● - 集群誕生的原因:
在當今的高并發環境中,對計算機性能的要求越來越高,通常提升性能的方式有兩種:
scale up 向上擴展:
提升現有主機的硬體性能,例如將單臺服務器進行硬體升級;
比如提升CPU或記憶體的性能,或者淘汰掉舊服務器,淘汰掉舊服務器;
即Scale vertically)縱向擴展,向上擴展,
稱為單節點系統,指系統中只包括一個有效節點(如果需要HA時,可以將兩個單節點以System Replication形式構成單節點的HA架構),這種架構的系統只具有垂直擴展能力,當需要擴展系統時,通過在節點上增加更多的CPU、記憶體和硬碟來擴大系統的能力,
Scale-up通過購買性能更好的硬體提升系統的并發處理能力,
比如:我們向原有的機器增加CPU、記憶體數,
scale out 向外擴展:
多節點擴展,將復雜任務分散給多個單點主機進行處理;
水平擴展,即計算機集群;
即Scale horizontally,橫向擴展,向外擴展 ,
稱為集群系統,指由多個節點組成的系統,這種系統的擴展主要以水平擴展方式(指增加節點的方式)來進行,
Scale-out 通過將多個低性能的機器組成一個分布式集群來共同抵御高并發流量的沖擊,
比如向原有的web、郵件系統添加一個新機器,
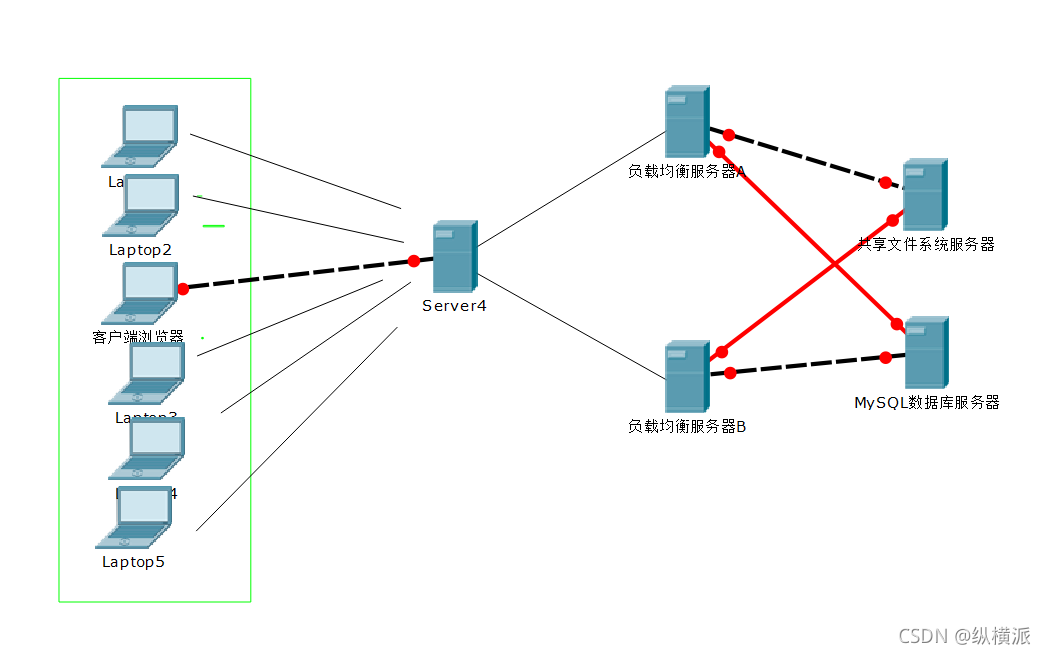
負載均衡集群
簡單的集群架構圖:
思考一下:當圖中兩個web服務器提供同樣的web服務時,由于被隨機分配至A或B上,這時如果之前客戶端在A服務器上上傳了圖片或文章,下次登錄時被分配到了B服務器,那么之前上傳在A服務器上的圖片和文章就不能訪問到了,為了避免這類問題,所以在后端使用了檔案共享服務器和資料庫服務器,這樣就保證了A和B服務器都可以讀取到同樣的資料或圖片;
客戶端瀏覽器:眾多的客戶端向服務器發起請求,訪問web服務;
server4:將來自不同客戶端的請求分散給后端的web服務器進行回應;
負載均衡服務器A、B:提供web服務,一般是nginx或apache;
檔案共享服務器:一般是NFS共享檔案系統,將web服務需要的網頁檔案存在此主機上;比如圖片;()
MySQL資料庫服務器:將web服務器需要讀取或存入的資料存在此服務器上;比如文章;
資料型別有三種:結構化資料,非結構化資料,半結構化資料;
●Cookie和Session機制:
HTTP協議是無狀態的,無狀態的意思就是服務器無法判斷用戶身份,現今有很多網站需要追蹤客戶端的訪問行為并記錄,比如電商站點,需要記錄客戶端瀏覽了哪些商品,在購物車加入了哪些商品等資訊,或者客戶訪問了哪些網站,這些資訊如果未同步提供web集群上,會導致用戶資料缺失;
舉例:比如客戶端首次訪問某電商網站被服務器A回應并建立會話連接,客戶端加入了自己挑選的商品在
購物車中,這時客戶端斷開連接并停止訪問網站了,過了兩天,這個用戶再次登錄,而這次負責建立連接
回應的是服務器B,因為B服務器中沒有之前用戶加入購物車的資料,那么用戶就無法查看到自己之前的商
品,這種體驗感就會大大下降,用戶一氣之下洗掉軟體也是非常可能的,哈哈~
那么為了避免這種情況的發生,就用到了cookie和session了;
我們看這張圖:
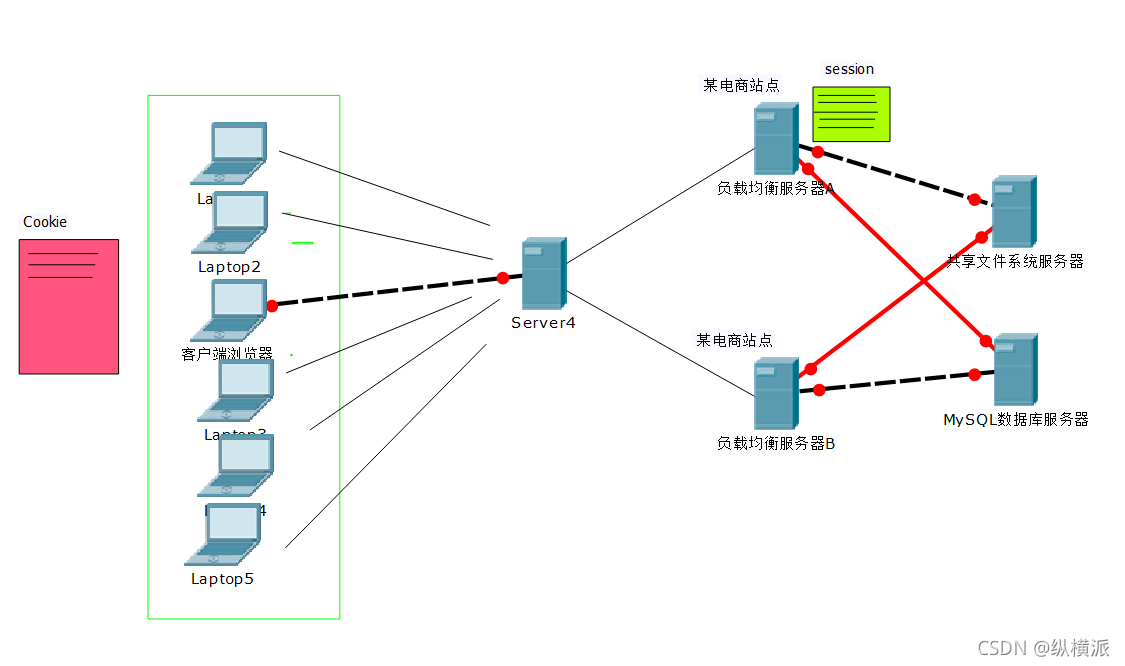
-
cookie:
在客戶端訪問站點時,如果服務器需要記錄用戶狀態,那么服務端會頒發給客戶端一個cookie檔案,客戶端將cookie保存在本地瀏覽器中,這個檔案將用戶使用瀏覽器在站點上的各種行為都記錄在cookie檔案中,每次客戶端訪問站點時,都將這個cookie檔案發送給服務器端,服務器通過讀取cookie檔案中的資料來識別用戶狀態;

將用戶狀態記錄在cookie中的機制也叫“胖cookie”機制,這種機制存在一些隱患,比如用戶再某站點的cookie被另外一個有競爭關系的站點所截獲,那么用戶的資訊就會有泄露的風險,所以還有一種機制即避免泄露用戶資訊,也能記錄用戶狀態,就是session機制; -
session:
session與cookie效果是相同的,都可以記錄用戶的狀態資料,區別在于session是記錄在服務器端的,我把這個記錄形式想象成一個表,專門記錄session的鍵、值等資訊,
當客戶端訪問服務端時,服務端會檢查客戶端的請求中是否包含了一個sessionID,如果有則證明之前給這個客戶端創建過,反之沒有的話則新建一個session資訊在表中,這個session資訊是對應關系,有sessionID和這個ID對應的資料資訊,sessionID是唯一標識的,不會重復的ID,服務器將sessionID發給客戶端,客戶端保存起來(有可能是保存在cookie中,這個cookie只保存sessionID而不保存用戶狀態,可能叫"瘦cookie"),每次客戶端發起請求時都將自己的sessionID發給服務器端,服務器端在自己的表或庫中檢索匹配相應的用戶狀態資料,這樣就可以保持用戶的狀態資訊了;
參考:
讓我們用幾個例子來描述一下cookie和session機制之間的區別與聯系,筆者曾經常去的一家咖啡店有喝5杯咖啡免費贈一杯咖啡的優惠,然而一次性消費5杯咖啡的機會微乎其微,這時就需要某種方式來紀錄某位顧客的消費數量,想象一下其實也無外乎下面的幾種方案:
1、該店的店員很厲害,能記住每位顧客的消費數量,只要顧客一走進咖啡店,
店員就知道該怎么對待了,這種做法就是協議本身支持狀態,
2、發給顧客一張卡片,上面記錄著消費的數量,一般還有個有效期限,每次消費時,
如果顧客出示這張卡片,則此次消費就會與以前或以后的消費相聯系起來,這種做法就是在客戶端保持狀態,
3、發給顧客一張會員卡,除了卡號之外什么資訊也不紀錄,每次消費時,如果顧客出示該卡片,
則店員在店里的紀錄本上找到這個卡號對應的紀錄添加一些消費資訊,這種做法就是在服務器端保持狀態,
由于HTTP協議是無狀態的,而出于種種考慮也不希望使之成為有狀態的,因此,后面兩種方案就成為現實的選擇,
具體來說cookie機制采用的是在客戶端保持狀態的方案,而session機制采用的是在服務器端保持狀態的方案,
同時我們也看到,由于采用服務器端保持狀態的方案在客戶端也需要保存一個標識,所以session機制可能需要
借助于cookie機制來達到保存標識的目的,但實際上它還有其他選擇,
簡單了解完cookie與session機制和作業原理,我們回到本文的集群正題中來!!!
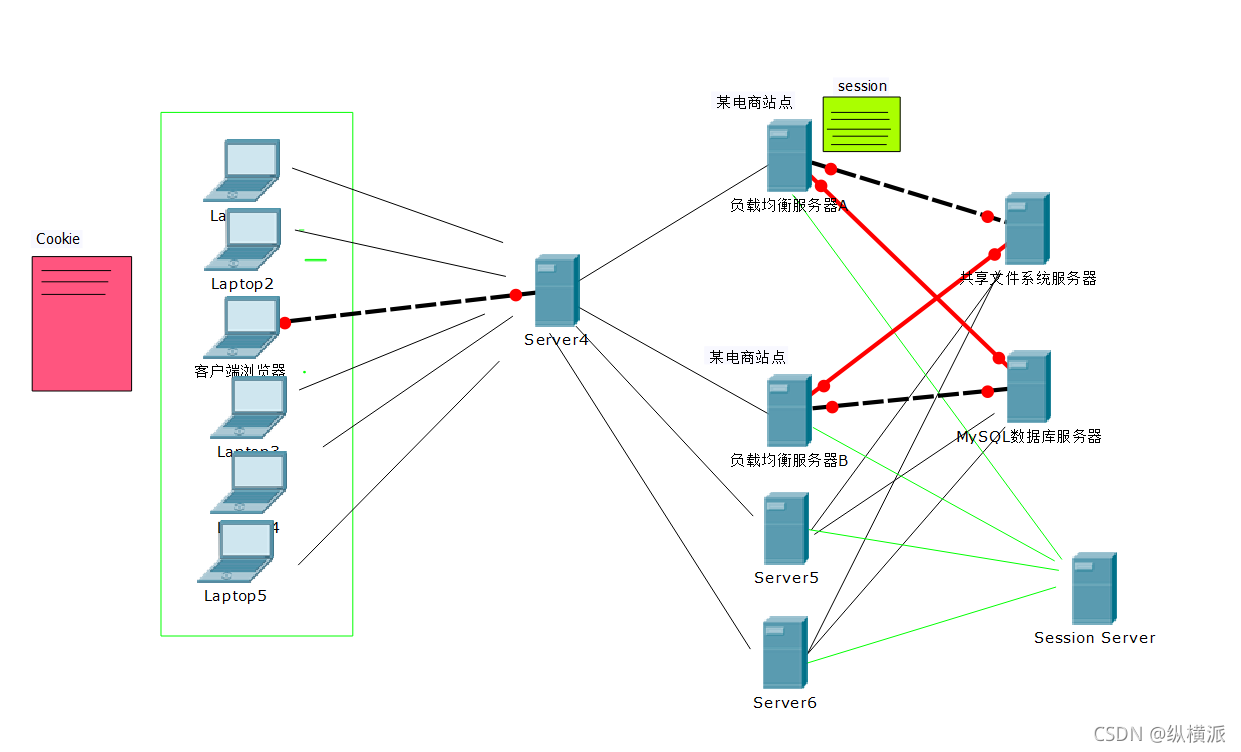
我們看這張圖,在右下角增加了一臺session server,它是做什么的呢?
當我們的集群變多時,客戶端每次的訪問就會輪流到不同的服務器上,比如第一次是有服務器A負責回應的,那么客戶端的session資料就保存在了服務器A上,下次客戶端訪問如果輪流到其他服務器上,那么就不會有之前在A服務器上的session資訊,這樣就麻煩了,session server就是負責給集群中的服務器共享session資料的,讓每一臺服務器都可以獲取到所有session資料;
其實要實作session共享有三種方式都可以,各自有自己的優點和缺點,簡單介紹一下三個方式:
集群下實作Session共享的幾種方案
1.Session Sticky
請求精確定位:基于IP地址的Hash策略,將同一用戶的請求都集中在一臺服務器上,這臺服務器上保存了該用戶的Session資訊,
讓負載均衡器能夠根據每次的請求的會話標識來進行請求的轉發,這樣就能保證每次都能落到同一臺服務器上面,這種方式稱為Session Sticky方式,
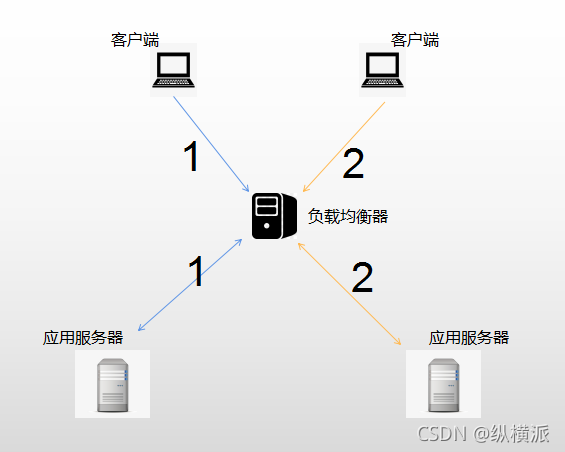
存在問題:
a. 如果這一臺Web服務器宕機或者重啟了,服務器上的會話資料會丟失,用戶需要重新登陸等,
b. 會話標識是應用層的資訊,那么負載均衡器要將同一個會話的請求都保存到同一個Web服務器上的話,就需要進行應用層的決議,這個開銷比第四層交換(LVS負載均衡器屬于第四層)要大,
c. 負載均衡器變為一個有狀態的節點,要將會話保存到具體的Web服務器的映射,和無狀態的節點相比,記憶體消耗會更大,容災方面會更麻煩,
打個比方,比如Web服務器是飯店,會話資料是碗筷,要保證每次吃飯都用自己的碗筷的話,我就把餐具存在某一家飯店,并且每次都去這家店吃飯,
2.Session Replication
Session復制共享:比如可以用Tomcat自帶的插件進行Session同步,使得多臺應用服務器之間自動同步Session,保持一致,如果一臺發生故障,負載均衡會遍歷尋找可用節點,Session也不會丟失,缺點:必須是Tomcat和Tomcat之間,Session的復制也會消耗系統 的性能,使得同步給成員時容易造成內網流量瓶頸,
還是以吃飯的例子,如果我們在每個飯店都存放一套自己的碗筷,就可以自己的選擇去哪家吃飯了,這就是Session Replication,如下圖:
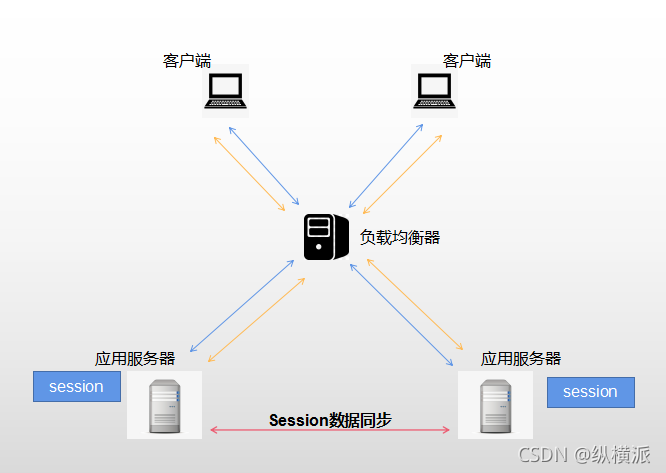
此方案不用再要求負載均衡器保證同一個會話的多次請求必須到同一個Web服務器上了,我們在Web服務器之間增加了會話資料的同步,通過同步就保證了不同Web服務器之間Session資料的一致,一般應用容器都支持Session Replication方式,與Session Sticky方案相比,Session Replication方式對負載均衡器沒有那么多的要求,
存在問題:
a. 同步Session資料造成了網路帶寬的開銷,只要Session資料有變化,就需要將資料同步到所有其他機器上,機器越多,同步帶來的網路帶寬開銷就越大,
b. 每臺Web服務器都要保存所有Session資料,如果整個集群的Session資料很多(很多人同時訪問網站)的話,每臺機器用于保存Session資料的內容占用會很嚴重,
這個方案是靠應用容器來完成Session的復制從而解決Session的問題的,應用本身并不關心這個事情,這個方案不適合集群機器數多的場景,如果只有幾臺機器,用這個方案是可以的,
3.Session資料集中存盤
基于cache DB快取的Session共享(推薦,Spring-Session也是同樣的原理,同自定義的JRedis一起配置可以實作目的):使用Redis存取Session資訊,應用服務器發生故障時,當Session不在記憶體中時就會去CacheDB中查找(要求Redis支持持久化),找到則復制到本機,實作Session共享和高可用,
將Session資料集中存盤,然后不同Web服務器從同樣的地方獲取Session,如下圖:
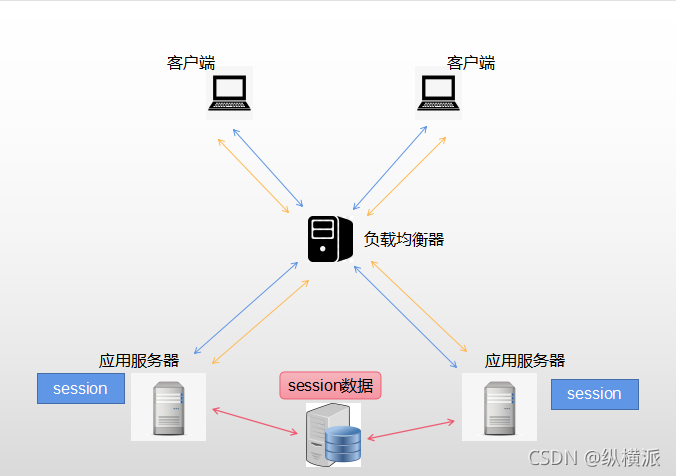
Session資料不保存到本機而且存放到一個集中存盤的地方,修改Session也是發生在集中存盤的地方,Web服務器使用Session從集中存盤的地方讀取,這樣保證了不同Web服務器讀取到的Session資料都是一樣的,存盤Session的具體方式可以是資料庫、分布式存盤系統等,這個方案解決了Session Replication方案中記憶體的問題,對于網路帶寬也比Session Replication要好,
存在問題:
a. 讀寫Session資料引入了網路操作,這相對于本機的資料讀取來說,問題就在于存在時延和不穩定性,不過我們的通訊基本都是發生在內網,問題不大,
b. 如果集中存盤Session的機器或者集群有問題,就會影響到我們的應用,
相對于Session Replication,當Web服務器數量比較大、Session數比較多的時候,這個集中存盤方案的優勢是非常明顯的,
●集群單點故障及冗余備份
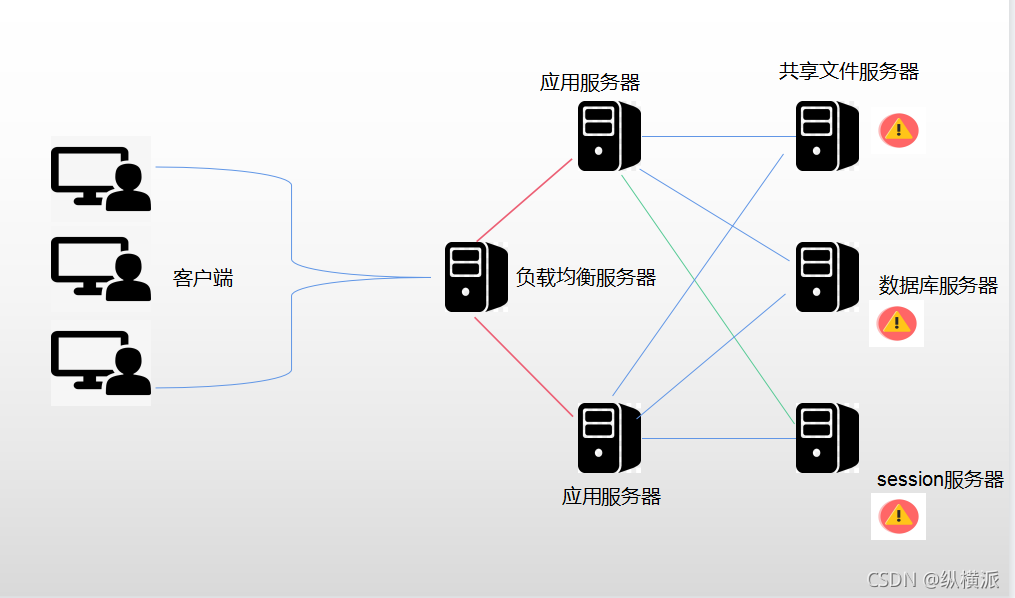
在集群架構中因某個節點故障導致全域無法運轉的故障叫做單點故障,上圖中標有嘆號的服務器一旦發生故障就會導致前端應用服務器不能提供正常的服務,在集群中要盡量避免這種情況的發生,所有關鍵性節點做好冗余備份;
●負載均衡器
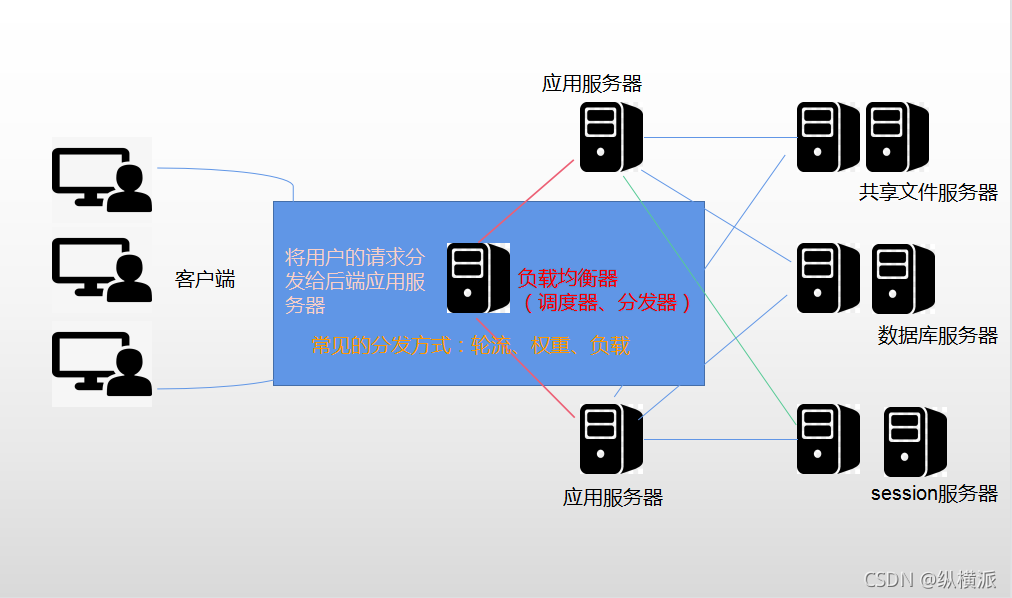
負載均衡器的三種分發方式:基于不同的調度演算法實作不同的分發方式;
輪流:集群中所有參與的服務器輪流負責回應,你一次我一次按順序輪流;
權重:給某臺服務器增加權重占比,比如性能好的服務器權重高,實作能者多勞;
負載:按服務器的負載情況來進分發,優先給負載低的服務器分發任務;比如哪個服務器的會話鏈接最少,就給它發任務;
負載均衡器是接收所有用戶請求并實作分發服務任務的最重要的一環,所以這里一定不要使用單點,要給負載均衡器做冗余,如果作業中的負載均衡器故障了,要有其他負載均衡器可以立刻接替作業,正常提供服務;
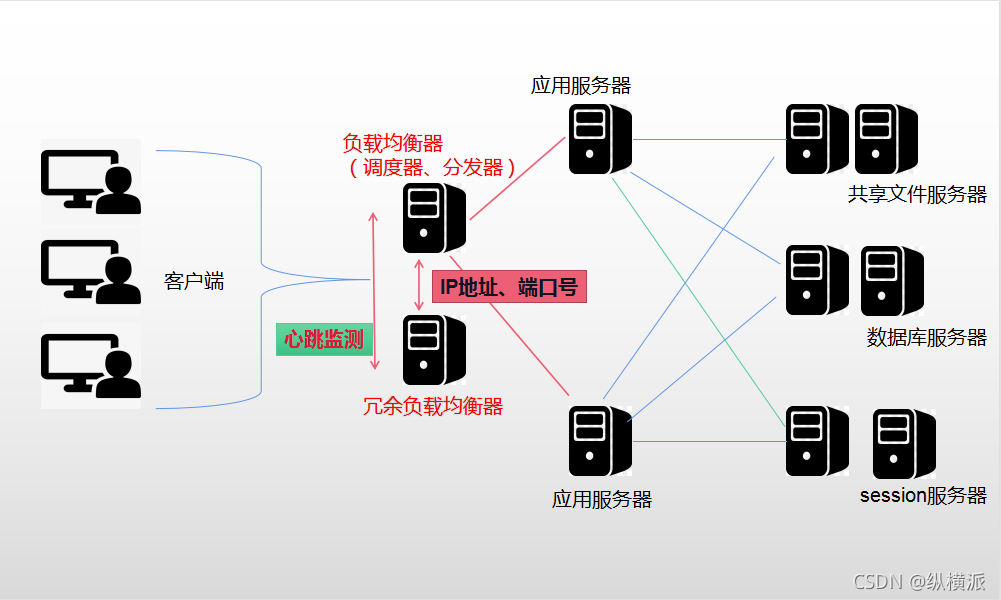
上圖所示:負載均衡器有主備關系,二者之間是持續保持連接的,主設備定期向備用設備發送報文,告知自己一切正常,可以看做是心跳正常,一旦備用服務器在一定時間沒有接收到主設備發來的心跳監測,那么備用服務器就認定主設備宕機了,這時備用設備就把主設備的IP地址和埠號拿過來使用,“搖身一變”就成了負責回應用戶端的調度器了;
failover:在集群中,在一個主機發生故障時,把它所提供的服務轉移至其他主機,叫做故障轉移,也叫失效轉移;
failback:一旦自己接觸故障,又恢復回來作業,叫做故障恢復;
高可用集群,像給負載均衡器添加冗余的這種思想就是高可用集群的思想;提升可用性;high availability cluster
Linux Cluster型別:
LB:Load Balancing,負載均衡;
HA:High Availiablity,高可用;避免SPOF(single point of failure)單點失敗
MTBF:平均無故障時間
MTTR:平均恢復前時間
A=MTBF/(MTBF+MTTR)
(0,1):90%, 95%, 99%, 99.5%, 99.9%, 99.99%, 99.999%, 99.9999%
HP:High Performance,高性能;
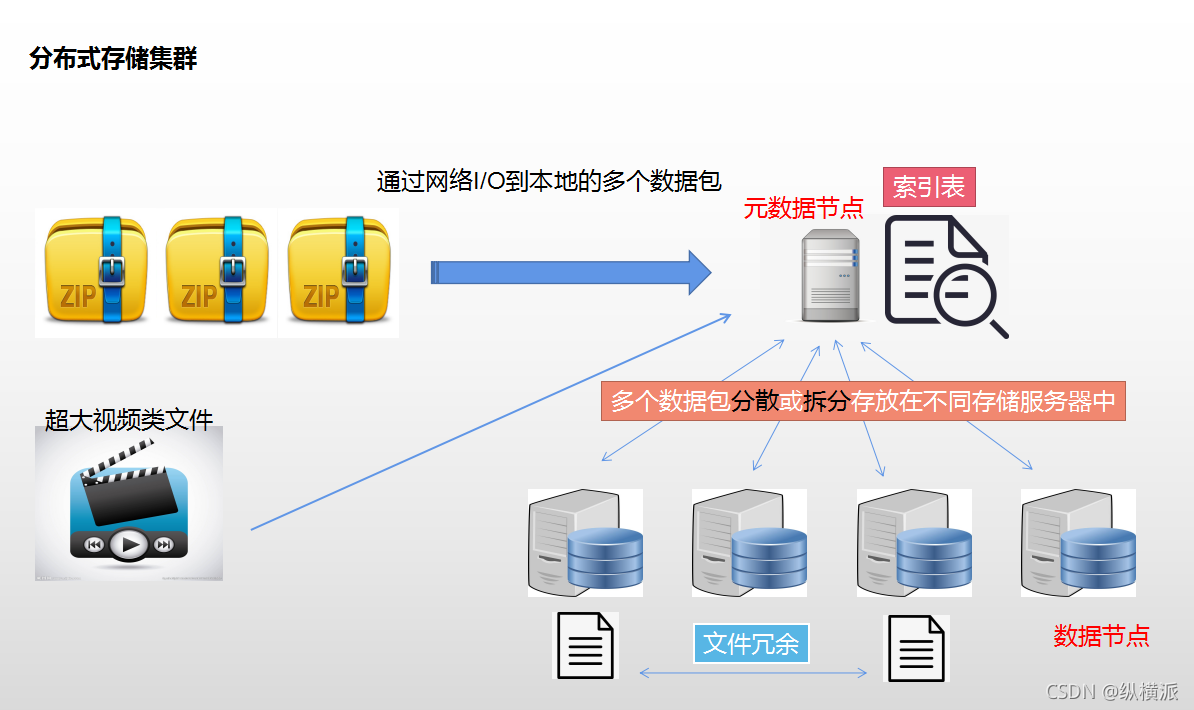
分布式系統:
分布式存盤
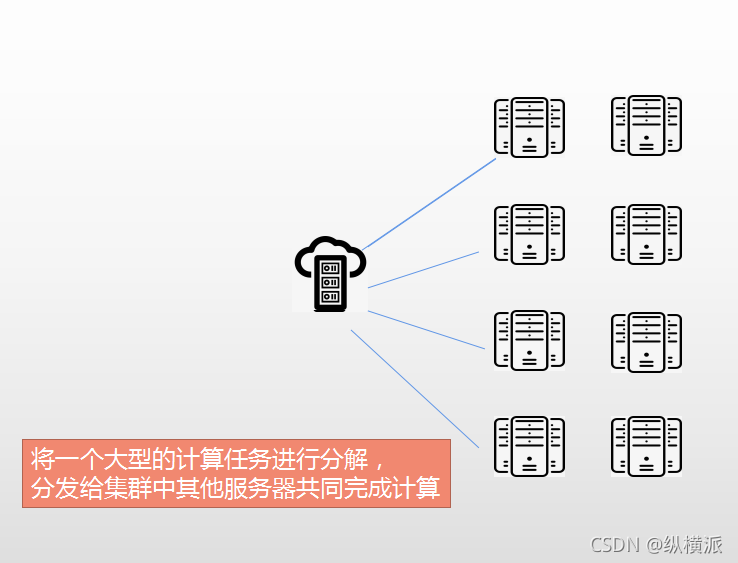
分布式計算
系統擴展方式:
scale up:向上擴展
scale out:向外擴展,集群方式都是此類,也是主流的系統擴展方式;
集群的種類就先學習到這里,如果有不對地方歡迎給與指正糾錯;
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/306204.html
標籤:其他