
一、正則運算式的定義:
正則運算式是你所定義的 模式模板 ( pattern template ), Linux 工具可以用它來過濾文本, Linux工具(比如sed 編輯器或 gawk 程式)能夠在處理資料時使用正則運算式對資料進行模式匹配,如果資料匹配模式,它就會被接受并進一步處理;如果資料不匹配模式,它就會被濾掉,
正則運算式模式匹配資料:
正則運算式模式利用通配符來描述資料流中的一個或多個字符,
Linux
中有很多場景都可以
使用通配符來描述不確定的資料,【*】號在我們作業中就比較常用,

示例說明:
a.*引數會讓ls命令只列出名字以a開頭的檔案,檔案名中a之后可以有任意多個字符(包括什么也沒有),ls命令會讀取目錄中所有檔案的資訊,但只顯示跟通配符匹配的檔案的資訊,
二、正則運算式的型別
使用正則運算式最大的問題在于有不止一種型別的正則運算式, Linux 中的不同應用程式可能會用不同型別的正則運算式,這其中包括編程語言(Java 、 Perl 和 Python )、 Linux 實用工具(比 如sed 編輯器、 gawk 程式和 grep 工具)以及主流應用(比如 MySQL 和 PostgreSQL 資料庫服務器),正則運算式是通過正則運算式引擎( regular expression engine )實作的,正則運算式引擎是一套底層軟體,負責解釋正則運算式模式并使用這些模式進行文本匹配,
兩種流行的正則運算式引擎:
- POSIX基礎正則運算式(basic regular expression,BRE)引擎
- POSIX擴展正則運算式(extended regular expression,ERE)引擎
POSIX BRE引擎通常出現在依賴正則運算式進行文本過濾的編程語言中,它為常見模式提供了高級模式符號和特殊符號,比如匹配數字、單詞以及按字母排序的字符,awk程式用ERE引擎來處理它的正則運算式模式,
說明:
由于實作正則運算式的方法太多,很難用一個簡潔的描述來涵蓋所有可能的正則運算式,后面會結合sed和awk演示最常見的正則運算式,
三、定義 BRE 模式
最基本的
BRE模式是匹配資料流中的文本字符,下面會演示如何在正則運算式中定義文本以及會得到什么樣的結果,
3.1 純文本

演示說明:
模式定義了一個單詞 test , sed 編輯器和 gawk 程式腳本用它們各自的 print 命令列印出匹配該正則運算式模式的所有行,由于echo 陳述句在文本字串中包含了單詞 test ,資料流文本能夠匹配所定義的正則運算式模式,編輯器能顯示該行,
正則運算式是區分大小寫的:

演示說明:
第一次嘗試沒能匹配成功,因為 this 在字串中并不都是小寫,而第二次嘗試在模式中使用大寫字母,所以能正常輸出,
在正則運算式中,你不用寫出整個單詞,只要定義的文本出現在資料流中,正則運算式就能
夠匹配,

演示說明:
資料流中的文本是 books ,在資料中含有正則運算式 book ,因此正則運算式模式跟資料匹配,
在正則運算式中,空格和其他的字符并沒有什么區別,

演示說明:
空格的出現無法和文本內容匹配,
如果在正則運算式中定義了空格,那么它必須出現在資料流中,甚至可以創建匹配多個連續空格的正則運算式模式,

演示說明:
單詞間有兩個空格的行匹配正則運算式模式,
3.2 特殊字符
正則運算式識別的特殊字符包括:
.*[]^${}\+?|()
如果要用某個特殊字符作為文本字符,就必須
轉義
,在轉義特殊字符時,你需要在它前面加一個特殊字符反斜杠(\)來告訴正則運算式引擎應該將接下來的字符當作普通的文本字符,

示例說明:
查找文本中的美元符,只要在它前面加個反斜線,
3.3 錨字符
默認情況下,當指定一個正則運算式模式時,只要模式出現在資料流中的任何地方,它就能匹配,有兩個特殊字符可以用來將模式鎖定在資料流中的行首或行尾,
3.3.1 鎖定在行首
脫字符(
^
)定義從資料流中文本行的行首開始的模式,如果模式出現在行首之外的位置,正則運算式模式則無法匹配,
要用脫字符,就必須將它放在正則運算式中指定的模式前面,

脫字符會在每個由換行符決定的新資料行的行首檢查模式,
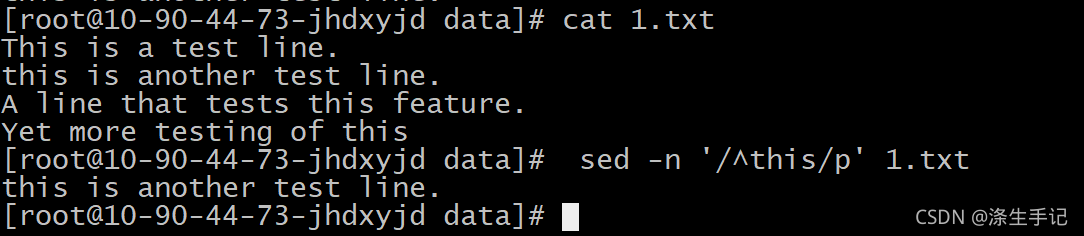
示例解說:
只要模式出現在新行的行首,脫字符就能夠發現它,

演示說明:
脫字符出現在正則運算式模式的尾部,sed編輯器會將它當作普通字符來匹配,
注意:
如果指定正則運算式模式時只用了脫字符,就不需要用反斜線來轉義,但如果在模式中先指定了脫字符,隨后還有其他一些文本,那么必須在脫字符前用轉義字符,
3.3.2 鎖定在行尾
跟在行首查找模式相反的就是在行尾查找,特殊字符美元符(
$
)定義了行尾錨點,將這個特殊字符放在文本模式之后來指明資料行必須以該文本模式結尾,

3.3.3 組合錨點
在一些常見情況下,可以在同一行中將行首錨點和行尾錨點組合在一起使用,在第一種情況中,假定你要查找只含有特定文本模式的資料行,

示例說明:
匹配文本中以test開頭和以test結尾的行
將兩個錨點直接組合在一起,之間不加任何文本,這樣過濾出資料流中的空白行,
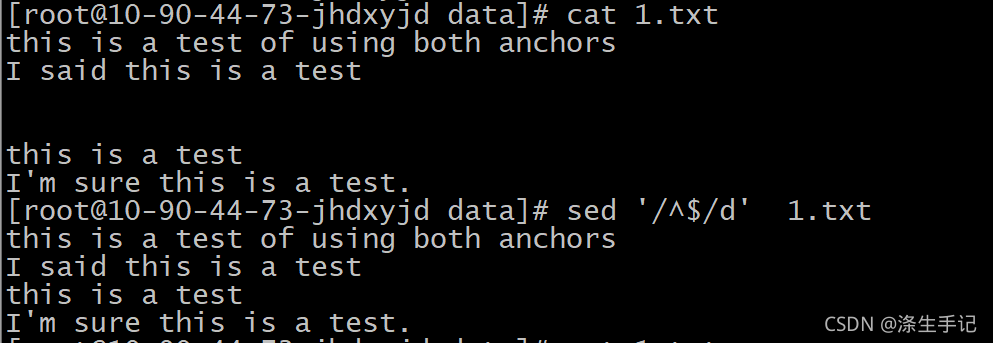
示例說明:
定義的正則運算式模式會查找行首和行尾之間什么都沒有的那些行,由于空白行在兩個換行符之間沒有文本,剛好匹配了正則運算式模式,sed 編輯器用洗掉命令 d 來洗掉匹配該正則運算式模式的行,因此洗掉了文本中的所有空白行,
3.4 點號字符
特殊字符點號用來匹配除換行符之外的任意單個字符,它必須匹配一個字符,如果在點號字符的位置沒有字符,那么模式就不成立,
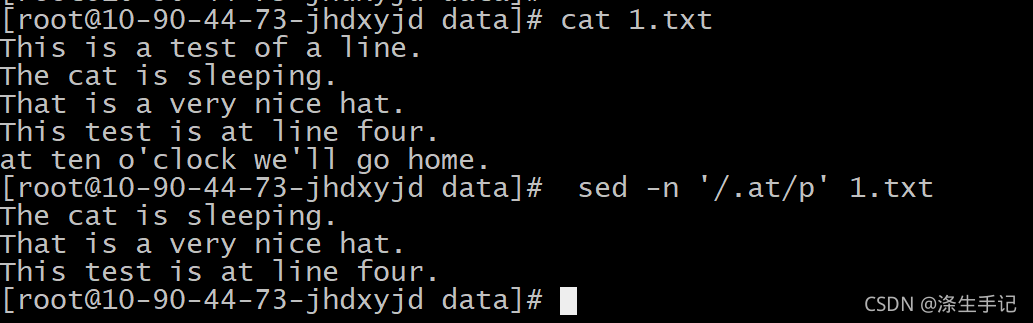
示例解說:
這個例子很具有說明性的,為什么第一行無法匹配,而第二行和第三行就可以,第四行有點復雜,注意, 我們匹配了at,但在at前面并沒有任何字符來匹配點號字符,其實是有的!在正則運算式中, 空格也是字符,因此at前面的空格剛好匹配了該模式,第五行證明了這點,將at放在行首就不 會匹配該模式了,
3.5 字符組
使用方括號來定義一個字符組,方括號中包含所有你希望出現在該字符組中的字符,然后可以在模式中使用整個組,就跟使用其他通配符一樣,
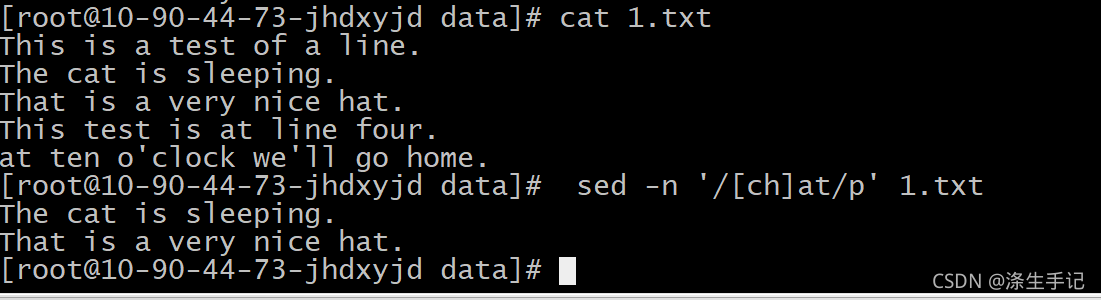
示例說明:
匹配這個模式的單詞只有 cat 和 hat ,還要注意以 at 開頭的行也沒有匹配,字符組中必須有個字符來匹配相應的位置,
在不太確定某個字符的大小寫時,字符組會非常有用,如下示例:

字符組不必只含有字母,也可以在其中使用數字,
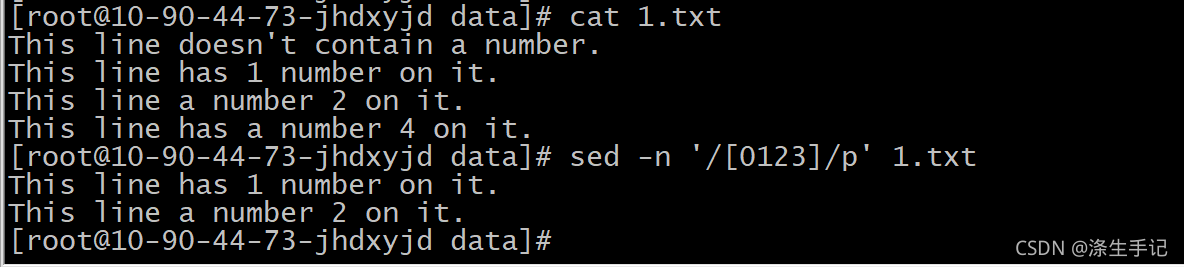
示例說明:
這個正則運算式模式匹配了任意含有數字 0 、 1 、 2 或 3 的行,含有其他數字以及不含有數字的行都會被忽略掉,

示例說明:
正則運算式模式可見于資料流中文本的任何位置,經常有匹配模式的字符之外的其他字符,如果要確保只匹配五位數,就必須將匹配的字符和其他字符分開,要么用空格,要么像這個例子中這樣,指明它們就在行首和行尾,
3.6 排除型字符組
在正則運算式模式中,也可以反轉字符組的作用,可以尋找組中沒有的字符,而不是去尋找組中含有的字符,要這么做的話,只要在字符組的開頭加個脫字符,
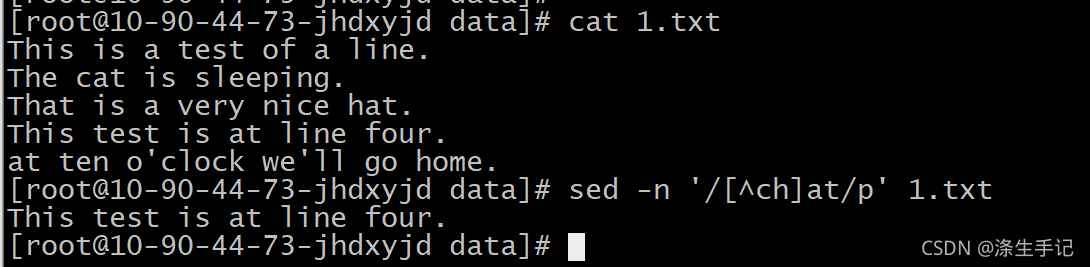
示例說明:
使用排除型字符組,正則運算式模式會匹配 c 或 h 之外的任何字符以及文本模式,由于空格字符屬于這個范圍,它通過了模式匹配,但即使是排除,字符組仍然必須匹配一個字符,所以以 at開頭的行仍然未能匹配模式,
3.7 區間
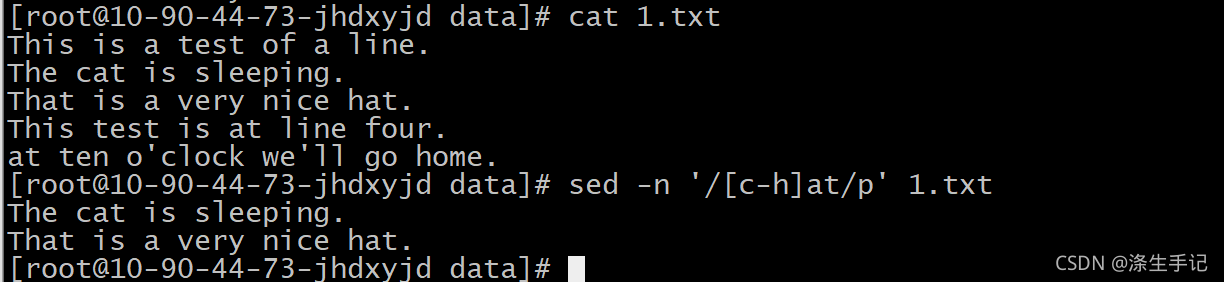
示例說明:
新的模式 [c-h]at 匹配了首字母在字母 c 和字母 h 之間的單詞,這種情況下,只含有單詞 at的行將無法匹配該模式,
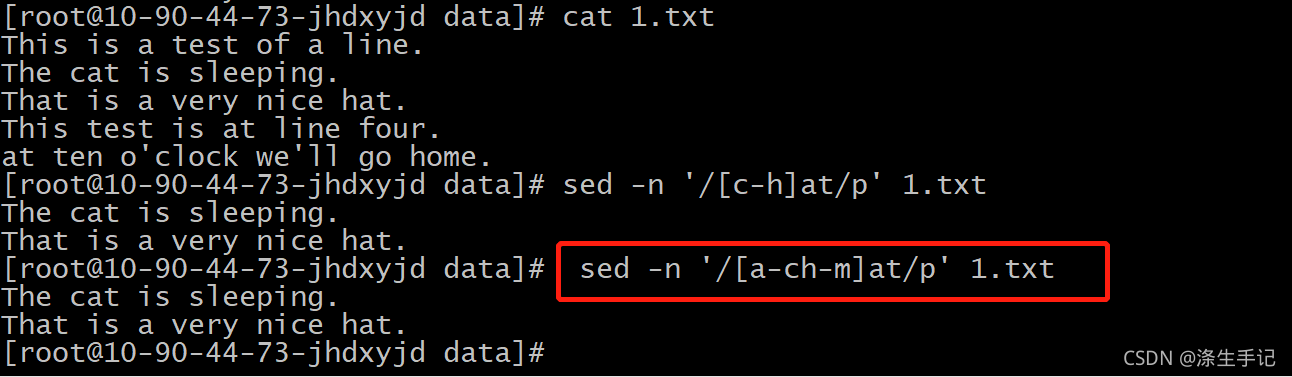
示例說明:
該字符組允許區間a~c、h~m中的字母出現在at文本前,但不允許出現d~g的字母,
3.8 特殊的字符組
除了定義自己的字符組外,
BRE
還包含了一些特殊的字符組,可用來匹配特定型別的字符,
- [[:alpha:]] 匹配任意字母字符,不管是大寫還是小寫
- [[:alnum:]] 匹配任意字母數字字符0~9、A~Z或a~z
- [[:blank:]] 匹配空格或制表符
- [[:digit:]] 匹配0~9之間的數字
- [[:lower:]] 匹配小寫字母字符a~z
- [[:print:]] 匹配任意可列印字符
- [[:punct:]] 匹配標點符號
- [[:space:]] 匹配任意空白字符:空格、制表符、NL、FF、VT和CR
- [[:upper:]] 匹配任意大寫字母字符A~Z

示例說明:
使用特殊字符組可以很方便地定義區間,可以用 [[:digit:]] 來代替區間 [0-9] ,
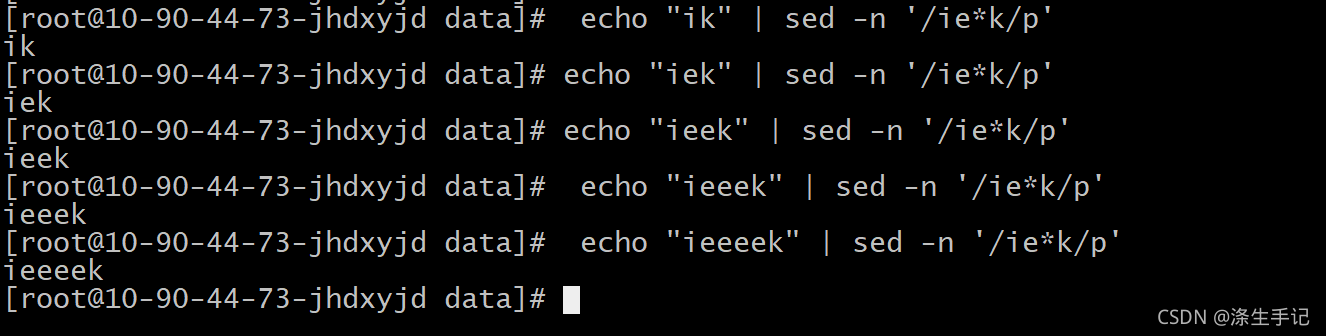
3.9 星號【*】
在字符后面放置星號表明該字符必須在匹配模式的文本中出現
0
次或多次,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/308897.html
標籤:其他
上一篇:如何在AppleScriptObj中獲取NSImage.Name?
下一篇:【演算法入門09】矩形覆寫