文章目錄
- 回顧指標
- 舉個例子回憶一下
- 1.字符指標
- 程式一:
- 程式二:
- 程式三:
- 程式四:
- 程式五:
- 程式六:
- 指標陣列 - 本質上是一個陣列
- 程式一:
- 程式二:
- 程式三:
- 這里我們回顧一下 二級指標
- 陣列指標 - 指標
- 程式一:
- 程式二:
- &陣列名 VS 陣列名
- 舉個例子
- 陣列指標的用法 : 一般用在 二維陣列
- 程式一:
- 在 明白 陣列指標 的真正用途之前,我們需要觀察一個程式
- 程式二(陣列指標的用法):
- 小匯總
- 陣列引數、指標引數
- 一維陣列傳參
- 二維陣列傳參
- 一級指標傳參
- 思考: 當 一個函式 的 引數部分 為 一級指標的時候,函式能接受什么引數?
- 二級指標的傳參
- 程式一(傳二級指標變數本身和一級指標變數地址):
- 程式二(傳 一級指標變數的地址):
- 程式三(傳 二級指標變數的本身):
- 程式四(傳 指標陣列 的 陣列名):
- 思考:當函式的引數為二進制的時候,可以接收什么引數?
- 函式指標
- 程式一:
- 程式二:
- 程式二:
- 閱讀兩段有趣的代碼
- 代碼1
- 代碼2(簡化 嵌套函式指標的寫法)
- 函式指標實戰
- 函式指標陣列
- 練習(寫一個函式指標 pf,能夠指向 my_strcpy)
- 接下來我們用函式指標陣列 實作計算器
- 正常方式
- 函式指標陣列方式
- 指向 函式指標陣列 的 指標
- 函式指標陣列 與 函式指標陣列的指標 (詳解)
- 回呼函式
- 實體:
- qsort 函式 的使用
- 先來回顧一下冒泡排序 :只能排整形資料
- qsort 函式 - 庫函式 - 排序 - quick sort (快速排序)
- 先來了解一下, qsort 的 結構型別
- void * 介紹
- 進入實戰
- qsort(陣列名,該陣列元素個數,該陣列單個元素記憶體大小,(函式指標,比較兩個元素的 所用函式 函式 的 地址 )函式指標的 兩個引數 是:待比較的兩個元素的地址
- 改進冒泡排序(回呼函式)
- 本文結束
回顧指標
1,指標就是個變數,用來存放地址,地址 唯一標識 一塊 記憶體空間,
2.指標的大小是固定的 4 / 8位元組(32位平臺 / 64位平臺),
3.指標是有型別的 ,指標的型別決定了指標的 +- 整數的步長,指標解參考操作的時候的權限(一次訪問幾個位元組內容)
4.指標的運算
舉個例子回憶一下
#include<stdio.h>
void test(int* arr)// 這里的 arr 是 陣列首元素地址的一份拷貝
{
printf("%d\n",sizeof(arr[0]));// 計算的陣列的一個元素大小,輸出為 4
printf("%d\n",sizeof(arr));// 計算的是地址的大小(這里不能算是陣列的地址,因為 該地址是test傳過來的 首元素地址 的一份拷貝),輸出為 4
// 32位系統
sizeof(arr)在這里是求指標(地址)大小(4 byte)
sizeof(arr[0])在這里求的是一個元素的大小,int型別(4位元組)
如果是64位系統,指標大小為 8 位元組,輸出此時就為 2
}
int main()
{
int arr[10] = { 0 };
test(arr);//傳過去的是陣列首元素地址,因為不是單獨 與 sizeof 和 & 運算子連用
return 0;
}
?
1.字符指標
在指標的型別 中 我們知道有一種 指標型別 為 字符指標 char*·
程式一:
#include<stdio.h>
int main()
{
char ch = 'w';
char* pc = &ch;
*pc =='w';
return 0;
}
?
程式二:
#include<stdio.h>
int main()
{
char arr[] = "abcdef";
char* pc = arr;//這里存入的是首元素 a 的地址
printf("%s\n",arr);//abcdef
printf("%s\n",pc);//abcdef 兩者都是向后列印,直到遇到'\0'停止
%s 就是 根據 給的地址位置開始向后列印的,知道遇到'\0'停止
return 0;
}
?
程式三:
#include<stdio.h>
int main()
{
char* p = "abcdef";// "abcdef" 雙引號引起來的abcdef\0,是一個常量字串
// 上運算式的意思是,把 a 的地址 存入指標變數p里面去
printf("%c\n",*p);// *p == a
// 輸出為 a
printf("%s\n",p);//從存入p的這個地址(首元素a的地址)開始往后列印知道遇到 '\0'
// 即輸出為 abcdef
return 0;
}
?
程式四:
#include<stdio.h>
int main()
{
const char* p = "abcdef";// 最穩妥寫法,就是在 * 前面加上 const
*p = 'w';// 這時候你想改都改不了,況且 "abcdef" 是一個常量字串,也改不了
printf("%s\n", p); //你會發現 沒有任何輸出,程式崩潰,違規操作
//還有一個原因 abcdef\0 是一個常量字串,是不可以被改變的(const:是變數具有常量屬性)
return 0;
}
?
程式五:
#include<stdio.h>
int main()
{
char arr1[] = "abcdef";
char arr2[] = "abcdef";
if (arr1 == arr2)//這里是兩個不同陣列的陣列名(不同的首元素地址),是否相同
//肯定不同,兩個不同陣列的起始空間肯定不一樣
{
printf("hehe\n");
}
else
{
printf("haha\n");// 所以輸出這條陳述句
}
return 0;
}
?
程式六:
#include<stdio.h>
int main()
{
建議下面兩句運算式在 * 前面防疫 const ,這樣就更保險,無法通過解參考去修改常量字串的內容
這樣寫,雖然意義不大(常量字串本身并不能被修改),語法更為準確
const char* p1 = "abcdef";
const char* p2 = "abcdef";
這里把常量字串 abcdef\0 的首元素(a)地址分別存入 2 個指標變數
是因為abcdef\0是常量字串,不可改變,因此沒有必要創建2個,直接共用一個,即 p1 == p2
if (p1 == p2)
{
printf("hehe\n");// 所以輸出這條陳述句
}
else
{
printf("haha\n");
}
return 0;
}
?
指標陣列 - 本質上是一個陣列
在pointer文章中,我們也學了指標陣列,指標陣列 指的是一個 存放指標 的陣列
程式一:
#include<stdio.h>
int main()
{
int arr[10] = { 0 };// 整形陣列
char ch[5] = { 0 };// 字符陣列
int* parr[4];// 這就是一個存放 整形指標 的陣列,簡稱 指標陣列
char* pch[5];// 這就是一個存放 字符指標 的陣列,簡稱 指標陣列
return 0;
}
?
程式二:
#include<stdio.h>
int main()
{
int a = 10;
int b = 20;
int c = 30;
int d = 40;
int* arr[4] = { &a, &b, &c, &d };
等價于 //int* pa = &a;
//int* pb = &b;
//int* pc = &c;
//int* pd = &d;
int i = 0;
for (i = 0; i < 4; i++)
{
printf("%d ",*arr[i]);// 10 20 30 40
}
return 0; // 指標陣列很少怎么用 ,下面程式將告訴你,指標陣列怎么使用
}
?
程式三:
#include<stdio.h>
int main()
{
int arr1[] = { 1, 2, 3, 4, 5 };
int arr2[] = { 2, 3, 4, 5, 6 };
int arr3[] = { 3, 4, 5, 6, 7 };//以上三個運算式,就是在說我有三陣列,內容是,,,,
int* parr[] = { arr1, arr2, arr3 };
// 把上面 三個陣列 的 陣列名/陣列首元素地址 存入這個 指標陣列
int i = 0;
for (i = 0; i < 3; i++)// 遍歷 指標陣列 parr 的元素
{
int j = 0;
for (j = 0; j < 5; j++)// 遍歷 指標陣列 parr 的 元素 所指向的 陣列 的 元素
{
printf("%d ",*(parr[i] + j));
}
printf("\n");
}
return 0;
}
?
這里我們回顧一下 二級指標
int* arr1[]; //一級整形指標陣列.
int** arr[];// 二級整形指標陣列
ichar* arr2[]; //一級字符指標陣列
char** arr2[]; //二級字符指標陣列
?
陣列指標 - 指標
程式一:
#include<stdio.h>
int main()
{
int* p = NULL;// 整形指標 - 指向 整形 的指標 作用:可以 存放 整形的地址
char* pc = NULL;//字符指標 - 指向 字符 的指標 作用:可以 存放 字符的地址
陣列指標 - 指向 陣列 的指標 作用:可以 存放 陣列的地址
//int arr[10] = { 0 }; 整形陣列
// arr - 首元素地址
// &arr[0] - 首元素的地址
// &arr - 陣列的地址
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int(* p)[10] = &arr;// 把陣列的地址存起來
// 為什么不能去掉(),因為 [] 的優先級 比 * 高,去掉(),p就和陣列[10]先結合,就成 指標陣列(存放指標的陣列) 了
// 加 () 把 * 和 p 先結合,使 p 成為一個指標 (另外請注意 這里不是解參考,只是說明 p 是一個指標)
// 把 *p 去掉,還剩int [10],意思就是說該指標(p)指向 一個 元素個數為 10 的陣列,且陣列每個元素的型別為整形
// 即 上運算式 int(*p)[10] 就是陣列指標
return 0;
}
?
程式二:
#include<stdio.h>
int main()
{
char* arr[5];
//如何把上運算式的陣列存入 陣列指標?
如下
char*(*pa)[5]=&arr;
// 先用()把 * 和 pa(指標變數名) 結合起來,使 pa 為一個指標,也就是說 * 告訴我們 pa 是個指標
//再在后面加[5],意思是 指標 指向一個元素個數為5的陣列
// 又因為 指標 指向的陣列 的 元素型別 為 char*,所以在前面補上
int arr2[10] = { 0 };
int (*pa2)[10] = &arr2;
return 0;
}
?
&陣列名 VS 陣列名
陣列名 絕大部分時候 都是為 首元素地址
只有兩種情況例外 &陣列名 和 sizeof(陣列名)
在這兩種情況下的陣列名,代表是整個陣列,取出的是陣列的地址(與陣列首元素地址相同,但意義不同)
舉個例子
&arr+1 - 直接 跳過一整個 陣列的位元組
比如 int arr[10],他的大小是40個位元組,&arr+1 陣列地址會加上40
如果是 arr+1 它就只跳過一個元素,意思就是 跳過第一個元素,地址指向第二個元素
?
陣列指標的用法 : 一般用在 二維陣列
程式一:
#include<stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10};
int (*pa)[10] = &arr;
int i = 0;
for (i = 0; i < 10; i++)
{
//printf("%d ",(*pa)[i]);// *pa 就相當于陣列名 *pa == arr
printf("%d ",* (*pa+i) );//等價于 printf("%d ",*(arr+i))
}
return 0; // 但 陣列指標 不是這么用的,以上只是讓你對它理解更深一點
}
在 明白 陣列指標 的真正用途之前,我們需要觀察一個程式
#include<stdio.h>
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int i = 0;
int* p = arr;// 指標變數p 接收的是 陣列的首元素地址,即 p == arr
for (i = 0; i < 10;i++)
{
printf("%d ",*(p+i));// 通過陣列首元素的地址,來遍歷陣列元素
}
printf("\n");
上下兩個回圈表達大額效果是相同的
for (i = 0; i < 10; i++)
{
printf("%d ", *(arr + i));
}
printf("\n");
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);// arr[i] == *(arr+i) == *(p+i) == p[i]
}
printf("\n");
上下兩個回圈表達大額效果是相同的
for (i = 0; i < 10; i++)
{
printf("%d ", p[i]);// arr[i] == p[i]
}
//以上所有寫法都是等價的,
return 0;
}
?
程式二(陣列指標的用法):
#include<stdio.h>
void print1(int arr[3][5], int x, int y)
{
int i = 0;
int j = 0;
for (i = 0; i < x; i++)// 雙重循環遍歷二維陣列
{
for (j = 0; j < y; j++)
{
printf("%d ",arr[i][j]);// printf("%d ". *(*(arr+i)+j) );
}
printf("\n");
}
}
void print2(int(*p)[5], int x, int y)//由于 二維陣列轉過的是 首元素地址(一維陣列的地址),需要一個一維陣列指標來接收
{
int i = 0;
int j = 0;
for (i = 0; i < x; i++)// t通過雙重回圈,來遍歷二維陣列
{
for (j = 0; j < y; j++)
{
//printf("%d ", *(*(p+i)+j));// p 是 一維陣列的地址 (一行),*p 就是找到了第一行的資料,也就是一維陣列的陣列名
// *( p + i),i=0,還是第一行,i=1 是第二行, i=2 第三行
// *(p+i)+j 就是第幾行 第幾個元素
printf("%d ",p[i][j]);
// *(*(p+i)+j)== p[i][j] 先用一個括號將 p 和 i括起來,得到一維陣列的首元素地址,在對其解參考得到"陣列名",
再用一個括號將其和 j 括起來,得到 i 行 第 j 個元素的地址,在對其 解參考,得到該元素的值,并將其列印(注意! [] 比 * 的優先級高)
//printf("%d ", *(p[i]+j))
// *(p+i) == arr[i] == p[i]
// *(p[i]+j) == p[i][j]
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, {3, 4, 5, 6, 7} };
print1(arr,3,5);
這里的 陣列名 就是 首元素【{1,2, 3,4, 5}】地址
首先我們要 把二維陣列 看作 一維陣列,把 第一行{1,2,3,4,5}資料,也就是我們的第一個元素(首元素),看作一個一維陣列 int a[5]
//以此類推 第二行資料 就是 第二個元素(也是一個一維陣列), 第三行資料 就是 第三個元素(也是一個一維陣列)
print2(arr,3,5);// 那么 傳過去的是陣列首元素地址,而且是一個一維陣列的地址
return 0;
}
?
小匯總
int arr[10] //arr是一個整形陣列,具有10個元素.
int* parr1[10];//parr1是指標陣列,首先它是一個陣列,具有10個元素,且每個元素的型別是(int*) ,
int(*parr2)[10]; ???parr2是一個整形陣列指標
用括號讓 * 與 parr2 先結合
所以parr2是一個指標,該指標指向了一個陣列,陣列有10個元素,每個元素的型別是int
int( * parr3 [10] ) [5]
因為()的優先級最高,所以先判斷()里的內容
又因為 * 和[],[]的優先級更高,所以 parr3先與[]結合,所以parr3是個陣列
把 parr3[10]去掉,還剩下int(* )[5] ,就是它的元素型別.
例子: int arr[10];去掉arr[10],乘下的 int,就是它的型別(整形)
那int(* )[5]是個什么型別?
仔細觀察一下,你會發現,它和陣列指標 int(*p)[10] 一樣
.那么、我們可以說 parr3是個陣列,元素有10個,每個元素都是一個整形陣列指標,這個指標能指向5個元素,每個元素的型別是int.的整形陣列,(我們稱 ? int( * )[5] ?為 整形陣列指標型別,簡稱 陣列指標型別 )
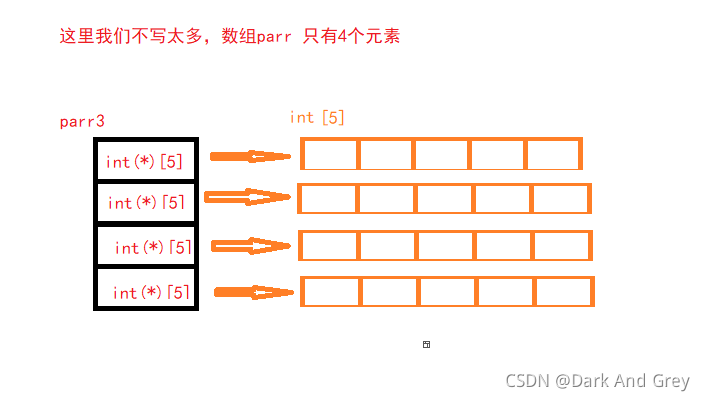
?
陣列引數、指標引數
在寫代碼的時候難免要把 [ 陣列 ] 或者 [ 指標 ]傳給函式,那函式的引數該如何設計?
一維陣列傳參
#include<stdio.h>
void test(int arr[])// OK
{}
void test(int arr[10])// OK
{}
void test(int* arr)// OK
{}
void test2(int* *arr)// OK
{}
void test2(int* arr[20])// OK 這里 20 跟上運算式一樣可以省略
{}
int main()
{
int arr[10] = { 0 };
int* arr2[20] = { 0 };
test(arr);
test2(arr2);
return 0;
}
?
二維陣列傳參
#include<stdio.h>
void test(int arr[3][5]) // OK
{}
void test(int arr[][5]) // OK 維陣列 的 行 是能省略的
{}
void test(int arr[3][]) // NO 二維陣列 的 列是不能省略的
{}
void test(int arr[][]) // NO 二維陣列 的 列是不能省略的
{}
void test(int* arr) // NO 這只能用來接收一維陣列的元素地址(陣列的地址,要用陣列指標來接收,而不是陣列一個一級指標),不能接收二維陣列的傳參
{}
void test(int* *arr) // 二維陣列的陣列名 是 首元素地址(第一行的地址,可以將其當做一個一維陣列的地址】)
{} // 一個陣列的地址,是不 能放進 二級指標的
// 二級指標 是用來 存放 一級指標變數 的地址
//所以該寫法也是錯的 NO
void test(int (*arr)[5]) // ok
()使 * 和 arr 先結合,使 arr 成為指標,用它來接收二維陣列的地址(首元素地址)
將二維陣列的首元素地址 就第一行資料的地址(可以看作 一維陣列的地址 ,所以需要一個 陣列指標 來接收),
該指標指向一個有五個元素的陣列(二維陣列的一行資料),且每個元素的型別為 int
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);// 二維陣列 的 陣列名 是 首元素地址(第一行的地址資料的地址,將其當做 一個 一維陣列的陣列名)
}
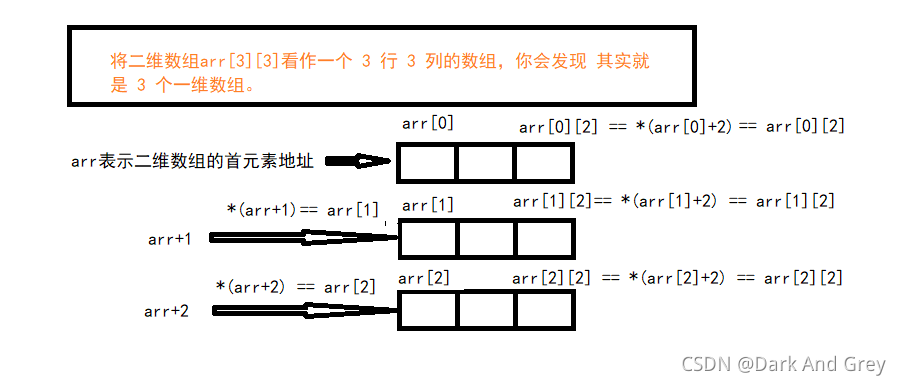
?
一級指標傳參
#include<stdio.h>
void print(int* p,int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ",*(p+i));
}
}
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
print(p,sz);//一級指標p 傳給函式
return 0;
}
思考: 當 一個函式 的 引數部分 為 一級指標的時候,函式能接受什么引數?
#include<stdio.h>
void tset(int* p)// 這里 的一級指標變數 p 是 print 函式 中 一級指標變數 的 一份拷貝
{
;
}
void print(int* p,int sz)
{
int a = 10;
int* p = &a;
test(&a);// ok
test(p);// ok,這里傳的是 一級指標變數本身,而不是 一級指標 的 地址,所以不需要 二級指標來接收
return 0;
}
能接受 一級指標變數本省 和 一個整形資料的地址
?
二級指標的傳參
程式一(傳二級指標變數本身和一級指標變數地址):
#include<stdio.h>
void test(int* *ptr)
{
printf("num = %d\n",**ptr);
}
int main()
{
int n = 10;
int* p = &n;
int* *pp = &p;// 最右邊的*,說明pp是一個指標,該指標指向 p;左邊 int*是型別,是該指標指向 p 的型別
test(pp);// ok,這里傳的是 二級指標變數本省,所以接收只需要 一個 二級指標,相當于 將其拷貝一份資料
test(&p);// ok 這里傳的是 一級指標變數 的 地址,一個一級指標 的 地址,需要一個二級指標來接收
return 0;
}
?
程式二(傳 一級指標變數的地址):
#include<stdio.h>
void test(int* * p)
{
printf("hehe");
}
int main()
{
int* ptr = 0;
test(&ptr);// 這里就是典型的,傳址(傳一級指標變數的地址),需要一個二級指標來接收
return 0;
}
程式三(傳 二級指標變數的本身):
#include<stdio.h>
void test(int* * p)
// 因為 test函式傳的是二級指標變數的本身,而不是二級指標變數的地址,所以我們只需用一個相同型別的二級指標來接收test的傳參
// 這里 的 二級指標變數 p, 相當于 是 二級指標變數 pp 的一份臨時拷貝
{
printf("hehe");
}
int main()
{
int* ptr = 0;
int* *pp = &ptr;
test(pp);// 這里傳的是 二級指標變數本身
return 0;
}
程式四(傳 指標陣列 的 陣列名):
#include<stdio.h>
void test(int* * p)
{
printf("hehe");
}
int main()
{
int* arr[10];
test(arr);
//指標陣列 也可以,這里傳的是陣列名(首元素地址),因為 指標陣列里 存放的元素的型別是 int* ,也就是說 首元素地址 其實是一個 一級指標變數(元素)的地址,一個 一級指標變數的地址,需要一個 二級指標變數 來接收
return 0;
}
?
思考:當函式的引數為二進制的時候,可以接收什么引數?
一級 指標變數 的地址
二級指標變數的本身
存放 一級指標陣列 的 陣列名
?
函式指標
陣列指標,是一個指向陣列的指標
那么,函式指標,是一個指向函式的指標 ,一個存放 函式的地址 的指標,
程式一:
#include<stdio.h>
int add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int a = 10;
int b = 20;
printf("%d\n", add(a, b));
printf("%p\n",&add);
printf("%p\n", add);// 這兩句程式,輸出的結果是一樣的,
//因為 函式名 和 &函式名 都是函式的地址, 而 函式 只有一個,所以函式的地址是唯一的
return 0;
}
?
程式二:
#include<stdio.h>
int add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int arr[10] = { 0 };// 整形陣列
int(*p)[10] = &arr;// 整形陣列的地址,需要一個 整形陣列指標來接收
int (*pa)(int,int) = add;
// 函式指標,先用()把 * 和 pa 先結合,是 pa 是一個指標(指標才能存放地址),
// 該指標 指向的函式 有兩個整形引數,然后該函式型別是 int
// 只需要告訴函式的引數型別就行,x 和 y 寫不寫都無所謂
printf("%d\n",(*pa)(2, 3));// 5
(*pa) == add,就是說 add 的地址,存入 函式指標 pa 中,我們再通過 解參考,找到add 函式,并對其呼叫,
就 好像一個函式宣告,告你說,這樣也能呼叫 add 函式
return 0;
}
程式二:
#include<stdio.h>
void print(char* str)
{
printf("%s\n", str);
}
int main()
{
void(*p)(char*) = print;
//這里不是解參考,我們用(),先讓 * 和 p 結合,使p為一個指標
//該指標 指向函式的引數的型別是 char*
//函式回傳型別是 void
//這個時候 p 就是我們的所謂的函式指標
(*p)("hello word!");
等價于
print("hello word!")
return 0;
}
你可以這么認為 函式指標 就是 函式名
?
閱讀兩段有趣的代碼
代碼1
void (*)() - 函式指標型別
( void (*)() )0, 最外面的括號 是 強制型別轉換符號,就是把 0 進行強制型別轉換( int -> 函式指標型別 )
到那時候 0 就是一個函式的地址
( * ( void ( * ) ( ) ) 0)
*解參考,呼叫 0 地址處的該函式【void (*)(),假設該式子等價于 void(*p)(int,int),這樣你們應該能理解】
就是呼叫 地址 0 處 的 函式 void(*p)(int,int)
?
代碼2(簡化 嵌套函式指標的寫法)
void(*signa1( int, void(*)(int))) (int);
signal這是一個函式宣告
signal 函式的引數有兩個,第一個是 int ,第二個是函式指標,該函式指標指向的函式的引數型別是int,回傳型別是void
signal 函式 的 回傳型別 也是一個 函式指標,該函式指標指向的函式的引數型別是int,回傳型別是void
然后我們把上面 三個去掉(函式 signal,和 它的兩個引數)
剩下: void (*)(int) 這又是一個函式指標型別,是函式signa1(int, void(*)(int))的回傳型別
typedef void(* pfun_t)(int); 現在這個時候 pfun_t 就是函式指標型別
// pfun_t 簡寫(重命名)是不能放后面的,要放在(*這里)
上下兩者 對 函式名 重命名的寫法是不相同的
typedef unsigned int uint; // 簡寫是可以直接寫在后面的
簡化 void(*signa1(int, void(*)(int)))(int);
typedef void(*pfun_t)(int);
pfun_t signa1(int, pfun_t);
?
函式指標實戰
#include<stdio.h>
int add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int arr[10] = { 0 };
int(*p)[10] = &arr;
int (*pa)(int,int) = add;// 函式指標,先用()把 * 和 pa 先結合,是 pa 是一個指標(指標才能存放地址),指向函式的兩個整形引數,然后該函式型別是 int
// 只需要告訴函式的引數型別就行,x 和 y 寫不寫都無所謂
printf("%d\n",(*pa)(2, 3));// 5
printf("%d\n", (**pa)(2, 3));// 5
printf("%d\n", (***pa)(2, 3));// 5
照理說 第一次 *pa 解參考,通過 pa的存入的地址,找到add 函式,第二次 **pa,以*pa為地址再找,以此類推,
但由 上三個運算式 的輸出結果顯示,* 沒有起到應有的 作用
那么我們可不可以 去掉 * 呢?
printf("%d\n", pa(2, 3));// 5
結果證明 可以
原因在程式一中:
printf("%p\n",&add);
printf("%p\n", add);// 這兩句程式,輸出的結果是一樣的,
//因為 函式名 和 &函式名 都是函式的地址, 而 函式 只有一個,所以函式的地址是唯一的
那么,再加上 pa本來就是等函式的地址(pa == &add == add),所以 在使用函式指標時,可以直接寫 函式指標變數
有的時候會有些人會加上 * 的原因,這樣可讀性高,讓讀者 能明白 pa 其實是一個指標
但 加上了 * ,要注意加上(),要不然會出現問題,
例 *pa(2,3),這時pa會先于(2,3)結合,形成一次函式呼叫,然后再解參考,就是說 對 呼叫結果 5 進行解參考,不是我們想要的結果
return 0;
}
?
函式指標陣列
#include<stdio.h>
int add(int x, int y)// 加法
{
return x + y;
}
int sub(int x, int y)// 減法
{
return x - y;
}
int mul(int x, int y)// 乘法
{
return x * y;
}
int div(int x, int y) //除法
{
return x / y;
}
int main()
{
int* arr[5];//指標陣列 arr是一個陣列,有5個元素,且每個元素的型別為int*,即每個元素都是一個整形指標、
int(*pa)(int ,int) = add;// 我們有4 個函式要被呼叫,要是 一個接著一個接著這樣會麻煩
這時需要一個陣列,這個陣列可以存放4個函式的地址 - 函式指標的陣列(前提是它們的引數和型別是完全一致的)
int(*parr[4])(int,int) = {add,sub,mul,div};// 函式指標陣列
將上式拆成 2 部分
int (*) (int,int)
parr[4]
表達的意思是 parr 先和 [4] 結合,成為一個陣列,元素有4個,每個元素 都是一個函式指標
int i = 0;
for(i = 0; i < 4; i++)
{
printf("%d ",parr[i](2, 3));// 加法 5, 減法 -1 乘法 6 除法 0
}
return 0;
}
?
練習(寫一個函式指標 pf,能夠指向 my_strcpy)
首先我們要知道 我們的自定義函式的型別: char* my_strcpy(char* dest, const char* src);
然后我們對它進行改造:char* ( * pf)(char * ,const char * ) = my_strcpy;
#include<stdio.h>
#include<assert.h>
char* My_strcopy(char* destination,const char* source)//這里本質上是個指標
{
assert(destination&&source);
char* ret = destination;
while (*destination++ = *source++);
return ret;
}
int main()
{
char arr[30] = { 0 };
char arr1[] = "abc";
char arr2[] = "def";
char arr3[] = "adcde";
char arr4[] = "abcdef";
char* arr5[4] = { arr1, arr2, arr3, arr4 };
char*(*pf)(char*, const char*) = My_strcopy;
for (int i = 0; i < 4; i++)
{
printf("%s\n", pf(arr,arr5[i]));
}
return 0;
}
寫一個函式指標陣列,能存放 4個 my_strcpy 函式的地址
char* ( * pfarr[4])(char*, const char*);
這個我就不寫,就跟 指標陣列一樣,給個打括號放函式名就行了
?
接下來我們用函式指標陣列 實作計算器
正常方式
#include<stdio.h>
void menu()
{
printf("**************************\n");
printf("** 1,add 2.sub ******\n");
printf("** 3,mul 4,div ******\n");
printf("***** 0.退出 ******\n");
printf("**************************\n");
}
int add(int x, int y)
{
return x + y;
}
int sub(int x, int y)
{
return x - y;
}
int mul(int x, int y)
{
return x * y;
}
int div(int x, int y)
{
return x / y;
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
do
{
menu();
printf("請選擇");
scanf("%d",&input);
switch (input)
{
case 1:
printf("請輸入兩個運算元:");
scanf("%d%d", &x, &y);
printf("%d\n",add(x,y));
break;
case 2:
printf("請輸入兩個運算元:");
scanf("%d%d", &x, &y);
printf("%d\n",sub(x,y));
break;
case 3:
printf("請輸入兩個運算元:");
scanf("%d%d", &x, &y);
printf("%d\n",mul(x,y));
break;
case 4:
printf("請輸入兩個運算元:");
scanf("%d%d", &x, &y);
printf("%d\n",div(x,y));
break;
case 0:
printf("退出程式");
break;
default:
printf("輸入錯誤,請重新選擇:");
break;
}
} while (input);
return 0;
}
?
函式指標陣列方式
#include<stdio.h>
void menu()
{
printf("**************************\n");
printf("** 1,add 2.sub ******\n");
printf("** 3,mul 4,div ******\n");
printf("***** 0.退出 ******\n");
printf("**************************\n");
}
int add(int x, int y)
{
return x + y;
}
int sub(int x, int y)
{
return x - y;
}
int mul(int x, int y)
{
return x * y;
}
int div(int x, int y)
{
return x / y;
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int(*parr[])(int, int) = { 0, add, sub, mul, div };// parr 是一個函式指標陣列
// 函式指標陣列的用途 又稱 轉移表
do
{
menu();
printf("請選擇");
scanf("%d", &input);
if (input >= 1)
{
printf("請輸入運算元:");
scanf("%d%d", &x, &y);
printf("%d\n", parr[input](x, y));
}
else if (input == 0)
{
printf("退出程式\n");
break;
}
else
{
printf("選擇錯誤,請重新輸入");
}
} while (input);
return 0;
}
?
指向 函式指標陣列 的 指標
int arr[10];
int(*p)[10] = &arr; // p就是一個指向 整形陣列 的指標
//這就是一個整形陣列指標
int* (*p)[10] = &arr;// p 就是一個指向 整形指標陣列 的 指標
int add(int x, int y)
{
return x + y;
}
int(*pf)(int,int) = add;//pf 是 函式指標
int(*pf[4])(int,int)// 這是一個 函式指標陣列
int(*(*pf)[4])(int,int)// pf 就是一個 指向函式指標陣列的 指標
()讓 pf 和 * 先結合,使其成為一個指標,去掉他們還剩 int(*()[4])(int,int)很明顯就是一個 函式指標陣列
?
函式指標陣列 與 函式指標陣列的指標 (詳解)
函式指標陣列
/先寫個陣列pfarr[5]
pfarr[5];
// 再用()把 * 和陣列 pfarr[5],結合 -指標陣列
(*parr[5]);
// 再寫函式引數型別與回傳型別
int(*parr[5])(int, int);// pafarr 是一個 函式指標 的 陣列
指向 函式指標陣列 的 指標
*ppfarr = &pfarr;// 函式指標陣列 的 地址,存起來,
//ppfarr就是 函式指標陣列 的 指標
//再將其替換入內,記得加括號
即:
int(*(*ppfarr)[5])(int, int) = &pfarr;
// 首先用()把 pparr 先和 * 結合,即pparr是一個指標
//該指標向外一看,指向一個陣列 [5], pparr 指標指向 一個陣列
//去掉 陣列 和 指標 : int(*)(int,int) 這是一個函式指標型別
//陣列每個元素,都是 函式指標型別
// 所以 ppfarr 就是一個指向 函式指標 陣列 的 指標
int(*p)(int, int); // 函式指標
int(*p[5])(int, int); // 函式指標陣列
int(*(*p)[5])(int, int);// 函式指標陣列 的 指標
函式指標陣列的指標 - 首先它是指標,其次 它是一個陣列,最后是 一個函式指標
?
回呼函式
回呼函式:
是一個通過函式指標呼叫的函式,如果你把函式的指標(地址)作為引數傳遞給另一個函式
當這個指標 被用來 呼叫 其所指向的函式時,我們就說這是回呼函式,
回呼函式不是由 該函式 的 實作方 直接呼叫,而是在 特定的事件 或 條件 發生時 由 另外的一方 呼叫 的
用于 對該 事件 或 條件 進行回應,
簡單來說,就是通過 把 實作功能函式的地址,交給另一哥 函式 ,由它去呼叫我們的 功能函式,
不能直接呼叫 功能函式,(就是說,你想玩電腦,得經過父母的同意,不然你玩個屁,)
實體:
#include<stdio.h>
void menu()
{
printf("**************************\n");
printf("** 1,add 2.sub ******\n");
printf("** 3,mul 4,div ******\n");
printf("***** 0.退出 ******\n");
printf("**************************\n");
}
// 這些是你上電腦,想玩的游戲
int add(int x, int y)
{
return x + y;
}
int sub(int x, int y)
{
return x - y;
}
int mul(int x, int y)
{
return x * y;
}
int div(int x, int y)
{
return x / y;
}
void calc(int(*pf)(int))// 這就是你父母,你父母同意了(函式收到相應地址,使用相應的功能),你才能玩
{
int x = 0;
int y = 0;
printf("請選擇兩個運算元:");
scanf("%d%d",&x,&y);
printf("%d\n", pf(x, y));
}
int main()
{
int input = 0;
do
{
menu();
printf("請選擇");
scanf("%d",&input);
switch (input)
{
case 1:
calc(add);//回呼函式
這里 就好比,你向你父母申請,請打開麥克風交流,,,
break;
case 2:
calc(sub);
break;
case 3:
calc(mul);
break;
case 4:
calc(div);
break;
case 0:
printf("退出程式");
break;
default:
printf("輸入錯誤,請重新選擇:");
break;
}
} while (input);
return 0;
}
?
qsort 函式 的使用
先來回顧一下冒泡排序 :只能排整形資料
#include<stdio.h>
void bubble_sort(int*arr, int sz)
{
int i = 0;
for(i = 0; i < sz - 1; i++)// 整個陣列,只用 排 元素的總個數 - 1,因為最后不需要排
// 就好比 432 1,前面的 比 1 大的數,都排到前面去了,
// 1 它自己就只能 stay here
{
//一趟冒泡排序
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
//那 一個數 和 它屁股后面的數 進行比較
{
if (arr[j] > arr[j + 1])
// 如果 它 比 它屁股 大,它就前進一位,然后再跟它目前的屁股,再比一次,直到,他沒屁股大,停止,然后屁股再去跟它后面的人去比
// 第一次要比 九次,
// 它一次比完之后,一開始 跟它比的 屁股的哪一位,他就要開始比了,
// 由于 屁股這位,跟它比過了,他就不會去比了,因為結果都知道,還比個錘子喲!
// 所以 屁股 這位 比的次數 比它 少一次,
// 而 屁股后面那位,跟 它們都比過了,它就比九次 少2次
// 以此類推
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 9, 8, 7, 6, 5, 4, 3, 2, 1, 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
qsort 函式 - 庫函式 - 排序 - quick sort (快速排序)
先來了解一下, qsort 的 結構型別
void qsort(void *base,目標陣列(需要排序的陣列)
size_t num, 陣列元素的個數
size_t width,元素大小(以位元組為單位)
int(*compare)(const void *e1, const void *e2)//函式指標,該函式是一個 比較函式
);
?
void * 介紹
void * : 萬能指標,能接受任何 型別的資料,但不能呼叫,如果要呼叫,只能強制型別轉換,才能使用
#include<stdio.h>
#include<stdlib.h>
int compare(const void* e1, const void* e2)//用來比較兩個整形值
// void* 無型別指標,
// void* 型別的指標 = 可以 接收 任意型別 的地址(指標),,但不能進行解參考
// 俗稱 萬能指標
{
;
}
int main()
{
int a = 10;
void* p = &a;
*p = 0;// void* 無法進行 解參考操作
// 因為 指標的型別,決定它解參考操作時,一次可以訪問多少個位元組
// 又因為 void* 是一個無型別指標,所以 在它 解參考操作時,無法確定一次訪問多少個位元組
return 0;
}
進入實戰
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int compare(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;// 如果兩個宿相等, 回傳 0
// 第一個 小于 第二個 回傳 復數
} // 第一個 大于 第二個 回傳 正數
void test()
{
int arr[] = { 9, 8, 7, 6, 5, 4, 3, 2, 1, 0 };
int sz = sizeof(arr) / sizeof (arr[0]);
qsort(arr, sz, sizeof(arr[0]), compare); // qsort 排序 arr,arr有10個元素,一個元素記憶體的大小,比較兩個元素的大小,回傳
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int compare_f(const void*e1, const void*e2)
{
return (int)(*(float*)e1 - *(float*)e2);
if (*(float*)e1 == *(float*)e2)
{
return 0;
}
else if (*(float*)e1 > *(float*)e2)
{
return 1;
}
else
{
return -1;
}
}
void test2()
{
float f[] = { 9.0, 8.0, 7.0, 6.0, 5.0, 4.0};
int sz = sizeof(f) / sizeof(f[0]);
qsort(f, sz, sizeof(f[0]), compare_f);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%.1f ", f[i]);
}
}
struct stu
{
char name[20];
int age;
};
int compare_by_age(const void*e1, const void*e2)
{
return ((struct stu*) e1)->age - ((struct stu*)e2)->age;
}
void test3()
{
struct stu s[3] = { { "zhangsan", 20 }, { "lisi", 30 }, { "wangwu", 10 } };
int sz = sizeof(s) / sizeof(s[0]);
qsort(s, sz, sizeof(s[0]), compare_by_age);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", s[i].age);
}
}
int compare_by_name(const void*e1, const void*e2)
{
return strcmp( ((struct stu*) e1)->name,((struct stu*)e2)->name);// 名字比較,就是字串比較,不能用大于,等于和小于來比較
} // 這里需要 用到 strcmp 函式
// 回傳值跟 大小等于的回傳值是一樣的,0 ,正數,負數
void test4()
{
struct stu s2[3] = { { "zhangsan", 20 },{ "lisi", 30 }, { "wangwu", 10 } };
int sz = sizeof(s2) / sizeof(s2[0]);
qsort(s2, sz, sizeof(s2[0]), compare_by_name);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s ", s2[i].name);
}
}
int main()
{
test();
printf("\n");
test2();
printf("\n");
test3();
printf("\n");
test4();
return 0;
}
qsort(陣列名,該陣列元素個數,該陣列單個元素記憶體大小,(函式指標,比較兩個元素的 所用函式 函式 的 地址 )函式指標的 兩個引數 是:待比較的兩個元素的地址
改進冒泡排序(回呼函式)
#include<stdio.h>
//實作 bubble_sort函式 的程式員,他 是否知道 未來排序 的 資料型別 - 不知道
//程式員也不知道 待 比較 的 兩個元素 的 型別
swap(char* buf1, char*buf2, int width)
{ 我們的 叫換函式,是通過一個位元組,一個位元組的進行交換
運用了 qsort 引數中的 元素大小,進行實作的
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
int compare_int(const void*e1, const void*e2)
{
return *(int*)e1 - *(int*)e2;
}
void bubble_sort(void*base, int sz, int width, int(*compare)(void*e1, void*e2))// 模擬 qsort 函式
{
int i = 0;
for (i = 0; i < sz; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
//兩個元素比較,前者比后者大,compare 會回傳一個 大于 0 的數字,小于(回傳一個差值(負的))相等(回傳0)
大于,回傳 一個 正數,條件成立,執行 if 陳述句,進行交換兩個元素的位置,其它情況,則不做改動,
if (compare((char*)base + j*width, (char*)base + (j + 1)*width)>0)// 這里實在呼叫int 函式名(const void*e1, const void*e2)
j 一開始 是 0, base 就是 第一個元素, base+(j+1),就是第二個元素
把他們交給 compare 函式 進行比較,如果 第一個元素 比 第二個元素 大
那就交換,否則,不交換,反上去,下回 j 就是 1,base 就第二個元素,base+(j+1)就是第三個元素
以此類推,
注意!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
((char*)base + j*width,的 char* 和 width(寬度【一個元素的大小】),這里我使用了 qsort 函式引數中 元素個數 和 元素大小,這兩點來實作我們的 元素遍歷,j*width 等于 跳過幾個元素(一個元素的大小 是 width,那 乘上 j,不就是跳過 j 個元素嘛,
{
//交換
由我們自制的交換函式去做
swap((char*)base + j*width, (char*)base + (j + 1)*width, width);
}
}
}
}
void test()
{
int arr[10] = { 9, 8, 7, 6, 5, 4, 3, 2, 1, 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
// 使用 bubble_sort 的程式員 一定要知道自己排序的是什么資料
//他就應該知道 如何比較待排序陣列中的元素
bubble_sort(arr, sz, sizeof(arr[0]), compare_int);
}
struct stu
{
char name[20];
int age;
};
int compare_by_age(const void*e1, const void*e2)
{
return ((struct stu*) e1)->age - ((struct stu*)e2)->age;// 因為 箭頭 的 優先級,強制型別轉換
}
void test2()
{
struct stu s[3] = { { "zhangsan", 20 }, { "lisi", 30 }, { "wangwu", 10 } };
int sz = sizeof(s) / sizeof(s[0]);
bubble_sort(s, sz, sizeof(s[0]), compare_by_age);
}
int compare_by_name(const void*e1, const void*e2)
{
return strcmp(((struct stu*) e1)->name, ((struct stu*)e2)->name);// 名字比較,就是字串比較,不能用大于,等于和小于來比較
} // 這里需要 用到 strcmp 函式
//
void test3()
{
struct stu s[3] = { { "zhangsan", 20 }, { "lisi", 30 }, { "wangwu", 10 } };
int sz = sizeof(s) / sizeof(s[0]);
bubble_sort(s, sz, sizeof(s[0]), compare_by_name);
}
int main()
{
test();
printf("\n");
test2();
printf("\n");
test3();
return 0;
}
本文結束
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/305508.html
標籤:其他
上一篇:海明碼/漢明碼的計算和糾錯
下一篇:實作簡易通訊錄(動態增長版)