總結了一些近幾天遇到模糊的問題,記錄一下,
時間:09-30
文章目錄
- 智能指標
- 智能指標的作用
- 說說你了解的auto_ptr
- 智能指標的回圈參考如何解決
- 手寫實作智能指標類需要實作哪些函式?
- 宏定義最小值和最大值
- 同步和異步
- 堆排序介紹及代碼
- 三種基本狀態
- 什么是自旋鎖
- 用戶態和內核態
- 超時重傳的問題
- TCP快速重傳為什么要三次
- epoll 水平(LT)和邊沿觸發(第二個回答好一點)
- 各種排序時間復雜度分析
- 為什么選擇快排而非歸并
- socket tcp http三者的區別
智能指標
代碼例子
- shared_ptr
- 實作原理: 采用參考計數器的方法,允許多個智能指標指向同一個物件,每當多一個指標指向該物件時,指向該物件的所有智能指標內部的參考計數加1,每當減少一個智能指標指向物件時,參考計數會減1,當計數為0的時候會自動的釋放動態分配的資源,
- 智能指標將一個計數器與類指向的物件相關聯,參考計數器跟蹤共有多少個類物件共享同一指標
- 每次創建類的新物件時,初始化指標并將參考計數置為1
- 當物件作為另一物件的副本而創建時,拷貝建構式拷貝指標并增加與之相應的參考計數(
鏈接有例子) - 對一個物件進行賦值時,賦值運算子減少左運算元所指物件的參考計數(如果參考計數為減至0,則洗掉物件),并增加右運算元所指物件的參考計數
- 呼叫解構式時,建構式減少參考計數(如果參考計數減至0,則洗掉基礎物件)
- unique_ptr
- unique_ptr采用的是獨享所有權語意,
一個非空的unique_ptr總是擁有它所指向的資源,轉移一個unique_ptr將會把所有權全部從源指標轉移給目標指標,源指標被置空;所以unique_ptr不支持普通的拷貝和賦值操作,不能用在STL標準容器中;區域變數的回傳值除外(因為編譯器知道要回傳的物件將要被銷毀);如果你拷貝一個unique_ptr,那么拷貝結束后,這兩個unique_ptr都會指向相同的資源,造成在結束時對同一記憶體指標多次釋放而導致程式崩潰,
- unique_ptr采用的是獨享所有權語意,
- weak_ptr
- weak_ptr:弱參考, 參考計數有一個問題就是互相參考形成環(環形參考),這樣兩個指標指向的記憶體都無法釋放,需要使用weak_ptr打破環形參考,weak_ptr是一個弱參考,它是為了配合shared_ptr而引入的一種智能指標,它指向一個由shared_ptr管理的物件而不影響所指物件的生命周期,也就是說,它只參考,不計數,如果一塊記憶體被shared_ptr和weak_ptr同時參考,當所有shared_ptr析構了之后,不管還有沒有weak_ptr參考該記憶體,記憶體也會被釋放,所以weak_ptr不保證它指向的記憶體一定是有效的,在使用之前使用函式lock()檢查weak_ptr是否為空指標,
- auto_ptr
- 主要是為了解決“有例外拋出時發生記憶體泄漏”的問題 ,因為發生例外而無法正常釋放記憶體,auto_ptr有拷貝語意,拷貝后源物件變得無效,這可能引發很嚴重的問題;而unique_ptr則無拷貝語意,但提供了移動語意,這樣的錯誤不再可能發生,因為很明顯必須使用std::move()進行轉移,auto_ptr不支持拷貝和賦值操作,不能用在STL標準容器中,STL容器中的元素經常要支持拷貝、賦值操作,在這程序中auto_ptr會傳遞所有權,所以不能在STL中使用,
智能指標shared_ptr代碼實作:
template<typename T>
class SharedPtr
{
public:
SharedPtr(T* ptr = NULL):_ptr(ptr), _pcount(new int(1))
{}
SharedPtr(const SharedPtr& s):_ptr(s._ptr), _pcount(s._pcount){
(*_pcount)++;
}
SharedPtr<T>& operator=(const SharedPtr& s){
if (this != &s)
{
if (--(*(this->_pcount)) == 0)
{
delete this->_ptr;
delete this->_pcount;
}
_ptr = s._ptr;
_pcount = s._pcount;
*(_pcount)++;
}
return *this;
}
T& operator*()
{
return *(this->_ptr);
}
T* operator->()
{
return this->_ptr;
}
~SharedPtr()
{
--(*(this->_pcount));
if (*(this->_pcount) == 0)
{
delete _ptr;
_ptr = NULL;
delete _pcount;
_pcount = NULL;
}
}
private:
T* _ptr;
int* _pcount;//指向參考計數的指標
};
智能指標的作用
-
C++11中引入了智能指標的概念,方便管理堆記憶體,
使用普通指標,容易造成堆記憶體泄露(忘記釋放),二次釋放,程式發生例外時記憶體泄露等問題等,使用智能指標能更好的管理堆記憶體, -
智能指標在C++11版本之后提供,包含在頭檔案中,shared_ptr、unique_ptr、weak_ptr,shared_ptr多個指標指向相同的物件,
shared_ptr使用參考計數,每一個shared_ptr的拷貝都指向相同的記憶體,每使用他一次,內部的參考計數加1,每析構一次,內部的參考計數減1,減為0時,自動洗掉所指向的堆記憶體,shared_ptr內部的參考計數是執行緒安全的,但是物件的讀取需要加鎖, -
初始化,
智能指標是個模板類,可以指定型別,傳入指標通過建構式初始化,也可以使用make_shared函式初始化,不能將指標直接賦值給一個智能指標,一個是類,一個是指標,例如std::shared_ptr<int> p4 = new int(1);的寫法是錯誤的, -

-
unique_ptr“唯一”擁有其所指物件,
同一時刻只能有一個unique_ptr指向給定物件(通過禁止拷貝語意、只有移動語意來實作 鏈接有例子),相比與原始指標unique_ptr用于其RAII的特性,使得在出現例外的情況下,動態資源能得到釋放,unique_ptr指標本身的生命周期:從unique_ptr指標創建時開始,直到離開作用域,離開作用域時,若其指向物件,則將其所指物件銷毀(默認使用delete運算子,用戶可指定其他操作),unique_ptr指標與其所指物件的關系:在智能指標生命周期內,可以改變智能指標所指物件,如創建智能指標時通過建構式指定、通過reset方法重新指定、通過release方法釋放所有權、通過移動語意轉移所有權, -
智能指標類將一個計數器與類指向的物件相關聯,參考計數跟蹤該類有多少個物件共享同一指標,每次創建類的新物件時,初始化指標并將參考計數置為1;當物件作為另一物件的副本而創建時,拷貝建構式拷貝指標并增加與之相應的參考計數;對一個物件進行賦值時,賦值運算子減少左運算元所指物件的參考計數(如果參考計數為減至0,則洗掉物件),并增加右運算元所指物件的參考計數;呼叫解構式時,建構式減少參考計數(如果參考計數減至0,則洗掉基礎物件),
-
weak_ptr 是一種不控制物件生命周期的智能指標, 它指向一個 shared_ptr 管理的物件. 進行該物件的記憶體管理的是那個強參考的 shared_ptr. weak_ptr只是提供了對管理物件的一個訪問手段,
weak_ptr 設計的目的是為配合 shared_ptr 而引入的一種智能指標來協助 shared_ptr 作業, 它只可以從一個 shared_ptr 或另一個 weak_ptr 物件構造, 它的構造和析構不會引起參考記數的增加或減少.
說說你了解的auto_ptr
-
auto_ptr的出現,主要是為了解決“
有例外拋出時發生記憶體泄漏”的問題;拋出例外,將導致指標p所指向的空間得不到釋放而導致記憶體泄漏; -
auto_ptr構造時取得某個物件的控制權,
在析構時釋放該物件,我們實際上是創建一個auto_ptr型別的區域物件,該區域物件析構時,會將自身所擁有的指標空間釋放,所以不會有記憶體泄漏; -
auto_ptr的建構式是explicit,阻止了一般指標隱式轉換為 auto_ptr的構造,
所以不能直接將一般型別的指標賦值給auto_ptr型別的物件,必須用auto_ptr的建構式創建物件; -
由于auto_ptr物件析構時會洗掉它所擁有的指標,所以使用時避免多個auto_ptr物件管理同一個指標; -
Auto_ptr內部實作,解構式中洗掉物件用的是delete而不是delete[],所以auto_ptr不能管理陣列; -
auto_ptr支持所擁有的指標型別之間的隱式型別轉換, -
可以通過*和->運算子對auto_ptr所有用的指標進行提領操作; -
T* get(),獲得auto_ptr所擁有的指標;T* release(),釋放auto_ptr的所有權,并將所有用的指標回傳, -
換種說法
就是幫我們C++程式員管理動態分配的記憶體的,它會幫助我們自動釋放new出來的記憶體,從而避免記憶體泄漏!
存在以下幾個問題
- 復制和賦值會改變資源的所有權,不符合人的直覺,
- 在 STL 容器中使用auto_ptr存在重大風險,因為容器內的元素必需支持可復制(copy constructable)和可賦值(assignable),
- 不支持物件陣列的操作 因為 delete 非 delete[]
常用三個操作
get() 獲取智能指標托管的指標地址
release() 取消智能指標對動態記憶體的托管
- reset() 重置智能指標托管的記憶體地址,如果地址不一致,原來的會被析構掉
幾個建議
- 盡可能不要將auto_ptr 變數定義為全域變數或指標;
- 除非自己知道后果,不要把auto_ptr 智能指標賦值給同型別的另外一個 智能指標;(改變所有權)
- C++11用更嚴謹的unique_ptr 取代了auto_ptr!
智能指標的回圈參考如何解決
- 回圈參考是指使用多個智能指標share_ptr時,出現了指標之間相互指向,從而形成環的情況,有點類似于死鎖的情況,這種情況下,智能指標往往不能正常呼叫物件的解構式,從而造成記憶體泄漏,
例子上面的鏈接有 弱指標用于專門解決shared_ptr回圈參考的問題,weak_ptr不會修改參考計數,即其存在與否并不影響物件的參考計數器,回圈參考就是:兩個物件互相使用一個shared_ptr成員變數指向對方,弱參考并不對物件的記憶體進行管理,在功能上類似于普通指標,然而一個比較大的區別是,弱參考能檢測到所管理的物件是否已經被釋放,從而避免訪問非法記憶體,
手寫實作智能指標類需要實作哪些函式?
-
智能指標是一個資料型別,
一般用模板實作,模擬指標行為的同時還提供自動垃圾回識訓制,它會自動記錄SmartPointer<T*>物件的參考計數,一旦T型別物件的參考計數為0,就釋放該物件, -
除了指標物件外,
我們還需要一個參考計數的指標設定物件的值,并將參考計數計為1,需要一個建構式,新增物件還需要一個建構式,解構式負責參考計數減少和釋放記憶體, -
通過覆
寫賦值運算子,才能將一個舊的智能指標賦值給另一個指標 -
一個建構式、拷貝建構式、復制建構式、解構式、移動函式;

宏定義最小值和最大值
- #define MAX(A,B) ( (A) > (B) ? (A) : (B))
- #define MIN(A,B) ( (A) > (B) ? (B) : (A))
需要注意的是:
1 宏定義的變數在參考的時候,用()括起來,防止預編譯器展開的錯誤
2 (a > b ? action1 : action2 ) 這樣的方式和 if —else 結果一樣,但他會使得編譯器產生更優化的代碼,這在嵌入式編程中比較重要,
- 當然也有第二種實作方式:參考鏈接
同步和異步
-
同步:是所有的操作都做完了,寫入服務器資料庫當中才會通知用戶執行成功,這樣的話會造成服務器壓力過大,而且用戶的體驗效果也不是很好,
-
異步:不用等待服務器資料庫是否寫入,而是先通知用戶執行成功,隨后在慢慢的寫入服務器資料庫,這樣會減輕服務器的壓力,同時對用戶的體驗效果很好,
-
第二種回答(更合適)
-
添加鏈接描述
-
阻塞和非阻塞 同步和異步(這個講的非常好)
-
二三結合一起看,內核把資料拷到行程空間 然后再通過其他方式通知我 (回呼函式 狀態)
堆排序介紹及代碼
- 大堆頂 根結點是最大值 的堆,用于維護和查詢 max、
- 第 i 個結點的 父結點 下標 為 (i-1)/2 ;
- 第 i 個結點的 左子結點 下標 為 2i+1 ;
- 第 i 個結點的 右子結點 下標 為 2i+2 ;
- 最后一個非葉子結點 下標為:n/2 -1(也可以理解成 最后一個節點坐標是 n-1 帶入第一個公式 就是 (n-2)/2)
- 思想就是: 將一個長為n的序列構造成一個大頂堆,則整個序列的最大值就是堆頂的根結點, 將最大值結點與末尾結點的值互換,此時末尾結點的值就是最大值,(即陣列的最后一個元素為最大值) ,然后將剩余的 n-1個序列重新構造成一個大頂堆,再將n-1序列的最大值與末尾結點的值互換,就會得到 次最大值, 如此重復執行,就可以得到一個有序序列了,
區域調整向下,從后向前建立(右下)
#include<iostream>
#include <algorithm>
using namespace std;
//調整的函式
//需要傳入的引數
// 1陣列
// 2陣列的調整的長度(最大下標+1)
// 3調整的起始點(下標)
void heapify(int* tree, int n, int i)
{
if (i >= n) return;
//左子結點
int c1 = i * 2 + 1;
//右子結點
int c2 = i * 2 + 2;
//假設最大值坐標是根結點,獲取左右子結點的最大值
int max = i;
if (c1<n && tree[c1]>tree[max])
{
max = c1;
}
if (c2<n && tree[c2]>tree[max])
{
max = c2;
}
if (max != i)
{
//將左右子樹的最大值賦給父結點
swap(tree[max],tree[i]);
//較小的值,被賦給左子樹或右子樹,則左子樹或右子樹 需要重新建堆
heapify(tree,n,max);
}
}
void build_heap(int *tree, int n)
{
int last_node = n - 1;
//最后一個結點的父節點 下標,即最后一個非葉子結點
int parent = (last_node - 1) / 2;
//針對最后一個父節點的 及其前面的父節點進行建堆
for (int i =parent; i>=0; i--)
{
heapify(tree,n,i);
}
}
// 實作整體排序
void heap_sort(int *tree, int n)
{
//建立一個堆 從后向前建立
build_heap(tree,n);
//回圈不斷把最大值放在最后 并且對第一個值進行區域調整
for (int i = n-1; i>=0; i--)
{
//堆頂與末尾結點值交換
swap(tree[i], tree[0]);
//每次把第一個移到最后 最后一個移上來 然后進行區域調整
heapify(tree,i,0);//注意這邊的i 放入i的下標 剩余i個元素
}
}
int main()
{
int tree[] = { 7,10,15,30,35,23,40 };
int n = 7;
heap_sort(tree,n);
for (int i=0;i<n;i++)
{
cout << tree[i]<<" ";
}
cout<< endl;
return 0;
}
- 參考鏈接
三種基本狀態
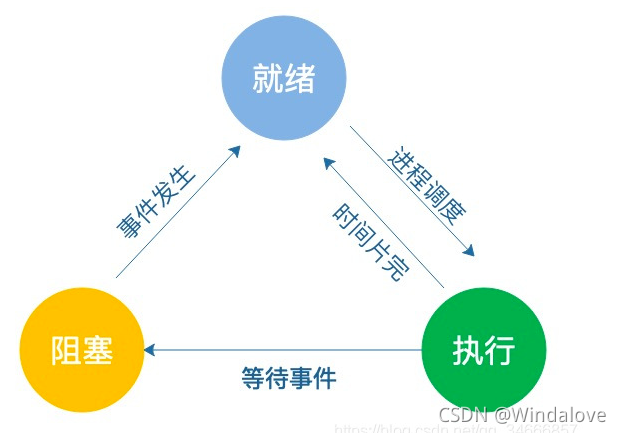
- 就緒態—>執行態:行程獲得CPU(被調度程式選中);
- 執行態—>阻塞態:向OS請求共享資源(互斥、同步)失敗、等待某種操作完成、新資料尚未到達(I/O操作)、等待新任務的到達;
- 阻塞態—>阻塞態:上述的四類等待事件發生;
執行態—>就緒態:分配給行程的時間片執行完成(輪轉調度演算法)、高優先級的行程到達(搶占式調度),
什么是自旋鎖


- 參考鏈接
用戶態和內核態
- 參考鏈接
超時重傳的問題
- 當一個報文段丟失時,會等待一定的超時周期然后才重傳分組,增加了端到端的時延,
- 當一個報文段丟失時,在其等待超時的程序中,可能會出現這種情況:其后的報文段已經被接收端接收但卻遲遲得不到確認,發送端會認為也丟失了,從而引起不必要的重傳,既浪費資源也浪費時間,
TCP快速重傳為什么要三次
- 冗余ACK的概念
- 即當接收端收到比期望序號大的報文段時,便會重復發送最近一次確認的報文段的確認信號,我們稱之為冗余ACK(duplicate ACK),
- 什么是快速重傳
- 如果在超時重傳定時器溢位之前,接收到連續的三個重復冗余ACK(其實是收到4個同樣的ACK,第一個是正常的,后三個才是冗余的),發送端便知曉哪個報文段在傳輸程序中丟失了,于是重發該報文段,不需要等待超時重傳定時器溢位,大大提高了效率,這便是快速重傳機制,
- 為啥是三次
-
即使發送端是
按序發送,由于TCP包是封裝在IP包內,IP包在傳輸時亂序,意味著TCP包到達接收端也是亂序的,亂序的話也會造成接收端發送冗余ACK,那發送冗余ACK是由于亂序造成的還是包丟失造成的,這里便需要好好權衡一番,因為把3次冗余ACK作為判定丟失的準則其本身就是估計值, -
在沒丟失的情況下,有40%的可能出現3次冗余ACK
-
在亂序的情況下必定是2次冗余ACK
-
在丟失的情況下,必定出現3次冗余ACK
-
基于這樣的概率,選定3次冗余ACK作為閾值也算是合理的,在實際抓包中,大多數的快速重傳都會在大于3次冗余ACK后發生,
-
epoll 水平(LT)和邊沿觸發(第二個回答好一點)
- 參考1 有代碼
epoll水平觸發: 只要監聽的檔案描述符中有資料,就會觸發epoll_wait有回傳值,這是默認的epoll_wait的方式;
epoll邊沿觸發 : 只有監聽的檔案描述符的讀/寫事件發生,才會觸發epoll_wait有回傳值;
通過epoll_ctl函式,設定該檔案描述符的觸發狀態即可
//水平觸發
evt.events = EPOLLIN; // LT 水平觸發 (默認) EPOLLLT
evt.data.fd = pfd[0];
//邊沿觸發
evt.events = EPOLLIN | EPOLLET; // ET 邊沿觸發
evt.data.fd = pfd[0];
-
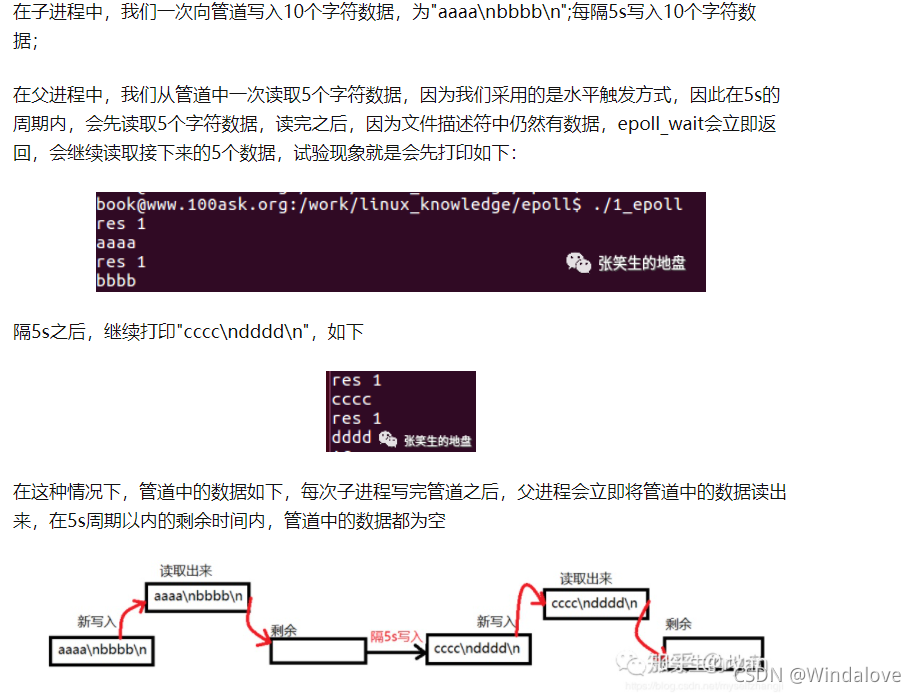
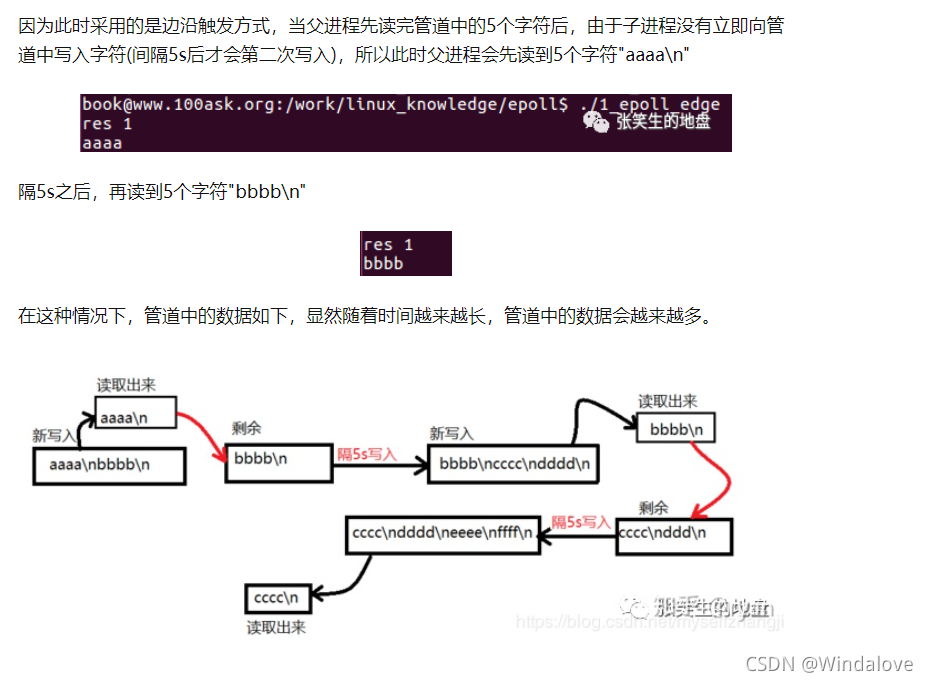
管道+epoll的例子
-
換一種說法:參考2
-
Level_triggered(水平觸發):當被監控的檔案描述符上有可讀寫事件發生時,
epoll_wait()會通知處理程式去讀寫,如果這次沒有把資料一次性全部讀寫完(如讀寫緩沖區太小),那么下次呼叫 epoll_wait()時,它還會通知你在上沒讀寫完的檔案描述符上繼續讀寫,當然如果你一直不去讀寫,它會一直通知你!!!如果系統中有大量你不需要讀寫的就緒檔案描述符,而它們每次都會回傳,這樣會大大降低處理程式檢索自己關心的就緒檔案描述符的效率!!! -
Edge_triggered(邊緣觸發):當被監控的檔案描述符上有可讀寫事件發生時
,epoll_wait()會通知處理程式去讀寫,如果這次沒有把資料全部讀寫完(如讀寫緩沖區太小),那么下次呼叫epoll_wait()時,它不會通知你,也就是它只會通知你一次,直到該檔案描述符上出現第二次可讀寫事件才會通知你(根據上一個說法 資料應該還是在的)!!!這種模式比水平觸發效率高,系統不會充斥大量你不關心的就緒檔案描述符!!!

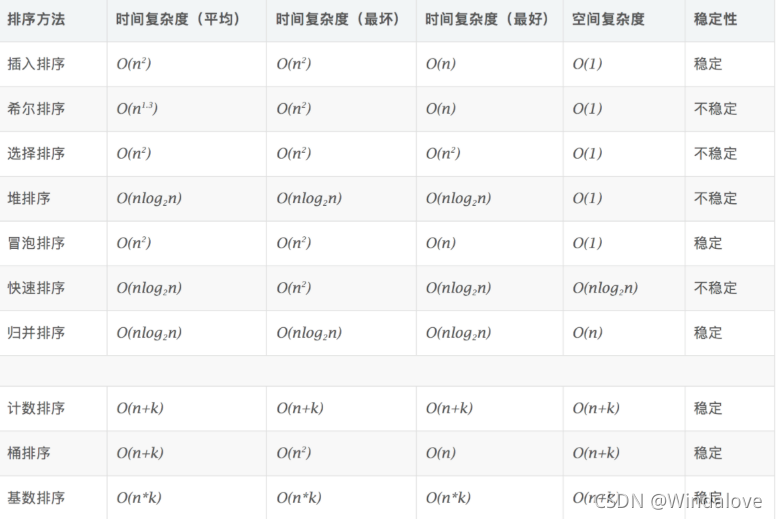
各種排序時間復雜度分析
- 1
為什么選擇快排而非歸并

2.《演算法圖解》說過另一個方面:雖然平均時間復雜度都是 O(logN), 但歸并排序的常數部分比快排大,因而速度慢
socket tcp http三者的區別
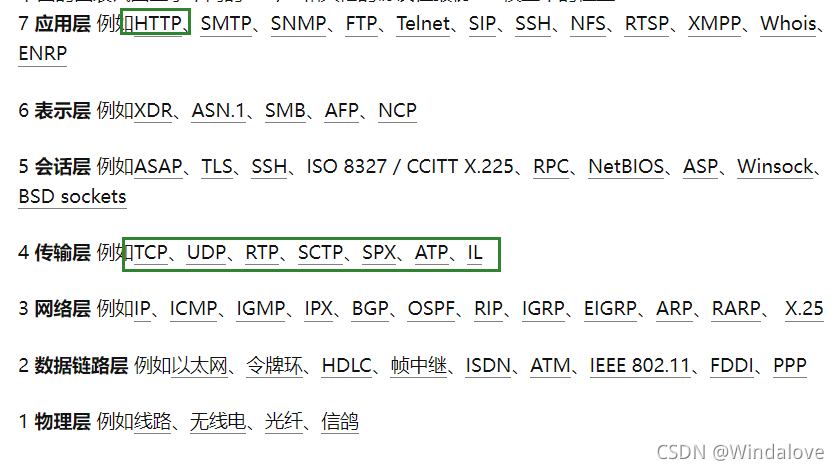
-
1、TCP/IP連接 :手機能夠使用聯網功能是因為手機底層實作了TCP/IP協議,可以使手機終端通過無線網路建立TCP連接,TCP協議可以對上層網路提供介面,使上層網路資料的傳輸建立在“無差別”的網路之上,
-
2、HTTP連接:HTTP協議即超文本傳送協議(Hypertext Transfer Protocol ),是Web聯網的基礎,也是手機聯網常用的協議之一,HTTP協議是建立在TCP協議之上的一種應用,HTTP連接最顯著的特點是客戶端發送的每次請求都需要服務器回送回應,在請求結束后,會主動釋放連接,從建立連接到關閉連接的程序稱為“一次連接”,(1.1 就另說了)
-
3、SOCKET原理:套接字(socket)是通信的基石,是支持TCP/IP協議的網路通信的基本操作單元,它是網路通信程序中端點的抽象表示,包含進行網路通信必須的五種資訊:連接使用的協議,本地主機的IP地址,本地行程的協議埠,遠地主機的IP地址,遠地行程的協議埠,
-
socket則是對TCP/IP協議的封裝和應用(程式員層面上),也可以說,TPC/IP協議是傳輸層協議,主要解決資料 如何在網路中傳輸,而HTTP是應用層協議,主要解決如何包裝資料,
-
“我們在傳輸資料時,可以只使用(傳輸層)TCP/IP協議,但是那樣的話,如 果沒有應用層,便無法識別資料內容,如果想要使傳輸的資料有意義,則必須使用到應用層協議,應用層協議有很多,比如HTTP、FTP、TELNET等,也 可以自己定義應用層協議,WEB使用HTTP協議作應用層協議,以封裝HTTP文本資訊,然后使用TCP/IP做傳輸層協議將它發到網路上,”
-
TCP/IP只是一個協議堆疊,就像作業系統的運行機制一樣,必須要具體實作,同時還要提供對外的操作介面,這個就像作業系統會提供標準的編程介面,比如win32編程介面一樣,TCP/IP也要提供可供程式員做網路開發所用的介面,這就是Socket編程介面,
-參
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/304723.html
標籤:其他
上一篇:計算機網路基礎-1
下一篇:計算機網路(謝希仁 第七版) 第一章(概述) -- 1.7 計算機網路的體系結構(計算機網路體系結構的形成、協議與層次劃分、具有五層協議的體系結構)