
作者:cmlchen,騰訊微信后臺開發工程師
最近某些代碼大倉的思想風靡整個 DevOps 圈子,這里的所謂大倉指的并不是倉庫的代碼容量達到多少 G,而是一種指導思想——就一個公司的代碼(如 Google)的增長趨勢,代碼的趨近于整合到一個單一的倉庫的,而非趨于分割為多個倉庫分開存盤的,但除了 Google、Microsoft 這些歷史悠久的公司實踐了大倉,其它的新興公司幾乎都沒有一個劃分倉庫的規則,
本文從微信后端的代碼倉儲方式的歷史說起,一步步的描述微信后端是如何構建一套真實可用的小倉方案的,并將這樣一種分倉的方法分享出來,希望實踐微服務的同事們有所幫助,
其實或許不應該使用小倉這個詞來描述當前微信后端的代碼組織方式,就占用空間而言,微信后端的某些倉庫從體積上來說并不算得上是小 ,微信支付后端的舊代碼倉庫專案截止 2021-08-23 已使用了超過 2T 的存盤空間,這里使用小倉這個詞匯實際上對應英語中的 multirepo 或 polyrepo,也就是相對于單倉 monorepo 概念中的多倉,
本文中所描述的倉庫的大小劃分并不是按照其占用空間劃分,而是提供一種劃分代碼倉庫的思想:
代碼倉庫應該是被合理劃分的,而非全公司共用的一個 repo(對應 monorepo)
代碼倉庫的劃分應該是有標準的(對應下文的一致性 )
代碼倉庫所使用的工具鏈應該不和代碼的組織結構強相關,甚至不應該和版本管理工具強耦合
小倉應該是一個完整的包含代碼的完整構建單元,包括但不限于實作代碼、單元測驗用例、自動生成的代碼報告(如覆寫率、用例執行結果)、代碼相關的說明檔案(README.md)、構建組態檔(BUILD、package.json 等)
本文將從微信后端的代碼倉庫的發展歷史開始,逐個分析微信后端代碼的演化程序,試圖從大倉逐漸分解成小倉的歷史行程來解構小倉研發流程的客觀規律,并最終提出小倉的整體解決方案,歡迎提出任何理性的討論和建議,
1 微信后端代碼倉庫發展史
以人為鑒可以知得失,以史為鑒可以知興替,
了解微信后端的開發都知道,微信這個專案啟動的非常偶然,微信最初來源于廣州研發部的一個創意,微信后端天生就繼承了 QQ 郵箱非常多的代碼,你仔細研究代碼就會發現,在很多部署的路徑中都是用了 QQMail 這樣的 hardcode(當然現在并不推薦這樣做),這里就來先回顧一下后端代碼倉庫的發展歷史,
1.1 單一svn倉時代 (2011~2013)
最開始的年代微信后臺是直接復制了一份郵箱的代碼然后在上面修改的,當時的微信后端代碼是一個單倉其中的代碼示意結構如下,

大部分的代碼都是原封不動的從 QQ 郵箱復制過來,只是創建一個新的 svn 倉庫用于撰寫業務代碼,可是由于業務的快速發展,代碼的管理也處出現了一些不和諧的音符,
剛開始大家都只把代碼倉庫當成一個放東西的地方,甚至是有些正式資料都放在了倉庫上;
公眾平臺專案隨后大爆發,某些不屬于微信基礎后端的代碼(如公共平臺的代碼)也被放置到此倉庫下,但新增的微信基礎團隊卻不應該有權限能看到到公眾平臺的代碼;
由于是基于 SVN 的大倉模式存盤代碼,導致核心倉庫的代碼權限審批特別復雜,只有非常少數的人有通用公共組件、通用后端框架的權限,導致有理想的新人非常難對基礎庫貢獻代碼,無奈之下只能將一些業務的公共庫被放置在業務代碼下,而這些公共函式最后又被吸收到公共組件檔案夾中,以至于代碼重復;
新人并不是不想共享代碼,而是疲于各種流程的審批、代碼倉庫權限的扯皮,最終這些流程打消的他們的積極性,同時他又不希望自己業務卡住不上線,所以只能找一個自己有權限放代碼的地方,最終導致代碼結構的混亂,而這也正是大倉非常難解決的難題,大倉的權限控制是集中的,在集中的檔案夾審批程序中,有理想的開發者壓根就不肯讓出自己寶貴的時間和權限的審批人員相互扯皮;
導致代碼重復的根本原因不是胡亂放置的第三方庫,而是散落在業務代碼倉庫的各種公共邏輯的私有化實作,
由于沒有統一構建系統,變更一個微服務的基本流程是野蠻的,
在本機除錯好代碼后上傳到 svn;
在一臺專用的編譯機上更新 svn;
使用魔改版的 blade 編譯 release 版本的二進制;
如果要發配置、前端頁面模板,需要手動將文本檔案
scp到編譯機上(當然你也可以把開發版本的二進制直接scp到編譯機上,省掉1,2,3);去微信運維門戶提交發布單,告訴發布系統需要更新那些檔案,需要重啟那些服務;
微信運維門戶發布到預發布環境;
灰度→全量上線,
單元測驗全憑自覺,上線前也不會跑 cc_test,所以不寫單元測驗也沒關系,就是這么野蠻,
1.2 拆分svn時代 (2013~2018)
隨著業務的成長,在單一 svn 倉庫逐漸不滿足的業務的開發了,2013 年左右逐漸開始將非微信基礎核心的業務部門的代碼,從 MicroMsg_proj 倉拆出去,各個業務團隊如微信支付、開放平臺基礎部、開放平臺業務部、微信游戲等都有了自己的倉庫,由于 svn 可以檢出子目錄,且可以通過目錄來設定權限,代碼庫的目錄劃分開始和組織架構掛鉤,
當時編譯機的目錄結構不再是映射單一的倉庫,而是第一級映射的是某個倉庫的 trunk 目錄下的子目錄,例如開放平臺創新部的作業區目錄是:

所有的一級子目錄都對應 svn 的一個子目錄,不同子目錄的權限由各個業務方維護,比如微信基礎(廣州)負責維護基礎框架和微信底層通信代碼,開放平臺基礎部(廣州)負責維護維護開放平臺的業務代碼,開放平臺業務部(深圳)負責維護搖一搖電視 ibeacon wifi 游戲等創新專案,微信支付(廣深)負責維護支付底層業務代碼,
此時實際上微信后端已經從 monorepo(單倉)走向了 multirepo(多倉)模式,
同時為了解決越來越多的依賴混亂的問題,廣研在后端微服務工具鏈中增加了對依賴的強制校驗,并規定:
基礎組件中的定義的 Protobuf 源檔案可以被所有的目錄依賴;
部門的對外服務,其中的 Protobuf 定義的結構可以被其他所有非基礎組件依賴,例如,創新業務內部服務可以依賴微信支付對外服務、開放平臺后端對外服務下的定義的結構;
非對外服務的只能依賴本部門對應的私有倉的微服務和其他對外的服務定義的結構,比如創新業務對外服務可以依賴創新業務內部服務、開放平臺對外服務但不能依賴開放平臺內部服務和微信內部服務,
每一個專案組都有獨立的編譯機,在這個編譯機上會有多個編譯賬戶用來管理編譯作業區(這個編譯賬戶在后面的統一編譯也會用到),有了不同的編譯賬戶就從編譯機上解決了某些代碼禁止依賴的問題,
微信支付編譯賬戶不會拉取微信后端內部服務、開放平臺后端內部服務、創新部內部服務的代碼,所以在微信支付的編譯賬戶下,編譯腳本如果分析出有微信后端內部服務、開放平臺后端內部服務、創新部內部服務下的依賴,就會提示路徑不存在(注意此時 bazel 還沒有開源,也沒有在包管理的概念);
通用框架使用的賬戶不能拉取任何業務代碼的倉庫,所以基礎庫的如果依賴了某個業務代碼將不會編譯通過;
以上規則只在編譯機上生效,如果你是在開發機,還是可以編譯通過的,這也就是為什么現在依然存在某些單元測驗編譯目標依賴混亂的問題,因為這些單元測驗并不需要在編譯機上編譯,
正是有了不同的編譯賬戶和各個部門不同的編譯機,使得不同業務部門之間有了高度的獨立性,高度受政策管控的微信支付業務可以使用穩定版本的基礎庫,而激進的開放平臺創新部以及后來的游戲中心卻非常樂于體驗帶新特性但不那么穩定的基礎庫框架的版本,而這樣的選擇是由于業務的迭代特性的自發的選擇,并非由某位大佬自上而下的強制推行,
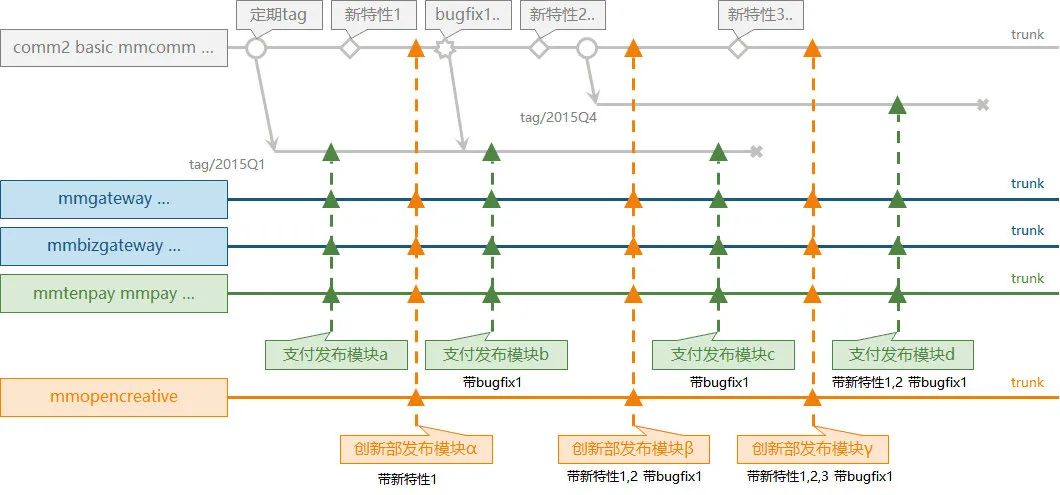
1.3 遷移git時代(2018~2020)
2018 年到 2019 年公司啟動倉庫由 svn 到 git 的程序,公司的出發點非常好,不強制業務選擇遷移的方案,廣研團隊和微信支付團隊分別提出了兩種不同的方案,廣研的方案比較粗暴直接:
將以前的編譯作業區各個一級檔案夾直接創建對應的 git 倉庫;
將代碼直接從 svn 遷移到 git,之后再考慮怎么拆;
第三方公共庫全部收斂到專用倉庫,但倉庫并不直接對應代碼,而是軟鏈到與開源倉庫對應的 Fork 倉庫路徑中,這樣保持代碼兼容性問題;
對于不同專案團隊會分配不同的工蜂(騰訊內部 git 管理平臺,類似于 gitlab 的私有化定制版)專案組,

此時的后端編譯倉庫不再是扁平的二級結構,而是樹形結構,每個節點都和一個 GIT 倉庫對應,這樣做的好處非常明顯:
后端的代碼作業區的結構和組織架構解耦,根據功能來劃分,以前需要增加一個第三方庫,需要到處求爺爺告奶奶,求廣研基礎部在自己管理倉庫
mm3rd下增加,到時候出了事,責任難界定;統一管理第三方庫,第三方庫統一收歸到
mm3rd2下,完全是一個開發協作的思想,你增加了第三方庫掛載到伏羲平臺中,自己的編譯賬戶就可以使用了,再也不需要自己硬復制檔案到自己的目錄下了;編譯依賴和庫版本解耦,曾經使用 bazel 寫依賴項需要帶上版本號,svn 時代都是大一統的單倉,根本沒辦法對依賴項統一規劃,某些時候不得不寫成
//mm3rd/boost-1.66:regex這樣奇葩的寫法,如果其包含的次級依賴中又依賴了//mm3rd/boost-target:regex,就會存在符號沖突,現在統一寫成//mm3rd/boost-target:regex即可,而使用不同的編譯賬戶,就可以完美的切換不同版本的第三方庫;公共組件可以及時共享協作了,新增的
mmcontrib非常開放的將所有想為 WXG 后端建設的成員開放,并集成到統一編譯中,并使用了專用的編譯賬戶以保證不能依賴業務倉庫中的代碼,代碼倉庫專案組和前后端構建系統解耦,越來越多的專案采用工蜂專案組的形式來管理,比如一個專案中同時存在前端、客戶端、小程式、后端不同的倉庫,以前這些代碼都需要被粗暴的拉到本地,但對于微信后端代碼的構建系統來說,客戶端、小程式、前端等并不需要被看到,現在只有那些需要被微信后端構建系統構建的代碼才會被檢出,
遷移到 git 后,廣研基礎團隊提出了改進 GitFlow 的作業流模式,
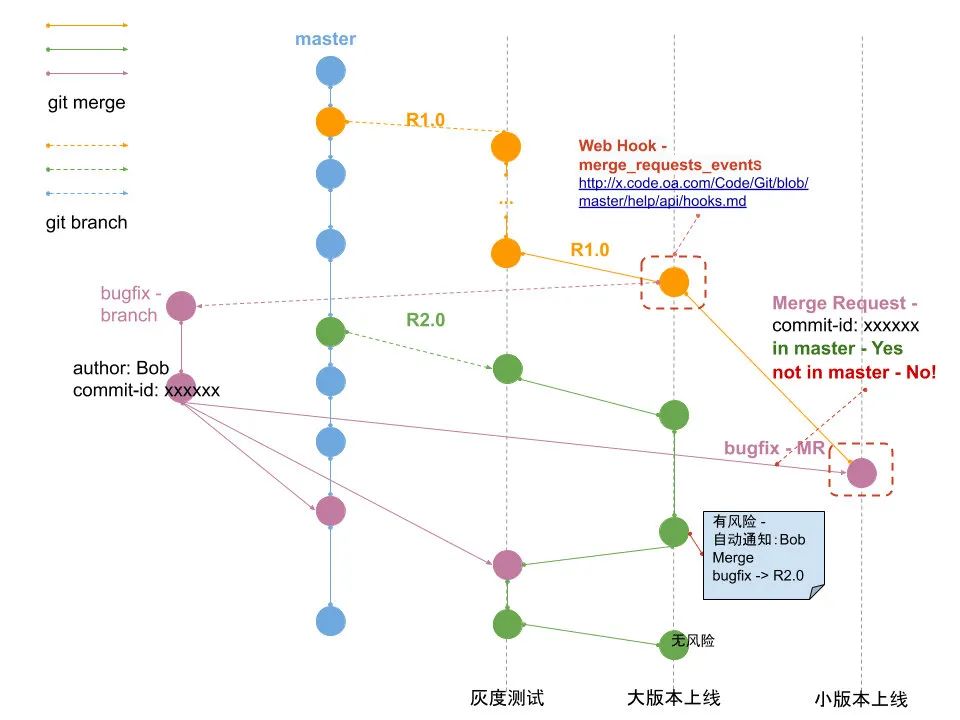
然而技術架構部所管理的 comm2 基礎庫使用了主干開發模式,
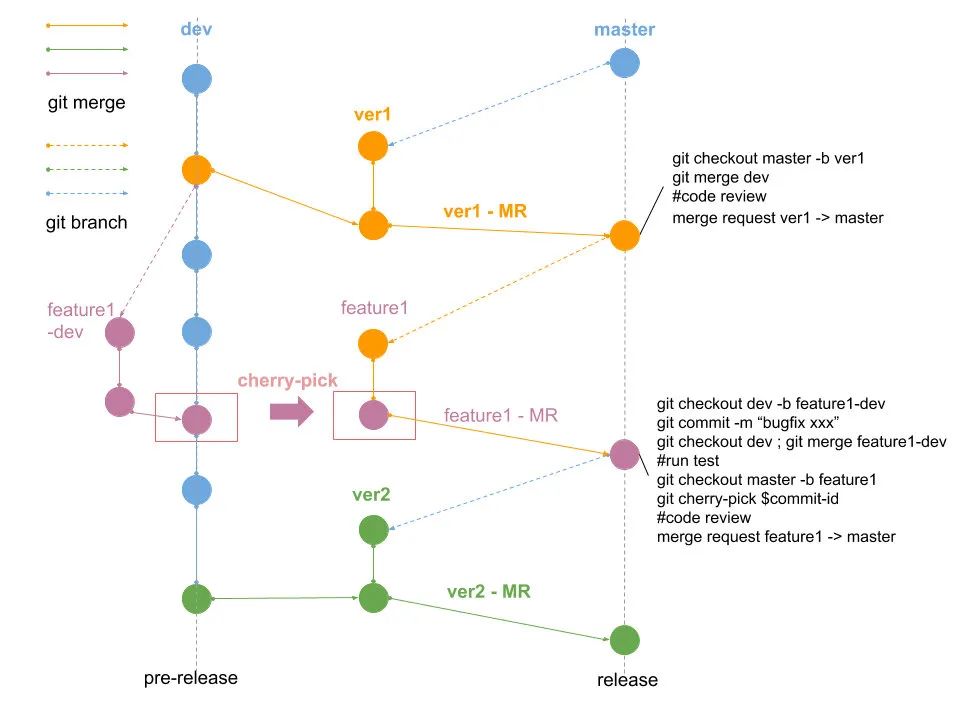
技術架構部提供了 PreMaster 分支給業務方使用,PreMaster 分支的特性要優先于 master,有些業務方和基礎架構部共建的特性會優先讓業務方使用,穩定運行過一段時間后,PreMaster 會合并到 master,之后 PreMaster 的特性就會應用到所有 WXG 后端服務代碼中,
1.4 根據領域驅動拆分小倉(微信支付整潔 git) (2020~現在)
在遷移到 git 時引出了另外的問題,如何劃分工蜂專案組?工蜂專案需要由什么樣的規則來管理呢?
微信基礎部也曾經遇到這樣的問題,當時只是僅僅通過行政組織架構來對應檔案夾,最終導致了依賴混亂,代碼耦合嚴重等問,
基于這樣的問題,支付團隊決定進一步將代碼倉庫拆小,在遷移 GIT 的程序時,支付提出了整潔 GIT的方案,

整潔 GIT 定義了一系列的使用規范,
位置約定
業務模塊路徑與領域邊界、模塊分類對齊,模塊路徑:系統、子域、模塊功能分類(gateway|application|domain)、模塊;
模塊公共代碼與模塊私有代碼分離,公共代碼包括:可以被其它模塊依賴的部分,組件api、錯誤碼、proto代碼、client代碼、以及用于公共使用而封裝業務基礎代碼;
業務模塊與組件分離,
依賴約束
只能依賴公共代碼不能依賴其他領域的私有代碼,編譯時檢測,依賴非自身外的私有代碼,編譯失敗;
跨專案組的業務代碼不能通過 lib 依賴,只能通過
service_export_gen或mmpay_service_export依賴,
接管服務契約
proto 檔案由專門的契約管理系統管理,結構化編輯、線上契約沖突檢查;
編輯完成后由 CI 工具生成 client 代碼推送到
service_export_gen代碼倉庫;service_export_gen除機器人外沒有任何人權限,
一站式管理
通過 API 訪問整潔 GIT 代碼樹;
使用契約系統持續集成統一生成服務 client 的代碼,禁止在 client 自己撰寫邏輯,
這樣有計劃的一致的拆分方案解決了使用大倉的一系列問題,
權限獨立
svn 中通過組織架構和檔案夾權限對應,一旦組織架構調整,檔案夾而又不可能隨著組織架構一起調整,最終導致撰寫代碼混亂;
整潔 GIT 將代碼通過業務系統拆分,同時工蜂可以將組織架構動態系結到專案組或專案中,當組織結構有變動時,可以非常的方便的調整權限,
持續集成
整潔 GIT 使用 CI 工具收斂了變更最多、協同最多的服務契約,者將會使得因為服務契約協同開發而導致的拉分支狀況相當少,只要在契約系統中完成契約編輯,會自動將契約轉化成
client.hclient.cpp并放置到對應的專用倉庫中;不同專案組由于業務性質不同,可以采用不同的 CI 策略,如基礎支付的產品生死攸關,必須添加單元測驗流水線,代碼覆寫率超過 80%,才能被合入主干發布;而行業運營開發組專案大多數實驗性專案,產品的生命周期很短,并不要求完美的單元測驗,只需要保證代碼基本的風格統一即可,
作業流優化
由于將代碼倉庫拆小,所有的發布關聯和問題集成都可以在工蜂中完成,特別是做基礎組件的團隊,已經非常熟悉 GitHub 一套 MR 流程,工蜂的使用效能達到最大化,而大倉除了提供一堆 99+ 的數字、無數五顏六色的 label 毫無利用價值,最終榷訓成帶歷史記錄的超大檔案系統;
各個編譯系統可以根據不同的編譯產物進行構建,自由組合虛擬的編譯作業區,而不是像無頭蒼蠅一樣把所有的代碼都拉取下來,例如:編譯后端代碼,只需要拉取編譯賬戶下的后端代碼倉庫,忽略掉專案組中其他的例如前端、小程式、私有組件倉庫,同時,若使用前端構建方案,則只需要檢出一個單獨的前端倉庫即可;
由于依賴的清晰化,從構建工具開始就對一些無效的依賴限制,如根據領域驅動設計來確定某些依賴項需要被斬斷,
代碼倉庫一直都是伴隨著開發一生繞不開的話題,隨著業務的膨脹,代碼倉庫也會一天天變的巨大,無論大倉還是小倉,都必須是在業務的發展中經得起檢驗的,而回顧這微信發展的 10 年,團隊也一直通過實踐的方式優化代碼倉庫的合理使用,并在使用程序中結合了軟體方法、領域驅動建模等非倉庫的理論來實踐,一步一步的發現問題解決問題,而并不是一開始就弄一個超大的概念,制定超過模糊的強規則讓眾多開發屈服,只有同時讓開發用的爽(提升研發效能)讓老板滿意(滿足組織上一致性)的方案才是最優秀可行的解決方案,
2 小倉的優秀實踐(效能篇)
某研發:你的方案怎么好,你來寫啊,別光說不做
首先需要承認一點的是,對于效能工具團隊,廣大的一執行緒式員就是最好的調研目標,讓他們開發起來爽,他們就更加有干勁的產出,同時要保證服務質量,就是我們存在的價值,如果弄一堆空中樓閣式的自研工具,搞一套業界差別很大的理論,讓開發人員疲于奔波和學習某深奧些理論知識,招來的不僅是一線業務團隊的拒絕合作,更會嚴重拖慢業務精益迭代的目標,
2.1 全域代碼搜索
由于使用了小倉和虛擬作業區的方法來處理各個開發機后端代碼,在每位開發本機開發或遠程編譯時,并不需要耗費非常長的時間把所有的代碼都下載到本機,只需要檢出自己有權限的倉庫(如果你使用遠程編譯,甚至是你當前開發專案的倉庫),
此時如果需要查詢某個符號的參考,如果在本機搜索當前作業區的副本顯然是不現實的(特別是后端代碼),如果直接使用全文搜索,不僅效率低,而且還費時,搜索的結果也差強人意(不能使用語意的搜索,按照符號型別搜索等),這里時候就有必要構建一個在線的準實時的全域代碼搜索門戶,
無論是使用 OpenGrok 還是使用 [Mozilla DXR](Overview — DXR 2.0 documentation) 都是非常成熟的解決方案,但這樣的解決方案都是基于單機目錄設計的,如果一個超級大倉都不能在一臺機器上被檢出,那幾乎無法簡單的做出一個非常好用的代碼搜索門戶,
微信后端團隊在 2013年左右就部署了一套基于 OpenGrok 的代碼搜索工具,當時的微信后端的倉庫比較小,一套門戶就適用所有的微信后端的開發,但隨著編譯賬戶的增多,代碼庫的數量也在增加慢慢一臺單機已完全不滿足所有微信后端代碼倉庫的搜索了,
基于這樣的特點,微信技術架構部開始使用不同賬戶分治的構建代碼搜索門戶,并使用了更強大的 [Mozilla DXR](Overview — DXR 2.0 documentation) 方案,這樣使得微信基礎團隊不用再去關心支付的業務代碼,微信基礎訊息收發的代碼也不必在支付團隊的成員中顯示,
大倉的支持者會想當然的會認為做搜索是不是直接弄一個超大倉做一個類似 Google 的搜索頁是不是更好呢,這個問題我們就需要回到最初的一線開發者愿景(Want)上來分析,
那一線開發到底是怎么來看待這個問題的呢?
我們需要一個快速搜索代碼符號的門戶;
我們只關心我自己寫的或依賴的代碼的符號;
當出現符號錯誤或鏈接錯誤時,我希望可以快速定位到依賴的關鍵;
前端開發者通常不太需要全域代碼搜索,因為使用
npm install之后所有的代碼依賴都會下載到本機,通過 IDE 搜索比一個單獨的搜索門戶來的方便,若想搜索開源組件,直接使用開源社區即可;依賴的第三方庫也不會在代碼庫中搜索,因為 Google、Stack Overflow 或 GitHub 已經可以提供足夠多的解決方案;
微服務的服務契約,有專門的門戶管理(管理兼容、輸入輸出請求、靜態規則校驗、回傳資訊等),也不應該直接在代碼庫中搜索中間代碼;
C# / Java 開發者也通常不需要全域代碼搜索,因為 IDE 內置的物件瀏覽器已經可以滿足各種搜索需求,而且還支持快速跳轉,查看實作,
所以全域代碼搜索這個需求服務的目標人群是:具有超大規模的后端編譯需求的開發們,
這樣看起來將后端編譯的作業區,作為搜索的資料源來分析是最合適不過了,如果整個 WXG 是一個大倉,或者全公司是一個大倉那么想這樣簡單做一個搜索專案出來就非常困難,
搜索出非常多的 fork 倉庫的代碼,這些代碼根本就不會在微信的編譯系統下使用,只是徒增篩選成本;
搜索到一些非代碼包括學習筆記之類的不想關心的內容;
想搜索符號或宣告,卻搜索出一堆注釋之類無關的代碼;
私有倉的代碼無法搜索,可惜 WXG 基礎部的核心代碼都是私有倉,只對 WXG 開放;
雖然搜索的速度很快,但篩選的成本相當高,你需要精通了解大倉的每個檔案夾是怎么放置的,才能精確搜索到自己關心的代碼,
2.2 第三方開源庫治理
小倉的方案被很多人詬病的原因是依賴混亂,很多開發使用第三方庫直接就在自己的倉庫的檔案夾下復制一份代碼,最終造成整個編譯作業區很多重復的開源庫,然后就有人提出使用大倉來統一管理開源的三方庫,
在單一 svn 倉時代微信后端編譯作業區也確實會遇到這樣的問題,因為在大倉時代檔案夾的權限和組織結構強系結,掌握 mm3rd 的開發者不愿意為其他開發者將第三方庫引入到編譯作業區中,因為 mm3rd 的開發者通常是最先創建倉庫的人,而非專職處理人員,通常情況下這些開發者會認為引入第三方庫會引入風險,故會對需求方的建議推諉、拖延、甚至拒絕執行,而需求方迫于業務時間上的壓力,不得不將庫粗暴的直接拷貝到自己有權限的檔案夾下,最終造成第三方庫參考混亂的問題,事實上正是因為大倉耦合了太多功能,才導致第三方開源庫治理的混亂,大倉耦合了組織架構權限、構建系統、代碼檢查規范等,導致某些時候不得不為了非存盤代碼的目標,而一定要將第三方開源庫引入到庫中,
在以靜態語言為基礎的構建系統中,這個問題會出現的尤為突出,而且會引起鏈接問題從而阻塞業務上線流程,例如,下圖中的 svrkit 框架升級到 v1.1 后,業務代碼將無法鏈接通過,因為 libboost-1.66 和 libboost-1.55 的符號有沖突,
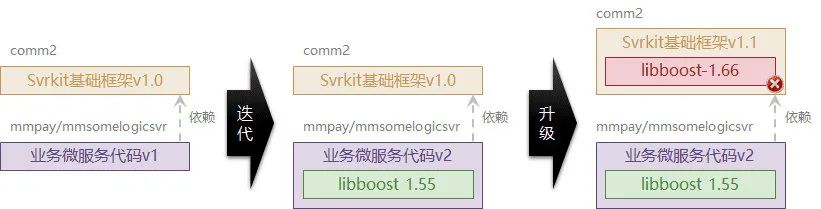
大倉的擁護者們提供了一個非常理想的方案,將所有的依賴都扁平化放置到一個專用的檔案夾下,并收歸這個檔案夾的權限給專有人員統一管理,貌似一定程度上解決了開源庫治理的問題,

此時在升級程序中只需要將業務代碼中不兼容的升級修改掉就解決了,大倉的擁護者們興奮的表示自己解決了世紀性依賴地域的難題,但從倉庫和構建系統角度來看,這些開源庫的代碼根本就不應該放置在大倉的某個檔案夾中,而應該是只和編譯系統相關,無論是 git 的 sub_module 還是 npm 的 package.json 都是通過宣告的方式將這些第三方庫臨時的添加到構建個作業區中,所以只需要在編譯或構建時將其參考出來,組成一個臨時的構建作業區滿足構建的需求,而并不需要費心費力費事的把這些第三方庫的代碼整體搬移到大倉中,
公司的工蜂小組強力推薦使用 git 和開源界對標,我們也調整了自己的構建作業區的環境來適配這樣的改變,比起使用 svn 來配置權限的,git 管理起來更加靈活而且通過不同的編譯賬戶,即可靈活的組織編譯依賴,

比起使用大倉單獨檔案夾來管理第三方依賴,使用虛擬檔案夾對應社區的完整的 git 的倉庫的好處是顯而易見的,
后端代碼也可以像前端代碼有良性互動,后端代碼中第三方倉庫由 GitHub Fork 而來,所有會保留以往的提交記錄,有想法的同學可以將自己貢獻的代碼 cherry-pick 到開源社區的倉庫中;
由于 mm3rd2 是一個虛擬的目錄,里面的第三方庫只是類似掛載的機制參考進來,第三方庫中所有的測驗、檔案、代碼都是完整的不可分割的,我們在貢獻代碼時也必須按照第三方庫的規范保持風格,如果使用公司級單倉,勢必會按照公司單倉的風格執行,屆時將形成完全不同風格的代碼,第三方庫作為一個完整倉庫的完整性遭到破壞;
伏羲平臺管理的統一編譯的代碼倉庫的虛擬檔案夾的映射表,這是一個開放的平臺,任何 WXG 參與開放的同學都可以將自己覺得需要的第三方庫掛載到統一編譯系統中,不過對于一些專門敏感的庫,如(openssl 總是會修復一些漏洞)會有專人運營,督促開發修復漏洞,而正是因為將這些第三方庫統一管理起來,使得我們修復漏洞時非常容易,重新編譯一下即可,(若是使用 wxmesh 架構的微服務,只需要更新 mesh Sidecar 即可,業務代碼無感),
2.3 統一編譯 伏羲平臺
其實相對于其他 BG,微信后端相比較是比較幸運的,我們一開始就站在了巨人的肩膀上,早在 2012 年就引入了 blade 后端構建系統,統一的編譯系統解決了 C++ 在編譯方面引起的巨大依賴問題,尤其是對于 C++ 缺乏完整的好用的包管理系統,早在 2014 年就推廣使用的發布平臺,統一了后端服務的發布流程,抓住了微服務的生產和發布兩個一致性的大頭,掃清了我們在流程一致性中的障礙,
但隨著代碼庫越來越多,comm2 basic mmcomm 等基礎庫變更越來越頻繁,越來越多的開發在本機開發需要頻繁的更新相關依賴,而且正是由于根深蒂固的單倉思想,開發者習慣于將整個編譯作業區都檢出到個人開發機上,但卻發現這樣做的收益是非常低的,因為撰寫一個微服務所需要提交的代碼相比基礎框架和依賴項是非常少的,
于是我們研究出了 patchbuild 統一編譯,patch 是指把只需要提交到編譯系統的部分通過補丁的方式提交到遠端,build 指這些提交補丁的行為是用于構建二進制產物,于是統一編譯系統提供了一套命令列工具給開發使用,其目的是希望用統一編譯取代開發機的本地編譯,實作本地開發,云端編譯[^8],
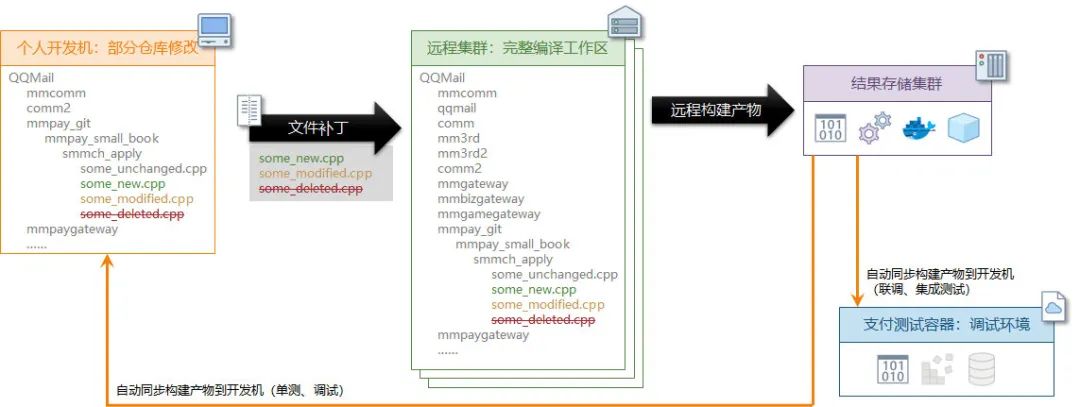
一個普通開發除錯一個服務直接走下面的流程即可
在本機的要開發的小倉中創建一個分支(特性分支、個人分支、修復分支)
撰寫代碼,將需要統一編譯的資源添加到 git 暫存區(cpp/h 等源代碼不需要添加,會自動識別)
使用
patchbuild build :build_target來編譯目標可以指定將編譯結果同和中間檔案(*.pb.h / *.pb.cc 之類)同步到本機
可以指定傳送編譯后傳送目標,傳送到預發布環境
可以指定編譯后打包 docker 鏡像并發布到微信測驗環境
可以指定編譯后傳送到微信支付個人除錯容器(資料和介面完全和正式環境隔離)
在本機使用 XTP 工具除錯開發機本機服務或遠程服務
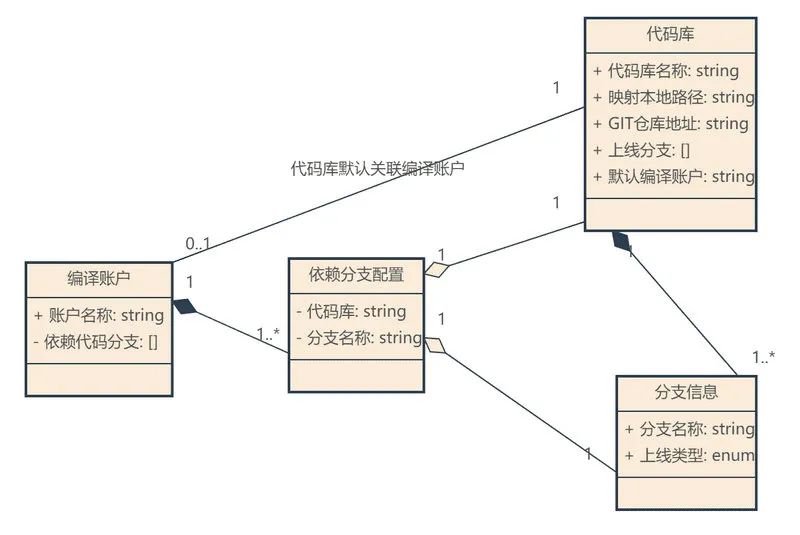
在伏羲平臺中維護了一套編譯賬戶和代碼庫的資訊,通過一套門戶來決定某位開發者在當前的目錄應該使用哪個編譯賬戶來統一編譯,管理者也可以通過這個網站來查看每日構建的使用情況,統計慢速編譯和快取使用情況,
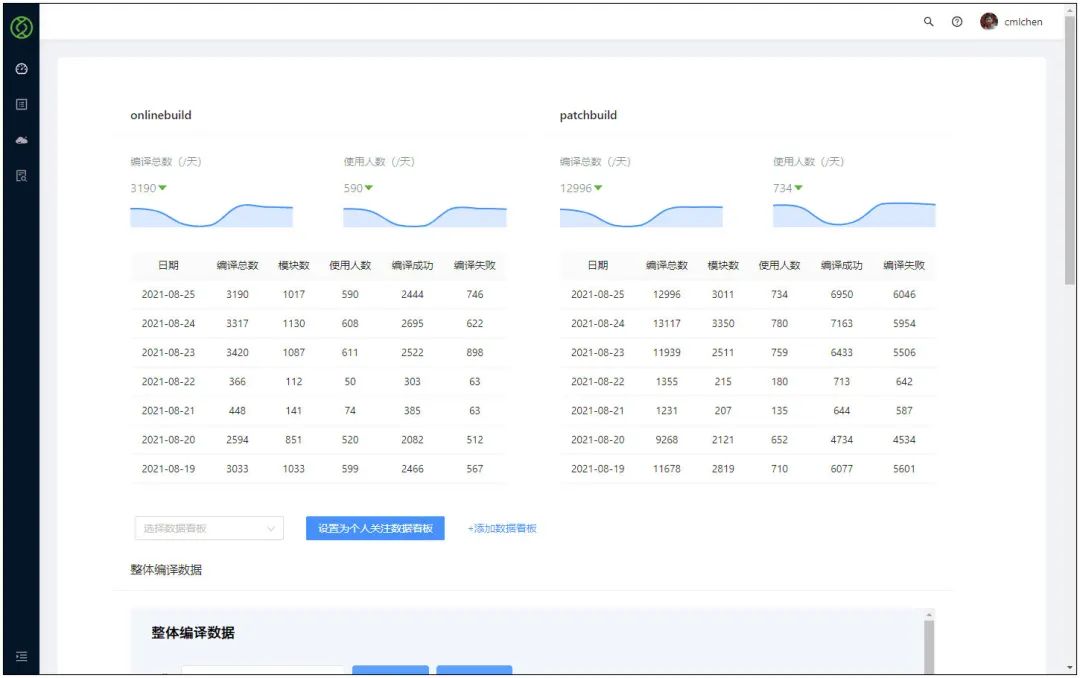
統一編譯對于開發測驗的時的工具叫 patchbuild,正式上線的工具是 onlinebuild,其中 onlinebuild 不對普通開發直接開放,而必須使用 p6n、微信上線平臺通過網頁操作,這樣就保證了只有特定的分支(master/PreMaster)才能上線到正式環境,
試想一下,如果使用大倉來管理所有微信后端的代碼,將會帶來非常多的問題,
需要把所有代碼都檢出到本機,消耗大量的時間,魔改版的工具的成本又相當高;
因為大倉的設計導致無論多么小的改動的提交都會創建一個整套倉的分支,現在已經有
mmtenpaymmbiz這樣的比較大的倉庫,已經無法使用 git 來管理和跟蹤 issue,上千個開發分支導致 git 完全成為一個超大的檔案存盤系統;超級大倉在計算 diff 時將消耗非常大的時間,云端編譯甚至可能將一些不需要的中間產物一起打包;
超級大倉在遠端編譯時拉取倉的時間會非常長,因為分支的數目眾多,使得非常小的改動就會要更新整個倉庫,大多數情況下這樣會導致 bazel 計算依賴路徑失效,頻繁的切換不同分支的源代碼,
無論大倉還是小倉,能夠服務于一線業務開發的倉就是好倉,騰訊公司作為一個超大體量的公司,從組織上說如果不能服務好他們,影響的不僅僅只是核心技術團隊的口碑,更還會影響公司業務的發展,整個微信后端也不是一開始就確定使用大倉或小倉的,還是在不斷的業務發展中優先為一線開發提供研發效能的解決方案,然后再從方案中提煉出合適自己團隊業務的方案的,
3 小倉的優秀實踐(一致性篇)
首先必須承認一點大倉在一致性方面確實有獨特的優勢——你離開了倉庫就不能寫代碼了,不能寫代碼了哪兒來的方式發布,特別是對于后端服務來說,使用大倉似乎是可以堵住胡亂發布、胡亂寫代碼的一種簡單粗暴的方式,但我們認為眾多小倉如果管理得當,一樣可以做到可規模化,也一樣可以做主干發布,這些優勢并不能成為使用大倉的理由,
3.1 切換后端構建系統
微信后端編譯系統于 2017 年將魔改版的 blade 切換到 bazel 構建工具,blade 實際上是一個 scons 腳本的生成工具,當我們通過命令列呼叫 blade 的,blade會根據所需要編譯的 target 通過 python eval 的方式加載本次編譯所需要用到的 BUILD 檔案,BUILD 檔案加載完成之后,blade 會根據 BUILD 檔案當中所宣告的target依賴關系和源檔案串列生成一個 scons 的宣告檔案,bazel 和 blade 一個最大的不同的地方就在于,bazel 在處理依賴關系的時候并不區分 targe t級別和檔案級別,也就是說在加載 BUILD 檔案的程序當中 bazel 是直接計算檔案之間的依賴,這使得 bazel 不需要等待整個編譯依賴圖全部都加載完成之后再開始執行編譯動作,
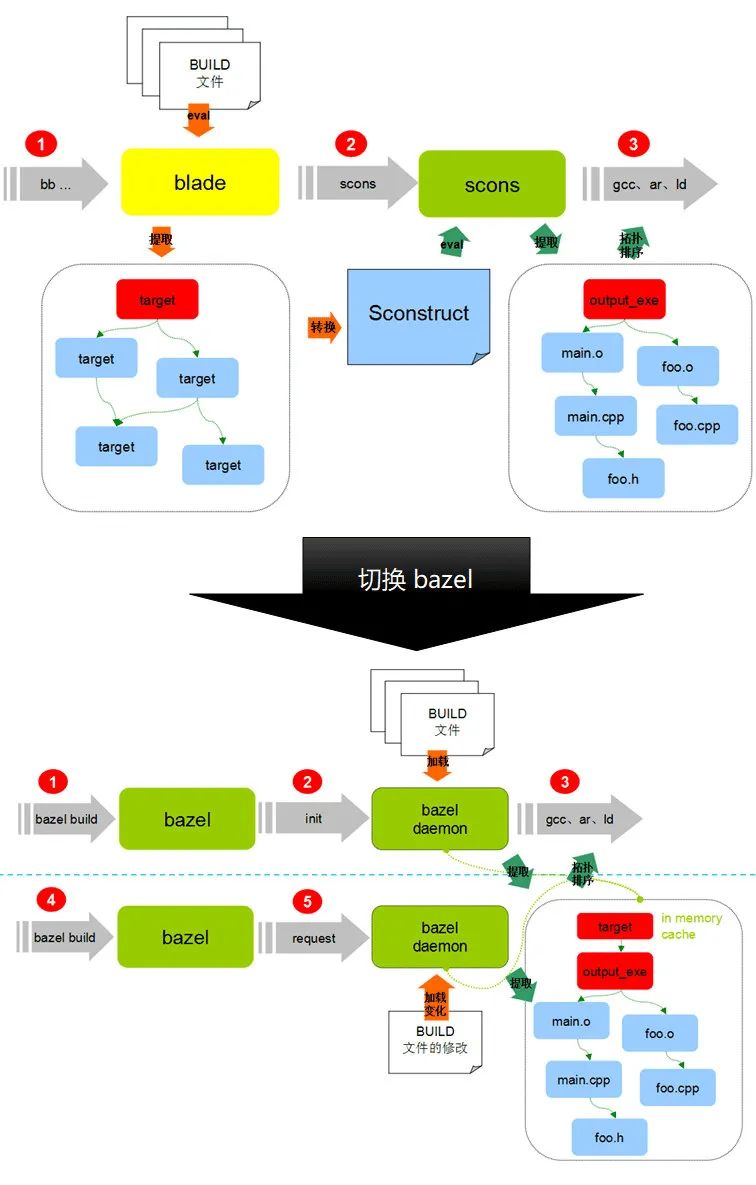
切換整個 WXG 后端編譯系統到 bazel 是一件收益很大,但困難重重的事情,但在遙遠的 2017 年代,WXG 的代碼倉庫還是使用 SVN 的多倉模式,這導致如果要切換構建工具,必須整個倉庫的遷移,而在業務快速迭代的同時,你根本就不知道遷移工具是否有 BUG,當時遷移的工程師提供了一個 blade2bazel 的轉換工具,并制定了一套遷移方案,整個遷移涉及到所有 WXG 后端開發,
升級后端構建工具魔改版的 blade,繼續魔改,如果發現有
BUILD_OF_BLADE就使用此檔案,否則就還是使用BUILD;提供
blade2bazel工具,嘗試通過工具將 blade 版本BUILD轉換為 bazel 版的BUILD,備份原有的檔案為BUILD_OF_BLADE;通過每日構建找到不兼容 bazel 的
BUILD檔案或無法轉換的檔案,提示開發根據指引修改;開發需要在一段時間持續維護
BUILD和BUILD_OF_BLADE兩個構建腳本;逐個 repo 遷移構建工具,直到所有的 repo 都遷移完畢,廢除 blade,
當時所有的開發都秉承一種思想“所有的技術升級都不能阻塞業務的開發”,在 WXG 里面最重要的思想就是灰度、平滑升級、業務無感(此思想也適用于效能團隊),
也正是當時微信后端都啟用分倉的模式,使得推進這行程沒有那么痛苦,
初期可以拿小倉庫來試點,搜集反饋,打磨方案;
工具鏈的倉庫可以使用不同的分支來開發,小范圍試點時,在構建系統中合理配置編譯賬戶的倉庫配置,即可使得不同倉庫的構建系統的升級切換平滑;
當試點一段時間方案成熟時,只需要調整對應編譯賬戶的構建工具倉的分支,即可對其他倉庫應用新的構建工具;
整個調整在陣痛時期都是可灰度可回退的,倉庫足夠小就能保證灰度和回退的粒度,當然某些大倉的擁護者會提出質疑說大倉分檔案夾也可以做這樣的事情,誠然分檔案夾也可以這么做,但你會讓每一次依賴聯都創建一個分支么,還是正如一些激進分子一把梭,一次性全部替換整個構建系統,一旦出現構建失敗,阻塞的就是每天上千次的微信后端發布流程,這顯然是不可接受的
在當時切換 bazel 時還有一次有意思的故事,支付團隊以前由于 mmtenpay 倉庫過大,一直都沒有處理,就算是有升級工具的加持,依然在每日構建時成為阻塞的瓶頸,有一部分比較開明的開發,單獨創建了一份 mmtenpay_bazel 的倉庫來只是用 bazel 作為構建工具,試想一下,當時如果存在支付的整潔 GIT,所有的倉庫根據業務系統來劃分,那么就會有更加一致性的遷移程序,遷移的時間也就更加平滑,更省時,
3.2 支付整潔 GIT 實踐
支付在 2016 年業務和開發人員規模迅速膨脹,導致 mmtenpay mmpaygateway 兩個 svn 的依賴混亂,構建復雜,甚至時不時的還引入環形依賴導致構建失敗,最終痛定思痛在在 2018年決定啟用單獨 mmpay 新的 svn 倉庫來結束混亂的局面,但 svn 依舊是權限管理非常生搬硬套,由于缺乏一個劃分檔案夾的標準,導致檔案夾的層級越來越深,依賴查找越來越復雜,2018年底公司提出整體搬遷 git 戰略,組織上加強領域驅動理論的學習,我們于是找到一套切實可行的劃分 git 作業組倉庫的方案,
首先我們需要理解領域驅動設計的思想:
把專案的主要重點放在核心領域和領域邏輯;
以領域中的模型為基礎,進行復雜的設計;
讓技術人員以及領域專家合作,以迭代方式來完善特定領域問題的概念模型,
如果按照領域驅動建模設計微服務是一個什么樣的結構呢

一個微服務是不是應該單獨一個倉庫呢?事情當然不應該是這么簡單的,由于微服務粒度太細,光支付目前就有數千個微服務,微服務之間的關聯性是很強的,最終我們選擇了一個領域內的作為一個作業組,每個子域作為一個代碼倉庫,
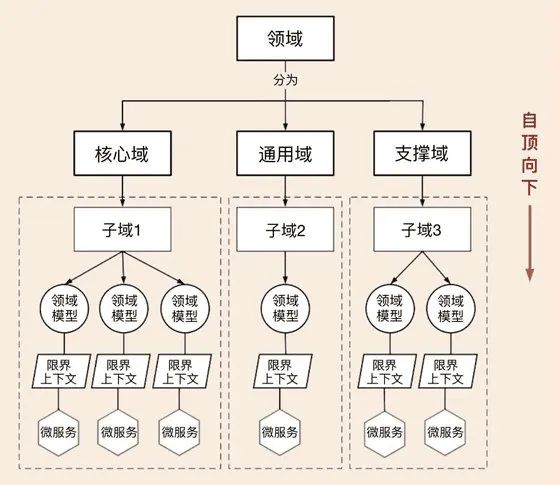
選擇這樣做的好處有非常明顯的,
一個領域(例如微信支付系統)中可以包含不同型別的倉庫,
后端服務:掛載到伏羲平臺中,進行統一編譯走微信后端發布系統發布;
前端工程:使用唐刀平臺、或 XDC 平臺進行統一 CI CD;
檔案沉淀(之后切換到 iWiki):使用工蜂平臺管理檔案源資料,跟蹤缺陷,保留修改記錄和討論詳情,
倉庫的權限和組織架構解耦,當組織架構變動時不需要頻繁更新整個倉庫的權限控制,
對于不同的倉庫都是一個完整的獨立代碼單元,可以根據工程不同型別做獨立的CI CD,
屬于支撐域的 RPC client 自動生成的倉庫,禁止人員修改,根據服務契約變更自動生成 client 的代碼,
但我們也需要了解并不是所有業務系統都會選擇領域驅動建模作為系統設計、代碼開發的指導思想,所以不同的團隊也許會有不同的劃分小倉的方案,支付團隊只能提供類似支付業務的一致性實踐,不能代表所有的業務的開發,
構建一個基于領域驅動建模的需求管理系統也是一個困難的工程,如果忽略掉了這些先決條件,盲目憑直覺而簡單地根據語言來劃分檔案,只用大倉甚至是全公司單倉來作為根本解決方案是不太合適的,
3.3 支付質量紅線
公司在 2019 年的一個 KM 樂問引爆了大家對代碼風格、規范的統一思考,支付團隊在 2020 年中成立了代碼委員會來統一管理微信支付代碼紅線,為了保證團隊代碼風格一致性和規范性,團隊在公司 C++ 代碼規范的基礎上制定了支付質量紅線,初步制定了要參與的代碼倉庫,
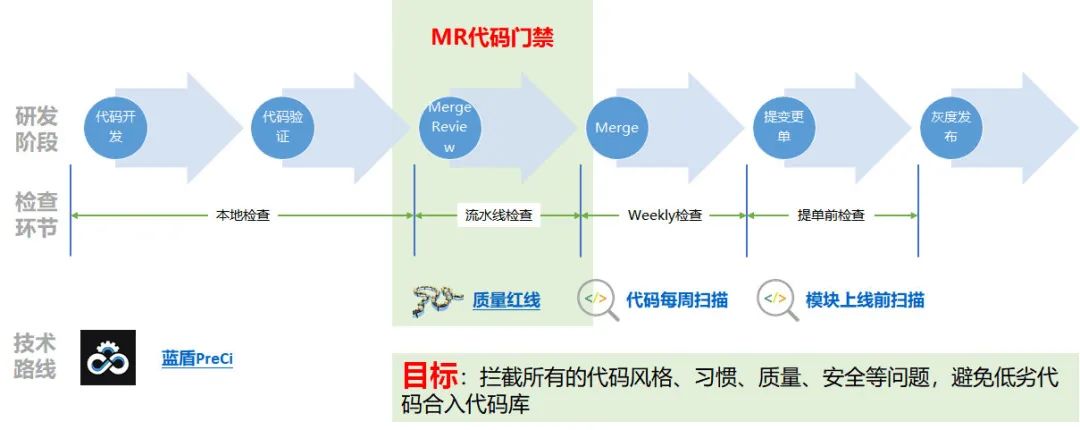
與公司不同的,支付對于代碼中的硬編碼、秘鑰泄露是管理非常嚴格的,所以我們會需要更多的質量紅線來防止一些安全事件的發生,包括但不限于:
杜絕代碼中對于公司內網 IP 的硬編碼行為;
杜絕代碼中對于 appid appsecect github 賬號賬號等硬編碼;
配置中杜絕明文私鑰的存盤,
在推行質量紅線時,同樣的我們對于任何一種發布或變更都會采取可灰度、可回退的方針,我們不能把質量紅線這樣一套門禁系統立即運用于所有代碼工程,一刀切的政策搞不好就會上熱搜,這樣對于整個團隊的士氣的打擊無疑是巨大的,同時我們也沒辦法一開始就保證流水線的設計是合理的,所以一定需要拿一些對質量要求特別敏感的倉庫來小試牛刀,由于藍盾的流水線的模板特性,我們確定只要我們設計好一套好用的流水線模板,就可以非常方便可擴展的應用到所有微信支付小倉專案中,
我們的行動計劃是:
拿出一些典型的倉庫作為設計質量紅線的目標客戶(如支付的公共組件 Xlib,基礎支付中心某些新的倉庫),設計支付紅線流水線;
驗證流水線是否可以攔截不規范的代碼;
根據流水線設計流水線模板;
擴大流水線應用的倉庫;
搜集流水線造成阻塞的反饋;
繼續調整流水線策略并加大風格習慣的宣傳;
將所有新增的倉庫都自動添加質量紅線堵住增量入口;
進一步灰度流水線到其他陳舊代碼倉庫,
支付線本身就有整潔 git 和非整潔 git 兩種不同代碼倉庫,在進度到第 8 步時遇到了非常大的阻力,因為陳舊代碼倉庫的代碼量之大導致藍盾出錯的幾率增加,而藍盾的客服人員告訴我們可以將 MR 關閉之后再打開重試流水線,這又造成了藍盾的負載進一步增加,
我們慶幸在 2021 年整潔 git 的思想和代碼撰寫模式已經非常深入人心,否則這樣強推質量紅線的實踐可能就會成為災難,在一個工具型產品應用的程序中,你會受到來自業務團隊開發的各種阻力,只有不斷的灰度打磨、精益的調整工具型產品的口碑,讓各行各業的開發人員切實感覺到提升了他們利益,而不是讓業務開發天天做一些修代碼風格,整治遺留重構的漩渦中,這樣才能讓廣大的開發人員接受研發效能作業,才能形成效能工具打磨的正反饋,至于說是否采用大倉,對于領導這一涉眾而言只是一個解決一致性問題的方案,工具和管理才是提高效能的本質,
從組織上來說,小倉大倉只要能解決“一致性”的問題就是好的解決方法,無論是從后端構建系統、開源治理、倉庫劃分等組織上的訴求來看,大倉都并沒有非常有利的優勢,相反大倉的支持者通常使用“我們先用一個大倉規范起來,既然都在一個倉庫了就理所應當的好治理了”這樣一種話術來掩飾組織上在治理“一致性”方面的難題,仔細想想是不是規整分類的小倉庫治理起來,比混亂不堪的檔案夾亂飛的大倉,要簡單容易呢,
4 分治
公司的開源治理的政策的核心是“一致性”,
首先大家需要有開源共建的精神;
在開源的基礎上提升代碼質量提升效能;
消除開發團隊中的資訊壁壘;
減少重復作業提升研發效率,
而大倉的擁護者似乎把這個政策搞顛倒了,似乎只有使用大倉或未來讓全公司都有幾個為數不多的大倉才能解決上述問題,似乎把所有生產程式的原材料堆放在一起,才是解決效能的第一步,而這恰恰是目前和近 10 年來去中心化的大主流不相符合,
4.1 主干開發 vs 金絲雀 vs GitFlow
你看的沒錯,微信支付團隊后端就是基于小倉做主干開發的,使用小倉并不影響使用主干開發,而且正式由于倉庫是基于領域驅動劃分的,所有的業務邏輯代碼都在一個非常聚焦的倉庫中進行,比起大倉做主干發開,小倉反而有更加靈活方便,主干開發并不是大倉的特有的,而是一種開發理念,只要是做業務開發的都可以選擇使用主干開發,大倉做主干開發只是一種非常想當然的認為,但主干開發并不是大倉的必要條件,
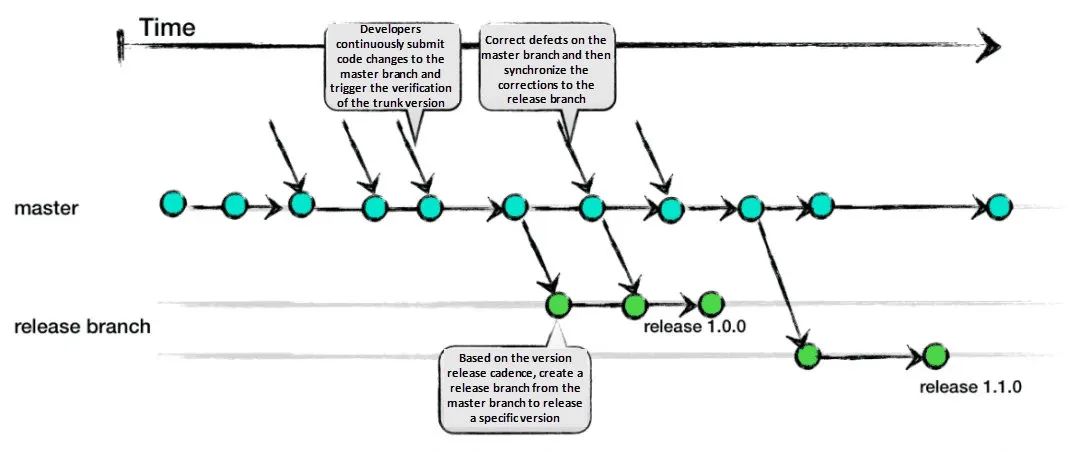
我們認為業務代碼的開發更適合于主干開發:
保留陳舊的不合時宜的業務代碼邏輯并不能提升效能,反而會影響團隊開發人員的視野;
由于現在自動化測驗用例工具非常普遍,盡快合入主干會防止一次性合入過多代碼而導致無法對代碼進行有效的審核;
微服務之間的交流通過統一的契約管理,通過契約變更的兼容性來保證,即便是在不同時期不同倉庫合入的主干,也不會出現通信上的兼容性問題;
特性開關、特性發布和構建產物解耦,就算是業務邏輯夾帶出去,也不會對非開啟特性的用戶產生影響,
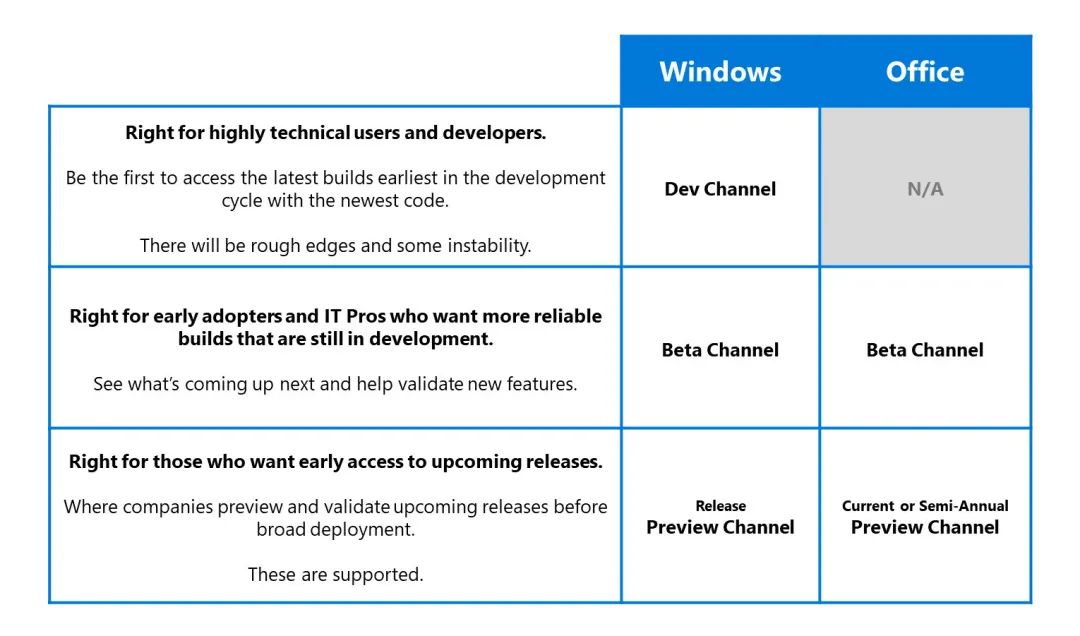
同時對于基礎框架的開發,我們認為采用類似 Windows Insider 的金絲雀方案來確定分支更合適,(金絲雀方案比較類似于 GitLab Flow,只是比 GitLab Flow 更簡化):
基礎框架維護的倉庫包含一個 master (Release Channel) 分支一個 PreMaster (Beta Channel) 分支;
當某個特性開發時創建 feature 分支,分支完成好后立即合入 PreMaster 分支;
此時 PreMaster 可能是未經大規模驗證的,但又可以基本使用的(跑通過了單元測驗用例)版本;
某些內在的 BUG 非常有可能不會出現:如核心微服務調度演算法,資源管理演算法類的框架,再沒有大規模上生產環境時,是很難被驗證的;
此時框架團隊會和有需求的團隊或比較激進的團隊來協商試用 PreMaster 版本的框架,此時需要注意業務團隊非常可能是用自己的 master 分支和框架的 PreMaster 分支一起構建(參見統一編譯的部分);
當 PreMaster 框架驗證一段時間后(比如一個月,跟劇規模和業務方的訴求來確定),再合入 master;
此時很多在 PreMaster 通過驗證發現的 BUG 會得到修復,也非常有可能在 PreMaster 評估不合理的特性會被去掉;
核心業務在此時會非常樂于接受被驗證的特性,因為已經經受到了其他業務團隊的驗證;
對于某些對可用率要求非常高的業務如(微信支付的收付退結,必須要達到 99.999%)會使用 stable 版本的框架;
stable 版本的框架是通過半年或以上沉淀下來的基礎庫的版本,只有在非常緊急的情況下才會將 bugfix 合入 stable;
任何人都沒辦法保證在 master 下的特定時期不會出現任何 bug,只有在得到充分驗證的情況下,可用率要求高的業務才會接受使用新版框架;
某個業務的升級灰度其可能會長達1年,他們根本就不想冒著框架中未知的 bug 而升級框架,
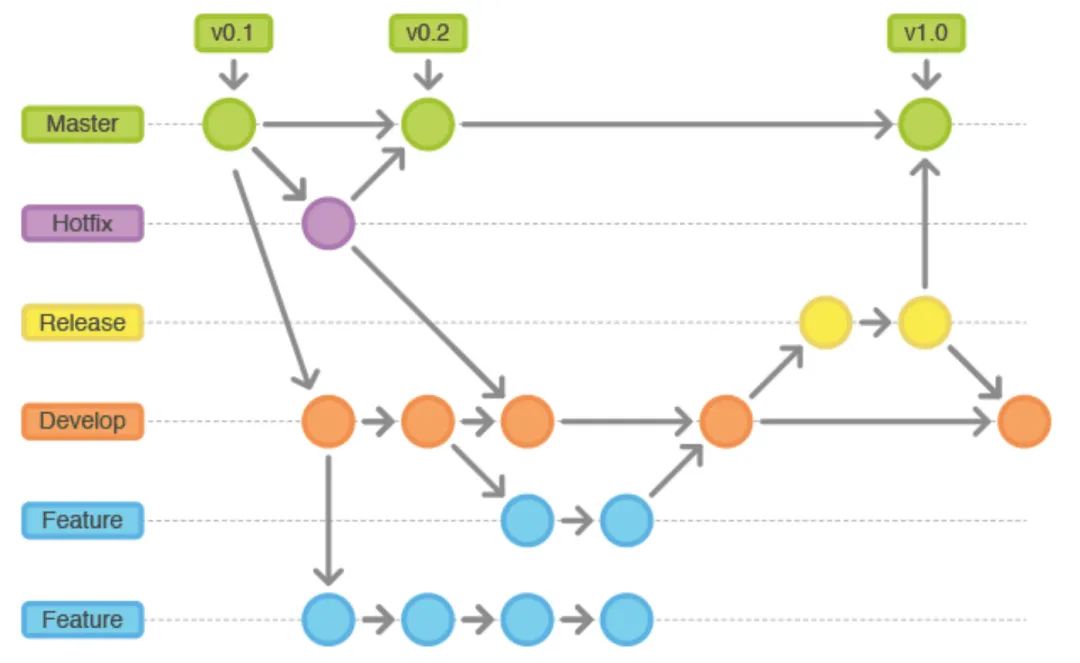
那什么情況下應該使用 GitFlow 呢,我們認為一些前端的或大量被未知世界依賴,強依賴未知世界源的對外開源框架,應該采用 GitFlow 模式:
因為不像公司內部代碼治理,你無法窮舉出所有開源的被依賴者;
所以你沒辦法對不兼容性更新舍棄一個大版本;
你必須會一個穩定的提交設定一個 tag 以便讓你的客戶有選擇的保留在這個提交中;
倉庫需要做的非常職責單一,要不耦合業務邏輯;
世界是瞬息萬變的,世界的變化可不能做到最大的兼容型(比如要吳簽同學下課你就得下);
業務也是瞬息萬變的,耦合了業務邏輯即使是的當時你認為穩定的 tag 也會變成要必須處理的問題;
倉庫要做的不能耦合公司的基礎設施;
公司的基礎設施天生不會為開源社區準備的,在版本維護上非常有可能只采取金絲雀模式(即只保留 dev PreMaster master stable)幾個版本;
倉庫耦合了公司的基礎設施首先對于開源社區是不和諧,因為離開了不開源的基礎設施,你的代碼根本沒辦法進行 CI CD,甚至連編譯都做不了(當然這樣的倉庫也不適合對外開源);
目前前端的一些公司級的開源產品(如 weRequest、wepy、omi)已經借助一個全世界的開源倉庫管理系統 github 實作完全的自洽,這一類專案應該按照目前開源界的運作規范來運行(不限于只是用 GitFlow),
由此可見主干開發、金絲雀開發、GitFlow 的選擇并不應該是由公司的政策所導向,而是應該由業務特性、所選用的基礎設施決定的,是需要不同定位的,而如果整個公司被劃分成幾個超級大倉,開發模式將會被完全鎖死到看似比較簡單的主干開發模式,至于騰訊會不會將來走到全公司一個大倉,大倉支持者卻認為不一定有必要,這里關鍵是看什么樣的專案使用什么樣的倉庫型別,而且倉庫之間的組合是需要根據業務、構建系統、所處在的研發階段動態配置的,
4.2 開源 vs 閉源
大倉的支持者一直認為將公共庫放在大倉中可以解決依賴地獄的問題,而且會使得代碼更容易的代碼復用與分享,但此時我認為大倉小倉的劃分不應該由代碼的是不是公共庫來劃分,而是需要根據公共庫所處在的研發地位和解決發方式來劃分,例如(這兩個例子都來源于真實的后端代碼):
非常單純且自洽的公共庫(如 RapaidJSON),適用于小倉;
此類公共庫應該是專門為一些通用的需求制定的,(RapaidJSON 就是為 Json 決議訪問驗證做的庫);
此類公共庫并不耦合特定的研發框架(RapidJSON 放在微信 svrkit 框架或 tRPC 下都可以解決特定域的問題);
此類公共庫可以能夠在集成開源界的 CI CD 工具形成完美的 issue 倍訓,分支管理等(RapidJSON 可以在不依賴 patchbuild 的基礎上實作完美的構建,運行單測用例);
專用框架的公共庫(如 svrkit 框架下的 Comm2),適合直接和專用框架一起存盤源代碼;
此類公共庫是專為特定框架 svrkit 定制的,而隨著 svrkit 框架的升級,此類別庫需要做頻繁的改動,此時放在單獨小倉中一定會出現版本依賴復雜,導致編譯失敗的問題;
此類公共庫不不需要貢獻給開源社區,和私有的構建工具深度系結,Comm2 只能在 patchbuild 下被構建,所以也只會存在深度耦合的 BUILD 檔案,而不需要
autoconf或cmake等標準構建檔案;此類公共庫很多是一些框架和其他組件的粘合劑(比如 Comm2 中的 pb2json)單獨離開了框架無法運行任何 CI CD 工具,
所以我們在選用小倉的同時必須考慮其代碼解決的問題域,如果屬于前者,我認為選擇獨立的小倉似乎更適合,而且這樣的小倉也能更好的為開源界互動,
開源的目的是為了更好的協作,也是為了集合更多的智慧讓某一份代碼可以解決更多其專有域的問題,此時開源的收益是大于閉源的,閉源的目的是為專用系統更好的定制代碼,使得業務開發更加能專注的開發其業務特性,而從依賴地獄、選擇困難中解脫出來,
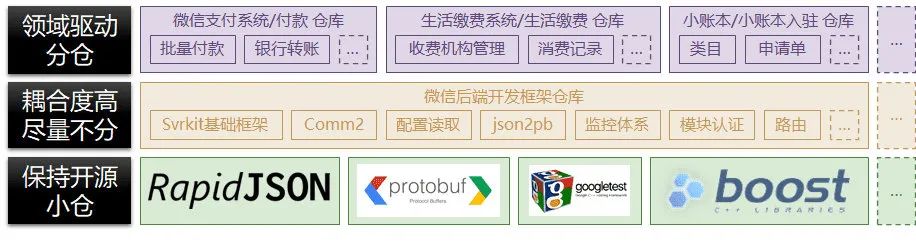
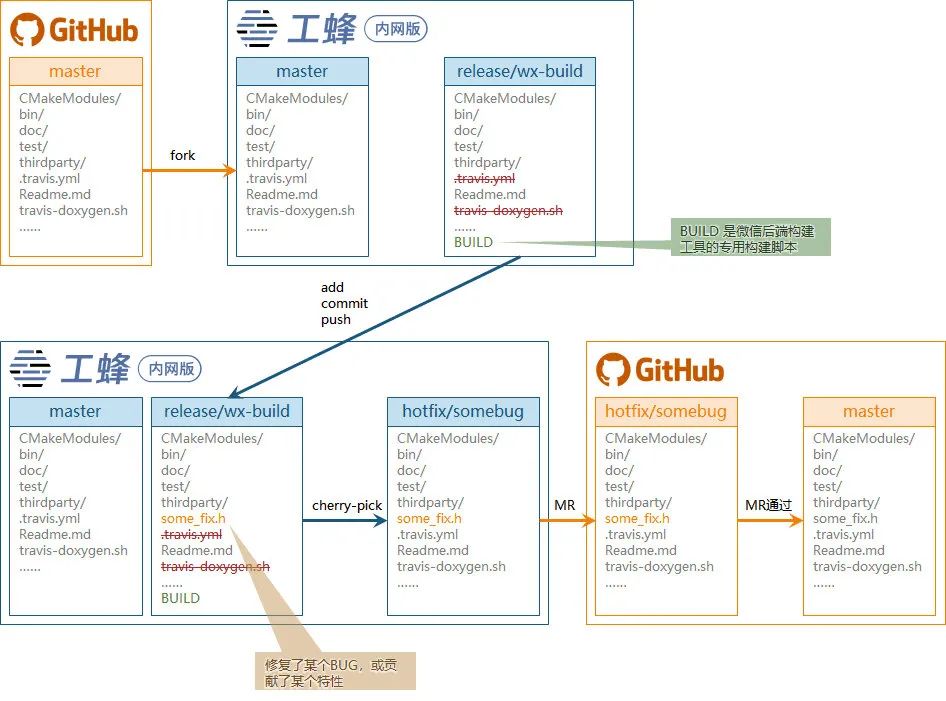
為了保持開源小倉的靈活和良性互動,開源的小倉是在工蜂的 Fork 的一份副本,理想的做法如下:
從工蜂中直接克隆 github 的倉庫;
在克隆的倉庫中建立一個專用的私有分支,如(release/wx-build);
在私有的構建分支中添加適配內部構建的代碼檔案,如集成到微信后端編譯系統,需要添加
BUILD構建依賴腳本;將私有分支資訊配置到內部構建系統中,如配置到伏羲平臺;
如果發現倉庫有 BUG 直接在 wx-build 分支中快速修復并驗證,需要貢獻特性也可以如法炮制;
將 wx-build 中的更改揀選到 hotfix 分支中;
將此分支在外源(如 github)中提交 MR,跑外源的 CI 流水線;
若外源有更新,也可以將外源的更新 merge 到 wx-build 中,
大倉的擁護者似乎想到一種另外的解決方案,即公司專門組織一個開源代碼委員會進行專門內源外源同步作業,在此我對此表示質疑:
外網的倉庫型別非常多,不論是前端后端,還是各種構件工具,找一組開源代碼委員會的人非常難精通各種不用的倉庫的場景;
代碼委員會因為不是倉庫代碼的貢獻者,非常難有將一個內網的代碼發到外網的動力,況且一旦出現構建失敗等問題將對這群人產生致命的積極性的打擊;
作為通用組件的作者,當然是希望自己的組件不會被專用的構建工具所系結,當然是希望自己能夠把自己的智慧貢獻給開源社區,所以由此人來維護代碼倉庫并保持和外源倉庫一直是非常自然的想法,
如果使用大倉,可能會將某個開源設計的代碼整體復制到一個檔案夾中,或采用 sub_module 的方式引入,到時候維護者非常有可能只從整個大倉的角度思考此組件的特性,而忽略了在外源專案中此倉庫的獨立性,
另外類似這樣的第三方庫似乎只和生成產物的構建系統強相關,也不適合將其放在代碼倉庫中,代碼倉庫應該盡可能做到職責單一,使用單獨的構建系統的產品(如微信后端的伏羲平臺)可以非常好的解決倉庫耦合度過重的問題,
由此可見,劃分倉庫的大小和作業組的分類并不是應該是有倉庫代碼的固有特性所決定的,過大過小都可能使得倉庫的代碼中喪失了其獨立性,如果整個公司都或整個BG都是使用同一種劃分模式,可能會出現:把代碼放進入容易,但日后如何管理這個大倉陷入比較麻煩的局面,
4.3 灰度 灰度 還是灰度
有次有幸聽到了 AMS 廣告營銷服務線的一次分享,分享主有幸提到了在半個月內將所有的模塊由 gcc4 升級到 gcc7,并因此推斷此單倉的方案能夠非常有效的解決遺留債務的問題,但還是那句話,如果拋開業務的特性,很難說任何方案都具有普適性,在微信支付內(特別是收付退結核心產品),在幾天內就將所有的模塊升級 gcc 大版本是非常不能被接受的,
你無法保證 gcc 升級之后一些語法上的特性導致業務上行為的變更(如 C++11 去掉 string cow 特性);
你無法保證某些業務在 gcc 升級之后依然保證可以獨立編譯成功(如 C++11 修改了 map 的 insert 方法的函式簽名);
你無法保證修改后的代碼是可以兼容其他的第三方庫的,其他的第三方庫是不是需要同步升級;
支付這邊的做法是:
在伏羲平臺中新建一個編譯賬戶;
對于基礎庫和依賴的組件配置低版本 gcc 的分支,并保留一段時間;
業務代碼使用這個編譯賬戶來構建低版本 gcc 的產物,并使用正常的編譯賬戶構建高版本 gcc 產物;
逐步遷移倉庫到高版本 gcc,并保持可回退編譯的能力;
當所有倉庫都遷移到高版本 gcc 一段時間后再廢棄掉升級時所用的編譯賬戶,
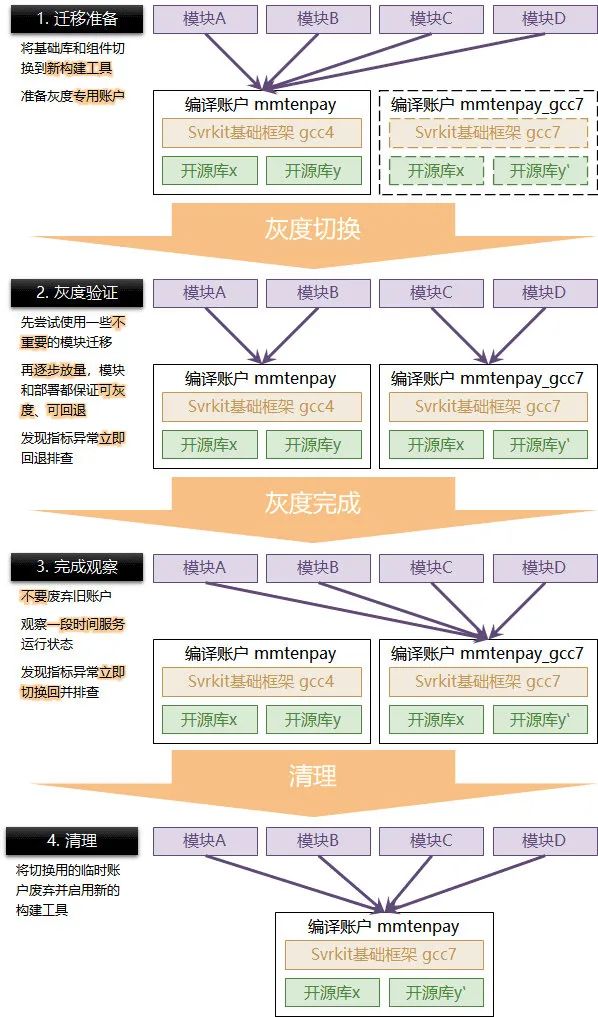
無論是資料遷移、庫遷移、模塊遷移,支付系統由于自身業務的定位,絕對不允許出現不可灰度、不可回退的方案,支付定位是金融級系統的可靠性保證,質量安全是支付生命線,
開源治理的思想應該是指定大的方針方向(比如我們要構建開源協同的文化氛圍 Oteam,構建開源協同的工具工蜂、Tapd、iWiKi等),而不是特別欽定必須使用哪一中具體的特定解決方案,解決方案應該是“接地氣”的和業務相關的一組策略的組合,而非強調必須使用這一組合中某個特定的工具,最終寄希望這一特定工具來解決所有問題,
結語
把上文的要論述的部分整理成一份腦圖分享一下,
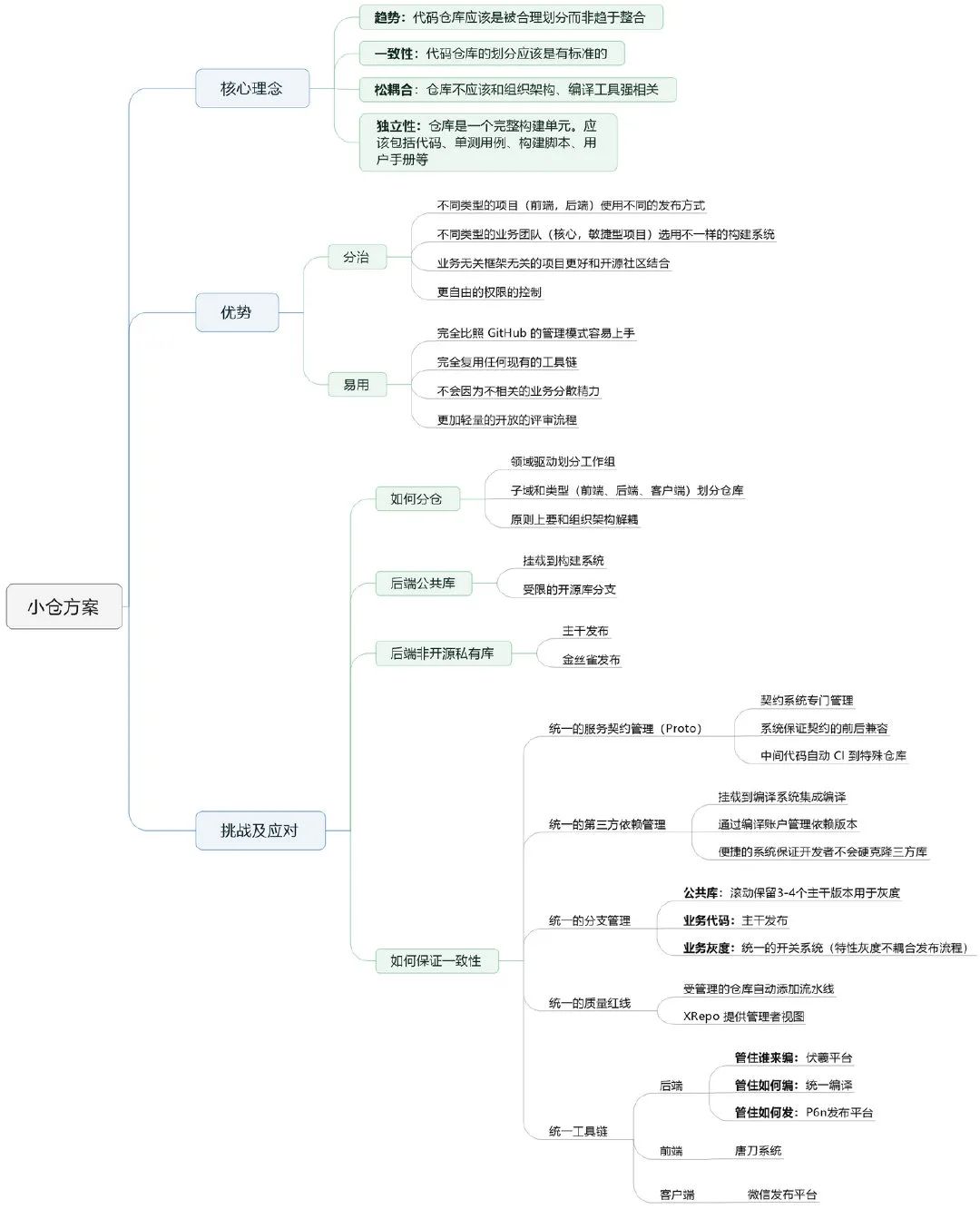
沒有哪一種分倉方案是完美的方案,也許 Google 在它的歷史而長河中選擇了大倉方案,Amazon 基于自身的基因選擇了小倉方案,只有辯證的看到大倉或小倉,才是最科學的辦法,然而只有一個空想沉思的口號而沒有具體實踐的指導計劃就是脫離了實事求是的魂,沒有去調研一線業務開發的疾苦就是脫離了群眾路線的根、不是根據歷史的發展規律而盲從 Google 的行為標準就是脫離了獨立自主的本,只有從實踐出發,結合公司業務發展的客觀規律,才能最終發掘出一份接地氣的解決方案,這也是我們對待技術與業務的最融洽的方式,
參考:
[1]: 領域驅動設計 - 維基百科: https://zh.wikipedia.org/wiki/%E9%A0%98%E5%9F%9F%E9%A9%85%E5%8B%95%E8%A8%AD%E8%A8%88
[2]: 領域驅動設計讀書筆記 nekeyzhong
[3]: Introducing Windows Insider Channels | Windows Insider Blog: https://blogs.windows.com/windows-insider/2020/06/15/introducing-windows-insider-channels/
[4]: Gitflow Workflow, Automated Builds, Integration & Deployment. (iamchuka.com): https://iamchuka.com/gitflow-workflow-continuous-integration-continu/
[5]: How to Select a Git Branch Mode? - Alibaba Cloud Community: https://www.alibabacloud.com/blog/how-to-select-a-git-branch-mode_597255
[6]: 任理軒:實事求是、群眾路線、獨立自主是興黨興國的三大法寶): http://theory.people.com.cn/n/2015/1111/c367485-27802217.html
[7]: Want VS Needs,產品經理基于場景的需求挖掘: https://cloud.tencent.com/developer/article/1643618
[8]: 弗朗西斯·福山《歷史的終結》: https://zh.wikipedia.org/wiki/歷史的終結及最后之人
[9]: 陳平《Do what American do, don't do what American say》: https://www.bilibili.com/video/BV1uJ411M7Ky/
[10]: 基于FUSE的大倉設計方案: https://docs.qq.com/doc/DVkpQWld6eW9xdEd2
[11]: Virtual File System for Git: https://github.com/microsoft/VFSForGit
[12]: Git at Scale | Microsoft Docs: https://docs.microsoft.com/en-us/previous-versions/azure/devops/git/git-at-scale
[13]: 為什么Google上十億行代碼都放在同一個倉庫里?: https://zhuanlan.zhihu.com/p/28524745
[14]: The Issue of Monorepo and Polyrepo In Large Enterprises (acm.org): https://dl.acm.org/doi/pdf/10.1145/3328433.3328435
視頻號最新視頻
歡迎點贊
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/302838.html
標籤:其他