
目錄
?
零.前言
1.分治法
1.含義
2.分治法主要思想
3.分治法的求解步驟
1.確定初始條件
2.計算每一部分的時間復雜度
3.合并時間復雜度
4.求解
3.最大最小值問題
1.問題描述
2.常規思想
3.用分治法改進演算法一:
1.演算法思想
2.圖解
3.計算時間復雜度
4.偽代碼實作
4.用分治法改進演算法2:
1.演算法思想:
2.圖解
3.偽代碼實作
4.計算時間復雜度
4.大數乘法問題
1.問題描述
2.常規演算法
3.分治法的初級改進
1.演算法思想
2.計算時間復雜度
4.分治法的進一步改進
1.演算法思想
2.計算時間復雜度
5.總結
5.棋盤覆寫問題
1.問題描述
2.用分治法思想分析問題
3.計算時間復雜度
6.中位數問題
1.歷史背景
2.分析問題
3.求解步驟
4.圖解
5.計算每一步的時間復雜度
6.偽代碼實作
7.排序的基本知識
1.排序的概念
1.內部排序
2.外部排序
2.排序的流程
1.排序流程
2.舉例
3.內部排序
1.內部排序的特點
2.分類
4.基于分治法的排序演算法
8.歸并排序(Mergesort)
1.含義
2.圖解
3.偽代碼實作
4.計算時間復雜度
9.快速排序1(Quicksort:Partition)
1.含義
2.圖解
3.偽代碼實作
4.演算法復雜度分析
1.最好情況
2.最壞情況
3.平均情況
10.快速排序2(Quicksort:PartitionRundom)
1.含義
2.偽代碼實作
3.演算法性能分析
1.定義
2.分析
3.求解p(ij)
11.排序問題的下界
1.含義
2.最壞情況下排序的下界
1.引入
2.證明
3.平均情況時間復雜度的下界
1.引入
2.證明
12.思考題1
1.題干
2.求解
13.思考題2
1.題目
2.求解
3.偽代碼實作
4.計算時間復雜度
13.總結
零.前言
分而治之的演算法,即層層深入逐個突破,最終解決問題,就像玄幻小說斗破某穹里的主角一樣,不可能上來就把魂族給滅了,得一步一步來,先滅個小家族,滅個傭兵團,再滅個什么門,滅個云嵐宗,然后開始滅帝國,滅四方閣,滅魂殿,最后才輪到魂族,但是這些程序都驚人的相似,無非都是主角剛開始被揍的很慘(但總能帶走一個),最后不斷晉級將各個階級團滅,這里就用到了分而治之的方法,雖然是一點一點從基層來解決問題,但是手段都是一樣的,沒有一個佛怒火蓮解決不了的問題,,,
1.分治法
1.含義
將一個大的問題分解成若干個小的問題,并且這些小問題與大問題的問題性質保持一致,通過處理小問題從而處理大問題,這里用到了遞回的思想,
2.分治法主要思想
1.分:將整個問題分成多個子問題,
2.求解:求解各個子問題,
3.合并:合并所有子問題的解,從而得到原始問題的解,
3.分治法的求解步驟
1.確定初始條件
設輸入資料大小為n,T(n)為時間復雜度,且當n<c的時候,T(n)=θ(1),這里是規定了下限,避免無限遞回下去,這些內容不是自己定義的而是在題目中總結出來的,
2.計算每一部分的時間復雜度
分:假設劃分問題為a個子問題,每個子問題大小為n/b,則時間復雜度為D(n),即是關于n的函式,
求解:每個子問題和原問題的性質一致,原問題大小為n,時間復雜度為T(n),子問題大小為n/b,則子問題的時間復雜度為T(n/b),有a個子問題,所以總時間復雜度為aT(n/b),
合并:即將所有子問題的時間復雜度和并起來,共有a個子問題,所以合并的程序的時間復雜度也是n的函式假設時間復雜度為C(n),
3.合并時間復雜度
T(n)=aT(n)+D(n)+C(n)
4.求解
利用遞回方程的解法求解遞回方程主要有三種方法,遞回方程的解法可以參考演算法設計與分析部分的上一篇博客,歡迎來我的創作中心逛一逛呀!
下面我們用分治法來解決下列問題:
3.最大最小值問題
1.問題描述
輸入:陣列A[1,2,3……]
輸出:A中的最大值max和最小值min
2.常規思想
常規思想就是將第一個值賦為max,然后一個一個遍歷,發現比max大的值就賦給max,min同理,對于一個有n個元素的陣列,找最大最小值共比較了(2n-2)次,
3.用分治法改進演算法一:
1.演算法思想
首先來講演算法思想,我們將這組資料進行前與后兩兩比較,即比較A[0]和A[n-1],A[1]和A[n-2]依次類推,將兩者中較大的放在后面,將兩者中較小的放在前面,可以分成兩個部分,再用常規思想進行遍歷即可找到最大最小值,
2.圖解
假設排序的數列為:6,10,32,8,19,20,2
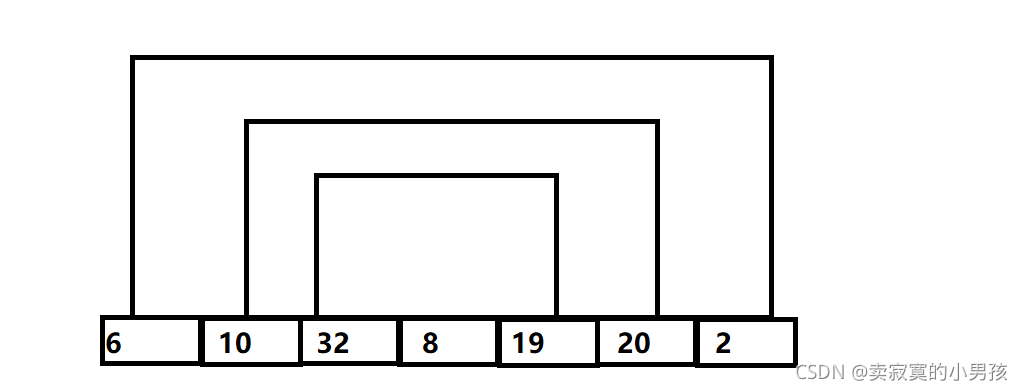
首先兩兩進行比較,交換后得到下列陣列:
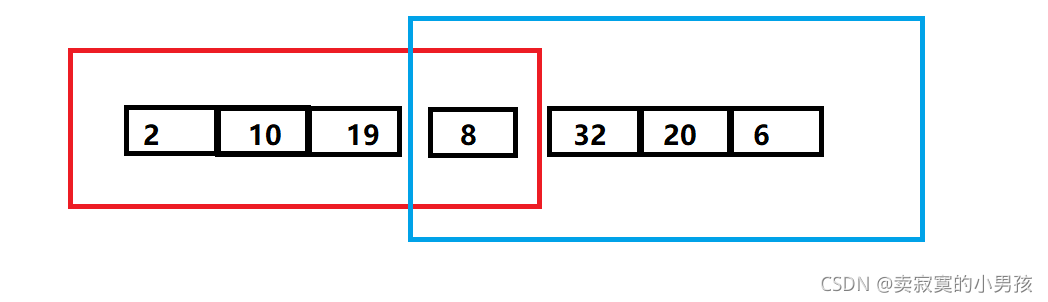
其中最小值在紅色框中出現,最大值在藍色框中出現,
3.計算時間復雜度
若沒有中間元素則一共需要遍歷(n/2-1)*2次,在加上分組所需要的次數n/2,一共需要3n/2-2次,
如果有中間元素,則分組需要(n-1)/2次 ,遍歷一共需要((n+1)/2-1)*2次,兩者相加得到3n/2-3/2次,
無論哪一種都比原來的(2n-2)小,這就是分治法的作用,
4.偽代碼實作
注意寫偽代碼之前要有宣告
STATEMENT
input:陣列A[1,2……n]
ouput:陣列A[1,2……n]中的最大元素
For i<--1 TO n/2 DO
IF A[i]>A[n+1-i] THEN swap(A[i],A[n+1-i];//交換相對稱的兩個元素
max<--A[n],min<--A[1];
For i<--2 TO n/2(取上界) DO
IF min>A[i] THEN min<--A[i];//在第一個集合里找到最小值
IF max<A[n-i+1] THEN max<--A[n-i+1];//在第二個集合里找到最大值
print max,min;4.用分治法改進演算法2:
1.演算法思想:
將一組數兩兩分組進行比較,每組都要選出最大最小值,再將每組的最大最小值進行兩兩比較,得到下一輪的最大最小值,并遞回下去,直到比較之后只剩下一個數,那么這個數就是該序列的最大或者最小值,
2.圖解
通過解這道題發現了一個求遞回函式的畫圖方法(機智如我):
假設要排序的數列為:6,10,32,8,19,20,2,14
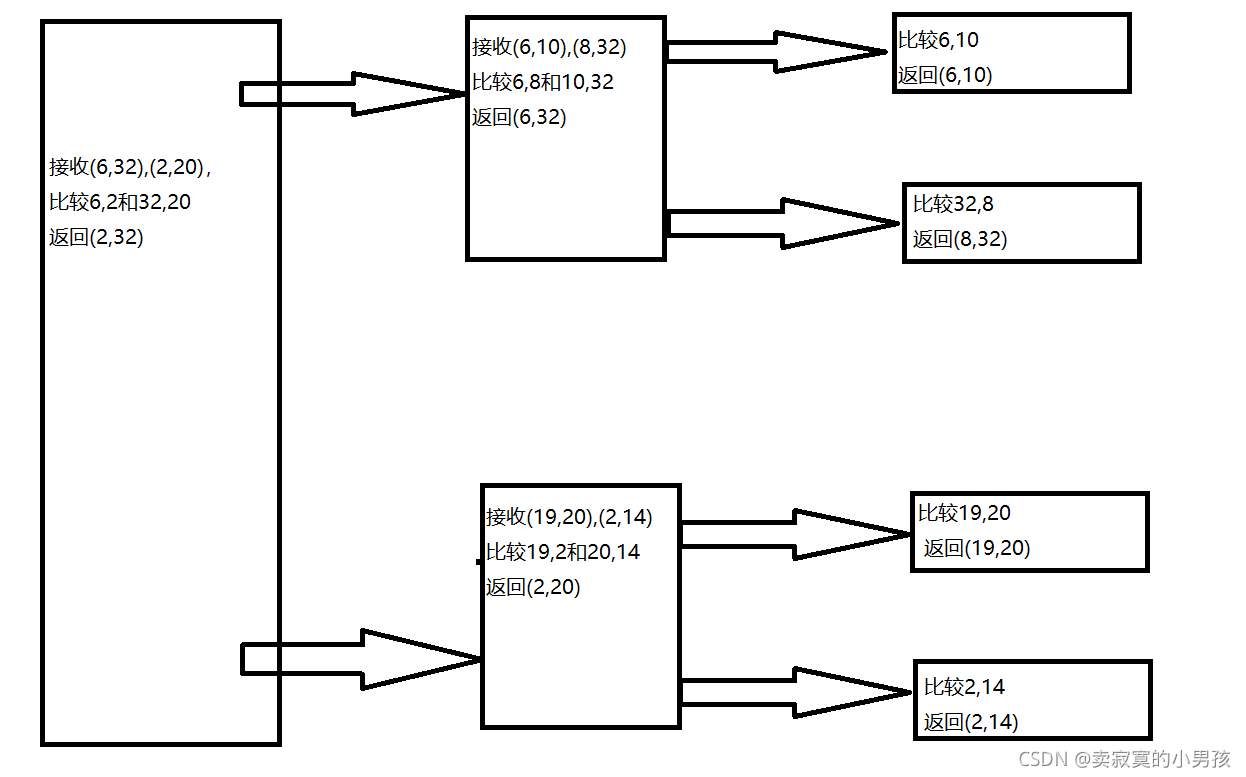
這里每一個模塊都代表了一次遞回,如果型別完全相同(包括執行代碼和回傳值),則模塊中的內容一樣,如果不同則模塊中的內容不同,即后面的四次是一樣的型別,前面的三次是一樣的型別,這么一看是不是很清晰呀,
3.偽代碼實作
STATEMENT
input:陣列A[1,2……n]
ouput:陣列A[1,2……n]的max和min
MAX_MIN(1,n) //表示函式首先傳的是1和n
MAX_MIN(low,high)
IF high-low=1 THEN
IF A[low]<A[high] THEN return (A[low],A[high]);
ELSE return (A[high],A[low]);//用于比較兩個相鄰元素的大小,是后四個模塊的模型
ELSE
mid<--(high+low)/2;
(x1,y1)<--MAX_MIN(low,mid);
(x2,y2)<--MAX_MIN(mid+1,high);
x<--max{y1,y2};
y<--min{x1,x2};//用于進行遞回比較,是前三個模塊的模型
return (x,y);4.計算時間復雜度
假設整體的時間復雜度為T(n),一共分為了兩組,所以每組的時間復雜度就為T(n/2),而最后還要進行兩次比較所以時間復雜度為:
T(n)=T(n/2)+2
根據遞回樹法求得
T(n)=3/2n-2
4.大數乘法問題
1.問題描述
輸入:n位二進制整數x,y
輸出:x和y的乘積
2.常規演算法
二進制數乘法的法則為:
0×0=0
0×1=1×0=0
1×1=1
由低位到高位,用乘數的每一位去乘被乘數,若乘數的某一位為1,則該次部分積為被乘數;若乘數的某一位為0,則該次部分積為0,某次部分積的最低位必須和本位乘數對齊,所有部分積相加的結果則為相乘得到的乘積,
這里多說一下幫大家科普一下,假如說我們要計算的是4*7=28
二進制的乘法計算規則和整數是一樣的:
列式:0100
* 0111
--------------------------
0100
0100
0100
-----------------------------
011100
即為28,這里將乘數的每一位都與被乘數相乘,最后結果再相加是一個θ(n^2)的演算法,
3.分治法的初級改進
1.演算法思想
 分別將x和y分為兩個二進制集合,其中A與B,C與D的二進制位的個數相同,
分別將x和y分為兩個二進制集合,其中A與B,C與D的二進制位的個數相同,
x*y=(A*2^(n/2)+b)*(C*2^(n/2)+D)=AC*2^n+(AD+BC)*2^(n/2)+BD
2.計算時間復雜度
此時要計算x*y就要計算AC,AD,BC,BD四個的值,假設T(n)是原式的時間復雜度,則AC,AD,BC,BD的時間復雜度均為T(n/2),所以T(n)=4T(n/2)+θ(n),根據主定理求得時間復雜度為O(n^2),
顯然這不滿足我們的需求,因為即使不使用分治法,計算的時間復雜度依然是O(n^2),
4.分治法的進一步改進
1.演算法思想
只要將第一步的x*y換一種寫法:x*y=AC*2^n+((A-B)*(D-C)+AC+BD)*2^(n/2)+BD
2.計算時間復雜度
此時只需要計算AC,(A-B)*(D-C),BD即可,三者的時間復雜度為T(n/2),所以T(n)=3T(n/2)+θ(n),根據主定理計算出時間復雜度為O(n^(log(2)(3))比O(n^2)小,所以得到了滿意的結果,
5.總結
我們發現一個式子經過不同的變換得到的時間復雜度是不同的,我們應該盡可能地減少乘法個數,增加加法或者減法個數,從而達到降低時間復雜度的目的,
5.棋盤覆寫問題
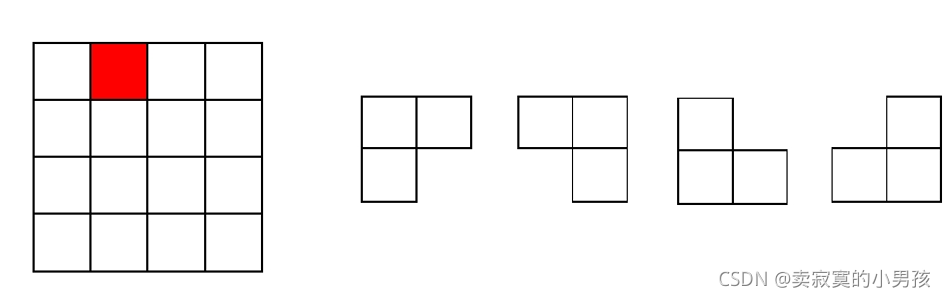
1.問題描述
在一塊4*4的棋盤上插入方塊組,其中棋盤上有一個方塊部分不能被覆寫,一共有四種形狀的方塊可供選擇,要求將除不能覆寫的地方全覆寫滿,
2.用分治法思想分析問題
正方格棋盤是4*4的分布,所以我們可以想到將之分為2*2的棋盤,即分為四個部分,
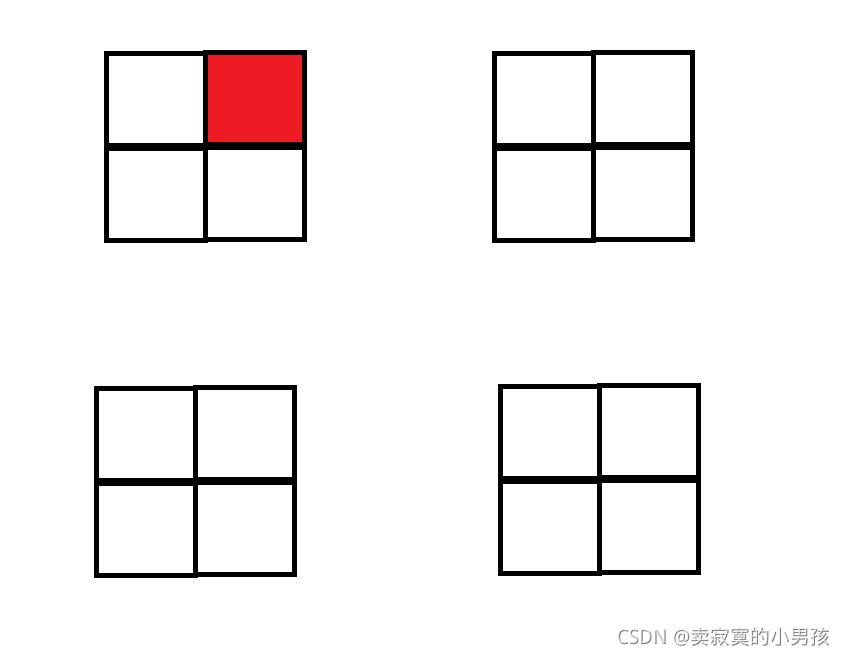
我們要做的就是在這四個部分中,找到相同的思想來填充,即在每個模塊中有且只能放一個方塊組合,且會空出一個未被填充,所以在填充的時候只需要注意將三個未被填充的空間連在一起來使之能存放一個方塊組,
注意我們應用的是分治法這一個方法,而不是我們思考怎么放方格組的程序,而是在思考之后放方格組這一行為算時間復雜度,即如何將未填充的方塊放在中間連在一起這一思考程序并不算時間復雜度,
3.計算時間復雜度
我們將在空一塊的2^k*2^k方格用四種不同形式的方格組填充這一程序的時間復雜度設為T(k),則我們需要將之分為2^(k-1)*2^(k-1)的四個方格組,每一個和原方格組一樣需要空一格出來,所以性質是相同的,時間復雜度為T(k-1),
所以T(k)=4T(k-1)+θ(1)
計算結果為T(k)=θ(4^k)
6.中位數問題
1.歷史背景
選擇中位數可以避免一組資料中最大值和最小值造成的影響,所以中位數也一直是人們樂于研究的問題,在歷史上人們對它的上界和下界進行了多次的研究,

2.分析問題
求中位數本質上就是查找某個陣列中第i大的數是哪個,所以轉化成查找第i個數多大的問題,下面討論如何在O(n)時間內查找n個元素中的第i個元素
input:n個數構成的集合X,整數i,1<=i<=n,
output:x∈X,且X中有i-1個元素小于x,
3.求解步驟
1.將整個陣列五個一組分為n/5組,計算出中位數應該在排好序后的第i個位置,
2.通過插入排序求出每組的中位數,
3.將這些中位數排成一個序列,找到中位數的中位數x,并記錄其下標k,
4.遍歷整個陣列,將比x的放在它的后面,比它小的放在前面,
5.如果i=k,則回傳x,
如果i<k,則在第一個部分遞回選取第i大的數,
如果i>k,則在第三個部分遞回選取第(i-k)大的數,
4.圖解
1.將整個陣列五個一組分為n/5組,計算出中位數應該在排好序后的第i個位置,

2.通過插入排序求出每組的中位數,
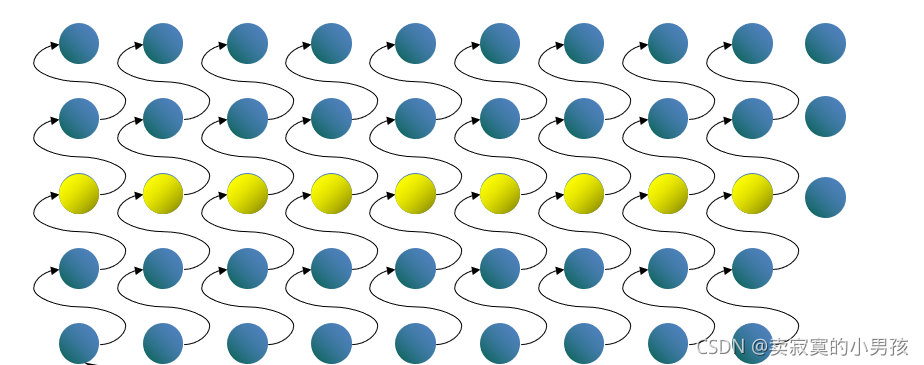
其中黃色的球為每一組的中位數,
3.將這些中位數排成一個序列,找到中位數的中位數x,并記錄其下標k,

其中紅色的球為這些中位數的中位數,即為x
4.遍歷整個陣列,將比x的放在它的后面,比它小的放在前面,
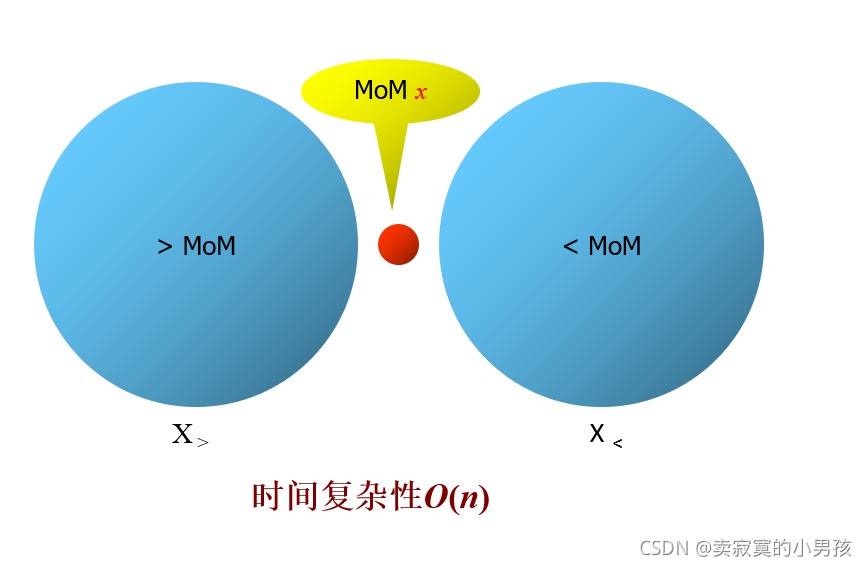
然后進行比較即可,
5.如果i=k,則回傳x,
如果i<k,則在第一個部分遞回選取第i大的數,
如果i>k,則在第三個部分遞回選取第(i-k)大的數,
5.計算每一步的時間復雜度
假設在n個數中找中位數的時間復雜度是T(n)
1.θ(1)
2.排序每組數時,比較操作的次數為5(5-1)/2=10次,總共需要10*(n/5)(取上界,把不夠5個的元素也算成了5個)次比較操作,時間復雜度為θ(n)
3.在n/5個數中尋找中位數,時間復雜度為T(n/5)(n/5取下界,因為多出來的不夠5個的元素沒參與比較),
4.遍歷整個陣列的時間復雜度是θ(n),
5.第五步相對來說比較復雜,而且是這個演算法的核心,還是拿圖說話:
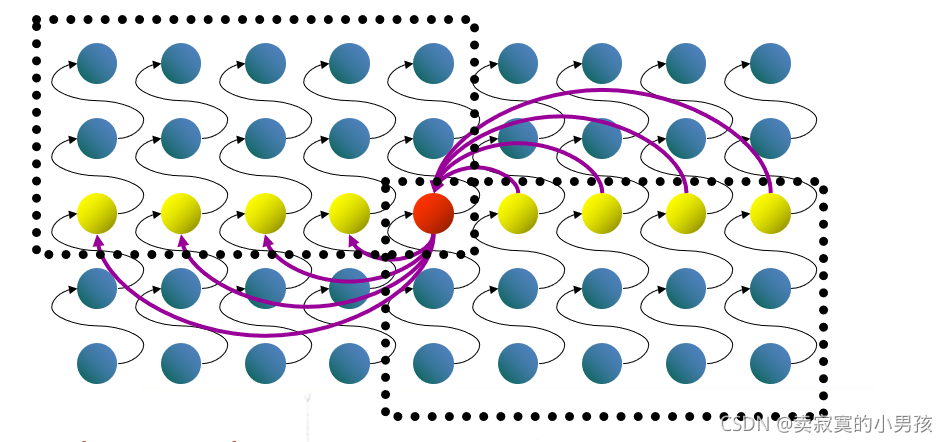
我們已經將資料分為了三組,分別是比x大的數,比x小的數和x,
當x為第i個元素時,演算法的復雜度就是θ(1),
當x不是第i個元素時,我們就要在它前面的資料中尋找第i大的元素,或者在它后面的資料中尋找第(i-k)大的元素,這和我們在n個數中尋找第i大的元素是同一性質的,所以復雜度也可以用T()來表示,我們只要知道要查找的元素個數就可以將之表示出來了,
通過圖我們可以看出,左邊方框中的元素是一定比x大的元素,右邊方框中的元素是一定比x小的元素,這些元素的個數為3*n/5/2(取下界),即比x大的元素最多有n-3*n/10(取下界)個,比n小的元素最多有n-3*n/10(取下界)個,所以在這些元素中查找第幾個數的時間復雜度一定不會超過T(7n/10+6),
將這幾步的時間復雜度加起來就是整個的時間復雜度:T(n)<=θ(n)+T(n/5)(取下界)+θ(n)+T(7n/10+6)
最終計算時間復雜度是小于O(n)的,
6.偽代碼實作
input :陣列A[1:n] //輸入陣列A有n個元素,:也可以表示‘到’的意思
output :A[1:n]中第i大的元素
Select(A,i)
For j<--1 TO n/5 DO
InsertSort(A[(j-1)*5+1],A[(j-1)*5+5];//利用插入排序尋找每一組中的中位數
swap(A[j],A[(j-1)*5+3]); //將所有中位數記錄在陣列A的前面
x<--Select(A[1:n/5],n/10); //在所有中位數中查找第n/10大的數,得到中位數的中位數x
k<--partition(A[1:n],x); //遍歷陣列A,將之分割成三部分,并找到x的坐標k
IF k=i THEN return x; //k為第i個元素則找到中位數x
else if k>i THEN return Select(A[1:k-1],i);//k>i在k之前尋找中位數
else THEN return Select(A[k+1:i-k); //k<i在k之后尋找中位數
7.排序的基本知識
分治法的優勢在排序中有著重要的體現,用了分治法的排序,才是時間復雜度最低的排序,在講解分治法對排序的影響時,我們先復習一下排序的基本知識,
1.排序的概念
排序是計算中經常進行的一系列操作,其目的是將一組“無序”的記錄序列調整為“有序”的記錄序列,簡單來說 無序->有序,
通常情況下排序分為兩種:內部排序,外部排序
1.內部排序
若整個排序的程序中不需要訪問外存便能完成,則成這類問題為內部排序,
2.外部排序
若參與排序的資料數量過大,整個序列排序程序中不可能在記憶體中完成,則稱此類排序為外部排序,
我們主要討論的是內部排序的各種方法,
2.排序的流程
1.排序流程
1.得到n個記錄資料的序列為{R1,R2,R3,R4,......,Rn},
2.找到這組資料每個元素的排序關鍵字(即排序依據)為{K1,K2,K3,K4,......,Kn},
3.利用函式對這些關鍵字進行比較發現{Kp1<=Kp2<=Kp3......<=Kpn},
4.將記錄數字的序列排序{Rp1,Rp2,Rp3,Rp4......Rpn},
將這一流程稱為排序的流程,
不要小看了這一流程,這是我們寫排序代碼時的步驟,可以讓你忙而不亂地完成任務,
2.舉例
假設要排序一組資料,資料中包含學生姓名和成績連個成員,要按成績從大到小排序,
1.羅列資料
(張三,89),(李四,55),(王五,79),(南宮問天,92),(東方鐵心,100)
2.找到這組資料的關鍵字
89,55,79,92,100
3.寫一個函式對這組關鍵字進行排序
100,92,89,79,55
4.對資料進行排序
(東方鐵心,100),(南宮問天,92),(張三,89),(王五,79),(李四,55)
對于這種既包含關鍵字又包含其他成分的我們通常使用結構體來記錄資料:
typedef define struct Record
{
char name[20];
integer score;
}Record;
Record R[5];
這里使用偽代碼創立了一個存盤資料元素的結構體,關于偽代碼的寫法可以逛逛我的博客呀!以后在演算法的這一部分我盡量都用偽代碼,方便學習各類語言的人都可以看懂(是不是很nice),
3.內部排序
1.內部排序的特點
在排序的程序中,參與排序的記錄序列中存在兩個區域:有序區和無序區,內部排序的程序是一個逐步擴大記錄的有序序列長度的程序,
使有序區中記錄的數目增加一個或幾個的操作稱為一趟排序,
舉個簡單的例子
假如對 3,1,6,8從大到小進行排序1,6,8就是一個有序序列,我們需要逐漸擴大這一有序序列,將有序序列的三個數變成4個數,就要將3和1調換位置,此時有序區數字增加了一個,所以該行為稱為一趟排序,
2.分類
我們根據逐步擴大記錄有序序列長度的方法有如下幾類:
1.插入類:將無序子序列中的一個或幾個記錄“插入”到有序序列中,從而增加記錄的有序子序列的長度,這一類排序有“直接插入排序”和“希爾排序”,
2.選擇類:從記錄的無序子序列中“選擇”關鍵字最小或最大的記錄,并將它加入到有序子序列中,以此方法增加記錄的有序子序列的長度,這一類排序有“簡單選擇排序”和“堆排序”,
3.交換類:通過“交換”無序序列中的記錄從而得到其中關鍵字最小或最大的記錄,并將它加入到有序子序列中,以此方法增加記錄的有序子序列的長度,
4.歸并類:通過“歸并”兩個或兩個以上的記錄有序子序列,逐步增加記錄有序序列的長度,
5.其他:比如還有一些基數排序的方法等,
4.基于分治法的排序演算法
主要有歸并排序和快速排序兩類,
mergesort(歸并排序):選擇一個位置將陣列劃分為兩個部分,
quicksort(快速排序):選擇一個劃分標準,根據元素與該標準的大小關系進行劃分,
不同的劃分策略對應不同的合并策略,
8.歸并排序(Mergesort)
1.含義
所謂歸并排序是指將兩個或兩個以上有序的數列(或有序表),合并成一個仍然有序的數列(或有序表),這樣的排序方法經常用于多個有序的資料檔案歸并成一個有序的資料檔案,
這是百度上給的定義,簡單地說就是先將元素分為兩兩一組,比較大小,在逐漸合并,每一次合并后的元素都是有序的,
歸并排序的求解是要從下向上進行的,但由于我們進行的是演算法分析,所以整個程序是從上向下分析的,
2.圖解
假設要排序一組數2,4,1,8,5,9,7,3
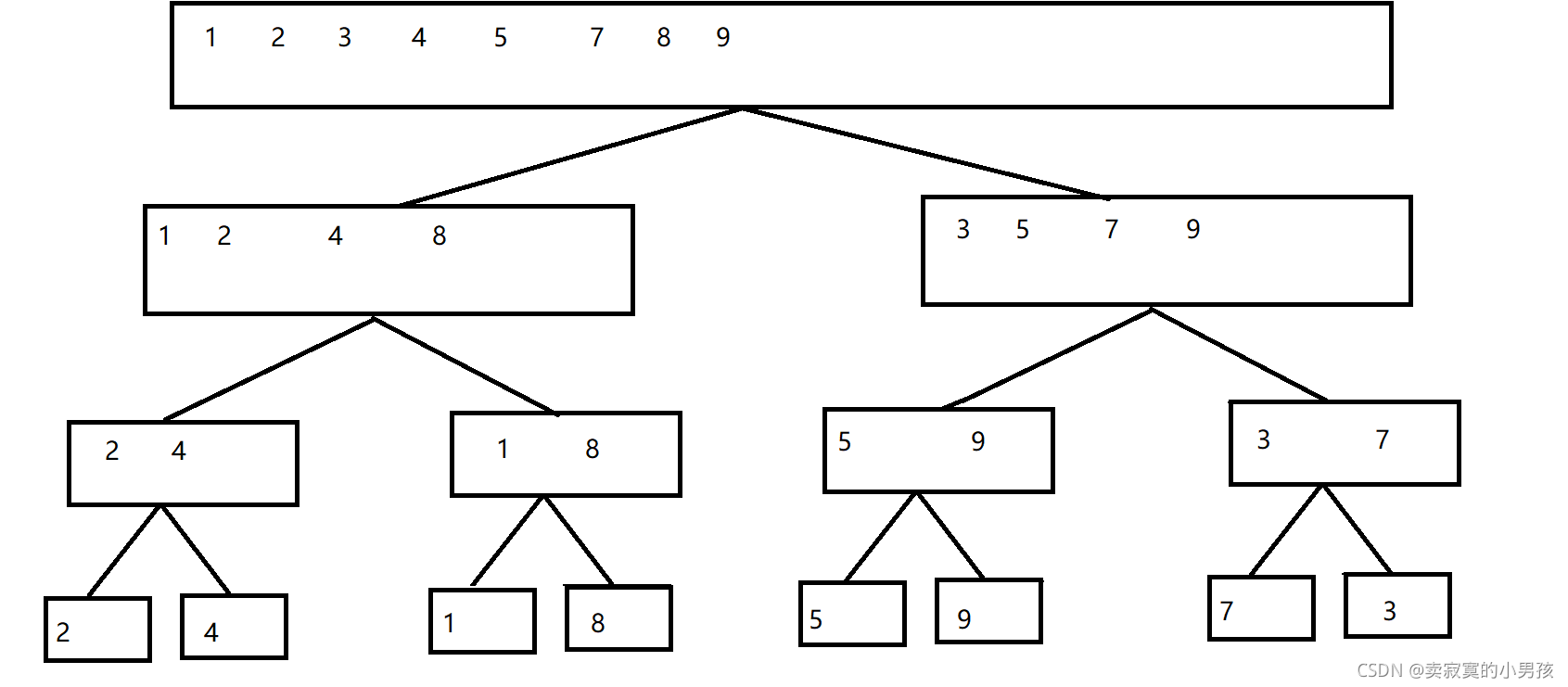
再說一下比較的程序,由于這不是演算法重點,就不畫圖了,以1 2 4 8和3 5 7 9為例,
首先定義指向1和3的指標,比較1和3的大小,把小的排在前面,然后將小的部分的指標加一,
3.偽代碼實作
input:A[i:j]
output:排序之后的A[i:j]
Mergesort(A.i,j)
k<--(i+j)/2;//找到陣列A中的中間值k作為分隔
Mergesort(A,i,k);//將前一半進行歸并排序
Mergesort(A,k+1,j);//將后一半進行歸并排序
l<--i,h<--k+1,t<--i//定義指標l和h分別指向兩個排好序的序列的第一個元素
While (l<=k AND h<=j) DO
IF A[l]>=A[h] THEN B[t]<--A[h];t++;h++;
ELSE THEN B[t]<--A[l];t++;l++;//將兩組數進行合并排序
IF l<k THEN
FOR v<--l TO k DO
B[t]<--A[v]; t++;
IF h<j THEN
FOR v<--k+1 TO j DO
B[t]<--A[v]; t++;//當第一組或第二組數個數多時,將多余的元素按順序插入到末尾4.計算時間復雜度
我們在計算時間復雜度時一定要先想到這里用到的是分治法,所以書寫演算法復雜度的方程時,一定是用遞回的形式來書寫的,
這里把將n個數進行歸并排序的時間復雜度記為T(n),那么n/2個數進行歸并排序的時間復雜度就是T(n/2),將兩組數比較的次數不超過n次,(一般沒有明確的比較次數的與資料量有關的時間復雜度中一定有n),所以剩余部分可以記為O(n),
所以T(n)=2T(n/2)+O(n),根據主定理計算出時間復雜度為O(nlgn),
9.快速排序1(Quicksort:Partition)
1.含義
快速排序兩種方法都應用到了分治法,Partition演算法是其中的一種,即先確定一個劃分標準x(通常為第一個元素),將陣列中小于x的元素放在陣列的前一部分,大于x的元素放到陣列的后面部分,并回傳一個劃分k,并進行遞回求解,
2.圖解
假設要排序一組資料7,3,4,9,2,8,這里的x是第一個元素,定義一個指向首元素的指標p和指向尾元素的指標q,當p指標++找到比x大的元素時停下來,當q指標--找到比x小的元素時停下來,并交換兩者指向的元素,直到q<p此時q前面的元素(包含q)比x小,p前面的元素(包含p)比x大,回傳q的值,進行下一次遞回,
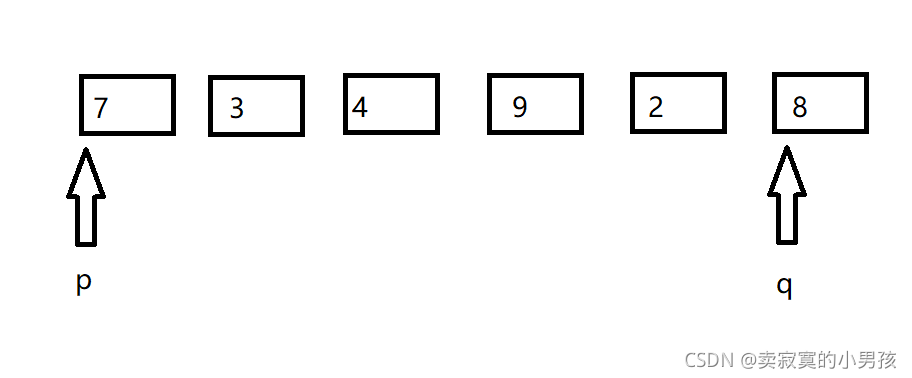
注意出于對函式的整體實作的考慮,為使每次使用函式時都一樣,所以第一次沒有進行任何比較的時候就需要交換一次,
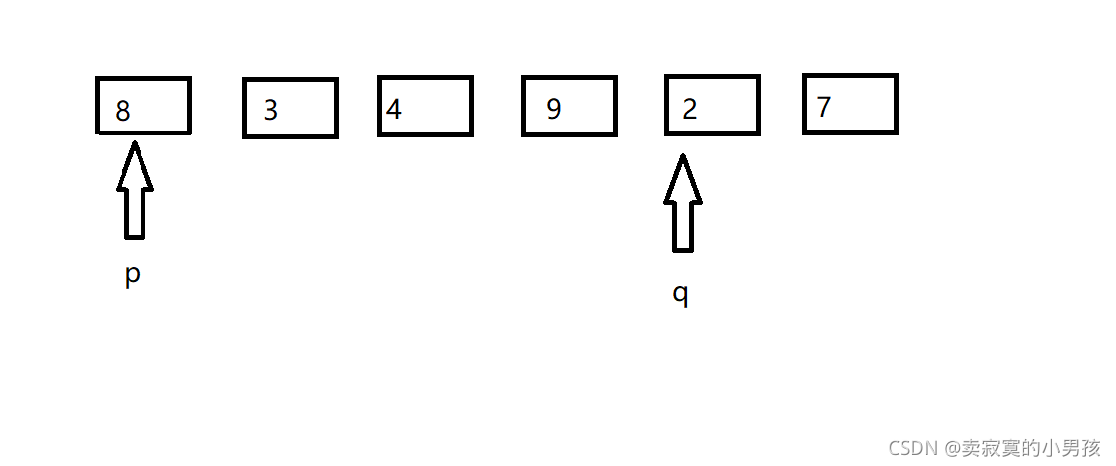
第一次交換后發現p指向的元素大于是8大于x,所以p不動,q指向的是7>=x,所以q--,之后q指向的元素是2所以q不動,
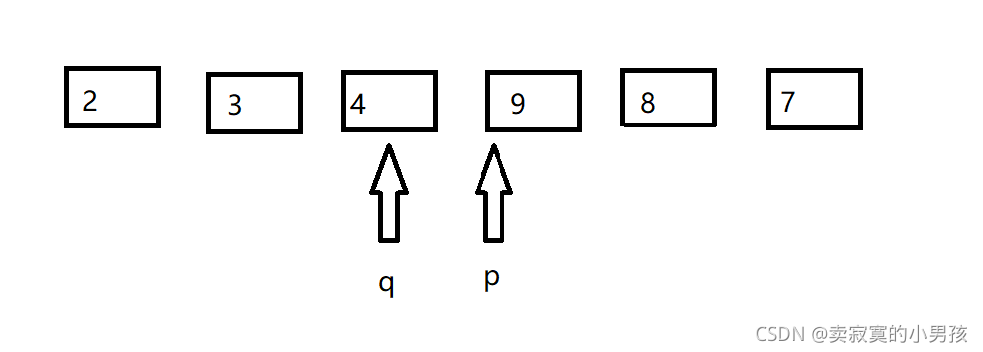
第二次交換后,p指向2比7小所以p++,直到p指向9比7大所以停下來,q指向8,比7大,q--直到q指向4,比7小所以停下來,
此時q<p,所以q前面的元素(包含q)比7小,p后面的元素(包含p)比7大,回傳q的值,再進行比較即可,
理解這段內容的關鍵就在于以每一次交換為一個周期,了解每一次交換之后發生的事情,
3.偽代碼實作
注意需要兩個函式來實作,分別是總框架partitionSort和分組函式partition
partitionSort(A,i,j)
input: A[i……j],x
ouput: 排序之后的A[i……j]
x<--A[i];
k=partition(A,i,j,x);//k來接識訓傳的q指標
IF(k==i) THEN return;//當q與i相等時停止,
partitionSort(A,i,k);//對q前面的元素進行分組
partitionSort(A,k+1,j);//對q后面的元素進行分組
partition(A,i,j,x)//進行分組
p<--i;q<--j; //兩指標就位
While(p<q) DO
swap(A[p],A[q]);//每次交換算一個周期
While(A[p]<x) DO
p<--p+1; //p指標++直到找到比x大的元素,停下來
While(A[q]>=x) DO
q<--q--; //q指標--直到找到比x小的元素,停下來
return q;4.演算法復雜度分析
1.最好情況
這一情況是最不重要的情況,在partition演算法里,最好的情況是陣列每次都能被分為大小相等的兩部分,設分隔m次,所以n/(2^m)=1,所以m=log(2)(n),每一輪都需要θ(n)次比較,所以時間復雜度為θ(nlog(2)(n)),
均分是最好情況的原因是,無論分幾次,比較的次數都是θ(n),所以只與分隔幾次有關,對于一組n個元素的陣列,將它們分成零散的元素,分隔次數最少的方法就是每次都進行均分,
同時分隔次數最多的方法就是每次都1個一個分,即為最壞的情況,
2.最壞情況
按一個元素一個元素來分,將每次比較的次數加起來得到時間復雜度為
(n-1)+(n-2)+……+1=n(n-1)/2=θ(n^2)
3.平均情況
平均情況即分隔點是任意找的,也是我們最經常遇到的一種情況,
設分隔點是第s大的元素
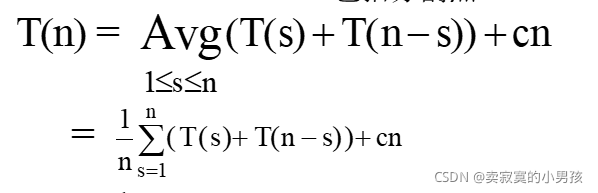
我們將s考慮到每一種情況,即分隔點可能是第1大,第二大,第三大,,,的元素,對每一種時間復雜度求和取平均得到平均時間復雜度,再加上第一次分隔時比較的次數cn,cn和n是同一個含義,但我們習慣于加一個系數,
展開
T(n)=1/n(2T(1)+2T(2)+......2T(n-1)+T(0)+T(n))+cn //注意這里T(0)=0所以可以刪去
(1) (n-1)T(n)=2T(1)+2T(2)+......2T(n-1)+c(n^2)
(2) (n-2)T(n-1)=2T(1)+2T(2)+......2T(n-2)+c(n-1)^2
(1)-(2)得到
(n-1)T(n)-nT(n-1)=c(2n-1)
則:T(n)/n=T(n-1)/(n-1)+c(1/n+1/n-1),根據遞回樹法
T(n)/n=c(1/n-1/(n-1))+c(1/(n-1)-1/(n-2)+……c(1/2+1)+T(1)
=c(1/n+1/(n-1)+……1/2)+c(1/(n-1)+1/(n-2)+……1)
H[n]=1+1/2+1/3+1/4+……1/n
根據調和級數公式H[n]=O(logn)
T(n)/n=c(H[n]-1)+cH[n-1]=c(2H[n]-1/n-1)
T(n)=2cnH[n]-c(n+1)=O(nlogn),
10.快速排序2(Quicksort:PartitionRundom)
1.含義
作為快速排序的另一種方式(和原來的一樣,注意不是填坑法,否則我就寫dig a hole了),這里的劃分方式和之前的不同,之前的是將第一個元素作為劃分點,這里是隨機產生一個元素作為劃分點,即將k的值在i到j中隨機產生,
2.偽代碼實作
和之前的一樣,只不過隨機產生k.
partitionSort(A,i,j)
input: A[i……j],x
ouput: 排序之后的A[i……j]
temp<--random(i,j)//在i與j之間產生一個亂數
x<--A[temp];
k=partition(A,i,j,x);//k來接識訓傳的q指標
IF(k==i) THEN return;//當q與i相等時停止,
partitionSort(A,i,k);//對q前面的元素進行分組
partitionSort(A,k+1,j);//對q后面的元素進行分組
partition(A,i,j,x)//進行分組
p<--i;q<--j; //兩指標就位
While(p<q) DO
swap(A[p],A[q]);//每次交換算一個周期
While(A[p]<x) DO
p<--p+1; //p指標++直到找到比x大的元素,停下來
While(A[q]>=x) DO
q<--q--; //q指標--直到找到比x小的元素,停下來
return q;3.演算法性能分析
這里和第一種并沒有什么復雜度的差別,只不過換了一種演算法的分析方式,分析的目的在于計算演算法的平均復雜度,
1.定義
1.定義S(i)代表第i大的元素,則最小的元素為S(1),最大的元素為S(n),
2.當在程式執行是S(i)和S(j)發生比較時,記為X(ij)=1,若沒比較則X(ij)=0,
2.分析
1.演算法比較的總次數為所有元素的比較次數之和:
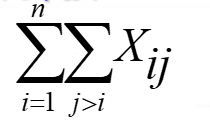
i表示將所有資料都遍歷一遍,j表示與第i個元素相比較的元素個數,即一個i對應固定個數的j
2.演算法的平均復雜度要使用數學期望來表示:
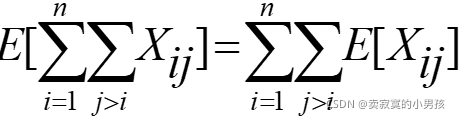
計算E[X(ij)]=p(ij)*1+(1-p(ij))*0=p(ij)
其中p(ij)表示的是S(i)與S(j)比較的概率,所以計算平均復雜度問題就轉變成了求S(i)與S(j)發生比較的概率的問題,
3.求解p(ij)
我們可以用樹來理解這一問題,即在n個數中p(ij)的值是多少,
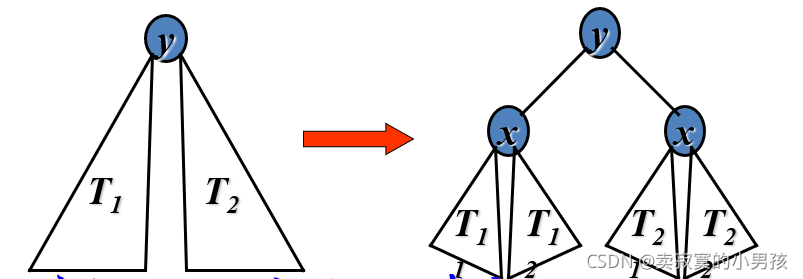
通過觀察我們發現:
1.當S(i)與S(j)發生比較時,S(i),S(i+1),S(i+2)……S(j)一定在同一個樹中,
2.只有在S(i)或者S(j)為被選中的參照值時,兩者才會比較,
滿足這兩個條件即可,總結出來就是在S(i)到S(j)這些數中,選中S(i)或者S(j)的概率之和,
p(ij)=2/(j-i+1),
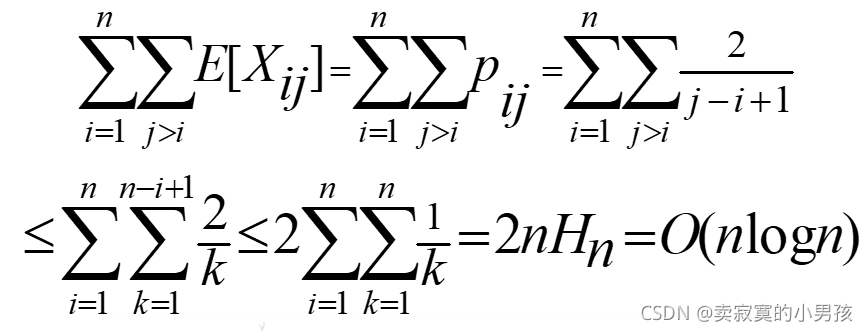
所以快速排序的平均時間復雜度就為O(nlogn),
11.排序問題的下界
1.含義
我們考慮一個演算法的優劣通常是用最壞情況和最優情況來衡量的,最優情況基本沒什么用,
本內容主要證明比較排序最壞情況和平均情況的時間復雜度的下界的極限是Ω(nlogn),不可能寫出時間復雜度比nlogn低的排序,即如果一個排序的時間復雜度為nlogn,那么這個排序演算法是最優的,不可能再找出比它更好的排序演算法,
比較排序:在排序的最終結果中,各元素的次序依賴于它們之間的比較,我們目前學的所有排序演算法都是比較排序,
我們以為三個元素排序為例,即為1,2,3這三個數字排序,
一個演算法的復雜度不是確定的,分為最優,最壞,平均三種,每一種情況都對應了一個上界和一個下界,你可能會說一個演算法的最優解的比較次數不是固定的嗎?那時間復雜度應該也是固定的啊,但是輸入資料的n在改變,是n的大小導致了三種情況的上下界問題,
2.最壞情況下排序的下界
1.引入
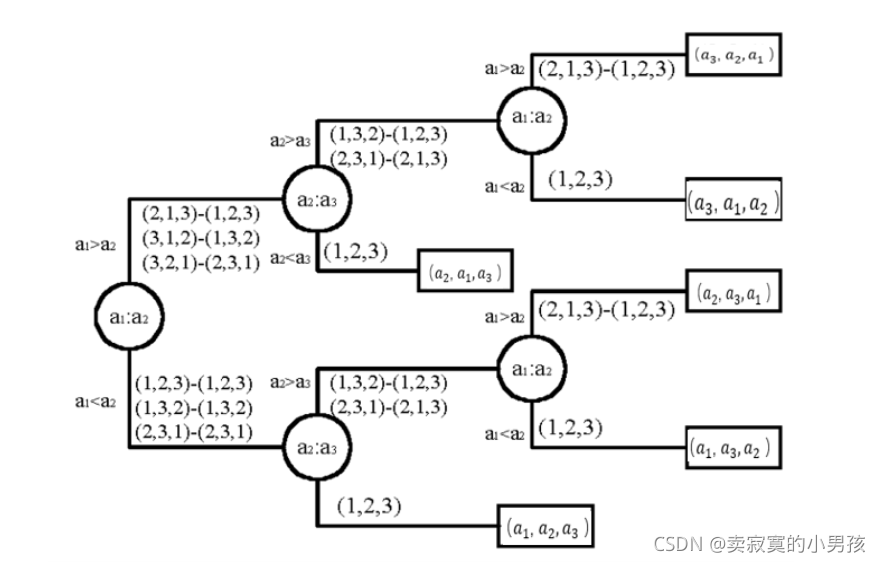
為1,2,3這三個數字進行排序,這三個數字的初始位置無非只有六種
1,2,3
1,3,2
2,1,3
2,3,1
3,1,2
3,2,1
我們可以畫出插入排序的決策樹:
也可以畫出冒泡排序的決策樹:
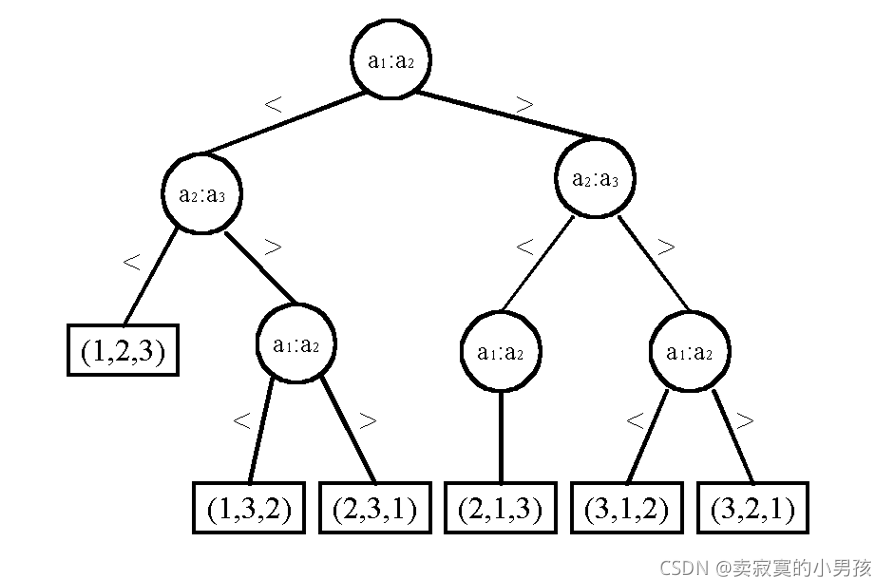 無論按哪一種排序方式來畫,最終每一個葉子節點對應一種1,2,3的排序方式,即這種排列方式經過從根節點到葉子節點這一程序完成排序,也就是說這樣一棵樹依賴于葉子節點得以建立,
無論按哪一種排序方式來畫,最終每一個葉子節點對應一種1,2,3的排序方式,即這種排列方式經過從根節點到葉子節點這一程序完成排序,也就是說這樣一棵樹依賴于葉子節點得以建立,
首先我們明確要找的是最壞情況的下界,即對n個數進行所有排序演算法中,由于n個數排列不同而導致比較次數最多的情況的下界,(吐槽一下ppt老師做的有問題,我發現了,但是老師估計永遠不會去看這篇博客),
聽起來很繞啊,再來解釋一下:我們要明確幾個點才能證明:
2.證明
1.所有比較排序演算法的決策樹都可以抽象成一棵決策樹,(觀察上面兩幅圖發現兩者是一樣的),并且這個決策樹一定是一棵完全二叉樹,
2.我們要找的是每一個排序演算法的最壞情況對應的時間復雜度,
3.我們要證明這些時間復雜度都為Ω(nlogn),
4.無論什么演算法,有n個數那么就有n!個形式,每種形式對應一種排序程序,注意每一個節點是一次比較,我們要找的最壞情況就是比較次數最多的情況(注意最差情況不止一種),即樹高,
5.每一種排序的最壞情況是可以計算出時間復雜度的,用O階什么的表示就是為了涵蓋多種情況,
了解了這些就可以把計算排序中最差情況抽象成在一棵有n!個葉子節點的完全二叉樹中,計算樹高h的問題,
完全二叉樹是滿二叉樹最后一行刪掉一些元素,所以n!<=2^h
計算求得h>=lg(n!),我們要求h的下限,即求lg(n!)的最小值,
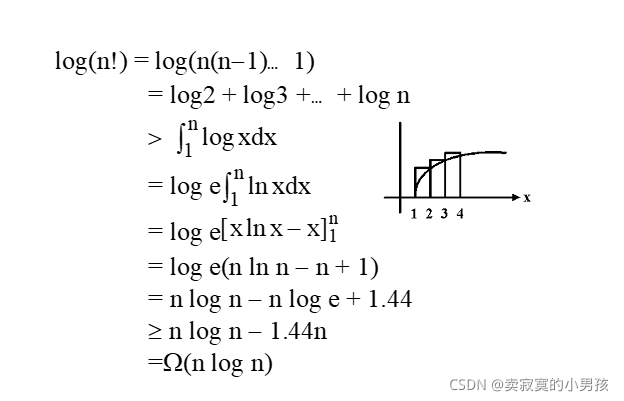
還想再說點:h已經是最壞的情況了其實我們就是通過n!與2^h的逼近程度區分不同演算法的,但即使有區分,每種演算法最壞情況的時間復雜度一定>nlogn,我們發現歸并排序和堆排序的演算法的上界是O(nlogn)所以他們是最優演算法,復雜度為θ(nlogn),(竟然如此之細致,表揚自己一波)
3.平均情況時間復雜度的下界
1.引入
如果你已經理解了最壞情況下的時間復雜度的下界,那么也很容易理解平均情況下時間復雜度的下界,從根節點到葉子節點的最長路徑對應最壞的情況,那么從根節點到所有葉子節點的路徑和再除以路徑條數就表示平均情況,我們可以計算出它的值,
2.證明
1.假設這是一顆有c個葉子節點的二叉樹,深度為d,由于決策樹是完全二叉樹,所以葉子節點僅僅出現在第d層和第d-1層,
2.假設x1個節點在d-1層,x2個節點在d層,
那么就可以得到:
x1+x2=c
x1+x2/2=2^(d-1)
可以推出:x1=2^d-c
x2=2(c-2^(d-1))
再經過一系列的運算:

這就證明出來了平均的時間復雜度的下界也是nlogn,
12.思考題1
1.題干
給定單調不減數列a0....an和一個數k,在O(logn)的時間復雜度內找到滿足ai>=k的最小i,寫出偽代碼,
2.求解
由于是已經排好序的,所以直接尋找中間值即可,
input:A[0...n],k
ouput:i
Lowbound(A,k)
lowbound=0;
upbound=A.length-1;
While upbound-lowbound>0 DO
mid=(lowbound+upbound)/2;
IF A[mid]>=k THEN
upbound=mid;
ELSE lowbound=mid+1;
print upbound;就是找中間值然后比較就可以了,
每次都比較的是一半的元素,寫出運算式
T(n)=T(n/2)+O(1),根據主定理計算出時間復雜度為O(logn),
13.思考題2
1.題目
給定一個平面內的n個點,用O(nlogn)的時間復雜度求出距離最近的兩個點,寫出偽代碼,
2.求解
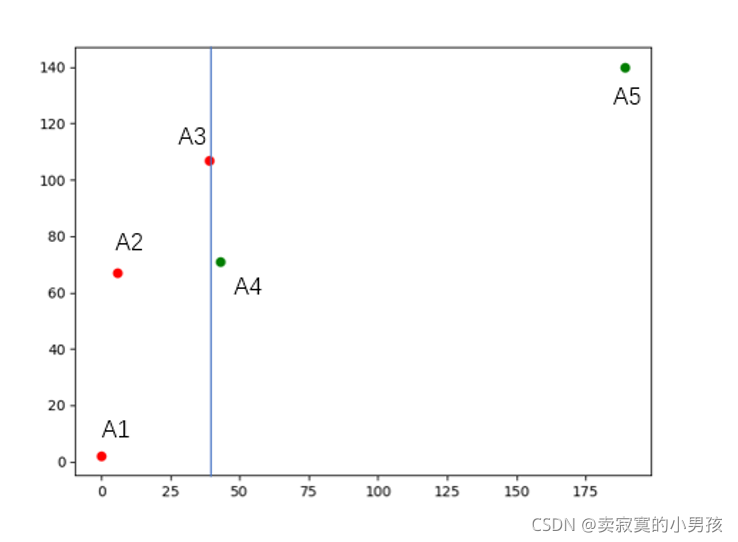
假設給定5個點:A1,A2,A3,A4,A5,使這五個點的x值逐漸增大的,
1.首先根據中間值將x軸劃分成兩部分
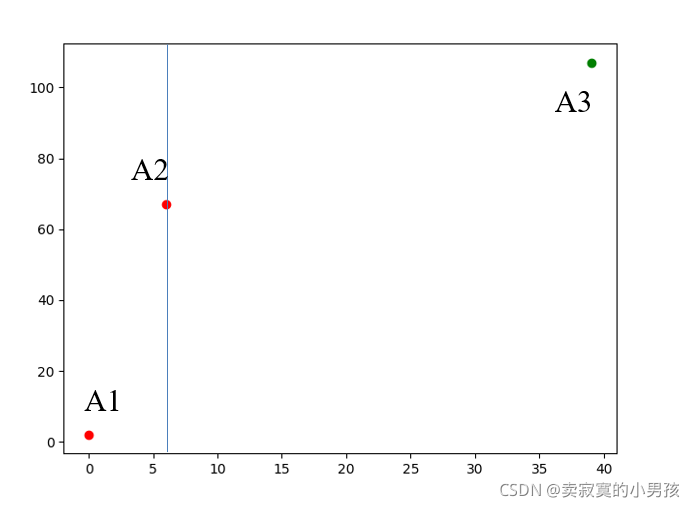
2.繼續劃分子問題,將A1到A3作為一個整體,找到中間值A2
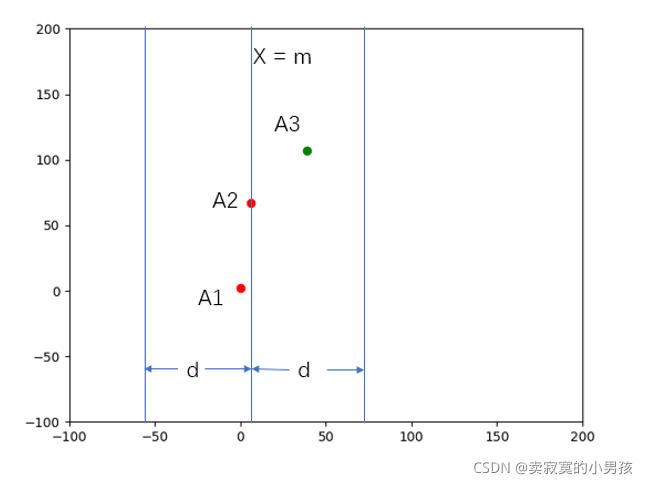
3.此時只剩下三個點了,計算左側最短距離d1,即A1與A2的距離;和右側最短距離d2,即A2與A3的距離,計算兩者的最小值為d,此時A2的左右兩側的最小值已經找到了,現在的問題是在A2點的周圍,一個左側元素和一個右側元素的距離是否可能小于d,
4.以A2的橫坐標x2為分隔點,尋找橫坐標在(x2-d,x2+d)的元素,因為只有在這個范圍內的左右兩側元素才有可能距離是小于d的,
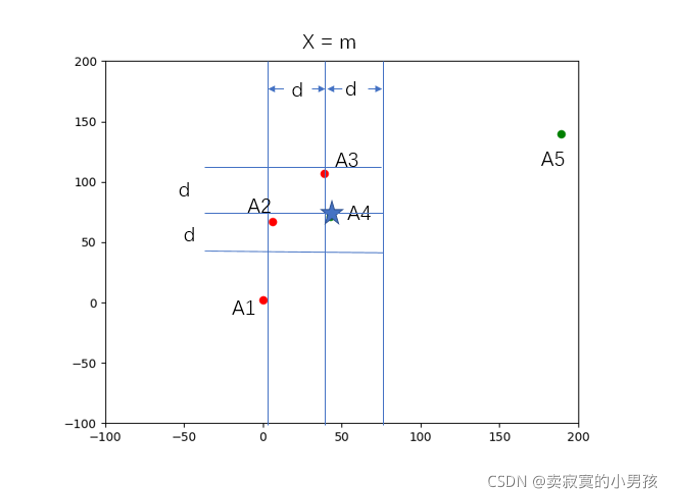
5.此時在(x2-d,x2+d)中涵蓋了一些點,對于這些點來說,以A1為例,為了尋找右側的與它距離小于d的點,那么兩者的縱坐標之差一定小于d,所以找出范圍內所有點的(縱坐標-d,縱坐標+d)這一范圍的點,計算兩者之間的距離d',與d比較看是否小于d,如果小于則d=d',此時的含義為在A3右側的點的最小值是d',我們又可以計算A3左側元素的距離最小值,兩者再比較從而形成了遞回,
3.偽代碼實作
input:A[1……n]
output:最小值d
closest_pair(A)//計算整體的最小距離
If A.size<=1 return INF//當
sort_by_x(A) //將資料按橫坐標大小進行排序
m = A.size/2; x= A[m].first //找出資料的中點,將其x坐標賦值給x
d = min(closest_pair(A[0..m]),closest_pair(A[m+1..n]))//計算兩側的最小距離d
sort_by_y(A)//將A按縱坐標大小排序
For i = 1 to n
If A[i].first-x>=d continue;//當A[i]的橫坐標與x的距離大于x時,進行下一次回圈
B.push(A[i])//定義一個B陣列,用于接收A陣列按縱坐標排序后且在2d范圍內的元素
for j=0 to b.size //當j從0到n
dx = A[i].first – B[b.size-j].first//計算x的差值
dy = A[i].second – B[b.size-j].second//計算量元素y的差值
If dy>=d break //當dy>d時,跳出這一次回圈,說明兩者的距離一定大于d
d = min(d,sqrt(dx*dx+dy*dy))//計算d與兩者距離的最小值賦值給d
Return d4.計算時間復雜度
找n個元素的距離最小值是T(n),那么找一半元素的最小值就是T(n/2)
所以T(n)=2T(n/2)+O(1)
根據主定理,T(n)=O(nlogn),
13.總結
突破記錄了,目前寫的字數最多的文章,但我感覺動態規劃的話會更多,寫完之后的感徑訓是“我原來可以這么細”,當然如果你比我更細的話,,歡迎私信我啊,讓好奇的我看一看“戲中戲”是什么樣子的啊,分治法是一種設計演算法的思想,它的優秀程度以及如何熟練使用也是需要進行不斷地練習才能感悟,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/306291.html
標籤:其他