人臉的檢測與識別是一個歷史悠久的方向,之前沒做過相關的作業,所以對人臉檢測的相關流程沒有很清晰的概念,作業原因,近期對人臉識別的來龍去脈做一個筆記和知識梳理,從上到下的一個pipeline,文章部分內容有參考或摘抄均給出了出處,如有侵權,還望及時與筆者聯系進行洗掉或整改,
作者:Wisley
郵箱:903953316@qq.com
GitHub:個人主頁
人臉識別
- 一、人臉識別背景👦
- 二、人臉識別演算法
- 2.1 人臉檢測🔍
- 2.2 人臉關鍵點定位📌
- 2.2.1 ASM模型
- 2.2.2 AAM 模型
- 2.1.3 CLM模型
- 2.3 人臉對齊📏
- 2.4 人臉表征🤔
- 2.4.1 人臉識別模型的評價指標
- 2.4.1.1 TPR和FPR
- 2.4.1.2 TAR 和FAR
- 2.4.1.3 TAR @ FAR=0.001
- 2.4.1.4 ROC 曲線
- 2.4.2 人臉識別中的損失函式
- 2.4.2.1 Triplet loss
- 2.4.2.2 Center loss
- 2.4.2.1 ArcFace loss
- 2.5 人臉匹配🎭
- 2.6 小結📝
- 三、參考文獻
一、人臉識別背景👦
人臉識別作為一種非入侵式的識別驗證方式相比其他生物識別技術更受大眾的喜愛與接受,隨著識別技術的發展與進步,人臉識別技術已廣泛部署在多種場景下如監控系統、安防系統、工業生產、家庭監護等,方便人們生活的各方各面,人臉識別的其它常見應用還包括訪問控制、欺詐檢測、身份認證和社交媒體等,
人臉識別主要可以分為以下三種場景模式,分別為1:1,1:N,N:N,
- 1:1 問題
銀行柜臺、海關、手機解鎖、酒店入住、網吧認證,會查身份證跟你是不是同一個人,這個應用的主要特點是,在大多數場景下都需要你先提供一個證件,然后跟自己的人臉做比對,簡單來說,這個問題就是給定兩張圖片,判斷是否是一個人,相當于做一個二分類 - 1:N問題
在圖書館,公司等重要場所,我們往往需要對人臉進行檢索沒判斷這個人有沒有出現在人臉庫中,相當于一張圖片,要與庫中的每張人臉進行比對,判斷是否一致,直到所有匹配的回答都是否時,才意味這個人不在我們的人臉庫中,而不予以通過,實際使用時一般是靜態的搜索,回傳TOP K個的相似人臉,這個和推薦系統領域的粗排,精排的目的相似, - N:N問題
在安防或者其他應用場景則有更難的任務,我們的城市有數不清的攝像頭,每天都會產生大量的抓拍圖片,同時對比庫也是非常大大,這就是N張圖片進行N次搜索的問題,比如我們100個攝像頭,每個攝像頭一天抓拍了1萬個人,而我們的底庫有10萬,總共搜索量精需要100x1w的搜索量,我們有10個嫌疑人,現在我們的演算法,報警量100次,最后抓到9個人,感徑訓是可以的,10個人抓到9個,召回率有90%,而且誤報率也非常低,但是實際卻不行,因為出警率有100次,卻抓到9個嫌疑人,只有9%的準確率,實際上我們希望每次出警都能準確定位出嫌疑人,
人臉識別不同于簡單的圖片分類任務,它是個開集任務,即對于測驗集的分類目標,不存在于訓練集中,這也非常好理解,因為我們拿到用于訓練的人臉圖片,與現場進行抓拍的人臉圖片肯定是不一致的,同時也無法做到將全世界所有人的人臉都收集起來訓練,在其次就是場景、設備、光線、妝容、表情、年齡等各方面因素,都會使得同一個人的照片出現天差地別的變化,這需要模型有較好的魯棒性,能夠從人臉中提取穩健的特定特征,
二、人臉識別演算法
人臉識別的基本流程:
- 人臉檢測
- 人臉關鍵點定位
- 人臉對齊
- 人臉表征
- 人臉匹配
2.1 人臉檢測🔍
人臉檢測是通過模型或演算法來尋找圖片中人臉的位置,輸出人臉邊界框的坐標,以將檢測到的人臉輸送到后續模型中,現有的人臉檢測模型有很多,與目標檢測的一類模型如RCNN、YOLO、Retina等框架通用,同時在人臉檢測時,模型還可以輸出關鍵點坐標以及相關屬性等資訊,

2.2 人臉關鍵點定位📌
人臉特征點檢測是指定位臉部預定義的關鍵點,比如眼睛、鼻子、嘴巴等,定位的目的是在人臉檢測的基礎上,進一步確定臉部特征點(眼睛、眉毛、鼻子、嘴巴、臉部外輪廓)的位置,傳統的定位演算法的基本思路是:人臉的紋理特征和各個特征點之間的位置約束相結合,
人臉特征點檢測的方法可以分成:
- 基于引數化模型的方法:ASM、AAM、CLM等
- 基于回歸的方法:ESR、SDM、RCPR、LBP等
- 基于神經網路的方法:包括CNN/RNN/FCN等
這里簡單介紹一些傳統方法,感興趣的小伙伴可以自行細查閱相關資料,這里不做過多詳細的說明,
2.2.1 ASM模型
參考
ASM是一種基于點分布模型(Point Distribution Model, PDM)的演算法,起源于snake模型(作為動態邊緣分割的snake模型),該方法用一條由n個控制點組成的連續閉合曲線作為snake模型,再用一個能量函式作為匹配度的評價函式,首先將模型設定在目標物件預估位置的周圍,再通過不斷迭代使能量函式最小化,當內外能量達到平衡時即得到目標物件的邊界與特征,

原始Snakes模型由一組控制點:v(s)=[x(s), y(s)] s∈[0, 1] 組成,這些點首尾以直線相連構成輪廓線,其中x(s)和y(s)分別表示每個控制點在影像中的橫縱坐標位置, s 是以傅立葉變換形式描述邊界的自變數,snake的大致思路是先給定一個坐標曲線,然后通過最小化能量函式來得到最優解,這個最優解會讓曲線趨近于平滑且靠近目標邊緣,能量函式如公式(1)所示,
E total = ∫ s ( α ∣ ? ? s v ? ∣ 2 + β ∣ ? 2 ? s 2 v ? ∣ 2 + E e x t ( v ? ( s ) ) ) d s ( 1 ) E_{\text {total }}=\int_{s}\left(\alpha\left|\frac{\partial}{\partial s} \vec{v}\right|^{2}+\beta\left|\frac{\partial^{2}}{\partial s^{2}} \vec{v}\right|^{2}+E_{e x t}(\vec{v}(s))\right) ds \qquad(1) Etotal ?=∫s?(α∣∣∣∣??s??v ∣∣∣∣?2+β∣∣∣∣??s2?2?v ∣∣∣∣?2+Eext?(v (s)))ds(1)
其中第1項稱為彈性能量是v的一階導數的模,第2項稱為彎曲能量,是v的二階導數的模,彈性能量和彎曲能量合稱內部能量(內部力),用于控制輪廓線的彈性形變,起到保持輪廓連續性和平滑性的作用,第3項是外部能量(外部力),表示變形曲線與影像區域特征吻合的情況,一般只取控制點或連線所在位置的影像區域特征例如梯度,如公式(2)所示,當輪廓C靠近目標影像邊緣,那么C的灰度的梯度將會增大,那么上式的能量最小,
E
e
x
t
(
v
?
(
s
)
)
=
P
(
v
?
(
s
)
)
=
?
∣
?
I
(
v
)
∣
2
(
2
)
E_{e x t}(\vec{v}(s))=P(\vec{v}(s))=-|\nabla I(v)|^{2} \qquad (2)
Eext?(v
(s))=P(v
(s))=?∣?I(v)∣2(2)
在能量函式極小化程序中,彈性能量迅速把輪廓線壓縮成一個光滑的圓,彎曲能量驅使輪廓線成為光滑曲線或直線,而影像力則使輪廓線向影像的高梯度位置靠攏,基本Snakes模型就是在這3個力的聯合作用下作業的,
ASM模型在實際訓練中包含訓練和搜索兩個部分(詳細參考),
- 1、建立形狀模型:
- 1.1 收集包含人臉的訓練集
- 1.2 手動標記K個關鍵點
- 1.3 構建形狀向量(坐標)
- 1.4 形狀歸一化(通過平移,旋轉,縮放,在不改變點分布模型的基礎上對齊到同一個點分布模型,采用Procrustes方法)
- 1.5 對齊后的形狀向量進行PCA處理
- 2、構建特征點的區域特征
- 如通過計算區域灰度值的梯度得到紋理特征,通過迭代的方式跟新特征點
- 3、搜索
- 對平均形狀通過平移,縮放,旋轉得到初始模型,通過搜索得到最終形狀,
- 計算相似度,相似度為區域特征的馬氏距離,新的目標特征點為前后特征點連線方向上,以其為中心兩邊各選擇l個像素點計算區域特征,通過計算這些子區域特征與當前特征點之間的馬氏距離最小的子區域特征中心,作為當前特征點的新位置
參考:1、2
2.2.2 AAM 模型
參考文獻:Active Appearance Models、Active Shape Models
前面說到,ASM是基于統計形狀模型的基礎上進行的,而AAM則是在ASM的基礎上,進一步對紋理(將人臉影像變形到平均形狀而得到的形狀無關影像g)進行統計建模,并將形狀和紋理兩個統計模型進一步融合為表觀模型,
AAM模型相對于ASM模型的主要改進為:使用兩個統計模型融合來取代 ASM的灰度模型,主要對特征點的特征描述子進行了改進,增加了描述子的復雜度和魯棒性,
2.1.3 CLM模型
參考:【機器學習理論與實戰(十六)概率圖模型04】
CLM(Constrained local model)顧名思義就是有約束的區域模型,ASM、AAM都屬于有約束的區域模型,它通過初始化平均臉的位置,然后讓每個平均臉上的特征點在其鄰域位置上進行搜索匹配來完成人臉點檢測,整個程序分兩個階段:模型構建階段和點擬合階段,模型構建階段又可以細分兩個不同模型的構建:形狀模型構建和Patch模型構建,如(圖一)所示,形狀模型構建就是對人臉模型形狀進行建模,說白了就是一個ASM的點分布函式(PDM),它描述了形狀變化遵循的準則,而Patch模型則是對每個特征點周圍鄰域進行建模,也就說建立一個特征點匹配準則,怎么判斷特征點是最佳匹配,
相關論文可以參考這篇文章的作業:Deformable Model Fitting by Regularized Landmark Mean-Shift
2.3 人臉對齊📏
人臉對齊是將人臉模型與影像進行匹配并提取人臉像素的語意的一種方法,它是人臉圖片送入模型提取特征前的預處理作業,主要目的是將形態各異、不規則的人臉圖片,校正到統一的模板,方便模型提取特征,從而提高模型精度,它使用一組位于人臉圖片中標準位置的固定坐標作為參考點,通過仿射變換將原始的人臉圖片變換到標準模板上,這個程序需要通過檢測器得到原始人臉圖片上的關鍵點坐標,再與參考點使用最小二乘法計算仿射變換的引數矩陣,
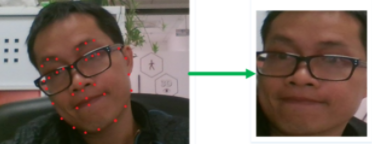
人臉對齊也是一項歷史悠久的作業,現如今已有非常多的方法,如傳統的約束模型,概率模型,到后來的回歸模型、樹模型,到現在層出不窮的深度模型、圖卷積、點云等技術,一般來說,關鍵點的檢測也容易受光線、角度、紋理、遮擋等因素的影響,從關鍵點定位到對齊,主要方法的類別還分為:2D方法,3D方法,稀疏方法和密集方法等,另外如于深度學習方法可以很好的實作對多任務的處理,因此有很多新的演算法可以同時完成人臉框檢測以及對2D關鍵點和3D關鍵點的獲取,進而可進一步支持后續的多任務分析,
人臉對齊也面臨很多挑戰,大多數對齊演算法都是為小到中等姿態(45度以下)的臉設計的,缺乏在高達90度的大姿態中對齊臉的能力;同時常用的基于參考坐標的演算法,都是假設再所有人臉中均可見的(無遮擋),這是不合理的,同時稠密人臉、三維人臉、大姿態人臉等場景下也面臨極大的挑戰,Xiangyu等人的作業Face Alignment Across Large Poses: A 3D Solution則提出了三維密集人臉對齊(3D Dense Face alignment, 3DDFA)框架,來解決這些問題,該框架通過卷積神經網路(CNN)將稠密的三維人臉模型擬合到影像上,同時他們還提出了一種在剖面視圖中合成大規模訓練樣本的方法來解決資料標記等問題,

\quad
2.4 人臉表征🤔
人臉表征是將人臉影像轉化為具有代表性的特征向量,用于后續的人臉匹配等作業,一個好的表征向量應該是同一個主體的所有人臉圖片都能映射到相類似的向量上,不同主體之間的特征向量具有一定的差距(如較大的歐氏距離或者余弦距離等),人臉表征在整個人臉識別當中算是最主要的一步,也是我們主要學習和介紹的重點,
基于CNN的人臉識別方法是目前領域內最常見的一類方法,其主要優點是使用大量資料訓練,從而學習到穩健的人臉表征,它不同于以往的方法,不需要手工設計人臉特征,并在資料集規模擴大的同時能適用于更加復雜的人臉場景,影響基于深度學習的人臉識別演算法主要有三個方面:
- 1、資料規模和質量,一定規模的訓練資料能提高模型的魯棒性(如更多的主體數量、每個主體下形態各異的圖片數量等),學習到更好的表征向量,而資料集的質量包括清晰度、角度、光照等,
- 2、網路結構,不同的網路模型結構也影響模型的識別能力,典型的網路結構有VGG、Resnet等,均可借鑒圖片分類中的一些 網路結構
- 3、優化和訓練方法,人臉識別是個開集問題,不同于簡單的圖片分類任務,合理設計優化目標是提高模型精度的關鍵,常用的方法有優化配對人臉或者人臉三元組之間的距離度量、選擇不同損失函式如:Center loss、Arcface等,
2.4.1 人臉識別模型的評價指標
在介紹人臉識別模型前,我們先來學習下人臉識別中常用的衡量指標,在人臉識別中常用到的指標是TAR(True Accept Rate)和FAR(False Accept Rate),他們與TPR(True Positive Rate)和FPR(False Positive Rate)有略微的差異,
2.4.1.1 TPR和FPR
首先來看我們熟悉的TPR(True Positive Rate)和FPR(False Positive Rate),TPR(True Positive Rate)和FPR(False Positive Rate)是二分類演算法常用的評價指標,分別是真正例率和假正例率,他們都是基于混淆矩陣的度量標準,混淆矩陣如下所示:
| n=192 | Predict 0 | Predict 1 |
|---|---|---|
| Actual 0 | 118 | 12 |
| Actual 1 | 14 | 15 |
- 真正類 (True Positive,TP):被分類器預測為正的正樣本 (預測正確)
- 真負類 (True Negative,TN):被分類器預測為負的負樣本 (預測正確)
- 假正類 (False Positive,Fp):被分類器預測為正的負樣本 (預測錯誤)
- 假負類 (False Positive,Fp):被分類器預測為負的正樣本 (預測錯誤)
那么TPR與FPR的計算可以根據混淆矩陣進行計算,如下:
TPR(True Positive Rate)真正率,也叫召回率或靈敏率:模型正確識別的正樣本在實際正樣本中的比例:
T
P
R
=
T
P
T
P
+
F
N
\mathrm{TPR}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}
TPR=TP+FNTP?
FPR (True Positive Rate)假正率, 模型錯誤識別為正樣本在實際負樣本中的比例:
F
P
R
=
F
P
T
N
+
F
P
\mathrm{FPR}=\frac{\mathrm{FP}}{\mathrm{TN}+\mathrm{FP}}
FPR=TN+FPFP?
混淆矩陣還能度量其他一些指標,如準確率,AUC,ROC等,
2.4.1.2 TAR 和FAR
人臉識別中的常用的指標TAR和FAR,TAR(True Accept Rate)表示正確接受的比例,FAR(False Accept Rate)表示錯誤接受的比例,所謂的接受就是在進行人臉驗證的程序中,兩張影像被認為是同一個人,
FAR(False Accept Rate) 的計算方式如下:
F
R
R
=
負對分數
>
T
負對總數
\mathrm{FRR}=\frac{\text { 負對分數 }>\mathrm{T}}{\text { 負對總數 }}
FRR= 負對總數 負對分數 >T?
做人臉驗證的時候,我們將兩張圖片Eembedding成兩個高維的特征向量,然后計算兩個特征向量的相似度或者距離(一般為余弦距離),公式中分數指的就是兩兩圖片的相似度得分,
在建立比對資料時,我們把同一個人的兩張圖片稱為正對(同人),不同人的兩張圖片稱為負對(非同人),在兩兩相似度計算后,我們希望同一個人的影像相似度比較高,不同人的相似度比較低,我們會給定一個相似度閾值T,比如0.6, 如果兩張影像的相似度大于T我們就認為兩張圖片是一個人的,如果小于T我們就認為兩證影像是不同人的,但是無論將T設定成什么樣值都會有一定得錯誤率,就是FAR,因為我們提取的影像的特征向量總是不夠好,并不總能 滿足:同一個人的影像相似度比較高,不同人的相似度比較低,偶爾也會出現不同人的影像的相似度大于給定的閾值T,這樣我們就會犯接受的錯誤,FAR就是我們比較不同人的影像時,把負對(兩張不同的人臉)影像對當成同一個人影像占所有負對的比例,我們希望FAR越小越好,
TAR(True Accept Rate) 表示正確接受的比例,計算方式如下:
F
R
R
=
正對分數
<
T
正對總數
\mathrm{FRR}=\frac{\text { 正對分數 }<\mathrm{T}}{\text { 正對總數 }}
FRR= 正對總數 正對分數 <T?
TAR 表示了在正對中,被預測為正的樣本數占所有正對的比例,同樣,對于給定閾值T,正對的預測分數(同人分數)大于T,表示了模型正確預測的數量,
2.4.1.3 TAR @ FAR=0.001
在閱讀人臉相關論文時,經常會看到 TAR @ FAR=0.001 這樣的演算法性能報告,意思就是在FAR為0.001的情況下,TAR是多少,一般來說,當給定FAR時,根據公式,我們能夠計算出閾值T,再根據閾值T,我們就能計算出對應的TAR為多少,TAR與FAR是一對相互對立的指標,一般來說,在同一組模型預測結果中,TAR減少,FAR就會增加,反之亦然,所以在報告TAR時,只有說明FAR為多少時才有意義,
一般在評價演算法的性能時,我們會統計在不同數量級的FAR下,TAR的分數,構成ROC曲線,相同FRR下,TAR的值越大,則模型的性能越好,
2.4.1.4 ROC 曲線
進一步,在人臉識別中,對模型進行評估時,我們還會畫出ROC曲線,來直觀地對比模型的性能,ROC 曲線為TPR-FPR的相關曲線,橫坐標為假正率,縱坐標為正正率,通過設定一系列的閾值,我們就能得到不同閾值下的橫縱坐標,從而畫出ROC曲線圖,如下圖所示:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-2KUkmpWZ-1633607029878)(./image_9.png)]](https://img.uj5u.com/2021/10/08/271680080846215.png)
該曲線一定經過(0,0)點與(1,1)點,曲線與坐標軸所包含的面積(綠色區域)越大,表示模型的性能越好,理想的最佳狀態是無論FPR為多少,TPR都非常高(接近1),此時曲線與坐標軸圍城的面積最大,
2.4.2 人臉識別中的損失函式
對于損失函式的研究是近年來在人臉識別領域活躍的熱點方向,樸素的做法是參考像圖片分類任務使用sofrmax損失訓練,把每個主體當作一種類別,但是使用這種損失函式無法很好地泛化測驗集中未出現在訓練集中的主體上,softmax損失能將指導模型學習主體間的差異,增加類間距離,但是對于類內距離并沒有約束,并且對于新出現的類別無法分配足夠的決策邊界,一種解決方法是使用度量學習來進行訓練,將人臉圖片進行配對得到對比損失,以此監督模型有向訓練,
2.4.2.1 Triplet loss
最常見的度量學習方法是三元組損失函式(Triplet loss),該損失函式的目標是以一定的余量(間隔),將正對與負對的距離分開,數學表示如下公式(3):
∥
f
(
x
a
)
?
f
(
x
p
)
∥
2
2
+
α
<
∥
f
(
x
a
)
?
f
(
x
n
)
∥
2
2
(
3
)
\left\|f\left(\boldsymbol{x}_{a}\right)-f\left(\boldsymbol{x}_{p}\right)\right\|_{2}^{2}+\alpha<\left\|f\left(\boldsymbol{x}_{a}\right)-f\left(\boldsymbol{x}_{n}\right)\right\|_{2}^{2}\qquad(3)
∥f(xa?)?f(xp?)∥22?+α<∥f(xa?)?f(xn?)∥22?(3)
其中
x
a
x_a
xa? 是錨影像,
x
p
x_p
xp? 是同一主體的影像,
x
n
x_n
xn? 是另一個不同主體的影像,
f
f
f 是模型學習到的映射關系,
α
α
α是 施加在正例對和負例對距離之間的余量,該表述所表達的思想非常直觀,盡可能讓正樣本距離類主體的距離小于負樣本距離類主體的距離,在實際的訓練程序,使用三元組損失訓練的 CNN 的收斂速度比使用 softmax 的慢,這是因為需要大量三元組(或對比損失中的配對)才能覆寫整個訓練集,然而窮舉整個訓練集的配對樣本是比較困難的,有學者提出可以通過在訓練階段賽選難例樣本(即違反余量條件的三元組)來緩解 ,常見的做法是在第一個訓練階段使用 softmax 損失訓練,在第二個訓練階段使用三元組損失來對一些難例進行微調學習,還有研究者進一步提出了三元組的一些變體,如使用點積作為相似度度量等來進一步優化三元組的訓練程序,
2.4.2.2 Center loss
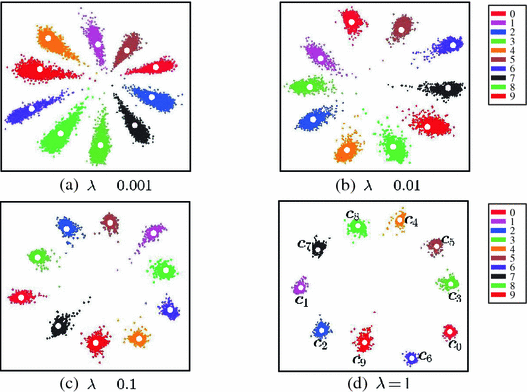
相比于對比損失和三元組損失,中心損失(centre loss)相對更高效且更容易實作,它不需要在訓練程序中構建配對或三元組,中心損失的目標是最小化樣本特征與它們對應類別的中心之間的距離,通過使用 softmax 損失和中心損失進行聯合訓練,能夠有效增大類間差異(softmax 損失)和降低類內個體差異(中心損失),如公式(4)所示,其中 L C \mathcal{L}_{C} LC?是中心損失,計算的是樣本特征向量距離中心的歐式距離,
L = L S + λ L C = ? ∑ i = 1 m log ? e W y i T x i + b y i ∑ j = 1 n e W j T x i + b j + λ 2 ∑ i = 1 m ∥ x i ? c y i ∥ 2 2 ( 4 ) \begin{aligned} \mathcal{L} &=\mathcal{L}_{S}+\lambda \mathcal{L}_{C} \\ &=-\sum_{i=1}^{m} \log \frac{e^{W_{y_{i}}^{T} x_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{W_{j}^{T} x_{i}+b_{j}}}+\frac{\lambda}{2} \sum_{i=1}^{m}\left\|\boldsymbol{x}_{i}-\boldsymbol{c}_{y_{i}}\right\|_{2}^{2} \qquad(4) \end{aligned} L?=LS?+λLC?=?i=1∑m?log∑j=1n?eWjT?xi?+bj?eWyi?T?xi?+byi???+2λ?i=1∑m?∥xi??cyi??∥22?(4)?
下圖是在MINIST資料集上,不同 λ \lambda λ下的訓練結果可視化:
2.4.2.1 ArcFace loss
文章鏈接
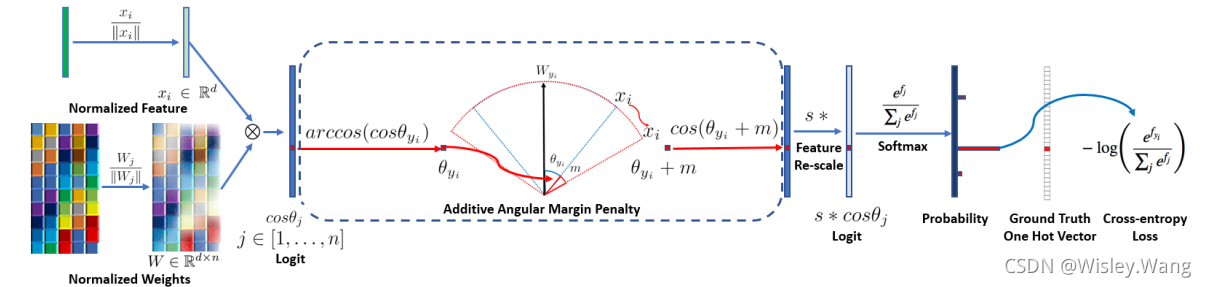
ArcFace是在SphereFace基礎上改進了特征向量歸一化和加性角度的間隔,提高了類間可分性同時加強類內緊度和類間差異,在ArchFace中是直接在角度空間(angular space)中最大化分類界限,相比CosineFace則是在余弦空間中最大化分類界限,傳統的softmax loss如公式(5)所示,其中
W
∈
R
d
×
n
W\in\mathbb{R}^{d\times n}
W∈Rd×n是訓練階段輸出層(也可以叫FC 全連接層)進行類別映射的引數矩陣,其中d是特征維度,n是映射的類別數量,
L
=
?
∑
i
=
1
m
log
?
e
W
y
i
T
x
i
+
b
y
i
∑
j
=
1
n
e
W
j
T
x
i
+
b
j
(
5
)
\mathcal{L}=-\sum_{i=1}^{m} \log \frac{e^{W_{y_{i}}^{T} x_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{W_{j}^{T} x_{i}+b_{j}}} \qquad(5)
L=?i=1∑m?log∑j=1n?eWjT?xi?+bj?eWyi?T?xi?+byi???(5)
從公式(5)中可知,直接讓偏置項b置0并不影響網路的訓練結果,進一步正則化向量
W
j
W_j
Wj?與
x
i
x_i
xi?,使其
∥
w
j
∥
=
1
\|w_j\|=1
∥wj?∥=1,
∥
x
j
∥
=
1
\|x_j\|=1
∥xj?∥=1,并添加一個固定的尺度因子S,則兩個向量的點積可表示成
W
j
T
x
i
=
∥
W
j
∥
∥
x
i
∥
cos
?
θ
j
=
cos
?
θ
j
W_{j}^{T} x_{i}=\left\|W_{j}\right\|\left\|x_{i}\right\| \cos \theta_{j}= \cos \theta_{j}
WjT?xi?=∥Wj?∥∥xi?∥cosθj?=cosθj?
這樣通過特征和權重的正則化使預測僅取決于特征和權重之間的角度,所學的嵌入特征分布在半徑為S的超球體上,
前文提到,僅僅是softmax loss 無法很好地監督模型優化內類距離,為了使得類內樣本盡可能靠近我們的類中心,縮小類間差距,我們讓
x
i
x_i
xi?和
W
y
j
W_{yj}
Wyj?之間的
θ
θ
θ加上角度間隔m,以加法的方式懲罰深度特征與其相應權重之間的角度,從而同時增強了類內緊度和類間差異,因此Arcface loss如公式(6)所示:
L
=
?
1
N
∑
i
=
1
N
log
?
e
s
(
cos
?
(
θ
y
i
+
m
)
)
e
s
(
cos
?
(
θ
y
i
+
m
)
)
+
∑
j
=
1
,
j
≠
y
i
n
e
s
cos
?
θ
j
(
6
)
\mathcal{L}=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{s\left(\cos \left(\theta_{y_{i}}+m\right)\right)}}{e^{s\left(\cos \left(\theta_{y_{i}}+m\right)\right)}+\sum_{j=1, j \neq y_{i}}^{n} e^{s \cos \theta_{j}}} \qquad(6)
L=?N1?i=1∑N?loges(cos(θyi??+m))+∑j=1,j?=yi?n?escosθj?es(cos(θyi??+m))?(6)
作者在文中經常與SphereFace和CosineFace進行對比,因此這里我們也分別給出這兩個損失函式的公式,如公式(7)和公式(8).
L
=
?
1
m
∑
i
=
1
m
log
?
e
∥
x
i
∥
cos
?
(
m
θ
y
i
)
e
∥
x
i
∥
cos
?
(
m
θ
y
i
)
+
∑
j
=
1
,
j
≠
y
i
n
e
∥
x
i
∥
cos
?
θ
j
(
7
)
\mathcal{L}=-\frac{1}{m} \sum_{i=1}^{m} \log \frac{e^{\left\|x_{i}\right\| \cos \left(m \theta_{y_{i}}\right)}}{e^{\left\|x_{i}\right\| \cos \left(m \theta_{y_{i}}\right)}+\sum_{j=1, j \neq y_{i}}^{n} e\left\|x_{i}\right\| \cos \theta_{j}} \qquad(7)
L=?m1?i=1∑m?loge∥xi?∥cos(mθyi??)+∑j=1,j?=yi?n?e∥xi?∥cosθj?e∥xi?∥cos(mθyi??)?(7)
L
=
?
1
m
∑
i
=
1
m
log
?
e
s
(
cos
?
(
θ
y
i
)
?
m
)
e
s
(
cos
?
(
θ
y
i
)
?
m
)
+
∑
j
=
1
,
j
≠
y
i
n
e
s
cos
?
θ
j
(
8
)
\mathcal{L}=-\frac{1}{m} \sum_{i=1}^{m} \log \frac{e^{s\left(\cos \left(\theta_{y_{i}}\right)-m\right)}}{e^{s\left(\cos \left(\theta_{y_{i}}\right)-m\right)}+\sum_{j=1, j \neq y_{i}}^{n} e^{s \cos \theta_{j}}} \qquad (8)
L=?m1?i=1∑m?loges(cos(θyi??)?m)+∑j=1,j?=yi?n?escosθj?es(cos(θyi??)?m)?(8)
從上述公式中可以看到,SphereFace是在角度空間乘了懲罰因子m,而CosinFace是在余弦空間減去懲罰因子m,
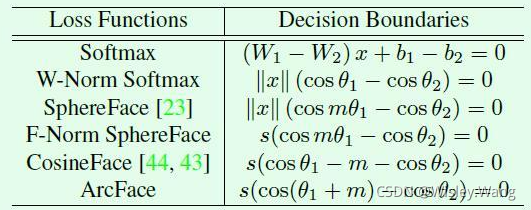
接下來讓我們看看幾個損失函式的分類邊界(decision boundary),決策邊界即是樣本輸出的logits在兩個類別上的值相等,由于分母是一樣的,分子都是以e為底,所以只要讓兩個指數部分相等即可,很容易理解和計算,下表表示的是幾種損失的決策邊界,圖來至:picture,
進一步,根據決策邊界的公式,以
θ
\theta
θ為坐標軸,便能畫出各損失函式的邊界圖,如下圖所示:
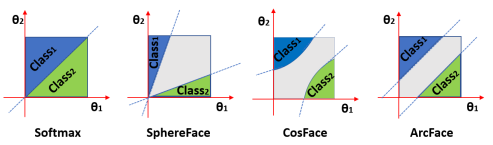
值得一提的是,ArchFace中是直接在角度空間(angular space,橫縱坐標是角度θ1和θ2)中最大化分類界限,而CosineFace中是cosθ1和cosθ2是以余弦空間中劃分,上圖是統一在角度空間畫出的,
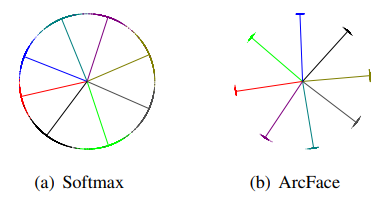
下圖中點表示樣本,線表示每個身份的中心方向,在特征歸一化的基礎上,將人臉所有特征推入固定半徑的圓弧空間,當添加角度懲罰后,最接近的類之間的分界線差距變得明顯,
2.5 人臉匹配🎭
人臉識別程序的最后一步就是人臉特征匹配,主要分為兩種型別,一種是通過特征算子從圖片中提取的特征進行比對;另外一種是現在使用廣泛的對特征向量計算相似度,并設定一系列的閾值和策略進行比對歸檔,
深度學習的廣泛應用,使得不需要在手工設計匹配特征,所以如今的匹配大多數是在特征向量上進行的,采用計算余弦相似度來衡量樣本間的距離,常用的距離有歐氏距離、 曼哈頓距離 、馬氏距離 、資訊熵等,當然評價指標也有很多,如本文2.4.1節提到的,在實際的業務場景中,也會根據實際情況制定不同的歸檔策略和清洗作業,這部分大多是采用機器學習和啟發式的方法進行的,最終的策略好壞比較難評估,是以實際的使用體驗和落地結果為導向的,這里就不過多介紹了,
2.6 小結📝
人臉識別領域這些年的發展,已經相當成熟并有很多成功落地的案列,但是復雜多變的環境在一些特定場景下也對演算法提出了特殊的要求,如種族歧視、性別歧視、人臉遮擋、密集人臉等問題,這些都有待進一步研究和優化,另外工業界也不同于學術界,講究準確率的同時還必須做到輕量化與高效性,因此在模型壓縮、并行計算上又有很多優化演算法和方法需要去具體落地和實作,這些工程問題也非常考驗一個演算法工程師的能力!! (我們還有很多需要學習的地方! 😭)
這里強烈推薦一個人臉識別開源的專案Insitght Face,里面設計到多個方面的演算法代碼,能學習到不少東西,且包含mxnet、pytorch、paddle等主流的深度學習框架實作!!
三、參考文獻
[1]An Introduction to Active Shape Models. Constrained Local Model for FaceAlignment. Xiaoguang Yan(2011).
[2] A Discriminative Feature Learning Approach for Deep Face Recognition
[3] ArcFace: Additive Angular Margin Loss for Deep Face Recognition
[4] 3DDFA: Face Alignment Across Large Poses- A 3D Solution
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/306295.html
標籤:其他
下一篇:順序表C語言實作附加力扣題