pyspark dataframe資料連接(join)、轉化為pandas dataframe、基于多個欄位洗掉冗余資料
目錄
pyspark dataframe資料連接(join)、轉化為pandas dataframe、基于多個欄位洗掉冗余資料
#pyspark dataframe的連接操作并洗掉無用欄位
#查看dataframe的shape
#把dataframe從pyspark轉化到pandas dataframe
#基于混合欄位洗掉重復記錄
#pyspark dataframe的連接操作并洗掉無用欄位
tijian_with_baseInfo_df = customer_df.join(base_info_df,base_info_df.XH == tijian_with_baseInfo_df.XH)\
.drop(base_info_df.XH)\
.drop(base_info_df.sex)\
.drop(base_info_df.x)\
.drop(base_info_df.y)\
.drop(base_info_df.x1)\
.drop(base_info_df.x4)\
.drop(base_info_df.x5)\
.drop(base_info_df.xx)#查看dataframe的shape
tijian_with_baseInfo_df.count(),len(tijian_with_baseInfo_df.columns)#把dataframe從pyspark轉化到pandas dataframe
tijian_with_baseInfo_pdf = tijian_with_baseInfo_df.toPandas()#基于混合欄位洗掉重復記錄
tijian_with_baseInfo_pdf = tijian_with_baseInfo_pdf.drop_duplicates(subset = ['x1','x2','x3','z1',],keep = 'first')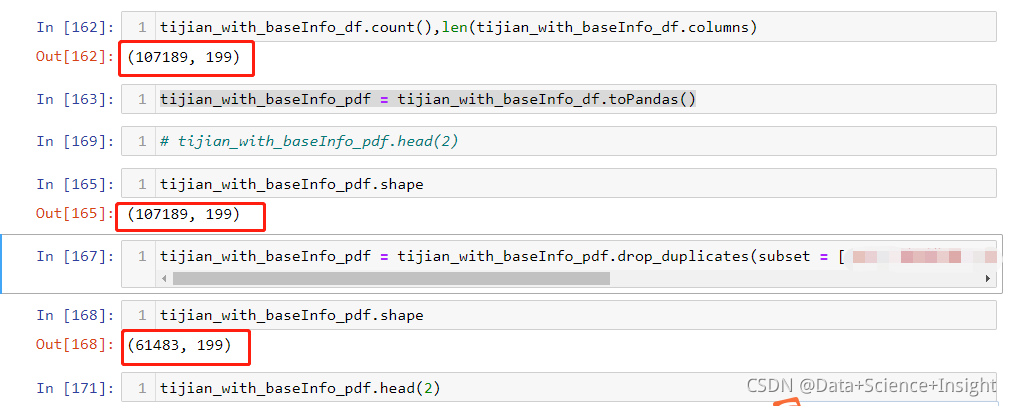
參考:python
參考:pyspark
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/304785.html
標籤:其他
上一篇:計算機網路(謝希仁 第七版) 第一章(概述) -- 1.7 計算機網路的體系結構(計算機網路體系結構的形成、協議與層次劃分、具有五層協議的體系結構)