實際上,我想在Python中生成3個圓,一個在另一個里面,有三個不同的類(class0、class1、class2)(即首先是較大的圓,然后在它里面是第二個最大的圓,在它里面是第三個圓)。我只能在下面的代碼中用兩個類生成兩個圓。誰能幫幫我呢?
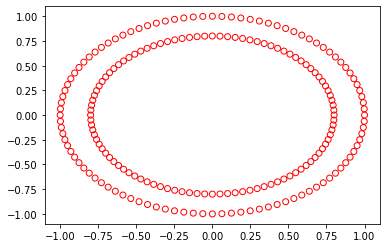
import numpy as np
import pylab as pl
import sklearn.metrics as sm
from sklearn.datasets import make_circles
X, y = make_circles(n_samples=200)
print(X)
print(y)
plt. scatter(X[:,0], X[: ,1], marker='o'/span>, facecolors='none'/span>, edgecolor='r'/span>)
uj5u.com熱心網友回復:
也許有一個更禮貌的方法來進行,但在這里我展示了一個實用的方法。
基本上,你可以用函式make_circles生成另外兩個圓,但要玩另一個超引數,factor。
我所做的,是生成相同的主圓,然后生成一個乘以因子值(在我的例子中是0.6)的新圓。
下面是代碼:
X, y = make_circles(n_samples=200)
z, w = make_circles(n_samples=200, factor=0.6)
plt.scatter(X[:,0],X[:,1], facecolors='none'/span>, edgecolor='r'/span>)
plt.scatter(z[:,0],z[:,1], facialcolors='none', edgecolor='r')
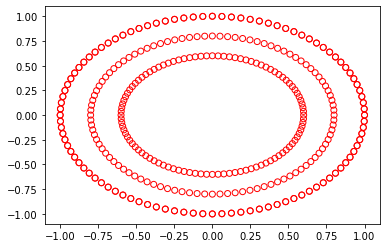
如果你想改變新圓的半徑,可以玩玩factor。
這段代碼的唯一問題是,大圓圈是重復的(繪制了兩次),但是,由于它們是重疊的,所以沒有視覺問題。
uj5u.com熱心網友回復:
根據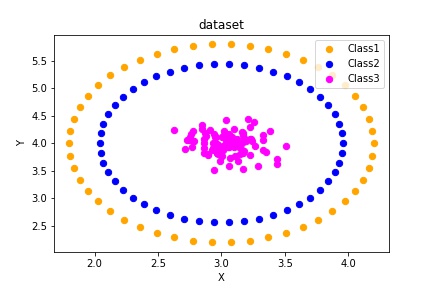
另一種方法是:另一種方法是使用兩個make_circle函式來生成4個圓,但使用其中的3個圓。
import sklearn.datasets as ds
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
data, labels = ds.make_circles(n_samples=100,
shuffle=True,
noise=0.01。
random_state=42)
data2, labels2 = ds.make_circles(n_samples=100,
shuffle=True,
noise=0.0。
random_state=42)
data2 = data2 * [1.2, 1.8]
然后用以下方法繪制結果:
fig, ax = plt.subplots()
顏色 = ["橙色"/span>, "藍色"/span>]
label_name = ["Class1"/span>, "Class2"/span>]
ax.scatter(data[labels==0, 0], data[labels==0, 1], color='red'
,s=40)
ax.scatter(data[labels==1, 0], data[labels==1, 1], color='green')
,s=40)
ax.scatter(data2[labsels2==0, 0], data2[labsels2==0, 1], color='blue',
s=40)
ax.set(xlabel='X'。
ylabel='Y',
title='dataset')
ax.legend(loc='upper right')
然后,結果表現為:
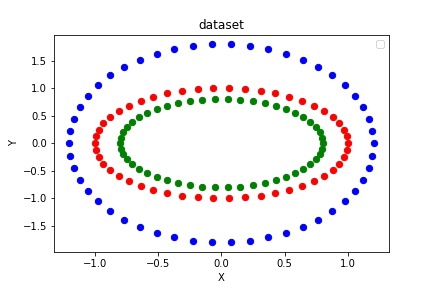
如果你想改變圓的大小(第三圓,這里是外圓),你可以乘以不同的系數。
data2 = data2 * [a1, a2] 。
其中a1和a2可以是任何數值,但完全在0和2之間。如果數值低于1,圓圈將放在其他圓圈內,反之亦然。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/316566.html
標籤:
上一篇:訓練資料比測驗資料有更多的列