文章目錄
- (1)前言
- (2)C++關鍵字(C++98)
- (3)命名空間
- 1)命名空間的定義
- 2)命名空間的使用
- (3)C++的輸入&輸出
- (4)預設引數
- 1)預設引數的概念
- 2)預設引數的分類
- (5)函式多載
- (6)extern "c"
(1)前言
C++是C語言的繼承,兼容絕大多數C的語法,在其基礎上增加了一些語法,一般是為了解決C語言做不到的事情、修改不夠好的地方
- 什么是C++
C語言是結構化和模塊化的語言,適合處理較小規模的程式,對于復雜的問題,規模較大的程式,需要高度的抽象和建模時,C語言則不合適,為了解決軟體危機, 20世紀80年代, 計算機界提出了OOP(object oriented programming:面向物件思想),支持面向物件的程式設計語言應運而生,
1982年,Bjarne Stroustrup 博士在C語言的基礎上引入并擴充了面向物件的概念,發明了一種新的程式言,為了表達該語言與C語言的淵源關系,命名C++,因此:C++是基于C語言而產生的,它既可以進行C語言的程序化程式設計,又可以進行以抽象資料型別為特點的基于物件的程式設計,還可以進行面向物件的程式設計,
- C++的發展史
| 最重要的兩個版本 | 內容 |
|---|---|
| C++98 | C++標準第一個版本,絕大多數編譯器都支持,得到了國際標準化組織(ISO)和美國標準化協會認可,以模板方式重寫C++標準庫,引入了STL(標準模板庫) |
| C++11 | 增加了許多特性,使得C++更像一種新語言,比如:正則運算式、基于范圍for回圈、auto關鍵字、新容器、串列初始化、標準執行緒庫等 |
- C++的應用領域
- 作業系統以及大型系統軟體開發
- 服務器端開發
- 人工智能
- 網路工具
- 游戲開發
- 嵌入式領域
- 數字影像處理
- 分布式應用
- 移動設備
- 學習C++:建議不要把「精通C++」作為一個一年目標,應該要把學習語言作為一個持續的程序,同時要把語言運用在具體的應用場合中,
(2)C++關鍵字(C++98)
- C++共有63個關鍵字,其中有32個關鍵字是我們在學習C語言時就見過的
- 在接下來的學習程序中,學到某個關鍵字時再展開細講
| asm | do | if | return | try | continue |
| auto | double | inline | short | typedef | for |
| bool | dynamic_cast | int | signed | typeid | public |
| break | else | long | sizeof | typename | throw |
| case | enum | mutable | static | union | wchar_t |
| catch | explicit | namespace | static_cast | unsigned | default |
| char | export | new | struct | using | friend |
| class | extern | operator | switch | virtual | register |
| const | false | private | template | void | true |
| const_cast | float | protected | this | volatile | while |
| delete | goto | reinterpret_cast |
(3)命名空間
- C語言中存在的一個問題
在不同的作用域,我們可以定義同名的變數;在同一作用域,不能定義同名的變數,
所以在一個大專案中,多個人分工寫代碼,最后合在一起時,你寫的代碼和我寫的代碼中的命名可能會沖突,我們寫的代碼中的命名又可能會和標準庫里的沖突,
假如張三寫了個函式取名為 Add,我也寫了個函式,取名也為 Add,代碼合在一起時,可能會引起命名沖突等等,
- 舉例說明
如果沒有包含
stdlib.h頭檔案,代碼可以正常運行;但包含之后,因為
stdlib.h庫中有一個叫rand函式,全域變數rand與其沖突了,
#include<stdio.h>
#include<stdlib.h> /*rand*/
int rand = 10; //全域變數rand
int main()
{
printf("%d\n", rand); //error: "rand"重定義,以前的定義是"函式"
return 0;
}
- C++提出了命名空間來解決命名沖突的問題
在C/C++中,變數、函式和類都是大量存在的,這些變數、函式和類的名稱將都存在于全域作用域中,可能會導致很多沖突,使用命名空間的目的是對識別符號的名稱進行本地化,以避免命名沖突或名字污染,namespace 關鍵字的出現就是針對這種問題的,
命名空間相當于一個域,把各自寫的東西隔起來,
1)命名空間的定義
定義命名空間,需要使用到 namespace 關鍵字,后面跟命名空間的名字,然后接一對 { } 即可,{ } 中即為命名空間的成員,
注意:一個命名空間代表定義了一個新的作用域,命名空間中的所有內容都局限于該命名空間中,
- 命名空間的普通定義
//命名空間的普通定義
namespace L1 //L1為命名空間的名稱
{
//命名空間中可以定義變數/函式/型別
int a = 10;
int Add(int x, int y)
{
return x + y;
}
struct Node
{
struct Node* next;
int val;
};
}
- 命名空間的嵌套定義
//命名空間的嵌套定義
namespace L2
{
int a = 10;
namespace L3 //嵌套定義一個名為L3的命名空間
{
int b = 20;
int sub(int x, int y)
{
return x - y;
}
}
}
- 同一個工程中允許存在多個相同名稱的命名空間,編譯器最后會合成到同一個命名空間中(所以相同名稱的命名空間中不能出現同名的變數/函式/型別,否則會引起沖突)
2)命名空間的使用
//定義一個命名空間N1
namespace N1
{
int a = 10;
int b = 10;
int Add(int x, int y)
{
return x + y;
}
}
命名空間的使用有三種方式:
- 全部展開到全域,就可以直接使用(使用 using namespace 將命名空間名稱引入)
// 優點:用起來方便
// 缺點:把自己的定義暴露出去了,導致命名污染
//using namespace std; //std是包含C++標準庫的命名空間
using namespace N1;
int main()
{
Add(1, 2);
return 0;
}
- 訪問命名空間中的成員時,加命名空間名稱及作用域限定符
// 優點:不存在命名污染
// 缺點:用起來麻煩,每個都需要去指定命名空間
int main()
{
printf("%d\n", N1::a);
N1::Add(1, 2);
return 0;
}
- 使用 using 將命名空間中常用的成員引入
// 優點:不會造成大面積的命名污染,又可以把常用的給展開
// 這是一個折中的解決方案
using N1::Add; //命名空間N1中Add函式和變數a用的非常多,將其展開到全域
using N1::a;
int main()
{
printf("%d\n", a);
Add(1, 2);
return 0;
}
- 補充一點:命名空間 std 的規范使用
C++把標準庫里面的東西都放到命名空間 std 中,所以在實際開發中,為了避免你自己寫的變數/函式/型別等等與標準庫中的沖突,建議不要把命名空間 std 直接展開到全域,而是把常用的展開就行,一般規范的寫法為:
#include<iostream>
//using namespace std; //不要將std直接展開到全域
//把常用的展開就行
using std::cout;
using std::endl;
int main()
{
cout << "hello world" << endl;
return 0;
}
如果是日常練習,就不需要像上面這么規范,直接展開用
(3)C++的輸入&輸出
C語言有自己的輸入輸出函式 scanf 和 printf,那么C++也有自己獨特的輸入輸出方式,cin 標準輸入流和 cout 標準輸出流,必須包含 頭檔案和 std 標準庫命名空間,
注意:早期標準庫將所有功能在全域域中實作,宣告在 .h 后綴的頭檔案中,使用時只需包含對應頭檔案即可,后來將其實作在 std 命名空間下,為了和 C 頭檔案區分,也為了正確使用命名空間,規定C++頭檔案不帶.h;舊編譯器(vc 6.0)中還支持 <iostream.h> 格式,后續編譯器已不支持,因此推薦使用 + std 的方式,
使用C++輸入輸出更方便,它可以自動識別變數的型別,不需增加資料格式控制,比如:整形–%d,字符–%c
#include<iostream>
using namespace std; //C++標準庫
int main()
{
int a;
cin >> a; // >> 輸入運算子/流提取運算子
cout << a; // << 輸出運算子/流插入運算子
cout << endl; //換行,等價于 cout << '\n';
return 0;
}
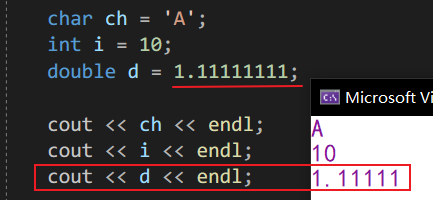
- 注意:C++中的浮點數,當小數點后數字超過 5 位時,cout 規定輸出的是小數點后 5 位,如果想要實作浮點數的格式化輸出,那就建議用 printf 來輸出,使用一定要靈活變通,
(4)預設引數
1)預設引數的概念
**預設引數是宣告或定義函式時為函式的引數指定一個默認值,**在呼叫該函式時,如果沒有指定實參則采用該默認值,否則使用指定的實參,
#include<iostream>
using namespace std;
void Func(int a = 0)
{
cout << a << endl;
}
int main()
{
Func(); //沒有傳參時,使用引數的默認值
Func(10); //傳參時,使用指定的引數
return 0;
}
- 預設引數的使用
以前入堆疊時必須得判斷一下容量是否為0,若為0,給capacity賦一個初始值,但賦的這個初始值沒辦法靈活的去控制,有了預設引數,我們就可以根據需要,來控制初始容量,
#include<iostream>
using namespace std;
//定義一個順序堆疊
struct Stack
{
int* a;
int top;
int capacity;
};
//初始化堆疊,給堆疊容量設定一個默認值4
void StackInit(struct Stack* ps, int DefaultCapacity = 4)
{
ps->a = (int*)malloc(sizeof(int) * DefaultCapacity);
ps->top = -1;
ps->capacity = 0;
}
//入堆疊
void StackPush(struct Stack* ps)
{
if (ps->top == ps->capacity + 1)
{
ps->capacity *= 2;
//......
}
//......
}
int main()
{
//假如我明確知道這里至少要存100個資料到st1中去
struct Stack st1;
StackInit(&st1, 100);
//假如我不知道要存多少個資料到st2中去
struct Stack st2;
StackInit(&st2);
return 0;
}
2)預設引數的分類
- 全預設引數
#include<iostream>
using namespace std;
void Func(int a = 10, int b = 20, int c = 30)
{
cout << a + b + c << endl;
}
int main()
{
//呼叫全預設引數的函式方式很靈活
Func();
Func(1);
Func(1, 2);
Func(1, 2, 3);
return 0;
}
- 半預設引數
#include<iostream>
using namespace std;
void Func(int a, int b = 10, int c = 20)
{
cout << a + b + c << endl;
}
int main()
{
//呼叫半預設引數的函式
Func(1); //1傳給a
Func(1, 2); //1傳給a,2傳給b
Func(1, 2, 3); //1傳給a,2傳給b,3傳給c
return 0;
}
- 總結
- 半預設引數必須從右往左依次來給出,不能間隔著給
- 預設引數不能在函式宣告和定義中同時出現(建議宣告的時候給預設引數,定義的時候就不要給了)
//注意:如果宣告與定義位置同時出現,恰巧兩個位置提供的值不同,那編譯器就無法確定到底該用那個預設值, //test.h void Func(int a = 10); //test.c void Func(int a = 20) { //...... }
- 預設值必須是常量或者全域變數
//不能這樣給預設值 void Func(int a, int b = x);//error
- C語言不支持預設引數(編譯器不支持)
(5)函式多載
自然語言中,一個詞可以有多重含義,人們可以通過背景關系來判斷該詞真實的含義,即該詞被多載了,
以前有一個笑話,國有兩個體育專案大家根本不用看,也不用擔心,一個是乒乓球,一個是男足,前者是 ” 誰也贏不了!”,后者是 “ 誰也贏不了!”
可以看出,同一句話,可能有多重意思,
- 函式多載的概念
函式多載是函式的一種特殊情況,C++允許在同一作用域中宣告幾個功能類似的同名函式,這些同名函式的形參串列(引數個數 / 型別 / 順序)必須不同,常用來處理實作功能類似但資料型別不同的問題,
int Add(int a, int b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}
long Add(long a, long b)
{
return a + b;
}
int main()
{
Add(10, 20);
Add(10.0, 20.0);
Add(10L, 20L); //L表示該常數是以長整型方式存盤,long
return 0;
}
- 思考
- 編譯器能不能實作函式名相同,引數相同,回傳值不同來構成函式多載?
結論:不能實作,無法多載僅按回傳值型別區分的函式,
int func(); -> _Z3ifunc double func(); -> _Z3dfunc如果把回傳值帶進名字修飾規則,那么編譯器層面是可以區分的,
但是語法呼叫層面,無法根據引數串列確定呼叫哪個多載函式,甚至帶有嚴重的歧義!
比如這條陳述句
func();,呼叫時,這里是要呼叫哪一個呢?
(6)extern “c”
C++編譯器能識別C++函式名修飾規則,也能識別C的函式名修飾規則,
我們在C++專案開發中,可能會用到一些第三方的庫,有些是純C實作的庫(動態庫/靜態庫),它里面的函式名修飾規則是C的,而C++是兼容C的,C++編譯器直接按照C的修飾規則去呼叫,
但如果是純C的專案,用到C++實作的庫(動態庫/靜態庫),比如:tcmalloc是google用C++實作的一個庫,他提供
tcmallc()和tcfree()兩個介面來使用(更高效,替代malloc和free函式),這個庫可以給C++專案用,但不能給C專案用,會存在鏈接失敗,因為C編譯器無法識別C++的修飾規則,如果想要給C用,需要將C++庫中的部分函式按照C的風格來編譯,在函式前加
extern "C",意思是告訴編譯器,將該函式按照C的修飾規則來編譯,extern "C" void Add(int a, int b);
- 總結
C++專案可以呼叫C++的庫,也可以呼叫C的庫,
C的專案可以呼叫C的庫,如果要呼叫C++的庫,需要在該函式前加上
extern "C",
- 思考題
下面兩個函式能形成函式多載嗎?——> 不能
void Func(int a = 10) { cout << "Func(int)" << endl; } void Func(int a) { cout << "Func(int)" << endl; }C語言中為什么不能支持函式多載?
——> C和C++編譯器的函式名修飾規則不一樣,C編譯器直接拿函式名在目標檔案里面充當函式名和函式地址的映射,所以在鏈接的時候,是拿函式名去目標檔案里面去找,函式名相同,雖然引數不同,但不知道找的是誰,
C++中函式多載底層是怎么處理的?
——> C++編譯器不直接拿函式名去找,而是拿修飾后的函式名去找,引數不同修飾后的函式名就不同,就能夠找到,
C++中能否將一個函式按照C的風格來編譯?
——> 能,在函式前加上
extern "C"
未完待續,下一篇,我們將學習C++中最重要的一個知識之一,參考 …… 一起期待吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/308900.html
標籤:其他
上一篇:超詳細!程式預處理的程序