文章目錄
- 一、必看內容!!!
- 1)簡短介紹
- 2)必備知識
- 3)為什么我要寫這篇文章?
- 4)強烈推薦教程專欄
- 二、開始使用xpath
- 2.1 常見的 HTML 操作
- 2.2 常見XML操作
- 2.2.1 選擇一個元素
- 2.2.2 選擇文字
- 2.3 瀏覽器使用xpath除錯
- 2.3.1演示案例一
- 三、檢查節點是否存在
- 3.1 案例一
- 3.2 案例二
- 四、檢查節點的文本是否為空
- 4.1 案例一
- 4.2 案例二
- 五、通過屬性查詢
- 5.1 查找具有特定屬性的節點
- 5.2 通過屬性值的子串匹配來查找節點
- 5.3 通過屬性值的子字串匹配查找節點(不區分大小寫)
- 5.4 通過匹配屬性值末尾的子字串查找節點
- 5.5 通過匹配屬性值開頭的子字串查找節點
- 5.6 查找具有特定屬性值的節點
- 六、查找包含特定屬性的元素
- 6.1 查找具有特定屬性的所有元素(1)
- 6.2 查找具有特定屬性值的所有元素(2)
- 七、查找包含特定文本的元素
- 八、多次強調的語法
- 8.1 XPath 軸的語法
- 8.2 XPath選取節點語法
- 8.3 Xpath謂語
- 8.4 Xpath選取未知節點
- 8.5 Xpath選取若干路徑
- 九、獲取相對于當前節點的節點
- 9.1 基本語法
- 9.2 尋找祖先節點
- 9.4 尋找兄弟節點
- 9.5 尋找祖父節點(2)
- 9.6 尋找父母節點
- 9.7 尋找當前節點之后的所有節點
- 9.8 尋找當前節點之前的所有節點
- 9.9 實體一
- 9.10 實體二
- 十、獲取節點數
- 10.1 實體一
- 10.2 實體二
- 十一、根據子節點數選擇節點
- 11.1 實體一
- 11.2 實體二
- 十二、選擇名稱等于或包含某個字串的節點
- 12.1 搜索名稱包含 Light 的節點
- 12.2 搜索名稱以 Ball 結尾的節點
- 12.3 搜索名稱以 Star 開頭的節點
- 12.4 搜索名稱為 Light、Device 或 Sensor 的節點
- 12.5 搜索名稱為 light 的節點(不區分大小寫)
- 12.6 搜索名稱為 light 的節點(不區分大小寫)
- 十三、實戰演練(城市二手房價爬取)
- 十四、實戰演練(虎牙美女直播爬取)
- 十三、粉絲福利
- 十四、總結
一、必看內容!!!
1)簡短介紹
XPath 是一種用于尋址 XML 檔案部分的語言,它在 XSLT 中使用并且是 XQuery 的子集,這個庫也可用于大多數其他編程語言,
2)必備知識
- 了解基本的html和xml語法和格式
- 沒有了,如果你不會html和xml,超過2000收藏,我出一篇html詳細教程,至于怎么達到2000贊,看各位粉絲了,
3)為什么我要寫這篇文章?
在我前面的幾十篇文章,寫了上百萬字把python的所有基礎已經講得很明白了,不管你是不是小白,跟著學都能學會,同時在我的粉絲群,我還會對教程中的問題進行答疑,所以包教包會的口號,我從來不是吹的,
這里是我的基礎教程專欄:python全堆疊基礎詳細教程專欄系列
當然,如果你對qq機器人制作感興趣請查看專欄:qq機器人制作詳細教程專欄
這兩個專欄,我為什么放在一起?第一個專欄是基礎教程,第二個專欄是進階,所以你在不會基礎之前,請不要冒然學習機器人制作,
說了半天,我還沒說為什么寫這一篇的原因,前面的基礎我已經差不多寫完了,基礎不會的自己去看我專欄,上百萬字寫基礎,我已經很用心教大家了,基礎過后,我們即將開始學爬蟲,因此xpath你不得不掌握,認真跟著我學,多看幾天就會了,
4)強烈推薦教程專欄
- python全堆疊基礎教程系列
- qq機器人小白教程系列
- matlab數學建模小白到精通系列
- Linux作業系統教程
- SQL入門到精通教程系列
其它專欄,看你自己個人興趣,這五個專欄我是主打,并是我強烈推薦,
二、開始使用xpath
2.1 常見的 HTML 操作
如果有一段html如下:
<html>
<body>
<a>link</a>
<div class='container' id='divone'>
<p class='common' id='enclosedone'>Element One</p>
<p class='common' id='enclosedtwo'>Element Two</p>
</div>
</body>
</html>
在整個頁面中查找具有特定 id 的元素:
//*[@id='divone'] # 回傳 <div class='container' id='divone'>
在特定路徑中查找具有特定 id 的元素:
/html/body/div/p[@id='enclosedone'] # 回傳 <p class='common' id='enclosedone'>Element One</p>
選擇具有特定 id 和 class 的元素:
//p[@id='enclosedone' and @class='common'] #回傳 <p class='common' id='enclosedone'>Element One</p>
選擇特定元素的文本:
//*[@id='enclosedone']/text() # 回傳 Element One
2.2 常見XML操作
比如有如下xml:
<r>
<e a="1"/>
<f a="2" b="1">Text 1</f>
<f/>
<g>
<i c="2">Text 2</i>
Text 3
<j>Text 4</j>
</g>
</r>
2.2.1 選擇一個元素
用xpath
/r/e
將選擇此元素:
<e a="1"/>
2.2.2 選擇文字
用xpath:
/r/f/text()
將選擇具有此字串值的文本節點:
"Text 1"
而這個 XPath:
string(/r/f)
回傳同樣是:
"Text 1"
2.3 瀏覽器使用xpath除錯
步驟如下:
- 按F12進入控制臺
- 按ctrl+F進入搜索框
- 將自己寫的xpath輸入進去,回車看看能不能匹配到
2.3.1演示案例一
以我自己的主頁網址為例:
https://blog.csdn.net/weixin_46211269?spm=1000.2115.3001.5343
分析:
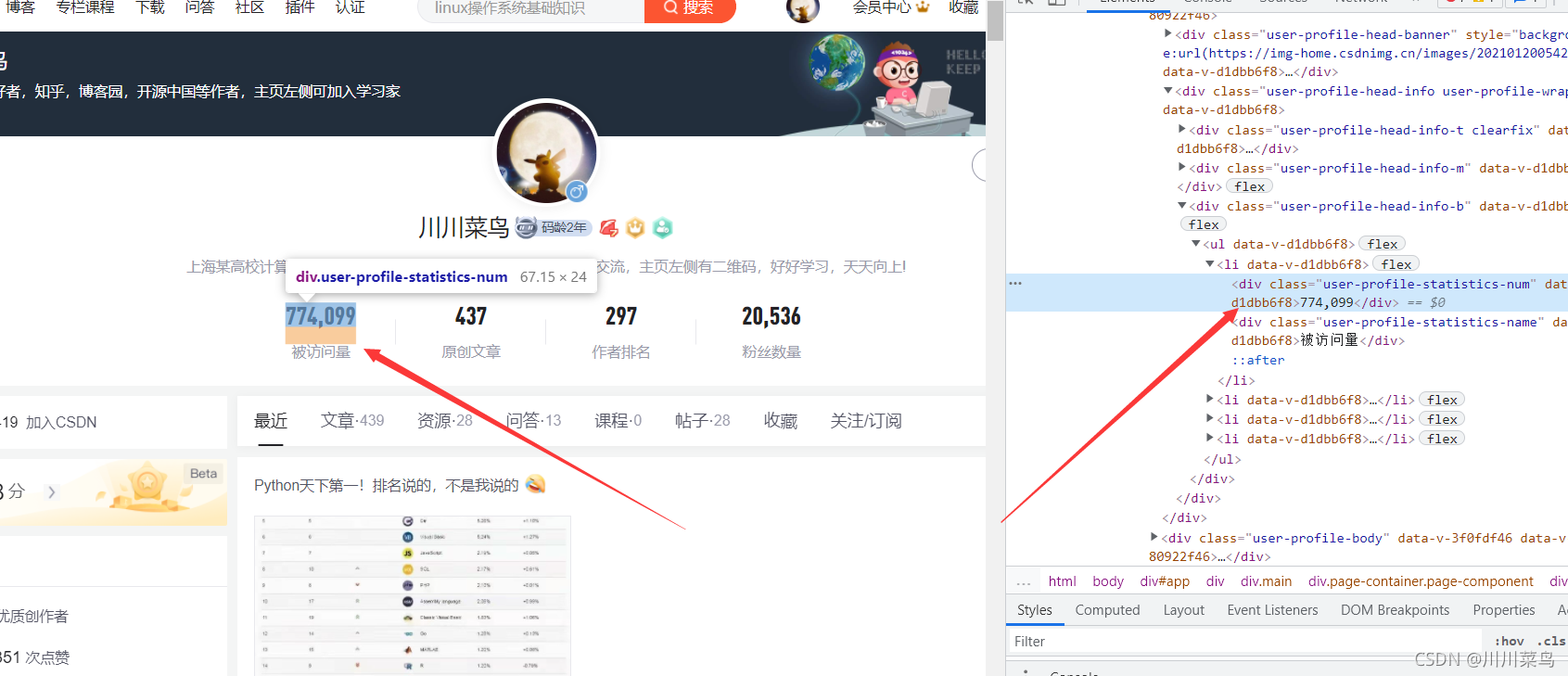
鎖定定位為:
user-profile-statistics-num
則xpath寫為:
//div[@class="user-profile-statistics-num"]
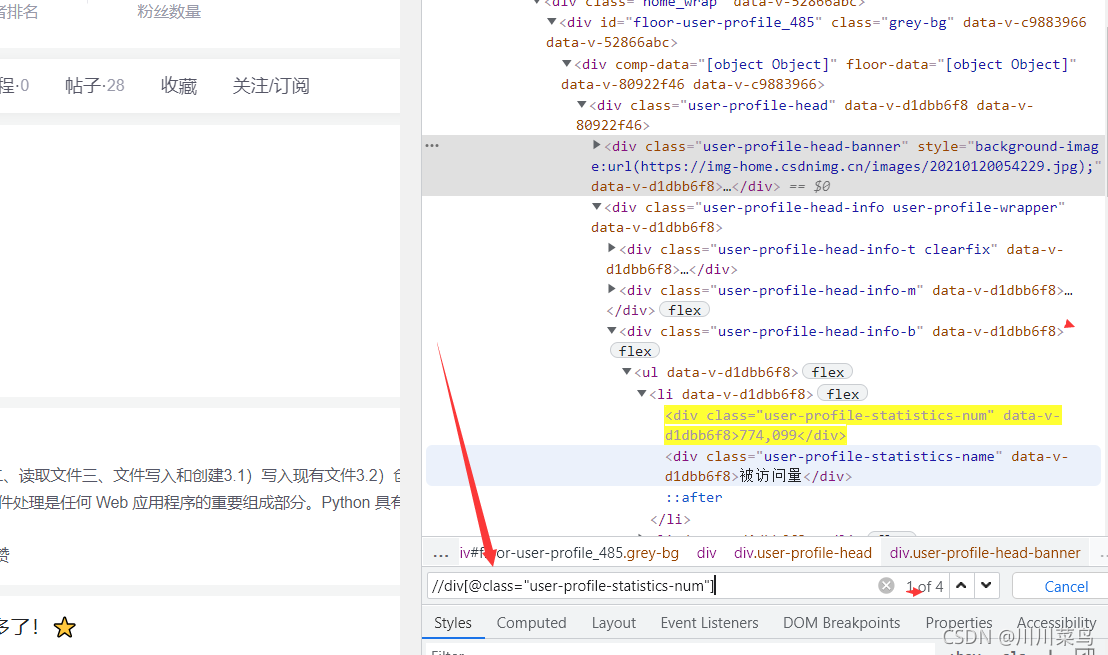
以上就是一種簡單的除錯xpath方法,難的我就不介紹了,沒必要吧,如果大家覺得有必要,評論區留言,人多我就重新編輯補充,
三、檢查節點是否存在
我們使用布爾來檢查我們寫的xpath是否存在,布爾真是一個很不錯的東西,
3.1 案例一
這里我就構造一個xml如下:
<House>
<LivingRoom>
<plant name="rose"/>
</LivingRoom>
<TerraceGarden>
<plant name="passion fruit"/>
<plant name="lily"/>
<plant name="golden duranta"/>
</TerraceGarden>
</House>
使用布爾來判斷:
boolean(/House//plant)
輸出:
true
說明該路徑正確,
3.2 案例二
假設有這樣一個xml:
<Animal>
<legs>4</legs>
<eyes>2</eyes>
<horns>2</horns>
<tail>1</tail>
</Animal>
使用布爾判斷:
boolean(/Animal/tusks)
輸出:
false
說明這個路徑是錯的,
四、檢查節點的文本是否為空
語法:
- 布爾(路徑到節點/文本())
- 字串(路徑節點)!= ‘’ ”
其他用途:
- 檢查節點是否存在
- 檢查引數是否不是數字 (NaN) 或 0
4.1 案例一
假設我構造這樣一個xml:
<Deborah>
<address>Dark world</address>
<master>Babadi</master>
<ID>#0</ID>
<colour>red</colour>
<side>evil</side>
</Deborah>
用布爾判斷:
boolean(/Deborah/master/text())
或者用string判斷:
string(/Deborah/master) != ''
輸出都為:
true
說明文本不為空,
4.2 案例二
假設我構造這樣一個xml:
<Dobby>
<address>Hogwartz</address>
<master></master>
<colour>wheatish</colour>
<side>all good</side>
</Dobby>
用布爾判斷:
boolean(/Dobby/master/text())
或者用string判斷:
string(/Dobby/master) != ''
輸出:
false
說明文本為空,
五、通過屬性查詢
說一些比較常見的語法:
- /從當前節點選取直接子節點
- //從當前節點選取子孫節點
- .選取當前節點
- …選取當前節點的父節點
- @選取屬性
- *代表所有
例如:
//title[@lang=’chuan’]
這就是一個 XPath 規則,它就代表選擇所有名稱為 title,同時屬性 lang 的值為 chuan的節點,
5.1 查找具有特定屬性的節點
假設有這樣一個xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路徑匹配如下:
/Galaxy/*[@name]
或者:
//*[@name]
輸出:
<CelestialObject name="Earth" type="planet" />
<CelestialObject name="Sun" type="star" />
5.2 通過屬性值的子串匹配來查找節點
假設有如下例子:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路徑:
/Galaxy/*[contains(@name,'Ear')]
值得補充的是,這里的contains函式就是代表包含的意思,這里就是查找Galaxy路徑下,所有name屬性中含有Ear的節點,
如上,我們也可以如下方式匹配:
//*[contains(@name,'Ear')]
雙引號也可以用來代替單引號:
/Galaxy/*[contains(@name, "Ear")]
輸出:
<CelestialObject name="Earth" type="planet" />
5.3 通過屬性值的子字串匹配查找節點(不區分大小寫)
假設有xml如下:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路徑
/Galaxy/*[contains(lower-case(@name),'ear')]
這里又出現了新的東西,加入 lower-case() 函式就是來保證我們可以包括所有的大小寫情況,
路徑
/Galaxy/*[contains(lower-case(@name),'ear')]
或者
//*[contains(lower-case(@name),'ear')]
或者,使用雙引號中的字串:
//*[contains(lower-case(@name), "ear")]
輸出
<CelestialObject name="Earth" type="planet" />
5.4 通過匹配屬性值末尾的子字串查找節點
假設有xml如下:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路徑
/Galaxy/*[ends-with(lower-case(@type),'tar')]
補充:這里又出現了新的函式,ends-with就是匹配以xx結尾,
或者
//*[ends-with(lower-case(@type),'tar')]
輸出
<CelestialObject name="Sun" type="star" />
5.5 通過匹配屬性值開頭的子字串查找節點
假設有這個xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路徑
/Galaxy/*[starts-with(lower-case(@name),'ear')]
補充:這里又出現了新的函式,starts-with就是匹配以什么開頭,
或者
//*[starts-with(lower-case(@name),'ear')]
輸出
<CelestialObject name="Earth" type="planet" />
5.6 查找具有特定屬性值的節點
假設有這個xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路徑
/Galaxy/*[@name='Sun']
補充:這里就是我開頭說到的,星號代表所有,@用來選取屬性
或者
//*[@name='Sun']
輸出
<CelestialObject name="Sun" type="star" />
六、查找包含特定屬性的元素
6.1 查找具有特定屬性的所有元素(1)
假設有xml如下:
<root>
<element foobar="hello_world" />
<element example="this is one!" />
</root>
xpath匹配:
/root/element[@foobar]
回傳:
<element foobar="hello_world" />
6.2 查找具有特定屬性值的所有元素(2)
假設有xml如下:
<root>
<element foobar="hello_world" />
<element example="this is one!" />
</root>
以下 XPath 運算式:
/root/element[@foobar = 'hello_world']
將回傳
<element foobar="hello_world" />
也可以使用雙引號:
/root/element[@foobar="hello_world"]
粉絲群:970353786
七、查找包含特定文本的元素
假設有xml如下:
<root>
<element>hello</element>
<another>
hello
</another>
<example>Hello, <nested> I am an example </nested>.</example>
</root>
以下 XPath 運算式:
//*[text() = 'hello']
將回傳<element>hello</element>元素,但不回傳元素,這是因為該<another>元素包含hello文本周圍的空格,
要同時檢索<element>and <another>,可以使用:
//*[normalize-space(text()) = 'hello']
補充:這里又多了新的函式,normalize-space作用就是去除空白的意思,
要查找包含特定文本的元素,您可以使用該contains函式,以下運算式將回傳<example>元素:
//example[contains(text(), 'Hello')]
如果要查找跨越多個子/文本節點的文本,則可以使用.代替text(),.指元素及其子元素的整個文本內容,
例如:
//example[. = 'Hello, I am an example .']
要查看多個文本節點,您可以使用:
//example//text()
這將回傳:
- “hello, ”
- “I am an example”
- “.”
為了更清楚地看到一個元素的整個文本內容,可以使用該string函式:
string(//example[1])
要不就
string(//example)
依然回傳:
Hello, I am an example .
八、多次強調的語法
8.1 XPath 軸的語法
現在我們要補充新的東西,又要開始記住了:
ancestor 選取當前節點的所有先輩(父、祖父等),
ancestor-or-self 選取當前節點的所有先輩(父、祖父等)以及當前節點本身,
attribute 選取當前節點的所有屬性,
child 選取當前節點的所有子元素,
descendant 選取當前節點的所有后代元素(子、孫等),
descendant-or-self 選取當前節點的所有后代元素(子、孫等)以及當前節點本身,
following 選取檔案中當前節點的結束標簽之后的所有節點,
namespace 選取當前節點的所有命名空間節點,
parent 選取當前節點的父節點,
preceding 選取檔案中當前節點的開始標簽之前的所有節點,
preceding-sibling 選取當前節點之前的所有同級節點,
self 選取當前節點,
8.2 XPath選取節點語法
為什么我在這里又來強調一下?因為很重要!
nodename 選取此節點的所有子節點,
/ 從根節點選取,
// 從匹配選擇的當前節點選擇檔案中的節點,而不考慮它們的位置,
. 選取當前節點,
.. 選取當前節點的父節點,
@ 選取屬性,
在下面的表格中,列出了一些路徑運算式以及運算式的結果:
bookstore 選取 bookstore 元素的所有子節點,
/bookstore 選取根元素 bookstore, 注釋:假如路徑起始于正斜杠( / ),則此路徑始終代表到某元素的絕對路徑!
bookstore/book 選取屬于 bookstore 的子元素的所有 book 元素,
//book 選取所有 book 子元素,而不管它們在檔案中的位置,
bookstore//book 選擇屬于 bookstore 元素的后代的所有 book 元素,而不管它們位于 bookstore 之下的什么位置,
//@lang 選取名為 lang 的所有屬性,
8.3 Xpath謂語
謂語用來查找某個特定的節點或者包含某個指定的值的節點,謂語被嵌在方括號中,
看一些例子就知道了:
路徑運算式 結果
/bookstore/book[1] 選取屬于 bookstore 子元素的第一個 book 元素,
/bookstore/book[last()] 選取屬于 bookstore 子元素的最后一個 book 元素,
/bookstore/book[last()-1] 選取屬于 bookstore 子元素的倒數第二個 book 元素,
/bookstore/book[position()<3] 選取最前面的兩個屬于 bookstore 元素的子元素的 book 元素,
//title[@lang] 選取所有擁有名為 lang 的屬性的 title 元素,
//title[@lang='eng'] 選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性,
/bookstore/book[price>35.00] 選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大于 35.00,
/bookstore/book[price>35.00]/title 選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大于 35.00,
8.4 Xpath選取未知節點
XPath 通配符可用來選取未知的 XML 元素,
通配符 描述
* 匹配任何元素節點,
@* 匹配任何屬性節點,
node() 匹配任何型別的節點,
在下面的表格中,我們列出了一些路徑運算式,以及這些運算式的結果:
路徑運算式 結果
/bookstore/* 選取 bookstore 元素的所有子元素,
//* 選取檔案中的所有元素,
//title[@*] 選取所有帶有屬性的 title 元素,
8.5 Xpath選取若干路徑
通過在路徑運算式中使用“|”運算子,您可以選取若干個路徑,
在下面的表格中,列出了一些路徑運算式,以及這些運算式的結果:
路徑運算式 結果
//book/title | //book/price 選取 book 元素的所有 title 和 price 元素,
//title | //price 選取檔案中的所有 title 和 price 元素,
/bookstore/book/title | //price 選取屬于 bookstore 元素的 book 元素的所有 title 元素,以及檔案中所有的 price 元素,
九、獲取相對于當前節點的節點
假設我們有xml如下:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
9.1 基本語法
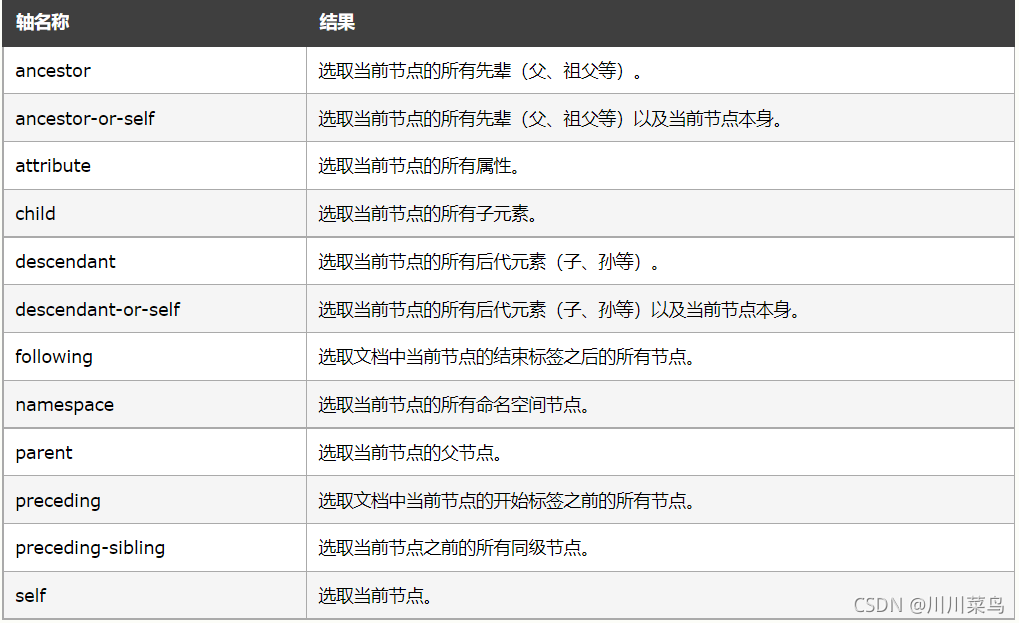
其實這些內容,大可不必都掌握,但是你一定要知道,你想用的時候,再來本文查一下會用就行,
這是相關實體:
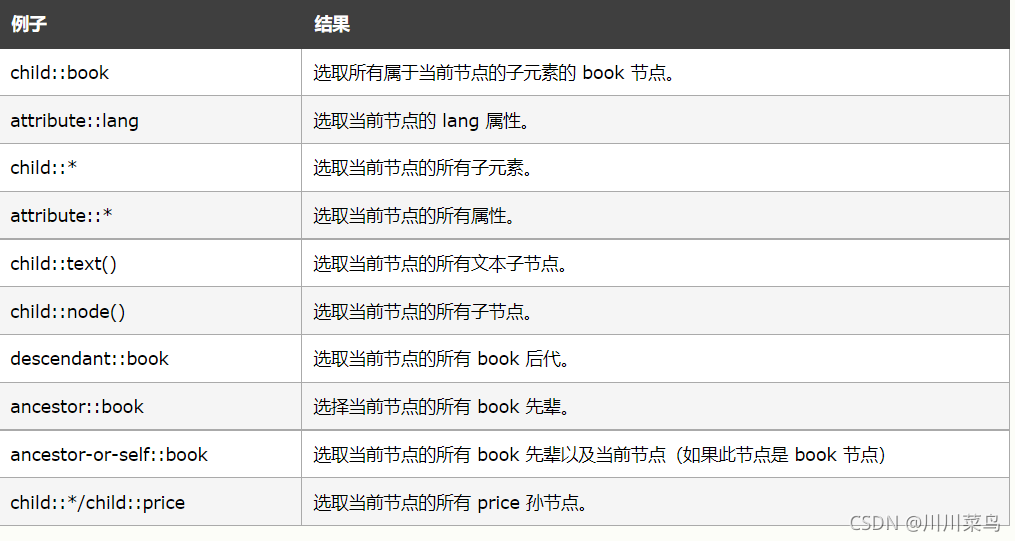
問題是:這里提到的祖先,孩子,兄弟,父母節點,大家知道嗎?如果你會html的話,你應該知道,超過2000贊我可以出一篇html的教程,本篇我就暫時默認大家知道了,
9.2 尋找祖先節點
假設有xml如下:(這里已經很形象說明了祖先,孩子,兄弟,父母節點的關系了,仔細看看)
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male"/>
<brother name="Goten" gender="male"/>
</Dad>
</GrandFather>
路徑
//Me/ancestor::node()
輸出:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
9.4 尋找兄弟節點
假設有xml如下:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<brother name="Goten" gender="male" />
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
路徑:
//Me/following-sibling::brother
輸出:
<brother name="Goten" gender="male" />
9.5 尋找祖父節點(2)
假設有xml如下:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
路徑
//Me/ancestor::GrandFather
或者
//Me/parent::node()/parent::node()
輸出:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
9.6 尋找父母節點
還是假設xml如下:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male"/>
<brother name="Goten" gender="male"/>
</Dad>
</GrandFather>
路徑
//Me/ancestor::Dad
或者
//Me/parent::node()
輸出:
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
9.7 尋找當前節點之后的所有節點
假設有xml如下:
<Dashavatar>
<Avatar name="Matsya"/>
<Avatar name="Kurma"/>
<Avatar name="Varaha"/>
<Avatar name="Narasimha"/>
<Avatar name="Vamana"/>
<Avatar name="Balabhadra"/>
<Avatar name="Parashurama"/>
<Avatar name="Rama"/>
<Avatar name="Krishna"/>
<Avatar name="Kalki"/>
</Dashavatar>
路徑
//Avatar[@name='Parashurama']/following-sibling::node()
輸出:
<Avatar name="Rama" />
<Avatar name="Krishna" />
<Avatar name="Kalki" />
9.8 尋找當前節點之前的所有節點
假設有xml如下:
<Dashavatar>
<Avatar name="Matsya"/>
<Avatar name="Kurma"/>
<Avatar name="Varaha"/>
<Avatar name="Narasimha"/>
<Avatar name="Vamana"/>
<Avatar name="Balabhadra"/>
<Avatar name="Parashurama"/>
<Avatar name="Rama"/>
<Avatar name="Krishna"/>
<Avatar name="Kalki"/>
</Dashavatar>
路徑
//Avatar[@name='Parashurama']/preceding-sibling::node()
輸出:
<Avatar name="Matsya"/>
<Avatar name="Kurma"/>
<Avatar name="Varaha"/>
<Avatar name="Narasimha"/>
<Avatar name="Vamana"/>
<Avatar name="Balabhadra"/>
9.9 實體一
獲取 House 中的所有房間名為 Room 的孩子,
假設有xml如下:
<House>
<numRooms>4</numRooms>
<Room name="living"/>
<Room name="master bedroom"/>
<Room name="kids' bedroom"/>
<Room name="kitchen"/>
</House>
路徑
/House/child::Room
或者
/House/*[local-name()='Room']
輸出:
<Room name="living" />
<Room name="master bedroom" />
<Room name="kids' bedroom" />
<Room name="kitchen" />
9.10 實體二
獲得 House 中的所有房間(不考慮位置),
假設有xml如下:
<House>
<numRooms>4</numRooms>
<Floor number="1">
<Room name="living"/>
<Room name="kitchen"/>
</Floor>
<Floor number="2">
<Room name="master bedroom"/>
<Room name="kids' bedroom"/>
</Floor>
</House>
路徑
/House/descendant::Room
輸出
<Room name="living" />
<Room name="kitchen" />
<Room name="master bedroom" />
<Room name="kids' bedroom" />
十、獲取節點數
我們主要用到count函式,實戰中我們來感悟,
10.1 實體一
假設有xml如下:
<Goku>
<child name="Gohan"/>
<child name="Goten"/>
</Goku>
路徑
count(/Goku/child)
輸出
2.0
10.2 實體二
假設有如下xml
<House>
<LivingRoom>
<plant name="rose"/>
</LivingRoom>
<TerraceGarden>
<plant name="passion fruit"/>
<plant name="lily"/>
<plant name="golden duranta"/>
</TerraceGarden>
</House>
路徑
count(/House//plant)
輸出
4.0
十一、根據子節點數選擇節點
11.1 實體一
假設有xml如下:
<Students>
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
<Student>
<Name>
<First>Bill</First>
<Last>Edwards</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
</Grades>
</Student>
</Students>
選擇至少記錄了 2 個成績的所有學生
//Student[count(./Grades/*) > 1]
輸出
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
11.2 實體二
假設有xml如下:
<Students>
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
<Student>
<Name>
<First>Bill</First>
<Last>Edwards</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
</Grades>
</Student>
</Students>
選擇所有記錄了 Exam2 分數的學生
//Student[./Grades/Exam2]
或者
//Student[.//Exam2]
輸出
<Student>
<Name>
<First>Ashley</First>
<Last>Smith</Last>
</Name>
<Grades>
<Exam1>A</Exam1>
<Exam2>B</Exam2>
<Final>A</Final>
</Grades>
</Student>
十二、選擇名稱等于或包含某個字串的節點
語法如下:
1.在特定節點內:
{path-to-parent}/name()='搜索字串']
2.檔案中的任何位置:
//*[name()='搜索字串']
12.1 搜索名稱包含 Light 的節點
假設有xml如下:
<Data>
<BioLight>
<name>Firefly</name>
<model>Insect</model>
</BioLight>
<ArtificialLight>
<name>Fire</name>
<model>Natural element</model>
<source>flint</source>
</ArtificialLight>
<SolarLight>
<name>Sun</name>
<model>Star</model>
<source>helium</source>
</SolarLight>
</Data>
路徑
/Data/*[contains(local-name(),"Light")]
或者
//*[contains(local-name(),"Light")]
輸出:
<BioLight>
<name>Firefly</name>
<model>Insect</model>
</BioLight>
<ArtificialLight>
<name>Fire</name>
<model>Natural element</model>
<source>flint</source>
</ArtificialLight>
<SolarLight>
<name>Sun</name>
<model>Star</model>
<source>helium</source>
</SolarLight>
12.2 搜索名稱以 Ball 結尾的節點
假設xml如下:
<College>
<FootBall>
<Members>20</Members>
<Coach>Archie Theron</Coach>
<Name>Wild cats</Name>
<StarPlayer>David Perry</StarPlayer>
</FootBall>
<VolleyBall>
<Members>24</Members>
<Coach>Tim Jose</Coach>
<Name>Avengers</Name>
<StarPlayer>Lindsay Rowen</StarPlayer>
</VolleyBall>
<FoosBall>
<Members>22</Members>
<Coach>Rahul Mehra</Coach>
<Name>Playerz</Name>
<StarPlayer>Amanda Ren</StarPlayer>
</FoosBall>
</College>
路徑
/College/*[ends-with(local-name(),"Ball")]
或者
//*[ends-with(local-name(),"Ball")]
輸出:
<FootBall>
<Members>20</Members>
<Coach>Archie Theron</Coach>
<Name>Wild cats</Name>
<StarPlayer>David Perry</StarPlayer>
</FootBall>
<VolleyBall>
<Members>24</Members>
<Coach>Tim Jose</Coach>
<Name>Avengers</Name>
<StarPlayer>Lindsay Rowen</StarPlayer>
</VolleyBall>
<FoosBall>
<Members>22</Members>
<Coach>Rahul Mehra</Coach>
<Name>Playerz</Name>
<StarPlayer>Amanda Ren</StarPlayer>
</FoosBall>
12.3 搜索名稱以 Star 開頭的節點
假設xml如下:
<College>
<FootBall>
<Members>20</Members>
<Coach>Archie Theron</Coach>
<Name>Wild cats</Name>
<StarFootballer>David Perry</StarFootballer>
</FootBall>
<Academics>
<Members>100</Members>
<Teacher>Tim Jose</Teacher>
<Class>VII</Class>
<StarPerformer>Lindsay Rowen</StarPerformer>
</Academics>
</College>
路徑
/College/*/*[starts-with(local-name(),"Star")]
或者
//*[starts-with(local-name(),"Star")]
輸出
<StarFootballer>David Perry</StarFootballer>
<StarPerformer>Lindsay Rowen</StarPerformer>
12.4 搜索名稱為 Light、Device 或 Sensor 的節點
假設xml如下:
<Galaxy>
<Light>sun</Light>
<Device>satellite</Device>
<Sensor>human</Sensor>
<Name>Milky Way</Name>
</Galaxy>
路徑
/Galaxy/*[local-name()='Light' or local-name()='Device' or local-name()='Sensor']
說白了就是多了幾個or而已,
或者
//*[local-name()='Light' or local-name()='Device' or local-name()='Sensor']
輸出
<Light>sun</Light>
<Device>satellite</Device>
<Sensor>human</Sensor>
12.5 搜索名稱為 light 的節點(不區分大小寫)
假設xml如下:
<Galaxy>
<Light>sun</Light>
<Device>satellite</Device>
<Sensor>human</Sensor>
<Name>Milky Way</Name>
</Galaxy>
路徑
/Galaxy/*[lower-case(local-name())="light"]
或者
//*[lower-case(local-name())="light"]
輸出
<Light>sun</Light>
12.6 搜索名稱為 light 的節點(不區分大小寫)
假設xml如下:
<Galaxy>
<Light>sun</Light>
<Device>satellite</Device>
<Sensor>human</Sensor>
<Name>Milky Way</Name>
</Galaxy>
路徑
/Galaxy/*[lower-case(local-name())="light"]
或者
//*[lower-case(local-name())="light"]
輸出
<Light>sun</Light>
十三、實戰演練(城市二手房價爬取)
有部分內容比如requests模塊和lxml模塊,我還沒有細講,如果你有一點基礎,能夠看懂,后續我會講解模塊的具體使用方法,在此如果你實在看不懂,可以三連支持我文章一下,有動力我才會繼續出新文講解,
分析如下:
(第一步找總體)
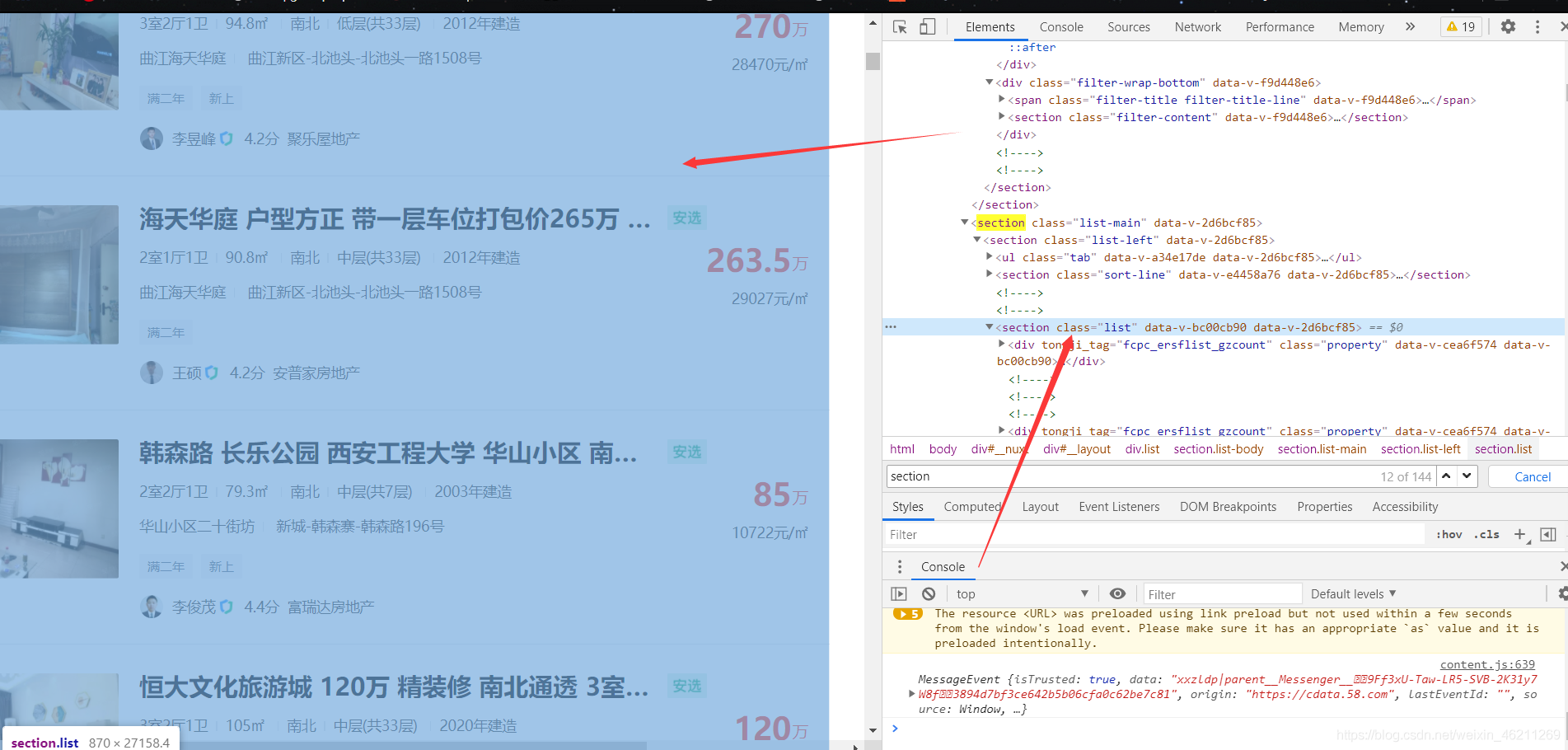
第二步看單個:
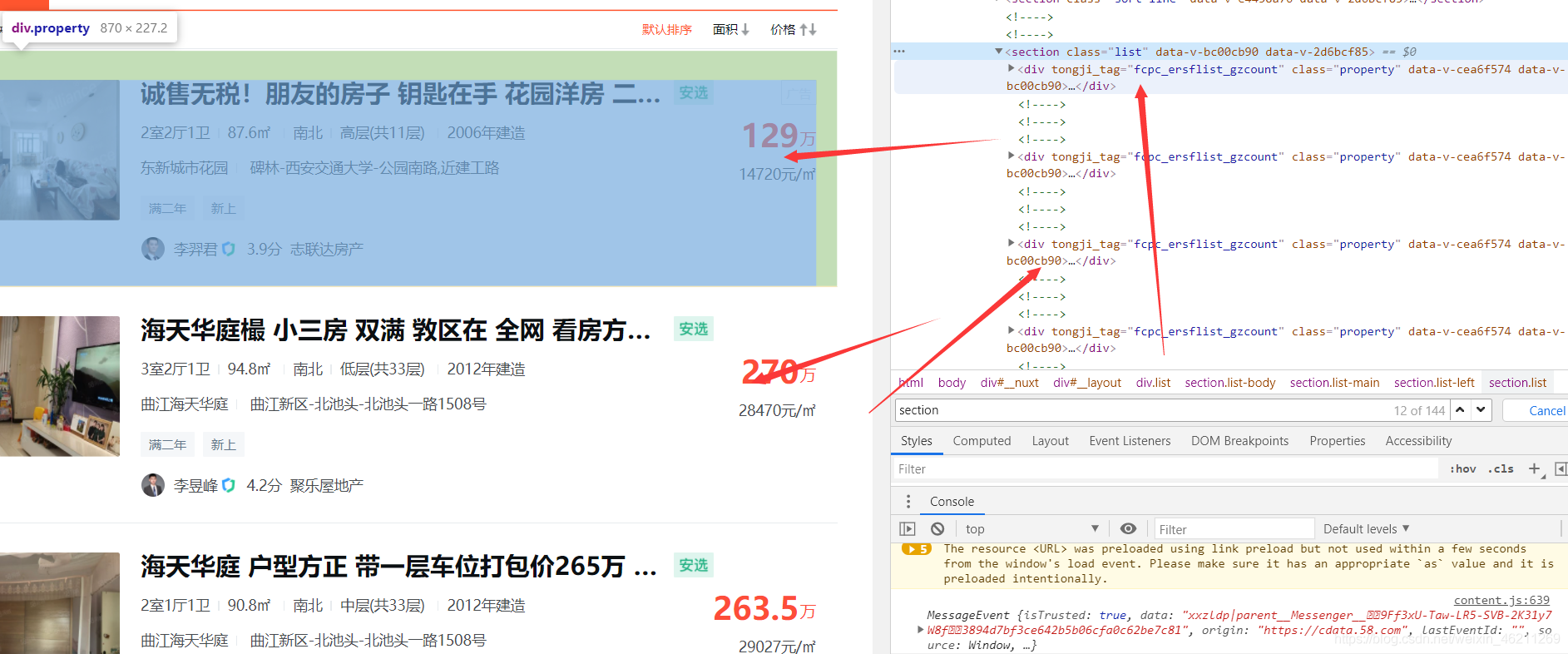
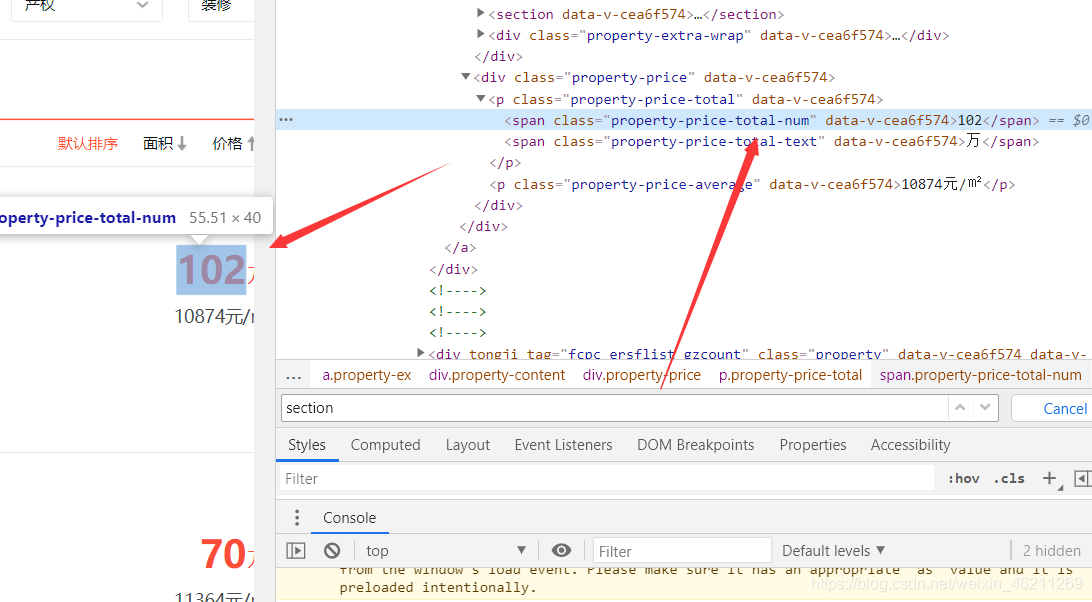
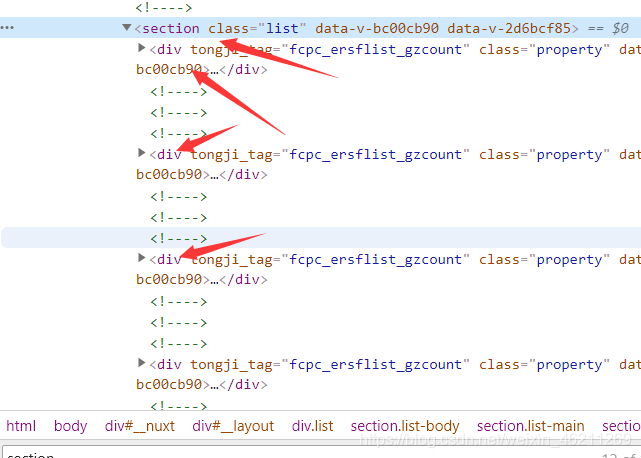
(找規律)可遍歷:
#coding=utf-8
"""
作者:川川
時間:2021/6/26
"""
from lxml import etree
import requests
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
url = 'https://xa.58.com/ershoufang/?q=%E4%B8%8A%E6%B5%B7'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
div_list = tree.xpath('//section[@class="list"]/div')
print(div_list)
fp = open('./上海二手房.txt','w',encoding='utf-8')
for div in div_list:
title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]
print(title)
price=str('總價格為'+div.xpath('.//div[@class="property-price"]/p/span[@class="property-price-total-num"]/text()')[0])+'萬元'
print(price)
fp.write(title+'\t'+price+'\n'+'\n')
結果:
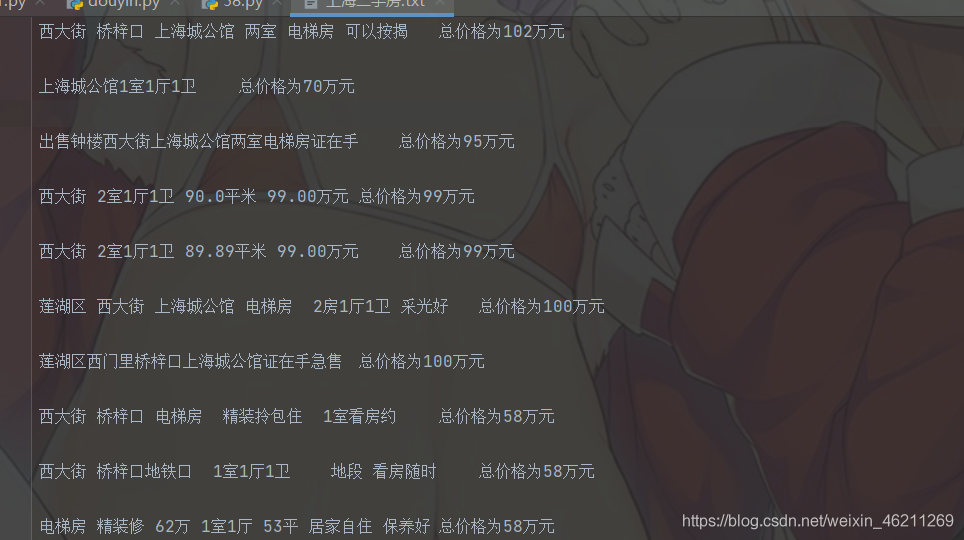
但是呢?這樣會不會還是顯得麻煩了呢?難不成每個城市都寫一份這樣的代碼嗎?不是的,請看如下分析:
上面這部分代碼是爬取的上海的二手房價
然而網址卻是這樣的:

這樣很容易想到,如果切換城市,僅僅只需要把上海換成別的城市就可以了,經過我分析,換個城市,網頁結構并不用變化,所以唯一變動就是這個城市,
因此修改后代碼:
#coding=utf-8
"""
作者:川川
時間:2021/10/10
"""
from lxml import etree
import requests
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
c=input('這里是二手房價爬取,請輸入你想要爬取的城市:\n')
url = 'https://xa.58.com/ershoufang/?q=%s'%c
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
div_list = tree.xpath('//section[@class="list"]/div')
print(div_list)
fp = open('./上海二手房.txt','w',encoding='utf-8')
for div in div_list:
title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]
print(title)
price=str('總價格為'+div.xpath('.//div[@class="property-price"]/p/span[@class="property-price-total-num"]/text()')[0])+'萬元'
print(price)
fp.write(title+'\t'+price+'\n'+'\n')
效果如下:
想爬取哪個城市就輸入哪個城市即可

結果如下:
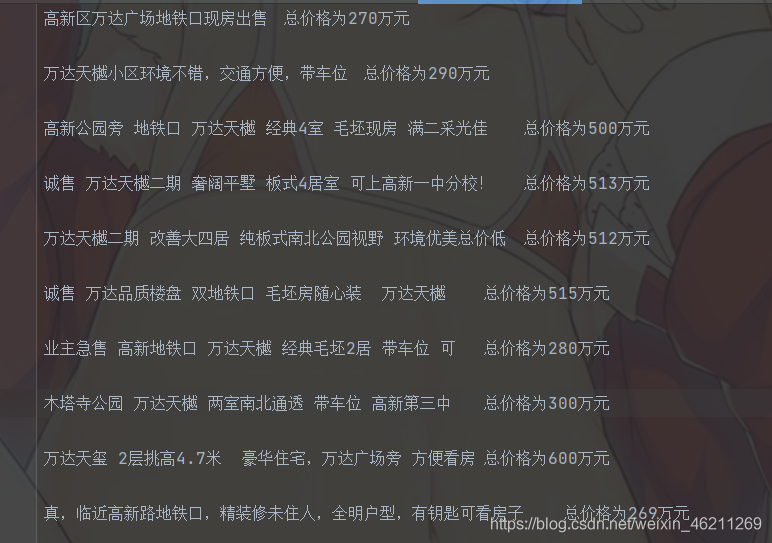
可是就算這樣能爬取到每個城市的二手價,每次創建的檔案名字沒有變動啊,所以還得繼續修改一點點,需要每次爬取就自動創建對應城市的檔案,所以再次修改后如下:
#coding=utf-8
"""
作者:川川
時間:2021/10/10
"""
from lxml import etree
import requests
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
c=input('這里是二手房價爬取,請輸入你想要爬取的城市:\n')
url = 'https://xa.58.com/ershoufang/?q=%s'%c
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
div_list = tree.xpath('//section[@class="list"]/div')
print(div_list)
wen=c+'二手房價.txt'
fp = open(wen,'w',encoding='utf-8')
for div in div_list:
title = div.xpath('.//div[@class="property-content-title"]/h3/text()')[0]
print(title)
price=str('總價格為'+div.xpath('.//div[@class="property-price"]/p/span[@class="property-price-total-num"]/text()')[0])+'萬元'
print(price)
fp.write(title+'\t'+price+'\n'+'\n')
輸入城市:

結果:
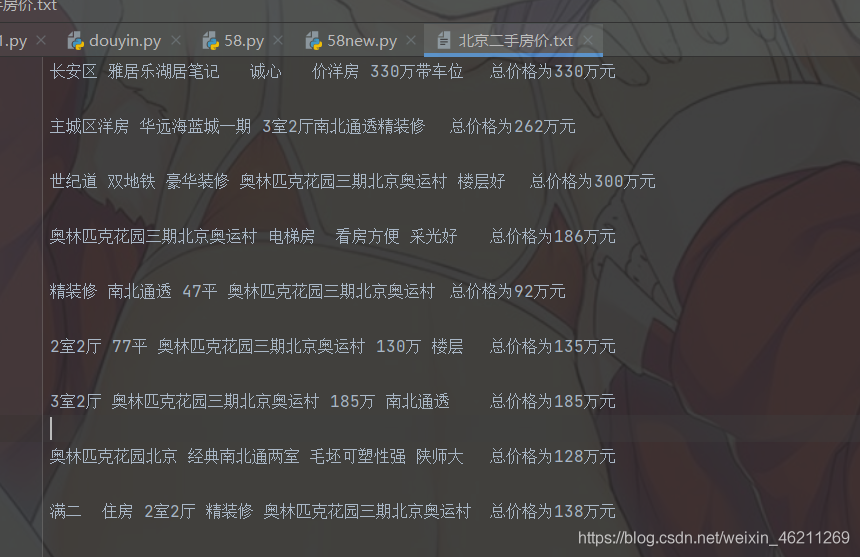
運行如下:

十四、實戰演練(虎牙美女直播爬取)
可以自己去跑一下,我就不分析了,這里我們用到了requests,但是我還沒講這個模塊,可以來體驗一下,
注意,你需要改如下路徑:
path='E://photo//'
完整代碼
import requests
from lxml import etree
import time
url='https://www.huya.com/g/4079/'
header={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response=requests.get(url=url,headers=header)#發送請求
# print(response.text)
data=etree.HTML(response.text)#轉化為html格式
image_url=data.xpath('//a//img//@data-original')
image_name=data.xpath('//a//img[@class="pic"]//@alt')
# print(image_url)
path='E://photo//'
for ur,name in zip(image_url,image_name):
url=ur.replace('?imageview/4/0/w/338/h/190/blur/1','')
title=name+'.jpg'
response = requests.get(url=url, headers=header) # 在此發送新的請求
with open(path+title,'wb') as f:
f.write(response.content)
print("下載成功" + name)
time.sleep(2)
我最近才學到xpath吧,所以就用的xpath,跟著我學爬蟲,一定會發現很簡單,很有趣,
部分結果:

十三、粉絲福利
前期已經送出很多基礎書和資料分析書籍,本次送人工智能的書籍如下:

送書僅在于個人心意,以此鼓勵大家學習,只隨機送兩本
十四、總結
這位大佬也寫了一篇xpath:十五分鐘掌握python爬蟲XPath庫 感興趣可以對照我的看看,
python全堆疊基礎專欄我已經講完大部分基礎,現在我們進軍爬蟲,本篇內容希望大家一定掌握,超過2000收藏,我補一篇html網頁基礎,寫了我周末兩個通宵,希望大家這次支持,謝謝,至于我送書活動,貨真價實,僅代表個人心意,鼓勵大家學習,
公眾號 發送:xpath 即可領取本篇文章的電子版,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/309558.html
標籤:其他