我寫了一個代碼來列印出一個值的串列。我想把得到的資料寫在一個csv檔案中。我的計算給了我5列,每列由5個資料組成。當我在 csv 檔案中列印資料時,我得到的是一個充滿所有數值的單元格,而不是在某一列的每一行中得到五個資料。
我把代碼寫成:
import csv
with open("/home/Documents/test.csv"/span>, "a") as fp:
wr = csv.writer(fp, dialect='excel')
wr.writerow(list)
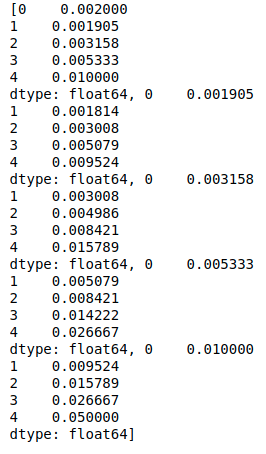
我在輸出中得到的結果是 :

預期的結果是 "A "列的值應該寫在每個單元格中,即0.002應該寫在A1單元格,0.001905應該寫在A2單元格,以此類推。同樣,B列的數值0.001814應該放在B2單元格中,以此類推。作為一個python的新手,我不知道是否有更好的方法來做或優化它。如果有任何幫助,我將非常感激。
uj5u.com熱心網友回復:
如果你使用Pandas,試試pd.concat:
pd.concat(your_list, axis=1).to_csv('file.csv')
uj5u.com熱心網友回復:
這看起來像你有一個numpy陣列或pandas系列的串列?僅僅根據你的列印結果,"dtype "的出現并不表明是一個純粹的python串列。
它看起來確實像某種可迭代的串列,所以你可以試試:
import csv
with open("/home/Documents/test.csv"/span>, "a") as fp:
wr = csv.writer(fp, dialect='excel')
for row in list
wr.writerow(row)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/308556.html
標籤:
上一篇:合并字典中的重復值