每天進步一點點!

什么叫結構體?結構體是由相同或者不同的資料構成的資料集合
在此之前了解一些小知識
2.1只有結構體變數才分配地址,而結構體的定義是不分配空間的,
2.2結構體中各成員的定義和之前的變數定義一樣,但在定義時也不分配空間,
2.3結構體變數的宣告需要在主函式之上或者主函式中宣告,如果在主函式之下則會報錯
2.4c語言中的結構體不能直接進行強制轉換,只有結構體指標才能進行強制轉換
2.5相同型別的成員是可以定義在同一型別下的
1.結構體的宣告與定義
1.結構體是一種自定義資料型別
struct 結構體名{
成員變數或者陣列
};
特別要注意的是末尾的分號一定不能少,表示結構體設計定義結束
結構體是一種集合,他里面包含了多個變數或者陣列,變數的型別可以相同也可以不同,每一個這樣的變數或者陣列都被稱為結構體成員,我們來看一個例子:
include<stdio.h>
struct student
{
int age;
char name[10];
int score;
char sex[10];
};stedent為結構體名,他一共有四個成員,分別是age,name ,score,sex,結構體的定義方式和我們在前面學過的陣列十分相似,只是陣列可以初始化,而在這里是不能初始化
2.先定義結構體型別在定義結構體變數
#include<stdio.h>
struct student
{
int age;
char name[10];
int score;
char sex[10];
};
struct student s1;//s1為全域變數
int main()
{
struct student s2;//s2為區域變數
}3.定義結構體型別的時候同時定義結構體變數
#include<stdio.h>
struct student
{
int age;
char name[10];
int score;
char sex[10];
}s1, s2;
int main()
{
return 0;
}4.定義匿名結構體
#include<stdio.h>
struct
{
int age;
char name[10];
int score;
char sex[10];
}s1;
int main()
{
return 0;
}但是這種方式不太好,這個結構體有一種一次性的感覺,不建議這樣定義結構體
總結:
1.使用struct 關鍵字,表示他接下來是一個結構體
2.接下來是一個結構體型別名,可以自己選擇
3.花括號,括起來了結構體成員串列,使用的都是宣告的方式來描述,用;來結束描述
4.在結束花括號后的分號表示結構體設計定義的結束
5.定義的方式
1)先宣告結構體型別再定義變數名
例如:struct(型別名) student(結構體) student1(變數名),student2(變數名);
定義了student1和student2為struct student型別的變數,即他們具有struct student型別的結構
(2)在宣告型別的同時定義變數這種形式的定義的一般形式為:struct 結構體名{
成員串列
}變數名;注意:
結構體里面的成員可以是基本資料型別也可以是自定義資料型別
5.結構體宣告的位置,及其作用
2.結構體變數的初始化
1.結構體變數和其他變數一樣可以在定義的時候指定初始值 ,結構體變數的初始化用大括號初始化
例:
#include<stdio.h>
struct student
{
int age;
char name[10];
int score;
char sex[10];
};
int main()
{
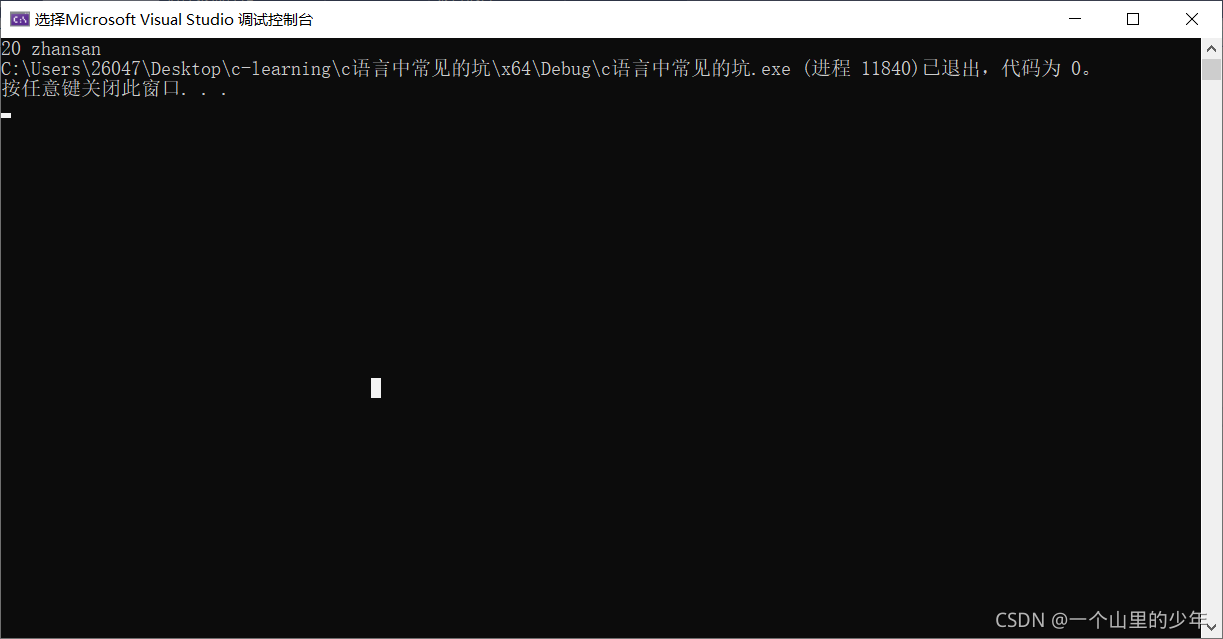
struct student s1={20,"zhangsan",60,"男" };//初始化s1;
printf("%d %s %d %s", s1.age, s1.name, s1.score, s1.sex);//列印s1中的成員
return 0;
}運行結果:
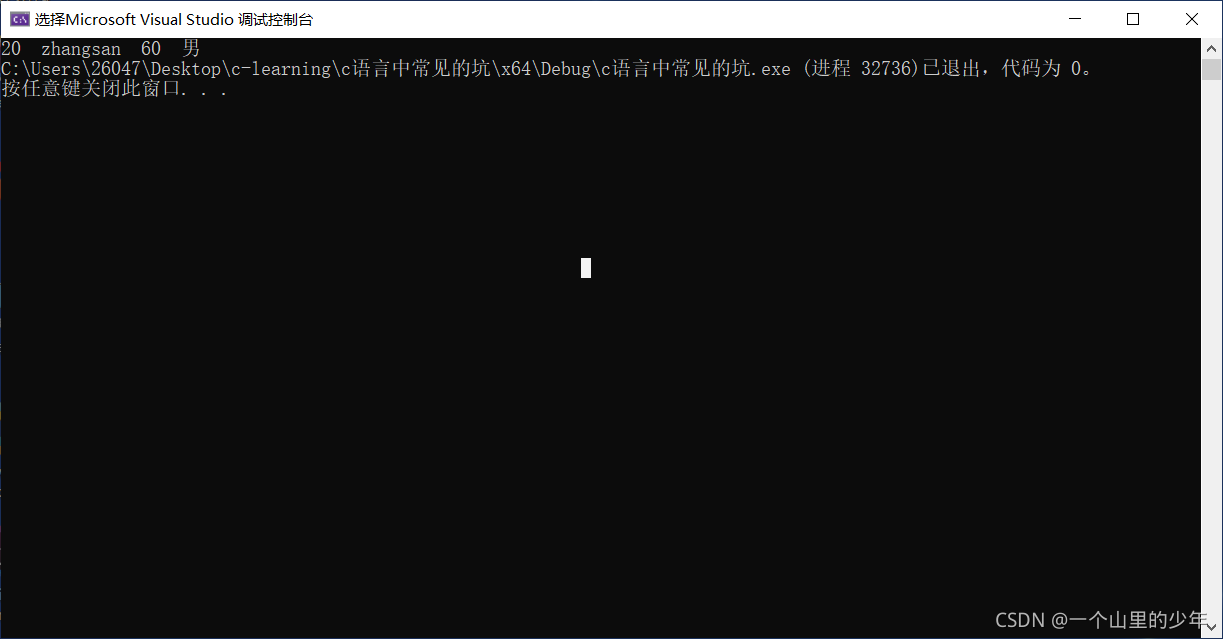
結構體變數的初始化用大括號初始化
那下面這種行不行了?
#include<stdio.h> struct student { int age; char name[10]; int score; char sex[10]; }; int main() { struct student s1; s1={20, "zhangsan", 60, "男" }; printf("%d %s %d %s", s1.age, s1.name, s1.score, s1.sex);//列印s1中的成員 return 0; }
這種是不行的,s1在之前已經定義過了,下面在給他值,不是初始化了而是賦值
我們可以看到
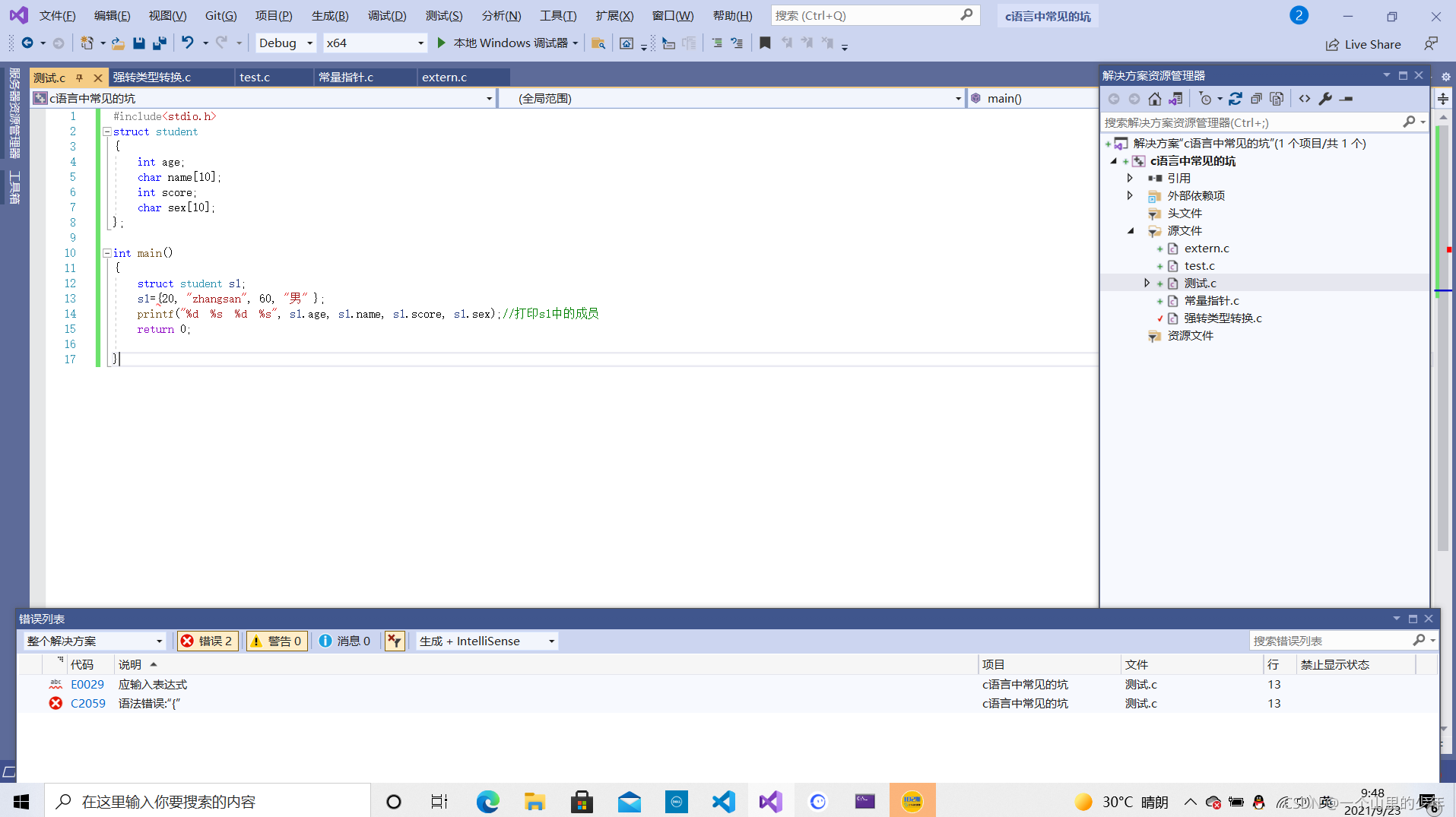
此時編譯器報錯了,在結構體變數定義后,如果仍要對成員變數賦值,此時我們只能一一賦值
#include<stdio.h>
#include<string.h>
struct student
{
int age;
char name[10];
int score;
char sex[10];
};
int main()
{
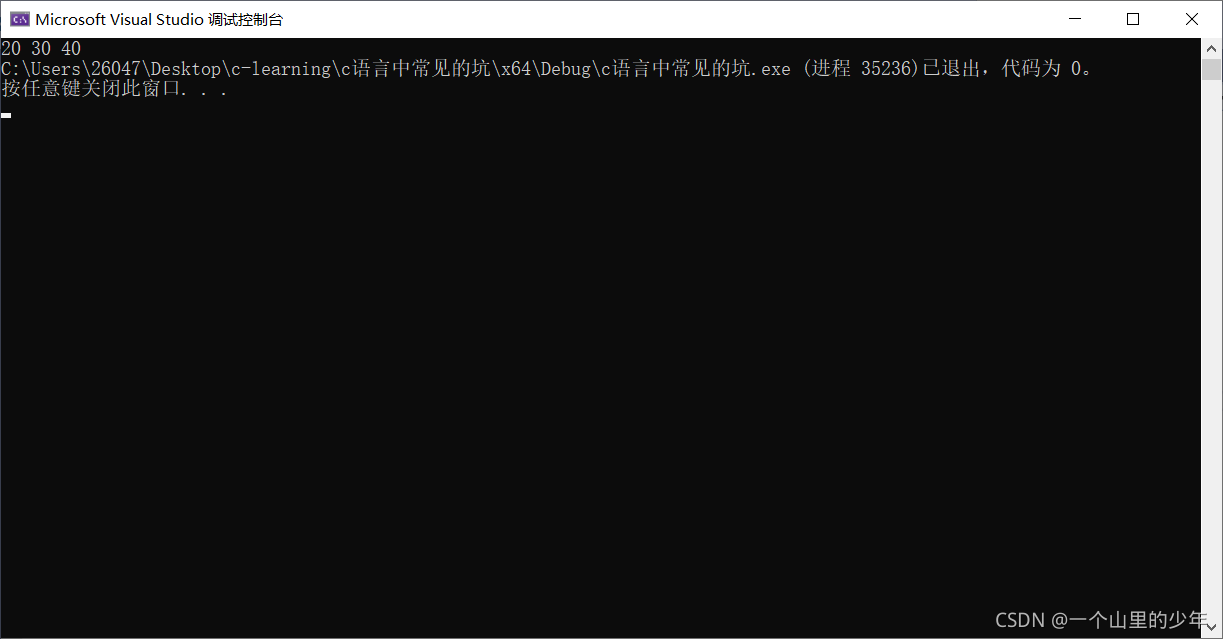
struct student s1;
strcpy(s1.name, "zhangsan");
s1.age = 40;
s1.score = 60;
strcpy(s1.sex, "男");
printf("%d %s %d %s", s1.age, s1.name, s1.score, s1.sex);//列印s1中的成員
return 0;
}運行結果:
2.結構體中嵌套結構體的初始化
結構體中中嵌套結構體的初始化我們依然使用大括號進行初始化
#include<stdio.h>
struct techer
{
int age;
char name[10];
};
struct student
{
int age;
char name[10];
int score;
char sex[10];
struct techer s2;
};
int main()
{
struct student s1 = { 20,"zhangsan",70,"男",{20,"老師"} };//初始化s1;
printf("%d %s %d %s %s", s1.age, s1.name, s1.score, s1.sex,s1.s2.name);//列印s1中的成員
return 0;
}3.訪問結構體成員
訪問結構體成員主要用兩種
1.使用成員訪問運算子 ,結構體變數.成員變數
2.使用->運算子,結構體指標->成員變數名
舉個例子:
#include<stdio.h>
struct techer
{
int age;
char name[10];
};
struct student
{
int age;
char name[10];
int score;
char sex[10];
struct techer s2;
};
int main()
{
struct student s1 = { 20,"zhangsan",70,"男",{20,"老師"} };//初始化s1;
printf("%d %s %d %s %s", s1.age, s1.name, s1.score, s1.sex,s1.s2.name);//列印s1中的成員
return 0;
}2.結構體指標訪問成員變數
#include<stdio.h>
struct t
{
int age;
char name[12];
char c;
};
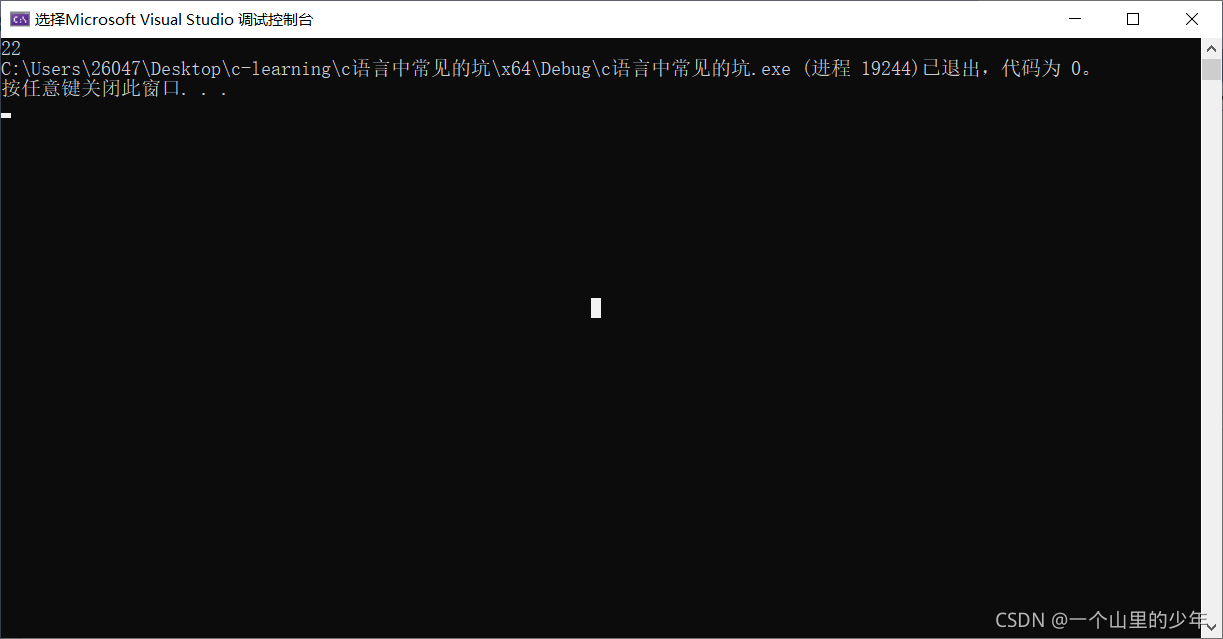
int main()
{
struct t s1 = { 20,"zhansan",'c' };//定義一個結構體變數s1并將其初始化為對應的值
struct t* p1 = &s1;
printf("%s %d", p1->name, p1->age);
return 0;
}運行結果:
#include<stdio.h>
#include<string.h>
struct t
{
int age;
char name[12];
char c;
};
int main()
{
struct t s1 = { 20,"zhansan",'c' };//定義一個結構體變數s1并將其初始化為對應的值
struct t* p1 = &s1;
printf("%s %d", p1->name, p1->age);
return 0;
}總結:
1.結構體整體賦值只限定于定義變數的時候并將其初始化,在使用的程序中只能對其一 一賦值,這一點和陣列是類似的,
2.結構體是一種自定義型別,是創建變數的模板,不占用空間,結構體變數才包含了實實在在的資料,需要空間來存盤
4.結構體傳參
1.可以把結構體作為函式引數,傳參的型別和其他變數或指標類似
第一種傳參方式,傳結構體用結構體來接收
#include<stdio.h>
#include<string.h>
struct t
{
int age;
char name[12];
char c;
};
void print(struct t s2)
{
printf("%d %s", s2.age, s2.name);
}
int main()
{
struct t s1 = { 20,"zhansan",'c' };//定義一個結構體變數s1并將其初始化為對應的值
print(s1);
return 0;
}運行結果:
方法二:
傳結構體變數的地址:
#include<stdio.h>
#include<string.h>
struct t
{
int age;
char name[12];
char c;
};
void print(const struct t* s2)
{
printf("%d %s", s2->age,s2->name);
}
int main()
{
struct t s1 = { 20,"zhansan",'c' };//定義一個結構體變數s1并將其初始化為對應的值
print(&s1);
return 0;
}運行結果:
兩種傳參方式都能達到目的,那哪一種傳參方式更好 了答案是第二種,原因是第一種是值傳遞,會創建一個臨時變數將實參的值拷貝給形參,如果結構體太大,傳遞的效率就會很低,空間的浪費很大,但是第二種傳遞的方式是傳地址,只需要拷貝4個或者8個位元組,如果要傳參盡量選擇第二種
5.結構體陣列
所謂的結構體陣列,指的是結構體里面的每一個元素都是結構體,在實際中常用來表示擁有相同資料結構的群體,比如一個班的學生
定義結構體陣列和定義結構體變數的方式類似定義時可以初始化
例:
#include<stdio.h>
#include<string.h>
struct student
{
int age;
char name[12];
char c;
};
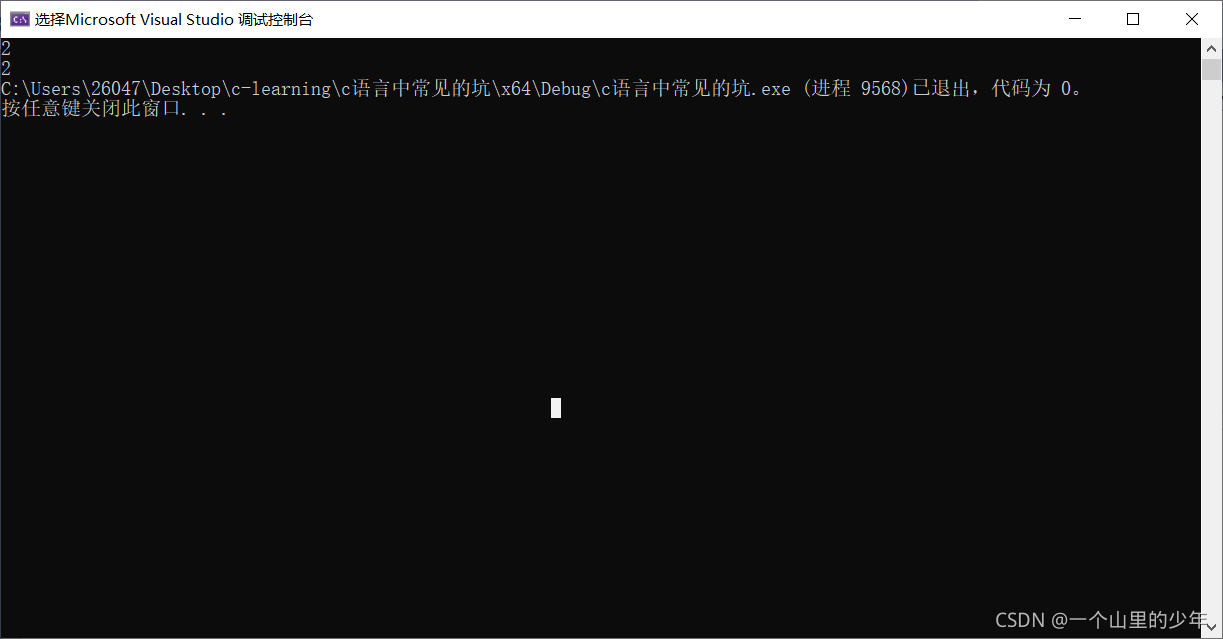
int main()
{
struct student arr[3] = { {20,"zhangsan",'c'},{30,"lisi",'d'},{40,"wangwu",'p'} };
printf("%d %d %d", arr[0].age, arr[1].age, arr[2].age);
}運行結果:
6.結構體指標
顧名思義就是指向結構體的指標,方式和定義整型指標那些類似,
定義格式: struct 結構體名*+結構體指標名字
例:struct student *struct _pointer;
struct_pointer=&s1;
訪問成員時使用->運算子
struct_pointer->+成員名
#include<stdio.h>
#include<string.h>
struct student
{
int age;
char name[12];
char c;
};
int main()
{
struct student s1 = { 22,"zhangli",'c' };
struct student* struct_pointer = &s1;
printf("%d", struct_pointer->age);
}運行結果:
注意:
結構體和結構體變數是兩個不同的概念:結構體是一種資料型別,是一種創建變數的模板,編譯器不會為它分配記憶體空間,就像 int、float、char 這些關鍵字本身不占用記憶體一樣;結構體變數才包含實實在在的資料,才需要記憶體來存盤,下面的寫法是錯誤的,不可能去取一個結構體名的地址,也不能將它賦值給其他變數:
下列寫法是錯誤的
#include<stdio.h>
#include<string.h>
struct student
{
int age;
char name[12];
char c;
};
int main()
{
struct student* p = &student;
struct student* s = student;
}
7.獲取結構體成員
通過結構體指標可以獲取結構體成員,一般形式為:
(*pointer).memberName
或者:
pointer->memberName
第一種寫法中,.的優先級高于*,(*pointer)兩邊的括號不能少,如果去掉括號寫成*pointer.memberName,那么就等效于*(pointer.memberName),這樣意義就不對了,
第二種寫法中,->是一個新的運算子,習慣稱它為“箭頭”,有了它,可以通過結構體指標直接取得結構體成員,這也是->在C語言中的唯一用途,
上面兩種寫法是等效的,我們通常采用第二種寫法,這樣更加直觀,
例:
#include<stdio.h>
#include<string.h>
struct student
{
int age;
char name[12];
char c;
};
int main()
{
struct student s1 = { 2,"zhansan",'e' };
struct student* pointer = &s1;
printf("%d\n", pointer->age);
printf("%d", (*pointer).age);
}運行結果:
7.結構體變數的參考(輸入和輸出)
結構體變數的輸入scanf和輸出printf和其他變數的操作是一樣的
1.值得注意的是.的優先級是比較高的
2.(如果結構體的成員本身是一個結構體,則需要繼續用.運算子,直到最低一級的成員,
#include<stdio.h>
#include<string.h>
struct student
{
int age;
char name[12];
char c;
struct Date
{
int year;
int month;
int day;
}brirthday;
}stu1;
int main()
{
printf("%d", stu1.brirthday);//這樣寫是錯誤的,因為brirthday是一個結構體
scanf("%d", &stu1.brirthday.month);//正確;
}8.結構體記憶體對齊(重點)
結構體中的記憶體對齊是用空間換時間的一種記憶體操作,
一.結構體對齊的規則
1、 資料成員對齊規則:結構(struct)(或聯合(union))的資料成員,第一個資料成員放在offset為0的地方,以后每個資料成員的對齊按照#pragma pack指定的數值和這個資料成員自身長度中,比較小的那個進行,
2、結構(或聯合)的整體對齊規則:在資料成員完成各自對齊之后,結構(或聯合)本身也要進行對齊,對齊將按照#pragma pack指定的數值和結構(或聯合)最大資料成員長度中,比較小的那個進行,
3、結合1、2可推斷:當#pragma pack的n值等于或超過所有 資料成員長度的時候,這個n值的大小將不產生任何效果,
1) 結構體變數的首地址是其最長基本型別成員的整數倍;
備注:編譯器在給結構體開辟空間時,首先找到結構體中最寬的基本資料型別,然后尋找 記憶體地址能是該基本資料型別的整倍的位置,作為結構體的首地址,將這個最寬的基本資料型別的大小作為上面介紹的對齊模數,
2)結構體每個成員相對于結構體首地址的 偏移量(offset)都是成員大小的整數倍,如有需要編譯器會在成員之間加上填充位元組(internal adding);
備注:為結構體的一個成員開辟空間之前,編譯器首先檢查預開辟空間的首地址相對于結構體首地址的偏移是否是本成員的整數倍,若是,則存放本成員,反之,則在本成員和上一個成員之間填充一定的位元組,以達到整數倍的要求,也就是將預開辟空間的首地址后移幾個位元組,
3) 結構體的總大小為結構體最寬基本型別成員大小的整數倍,如有需要, 編譯器會在最末一個成員之后加上填充位元組(trailing padding),
備注:結構體總大小是包括填充位元組,最后一個成員滿足上面兩條以外,還必須滿足第三條,否則就必須在最后填充幾個位元組以達到本條要求,
4) 結構體內型別相同的連續元素將在連續的空間內,和 陣列一樣,
5) 如果結構體記憶體在長度大于處理器位數的元素,那么就以處理器的倍數為對齊單位;否則,如果結構體內的元素的長度都小于處理器的倍數的時候,便以結構體里面最長的 資料元素為對齊單位,
2.為什么要設定結構體記憶體對齊?
一、硬體原因:加快CPU訪問的速度
我們大多數人在沒有搞清楚CPU是如何讀取資料的時候,基本都會認為CPU是一位元組一位元組讀取的,但實際上它是按照塊來讀取的,塊的大小可以為2,4,8,16,塊的大小也稱為記憶體讀取粒度,
假設CPU沒有記憶體對齊,要讀取一個4位元組的資料到一個暫存器中,(假設讀取粒度為4),則會出現兩種情況
1、資料的開始在CPU讀取的0位元組處,這剛CPU一次就你能夠讀取完畢
2、資料的開始沒在0位元組處,假設在1位元組處吧,CPU要先將0~3位元組讀取出來,在讀取4~7位元組的內容,然后將0~3位元組里的0位元組丟棄,將4~7位元組里的5,6,7位元組的資料丟棄,然后組合1,2,3,4的資料,
由此可以看出,CPU讀取的效率不是很高,可以說比較繁瑣,
但如果有記憶體對齊的話:
由于每一個資料都是對齊好的,CPU可以一次就能夠將資料讀取完成,雖然會有一些記憶體碎片,但從整個記憶體的大小來說,都不算什么,可以說是用空間換取時間的做法,
二、平臺原因:
不是所有的硬體平臺都可以訪問任意地址上的任意資料,某些硬體平臺只能在某些地址處取某些型別的資料,否則拋出硬體例外,
3.結構體大小的計算
計算結構體的大小需要按照上面的規則:
在次說明一下:
第一個成員在結構體變數偏移量為0 的地址處,
其他成員變數要對齊到某個數字(對齊數)的整數倍的地址處,對齊數 = 編譯器默認的一個對齊數與該成員大小中的較小值,vs中默認值是8 Linux默認值為4.
結構體總大小為最大對齊數的整數倍,(每個成員變數都有自己的對齊數)
如果嵌套結構體,嵌套的結構體對齊到自己的最大對齊數的整數倍處,結構體的整體大小就是所有最大對齊數(包含嵌套結構體的對齊數)的整數倍,
下面我們來實踐一下,光說不練,假把式
#include<stdio.h>
#include<string.h>
struct student
{
int age;
char a;
}stu1;
int main()
{
printf("%d", sizeof(stu1));
return 0;
}
上面這個結構體的大小是多少了?
首先按照上面的規則第一個元數放到偏移量為0的地方,第一個元素的型別是整型,大小為4個位元組,而第二個元素的a的型別是char,大小是1個位元組,而編譯器默認的最大對對齊數是8,兩者取最小值為1,那么a就要放到1的倍數下,此時a和age一共占用了5個位元組,但所有成員里面最大對齊數為4也就是age,5并不是4的倍數,所以編譯器會浪費3個位元組的空間對齊,所以這個結構體的大小為8
運行結果:
下面我們再來看一道題
#include<stdio.h>
#include<string.h>
struct student
{
char c1;
char c2;
int i;
}stu1;
int main()
{
printf("%d", sizeof(stu1));
return 0;
}運行結果:
結果是8,我們來分析一下為什么結果是 8??
c1是char型,占一個位元組,第一個成員即 c1 在結構體變數偏移量為0 的地址處,
c2是char型,占一個位元組,要對齊到對齊數的整數倍的位置,對齊數 = 編譯器默認的一個對齊數與該成員大小中的較小值,vs中默認值是8,取較小值1,char型別的對齊數是1,所以對齊到1 的整數倍,那就是偏移量為1開始的地址空間,
i是int型別,占四個位元組,要對齊到對齊數的整數倍的位置,int型別的對齊數就是 4,所以對齊到4 的整數倍,
我們來看一下記憶體分布圖:
記憶體分布圖:

那么這一個結果又是多少了?
#include<stdio.h>
#include<string.h>
struct student
{
char c1;
int i;
char c2;
}stu1;
int main()
{
printf("%d", sizeof(stu1));
return 0;
}運行結果:
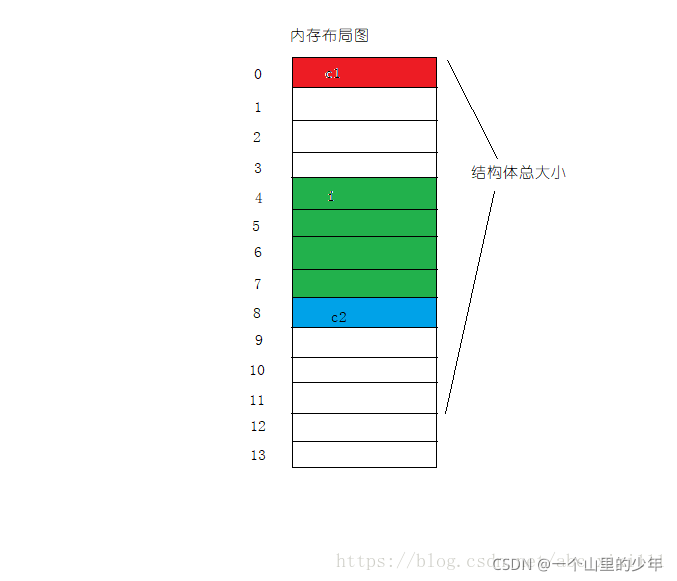
結果是12,來看一下程序?
c1是char型,占一個位元組,對應到結構體變數偏移量為0 的地址處,
i是int型,占四個位元組,對齊數就是4,對齊到4的整數倍位置處,即偏移量為4開始的地址空間,
c2是char型,占一個位元組,對齊到1 的整數倍,那就是下一個地址空間,對齊到偏移量為8的地址空間,
結構體總大小為最大對齊數的整數倍,所以為對齊數4的整數倍,現在已經用了9個位元組的空間,那么總大小就是12個位元組空間,所以輸出結果是12,
記憶體圖:
下面我們在來看一個例子結構體嵌套結構體的大小又應該如何計算
例:
#include<stdio.h>
struct s3
{
double d;
char c;
int i;
};
struct s4
{
char c1;
struct s3 s;
double d;
};
int main()
{
struct s4 t;
printf("%d ", sizeof(t));
}運行結果:
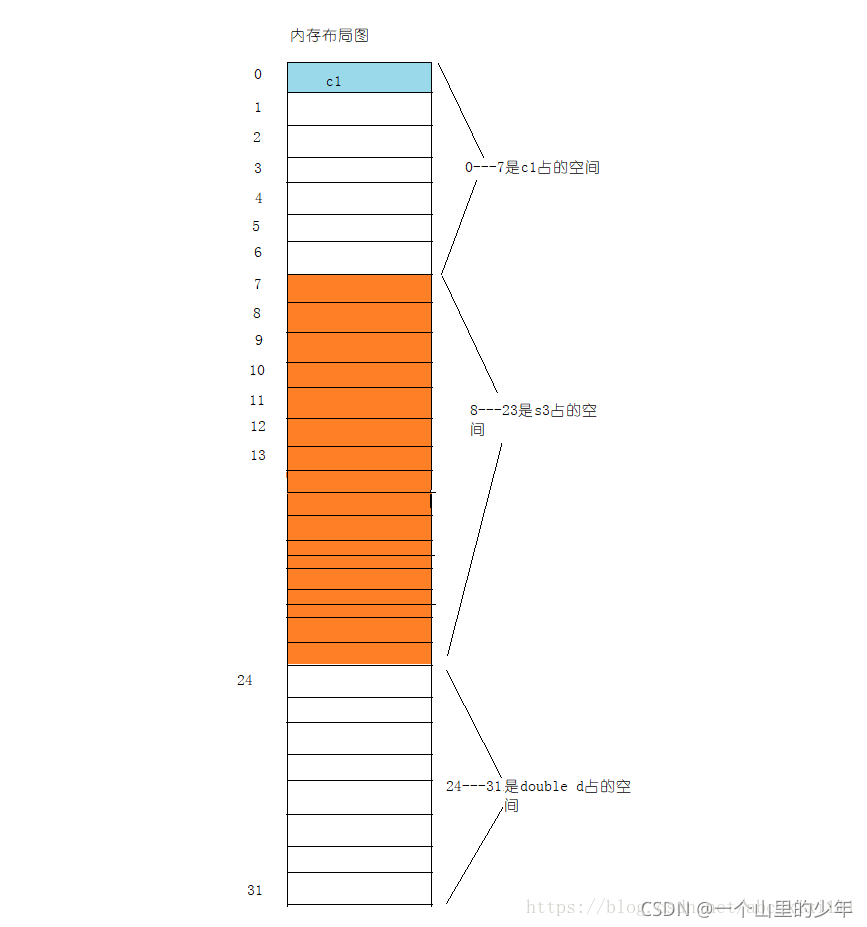
結果是32,我們來看一下分析:
容易得出struct S3占16個位元組,請讀者自行分析,如果不會的話可以問我哦,
那我們來看一下struct S4的大小,struct S4中有三個成員變數,第一個char型,占一個位元組,對齊到偏移量為0的地址處,第二個成員是結構體嵌套使用,結構體S3變數s3,剛才已經得出占16個位元組,所以第二個成員對齊數是16,又因為對齊數是編譯器默認數與成員對齊數中的較小值,vs默認對齊數是8,取較小值8,所以對齊到偏移量為8的地址空間,處,第三個成員是double型,占8個位元組,對應到8的整數倍即偏移量24的地址處,
結構體總大小是最大對齊數8的整數倍,所以是32,
來看一下記憶體分布圖:
#pragma pack()修改默認對齊數
簡單理解#pragma
作為較為復雜的預處理指令之一,它的作用為更改編譯器的編譯狀態以及為特定的編譯器提供特定的編譯指示,這些指示是具體針對某一種(或某一些)編譯器的,其他編譯器可能不知道該指示的含義又或者對該指示有不同的理解,也即是說,#pragma的實作是與具體平臺相關的,可以簡單將其理解為該預處理指令是開發者和編譯器互動的一個工具,
#pragma pack指令說明
由于記憶體的讀取時間遠遠小于CPU的存盤速度,這里用設定資料結構的對齊系數,即犧牲空間來換取時間的思想來提高CPU的存盤效率,
這里先說編譯器的對齊配置,以vc6為例,vc6中的編譯選項有 /Zp[1|2|4|8|16] ,/Zp1表示以1位元組邊界對齊,相應的,/Zpn表示以n位元組邊界對齊,n位元組邊界對齊的意思是說,一個成員的地址必須安排在成員的尺寸的整數倍地址上或者是n的整數倍地址上,取它們中的最小值,也就是:
min ( sizeof ( member ), n)
實際上,1位元組邊界對齊也就表示了結構成員之間沒有空洞,
/Zpn選項是應用于整個工程的,影響所有的參與編譯的結構,
例子:
#include<stdio.h>
#pragma pack(1)
struct s4
{
char c1;
double d;
};
int main()
{
struct s4 t;
printf("%d ", sizeof(t));
}運行結果:
答案為9,我們通過#pragma修改了默認對齊數,修改為1,所有成員的大小和1取最小值,那么所有成員的對齊數為1,也就是挨著放的,9所以大小為9
offfsetof及其實作
offsetof是一個庫函式在<stddef.h>中,其作用是計算成員變數在結構體中的偏移量·
函式原型:
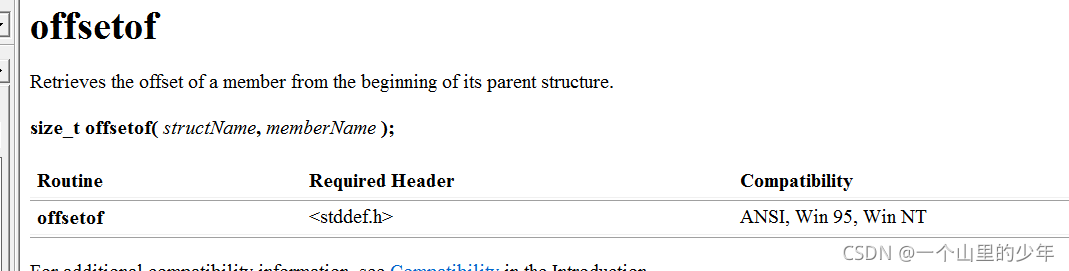
如何使用了:
#include<stdio.h>
#include<stddef.h>
struct s4
{
char c1;
double d;
};
int main()
{
struct s4 t;
printf("%d ", offsetof(struct s4, d));
}運行結果:
原理已經在上面說過了在這里就不過多贅述
實作offsetof,他實際是一個宏
代碼實作:
#include<stdio.h>
#include<stddef.h>
#define OFFSETOFF(struct_type ,member)(int)&((struct_type*)0)->member
struct s4
{
char c1;
int a;
double d;
};
int main()
{
printf("%d ", OFFSETOFF(struct s4, a));
}第一個引數是結構體的名字,第二個引數是結構體成員的名字,回傳的是該成員在結構體中的偏移量
這個宏的實作巧妙之處在于,將起始的物件的地址強制賦為0, 即是(struct_type*)0這里.那么回傳的(struct_type*)0->member即是成員的偏移量了.
注意:這個結構并沒有申請記憶體空間,卻要去訪問其成員,按常理不是會出錯,因為訪問了未申請的記憶體空間.
但是,在這里我們實際并沒有訪問結構成員的記憶體空間,只是回傳其地址值,我們用的是取址運算子.而這里的值是編繹器在編繹階段便已經計算好的,hs
聯合體
什么是聯合體?在C語言中,變數的定義是分配存盤空間的程序,一般的,每個變數都具有其獨有的存盤空間,那么可不可以在同一個記憶體空間中存盤不同的資料型別(不是同事存盤)呢?
答案是可以的,使用聯合體就可以達到這樣的目的,聯合體也叫共用體,在C語言中定義聯合體的關鍵字是union,
1.定義一個聯合體的格式和結構體類似
union 聯合體名{
成員串列
};
成員串列中有若干成員,成員形式一般為:型別說明符 成員名,
與結構體,列舉一樣,聯合體也是一種構造型別
2.聯合體定義的方法
方法一:先創建模板后定義變數
#include<stdio.h>
union student{
int a;
char c;
};
int main()
{
union student s1;
return 0;
}方法二:創建模板和變數
#include<stdio.h>
union student
{
int a;
char c;
}s1;
int main()
{
return 0;
}方法三:省略聯合體名,也就是匿名聯合體
#include<stdio.h>
union
{
int a;
char c;
}s1;
int main()
{
return 0;
}聯合體的初始化和結構體基本一樣,在這里就不過多贅述
2.聯合體的大小計算
當沒有定義#pragma pack()這種指定value位元組對齊時,他的計算規則時聯合體中最大成員所占的記憶體的大小,并且必須為最大型別所占位元組的倍數
下面我們來看一個例子:
#include<stdio.h>
union
{
char s[10];
int a;
}s1;
int main()
{
printf("%d", sizeof(s1));
return 0;
}運行結果:
在這個聯合體中最大的成員的大小為10也就是那個陣列,但是最大型別所占位元組數的大小為4.并不是4的整數倍所以編譯器會浪費2個位元組,所以大小為12個位元組
3.使用聯合體判斷大小端:
聯合體的概念和特征:union維護足夠的空間來存放多個資料成員中的“一種”,而不為每一個資料成員都配置空間,在union中所有的成員共用同一個空間,同一時間只存盤一個資料成員,最大的特征就是所有的資料成員具有相同的起始地址即聯合體的基地址,
2)計算機中位元組存盤主要有兩種:大端模式(Big_endian)和小端模式(Little_endian),從英文名字上可以明白,大端模式是從低地址開始,高位結束,(即高地址存地位,低地址存高位);小端模式是從高地址開始,低地址結束(與大端相反,),
3)利用union中所有資料成員具有同樣的起始地址的特點,通過一個int成員存盤1,然后通過char成員來讀取,即可巧妙地得出資料存放的方式,若通過char成員(即讀取起始位置上的第一個位元組)讀取,若得出值為1,則說明是小端模式,
代碼如下:
#include<stdio.h>
union stu
{
int a;
char c;
};
int main()
{
union stu s;
s.a = 1;
if (s.c == 1)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}博主實力有限如有錯誤請在評論區留言,如果覺得寫的不錯可以點個贊,謝謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/303085.html
標籤:其他
上一篇:【Java】認識Sring、String的常見操作和StringBuffer 和StringBuilder的區別【字串詳解】