43 預習:Socket通信之網路協議基本原理
網路協議:一臺機器將內容按照約定好的格式發送出去,另外一臺機器收到后能按照約定格式決議,獲取到資訊,
兩種網路協議,
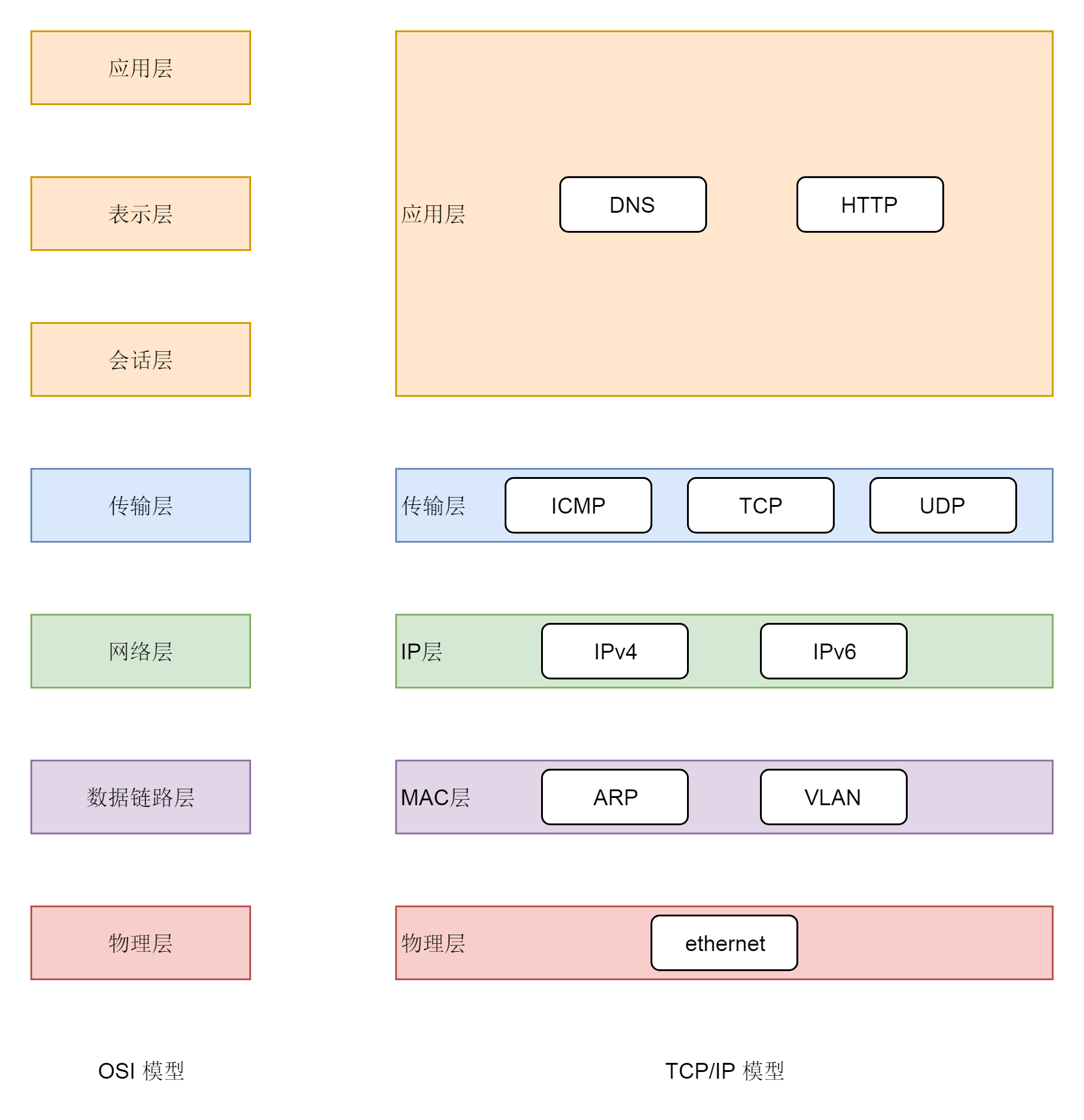
osi標準七層模型:物理層 資料鏈路層 網路層 傳輸層 會話層 表示層 應用層
TCP/IP模型:物理層 mac層 ip層 傳輸層 應用層(dns http)
具體如下圖:
為什么要分層呢?
同一套網路協議堆疊通過切分成多個層次和組合,來滿足不同服務器和設備的通信需求,
網路協議層次介紹
物理層:即物理設備,如連著電腦的網線、wifi
資料鏈路層:又稱mac層,因為每個網卡都有唯一的硬體地址,在該層IP地址經過ARP協議得到對應的mac地址,在網路內服務器匹配上廣播包對應的MAC地址就接收,
網路層:也就IP層,網路包從一個起始的IP地址,沿著路由協議指的道兒,經過多個網路,通過多次路由器轉發,到達目標IP地址,
傳輸層:協議包括UDP/TCP,TCP是可靠協議,通過重傳、編號等手段避免了丟包等問題,
應用層:如咱們在瀏覽器里面輸入的 HTTP,Java 服務端寫的 Servlet
應用層是用戶態的,二層到四層都是在Linux內核里面處理的,內核對于網路包的處理不區分內核應用,應用層則進行區分,如通過埠,nginx監聽80,tomcat監聽8080.
用戶態的應用層和內核2~4層的互通,就是通過socket系統呼叫,
資料包的傳輸程序
網路分完層后,對于資料包的發送和接收就是層層封裝與解封裝的程序,
在 Linux服務器B上部署的服務端Nginx, Linux 服務器 A 上的客戶端,打開一個 Firefox 連接 Ngnix,如下圖:
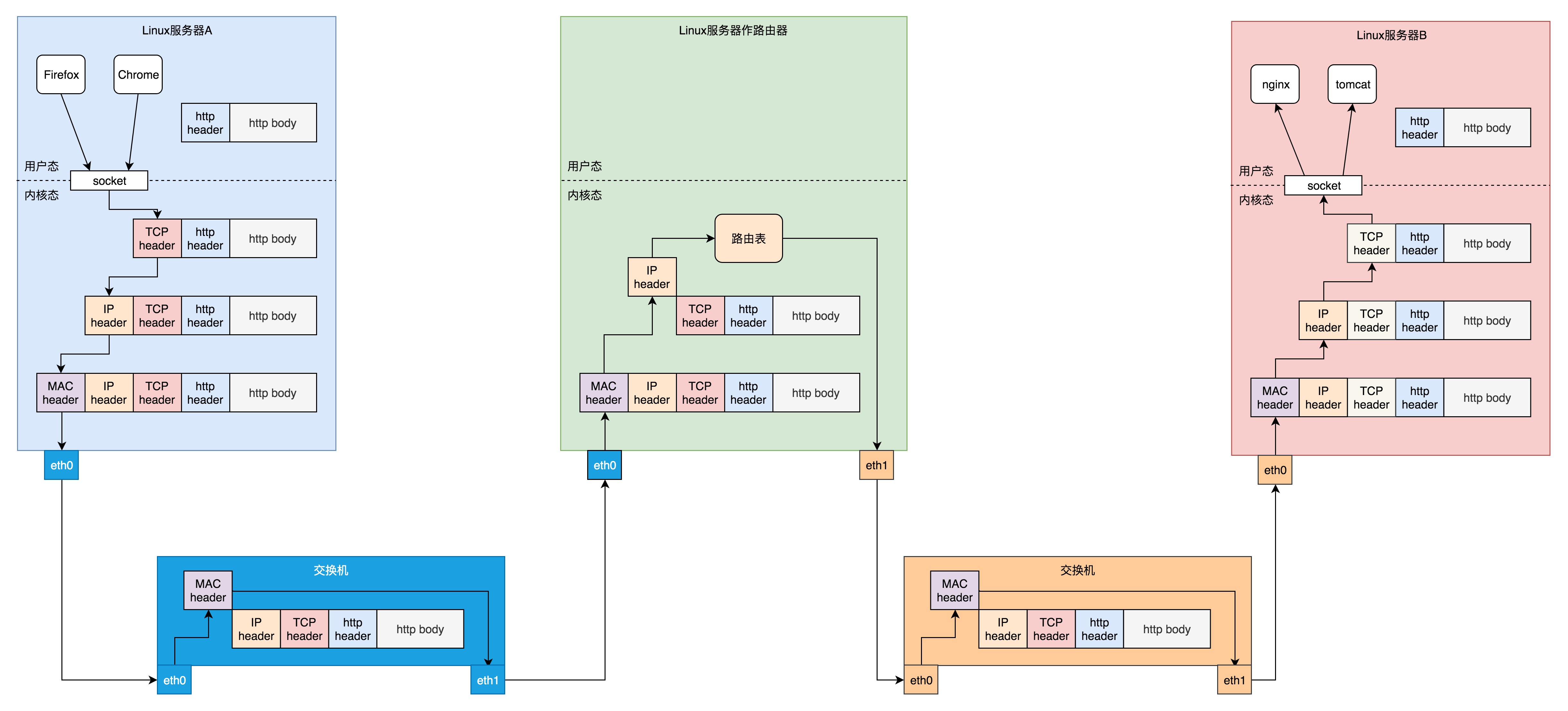
那么網路傳輸的具體流程:
1)在服務器A上,瀏覽器請求封裝為HTTP協議,通過Socket發送到A的內核,傳輸層將http包加上TCP頭發送給IP層,IP層加上IP頭發送給mac層,mac層加上mac頭,從硬體網卡發出去,
2)到達交換機,因只會處理到第二層所以被稱為二層設備,會將網路包的MAC頭拿下來,發現目標MAC是在自己右面的網口,于是就從這個網口發出去,
3)到達路由器,它左面的網卡會收到網路包,發現 MAC 地址匹配,就交給 IP 層,在 IP 層根據 IP 頭中的資訊,在路由表中查找,然后從合適的網口發出去,常把路由器稱為三層設備,因為它只會處理到第三層
4)交換機,還是會經歷一次二層的處理,轉發到交換機右面的網口,
5)linux服務器B,它發現 MAC 地址匹配,就將 MAC 頭取下來,交給上一層,IP 層發現 IP 地址匹配,將 IP 頭取下來,交給上一層,TCP 層會獲取TCP 頭中的資訊,內核會根據 TCP 頭中的埠號,將網路包發給相應的應用,
6)應用會決議HTTP 層的頭和正文,處理后獲取結果,然后仍然封裝為http的網路包,通過一系列程序回傳給客戶端,
43 socket通信
TCP/UDP的區別
1)TCP是面向連接的,UDP無連接
2)TCP通過編號、重試等是可靠傳輸,且提供流量控制和擁塞控制,UDP不可靠
3)TCP效率較低,
4)TCP是基于流的,UDP基于資料報
說明:所謂的連接,就是兩端資料結構狀態的協同,兩邊的狀態能夠對得上,可靠也是兩端的資料結構做的事情,如不丟失其實是資料結構在“點名”,順序到達其實是資料結構在“排序”,面向資料流其實是資料結構將零散的包,按照順序捏成一個流發給應用層,
socket操作tcp或udp,都要呼叫socket函式,如下:
int socket(int domain, int type, int protocol);
引數說明:
domain:表示使用什么 IP 層協議,AF_INET 表示 IPv4,AF_INET6 表示 IPv6,
type:表示 socket 型別,SOCK_STREAM,顧名思義就是 TCP 面向流的,SOCK_DGRAM 就是 UDP 面向資料報的,SOCK_RAW 可以直接操作 IP 層,或者非 TCP 和 UDP 的協議,例如 ICMP,
protocol 表示的協議,包括 IPPROTO_TCP、IPPTOTO_UDP,
函式功能:在內核中,創建一個 socket 的檔案描述符,后續的操作都會用到,
TCP下socket編程
整體流程如下圖:
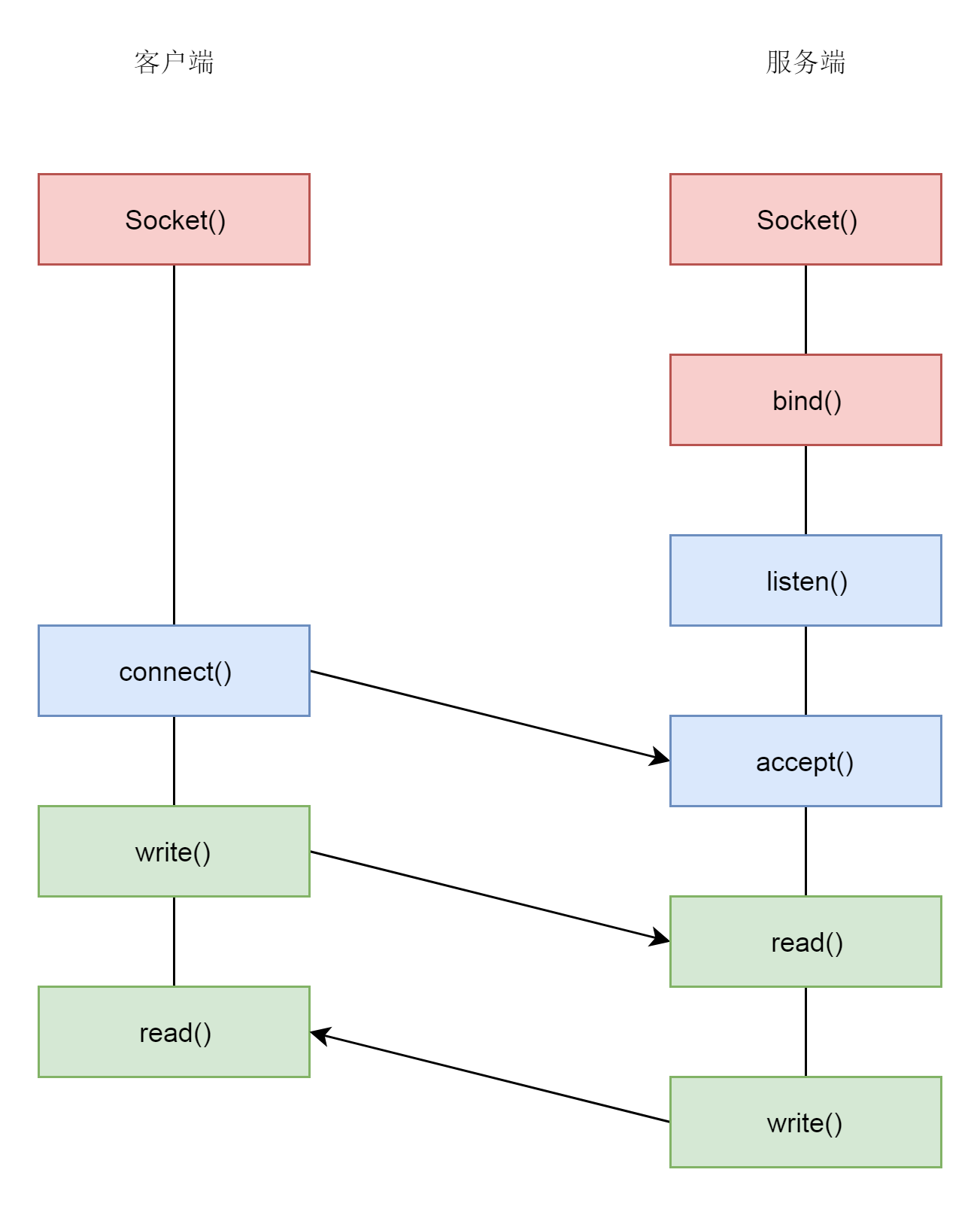
0)服務端和客戶端分別呼叫socket函式,獲取socket檔案描述符
1)服務端呼叫bind函式,監聽一個埠,給socket賦一個ip地址和埠,這樣后面客戶端可以通過ip和埠訪問服務端,客戶端則不需要bind
說明:服務端所在的服務器可能有多個網卡、多個地址,可以選擇監聽在一個地址,也可以監聽 0.0.0.0 表示所有的地址都監聽,服務端一般要監聽在一個眾所周知的埠上,例如,Nginx 一般是 80,Tomcat 一般是 8080,
2)服務端呼叫listen進入LISTEN狀態,等待客戶端連接,
3)服務端呼叫 accept,等待內核完成了至少一個連接的建立,才回傳,如果有多個客戶端發起連接,并且在內核里面完成了多個三次握手,建立了多個連接,這些連接會被放在一個佇列里面,回圈呼叫accpet進行處理,
4)客戶端通過connect函式發起連接,指明要連接的 IP 地址和埠號,然后發起三次握手,握手成功后,服務端的 accept 就會回傳另一個 socket,
監聽的 socket 和真正用來傳送資料的 socket,是兩個 socket,一個叫作監聽 socket,一個叫作已連接 socket,
5)雙方開始通過 read 和 write 函式來讀寫資料
上面提到的三次握手如下圖:
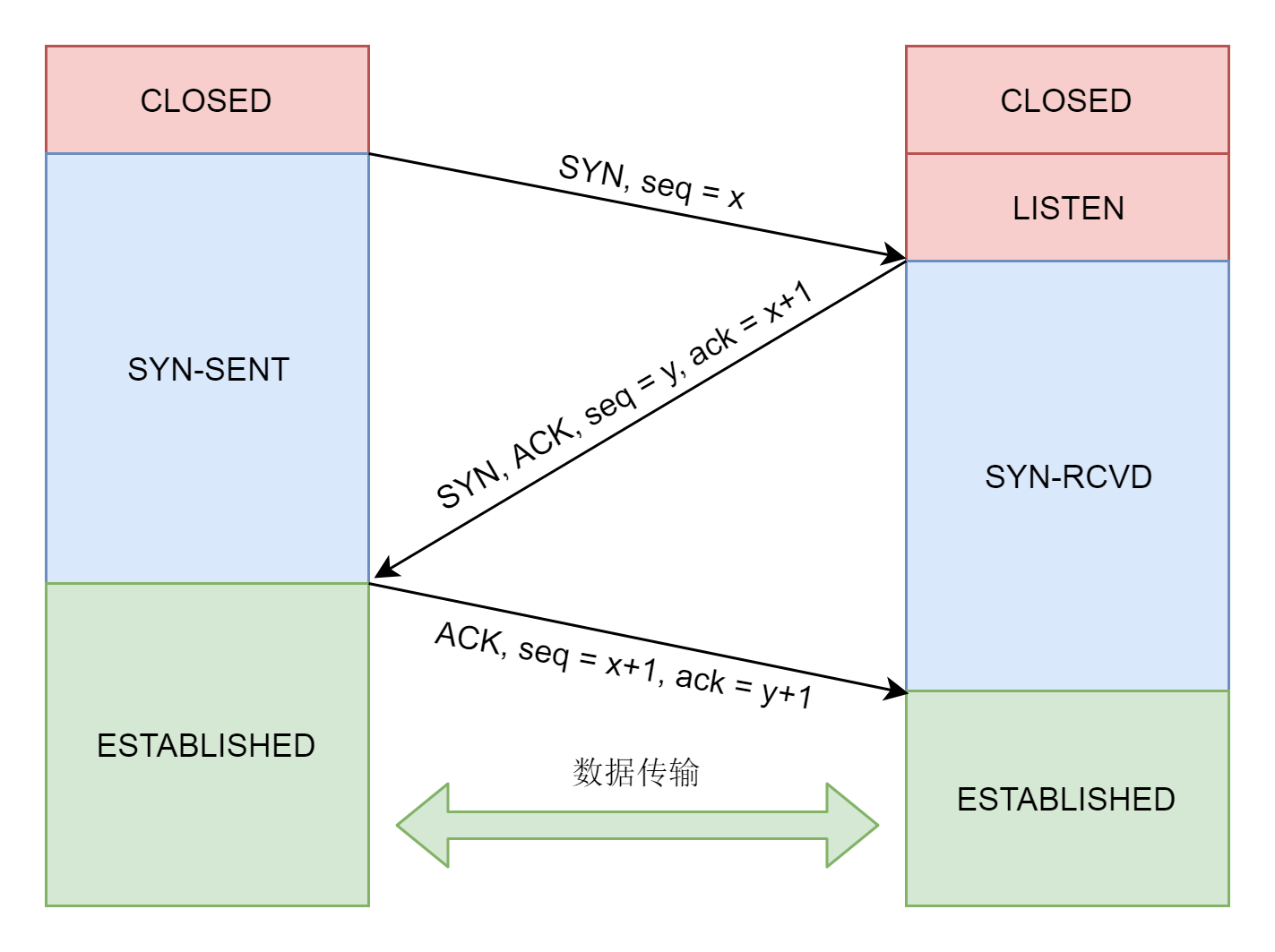
為什么是三次握手,不是2次或四次?tcp的報文序號,三次握手和四次揮手_進化的深山猿-CSDN博客
UDP下的socket編程
如下圖:
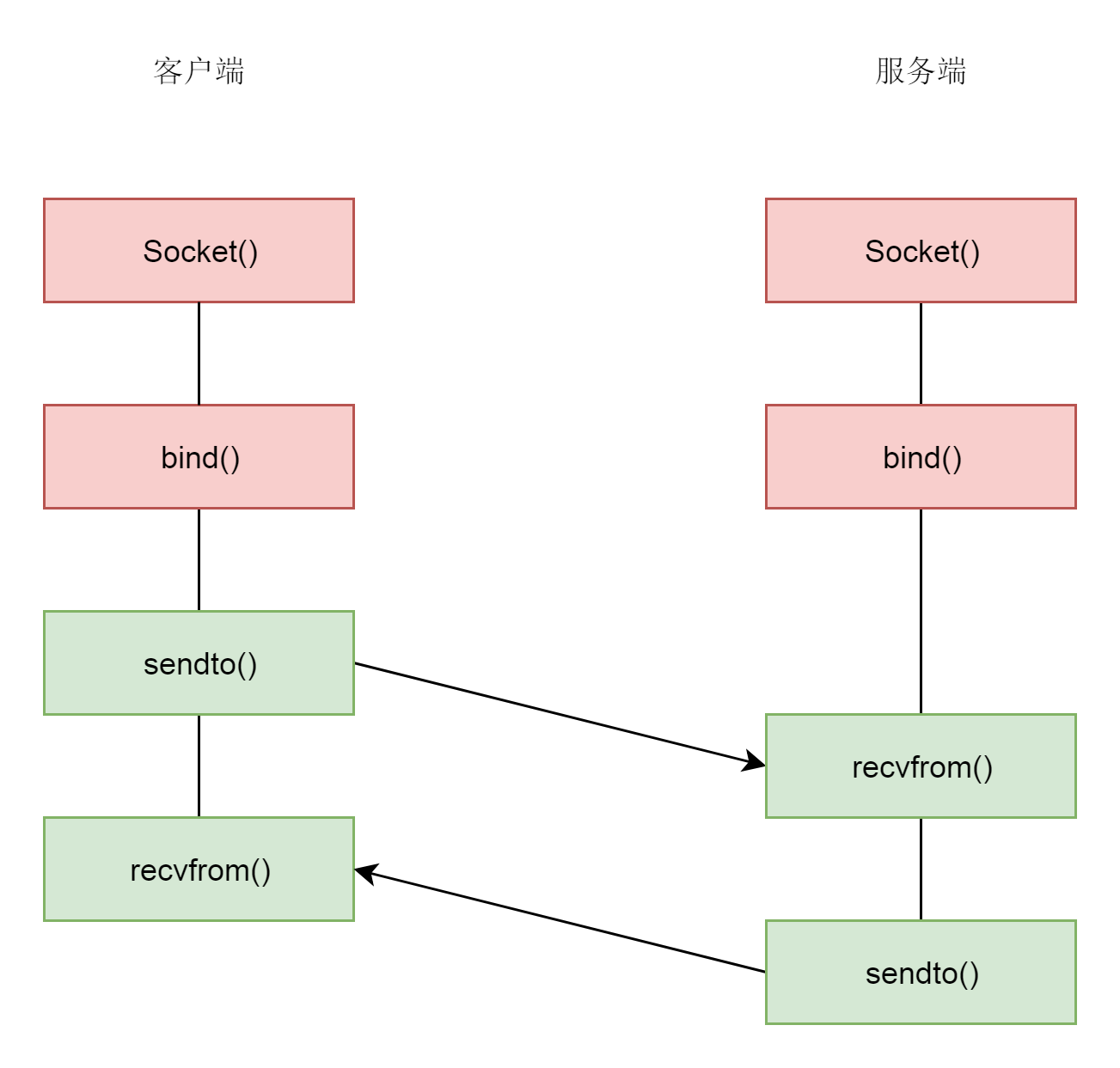
UDP 是沒有連接的,所以不需要三次握手,也就不需要呼叫 listen 和 connect,但是 UDP 的互動仍然需要 IP 地址和埠號,因而也需要 bind,
每次通信時,呼叫 sendto 和 recvfrom,都要傳入 IP 地址和埠,
44 socket內核資料結構
socket函式決議
Socket系統呼叫會呼叫sock_create創建一個struct socket結構,然后通過sock_map_fd和檔案描述符對應起來,
引數:
先分配struct socket 結構,
family,表示地址族, net_families 陣列中以該引數為下標,找到對應的 struct net_proto_family,net_proto_family中會指定create函式的指向,
type,也即 Socket 的型別,型別是比較少的,包括SOCK_STREAM、SOCK_DGRAM 和 SOCK_RAW,type作為inetsw陣列下標,找到type對應的串列,根據protocol最終得到用戶指定的 family->type->protocol 的 struct inet_protosw *answer 物件,其ops賦給struct socket *sock 的 ops 成員變數,
然后創建一個 struct sock *sk 物件,說明:socket 是用于負責對上給用戶提供介面,并且和檔案系統關聯,而 sock,負責向下對接內核網路協議堆疊,
struct inet_protosw *answer 結構的 tcp_prot 賦值給了 struct sock *sk 的 sk_prot 成員,
protocol,是協議,協議數目是比較多的,也就是說,多個協議會屬于同一種型別,會回圈對應的鏈表,找到對應型別下對應協議的inetsw
決議bind函式
sockfd_lookup_light 會根據 fd 檔案描述符,找到 struct socket 結構,然后將 sockaddr 從用戶態拷貝到內核態,然后呼叫 struct socket 結構里面 ops 的 bind 函式,根據前面創建 socket 的時候的設定,呼叫的是 inet_stream_ops 的 bind 函式,即呼叫inet_bind,檢查埠是否沖突,是否可以系結,可以則進行系結,
決議listen函式
即呼叫 inet_listen,如果socket還不在TCP_LISTEN狀態,會呼叫inet_csk_listen_start進入監聽狀態,
在內核中,為每個Socket維護兩個佇列:
1)一個是已經建立了連接的佇列,這時候連接三次握手已經完畢,處于 established 狀態;即icsk_accept_queue
2)一個是還沒有完全建立連接的佇列,這個時候三次握手還沒完成,處于 syn_rcvd 的狀態,
初始化完之后,將 TCP 的狀態設定為 TCP_LISTEN,再次呼叫 get_port 判斷埠是否沖突,
決議accept函式
即呼叫inet_accept
原來的 socket 是監聽 socket,這里我們會找到原來的 struct socket,并基于它去創建一個新的 newsock,這才是連接socket,除此之外,我們還會創建一個新的 struct file 和 fd,并關聯到 socket,
如果 icsk_accept_queue 為空,則呼叫 inet_csk_wait_for_connect 進行等待;等待的時候,呼叫 schedule_timeout,讓出 CPU,并且將行程狀態設定為 TASK_INTERRUPTIBLE,
如果再次 CPU 醒來,我們會接著判斷 icsk_accept_queue 是否為空,同時也會呼叫 signal_pending 看有沒有信號可以處理,一旦 icsk_accept_queue 不為空,就從 inet_csk_wait_for_connect 中回傳,在佇列中取出一個 struct sock 物件賦值給 newsk,
決議connect函式
三次握手結束后,icsk_accept_queue 才不為空,下面分析三次握手的程序,
客戶端發送SYN:
三次握手由客戶端呼叫connect函式發起,呼叫inet_stream_connect,
如果socket處于SS_UNCONNECTED 狀態,呼叫tcp_v4_connect函式,主要作業如下:
1)ip_route_connect 其實是做一個路由的選擇,SYN 包了,這就要湊齊源地址、源埠、目標地址、目標埠,
2)發送 SYN 之前,我們先將客戶端 socket 的狀態設定為 TCP_SYN_SENT,然后初始化 TCP 的 seq num
3)呼叫 tcp_connect 進行發送SYN,會有重試機制,
服務端接受SYN:
通過struct net_protocol 結構中的 handler 進行接收,呼叫的函式是 tcp_v4_rcv,接下來的呼叫鏈為 tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_state_process,
服務端處于TCP_LISTEN狀態,接收到SYN.
回復一個 SYN-ACK,呼叫 icsk->icsk_af_ops->conn_request 函式,其實呼叫的是 tcp_v4_conn_request-->tcp_conn_request
回復完畢后,服務端處于 TCP_SYN_RECV狀態
客戶端接收SYN-ACK網路包了:
都是 TCP 協議堆疊,所以程序和服務端沒有太多區別,還是會走到 tcp_rcv_state_process 函式的,此時客戶端目前處于 TCP_SYN_SENT 狀態,所以tcp_rcv_synsent_state_process 會呼叫 tcp_send_ack,發送一個 ACK-ACK,發送后客戶端處于 TCP_ESTABLISHED 狀態,
服務端接收ACK-ACK網路包
又tcp_rcv_state_process 函式處理,由于服務端目前處于狀態 TCP_SYN_RECV 狀態,因而又走了另外的分支,當收到這個網路包的時候,服務端也處于 TCP_ESTABLISHED 狀態,三次握手結束,
45-46 發送資料包
這個程序分成幾個層次:
VFS 層:write 系統呼叫找到 struct file,根據里面的 file_operations 的定義,呼叫 sock_write_iter 函式,sock_write_iter 函式呼叫 sock_sendmsg 函式,
Socket 層:從 struct file 里面的 private_data 得到 struct socket,根據里面 ops 的定義,呼叫 inet_sendmsg 函式,
Sock 層:從 struct socket 里面的 sk 得到 struct sock,根據里面 sk_prot 的定義,呼叫 tcp_sendmsg 函式,
TCP 層:tcp_sendmsg 函式會呼叫 tcp_write_xmit 函式,tcp_write_xmit 函式會呼叫 tcp_transmit_skb,在這里實作了 TCP 層面向連接的邏輯,
IP 層:擴展 struct sock,得到 struct inet_connection_sock,根據里面 icsk_af_ops 的定義,呼叫 ip_queue_xmit 函式,
IP 層:ip_route_output_ports 函式里面會呼叫 fib_lookup 查找路由表,FIB 全稱是 Forwarding Information Base,轉發資訊表,也就是路由表,
在 IP 層里面要做的另一個事情是填寫 IP 層的頭,
在 IP 層還要做的一件事情就是通過 iptables 規則,
MAC 層:IP 層呼叫 ip_finish_output 進行 MAC 層,
MAC 層需要 ARP 獲得 MAC 地址,因而要呼叫 ___neigh_lookup_noref 查找屬于同一個網段的鄰居,他會呼叫 neigh_probe 發送 ARP,
有了 MAC 地址,就可以呼叫 dev_queue_xmit 發送二層網路包了,它會呼叫 __dev_xmit_skb 會將請求放入佇列,
設備層:網路包的發送會觸發一個軟中斷 NET_TX_SOFTIRQ 來處理佇列中的資料,這個軟中斷的處理函式是 net_tx_action,
在軟中斷處理函式中,會將網路包從佇列上拿下來,呼叫網路設備的傳輸函式 ixgb_xmit_frame,將網路包發到設備的佇列上去,
47-48 接收資料包
整個程序可以分成以下幾個層次:
硬體網卡接收到網路包之后,通過 DMA 技術,將網路包放入 Ring Buffer;
硬體網卡通過中斷通知 CPU 新的網路包的到來;
網卡驅動程式會注冊中斷處理函式 ixgb_intr;
中斷處理函式處理完需要暫時屏蔽中斷的核心流程之后,通過軟中斷 NET_RX_SOFTIRQ 觸發接下來的處理程序;
NET_RX_SOFTIRQ 軟中斷處理函式 net_rx_action,net_rx_action 會呼叫 napi_poll,進而呼叫 ixgb_clean_rx_irq,從 Ring Buffer 中讀取資料到內核 struct sk_buff;
呼叫 netif_receive_skb 進入內核網路協議堆疊,進行一些關于 VLAN 的二層邏輯處理后,呼叫 ip_rcv 進入三層 IP 層;
在 IP 層,會處理 iptables 規則,然后呼叫 ip_local_deliver 交給更上層 TCP 層;
在 TCP 層呼叫 tcp_v4_rcv,這里面有三個佇列需要處理,如果當前的 Socket 不是正在被讀取,則放入 backlog 佇列,如果正在被讀取,不需要很實時的話,則放入 prequeue 佇列,其他情況呼叫 tcp_v4_do_rcv;
在 tcp_v4_do_rcv 中,如果是處于 TCP_ESTABLISHED 狀態,呼叫 tcp_rcv_established,其他的狀態,呼叫 tcp_rcv_state_process;
在 tcp_rcv_established 中,呼叫 tcp_data_queue,如果序列號能夠接的上,則放入 sk_receive_queue 佇列;如果序列號接不上,則暫時放入 out_of_order_queue 佇列,等序列號能夠接上的時候,再放入 sk_receive_queue 佇列,
至此內核接收網路包的程序到此結束,接下來就是用戶態讀取網路包的程序,這個程序分成幾個層次,
VFS 層:read 系統呼叫找到 struct file,根據里面的 file_operations 的定義,呼叫 sock_read_iter 函式,sock_read_iter 函式呼叫 sock_recvmsg 函式,
Socket 層:從 struct file 里面的 private_data 得到 struct socket,根據里面 ops 的定義,呼叫 inet_recvmsg 函式,
Sock 層:從 struct socket 里面的 sk 得到 struct sock,根據里面 sk_prot 的定義,呼叫 tcp_recvmsg 函式,
TCP 層:tcp_recvmsg 函式會依次讀取 receive_queue 佇列、prequeue 佇列和 backlog 佇列,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/310538.html
標籤:其他