目錄
MongoDB概念
MongoDB Shell 基本命令
1.基本概念
3.資料庫(db)
3. 集合(collection)
3.1 添加檔案到集合
3.2 查詢檔案記錄
3.3 更新檔案記錄
3.4 洗掉檔案記錄
4. 游標和腳本
4.5 單一功能聚合函式
4.6 匯入與匯出
4.7 備份與恢復
每文一語
MongoDB概念
點擊標題,即可跳轉到博主詳情文章,本文介紹了MongoDB的概念和基本的知識,至于MongoDB到底可以用來做什么,資料庫的存盤,而且是大資料的存盤,因為MongoDB是基于大資料分布式集群所建立的,廣泛的應用在資料量大的操作之上,我們可以把資料存盤在MongoDB集群上,

MongoDB Shell 基本命令
1.基本概念
| SQL術語/概念 | MongoDB術語/概念 | 解釋/說明 |
| database | db | 資料庫 |
| table | collection | 資料庫表/集合 |
| row | document | 資料記錄行/檔案 |
| column | field | 資料欄位/域 |
| index | index | 索引 |
| table joins | 表連接,MongoDB不支持 | |
| primary key | primary key | 主鍵,MongoDB自動將_id欄位設定為主鍵 |
檔案的基本結構:{ : , : {}, ... }
封閉符 {}
分隔符 ,
連接符 :
鍵的資料型別:UTF-8字符,可以用”“引起來,如”name“
的用戶命名規則:
(1)'_id' 為保留欄位key
(2) 禁止使用'$'符號
(3) 禁止使用'.'符號
(4) 避免同一個{}中使用重復的
值的資料型別:MongoDB支持的任意資料型別
示例一:
{ "_id" : 1, "name" : "Zhang San" }
示例二:
{
"_id" : ObjectId("5e746c62040a548ab32fff13"), //ObjectId物件
"name" : "Zhang San",// 字串
"age" : 18,// 數字
"alive" : true, // 布林值
"hobbies" : ["Anime","Comic","Game", 19], // 串列(陣列)
"body": {
"height" : 170,
"weight" : 65
}, // 內嵌檔案
"courses" : [
{ "coursename" : "nosql" },
{ "coursename" : "mysql" },
{ "coursename" : "python" },
{ "coursename" : "linux" },
{ "coursename" : "kettle" }
] // 內嵌檔案的串列
}
MongoDB的基本資料型別
| 資料型別 | 描述 |
| String | 字串,存盤資料常用的資料型別,在 MongoDB 中,UTF-8 編碼的字串才是 合法的, |
| Integer | 整型數值,用于存盤數值,根據你所采用的服務器,可分為 32 位或 64 位, |
| Boolean | 布林值,用于存盤布林值(真/假), |
| Double | 雙精度浮點值,用于存盤浮點值, |
| Min/Max keys | 將一個值與 BSON(二進制的 JSON)元素的最低值和最高值相對比, |
| Arrays | 用于將陣列或串列或多個值存盤為一個鍵, |
| Timestamp | 時間戳,記錄檔案修改或添加的具體時間, |
| Object | 用于內嵌檔案, |
| Null | 用于創建空值, |
| Symbol | 符號,該資料型別基本上等同于字串型別,但不同的是,它一般用于采用特殊 符號型別的語言, |
| Date | 日期時間,用 UNIX 時間格式來存盤當前日期或時間,你可以指定自己的日期時 間:創建 Date 物件,傳入年月日資訊, |
| Object ID | 物件 ID,用于創建檔案的 ID, |
| Binary Data | 二進制資料,用于存盤二進制資料, |
| Code | 代碼型別,用于在檔案中存盤 JavaScript 代碼, |
| Regular expression | 正則運算式型別,用于存盤正則運算式, |
3.資料庫(db)
// 查看當前服務器上的資料庫
show dbs;
show databases;
// 選擇名為mydb的資料庫(如果沒有則創建)
use mydb;
// 查看當前使用的資料庫
db;
// 查看當前資料庫的統計資訊
db.stats();
// 查看當前資料庫的操作資訊
db.currentOp();
// 洗掉當前資料庫
db.dropDatabase();3. 集合(collection)
// 查看當前資料庫中的集合
show collections;
show tables;
// 創建一個名為mycoll的集合
db.createCollection("mycoll");
// 重命名mycoll集合,新集合名叫mycollection
db.mycoll.renameCollection("mycollectioin")
// 清空一個名為mycollection的集合
db.mycollection.remove({});
// 洗掉一個名問mycollection的集合
db.mycollection.drop();3.1 添加檔案到集合
insert() 方法
注意:db.collection中,collection為你要操作的集合的名稱
db.collection.insert(
<document or array of documents>,
{multi: false}
)insertOne() 方法
添加一條檔案記錄
db.collection.insertOne(
<document>{}
)insertMany() 方法
添加多條檔案記錄 ([]方括號表示陣列)
db.collection.insertMany(
[ <document 1> {} , <document 2> {}, ... ] --jsonArray
)// 添加一條檔案記錄{"lastname":"wang", "firstname":"xiaowang"}到集合mycollection
db.mycollection.insert({"lastname":"wang", "firstname":"xiaowang"});
db.mycollection.insertOne({"lastname":"wang", "firstname":"wang"});
// 添加一個檔案記錄物件mydoc到集合mycollection, 使用insert或insertOne方法
var mydoc = {"lastname":"wang", "firstname":"xiaowang"};
db.mycollection.insert(mydoc);
// 3.2版后新的方法:insertOne
db.mycollection.insertOne(mydoc);
// 添加多條記錄到集合mycollection,使用insert或insertMany方法
// 多條檔案記錄,用[]組合,用逗號分隔
db.mycollection.insert(
[
{"lastname":"wang", "firstname":"xiaowang", "role":"teacher",
"teacher_id":"123", "title":"講師", "courses":[{"coursename":"nosql"},
{"coursename":"mysql"}]},
{"lastname":"wang", "firstname":"xiaowang", "role":"student",
"student_id":"456", "grade":"2019", "class":"1", "score":100}
] )
;
// 添加一個檔案陣列mydocs(多條檔案的陣列)到集合mycollection,使用insert或insertMany方法
// 多條檔案記錄用[]組合到一個陣列mydocs中,
// 注意 coursename處于兩個花括號中,屬于兩個內嵌的檔案,不算重復的鍵
var mydocs = [
{
"lastname" : "wang",
"firstname" : "xiaowanag",
"role" : "teacher",
"teacher_id" : "2019814",
"title" : "講師",
"courses" : [
{ "coursename" : "nosql" },
{ "coursename" : "mysql" },
{ "coursename" : "python" },
{ "coursename" : "linux" },
{ "coursename" : "kettle" }
]
},
{
"lastname" : "xiaowang1",
"firstname" : "wang",
"role" : "student",
"student_id" : "2019000001",
"grade" : "2019",
"class" : "1",
"score" : 80
},
{
"lastname" : "w",
"firstname" : "Er",
"role" : "student",
"student_id" : "2019000002",
"grade" : "2019",
"class" : "1",
"score" : 70
}
];
db.mycollection.insert(mydocs);
// 3.2版后新的方法:insertMany
db.mycollection.insertMany(mydocs);注意我們的insert方法和insertMany方法,具有一樣的效果
3.2 查詢檔案記錄
find() 方法
這里給出了幾種常見的查詢方法,一般利用查詢運算子進行查詢
db.mycollection.find({"score":{$gt:70}},{student_id:1});
// 查詢集合mycollection中的檔案
db.mycollection.find();
// 將查詢結果"漂亮化"
db.mycollection.find().pretty();
// 查詢集合mycollection中鍵為role, 值為student的檔案記錄
db.mycollection.find( {"role" : "student"} );
// 將查詢條件寫入檔案物件ceriteria查詢
var criteria = { "role" : "student" };
db.mycollection.find(criteria);
// 使用內嵌物件的欄位值查詢
db.mycollection.find({"courses.coursename":"mysql"})| 操作 | 運算子 | 范例 | SQL 陳述句的類似 |
| 等于 | : | db.mycollection.find({"role":"student"}) | whererole='student' |
| 小于 less than | $lt: | db.mycollection.find({"score":{$lt:80}}) | where score < 80 |
| 小于或等于less than /equal | $lte: | db.mycollection.find({"score": {$lte:80}}) | where score <=80 |
| 大于greater than | $gt: | db.mycollection.find({"score":{$gt:80}}) | where score > 80 |
| 大于或等于greater than /equal | $gte: | db.mycollection.find({"score": {$gte:80}}) | where score >=80 |
| 不等于 not equal | $ne: | db.mycollection.find({"score":{$ne:80}}) | where score !=80 |
// 按資料型別查詢
// 數值(double):1
// 字串(string):2
// 物件(object):3
// 陣列(array):4
// 二進制資料(binary):5
// 未定義(Undefined):6
// 物件ID(ObjectId): 7
// 布林值(boolean):8
// 日期(date):9
// 空(null):10
db.mycollection.find({"score":{$type:1}});
// 查詢條件的邏輯運算 (AND)
db.mycollection.find({"role":"student","score":80});
// 查詢條件的邏輯運算 (OR) , 注意$or是一個陣列[]
db.mycollection.find({$or:[{"role":"student"},{"role":"teacher"}]});
// 查詢條件的成員運算 (IN)
db.mycollection.find({"student_id":{$in:["2019000001","2019000002"]}})
等價于:
db.mycollection.find({$or:[{"student_id":"2019000001"},
{"student_id":"2019000002"}]})
// 限制查詢結果欄位
// 查詢role是student的檔案中的score欄位值(只回傳_id和score)
// 類比 sql: select score from mycollection where role="student";
// projection格式: { field1: <value>, field2: <value> ... }
db.mycollection.find({role:"student"}, {score:1})
// 使用變數存放 查詢檔案 和 回傳欄位檔案(包含或者排除欄位 1:包含 0:排除,不能混用(可以單獨排除_id))
my_query = {$or:[{"student_id":"2019000001"},{"student_id":"2019000002"}]}
my_projection = {"_id":0, "score": 1,"firstname":1, "lastname":1}
db.mycollection.find(my_query, my_projection)范例集合
courses陣列中包含一個分布式的課程(course), 而且(AND), courses陣列中包含大于80的分數(score)
var 查詢條件1 = {
"courses.course":"分布式資料庫原理與應用",
"courses.score":{$gt:80}
};
var 查詢條件2 = {
"courses":{
$elemMatch:{
"course":"分布式資料庫原理與應用",
"score":{$gt:90}
}
}
}; // courses陣列中包含一個 分布式課程而且其分數大于80 的陣列元素
var 回傳條件 = {
_id:0,
sno:1,
// courses:1
courses:{$elemMatch:{"course":"分布式資料庫原理與應用"}}
};
db.getCollection("students").find(查詢條件2, 回傳條件)3.3 更新檔案記錄
update operators 更新運算子
| Name | Description |
| $currentDate | $currentDate:{'欄位名':{$type:'date|timestamp'}} |
| $inc | increase : 欄位值+1 |
| $min | 如果更新值更小才更新 |
| $max | 如果更新值更大才更新 |
| $mul | multiply: 欄位值乘n |
| $rename | 重命名欄位 |
| $set | 設定一個鍵值對 |
| $setOnInsert | 只在檔案不存在需要插入是設定的欄位 |
| $unset | 洗掉一個鍵值對 |
db.collection.updateOne|updateMany|replaceOne(
<query>,
<update>,
{
upsert: <boolean>,
collation: <document>
}
)
引數說明:
query : update的查詢條件,類似sql update查詢內where后面的,
update : update的物件和一些更新的運算子(如 inc...)等,也可以理解為sql update查詢內set后面的
upsert : 可選,這個引數的意思是,如果不存在update的記錄,是否插入objNew,true為插入,默認是false,不插入,
multi : 可選,mongodb 默認是false,只更新找到的第一條記錄,如果這個引數為true,就把按條件查出來多條記錄全部更新,
writeConcern :可選,拋出例外的級別,
// 將學號(student_id)為2019000000的記錄的score的值更改為90
// 類比sql: update mycollection set score=90 where student_id='2019000000';
db.mycollection.update({"student_id":"2019000000"}, {$set:{"score":90}});// 將所有的學生的的成績(score)增加5, 注意:修改多條記錄要使用{multi:true}
// 類比sql: update mycollection set score=score+5 where role='student';
db.mycollection.update({"role":"student"}, {$inc:{"score":5}}, {multi:true});// 將所有的學生的成績提高5分
query1 = {"role":"student"}
update1 = {$inc:{"score":5}}
option1 = {}
db.mycollection.updateMany(query1, update1, option1)// 將所有2018級的學生改為2019級
query2 = {"grade":"2018"}
update2 = {$set:{"grade":"2019"}}
option2 = {}
db.mycollection.updateMany(query2, update2, option2)// 將學號為2019000003的學生的姓、名、班、級替換為指定的值
// 如果集合中沒有2019000003學生,則插入這個學生資訊
query3 = {"student_id":"2019000003"}
update3 = {$set:{"score":60, "class":3, "grade":"2019", "firstname":"Yanzu",
"lastname":"Wu"}}
option3 = {"upsert":true}
db.mycollection.updateOne(query3, update3, option3)注意這里使用了,upset這個引數,這個引數在上面的引數介紹里面也有過說明,如果不存在這個那么就會執行插入操作
// 也可以使用replaceOne, 注意update3的寫法,不需要使用$set,... 運算子
query3 = {"student_id":"2019000004"}
update3 = {"lastname":"Wu", "firstname":"Yanzu", "grade":"2019", "class":3,
"score":60}
option3 = {"upsert":true}
db.mycollection.replaceOne(query3, update3, option3)update陣列中的元素
// $push: 向陣列的尾部添加一個元素,如果欄位不存在則創建
// $push + $each : 批量push,將$each:[]中的元素依次push到陣列中
// $pushAll = $push + $each 批量push
// $addToSet:不重復的set集合
// $pop: 彈出陣列的頭部元素或尾部元素: -1:頭部,1:尾部
// $pull: 洗掉陣列中的值
// 使用小標或者定位運算子$來操作陣列 $表示querydoc中確定的陣列元素
// 修改內嵌檔案陣列中第n個元素的值
// 定位運算子$: 查詢條件一般是以陣列中的元素為條件,使用$符號作為滿足查詢條件的第一條檔案對應的下標值
3.4 洗掉檔案記錄
remove() 方法
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)deleteOne() 方法
deleteMany() 方法
db.collection.deleteOne|deleteMany(
<query>,
{
writeConcern: <document>,
collation: <document>
}
)query :(可選)洗掉的檔案的條件,
justOne : (可選)如果設為 true 或 1,則只洗掉一個檔案,如果不設定該引數,或使用默認值
false,則洗掉所有匹配條件的檔案,
writeConcern :(可選)拋出例外的級別,
范例大全
// 條件洗掉學號為2019000002的檔案記錄
// 類比sql: delete from mycollection where student_id='2019000000';
db.mycollection.remove({"student_id":"2019000002"});db.mycollection.deleteMany{"student_id":"2019000002"});// 洗掉第一條符合條件的檔案記錄
db.mycollection.remove({"role":"student"},justOne:true);
// 或者
db.mycollection.deleteOne({"role":"student"});
一般的,我們使用remove就可以很好的解決問題
// 洗掉所有記錄
db.mycollection.remove({});remove() 方法 并不會真正釋放空間,需要繼續執行 db.repairDatabase() 來回收磁盤空間,
db.repairDatabase()
// 或者
db.runCommand({ repairDatabase: 1 })小結:
增: db.collection.insert(newdocs)
-> db.collection.insertOne|insertMany
刪: db.collection.remove(querydoc)
-> db.collection.deleteOne|deleteMany
改: db.collection.update(querydoc, updatedoc or newdoc, {upset:true})
-> db.collection.updateOne|updateMany|replaceOne
查: db.collection.find(querydoc, projection)
var query = {"courses.course":"分布式資料庫原理與應用"}
var projection = {
_id:0,
major:1,
grade:1,
class:1,
courses:{$elemMatch:{"course":"分布式資料庫原理與應用"}}
}
db.students.find(query,projection)4. 游標和腳本
4.1 游標的用法
宣告一個游標
var mycursor = db.collection.find()hasNext() next()
var mycursor = db.collection.find()
while(mycursor.hasNext()){
printjson(mycursor.next());
}forEach()
var getScore = function(doc) {
for(i=0;i<doc.courses.length;i++) {
if(doc.courses[i].course == "分布式資料庫原理與應用") {
print(doc.name, doc.courses[i].score)
}}}
var query = {"courses.course":/^分布式/};
var proje = {"_id":0, name:1, courses:1};
var curNoSQL = db.students.find(query, proje);
curNoSQL.forEach(getScore)4.2 腳本的執行
我們可以使用Navicat進行直接匯入,這個一個軟體給我們提供的圖形界面,進行操作腳本
互動式命令load(script.js)

注意,windows路徑中包含\,在js中表示轉義符,必須使用 \\ 來表示\字符,
mongo命令

4.3 聚合管道 aggregate
$avg: 求平均值
$sum: 求和
$max: 求最大值
$min: 求最小值
// 按專業取所有學生的平均身高
db.getCollection("students").aggregate([
{$group:{_id:"$major", avgHeight:{$avg:"$height"}}}
])// 按專業求女生平均身高低于170的專業平均身高,并排序
/*
SQL: select AVG(height) as avgHeight, major as _id
from students
where gender=0
group by major
having avgHeight>170
sorted by avgHeight DESC
*/
db.getCollection("students").aggregate([
//第一步,查資料
{$match:{gender:0}}
//第二步,限制回傳欄位
,{$project:{_id:0,major:1, grade:1, class:1, height:1}}
//第三步,分組求平均值
// _id: group by的欄位, 欄位名要加$符號前綴,表示是一個欄位名
// avgHeight: 新生成的平均值欄位名
// $avg: 平均值運算子,它的值為要求平均值的欄位名,注意加$前綴
,{$group:{_id:"$major", avgHeight:{$avg:"$height"}}
//第四步,篩選聚合結果
,{$match:{avgHeight:{$lte:170}}}
//第五步,排序,按照avgHeight的值從大到小排序, -1: DESC, 1:ASC
,{$sort:{avgHeight:-1}}
])/*******************************************************
*示例:按專業-年級-班級-性別 列出全校學生的平均升高
- 使用多個欄位進行分組
*******************************************************/
db.getCollection("students").aggregate([
//第一步,查資料,可以不要,那么對整個集合的資料進行操作
//{$match:{gender:0}},
//第二步,限制回傳欄位,也可以不要,那么回傳所有的欄位
//{$project:{_id:0,major:1, grade:1, class:1, height:1}}
//第三步,分組求平均值,可以以多個欄位聯合作為分組鍵,當多個欄位的值都相等才是一組
{$group:{_id:{專業:"$major", 年級:"$grade", 班級:"$class", 性別:"$gender"},
avgHeight:{$avg:"$height"}}}
//第四步,篩選聚合結果
// ,{$match:{avgHeight:{$lte:170}}}
//第五步,排序,按照avgHeight的值從大到小排序, -1: DESC, 1:ASC
,{$sort:{avgHeight:-1}}
])/*******************************************************
*示例:按專業-年級-班級 分組計算全校分布式資料庫課程的平均分
- 使用變數定義查詢條件和回傳欄位
- 對陣列欄位中的值進行聚合操作
- 使用多個欄位進行分組
- 使用多個欄位進行排序
*******************************************************/
var 查詢條件 = {"courses.course":"分布式資料庫原理與應用"}
var 回傳欄位 = {_id:0, major:1, grade:1, class:1, courses:1}
db.students.aggregate( [
// 第一步,查詢上分布式課程的學生,注意,這里每個學生可能還有別的課程
{$match:查詢條件}
// 第二步,指定回傳的欄位值,這里使用了前面定義的變數
,{$project: 回傳欄位}
// 第三步,由于課程資訊是在一個陣列中,所以先將陣列拆開,將資料拉平
,{$unwind:"$courses"}
// 第四步,對非分布式資料庫的課程資訊進行過濾,只匹配分布式資料庫課程的分數
,{$match:查詢條件}
// 第五步,對分布式資料庫的課程分數進行平均值計算
,{$group: {_id:{"m":"$major","g":"$grade",c:"$class"}, avgScore:
{$avg:"$courses.score"} } }
// 第六步,排序,1: ASE(從小到大,正序), -1: DESC(從大到小,反序)
,{$sort:{"_id.m":1,"_id.g":1, "_id.c":1}}
] )4.4 MongoDB MapReduce
1、基本語法
1)定義MapReduce操作
db.collection.mapReduce(
function() {emit(key,value);}, //map 函式
function(key,values[]) {return reduceFunction}, //reduce 函式
{
out: collection,
query: document,
sort: document,
limit: number
}
)使用 MapReduce 要實作兩個函式 Map 函式和 Reduce 函式,Map 函式呼叫 emit(key, value), 遍
歷 collection 中所有的記錄, 將key 與 value 傳遞給 Reduce 函式進行處理,
Map 函式必須呼叫 emit(key, value) 回傳鍵值對,這個鍵可以是一個常量,也可以是原始檔案中
某個鍵的值
map :映射函式 (生成鍵值對序列,作為 reduce 函式引數),
reduce 統計函式,reduce函式的任務就是將key-values變成key-value,也就是把values數
組變成一個單一的值value,
out 統計結果存放集合 (不指定則使用臨時集合,在客戶端斷開后自動洗掉),
query 一個篩選條件,只有滿足條件的檔案才會呼叫map函式,(query,limit,sort可以隨
意組合)
sort 和limit結合的sort排序引數(也是在發往map函式前給檔案排序),可以優化分組機制
limit 發往map函式的檔案數量的上限(要是沒有limit,單獨使用sort的用處不大)
// mapreduce
// mapper: 采集單元資料鍵值對
var mapper = function(){
// key:group by 的欄位,分組標準
var key = this.major
// value: 要進行聚合計算的欄位
var value = 1
emit(key, value);
// {{grade:2018,gender:1}, 1}
} /
/ map -- conbine+shuffle -> reduce
// {{grade:2018,gender:1}, [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]}
// reducer: 聚合資料, 產生一個單值資料
var reducer = function(key,values){
// key: {grade:2018,gender:1}
// values [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
var result = Array.sum(values)
return result
} /
/ options: 設定輸入輸出
var options = {out:"output", query:{}}
db.students.mapReduce(mapper, reducer, options)
db.output.find()// 求全體學生的平均身高
// map方法將每一個集合中的檔案轉化成如 {"全體學生",171},{"全體學生",171}...的輸出
var mapper=function(){emit("全體學生",this.height)};
// MongoDB內部將進行聚合
// reduce方法得到如{"全體學生",[171,172,173,...]}的輸入,然后對
values[171,172,173,...]陣列進行avg()平均值運算,得到一個value
var reducer=function(key,values){return Array.avg(values)};
// options中我們指定輸出的資料將存入AvgHeight集合
var options={out:"AvgHeight"};
// 使用定義好的mapper,reducer方法和options設定進行mapReduce運算
db.students.mapReduce(map,reduce,options);
// 查詢結果集合AvgHeight
db.AvgHeight.find();// 分專業-年級-班級計算平均身高
// 定義一個mapper方法,從集合中的每一個檔案中提取key-value對
var mapper=function(){
// 構造key,key可以是一個字串,如:"大資料2018-1"
key=this.major+this.grade+"-"+this.class
// 構造key,key可以是一個檔案物件,如:{專業:"大資料",年級:2018,班級:1}
// key = {專業:this.major,年級:this.grade,班級:this.class};
// 構造value,這里要計算身高,所以將height欄位值作為value
value=this.height;
/* 回傳key-value對,如:
{"大資料2018-1":171},{"大資料2018-1":172}, ... ,
{"應數2018-1":170},{"應數2018-1":173},{"應數2018-1":171} ... ,
{"應數2018-2":170},{"應數2018-2":171},{"應數2018-2":172} ... ,
*/
emit(key, value);
}
/* MongoDB將按照key進行資料聚合,得到values陣列
{"大資料2018-1":[171,172,...]},
{"應數2018-1":[170,173,171,...]},
{"應數2018-2":[170,171,172,...]},
...
*/
// 對于每個key的values陣列進行reduce操作,這里我們要用陣列的avg方法對[171,172,...]進行平
均值計算
var reducer=function(key,values){
return Array.avg(values);
}
// options中我們指定輸出的資料將存入AvgHeight集合
var options={out:"AvgHeight"};
// 使用定義好的mapper,reducer方法和options設定進行mapReduce運算
db.students.mapReduce(mapper,reducer,options);
// 查詢結果集合AvgHeight, 可以對結果進行排序
db.AvgHeight.find().sort();4.5 單一功能聚合函式
// 查詢students集合中2019級的學生數量
db.students.count({"grade":2019})
// 查詢students集合中有哪些單獨的課程名
db.students.distinct("courses.course")//任務1:給全校分布式資料庫課程考試班級平均分前三名的班級中每個學生發獎
// (1)求分布式課程的班級平均分
// (2)排序取前三名的班級
// (3)更新前三名班級的學生檔案,增加一個prize欄位
var mapper = function() {
for(var i=0;i<this.courses.length;i++) {
if(this.courses[i].course=="分布式資料庫原理與應用") {
var key = {課程:this.courses[i].course,專業:this.major,年
級:this.grade,班號:this.class};
var value = this.courses[i].score;
emit(key,value);// {課程:"分布式資料庫原理與應用",班級:應用統計2018-2}, 79
}}}
// {課程:"分布式資料庫原理與應用",班級:應用統計2018-2}, [79,87,67,99,......]
var reducer = function(key, values){
return Array.avg(values)
}
// mapreduce結果資料輸出到nosql_avg_score集合
var options = {out:"nosql_avg_score"}
// 執行mapreduce運算
db.students.mapReduce(mapper, reducer, options)
// 查詢mapreduce得到的前三名的班級資訊,將查詢結果放入一個游標
var cursor = db.nosql_avg_score.find().sort({"value":-1}).limit(3)
// 定義一個變數n,記錄游標中的位置,由于游標next方法從第一個開始獲取,而且游標中的資料在前面已經做了sort排序,所以第一條資料就是第一名, 注意,在每一次while回圈結束時,n會增加1
var n=1;
while(cursor.hasNext()){
// 從游標中獲取一條資料
var doc = cursor.next();
// 查詢條件
var querydoc = {major:doc._id.專業, grade:doc._id.年級, class:doc._id.班號}
// 更新條件,設定一個prize欄位,值為“第幾名”
var updatedoc = {$set:{prize:"第"+n+"名"}}
// 執行資料更新
db.students.updateMany(querydoc, updatedoc)
n++; // 回圈題末尾,n自增1
}
// 查詢students表驗證結果
db.students.find({prize:{$type:2}})
db.students.find()// 任務1升級版:給全校每門課程考試班級平均分前三名的班級中每個學生發獎
// (1)求各門課程的班級平均分
// (2)按課程,平均分排序
// (3)遍歷排序后的資料,對每門課程前三名的班級去更新對應的學生資料
// 資料的分片采集: key:{major,grade,class}, value:courses.$.score =>
var mapper = function() {
var cls = {major:this.major, grade:this.grade, class:this.class}
for(var i=0;i<this.courses.length;i++) {
cls.course = this.courses[i].course;
var score = this.courses[i].score;
//print(cls.major, cls.grade, cls.class, score);
emit(cls, score);
}
} // 資料的聚合處理
var reducer = function(cls, scores) {
return Array.avg(scores)
} // 資料的輸入輸出
var options = {out:"avgScore"}
db.avgScore.drop()
db.students.mapReduce(mapper,reducer,options)
// 將已經存在的獎prize洗掉掉, 避免型別錯誤
db.students.updateMany({},{$unset:{"prize":1}});
// 得到按課程和平均分排序的班級串列
var cursor = db.avgScore.find().sort({"_id.course":1,"value":-1})
// 定義個變數n,表示第幾名,由于資料已經按照課程和分數排序,第一個獲取的分數就是第1名
var n = 1;
// 定義2個變數,存放當前處理的資料的課程欄位和上一次處理的課程欄位
var curCourse, lstCourse;
while(cursor.hasNext()) {
var doc = cursor.next();
var query = {"major":doc._id.major, "grade":doc._id.grade,"class":doc._id.class};
// 將當前處理的課程欄位賦值給curCoourse
curCourse = doc._id.course;
// 如果當前處理的欄位和上一次處理的欄位一樣
if(curCourse==lstCourse) {
n+=1;
// 只取前3名,當n小于等于3是,是前三名,更新學生prize陣列
if(n<=3) {
var prizename = curCourse+"第"+n+"名";
var updatedoc = {$push:{prize:prizename}};
db.students.updateMany(query,updatedoc);
}
else //只取前3名,所以n大于3的情況下,這個班級不處理,直接跳過
{
lstCourse = curCourse;
continue;
}
}
else // 如果當前處理的課程curCourse和上一次處理的課程不一樣,要重置名詞變數n,重新取新
課程的前三名
{
n=1;
var prizename = curCourse+"第"+n+"名";
var updatedoc = {$push:{prize:prizename}};
db.students.updateMany(query,updatedoc);
} // 處理一條資料后,將當前處理的課程賦值給lstCourse
lstCourse = curCourse;
}
db.students.find({prize:{$type:2}})
// db.students.find()4.6 匯入與匯出
Navicat 轉儲js腳本 備份資料庫/集合
(1)右鍵點資料庫或者集合
(2)選擇“轉儲腳本檔案” > “結構和資料”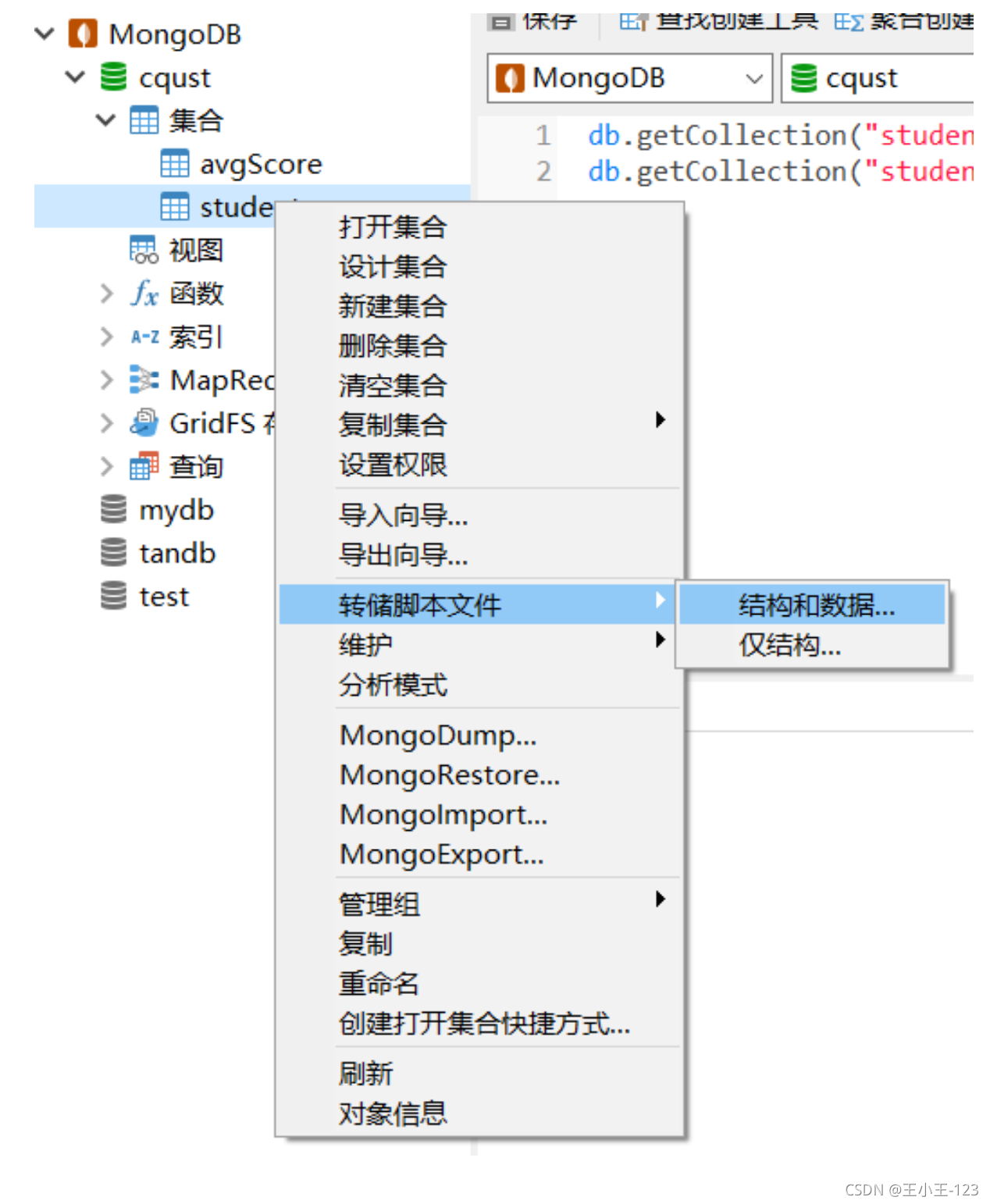
Navicat 執行js腳本 還原資料庫/集合
(1) 右鍵點資料庫
(2) 選擇“運行腳本檔案”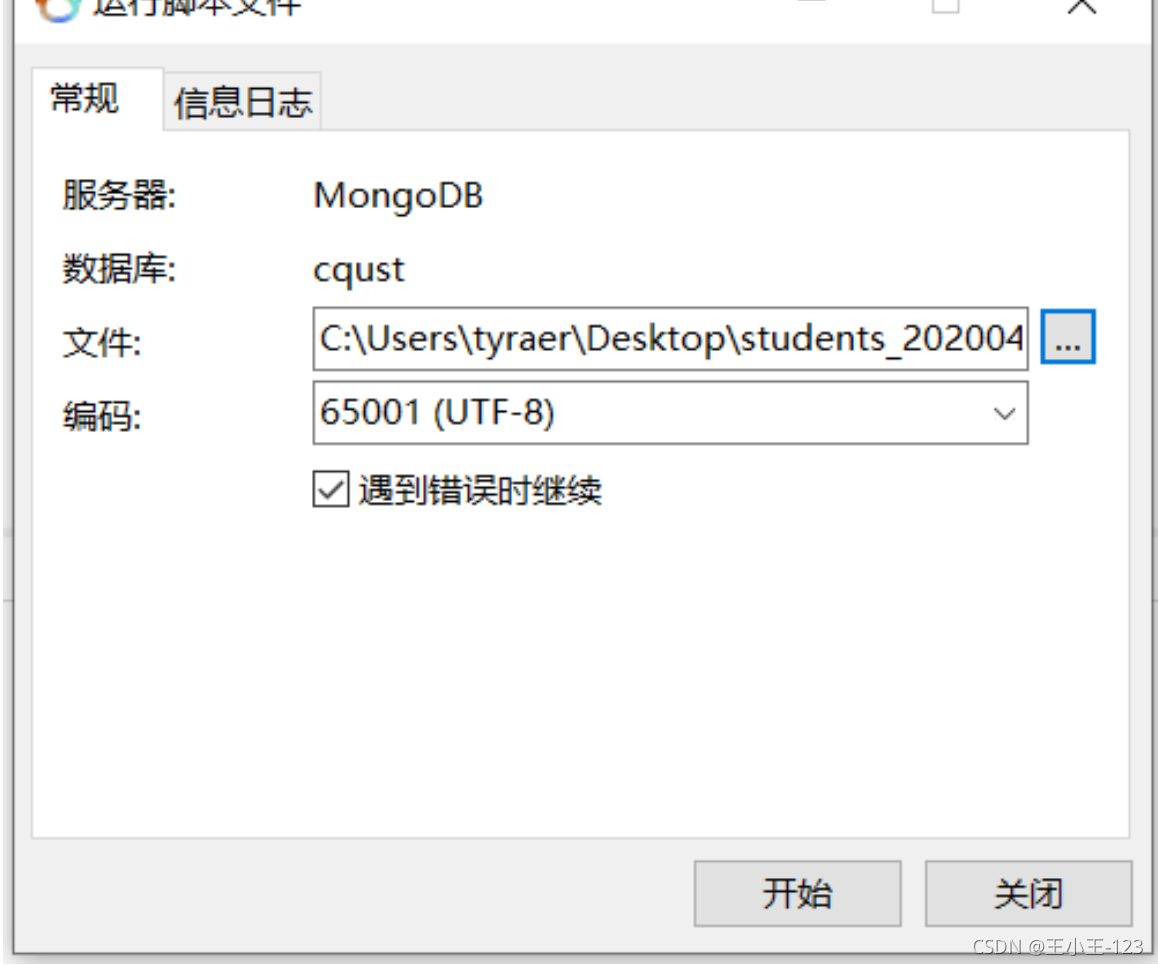
注意:檔案編碼應根據js檔案具體設定,默認UTF-8
Navicat 匯出向導
Navicat 匯入向導
mongoexport
關鍵引數說明:
-h,--host :代表遠程連接的資料庫地址,默認連接本地Mongo資料庫;
--port: 代表遠程連接的資料庫的埠,默認連接的遠程埠27017;
--uri: 使用mongodb:// 連接uri, 如:"mongodb://localhost:27017/cqust"
-u,--username:代表連接遠程資料庫的賬號,如果設定資料庫的認證,需要指定用戶賬號;
-p,--password:代表連接資料庫的賬號對應的密碼;
-d,--db: 代表連接的資料庫;
-c,--collection:代表連接資料庫中的集合;
-f, --fields: 代表集合中的欄位,可以根據設定選擇匯出的欄位;
--type: 代表匯出輸出的檔案型別,包括csv和json檔案;
-o, --out: 代表匯出的檔案名;
-q, --query: 代表查詢條件;
--skip: 跳過指定數量的資料;
--limit: 讀取指定數量的資料記錄;
--sort: 對資料進行排序,可以通過引數指定排序的欄位,并使用 1 和 -1 來指定排序的方式,其中 1 為升序排列,而-1是用于降序排列,如sort({KEY:1}),
當查詢時同時使用sort,skip,limit,無論位置先后,最先執行順序 sort再skip再limit,
# 匯出students集合中全部的資料到JSON檔案
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=json
--out=".\export\students.json"
# 匯出students集合中全部的資料到JSON檔案(jsonArray格式)
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=json
--out=".\export\students.json" --jsonArray
# 使用JSON檔案匯入資料到students_recover集合
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type json --file=".\export\students.json"
# 使用JSON檔案匯入資料到students_recover集合
# 使用upsert mode更新/插入資料
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type json --file=".\export\students.json" --mode=upsert
# 使用JSON檔案匯入資料到students_recover集合(jsonArray格式)
# 使用--drop先洗掉目標集合
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type json --file=".\export\students.json" --jsonArray --drop
# 匯出students集合的指定欄位資料到CSV檔案
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=csv -
-out=".\export\students.csv" -
fields="name,gender,height,phone,role,sno,major,grade,class,courses"
# 匯出students集合的指定欄位(使用欄位檔案,每個欄位寫一行)資料到CSV檔案
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=csv -
-out=".\export\students.csv" --fieldFile="fields.txt"
# 匯入CSV檔案中的資料到students_recover集合(用--drop選項先洗掉目標集合)
# 使用--headerline選項從CSV檔案頭行獲得欄位名
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type csv --file=".\export\students.csv" --headerline --drop
# 匯入CSV檔案中的資料到students_recover集合(用drop選項先洗掉目標集合)
# 使用--columnsHaveTypes選項以指定的JSON資料型別匯入
# 使用--fields選項指定匯入欄位(欄位名.資料型別格式是配合--columnsHaveTypes使用的)
# 使用--parseGrace=skipRow跳過頭行(在資料型別轉換失敗時跳過)
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type csv --file=".\export\students.csv" --
fields="name.string(),gender.string(),height.double(),phone.string(),role.string
(),sno.double(),major.string(),grade.string(),class.string(),courses.auto()" --
parseGrace=skipRow --columnsHaveTypes --drop4.7 備份與恢復
# mongodump 備份資料庫cqust 到當前目錄下的dump目錄(默認)
mongodump --host=localhost:27017 --db=cqust
# mongorestore 從默認備份目錄dump恢復資料
# 不使用--drop:只恢復資料庫中沒有的資料
mongorestore --host=localhost:27017
# 使用--drop:先洗掉原有資料再完全
mongorestore --host=localhost:27017 --drop
# mongodump 備份資料庫cqust的集合students 到cqustdump目錄(指定備份檔案目錄)
mongodump --host=localhost:27017 --db=cqust --collection=students --
out="D:\MongoDB\output\cqust_students_dump"
# --nsInclude=cqust.students <=> --db=cqust --collection=students
mongodump --host=localhost:27017 --nsInclude=cqust.students --
out="D:\MongoDB\output\cqust_students_dump"
# mongorestore 從備份目錄中的BSON檔案恢復集合students的資料(使用--drop先洗掉集合再恢復)
mongorestore --host=localhost:27017 --nsInclude=cqust.students --
dir="D:\MongoDB\output\cqustdump\cqust\students.bson" --drop
mongorestore --host=localhost:27017 --db=cqust --collection=students --
dir="D:\MongoDB\output\cqustdump\cqust\students.bson.gz" --gzip --drop
# mongodump 備份資料庫cqust的集合students 到一個存檔檔案
mongodump --host=localhost:27017 --db=cqust --collection=students --
archive="D:\MongoDB\output\cqust-students.dump"
# mongorestore 從存檔檔案中恢復資料(使用--drop先洗掉集合再恢復)
mongorestore --host=localhost:27017 --archive="D:\MongoDB\output\cquststudents.dump" --drop
# mongorestore 從存檔檔案中恢復cqust資料庫students集合的資料到資料庫cqust的recover集合中
mongorestore --host=localhost:27017 --archive="D:\MongoDB\output\cquststudents.dump" --nsInclude=cqust.students --nsFrom=cqust.students --
nsTo=cqust.recover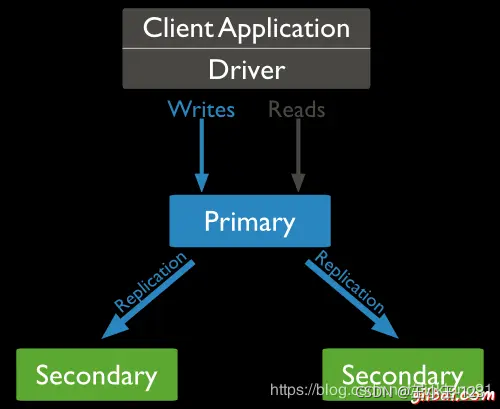
其實到了這一步,我們應該也就了解到了,我們的MongoDB的基本的操作語法,但是如果你是初學者,我建議你先看完上面的全部的語法案例和詳解,有利于學習和夯實MongoDB的基礎,至于我們的實際運用,如何去真正的增刪改查,后面的文章我會給出比較詳細的案例的!
每文一語
喜歡毫無理由
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/309551.html
標籤:其他