認應答包,告訴發送端,下一個該接收 6001 的資料包了,
- 發送端發送資料包:發送端收到確認應答包后,繼續發送視窗大小為 3的資料包,分別為 6001-7000、7001-8000 和8001-9000,
對于步驟6、7:由于之前2001-6000的資料接收端其實之前就已經收到了, 被放到了接收端作業系統內核的接識訓沖區中,所以直接發送6001開始的資料即可,
3. 流量控制
? 在使用滑動視窗機制進行資料傳輸時,發送方根據實際情況發送資料包,接收端接收資料包,但是,接收端處理資料包的能力是不同的,因此可能出現下面兩種現象
-
如果視窗過小,發送端發送少量的資料包,接收端很快就處理了,并且還能處理更多的資料包,這樣,當傳輸比較大的資料時需要不停地等待發送方,造成很大的延遲,
-
如果視窗過大,發送端發送大量的資料包,而接收端處理不了這么多的資料包,這樣,就會堵塞鏈路,如果丟棄這些本應該接收的資料包,又會觸發重發機制,
為了避免這種現象的發生,TCP 提供了流量控制,所謂的流量控制就是動態調節視窗大小發送資料包,發送端第一次以視窗大小**(第一次的視窗大小是根據鏈路帶寬的大小來決定的)**發送資料包,接收端接收這些資料包,并回傳確認應答包,告訴發送端自己下次希望收到的資料包是多少(新的視窗大小),發送端收到確認應答包以后,將以該視窗大小進行發送資料包,
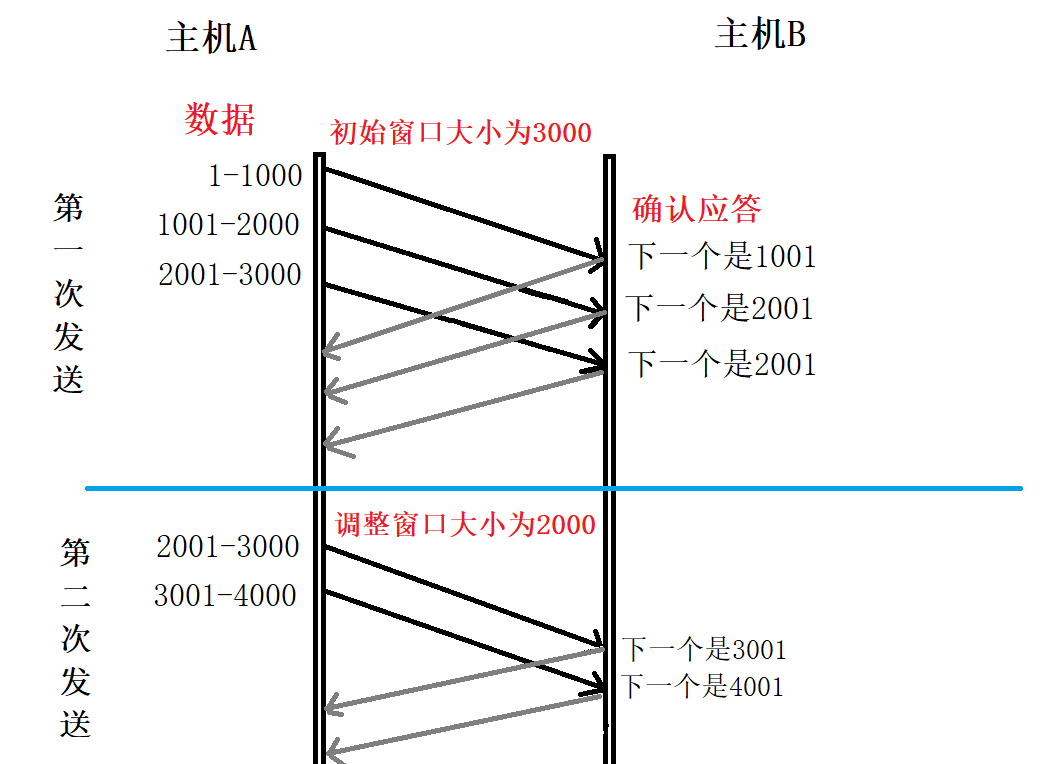
圖解如下:
- 首先發送端根據當前鏈路帶寬大小決定發送資料包的視窗大小,假設初始視窗大小為3,因此發送端發送了 3 個資料包,分別為 1-1000、1001-2000 和 2001-3000,
- 接收端接收這些資料包,但是緩沖區只能處理 2 個資料包,第 3 個資料包 2001-3000 沒有被處理,因此只回傳前兩個的確認應答包,并設定視窗大小為 2000,告訴發送端自己現在只能處理 2 個資料包,下一次請發送 2 個資料包,
- 發送端接收到確認應答包,查看到接收端回傳視窗大小為 2000,知道接收端只處理了 2 個資料包,發過去的第 3 個資料包 2001-3000 沒有被處理,這說明此時接收端只能處理 2 個資料包,第 3 個資料包還需要重新發送,
- 因此發送端發送 2 個資料包 2001-3000 和 3001-4000,接收端收到這兩個資料包并進行了處理,此時,還是只能處理 2 個視窗,繼續向發送端發送確認應答包,設定視窗為 2,告訴發送端,下一個應該接收 4001 的資料包,
視窗探測
但是,如果在接收端回傳的確認應答包中,視窗設定為 0,則表示現在不能接收任何資料,這時,發送端將不會再發送資料包,只有等待接收端發送視窗更新通知才可以繼續發送資料包,
如果這個更新通知在傳輸中丟失了,那么就可能導致無法繼續通信,為了避免這樣的情況發生,發送端會時不時地發送視窗探測包,該包僅有1個位元組,用來獲取最新的視窗大小的資訊,如下圖所示
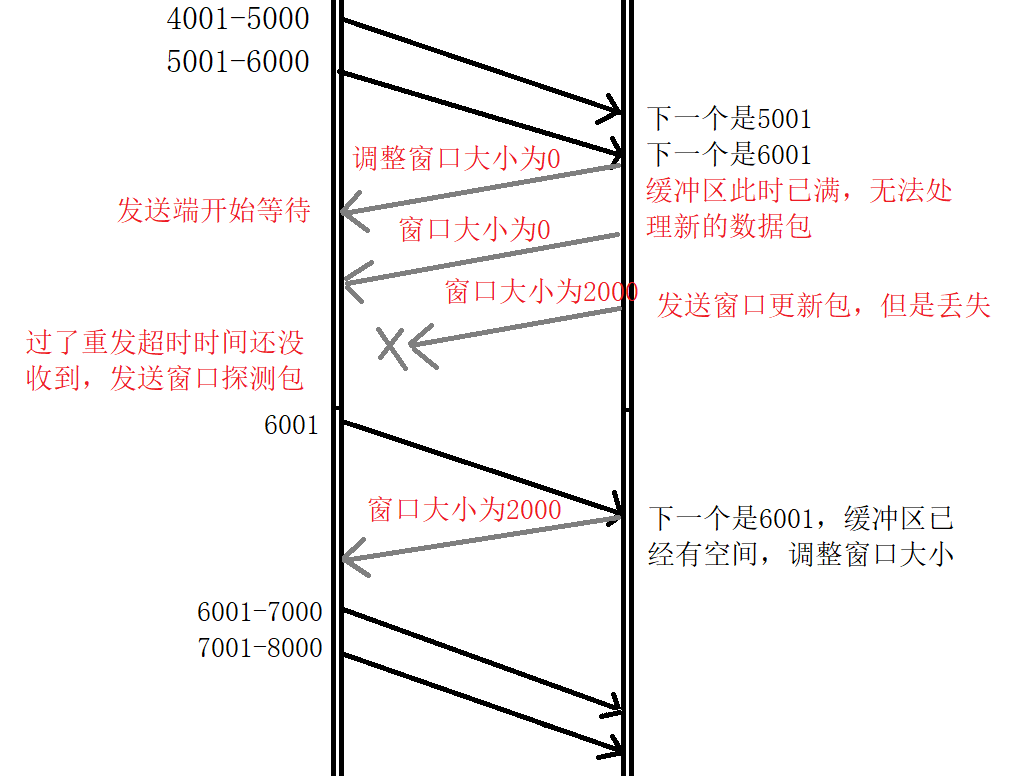
上述圖解
- 發送端發送資料,發送端以視窗大小為 2000,發送了 2 個資料包,分別為 4001-5000 和 5001-6000,接收端接收到這些資料以后,緩沖區滿了,無法再處理資料,于是向發送端回傳確認應答包,告訴它下一個接收 6001 的資料,但是現在處理不了資料,先暫停發送資料,設定視窗大小為 0,
- 發送端暫停發送資料,發送端收到確認應答包,查看到下一次發送的是 6001 的資料,但視窗大小為 0,得知接收端此時無法處理資料,此時,不進行發送資料,進入等待狀態,
- 接收端發送視窗大小更新包,當接收端處理完發送端之前發來的資料包以后,將會給發送端發送一個視窗大小更新包,告訴它,此時可以發送的資料包的數量,這里設定視窗大小為 2000,表示此時可以處理 2 個資料包,但是該資料包丟失了,沒有發送到發送端,
- 發送端發送視窗探測包,由于視窗大小更新包丟失,發送端的等待時間超過了重發超時時間,此時,發送端向接收端發送一個視窗探測包,大小為 1 位元組,這里是 6001,
- 接收端再次發送視窗大小更新包,接收端收到發送端發來的探測包,再次發送視窗大小更新包,視窗大小為 2000,
- 發送端發送資料,發送端接收到視窗大小更新包,查看到應該發的是 6001 的資料包,視窗大小為2000,可以發送 2個資料包,因此發送了資料包,分別為 6001-7000和 7001-8000,
4. 擁塞控制
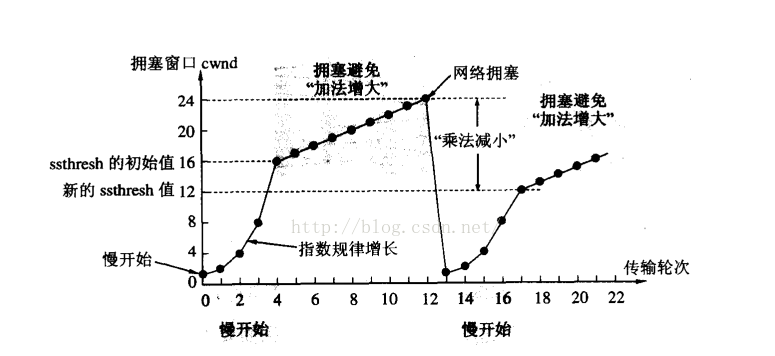
雖然TCP有了滑動視窗這個大殺器, 能夠高效可靠的發送大量的資料. 但是如果在剛開始階段就發送大量的資料, 仍然可能引發問題.因為網路上有很多的計算機, 可能當前的網路狀態就已經比較擁堵. 在不清楚當前網路狀態下, 貿然發送大量的資料, 是很有可能引起雪上加霜的. 于是,TCP引入 慢啟動 機制, 先發少量的資料, 探探路, 摸清當前的網路擁堵狀態, 再決定按照多大的速度傳輸資料,
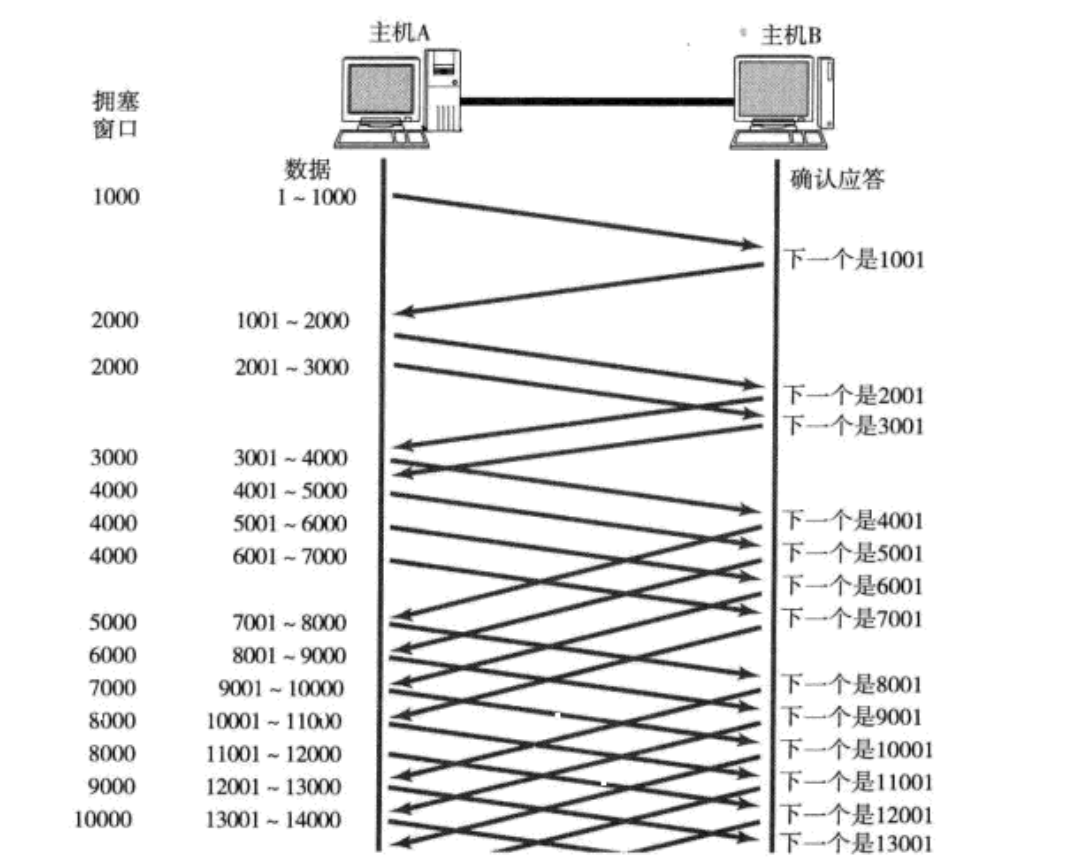
如上圖所示
- 發送開始的時候, 定義擁塞視窗大小為1;
- 每次收到一個ACK應答, 擁塞視窗加1;
- 每次發送資料包的時候, 將擁塞視窗和接收端主機反饋的視窗大小做比較, 取較小的值作為實際發送的視窗;
線增積減(和式增加,積式減少)
像上面這樣的擁塞視窗增長速度, 是指數級別的. “慢啟動” 只是指初使時慢, 但是增長速度非常快,具體的增長如下所示
? 剛開始的時候從1指數增長,到達閾值后開始線性增長,如果出現網路阻塞,直接減小到初始值,然后再次指數增長到達新的閾值(新閾值為上次阻塞視窗大小的一半),再次線性增長直到網路阻塞,一直這樣動態變換回圈,
5. 延遲應答
? 在之前的問題中我們提到,如果發送端發送資料后,接收資料的主機需要回傳ACK應答, 但這時候如果立刻回傳的話,視窗可能比較小(緩沖區的資料只處理了一部分),所以TCP中采用了延遲應答機制,舉個例子
? 現在有一個超市,里面賣泡面,假設庫房最多存盤100箱,隔段時間就有人來補貨,有一天早上,超市還有50箱泡面時,補貨的人來詢問,現在需要補多少箱泡面,這時最多補貨50箱(已經有50箱,庫房只能裝100箱),但是白天肯定會賣出去一部分,如果這時候補貨,第二天又要再次補貨,就太麻煩,
? 所以老板給補貨的人說,我晚上給你打電話,告訴你我要多少箱,那天白天賣出去了30箱,所以庫房只剩20箱,于是老板晚上給補貨的人打電話說,你明天給我補貨80箱~
上述例子中,老板晚上告訴補貨員的方式就相當于延遲應答,
那么所有的包都可以延遲應答么? 肯定也不是
數量限制: 每隔N個包就應答一次,(N一般為2)
時間限制: 超過最大延遲時間就應答一次,(時間一般為200 ms,必須小于超時重傳時間,不然就重傳了)
6. 捎帶應答
? 根據應用層協議,發送出去的訊息到達對端,對端進行處理之后,會回傳一個回執,即在很多情況下,客戶端服務器在應用層也是“一發一收”的,意味著客戶端給服務器說了“How are you”,服務器再給客戶端回傳ACK后,接著會給客戶端回一個“Fine,thank you”,在延時應答的基礎上,讓ACK等待一段時間(不能超過超時重發時間)后和“Fine,thank you”通過一個包同時發送,
? 另外接受資料以后如果立刻回傳資料,就無法實作捎帶應答,所以是在延遲應答的基礎上,才能進行的捎帶應答,延遲確認應該是能夠提高網路利用率從而降低計算機處理負荷的一種較優的處理機制,
就像之前提到的問題:四次揮手可以只揮手三次嗎?
在捎帶應答的情況下是可以的,當ACK延遲應答,就可能剛好與在資料緩沖區中的資料處理完后,與FIN合并,在一起發送,(相當于FIN捎帶上了ACK)
捎帶應答是指在同一個TCP包中即發送資料又發送確認應答的一種機制,由此,網路的利用率會提高,計算機的負荷也會減輕,不過,確認應答必須等到應用處理完資料并將作為回執的資料回傳為止,才能進行捎帶應答,
7. 粘包問題
TCP粘包是指發送方發送的若干包資料到接收方接收時粘成一包,從接識訓沖區看,后一包資料的頭緊接著前一包資料的尾,出現粘包現象的原因是多方面的,它既可能由發送方造成,也可能由接收方造成,
如果雙方建立連接,需要在連接后一段時間內發送不同結構資料,如連接后,有好幾種結構:
- “你好不好”
- “我很好”
那這樣的話,如果發送方連續發送這個兩個包出去,接收方一次接收可能會是"你好不好我很好"這樣對方可能就傻了,到底是好還是不好?
不知道,因為協議沒有規定這么詭異的字串,所以要處理把它分包,怎么分也需要雙方組織一個比較好的包結構
如何處理粘包問題?
- 方式1:在頭加一個資料長度之類的包
比如,上述例子改為 “4你好不好3我很好”
? 這樣就知道了,4就表示后面的資料內容應該是4個,3也類似,之前講過的TCP服務器的Content-length欄位就是這個作用
-
方式2:使用特殊標記來區分訊息間隔
比如,上述例子改為 “你好不好;我很好”
用**;當做兩個包的分隔符,之前講到的TCP服務器中,回應頭和回應體中間的回應空行**就是這個作用
8. 保活機制
TCP協議中有長連接和短連接之分,短連接環境下,資料互動完畢后,主動釋放連接;
雙方建立互動的連接,但是并不是一直存在資料互動,有些連接會在資料互動完畢后,主動釋放連接,而有些不會,那么在長時間無資料互動的時間段內,互動雙方都有可能出現掉電、死機、例外重啟,還是中間路由網路無故斷開、NAT超時等各種意外,
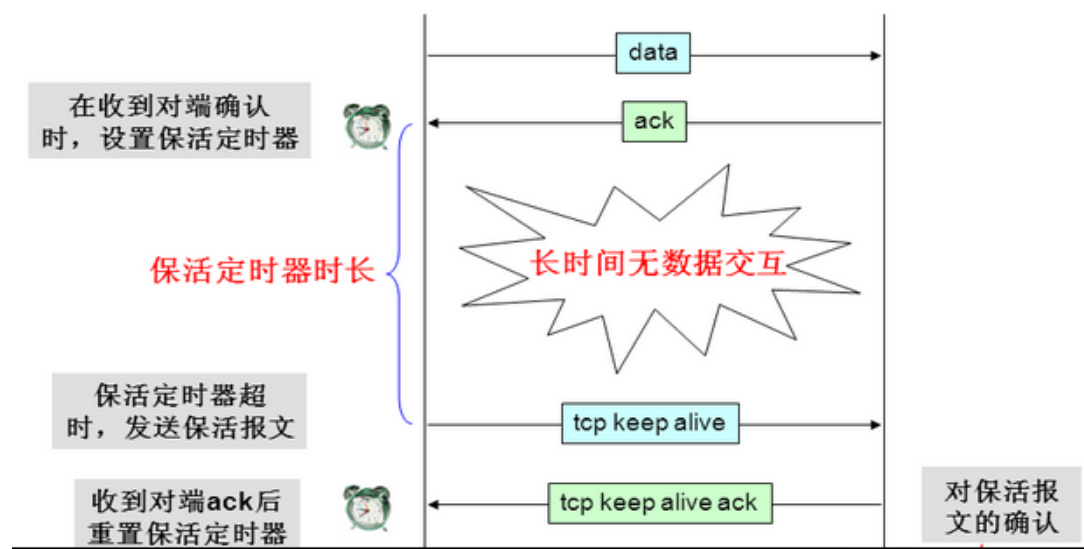
當這些意外發生之后,這些TCP連接并未來得及正常釋放,那么,連接的另一方并不知道對端的情況,它會一直維護這個連接,長時間的積累會導致非常多的半打開連接,造成端系統資源的消耗和浪費,為了解決這個問題,在傳輸層可以利用TCP的保活報文來實作,這就有了TCP的Keep-alive(保活探測)機制,
服務器或客戶端建立連接后,會按照一定時間間隔(保活定時器時長)發送一個“心跳包”,來保證對方還在線,如果對方長時間不在線就將斷開連接,如下所示
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/301926.html
標籤:其他