
[C++]入門學習的前言與內容的講解分析
- 引言
- 一、C++學習前言
- 1.1、什么是C++
- 1.2、C++發展史
- 1.3、C++學習的重要性
- 1.3.1語言的使用廣泛
- 1.3.2在作業領域
- 1.3.3招聘需求
- 二、C++入門知識
- 2.1、C++關鍵字
- 2.2、命名空間
- 2.2.1引言
- 2.2.2命名空間的定義
- 2.2.3命名空間的使用
- 2.3、C++輸入&輸出
- 2.4、預設引數
- 2.4.1全預設引數
- 2.4.2半預設引數
- 2.5、函式多載
- 2.5.1名字修飾
- 2.5.2return "C"
- 2.6、參考
- 2.6.1應用的特性
- 2.6.2常參考
- 2.6.3 使用場景
- 2.6.3.1做回傳值
- 2.6.3.2做引數
- 2.6.4參考&傳值的效率比較(了解)
- 2.6.5參考&指標的比較(了解)
- 2.7、行內函式
- 2.8、auto關鍵字(C++11)
- 2.9、基于范圍的for回圈(C++11)
- 2.10、指標空值——nullptr(C++11)
- 總結
引言
相信我們這些接觸過計算機的學生,都或多或少聽過C++這一門語言,我們或多或少有過一些想法,C++是什么?是C語言的升級嗎?還是說是一門全新的語言?C++難學么?上述的內容在我接觸C++之前也有過思考,在這里我們就話不多數,將更多的精力花在實實在在的知識方面的學習,下面然我們開始我們的C++學習之旅,
一、C++學習前言
1.1、什么是C++

①C語言是結構化和模塊化的語言,適合處理較小規模的程式,對于復雜的問題,規模較大的程式,需要高度的抽象和建模時,C語言則不合適,為了解決軟體危機, 20世紀80年代, 計算機界提出了OOP(objectoriented programming:面向物件)思想,支持面向物件的程式設計語言應運而生,

②1982年,Bjarne Stroustrup博士在C語言的基礎上引入并擴充了面向物件的概念,發明了一種新的程式語言,為了表達該語言與C語言的淵源關系,命名為C++,因此:C++是基于C語言而產生的,它既可以進行C語言的程序化程式設計,又可以進行以抽象資料型別為特點的基于物件的程式設計,還可以進行面向物件的程式設計,
③換一句話說,C++的創建就是補充C語言中沒有的內容,同時更加方便的使用一些庫函式,省去了我們C語言時期的“什么都要自己造”的時代,
1.2、C++發展史
或許我們會對C++的發展史有所忽略,但如果我們可以了解跟多關于C++的內容,那么我們在學習或者理解相關知識的時候會對我們有一些潛在的幫助,比如C++一些重要的內容的加入,使得C++一直熱度不減,直到現在一直保持著編譯語言前三名,

| 階段 | 內容 |
|---|---|
| C With classes | 類及派生類、共有和私有成員、類的構造和析構、友元、行內函式、賦值運算子多載等 |
| C++1.0 | 添加虛函式概念、函式和運算子多載,參考、常量等 |
| C++2.0 | 更加完善支持面對物件,新增保護成員、多重繼承、物件的初始化、抽象類、靜態成員以及const成員函式 |
| C++3.0 | 進一步完善,引入模板,解決多重繼承產生的二義性問題和想對應構造和析構的處理 |
| C++98 | C++標準第一個版本,絕大多數編譯器都支持,得到了國際標準化組織(ISO)和美國標準化協會認可,以模板方式重寫C++標準庫,引入了STL(標準模板庫) |
| C++03 | C++標準第二個版本,語言特性無大改變,主要:修訂錯誤、減少多異性 |
| C++05 | C++標準委員會發布了一份計數報告(Technical Report,TR1),正式更名C++0x,即:計劃在本世紀第一個10年的某個時間發布 |
| C++11 | 增加了許多特性,使得C++更像一種新語言,比如:正則運算式、基于范圍for回圈、auto關鍵字、新容器、串列初始化、標準執行緒庫 |
| C++14 | 對C++11的擴展,主要是修復C++11中漏洞以及改進,比如:泛型的lambda運算式,auto的回傳值型別推導,二進制字面常量等 |
| C++17 | 在C++11上做了一些小幅改進,增加了19個新特性,比如:static_assert()的文本資訊可選,Fold運算式用于可變的模板,if和switch陳述句中的初始化器等 |
| C++20 | 令人失望 |
1.3、C++學習的重要性

我們這里簡單的幾個方面介紹一下C++的重要性
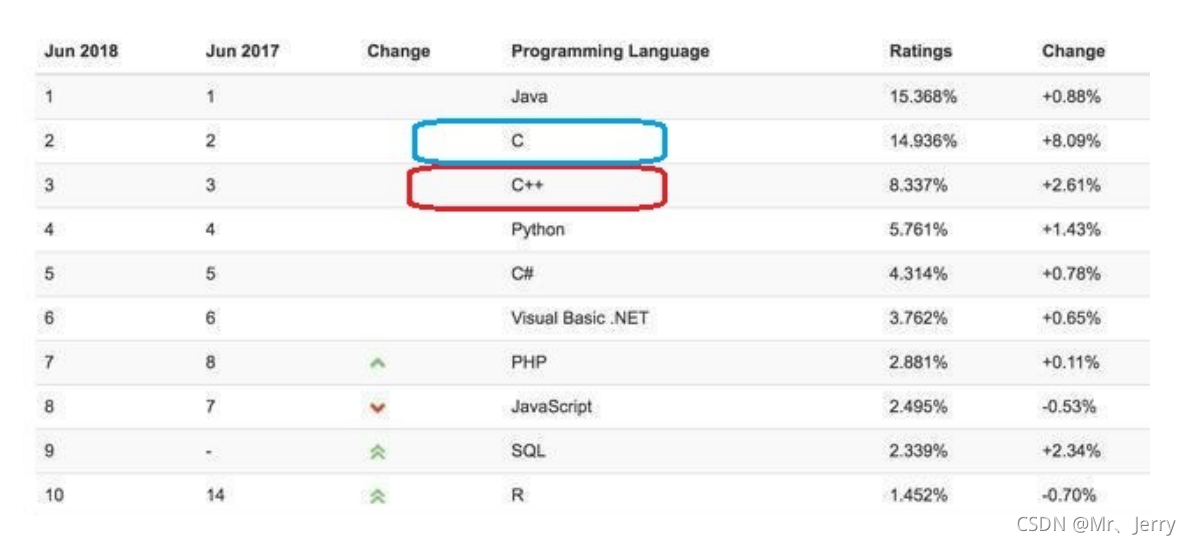
1.3.1語言的使用廣泛
今年的開發語言排行榜的情況:
1.3.2在作業領域
我們隨意舉一些需要用到C++方面的作業崗位:
①作業系統以及大型軟體開發
②人工智能
③網路開發
④游戲開發
⑤嵌入式領域
…………
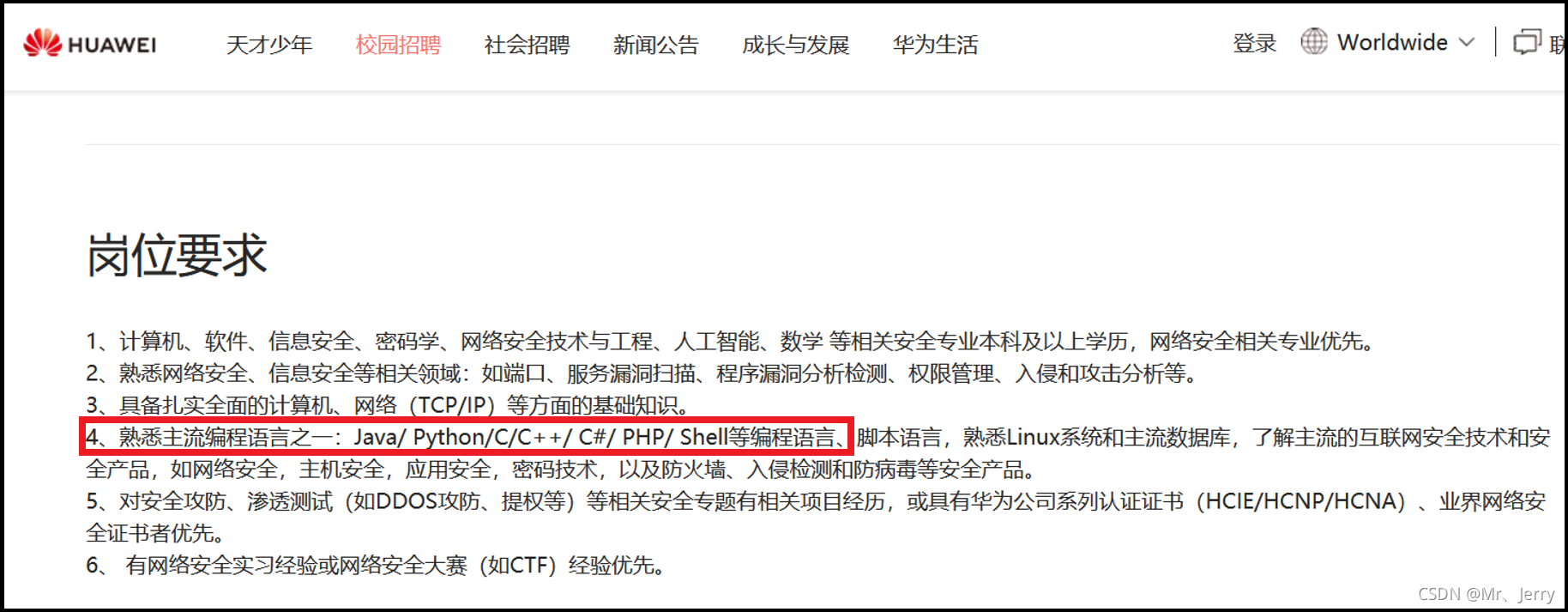
1.3.3招聘需求
崗位的需求與要求:
①華為
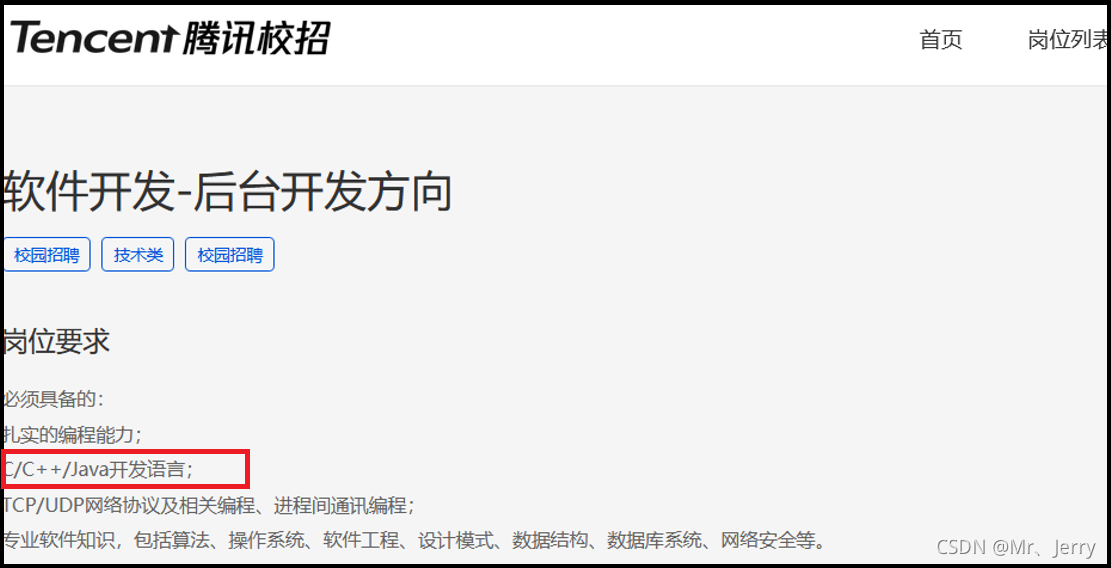
②騰訊:
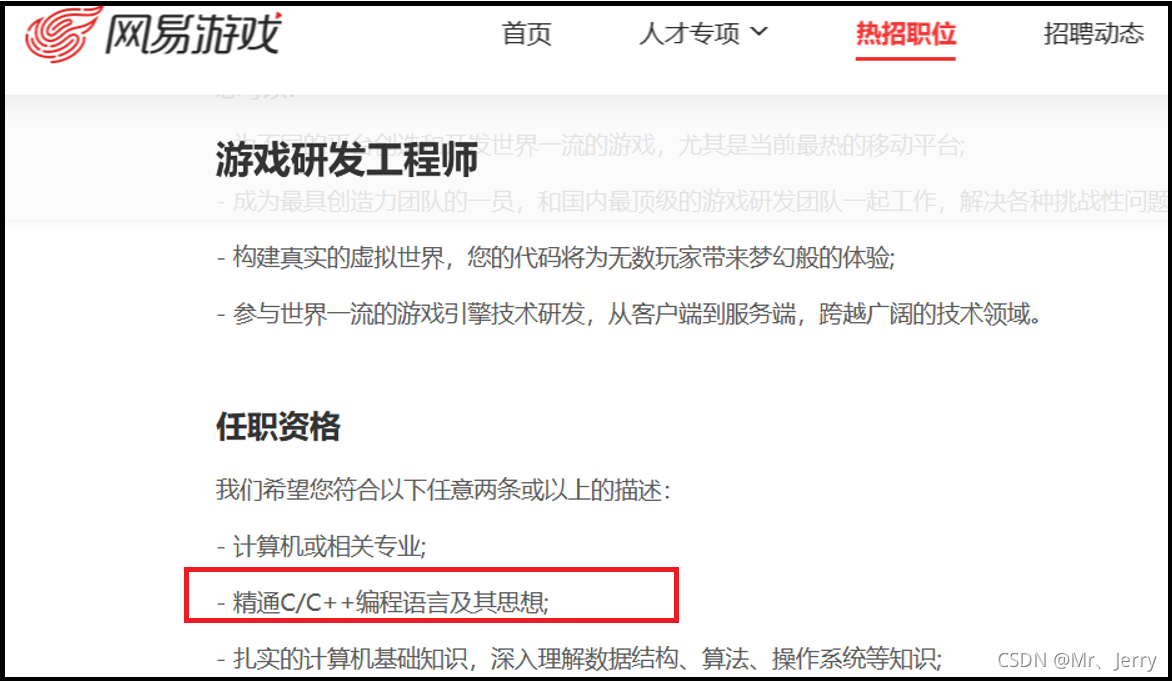
③網易:
二、C++入門知識
2.1、C++關鍵字
我們在C語言中學習了32個關鍵字,既然C++是對C語言內容的補充和添加,那么C++中也含有關鍵字,其中就包括C語言中的關鍵字,一共63個關鍵字,
| asm | do | if | return | try | continue |
|---|---|---|---|---|---|
| auto | double | inline | short | typedef | for |
| bool | dynamic_cast | int | signed | typeid | public |
| break | else | long | sizeof | typename | throw |
| case | enum | mutable | static | union | wchar_t |
| catch | explicit | namespace | static_cast | unsigned | default |
| char | export | new | struct | using | friend |
| class | extern | operator | switch | virtual | register |
| const | false | private | template | void | true |
| const_cast | float | protected | this | volatile | while |
| delete | goto | reinterpret_cast |
2.2、命名空間

2.2.1引言
相信你在學習的程序中一定遇到過這樣的情況,就是我們明明只是想實作一個交換的功能,但卻因為要交換的資料型別不同,導致我們在C語言中需要將統一功能的函式命名為不同的函式名;又或者在作業中或者小組作業中,每個人都被分配了任務,但兩個人之間的函式名可能重名,那么這個時候就需要一個人去修改自己的程式,如果這個很大,很復雜,那么就會很繁瑣,讓人頭痛,而C++就考慮了這個問題,而其為了解決這個問題,C++中就有了“命名空間”這個定義,
2.2.2命名空間的定義
①
在C語言中,一個工程的建立我們可能需要創建大量的變數、函式、類等,而這些內容都將存在于全域域中,而這可能會導致沖突,而命名空間的出現,就可以避免命名沖突、名字污染等情況,命名空間的出現可以對識別符號的名稱進行本地化,namespace 關鍵字的出現就可以針對這個問題并且解決,
②
定義命名空間時,我們現在知道需要namespace這個關鍵字,后面更加命名空間的名字,然后像創建一個函式一樣,用{}進行內容的包裹,而這其中的內容就是命名空間的成員,
③
一個命名空間就相當于定義了一個新的作用域,命名空間中的所有內容都局限于命名空間中
④代碼:
④—①命名空間中可以定義變數和函式
namespace hzh
{
int a = 10;
int b = 20;
int Add(int x, int y)
{
return x + y;
}
}
④—②命名空間中可以嵌套定義命名空間
namespace lzy//命名空間一:lzy
{
int a;
int b;
namespace csz//命名空間二:csz
{
int Sub(int x, int y)
{
return x - y;
}
}
}
④—③同一個工程中允許存在多個相同的命名空間,編譯器在最后會合成同一個命名空間中
namespace hzh//在一個工程中的頭檔案中定義hzh這個命名空間
{
struct Stack
{
int* a;
int size;
int capacity;
};
}
namespace hzh//在③—①中我們定義的命名空間
{
int a = 10;
int b = 20;
int Add(int x, int y)
{
return x + y;
}
}
//在一個工程中我們允許多次對同一個命名空間進行定義
2.2.3命名空間的使用
①引言
我們通過上面的學習知道了如何定義一個命名空間,那么命名空間應該如何使用呢?我們先來看一段代碼,
#include<stdio.h>
#include<stdlib.h>
namespace hzh
{
int a = 20;
int b = 10;
int Add(int x, int y)
{
return x + y;
}
}
int main()
{
printf("%d", a);
return 0;
}
你覺得這里程式可以成功運行嗎?讓我們來看看運行結果,
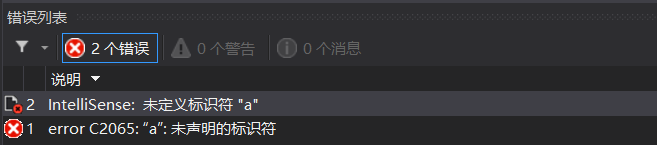 這里就體現了我們在上一小結中的一句話:
這里就體現了我們在上一小結中的一句話:
一個命名空間就相當于定義了一個新的作用域,命名空間中的所有內容都局限于命名空間中
那么如果我們想要將命名空間hzh中的變數a進行列印,那么我們應該進行什么操作呢?
這里我們就引出我們的命名空間的使用,
②命名空間的使用方式:
方式1.使用using namespace命名空間名稱,實作引入
代碼:
#include<stdio.h>
#include<stdlib.h>
namespace hzh
{
int a = 20;
int b = 10;
int Add(int x, int y)
{
return x + y;
}
}
using namespace hzh;//這里關鍵字using的使用將我們的hzh命名空間進行展開,展開到全域作用域中,這樣我們可以直接使用我們命名空間中的內容
int main()
{
printf("%d", a);
return 0;
}
方式2.使用命名空間名稱+作用域限定符::,實作引入
代碼:
#include<stdio.h>
#include<stdlib.h>
namespace hzh
{
int a = 20;
int b = 10;
int Add(int x, int y)
{
return x + y;
}
}
int main()
{
printf("%d\n",hzh::a);//作用域限定符:: 這里我們可以理解為"::"的使用,讓我們在hzh這個命名空間中找到了a這個變數,這個時候我們就可以將其列印
return 0;
}
方式3.使用using將命名空間中的成員引入
代碼:
#include<stdio.h>
#include<stdlib.h>
namespace hzh
{
int a = 20;
int b = 10;
int Add(int x, int y)
{
return x + y;
}
}
using hzh::a;//這里我們可以理解為我們將hzh這個命名空間中變數a釋放,將其的作用域展開到全域作用域中,從而可以被我們呼叫實作列印
int main()
{
printf("%d", a);
return 0;
}
2.3、C++輸入&輸出

我們在學習C語言時,第一句學習的代碼相信都是“hellow world”,那么我們在C++這門編譯語言中,我們應該如何實作這句代碼呢?如果實作,那它和C語言有什么區別呢?下面讓我們先看實作的代碼,然后我們再進行分析,
代碼:
#include<iostream>
using namespace std;
int main()
{
cout << "Hellow world" << endl;
return 0;
}
運行結果:
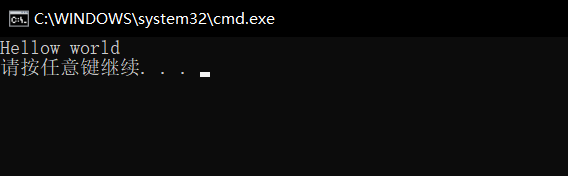 這里我們進行分析與知識點的講解:
這里我們進行分析與知識點的講解:
①
我們使用cout標準輸出(控制臺)和cin標準輸出(控制臺)時,必須包含頭檔案以及std標準命名空間,
②
cin就相當于我們C語言中的輸出,結合>>(可以想象為從左側進行向內輸入);
cout就相當于我們C語言中的輸入,結合<<(可以想象為從左側進行向外輸出);
③早期標準庫將所有功能在全域域中實作,宣告在.h后綴的頭檔案中,使用時只需包含對應頭檔案即可,后來將其實作在std命名空間下,為了和C頭檔案區分,也為了正確使用命名空間,規定C++頭檔案不帶.h;舊編譯器(vc 6.0)中還支持<iostream.h>格式,后續編譯器已不支持,因此推薦使用+std的方式,
④
我們在C++中進行輸入輸出時,是不需要考慮資料的型別的
代碼:
#include<iostream>
using namespace std;
int main()
{
int a;
double b;
char c;
cin >> a;
cin >> b >> c;
cout << a << endl;
cout << b << " " << c << endl;
return 0;
}
代碼分析:


2.4、預設引數
 ①引言:
①引言:
在C語言中,我們建立函式時,設定的形參只有實參傳參之后我們才能成功呼叫函式,而C++中我們即使沒有傳參,這個函式我們也可以呼叫,但這個呼叫時,我們使用的引數是我們一開始設定的引數,又叫做預設引數,而如果我們傳入我們的引數,那么這個之前默認的引數就作廢了,就和上面的圖片一樣,是個備胎,
②預設引數的定義:
預設引數是宣告或者定義函式時為函式的引數指定一個默認值,在呼叫函式的時,如果沒有指定實參則采用該默認值,否則使用指定的實參,
③舉例與分析:
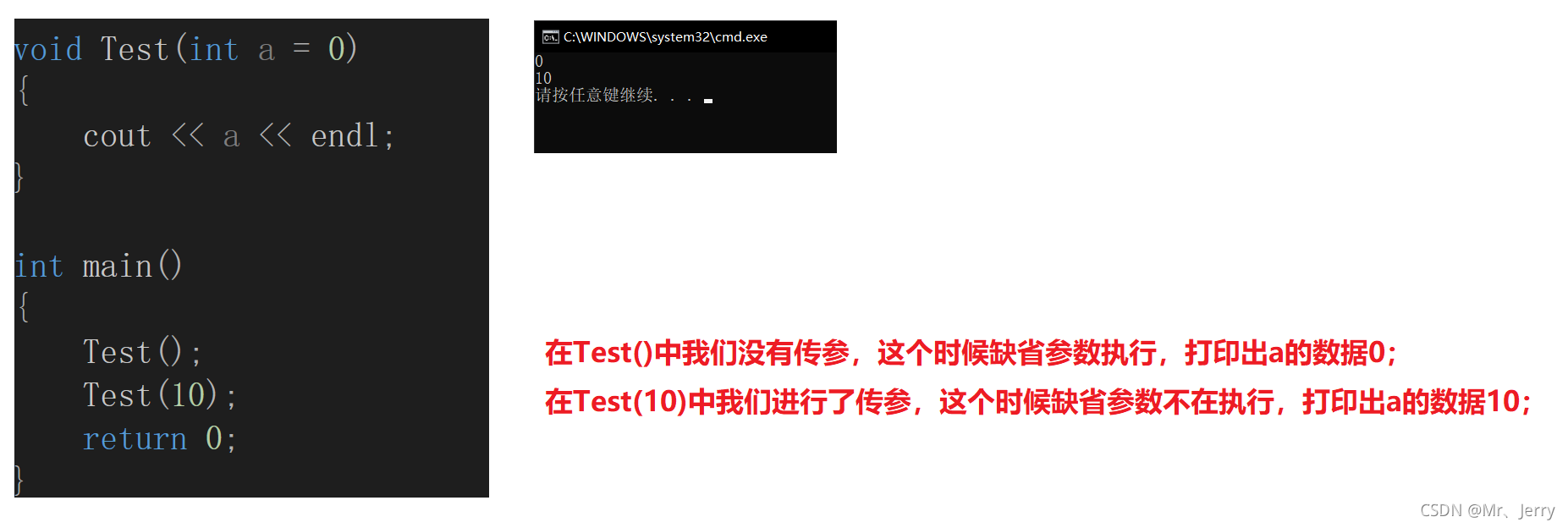
代碼一:
#include<iostream>
using namespace std;
void Test(int a = 0)
{
cout << a << endl;
}
int main()
{
Test();
Test(10);
return 0;
}
分析:
④預設引數的分類:
2.4.1全預設引數
在定義函式時,所有引數我們都將其設定為預設引數
void Test(int a = 10; int b = 20; int c = 30)
{
cout << "a = " << a << endl;
cout << "a = " << b << endl;
cout << "a = " << c << endl;
}
2.4.2半預設引數
在定義函式時,我們將函式中的部分引數設定為預設引數
void Test(int a; int b; int c = 30)
{
cout << "a = " << a << endl;
cout << "a = " << b << endl;
cout << "a = " << c << endl;
}
⑤注意:
1.在函式中設定預設引數時,其必須從左到右設定,不能間隔設定
錯誤代碼:
void Test(int a=10; int b; int c = 30)
{
cout << "a = " << a << endl;
cout << "a = " << b << endl;
cout << "a = " << c << endl;
}
因為這樣我們在傳參時,實參我們只輸入了一個數字,那么這個數字傳遞給那個形參編譯器無法判斷
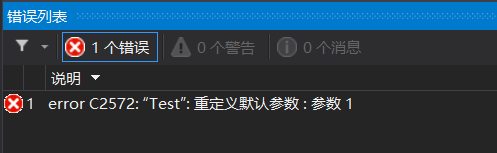
2.預設引數不能在函式宣告和定義中同時出現,這里這樣定義是因為防止在宣告和定義時,兩處函式中預設引數設定的數值不同,這樣編譯器就無法確定到底使用哪一個預設值,
代碼如下:
//test.h
void Test(int a = 10);
//test.cpp
void Test(int a = 20)
{}
int main()
{
Test();
return 0;
}
運行結果:
3.預設值必須是常量或者全域變數
4.C語言不支持
2.5、函式多載

①引言
在西游記中我們知道有真偽美猴王這一情節,這里我們從另一方面看待真偽美猴王,他們都可以實作變身,也都有武器,也就是說他們可以實作相同的功能,但從另一方面來看,他們的區別似乎只有自身的種類不同,一個是靈明石猴,一個是六耳獼猴;而這樣的情況在C++中也是存在的,這種情況就是C++中的函式多載,
②概念
函式的一種特殊情況,C++允許在同一作用域中宣告幾個功能類似的同名函式,這些同名函式的形參串列(引數個數 或 型別 或 順序)必須不同,常用來處理實作功能類似資料型別不同的問題
③舉例分析
代碼如下:
int Add(int a, int b)
{
return a + b;
}
int Add(int a, double b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}
分析:
上面代碼中的Add函式就是函式的多載,因為上面舉例的代碼中每一個Add函式中引數的型別都不完全相同,當我們在main函式中呼叫時,其會根據我們傳入的引數來自動判斷比較選擇想對應的函式
2.5.1名字修飾

①引言
為什么C語言不支持函式的多載而C++支持函式的多載呢?
②引言解答
在這里我們進行一個簡單的回答,因為如果在這里進行展開講解的話,一篇兩萬字左右的博客可能才可以徹底講清楚,所以這里我們進行一個簡單的回答,最主要的目的是告訴我們為什么C語言不支持函式的多載而C++支持函式的多載,以及引出名字修飾的內容
代碼:
int Add(int a, int b)
{
return a + b;
}
int Add(int a, double b)
{
return a + b;
}
分析:
這里我們對上面的代碼在不同的環境下進行分析:
當我們在C的環境中時,我們通過編譯的一些方式可以獲得如下內容
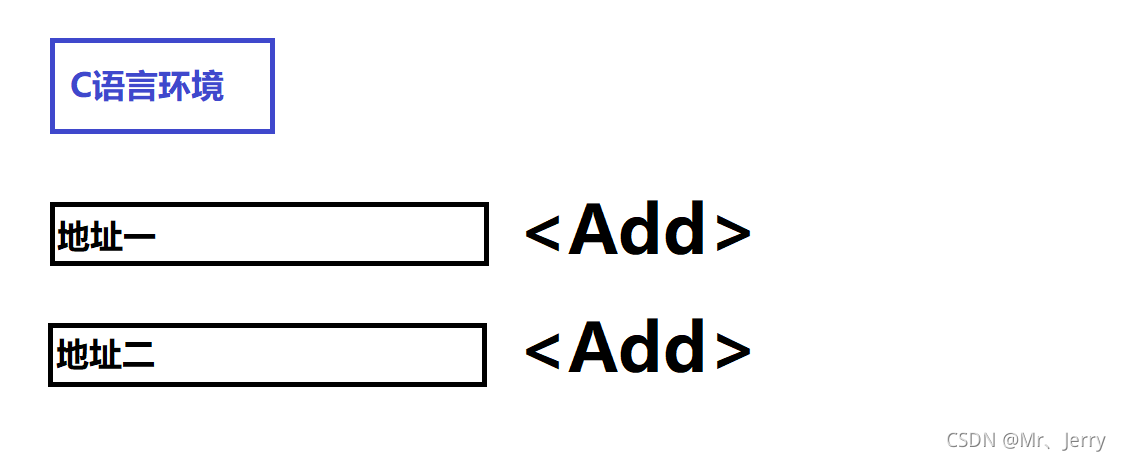 當我們在C++的環境中時,我們通過編譯的一些方式可以獲得如下內容
當我們在C++的環境中時,我們通過編譯的一些方式可以獲得如下內容
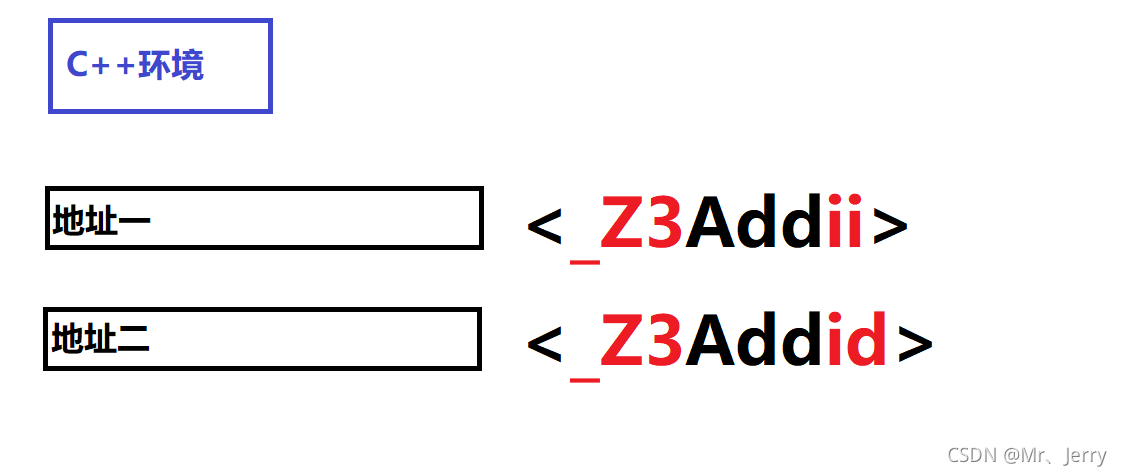
這里我們可以發現:在C++的環境中,函式名字的修飾發生了改變,編譯器將函式引數的型別資訊添加到了修改后的函式名中
這也就是為什么C語言環境中不支持函式多載而C++環境中支持函式多載的原因,同時上述的情況對比我們簡單了解了函式名字修飾的情況,在后面我寫一篇博客,對這一小結內容進行更加詳細的內容分析
2.5.2return “C”
①引言
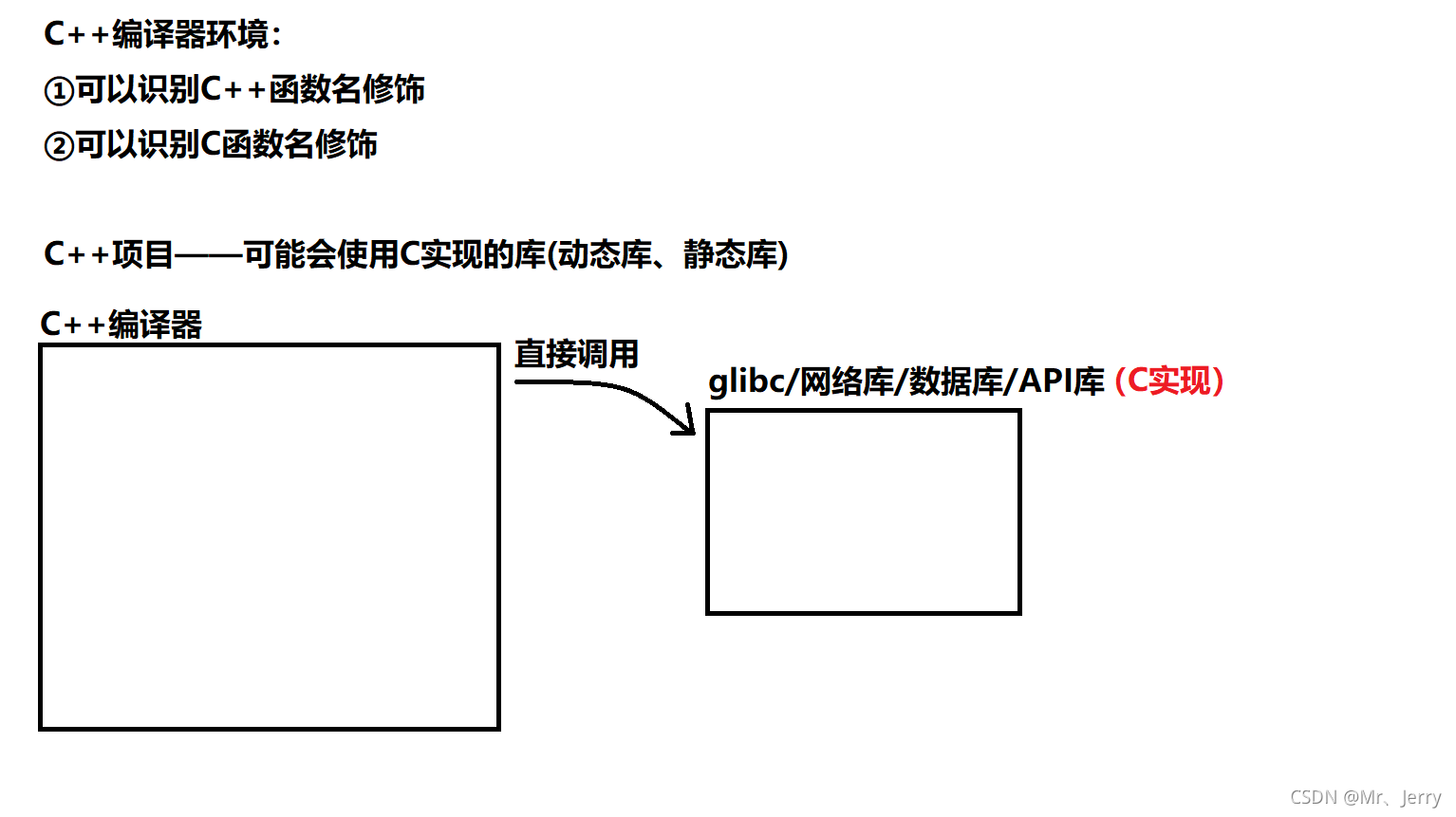
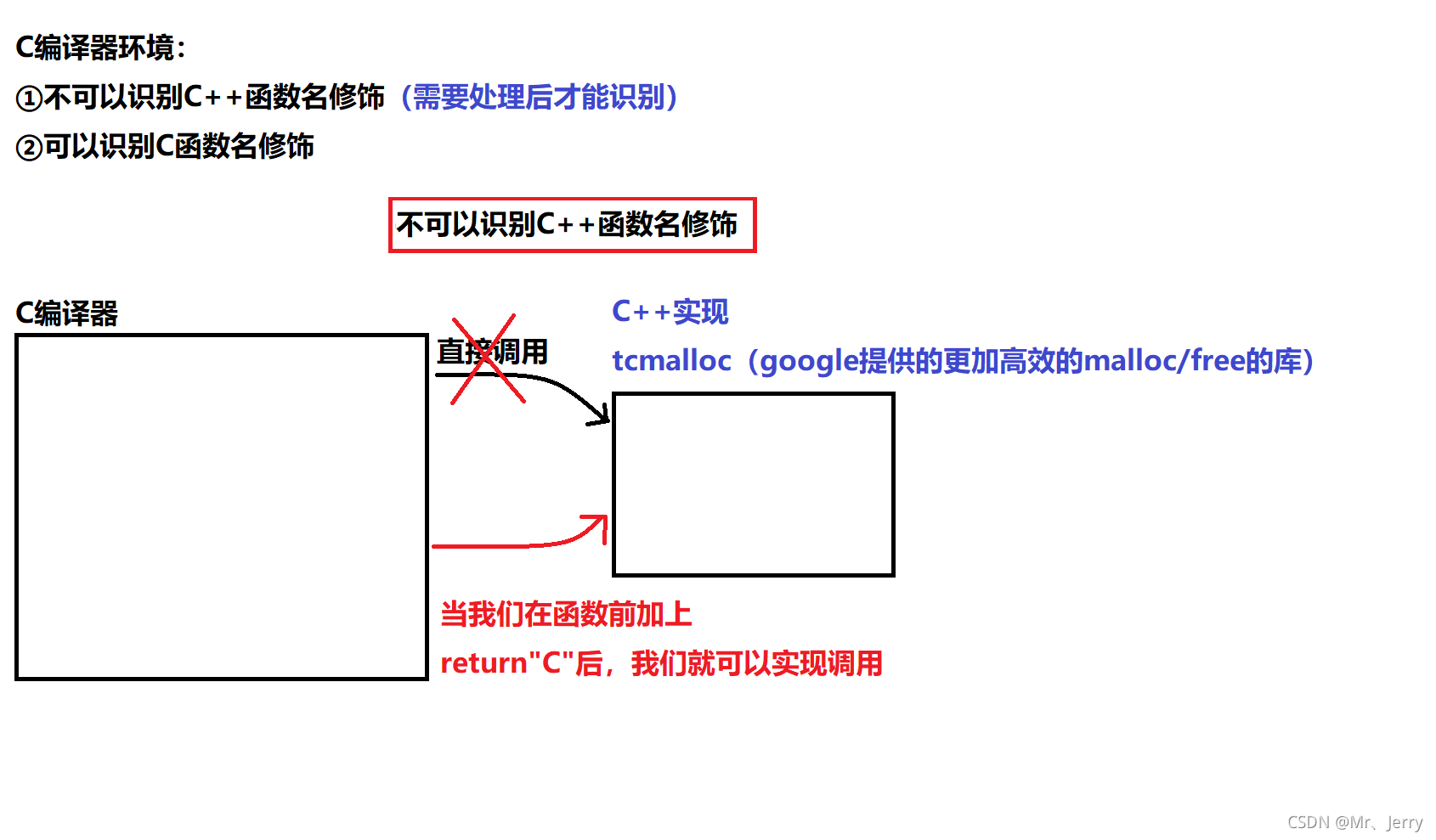
我們知道C++的出現是為了對C的內容進行補充和修改完善,有時候我們在C語言環境的程式中使用C++的某些內容是比較高效的,但我們又知道C++是對C兼容的,但C對C++環境并不兼容,那么這個時候我們該怎么辦? 這里我們在函式前加extern "C"就可以解決這個問題
②圖解分析
2.6、參考
 ①引言
①引言
在生活中,我們每個人在兒時都有自己的小名,和朋友之間也有自己專屬的外號,而這一現象并不是只有在生活中才有,在C++中我們也有相同的情況,但C++中這樣的情況卻另有他用,
②概念
參考不是新定義一個變數,而是給已存在變數取了一個別名,編譯器不會為參考變數開辟記憶體空間,它和它參考的變數共用同一塊記憶體空間,
③舉例分析
代碼:
void Test()
{
int a = 10;
int& b = a;
}
分析:
 代碼:
代碼:
#include<iostream>
using namespace std;
void Swap(int&rx, int&ry)
{
int temp = rx;
rx = ry;
ry = temp;
}
int main()
{
int x = 0, y = 1;
Swap(x, y);
return 0;
}
分析:

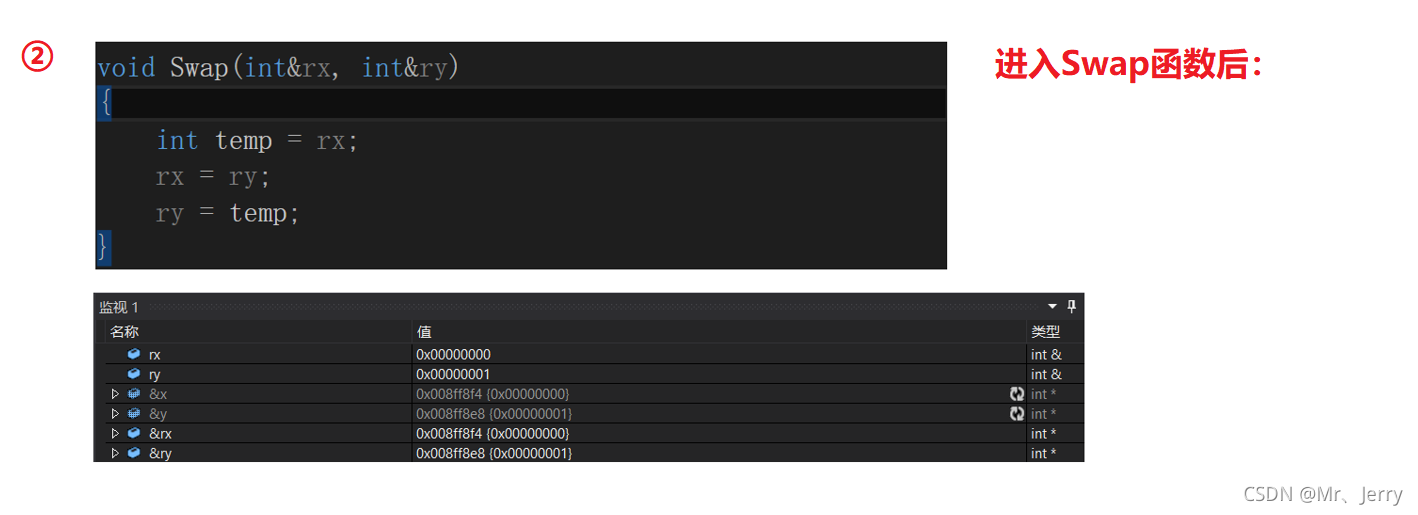

2.6.1應用的特性
①參考在定義時必須初始化
正確代碼:
void Test()
{
int a = 10;
int& ra = a;
}
錯誤代碼:
void Test()
{
int a = 10;
int& rb;//這里的&rb是無效定義,因為這里編譯器不知道你要對誰進行取別名;
int& ra = a;
}
②一個變數可以有多個參考
void Test()
{
int a = 10;
int& ra = a;
int& rra = a;
int& rrra = a;
}
③參考一旦參考一個物體之后,就再不能參考其他物體
void Test()
{
int a = 10;
int b = 20;
int& ra = a;
int& rb = b;
int&rb = a;//這里我們已經對b取別名為rb,此時再對a取別名rb后,編譯器無法識別rb到底是哪一個變數的別名,所以參考一旦參考一個物體之后,就再不能參考其他物體,
}
2.6.2常參考
現在我們分析這一段代碼
int main()
{
int i = 10;
double d = i;
double&r = i;
}
當我們執行這一段代碼時,編譯器報錯
 說明這里第三行代碼"double&r = i"錯誤,但我們這個時候發現 int型別的i都可以賦值給double型別的變數d,那為什么不可以對int型別的變數取double型別的別名呢?
說明這里第三行代碼"double&r = i"錯誤,但我們這個時候發現 int型別的i都可以賦值給double型別的變數d,那為什么不可以對int型別的變數取double型別的別名呢?
下面是可以成功執行的代碼
int main()
{
int i = 10;
double d = i;
const double&r = i;
}
那么為什么第一種代碼執行錯誤,而第二種代碼就可以成功執行?僅僅一個const的添加就解決了問題?其實這里是我們在學習C語言時學習過的一個知識的擴展,下面我們通過圖解來分析:
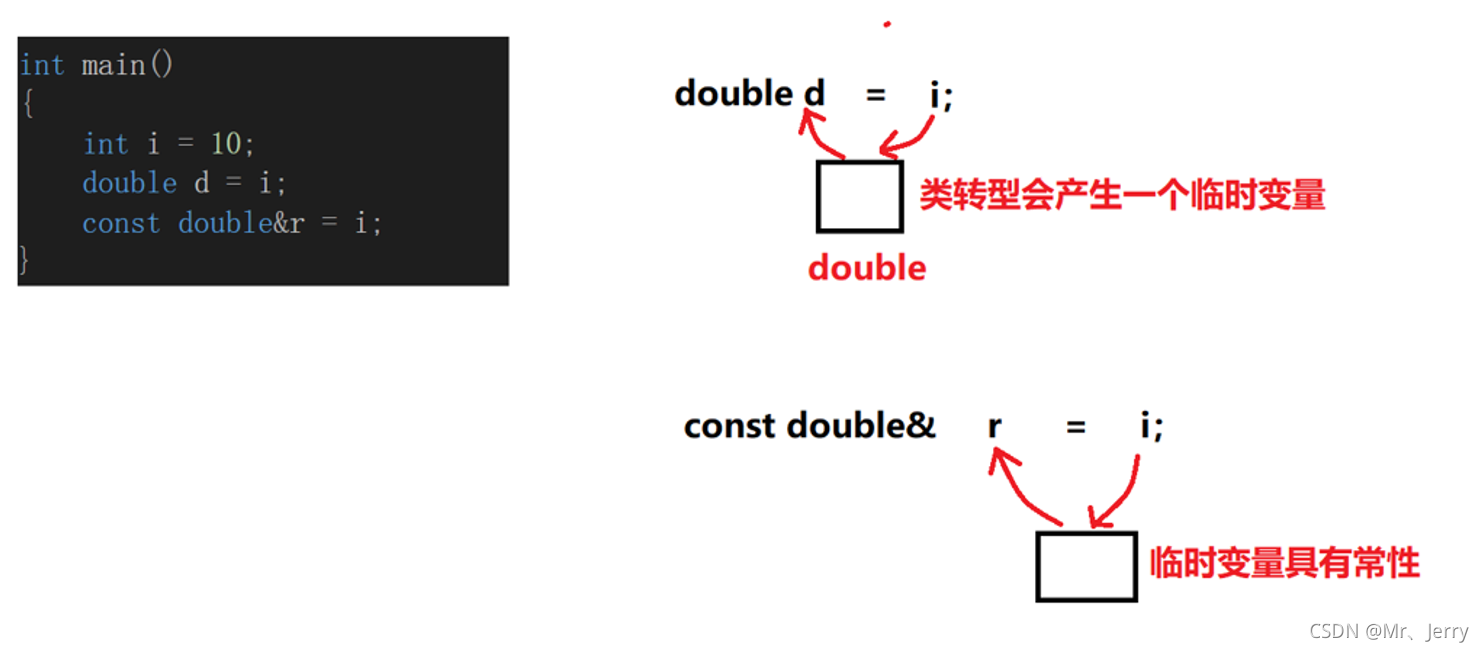
上面是常參考的簡單講解,可能我們現在任不知道常參考的好處,下面我們從兩個方面來講解它的好處:
常參考的好處一:
#include<stdio.h>
#include<iostream>
#include<stdlib.h>
using namespace std;
typedef struct Stack
{
int* a;
int top;
int capacity;
}ST;
void StackInit(ST& rs)
{
rs.a = NULL;
rs.top = rs.capacity = 0;
}
void StackPrint(const ST& rs)//在這里我們使用const是為了放置我們在函式中失誤將代碼寫出rs.capacity = 0;這樣就可以被檢查出來
//①傳參考是為了減少傳值傳參時的拷貝;②可以保護形參傳參時不會被改變
{
if (rs.capacity == 0)//既可以接受變數,又可以及接受常量
{
}
}
int main()
{
ST st;
StackInit(st);
StackPrint(st);
return 0;
}
常參考的好處二:
void Func(const int&n)
{
}
int main()
{
int i = 10;
Func(i);
Func(20);
return 0;
}
2.6.3 使用場景
2.6.3.1做回傳值
那么我們在分析了上面的代碼之后,我們再分析下面的代碼:
代碼
int Add(int a,int b)
{
int c = a + b;
return c;
}
int main()
{
int ret = Add(1,2);
Add(3,4);
cout<<"Add(1,2)is:"<<ret<<endl;
return 0;
}
圖解
對代碼進行初步分析:
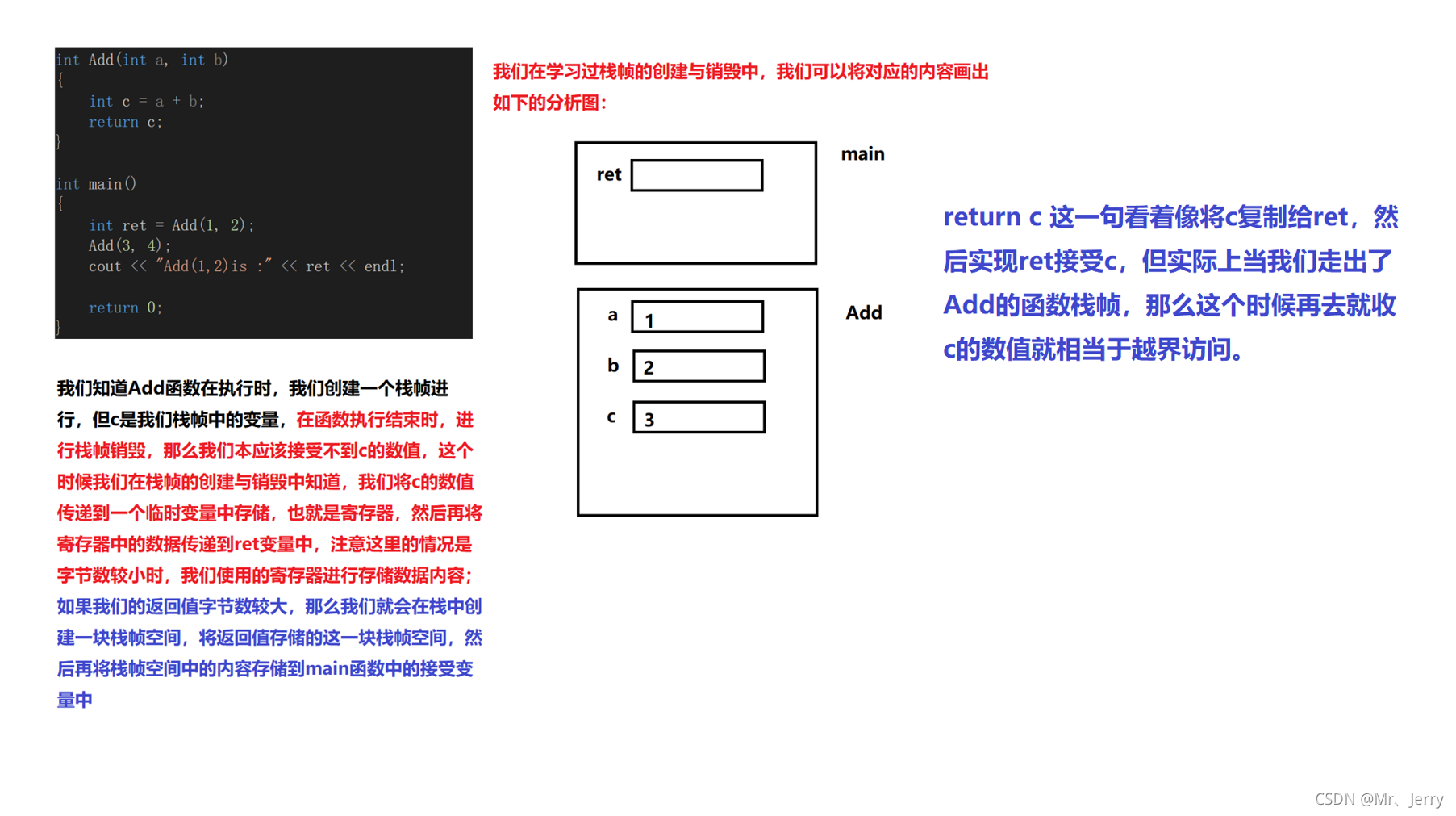
對代碼進一步分析,我們修改部分代碼:

那么我們再分析下面的代碼:
代碼
int& Add(int a,int b)
{
int c = a + b;
return c;
}
int main()
{
int ret = Add(1,2);
Add(3,4);
cout<<"Add(1,2)is:"<<ret<<endl;
return 0;
}
圖解:




2.6.3.2做引數
這里關于做引數的實作,其實我們在上面講解Swap函式時就已經實作,當參考用于做引數時,我們就可以直接對實參進行操作,省去了實參的復制,提升了效率,
#include<iostream>
using namespace std;
void Swap(int&rx, int&ry)
{
int temp = rx;
rx = ry;
ry = temp;
}
int main()
{
int x = 0, y = 1;
Swap(x, y);
return 0;
}
2.6.4參考&傳值的效率比較(了解)
以值作為引數或者回傳值型別,在傳參和回傳期間,函式不會直接傳遞實參或者將變數本身直接回傳,而是傳遞實參或者回傳變數的一份臨時的拷貝,因此用值作為引數或者回傳值型別,效率是非常低下的,尤其是當引數或者回傳值型別非常大時,效率就更低,
下面的代碼只是用來通過時間來進行一個簡單的判斷,實際意義不大:
#include <time.h>
struct A{ int a[10000]; };
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{
A a;
// 以值作為函式引數
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以參考作為函式引數
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分別計算兩個函式運行結束后的時間
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
2.6.5參考&指標的比較(了解)
這一小結的內容重在我們對參考和指標的理解,并不需要對這一小結的內容死記硬背,所以我們簡答了解之后,可以在后續的學習中不斷重復理解
1. 參考在定義時必須初始化,指標沒有要求
2. 參考在初始化時參考一個物體后,就不能再參考其他物體,而指標可以在任何時候指向任何一個同型別物體
3. 沒有NULL參考,但有NULL指標
4. 在sizeof中含義不同:參考結果為參考型別的大小,但指標始終是地址空間所占位元組個數(32位平臺下占4個位元組)
5. 參考自加即參考的物體增加1,指標自加即指標向后偏移一個型別的大小
6. 有多級指標,但是沒有多級參考
7. 訪問物體方式不同,指標需要顯式解參考,參考編譯器自己處理
8. 參考比指標使用起來相對更安全
2.7、行內函式

①引言
或許現在的我們還沒有太過深入的學習,但我們知道當我們執行程式的時候我們需要對呼叫的函式進行堆疊幀的創建,但這個時候我們思考一個問題,若果我們的程式中有一個函式需要多次呼叫,那么我們在執行程式時,編譯器就要多次創建堆疊幀,在執行之后我們還需要將這個堆疊幀銷毀,這樣的話效率太過低下,那么我們有什么辦法可以解決這個問題呢?
②概念
以inline修飾的函式叫做行內函式,編譯時C++編譯器會在行內函式的地方展開,沒有函式壓堆疊的開銷,行內函式可以提升程式的運行效率
③對引言問題的思考&行內函式的執行
面對引言中的問題我們有什么方法可以解決嗎?為了便于講解,我們這里提供程式的環境,在當前的程式中我們需要多次呼叫ADD函式,這里ADD函式實作將傳入的引數進行相加,然后回傳結果;
這里我們提供兩種方法:
第一種:C語言中的宏替代
#define ADD(a,b)((a)+(b))
int main()
{
cout<<ADD(1,2)<<endl;
return 0;
}
在這里我們通過宏替代,雖然可以解決我們參考中的問題,但它也帶來的許多問題:
1.語法復雜,細節多如牛毛,容易出錯;
2.沒有型別的安全檢查
3.不能進行除錯
面對上面宏替代帶來的問題,我們這里講解第二種方法,也就是我們的行內函式:
第二種:行內函式
inline int add(int a, int b)
{
return a + b;
}
int main()
{
int ret = add(1, 2);
return 0;
}
我們雖然說行內函式可以省去函式壓堆疊的開銷,但第一次接觸C++的我們或者第一次讀沒有理解這句話是什么意思,現在我通過圖解來進行講解:
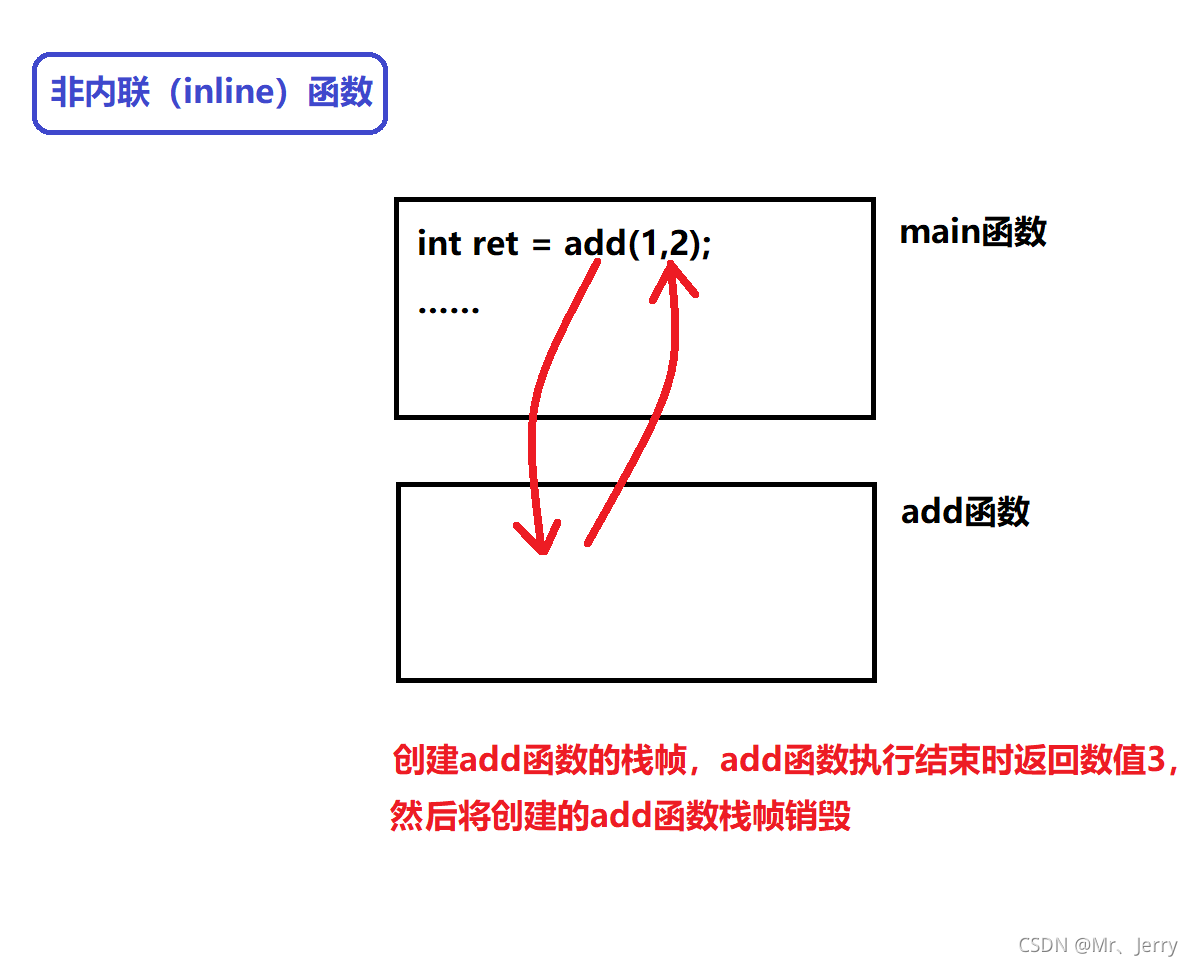

④注意
1.inline是一種以空間換時間的做法,省去呼叫函式的開銷,所以這個時候代碼很長或者有遞回/回圈的函式不適宜作為行內函式
2.inline對于編譯器只是一種建議,編譯器會自動優化,如果定義為inline的函式內有遞回/回圈等代碼,那么編譯器在優化時會自動忽略這些定義的行內函式
3.inline不建議宣告和定義分離,分離會導致鏈接錯誤,因為inline被展開,就沒有函式地址了,鏈接就會找不到
4.我們對第三點再進行詳細講解

2.8、auto關鍵字(C++11)

①概念
通過右邊的復制,自動推到出變數型別
舉例:
#include<iostream>
using namespace std;
int main()
{
int a = 1;
char b = 'a';
auto c = a;
auto d = b;
cout << c << endl;
cout << d << endl;
cout << typeid(c).name() << endl;//這里typeid可以獲取傳入引數的資料型別,知道即可;
cout << typeid(d).name() << endl;
return 0;
}
執行結果:
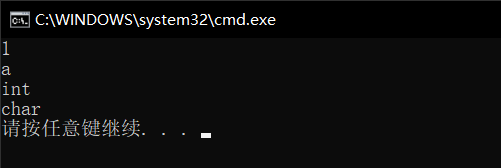
這里我們可以得出c和d的資料型別和a和b的資料型別相同,那么我們就可以證明auto可以實作通過右邊的復制,自動推到出變數型別,
②用處
1.auto與指標和參考結合起來使用用auto宣告指標型別時,用auto和auto*沒有任何區別,但用auto宣告參考型別時則必須加&
代碼如下:
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 20;
*b = 30;
c = 40;
return 0;
}
2.在同一行定義多個變數當在同一行宣告多個變數時,這些變數必須是相同的型別,否則編譯器將會報錯,因為編譯器實際只對第一個型別進行推導,然后用推匯出來的型別定義其他變數,
代碼如下:
void Test()
{
auto a = 1, b = 2;
auto c = 3, d = 4.0; // 該行代碼會編譯失敗,因為c和d的初始化運算式型別不同
}
③注意
1.auto不能作為函式的引數,因為編譯器無法事變auto型別引數的實際資料型別,無法推斷
void Test(auto a)//這里就是錯誤的代碼,編譯器無法對auto資料的資料型別判斷
{
……
}
2.auto不能直接用來宣告陣列,因為我們不知道應該將陣列中哪一個元素作為陣列的資料型別
void Test()
{
int a[] = {1,2,3};
auto b[] = {4,5,6};//錯誤
auto c[] = {'A', 123, 12.189};//錯誤
}
2.9、基于范圍的for回圈(C++11)
 ①比較
①比較
首先我們回歸一下C語言中我們使用for回圈的常見:
int array[] = { 1, 2, 3, 4, 5 };
//常見的陣列訪問方式:陣列和指標
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)
array[i] *= 2;
for (int*p = array; p < array + sizeof(array) / sizeof(array[0]); p++)
cout << *p << " ";
cout << endl;
下面是我們基于范圍的for回圈,處理上面的場景:
//C++11中提供的一種新的訪問陣列的方式
//自動依次取陣列中的值賦值給e(注意這里的e只是個變數,可以換成任何字母)
//自動判斷結束
for (auto& e : array)
{
e *= 2;
}
for (auto e : array)
{
cout << e << " ";
}
cout << endl;
下面是我們以后會學習的內容代碼,這里我們可以使用我們的范圍for回圈,在后續的學習中我會再進行分析講解,這里我們先大概了解一下
map<string,string>dict = { { "string", "字串" }, { "sort", "排序" },{ "true", "真" } };
//迭代器遍歷:
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
cout << it->first << ":" << it->second << endl;
it++;
}
cout << endl;
//C++11范圍for可以更簡單的回圈遍歷容器
for (auto e : dict)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
②講解
對于一個有范圍的集合而言,由程式員來說明回圈的范圍是多余的,有時候還會容易犯錯誤,因此C++11中引入了基于范圍的for回圈,for回圈后的括號由冒號“ :”分為兩部分:第一部分是范圍內用于迭代的變數,第二部分則表示被迭代的范圍,
2.10、指標空值——nullptr(C++11)
①講解
在良好的C/C++編程習慣中,宣告一個變數時最好給該變數一個合適的初始值,否則可能會出現不可預料的錯誤,比如未初始化的指標,如果一個指標沒有合法的指向,我們基本都是按照如下方式對其進行初始化:
void TestPtr()
{
int* p1 = NULL;
int* p2 = 0;
// ……
}
NULL實際是一個宏,在傳統的C頭檔案(stddef.h)中,可以看到如下代碼:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定義為字面常量0,或者被定義為無型別指標(void*)的常量,不論采取何種定義,在使用空值的指標時,都不可避免的會遇到一些麻煩,比如:
void f(int)
{
cout<<"f(int)"<<endl;
}
void f(int*)
{
cout<<"f(int*)"<<endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}
程式本意是想通過f(NULL)呼叫指標版本的f(int * )函式,但是由于NULL被定義成0,因此與程式的初衷相悖,在C++98中,字面常量0既可以是一個整形數字,也可以是無型別的指標(void * )常量,但是編譯器默認情況下將其看成是一個整形常量,如果要將其按照指標方式來使用,必須對其進行強轉(void * )0,
②注意
1. 在使用nullptr表示指標空值時,不需要包含頭檔案,因為nullptr是C++11作為新關鍵字引入的,
2. 在C++11中,sizeof(nullptr) 與 sizeof((void * )0)所占的位元組數相同,
3. 為了提高代碼的健壯性,在后續表示指標空值時建議最好使用nullptr,
總結
以上就是我對C++入門內容的講解與個人的學習思考,這里的auto關鍵字、基于范圍的for回圈、指標空值講解的比較淺顯,因為我們部分內容還沒學到,所以我們暫時還不能體會到他們的奇妙之處,所以我會在后續的學習中在重新講解
上述內容如果有錯誤的地方,還麻煩各位大佬指教【膜拜各位了】【膜拜各位了】

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/305258.html
標籤:其他