我做了以下函式,它可以從一個標量欄位創建標量剖面圖。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
dummy_data_A = {'A'/span>: np.random.uniform(low=-3. 5, high=3.5, size=(98,501))。)
'B': np.random.uniform(low=-3.5, high=3. 5, size=(98,501)), 'C'/span>: np. random.uniform(low=-3.5, high=3.5, size=(98,501) }.
dummy_data_B = {'A': np.隨機.uniform(low=-3. 5, high=3.5, size=(98,501))。)
'B': np.random.uniform(low=-3.5, high=3. 5, size=(98,501)), 'C'/span>: np. random.uniform(low=-3.5, high=3.5, size=(98,501) }。
def plot_scalar_profiles(true_var, pred_var,
coordinates = ['x','y']。
x_position = None,
bounds_var = None,
norm = False )。)
fig = plt.figure(figsize=(12,10)
st = plt.suptitle("Scalar fields", fontsize="x-large")
nr_plots = len(list(true_var.key()) #不繪制x或y
plot_index = 1
for key in true_var.keys()。
rmse_list = []
for profile_pos in x_position:
true_field_star = true_var[key] 。
pred_field_star = pred_var[key] 。
axes = plt.subplot(nr_plots, len(x_position), plot_index)
axes.set_title(f "scalar: {key}, X_pos: {profile_pos}") # ,RMSE: {rms:.2f}
true_profile = true_field_star[...,profile_pos] # for i in range(probe positions)
pred_profile = pred_field_star[...,profile_pos)
if norm:
#true_profile = true_field_star[...,profile_pos] # for i in range(probe positions)
#pred_profile = pred_field_star[...,profile_pos]
true_profile = normalize_list(true_field_star[...,profile_pos])
pred_profile = normalize_list(pred_field_star[...,profile_pos])
rms = mean_squared_error(true_profile, pred_profile, squared=False)
true_profile_y = range(len(true_profile)
axes.plot(true_profile, true_profile_y, label='True'/span>)
#
pred_profile_y = range(len(pred_profile)
axes.plot(pred_profile, pred_profile_y, label='Pred'/span>)
rmse_list.append(rms)
plot_index = 1sum(rmse_list)
print(f "RMSE {key}: {RMSE}")
lines, labels = fig.axes[-1].get_legend_handles_labels()
fig.legend(lines, labels, loc = " lower right")
fig.supxlabel('u Velocity (m/s)')
fig.supylabel('y Distance (cm)')
fig.tight_layout()
#plt.savefig(save_name '.png', facecolor='white', transparent=False)
plt.show()
plt.close('all')
plot_scalar_profiles(dummy_data_A, dummy_data_B,
x_position = [1, 100, 200, 400]。
bounds_var=None。
norm=False)
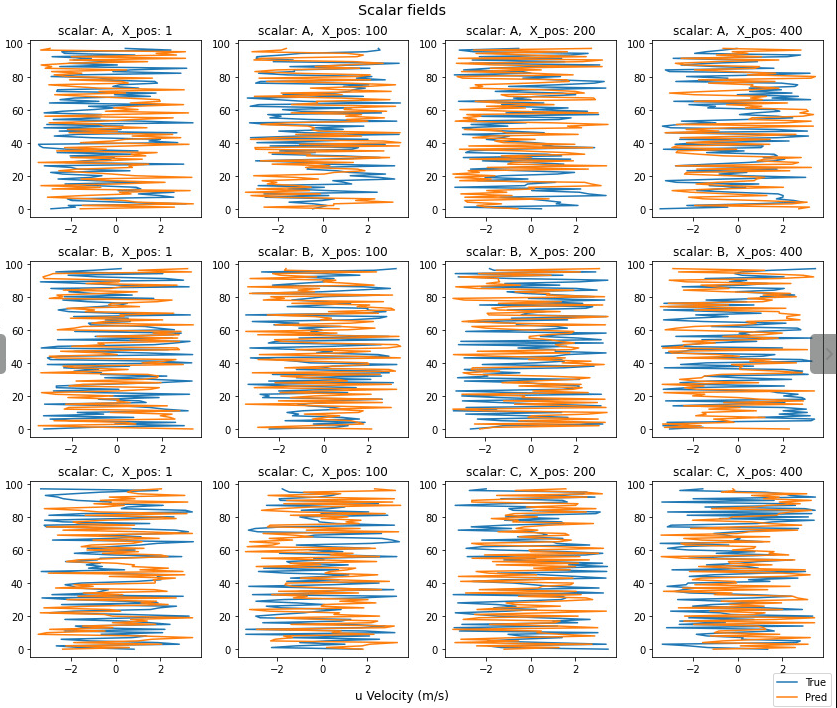
它還計算了沿x_position提取的標量場'A','B','C'的輪廓的總均方根誤差。
控制臺輸出。
RMSE A: 11.815624240063709[/span
RMSE B: 11.623509385371737[/span
RMSE C: 11.435156749416366[/span
我有2個問題:
我有2個問題。
我有兩個問題:
我如何給每一行和每一列貼標簽?給每個子圖貼標簽看起來很雜亂。
我如何在每一行的右邊注釋RMSE的輸出?
下面是我對這2個點的粗略畫法。
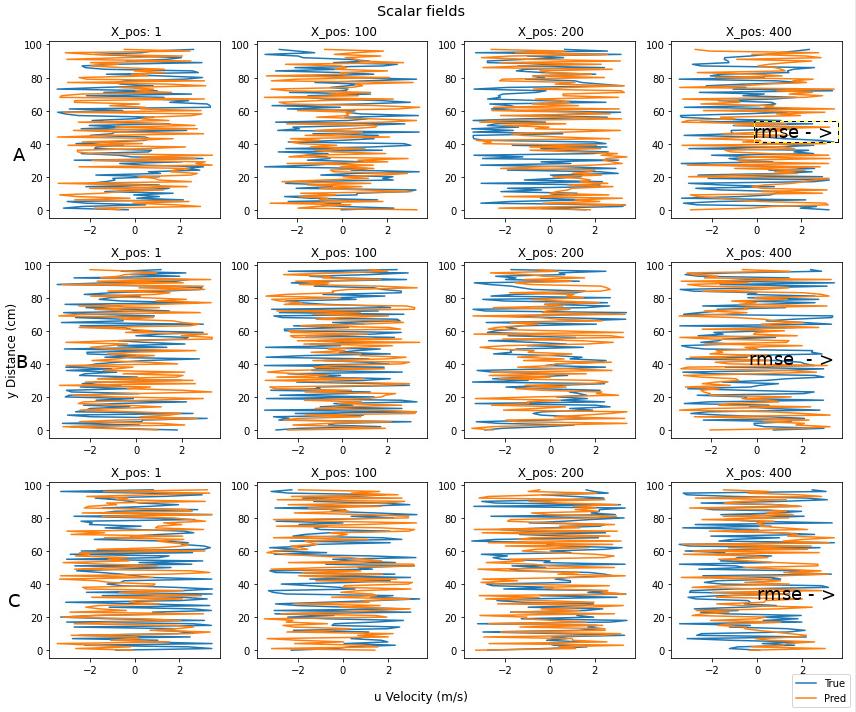
也歡迎任何其他的改進建議。我仍在嘗試找出最干凈/最好的方式來表示這些資料。
uj5u.com熱心網友回復:
假設
我的答案是基于你總是有12個圖的假設,所以我把注意力集中在一些有固定位置的圖上。
答案是
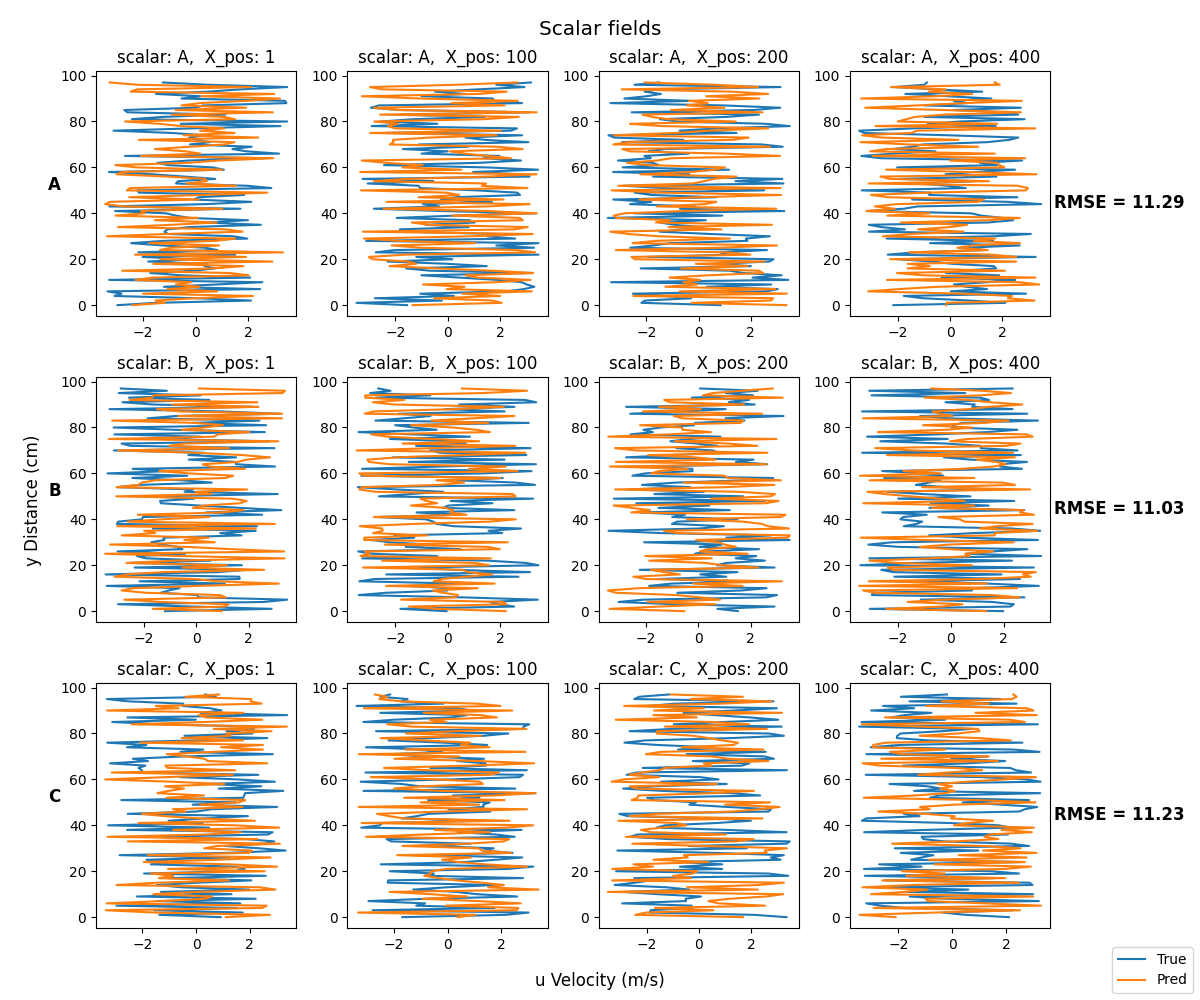
。為了給每一行貼上標簽,你可以用fig.axes[n].set_ylabel來設定左邊的圖的y標簽,你也可以選擇添加額外的引數來定制標簽:
fig.axes[0]。 set_ylabel('A', rotation = 0, weight = 'bold', fontsize = 12)
fig.axes[4].set_ylabel('B', rotation = 0, weight = 'bold', fontsize = 12)
fig.axes[8].set_ylabel('C', rotation = 0, weight = 'bold', fontsize = 12)
為了報告每一行的RMSE,你需要將這些值保存在一個串列中,然后你可以利用與上面相同的概念:將繪圖的y標簽設定在右邊,并將y標簽移到右邊:
RMSE = sum(rmse_list)
RMSE_values.append(RMSE)
print(f "RMSE {key}: {RMSE}")
...
fig.axes[3].set_ylabel(f'RMSE = {RMSE_values[0]:. 2f}', rotation = 0, weight = 'bold', fontsize = 12, labelpad = 50)
fig.axes[7].set_ylabel(f'RMSE = {RMSE_values[1]:. 2f}', rotation = 0, weight = 'bold', fontsize = 12, labelpad = 50)
fig.axes[11].set_ylabel(f'RMSE = {RMSE_values[2]:. 2f}', rotation = 0, weight = 'bold', fontsize = 12, labelpad = 50)
fig.axes[3].yaxis.set_label_position('right')
fig.axes[7].y軸.set_label_position('right')
fig.axes[11].y軸.set_label_position('right')
完整的代碼
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
dummy_data_A = {'A'/span>: np.random.uniform(low = -3. 5, high = 3.5, size = (98, 501))。
'B': np.random.uniform(low = -3.5, high = 3.5, size = (98, 501))。
'C': np.random.uniform(low = -3.5, high = 3.5, size = (98, 501))}.
dummy_data_B = {'A': np.隨機.uniform(low = -3. 5, high = 3.5, size = (98, 501))。
'B': np.random.uniform(low = -3.5, high = 3.5, size = (98, 501)),
'C': np.random.uniform(low = -3.5, high = 3.5, size = (98, 501))}。
def plot_scalar_profiles(true_var, pred_var,
coordinates = ['x', 'y']。
x_position = None,
bounds_var = None,
norm = False)。)
fig = plt.figure(figsize = (12, 10)
st = plt.suptitle("Scalar fields", fontsize ="x-large")
nr_plots = len(list(true_var.key()) #不繪制x或y
plot_index = 1
RMSE_values = []
for key in true_var.keys()。
rmse_list = []
for profile_pos in x_position:
true_field_star = true_var[key] 。
pred_field_star = pred_var[key] 。
axes = plt.subplot(nr_plots, len(x_position), plot_index)
axes.set_title(f "scalar: {key}, X_pos: {profile_pos}") # ,RMSE: {rms:.2f}
true_profile = true_field_star[..., profile_pos] # for i in range(probe positions)
pred_profile = pred_field_star[..., profile_pos)
if norm:
# true_profile = true_field_star[...,profile_pos] # for i in range(probe positions)
# pred_profile = pred_field_star[...,profile_pos]
true_profile = normalize_list(true_field_star[..., profile_pos])
pred_profile = normalize_list(pred_field_star[..., profile_pos])
rms = mean_squared_error(true_profile, pred_profile, squared = False)
true_profile_y = range(len(true_profile)
axes.plot(true_profile, true_profile_y, label = 'True'/span>)
#
pred_profile_y = range(len(pred_profile)
axes.plot(pred_profile, pred_profile_y, label = 'Pred'/span>)
rmse_list.append(rms)
plot_index = 1sum(rmse_list)
RMSE_values.append(RMSE)
print(f "RMSE {key}: {RMSE}")
lines, labels = fig.axes[-1].get_legend_handles_labels()
fig.legend(lines, labels, loc = " lower right")
fig.supxlabel('u Velocity (m/s)')
fig.supylabel('y Distance (cm)')
fig.axes[0].set_ylabel('A', rotation = 0, weight = 'bold', font size = 12)
fig.axes[4].set_ylabel('B', rotation = 0, weight = 'bold', fontsize = 12)
fig.axes[8].set_ylabel('C', rotation = 0, weight = 'bold', fontsize = 12)
fig.axes[3].set_ylabel(f'RMSE = {RMSE_values[0]:. 2f}', rotation = 0, weight = 'bold', fontsize = 12, labelpad = 50)
fig.axes[7].set_ylabel(f'RMSE = {RMSE_values[1]:. 2f}', rotation = 0, weight = 'bold', fontsize = 12, labelpad = 50)
fig.axes[11].set_ylabel(f'RMSE = {RMSE_values[2]:. 2f}', rotation = 0, weight = 'bold', fontsize = 12, labelpad = 50)
fig.axes[3].yaxis.set_label_position('right')
fig.axes[7].y軸.set_label_position('right')
fig.axes[11].y軸.set_label_position('right')
fig.tight_layout()
# plt.savefig(save_name '.png', facecolor='white', transparent=False)
plt.show()
plt.close('all')
plot_scalar_profiles(dummy_data_A, dummy_data_B,
x_position = [1, 100, 200, 400]。
bounds_var = None,
norm = False)
計劃
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/312409.html
標籤: