本文收錄于《技術專家修煉》
文中配套資料合集 提取碼:ar6f
路線導圖高清源檔案:地址
哈嘍,大家好,我是一條~
根據群內粉絲的需求,一條爆肝一周整理了一套Java學習路線,有了方向才能按圖索驥,事半功倍,
寫給Java零基礎小白的自學路線和進階指南,收藏能省掉幾萬學費,
本文分為學習路線和配套資料兩部分,
文章目錄
- 自學路線
- 0.貴在堅持
- 按計劃行事
- 貴在堅持
- 抱團生長
- 1.Java基礎
- 基本資料型別
- 參考資料型別
- 面向物件三大特性
- 完整講解
- 入門練習案例
- 配套資料
- 2.JavaWeb
- HTTP網路請求方式
- GET和POST
- 常見的網路狀態碼
- 轉發和重定向
- Servlet
- Servlet的生命周期
- MVC與三層架構
- session、cookie、token
- 完整講解
- 3.集合
- ArrayList
- 完整講解
- 4.JVM
- 垃圾回收
- 完整講解
- 配套資料
- 5.多執行緒
- 并行和并發
- 執行緒和行程
- 守護執行緒
- 創建執行緒4種方式
- synchronized 底層實作
- synchronized 和 volatile 的區別
- synchronized 和 ReentrantLock 區別
- synchronized 和 Lock 區別
- 配套資料
- 6.設計模式
- 建造者模式
- 定義
- 結構圖
- 代碼演示
- 目錄結構
- 開發場景
- 代碼演示
- 鏈式呼叫
- 應用場景
- 總結
- 更多設計模式
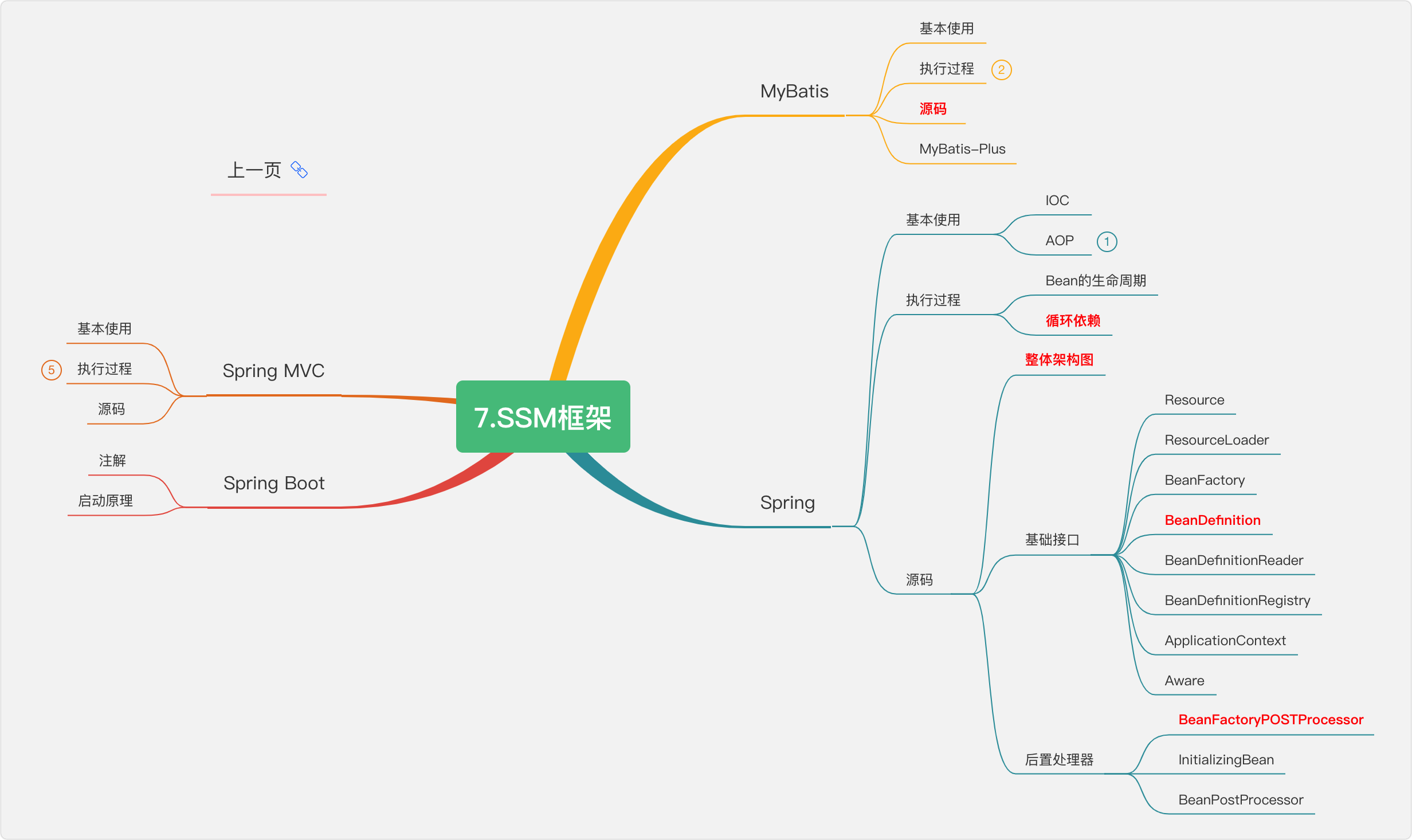
- 7.SSM框架
- ORM 框架?
- MyBatis 中 #{}和 的區別
- 什么是Spring
- 什么是 aop
- 什么是 ioc
- spring mvc 運行流程
- 什么是 spring boot?
- 為什么要用 spring boot?
- 8.Redis
- 什么是Redis
- Redis 的功能
- Redis 和 memcache
- Redis 為什么是單執行緒的
- 快取穿透
- Redis 資料型別
- 配套資料
- Redis 深度歷險:核心原理與應用實踐
- 9.Zookeeper
- 什么是zookeeper
- zookeeper 的功能
- zookeeper 的部署模式
- 10.Kafka
- kafka和zookeeper的關系
- kafka的資料保留的策略?
- kafka性能瓶頸
- kafka集群
- 配套資料
- Apache Kafka實戰
- 11.ES
- 12.Dubbo
- 13.SpringCloud
- 什么是 spring cloud
- spring cloud 的核心組件
- 斷路器的作用
- 配套資料
- 14.Nginx
- 15.Netty
- 16.架構設計
- V0——單體架構
- V1——負載均衡
- V2——服務限流
- V3 同步狀態
- V4執行緒優化
- V5業務邏輯
- V6流量削峰
- 17.Linux
- 18.Git
- 命令大全
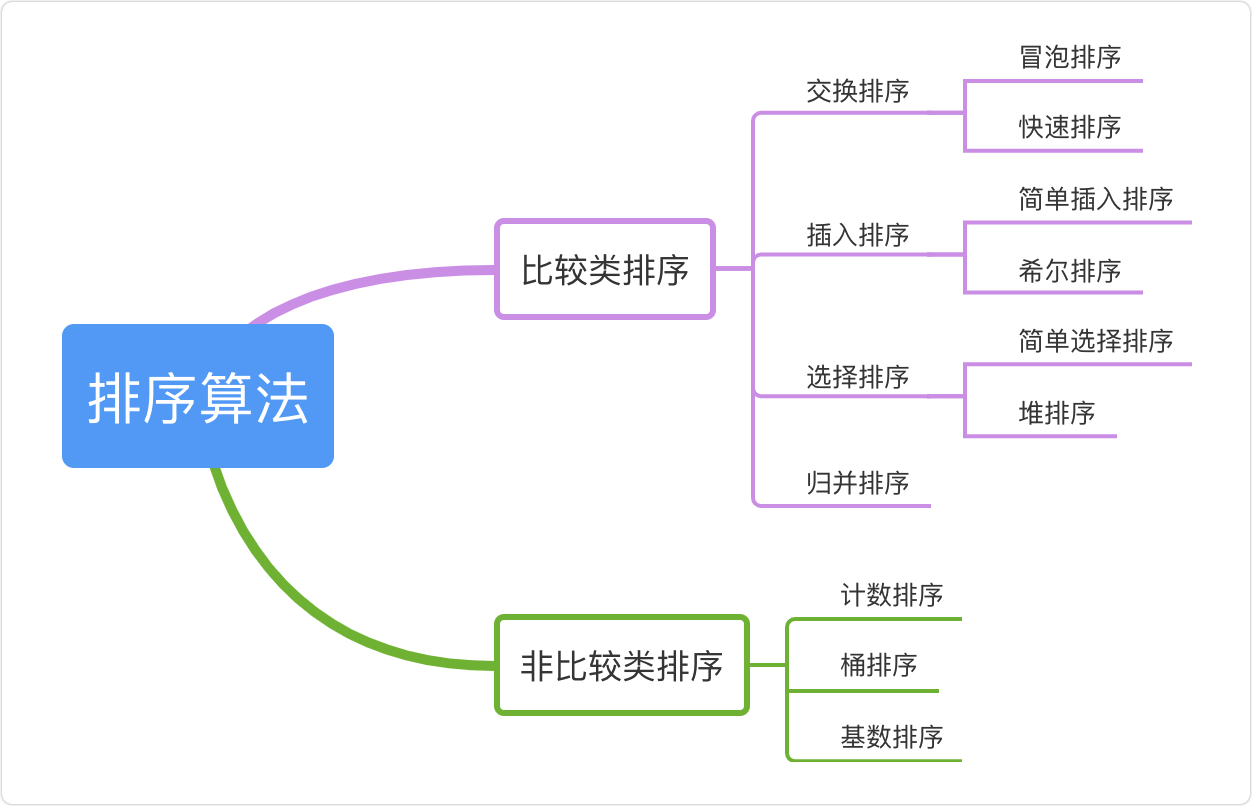
- 19.資料結構和演算法
- 排序演算法
- leetcode刷題
- 20.計算機網路
- 21.作業系統
- 22.計算機組成原理
- 23.程式員英語
- 24.寫作能力
- 25.演講能力
- 26.管理能力
- 配套資料
- 1.阿里巴巴Java開發手冊
- 2.程式員一條
- 3.Java核心知識點
- 4.204道全路線面試題合集
自學路線
0.貴在堅持
Java學習,如逆水行舟,不進則退,而自學,逆水還得加個水逆,難上加難,
所以我們要做好打持久戰的準備,
按計劃行事
凡事預則立,不預則廢,一個好的計劃是成功的一半,而這一半,一條已經幫你整理好了,你只需要收藏即可,
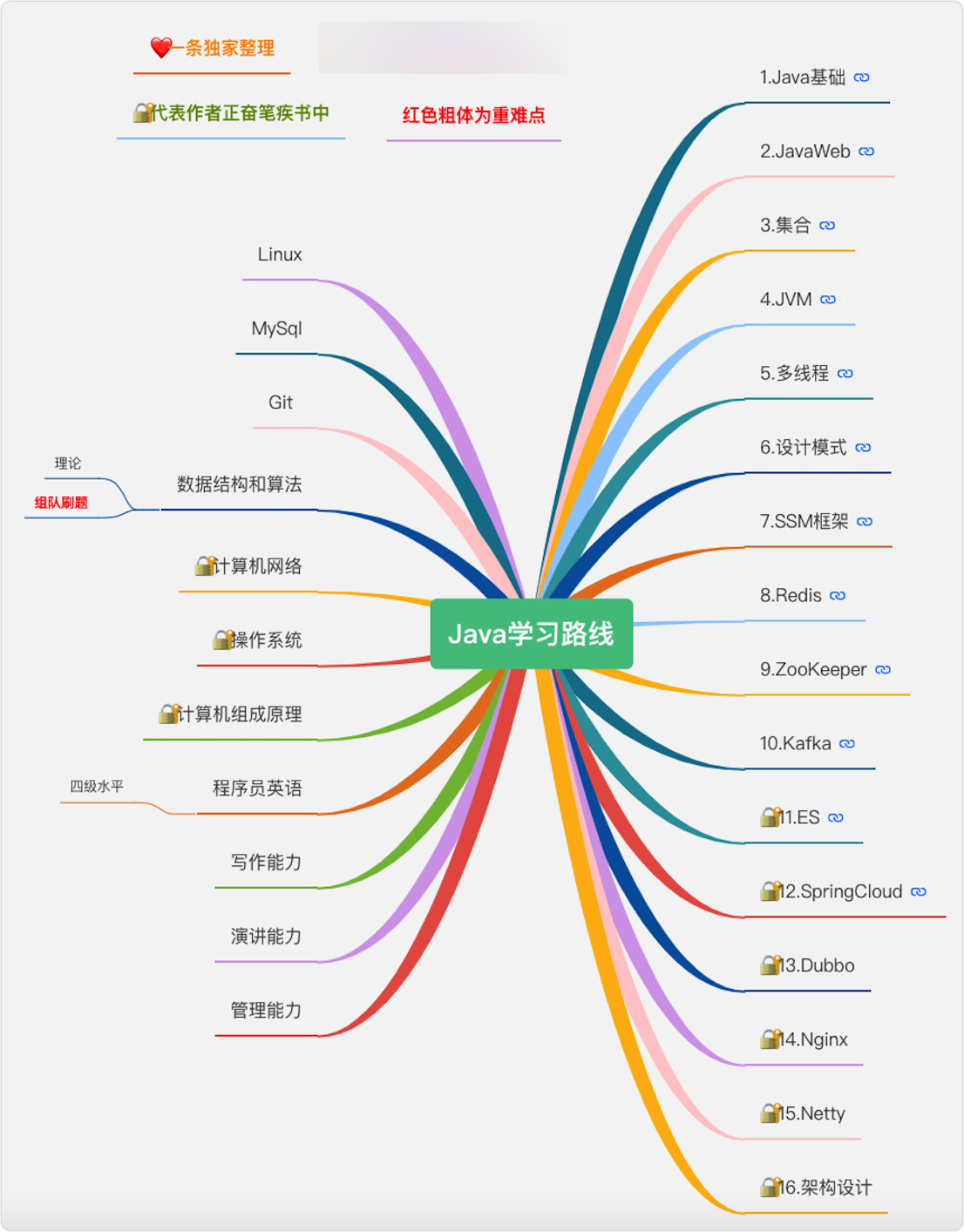
該路線圖右側為主路線,需循序漸進,步步為營;左側為輔助路線,需貫穿始終,熟練掌握,
建議做好時間規劃,不斷的提高自己的學習效率,學習程序中盡量把手機調至靜音給自己一個安靜的學習環境和氛圍,
貴在堅持
駑馬十駕,功在不舍,自學Java非一日之功,你知道的越多,不知道的也越多,所以,為自己找一個動力,為了改變命運,或是為了心愛的人,或是為了讓別人高看一眼,男兒何不帶吳鉤,收取關山十五州,歲月無情,余生有涯,請將生活扛在肩上,只顧風雨兼程,
抱團生長
獨腳難行,孤掌難鳴,一個人的力量終究是有限的,一個人的旅途也注定是孤獨的,當你定好計劃,懷著滿腔熱血準備出發的時候,一定要找個伙伴,和唐僧西天取經一樣,師徒四人團結一心才能通過九九八十一難,
在學習程序中看下自己身邊有沒有Java這方面的大神,盡量多問,多交流,如果沒有的話,來找我,我一定知無不言言無不盡,還可以給你找一群志同道合的人,水漲船高,柴多火旺,就是這個道理,閉門造車注定會半途而廢,
1.Java基礎
學習任何語言,都是先從他的基本語法開始,如果你有C語言的基礎,會容易許多,沒有也不用現學,
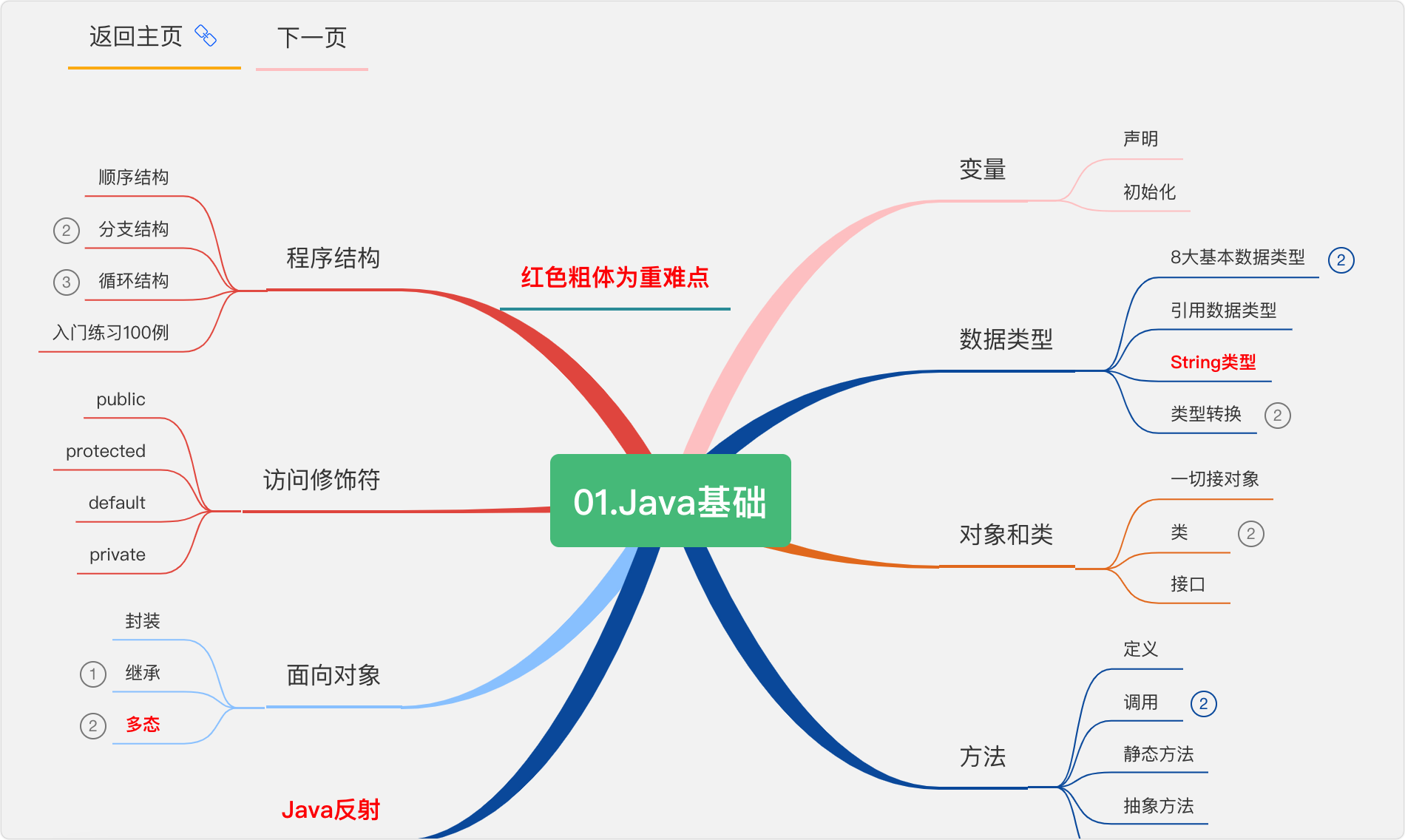
基本資料型別
Java 語言提供了 8 種基本型別,大致分為 4 類(8位=1位元組)
- 整數型
byte- 1位元組short- 2位元組int- 4位元組long- 8位元組,賦值時一般在數字后加上l或L
- 浮點型
float- 4位元組,直接賦值時必須在數字后加上f或Fdouble- 8位元組,賦值時一般在數字后加d或D
- 字符型
char- 2位元組,存盤 Unicode 碼,用單引號賦值
- 布爾型
boolean- 1位元組,只有 true 和 false 兩個取值,一個位元組就夠了
參考資料型別
簡單來說,所有的非基本資料型別都是參考資料型別,除了基本資料型別對應的參考型別外,類、 介面型別、 陣列型別、 列舉型別、 注解型別、 字串型都屬于參考型別,
主要有以下區別:
1、存盤位置
- 基本變數型別在方法中定義的非全域基本資料型別變數的具體內容是存盤在堆疊中的
- 參考資料型別變數其具體內容都是存放在堆中的,而堆疊中存放的是其具體內容所在記憶體的地址
2、傳遞方式
- 基本資料型別是按值傳遞
- 參考資料型別是按參考傳遞
面向物件三大特性
封裝
1.什么是封裝
封裝又叫隱藏實作,就是只公開代碼單元的對外介面,而隱藏其具體實作,
其實生活中處處都是封裝,手機,電腦,電視這些都是封裝,你只需要知道如何去操作他們,并不需要知道他們里面是怎么構造的,怎么實作這個功能的,
2.如何實作封裝
在程式設計里,封裝往往是通過訪問控制實作的,也就是剛才提到的訪問修飾符,
3.封裝的意義
封裝提高了代碼的安全性,使代碼的修改變的更加容易,代碼以一個個獨立的單元存在,高內聚,低耦合,
好比只要你手機的充電介面不變,無論以后手機怎么更新,你依然可以用同樣的資料線充電或者與其他設備連接,
封裝的設計使使整個軟體開發復雜度大大降低,我只需要使用別人的類,而不必關心其內部邏輯是如何實作的,我能很容易學會使用別人寫好的代碼,這就讓軟體協同開發的難度大大降低,
封裝還避免了命名沖突的問題,
好比你家里有各種各樣的遙控器,但比還是直到哪個是電視的,哪個是空調的,因為一個屬于電視類一個屬于空調類,不同的類中可以有相同名稱的方法和屬性,但不會混淆,
繼承
繼承的主要思想就是將子類的物件作為父類的物件來使用,比如王者榮耀的英雄作為父類,后裔作為子類,后裔有所有英雄共有的屬性,同時也有自己獨特的技能,
多型
多型的定義:
指允許不同類的物件對同一訊息做出回應,即同一訊息可以根據發送物件的不同而采用多種不同的行為方式,(發送訊息就是函式呼叫)
簡單來說,同樣呼叫攻擊這個方法,后裔的普攻和亞瑟的普攻是不一樣的,
多型的條件:
- 要有繼承
- 要有重寫
- 父類參考指向子類物件
多型的好處:
多型對已存在代碼具有可替換性,
多型對代碼具有可擴充性,
它在應用中體現了靈活多樣的操作,提高了使用效率,
多型簡化對應用軟體的代碼撰寫和修改程序,尤其在處理大量物件的運算和操作時,這個特點尤為突出和重要,
Java中多型的實作方式:
- 介面實作
- 繼承父類進行方法重寫
- 同一個類中進行方法多載
完整講解
Java基礎完整講解
入門練習案例
《入門練習100例》
配套資料
1.Java核心技術卷一、二
全書共14章,包括Java基本的程式結構、物件與類、繼承、介面與內部類、圖形程式設計、事件處理、Swing用戶界面組件、部署應用程式和Applet、例外日志斷言和除錯、敘述方式深入淺出,并包含大量示例,從而幫助讀者充分理解Java語言以及Java型別庫的相關特性,

2.學習視頻
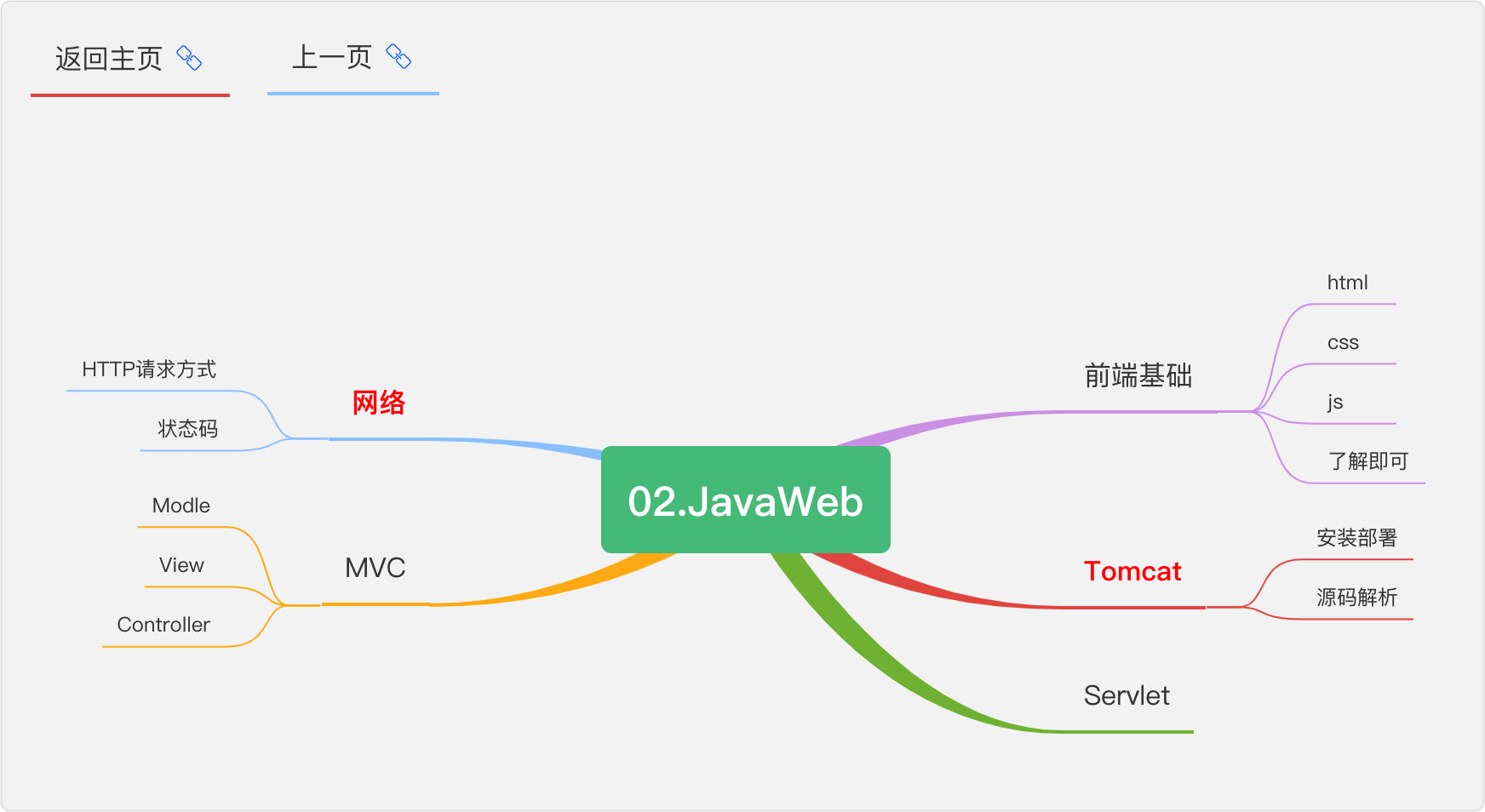
2.JavaWeb
本章難度不高,但也不可忽視,其中前端基礎不需花過多時間,重點放在Tomcat上,會陪伴你整個Java生涯,
JavaWeb是用Java技術來解決相關web互聯網領域的技術堆疊,Web就是網頁,分為靜態和動態,涉及 的知識點主要包括jsp,servlet,tomcat,http,MVC等知識,
HTTP網路請求方式
GET:最常用的方式,用來向服務器請求資料,沒有請求體,請求引數放在URL后面,POST:用于向表單提交資料,傳送的資料放在請求體中,PUT:用來向服務器上傳檔案,一般對應修改操作,POST用于向服務器發送資料,PUT用于向服務器儲存資料,沒有驗證機制,任何人都可以操作,存在安全問題,具有冪等性,DELETE:用于洗掉服務器上的檔案,具有冪等性,同樣存在安全問題,HEAD:用HEAD進行請求服務器時,服務器只回傳回應頭,不回傳回應體,與GET一樣沒有請求體,常用于檢查請求的URL是否有效,PATCH:對資源進行部分修改,與PUT區別在于,PUT是修改所有資源,替代它,而PATCH只是修改部分資源,TRACE:用來查看一個請求,經過網關,代理到達服務器,最后請求的變換,因安全問題被禁用,OPTIONS:當客戶端不清楚對資源操作的方法,可以使用這個,具有冪等性,
GET和POST
- 作用不同:GET 用于獲取資源,而 POST 用于傳輸物體主體,
- 引數位置不一樣: GET 的引數是以查詢字串出現在 URL 中,而 POST 的引數存盤在物體主體中,雖然GET的引數暴露在外面,但可以通過加密的方式處理,而 POST 引數即使存盤在物體主體中,我們也可以通過一些抓包工具如(Fiddler)查看,
- 冪等性:GET是冪等性,而POST不是冪等性,(面試官緊接著可能就會問你什么是冪等性?如何保證冪等性?)
- 安全性:安全的 HTTP 方法不會改變服務器狀態,也就是說它只是可讀的, GET 方法是安全的,而 POST 卻不是,因為 POST 的目的是傳送物體主體內容,這個內容可能是用戶上傳的表單資料,上傳成功之后,服務器可能把這個資料存盤到資料庫中,因此狀態也就發生了改變,
常見的網路狀態碼
網路狀態碼共三位數字組成,根據第一個數字可分為以下幾個系列:
1xx(資訊性狀態碼)
代表請求已被接受,需要繼續處理,
包括:100、101、102
這一系列的在實際開發中基本不會遇到,可以略過,
2xx(成功狀態碼)
表示成功處理了請求的狀態代碼,
200:請求成功,表明服務器成功了處理請求,
202:服務器已接受請求,但尚未處理,
204:服務器成功處理了請求,但沒有回傳任何內容,
206:服務器成功處理了部分 GET 請求,
3xx(重定向狀態碼)
300:針對請求,服務器可執行多種操作,
301:永久重定向
302:臨時性重定向
303:303與302狀態碼有著相同的功能,但303狀態碼明確表示客戶端應當采用GET方法獲取資源,
301和302的區別?
301比較常用的場景是使用域名跳轉,比如,我們訪問 http://www.baidu.com 會跳轉到https://www.baidu.com,發送請求之后,就會回傳301狀態碼,然后回傳一個location,提示新的地址,瀏覽器就會拿著這個新的地址去訪問,
302用來做臨時跳轉比如未登陸的用戶訪問用戶中心重定向到登錄頁面,
4xx(客戶端錯誤狀態碼)
400:該狀態碼表示請求報文中存在語法錯誤,但瀏覽器會像200 OK一樣對待該狀態碼,
401:表示發送的請求需要有通過HTTP認證的認證資訊,比如token失效就會出現這個問題,
403:被拒絕,表明對請求資源的訪問被服務器拒絕了,
404:找不到,表明服務器上無法找到請求的資源,也可能是拒絕請求但不想說明理由,
5xx(服務器錯誤狀態碼)
500:服務器本身發生錯誤,可能是Web應用存在的bug或某些臨時的故障,
502:該狀態碼表明服務器暫時處于超負載或正在進行停機維護,現在無法處理請求,
??有時候回傳的狀態碼回應是錯誤的,比如Web應用程式內部發生錯誤,狀態碼依然回傳200
轉發和重定向
上面提到了重定向,那你知道什么是轉發嗎?
1.轉發
A找B借錢,B沒有錢,B去問C,C有錢,C把錢借給A的程序,
客戶瀏覽器發送http請求,web服務器接受此請求,呼叫內部的一個方法在容器內部完成請求處理和轉發動作,將目標資源發送給客戶,
整個轉發一個請求,一個回應,地址欄不會發生變化,不能跨域訪問,
2.重定向
A找B借錢,B沒有錢,B讓A去找C,A又和C借錢,C有錢,C把錢借給A的程序,
客戶瀏覽器發送http請求,web服務器接受后發送302狀態碼回應及對應新的location給客戶瀏覽器,客戶瀏覽器發現是302回應,則自動再發送一個新的http請求,請求url是新的location地址,服務器根據此請求尋找資源并發送給客戶,
兩個請求,兩個回應,可以跨域,
Servlet
servlet是一個比較抽獎的概念,也是web部分的核心組件,大家回答這個問題一定要加入自己的理解,不要背定義,
servlet其實就是一個java程式,他主要是用來解決動態頁面的問題,
之前都是瀏覽器像服務器請求資源,服務器(tomcat)回傳頁面,但用戶多了之后,每個用戶希望帶到不用的資源,這時就該servlet上場表演了,
servlet存在于tomcat之中,用來網路請求與回應,但他的重心更在于業務處理,我們訪問京東和淘寶的回傳的商品是不一樣的,就需要程式員去撰寫,目前MVC三層架構,我們都是在service層處理業務,但這其實是從servlet中抽取出來的,
看一下servlet處理請求的程序:
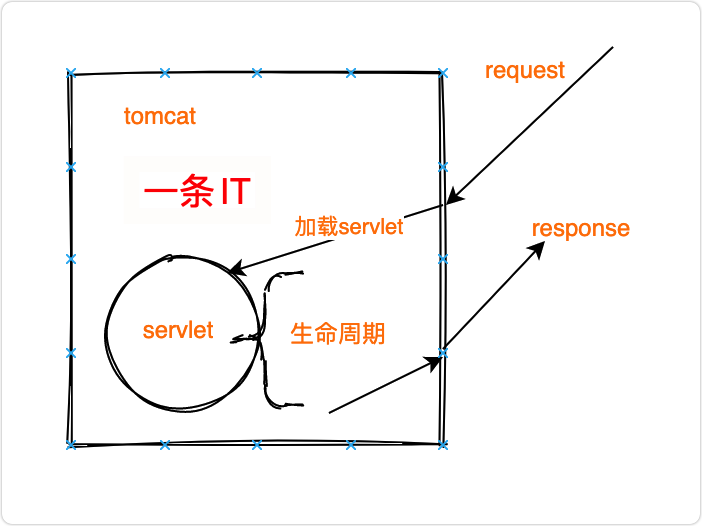
Servlet的生命周期
Servlet生命周期分為三個階段:
- 初始化階段 呼叫init()方法
- 回應客戶請求階段 呼叫service()方法-àdoGet/doPost()
- 終止階段 呼叫destroy()方法
MVC與三層架構
三層架構與MVC的目標一致:都是為了解耦和、提高代碼復用,MVC是一種設計模式,而三層架構是一種軟體架構,
MVC
Model 模型
模型負責各個功能的實作(如登錄、增加、洗掉功能),用JavaBean實作,
View 視圖
用戶看到的頁面和與用戶的互動,包含各種表單, 實作視圖用到的技術有html/css/jsp/js等前端技術,
常用的web 容器和開發工具
Controller 控制器
控制器負責將視圖與模型一一對應起來,相當于一個模型分發器,接收請求,并將該請求跳轉(轉發,重定向)到模型進行處理,模型處理完畢后,再通過控制器,回傳給視圖中的請求處,
三層架構
表現層(UI)(web層)、業務邏輯層(BLL)(service層)、資料訪問層(DAL)(dao層) ,再加上物體類別庫(Model)
- 物體類別庫(Model),在Java中,往往將其稱為Entity物體類,資料庫中用于存放資料,而我們通常選擇會用一個專門的類來抽象出資料表的結構,類的屬性就一對一的對應這表的屬性,一般來說,Model物體類別庫層需要被DAL層,BIL層和UI層參考,
- 資料訪問層(DAL),主要是存放對資料類的訪問,即對資料庫的添加、洗掉、修改、更新等基本操作,DAL就是根據業務需求,構造SQL陳述句,構造引數,呼叫幫助類,獲取結果,DAL層被BIL層呼叫
- 業務邏輯層(BLL),BLL層好比是橋梁,將UI表示層與DAL資料訪問層之間聯系起來,所要負責的,就是處理涉及業務邏輯相關的問題,比如在呼叫訪問資料庫之前,先處理資料、判斷資料,
session、cookie、token
首先我們要明白HTTP是一種無狀態協議,怎么理解呢?很簡單
夏洛:大爺,樓上322住的是馬冬梅家吧?
大爺:馬冬什么?
夏洛:馬冬梅,
大爺:什么冬梅啊?
夏洛:馬冬梅啊,
大爺:馬什么梅?
夏洛:行,大爺你先涼快著吧,
這段對話都熟悉吧,HTTP就是那個大爺,那如果我們就直接把“大爺”放給用戶,用戶不用干別的了,就不停的登錄就行了,
既然“大爺不靠譜”,我們找“大娘”去吧,
哈哈哈,開個玩笑,言歸正傳,
為了解決用戶頻繁登錄的問題,在服務端和客戶端共同維護一個狀態——會話,就是所謂session,我們根據會話id判斷是否是同一用戶,這樣用戶就開心了,
但是服務器可不開心了,因為用戶越來越多,都要把session存在服務器,這對服務器來說是一個巨大的開銷,這是服務器就找來了自己的兄弟幫他分擔(集群部署,負載均衡),
但是問題依然存在,如果兄弟掛了怎么辦,兄弟們之間的資料怎么同步,用戶1把session存放在機器A上,下次訪問時負載均衡到了機器B,完了,找不到,用戶又要罵娘,
這時有人思考,為什么一定要服務端保存呢,讓客戶端自己保存不就好了,所以就誕生了cookie,下一次請求時客戶段把cookie發送給服務器,說我已經登錄了,
但是空口無憑,服務器怎么知道哪個cookie是我發過去的呢?如何驗證成了新的問題,
有人想到了一個辦法,用加密令牌,也就是token,服務器發給客戶端一個令牌,令牌保存加密后id和密鑰,下一次請求時通過headers傳給服務端,由于密鑰別人不知道,只有服務端知道,就實作了驗證,且別人無法偽造,
完整講解
JavaWeb完整講解
3.集合
工欲善其事必先利其器,集合就是我們的器,
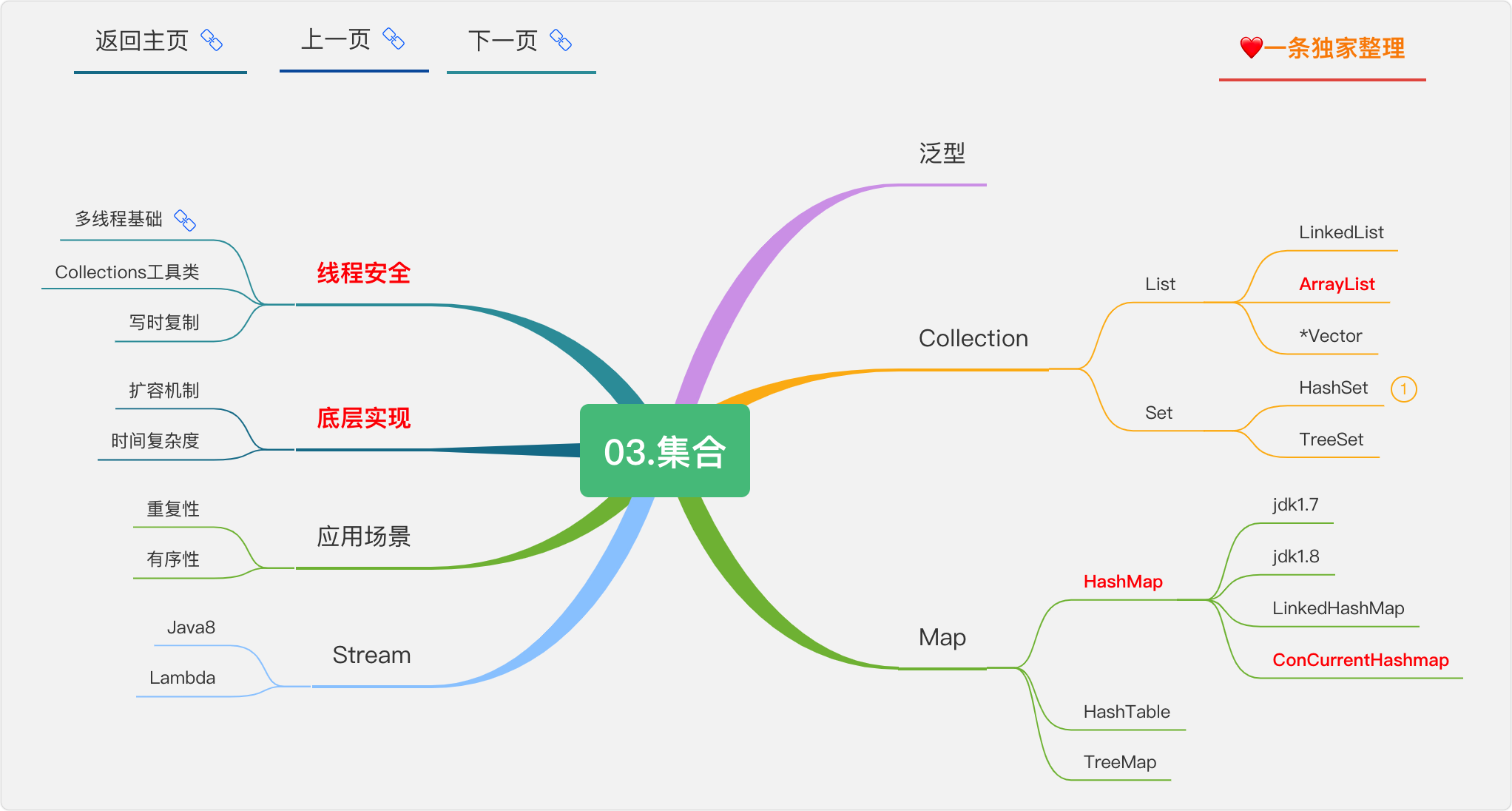
ArrayList
底層實作
由什么組成,我說了不算,看原始碼,怎么看呢?
List<Object> list = new ArrayList<>();新建一個
ArrayList,按住ctrl或command用滑鼠點擊,
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
* 翻譯
* 陣列緩沖區,ArrayList的元素被存盤在其中,ArrayList的容量是這個陣列緩沖區的長度,
* 任何空的ArrayList,如果elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA,
* 當第一個元素被添加時,將被擴展到DEFAULT_CAPACITY,
*/
transient Object[] elementData;
毋庸置疑,底層由陣列組成,那陣列的特點就是ArrayList的特點,
- 由于陣列以一塊連續的記憶體空間,每一個元素都有對應的下標,查詢時間復雜度為
O(1),好比你去住酒店,每個房間都挨著,房門都寫著房間號,你想找哪一間房是不是很容易, - 相對的,一塊連續的記憶體空間你想打破他就沒那么容易,牽一發而動全身,所以新增和洗掉的時間復雜度為
O(n),想像你在做excel表格的時候,想增加一列,后面的列是不是都要跟著移動, - 元素有序,可重復,可用在大多數的場景,這個就不需要過多解釋了,
擴容
我們知道陣列是容量不可變的資料結構,隨著元素不斷增加,必然要擴容,
所以擴容機制也是集合中非常容易愛問的問題,在原始碼中都可以一探究竟,
1.初始化容量為10,也可以指定容量創建,
/**
* Default initial capacity.
* 定義初始化容量
*/
private static final int DEFAULT_CAPACITY = 10;
2.陣列進行擴容時,是將舊資料拷貝到新的陣列中,新陣列容量是原容量的1.5倍,(這里用位運算是為了提高運算速度)
private void grow(int minCapacity) {
int newCapacity = oldCapacity + (oldCapacity >> 1);
}
3.擴容代價是很高得,因此再實際使用時,我們因該避免陣列容量得擴張,盡可能避免資料容量得擴張,盡可能,就至指定容量,避免陣列擴容的發生,
為什么擴容是1.5倍?
- 如果大于1.5,也就是每次擴容很多倍,但其實我就差一個元素的空間,造成了空間浪費,
- 如果小于1.5,擴容的意義就不大了,就會帶來頻繁擴容的問題,
所以,1.5是均衡了空間占用和擴容次數考慮的,
執行緒安全問題
怎么看執行緒安全?說實話我以前都不知道,看網上說安全就安全,說不安全就不安全,
其實都在原始碼里,找到增加元素的方法,看看有沒有加鎖就知道了,
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
沒有加鎖,所以執行緒不安全
在多執行緒的情況下,插入資料的時可能會造成資料丟失,一個執行緒在遍歷,另一個執行緒修改,會報ConcurrentModificationException(并發修改例外)錯誤.
多執行緒下使用怎么保證執行緒安全?
保證執行緒安全的思路很簡單就是加鎖,但是你可沒辦法修改原始碼去加個鎖,但是你想想撰寫
java的大佬會想不到執行緒安全問題?早就給你準備了執行緒安全的類,
1.Vector
Vector是一個執行緒安全的List類,通過對所有操作都加上synchronized關鍵字實作,
找到add方法,可以看到被synchronized關鍵字修飾,也就是加鎖,但synchronized是重度鎖,并發性太低,所以實際一般不使用,隨著java版本的更新,慢慢廢棄,
public void add(E e) {
int i = cursor;
synchronized (Vector.this) {
checkForComodification();
Vector.this.add(i, e);
expectedModCount = modCount;
}
cursor = i + 1;
lastRet = -1;
}
2.Collections
注意是Collections而不是Collection,
Collections位于java.util包下,是集合類的工具類,提供了很多操作集合類的方法,其中Collections.synchronizedList(list)可以提供一個執行緒安全的List,
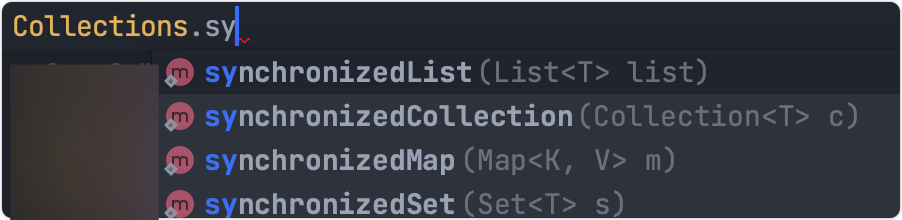
對于Map、Set也有對應的方法
3.CopyOnWrite(寫時復制)
寫時復制,簡稱COW,是計算機程式設計領域中的一種通用優化策略,
當有多人同時訪問同一資源時,他們會共同獲取指向相同的資源的指標,供訪問者進行讀操作,
當某個呼叫者修改資源內容時,系統會真正復制一份副本給該呼叫者,而其他呼叫者所見到的最初的資源仍然保持不變,修改完成后,再把新的資料寫回去,
通俗易懂的講,假設現在有一份班級名單,但有幾個同學還沒有填好,這時老師把檔案通過微信發送過去讓同學們填寫(復制一份),但不需要修改的同學此時查看的還是舊的名單,直到有同學修改好發給老師,老師用新的名單替換舊的名單,全班同學才能查看新的名單,
共享讀,分開寫,讀寫分離,寫時復制,
在java中,通過CopyOnWriteArrayList、CopyOnWriteArraySet容器實作了 COW 思想,
平時查詢的時候,都不需要加鎖,隨便訪問,只有在更新的時候,才會從原來的資料復制一個副本出來,然后修改這個副本,最后把原資料替換成當前的副本,修改操作的同時,讀操作不會被阻塞,而是繼續讀取舊的資料,
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
原始碼里用到了ReentrantLock鎖和volatile關鍵字,會在《資深程式員修煉》專欄中做全面深度講解,
完整講解
集合完整講解
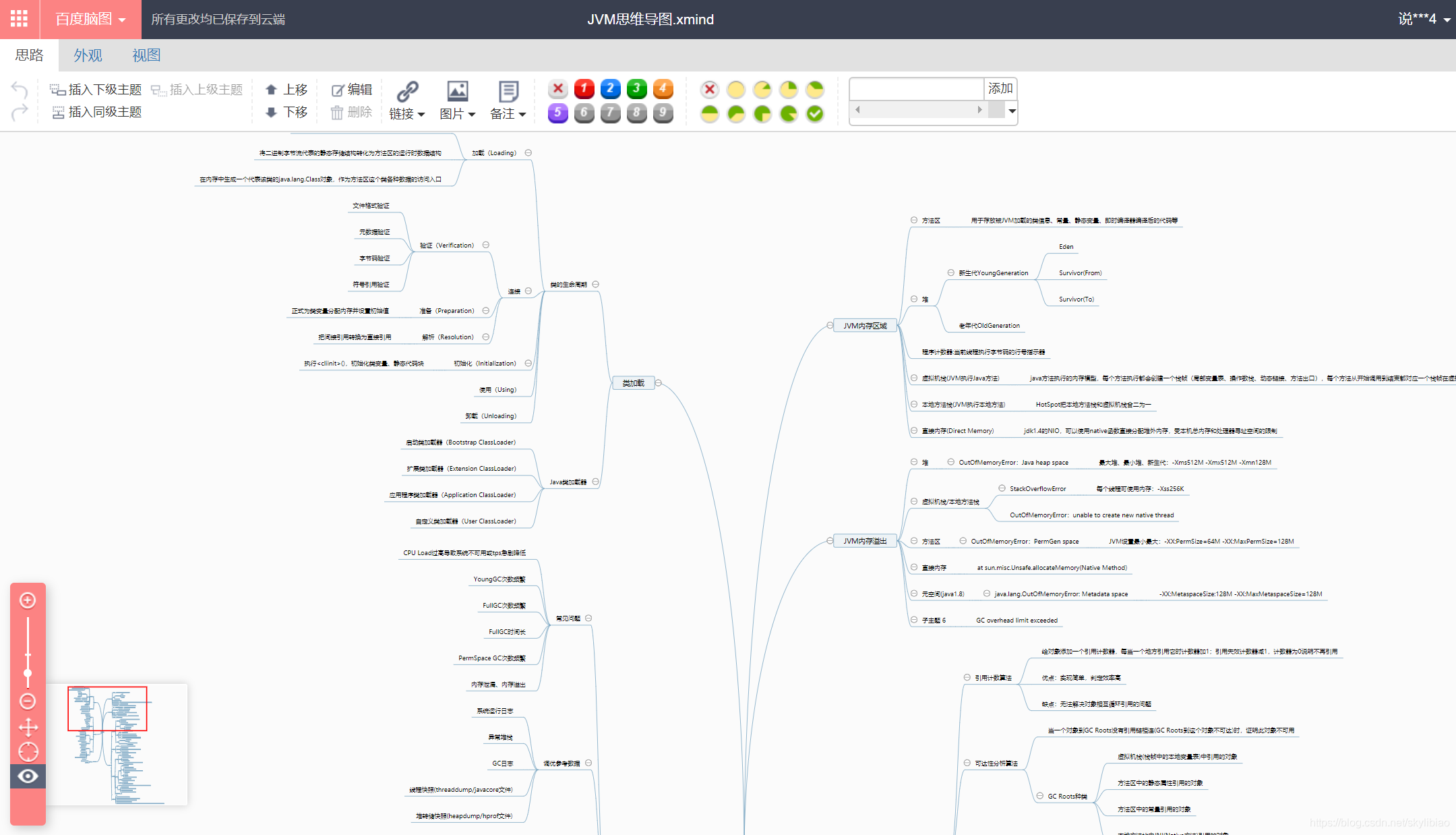
4.JVM
重點來了,Java程式員一定要深入研究的內容
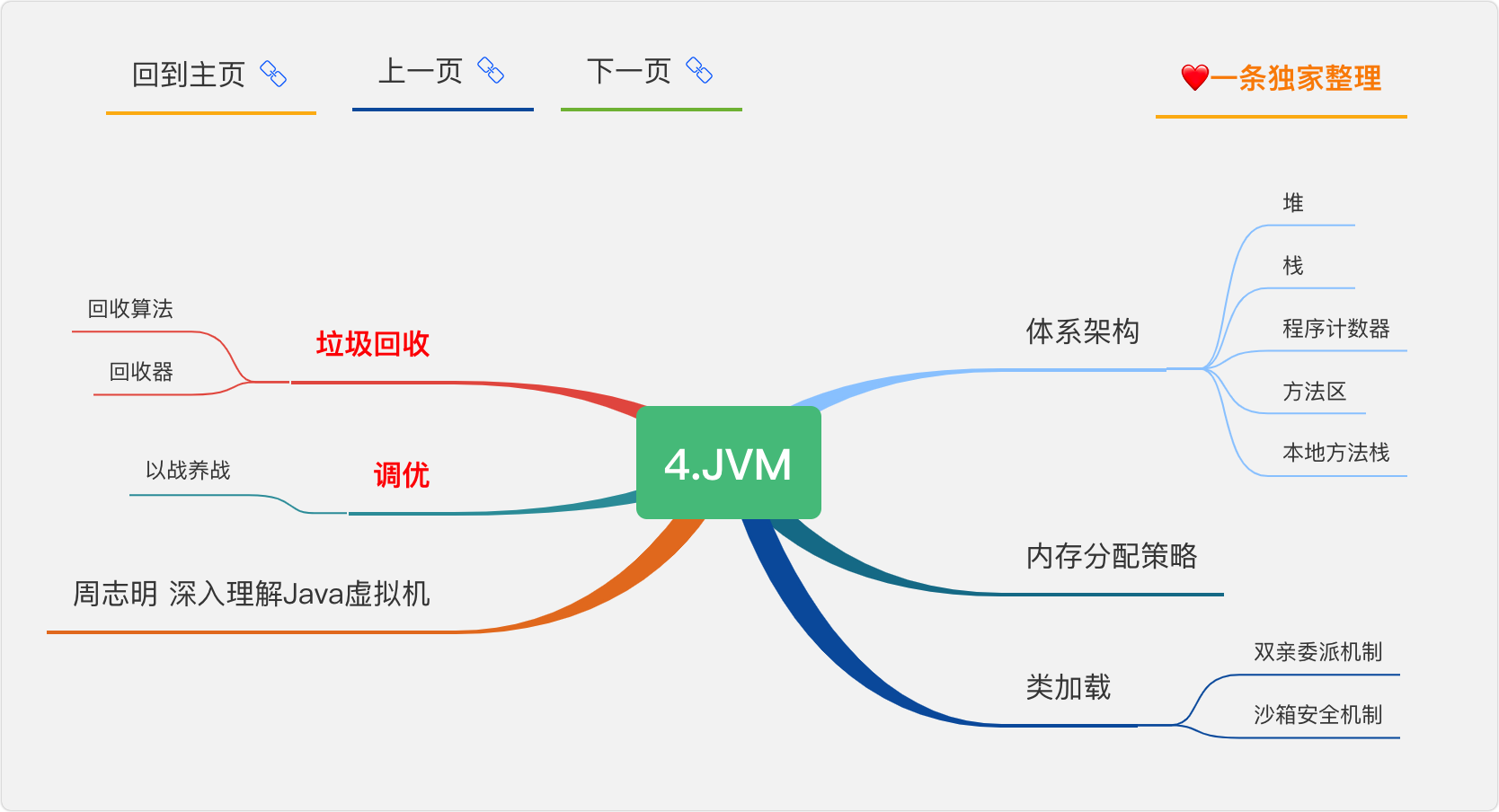
垃圾回收
垃圾回收是重點難,先理解了垃圾回收,才能理解調優的思路,
判斷垃圾
判斷是否是垃圾共有兩種方法,參考計數法和可達性分析
1.參考計數法
非常好理解,參考一次標記一次,沒有被標記的就是垃圾,
在堆中存盤物件時,在物件頭處維護一個counter計數器,如果一個物件增加了一個參考與之相連,則將counter++,
如果一個參考關系失效則counter--,如果一個物件的counter變為0,則說明該物件已經被廢棄,不處于存活狀態,此時可以被回收,
2.參考計數的缺點
- 效率低
- 無法分析回圈參考問題
3.可達性分析
類似樹的樹結構,從根結點出發,即GC root,把有關系的物件用一顆樹鏈接起來
那么我們遍歷這棵樹,沒遍歷到的物件,就是垃圾
4.有哪些可以做GC Roots的物件?
- 虛擬機堆疊(堆疊楨中的本地變數表)中的參考的物件
- 方法區中的類靜態屬性參考的物件
- 方法區中的常量參考的物件
- 本地方法堆疊中JNI(Native方法)的參考的物件
回收演算法
回收演算法是垃圾回收的思想,回收器是垃圾回收的實作
1.標記-清除
兩次遍歷:
- 標記垃圾
- 清除垃圾
優點:
- 不需要格外空間,適合回收物件較少的區域
缺點:
- 效率低,遍歷兩次,時間復雜度O(n^2)
- 會有執行緒停頓,
stop the world (STW) - 空間碎片,因為垃圾可能不是連續的,大量的空間碎片會導致提前GC,這也是最主要的問題,
2.標記-復制
將空間分為相等大小的兩部分,每次只使用其中的一塊,當這一塊的記憶體用完了,就將還存活著的物件復制到另外一塊上面,然后再把已使用的記憶體空間一次清理掉,這樣一來就不容易出現記憶體碎片的問題,犧牲空間解決碎片問題,
優點:
- 高效無碎片
缺點:
- 占用大量空間
3.標記-整理
同樣是為了解決空間碎片提出,區別是通過犧牲時間的方式,
和標記-清除類似,不一樣的是在完成標記之后,它不是直接清理可回收物件,而是將存活物件都向一端移動,然后清理掉端邊界以外的記憶體,
優點:
- 解決空間碎片的問題
- 不浪費空間
缺點:
- 相對比較耗時
完整講解
JVM完整講解
配套資料
1.深入理解Java虛擬機
附帶讀書筆記,
2.視頻
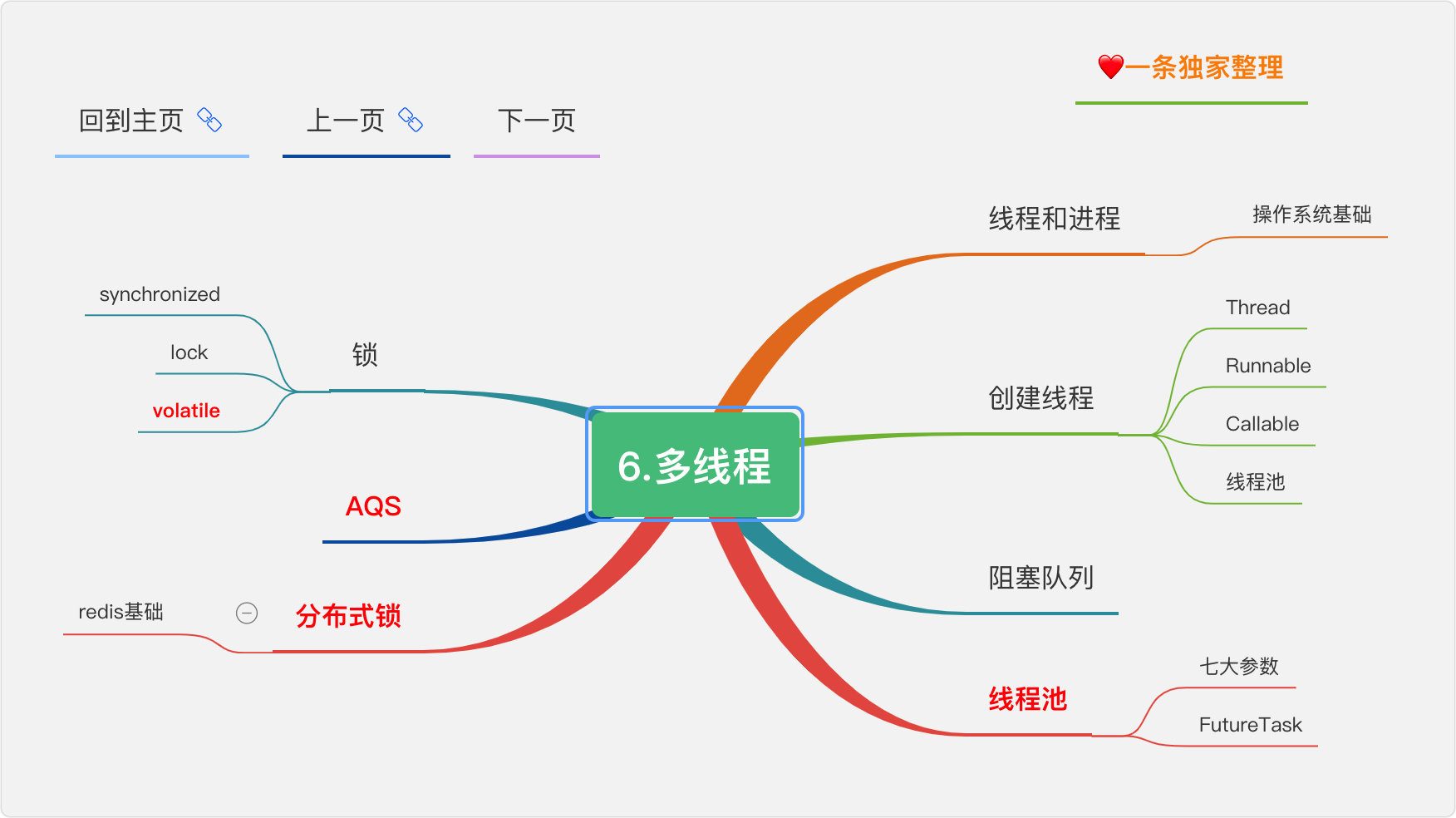
5.多執行緒
理解多執行緒,才能更好的理解框架原始碼,進行高并發的架構設計,重中之重,
并行和并發
并行:多個任務在同一個 CPU 核上,按細分的時間片輪流(交替)執行,從邏輯上來看那些任務是同時執行,
并發:多個處理器或多核處理器同時處理多個任務,
舉例:
并發 = 兩個佇列和一臺咖啡機,
并行 = 兩個佇列和兩臺咖啡機,
執行緒和行程
一個程式下至少有一個行程,一個行程下至少有一個執行緒,一個行程下也可以有多個執行緒來增加程式的執行速度,
守護執行緒
守護執行緒是運行在后臺的一種特殊行程,它獨立于控制終端并且周期性地執行某種任務或等待處理某些發生的事件,在 Java 中垃圾回收執行緒就是特殊的守護執行緒,
創建執行緒4種方式
-
繼承 Thread 重新 run 方法;
-
實作 Runnable 介面;
-
實作 Callable 介面,
-
執行緒池
synchronized 底層實作
synchronized 是由一對 monitorenter/monitorexit 指令實作的,monitor 物件是同步的基本實作單元,
在 Java 6 之前,monitor 的實作完全是依靠作業系統內部的互斥鎖,因為需要進行用戶態到內核態的切換,所以同步操作是一個無差別的重量級操作,性能也很低,
但在 Java 6 的時候,Java 虛擬機 對此進行了大刀闊斧地改進,提供了三種不同的 monitor 實作,也就是常說的三種不同的鎖:偏向鎖(Biased Locking)、輕量級鎖和重量級鎖,大大改進了其性能,
synchronized 和 volatile 的區別
volatile 是變數修飾符;synchronized 是修飾類、方法、代碼段,
volatile 僅能實作變數的修改可見性,不能保證原子性;而 synchronized 則可以保證變數的修改可見性和原子性,
volatile 不會造成執行緒的阻塞;synchronized 可能會造成執行緒的阻塞,
synchronized 和 ReentrantLock 區別
synchronized 早期的實作比較低效,對比 ReentrantLock,大多數場景性能都相差較大,但是在 Java 6 中對 synchronized 進行了非常多的改進,
主要區別如下:
ReentrantLock 使用起來比較靈活,但是必須有釋放鎖的配合動作;
ReentrantLock 必須手動獲取與釋放鎖,而 synchronized 不需要手動釋放和開啟鎖;
ReentrantLock 只適用于代碼塊鎖,而 synchronized 可用于修飾方法、代碼塊等,
volatile 標記的變數不會被編譯器優化;synchronized 標記的變數可以被編譯器優化,
synchronized 和 Lock 區別
synchronized 可以給類、方法、代碼塊加鎖;而 lock 只能給代碼塊加鎖,
synchronized 不需要手動獲取鎖和釋放鎖,使用簡單,發生例外會自動釋放鎖,不會造成死鎖,
lock 需要自己加鎖和釋放鎖,如果使用不當沒有 unLock()去釋放鎖就會造成死鎖,
通過 Lock 可以知道有沒有成功獲取鎖,而 synchronized 卻無法辦到,
配套資料
1 .java并發編程的藝術
《Java并發編程的藝術》內容涵蓋Java并發編程機制的底層實作原理、Java記憶體模型、Java并發編程基礎、Java中的鎖、并發容器和框架、原子類、并發工具類、執行緒池、Executor框架等主題,每個主題都做了深入的講解,同時通過實體介紹了如何應用這些技術,

6.設計模式
好多人覺得設計模式模式,那是因為你學的還不夠深入,還沒有看過原始碼,所以我特意將設計模式往前放了,
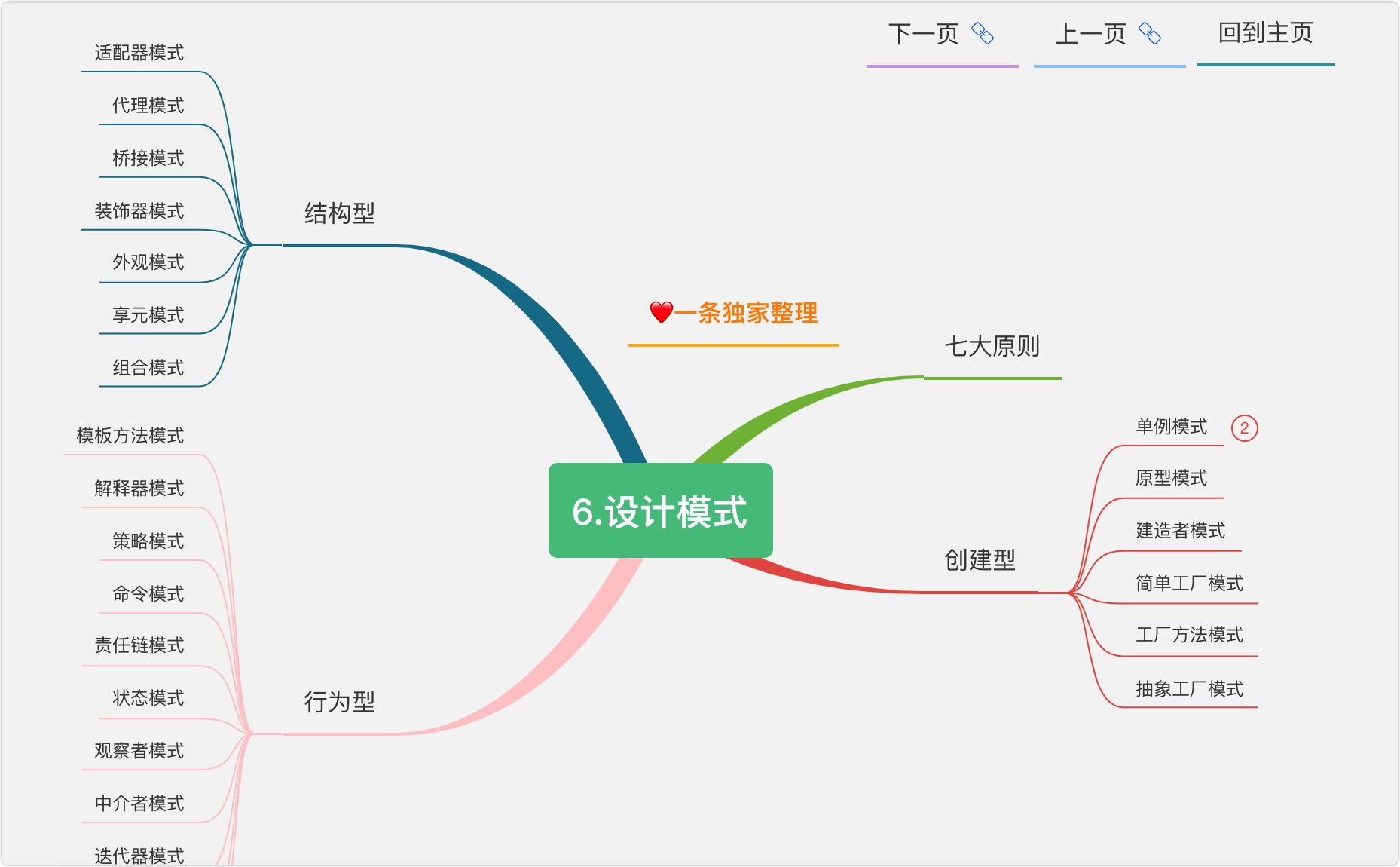
建造者模式
定義
官方定義
將一個復雜物件的構建與它的表示分離,使得同樣的構建程序可以創建不同的表示,
通俗解讀
提供一種創建物件的方式,創建的東西細節復雜,還必須暴露給使用者,屏蔽程序而不屏蔽細節,
類似建房子,只需要把材料和設計圖紙給工人,就能建成想要的房子,不關注工人建房子的程序,但對于細節,我們又可以自己設計,
結構圖
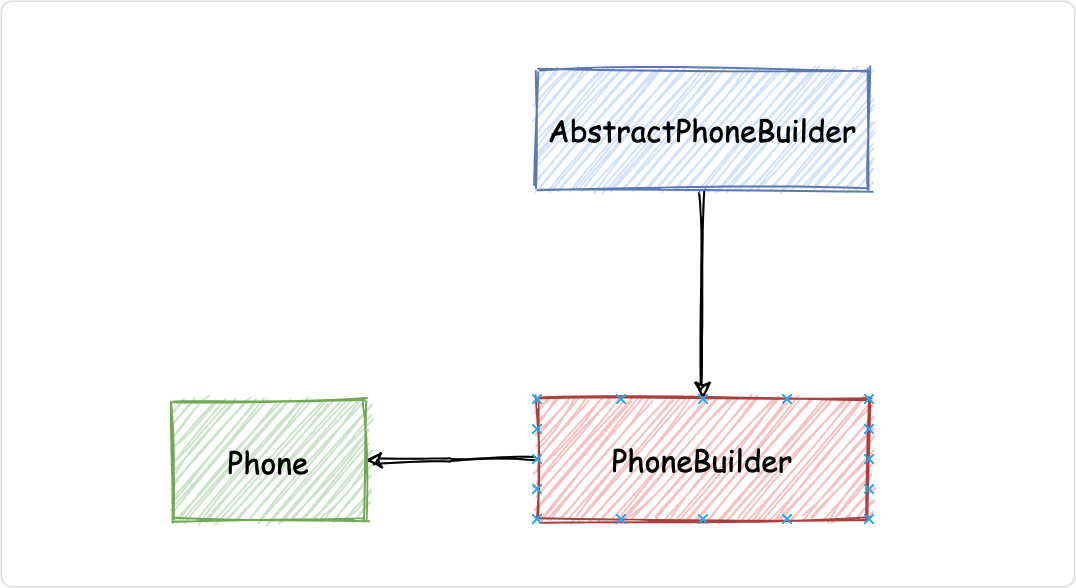
代碼演示
本文原始碼:建造者模式 提取碼: vpqt
目錄結構
建議跟著一條學設計模式的小伙伴都建一個maven工程,并安裝lombok依賴和插件,
并建立如下包目錄,便于歸納整理,
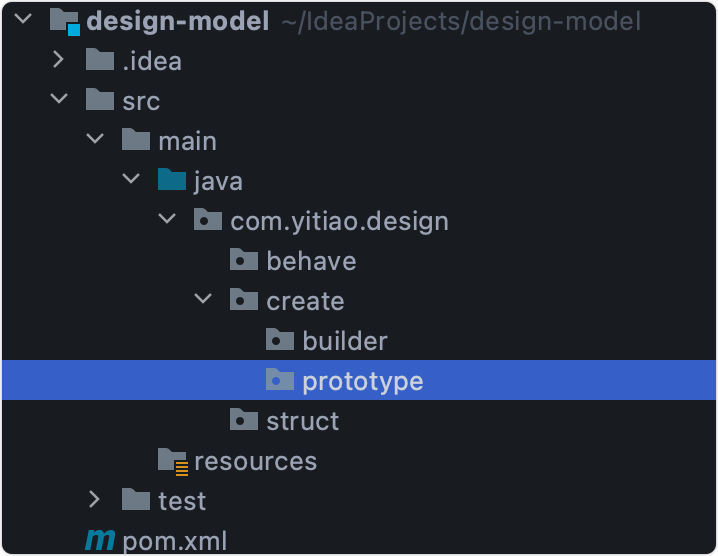
pom如下
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
</dependency>
開發場景
現在有一個手機的建造者,我要讓它為我生產不用品牌和配置的手機,該怎么實作?
代碼演示
1.創建手機類
@Data
public class Phone {
//處理器
protected String cpu;
//記憶體
protected String mem;
//磁盤
protected String disk;
//螢屏大小
protected String size;
}
2.創建建造者介面
//定義建造者的模板方法
public interface Builder {
Phone phone = new Phone();
void buildCpu(String cpu);
void buildMem(String mem);
void buildDisk(String disk);
void buildSize(String size);
default Phone getPhone(){
return phone;
}
}
3.創建Vivo手機的建造者
public class VivoPhoneBuilder implements Builder{
//建造者細節的實作
@Override
public void buildCpu(String cpu) {
phone.cpu=cpu;
}
@Override
public void buildMem(String mem) {
phone.mem=mem;
}
@Override
public void buildDisk(String disk) {
phone.disk=disk;
}
@Override
public void buildSize(String size) {
phone.size=size;
}
}
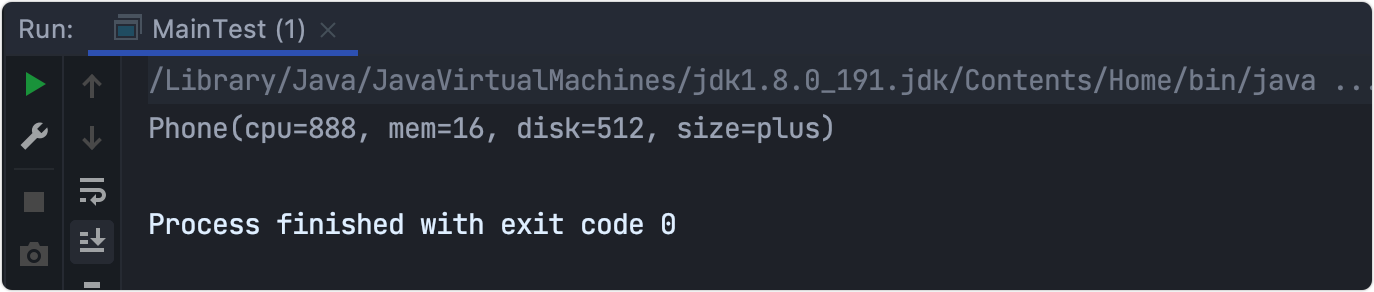
4.創建測驗類
public class MainTest {
public static void main(String[] args) {
VivoPhoneBuilder builder = new VivoPhoneBuilder();
builder.buildCpu("888");
builder.buildDisk("512");
builder.buildMem("16");
builder.buildSize("plus");
Phone phone = builder.getPhone();
System.out.println(phone);
}
}
5.輸出結果
如果我這時需要生產OPPO手機,只需新建一個OppoPhoneBuilder實作Builder介面即可,
鏈式呼叫
相信大家在開發中都遇見過這樣的代碼,像鏈子一樣可以一直呼叫下去,
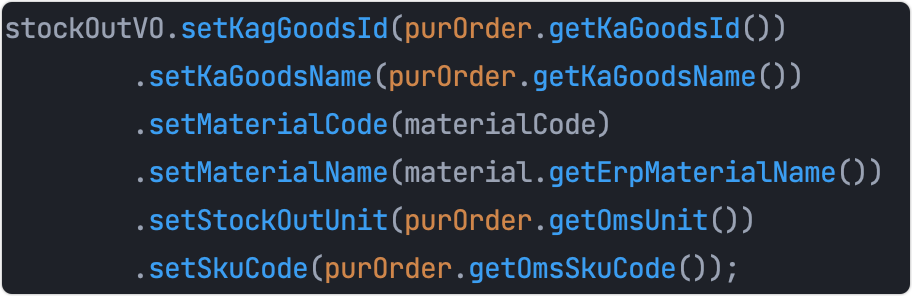
那么如何實作鏈式建造者呢?
有以下兩種方式:
1.修改回傳值為Builder
public interface Builder {
Phone phone = new Phone();
// void 改為 Builder 同步修改實作類
Builder buildCpu(String cpu);
Builder buildMem(String mem);
Builder buildDisk(String disk);
Builder buildSize(String size);
default Phone getPhone(){
return phone;
}
}
測驗1
public class MainTest {
public static void main(String[] args) {
// ……
VivoPhoneBuilder builder2 = new VivoPhoneBuilder();
Phone phone1 = builder2
.buildCpu("888")
.buildDisk("512")
.buildMem("16")
.buildSize("plus")
.getPhone();
System.out.println("phone1:"+phone1);
}
}
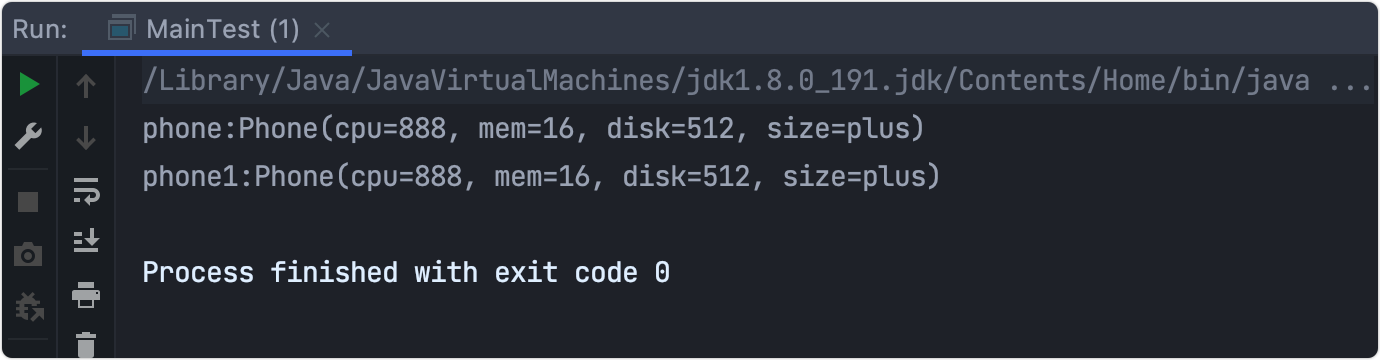
結果1
2.使用lombok
@Data
@Builder //使用鏈式建造者
@NoArgsConstructor
@AllArgsConstructor
public class Phone {
// ……
}
測驗2
public class MainTest {
public static void main(String[] args) {
// ……
Phone build = Phone.builder()
.cpu("888")
.mem("16")
.disk("512")
.size("plus").build();
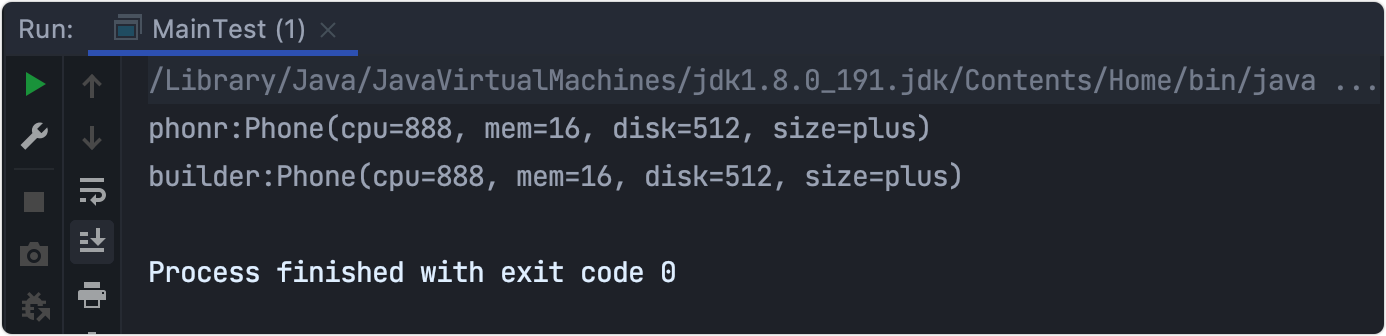
System.out.println("builder:"+build);
}
}
結果2
應用場景
- StringBuilder:
append();給誰append呢?
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
- Swagger-ApiBuilder;
- 快速實作:
Lombok-@Builder
總結
建造者模式提供了對于同一構建程序的不同表示,像流水線一樣生產物件,對于新增的物件,只需要創建對應的建造者即可,不需要修改源代碼,
lombok為我們提供了建造者模式的快速實作(@Builder),要應用到實際編碼中,
更多設計模式
更多設計模式
7.SSM框架
這對于初學者來說,是一個坎,前幾年學完這些,已經可以開始找作業了,所以恭喜你能堅持帶這里,勝利就在前方,
ORM 框架?
ORM(Object Relation Mapping)物件關系映射,是把資料庫中的關系資料映射成為程式中的物件,
使用 ORM 的優點:提高了開發效率降低了開發成本、開發更簡單更物件化、可移植更強,
MyBatis 中 #{}和 的區別
#是預編譯處理,{}的區別是什么?#{}是預編譯處理,的區別是什么?#是預編譯處理,{}是字符替換, 在使用 #{}時,MyBatis 會將 SQL 中的 #{}替換成“?”,配合 PreparedStatement 的 set 方法賦值,這樣可以有效的防止 SQL 注入,保證程式的運行安全,
什么是Spring
spring 提供 ioc 技術,容器會幫你管理依賴的物件,從而不需要自己創建和管理依賴物件了,更輕松的實作了程式的解耦,
spring 提供了事務支持,使得事務操作變的更加方便,
spring 提供了面向切片編程,這樣可以更方便的處理某一類的問題,
更方便的框架集成,spring 可以很方便的集成其他框架,比如 MyBatis、hibernate 等,
什么是 aop
aop 是面向切面編程,通過預編譯方式和運行期動態代理實作程式功能的統一維護的一種技術,
簡單來說就是統一處理某一“切面”(類)的問題的編程思想,比如統一處理日志、例外等,
什么是 ioc
ioc:Inversionof Control(中文:控制反轉)是 spring 的核心,對于 spring 框架來說,就是由 spring 來負責控制物件的生命周期和物件間的關系,
簡單來說,控制指的是當前物件對內部成員的控制權;控制反轉指的是,這種控制權不由當前物件管理了,由其他(類,第三方容器)來管理,
spring mvc 運行流程
spring mvc 先將請求發送給 DispatcherServlet,
DispatcherServlet 查詢一個或多個 HandlerMapping,找到處理請求的 Controller,
DispatcherServlet 再把請求提交到對應的 Controller,
Controller 進行業務邏輯處理后,會回傳一個ModelAndView,
Dispathcher 查詢一個或多個 ViewResolver 視圖決議器,找到 ModelAndView 物件指定的視圖物件,
視圖物件負責渲染回傳給客戶端,
什么是 spring boot?
spring boot 是為 spring 服務的,是用來簡化新 spring 應用的初始搭建以及開發程序的,
為什么要用 spring boot?
配置簡單
獨立運行
自動裝配
無代碼生成和 xml 配置
提供應用監控
易上手
提升開發效率
8.Redis
隨著QPS的逐漸升高,傳統的mysql資料庫已經無法滿足,所以有了基于記憶體的redis快取資料庫來存盤熱點資料,
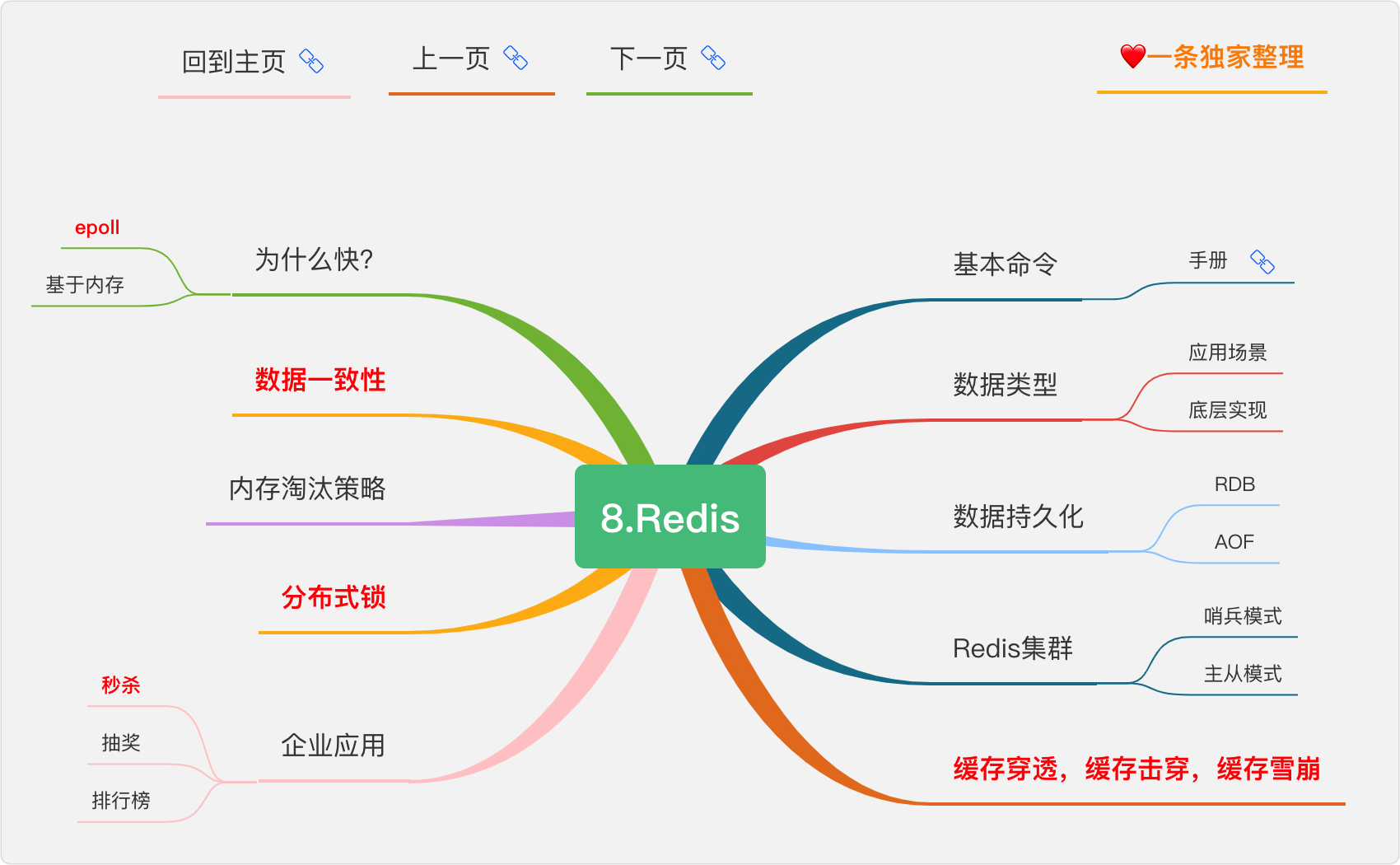
什么是Redis
Redis 是一個使用 C 語言開發的高速快取資料庫,
Redis 使用場景:
-
記錄帖子點贊數、點擊數、評論數;
-
快取近期熱帖;
-
快取文章詳情資訊;
-
記錄用戶會話資訊,
Redis 的功能
- 資料快取功能
- 分布式鎖的功能
- 支持資料持久化
- 支持事務
- 支持訊息佇列
Redis 和 memcache
存盤方式不同:memcache 把資料全部存在記憶體之中,斷電后會掛掉,資料不能超過記憶體大小;Redis 有部份存在硬碟上,這樣能保證資料的持久性,
資料支持型別:memcache 對資料型別支持相對簡單;Redis 有復雜的資料型別,
使用底層模型不同:它們之間底層實作方式,以及與客戶端之間通信的應用協議不一樣,Redis 自己構建了 vm 機制,因為一般的系統呼叫系統函式的話,會浪費一定的時間去移動和請求,
value 值大小不同:Redis 最大可以達到 1gb;memcache 只有 1mb,
Redis 為什么是單執行緒的
因為 cpu 不是 Redis 的瓶頸,Redis 的瓶頸最有可能是機器記憶體或者網路帶寬,既然單執行緒容易實作,而且 cpu 又不會成為瓶頸,那就順理成章地采用單執行緒的方案了,
關于 Redis 的性能,官方網站也有,普通筆記本輕松處理每秒幾十萬的請求,
而且單執行緒并不代表就慢 nginx 和 nodejs 也都是高性能單執行緒的代表,
快取穿透
快取穿透:指查詢一個一定不存在的資料,由于快取是不命中時需要從資料庫查詢,查不到資料則不寫入快取,這將導致這個不存在的資料每次請求都要到資料庫去查詢,造成快取穿透,
解決方案:最簡單粗暴的方法如果一個查詢回傳的資料為空(不管是資料不存在,還是系統故障),我們就把這個空結果進行快取,但它的過期時間會很短,最長不超過五分鐘,
Redis 資料型別
Redis 支持的資料型別:string(字串)、list(串列)、hash(字典)、set(集合)、zset(有序集合),
配套資料
Redis 深度歷險:核心原理與應用實踐
《Redis 深度歷險:核心原理與應用實踐》分為基礎和應用篇、原理篇、集群篇、拓展篇、原始碼篇共 5 大塊內容,基礎和應用篇講解對讀者來說最有價值的內容,可以直接應用到實際作業中;原理篇、集群篇讓開發者透過簡單的技術表面看到精致的底層世界;拓展篇幫助讀者拓展技術視野和夯實基礎,便于進階學習;原始碼篇讓高階的讀者能夠讀懂原始碼,掌握核心技術實力,

9.Zookeeper
Zookeeper作為統一組態檔管理和集群管理框架,是后續學習其他框架的基礎,在微服務中,還可以用來做注冊中心,
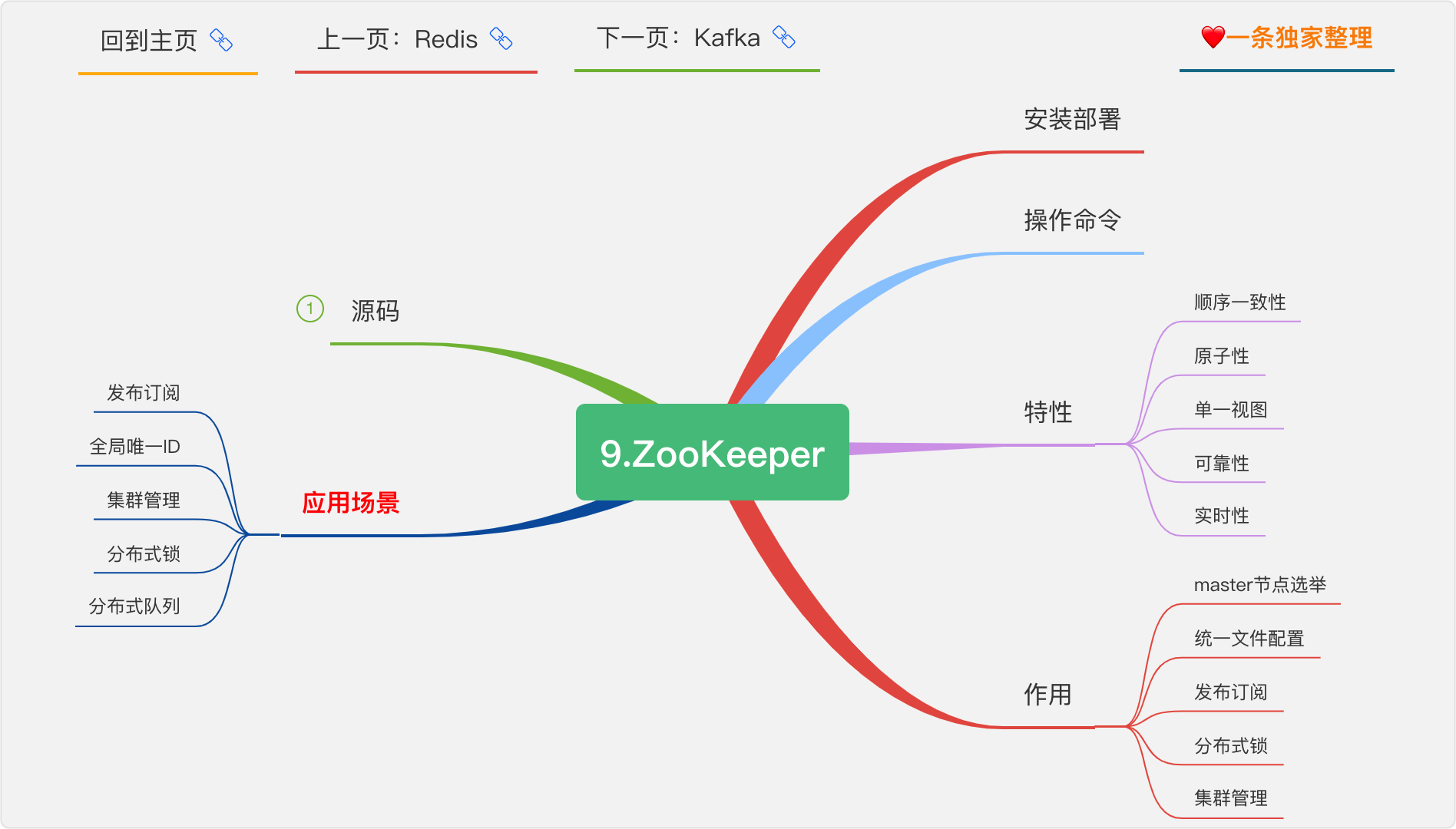
什么是zookeeper
zookeeper 是一個分布式的,開放原始碼的分布式應用程式協調服務,是 google chubby 的開源實作,是 hadoop 和 hbase 的重要組件,它是一個為分布式應用提供一致性服務的軟體,提供的功能包括:配置維護、域名服務、分布式同步、組服務等,
zookeeper 的功能
集群管理:監控節點存活狀態、運行請求等,
主節點選舉:主節點掛掉了之后可以從備用的節點開始新一輪選主,主節點選舉說的就是這個選舉的程序,使用 zookeeper 可以協助完成這個程序,
分布式鎖:zookeeper 提供兩種鎖:獨占鎖、共享鎖,獨占鎖即一次只能有一個執行緒使用資源,共享鎖是讀鎖共享,讀寫互斥,即可以有多線執行緒同時讀同一個資源,如果要使用寫鎖也只能有一個執行緒使用,zookeeper可以對分布式鎖進行控制,
命名服務:在分布式系統中,通過使用命名服務,客戶端應用能夠根據指定名字來獲取資源或服務的地址,提供者等資訊,
zookeeper 的部署模式
zookeeper 有三種部署模式:
單機部署:一臺集群上運行;
集群部署:多臺集群運行;
偽集群部署:一臺集群啟動多個 zookeeper 實體運行,
10.Kafka
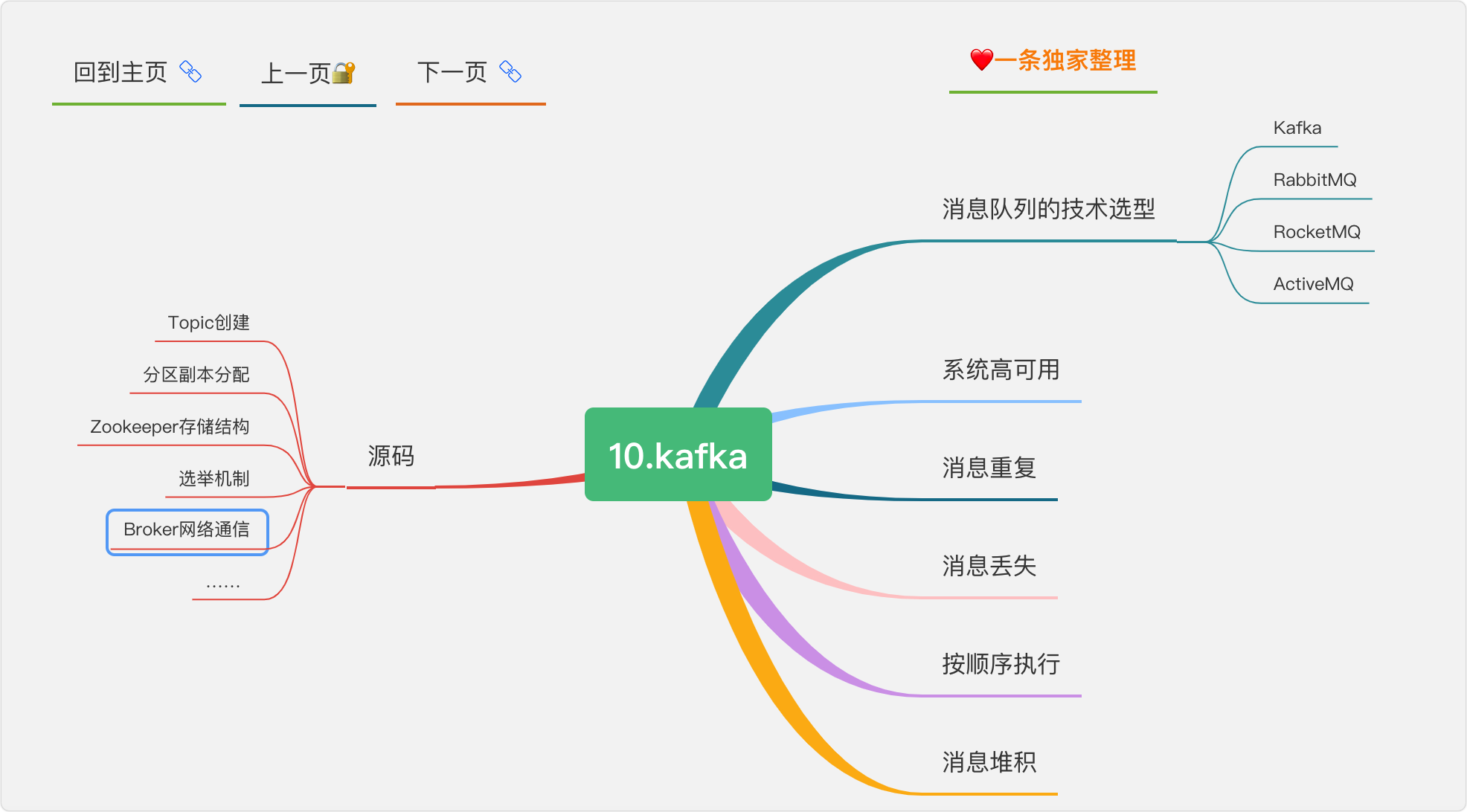
kafka和zookeeper的關系
kafka 不能脫離 zookeeper 單獨使用,因為 kafka 使用 zookeeper 管理和協調 kafka 的節點服務器,
kafka的資料保留的策略?
kafka 有兩種資料保存策略:按照過期時間保留和按照存盤的訊息大小保留,
kafka 同時設定了 7 天和 10G 清除資料,到第五天的時候訊息達到了 10G,這個時候 kafka 將如何處理?
這個時候 kafka 會執行資料清除作業,時間和大小不論那個滿足條件,都會清空資料,
kafka性能瓶頸
cpu 性能瓶頸
磁盤讀寫瓶頸
網路瓶頸
kafka集群
集群的數量不是越多越好,最好不要超過 7 個,因為節點越多,訊息復制需要的時間就越長,整個群組的吞吐量就越低,
集群數量最好是單數,因為超過一半故障集群就不能用了,設定為單數容錯率更高,
配套資料
Apache Kafka實戰
《Apache Kafka實戰》是一本涵蓋Apache Kafka各方面的具有實踐指導意義的工具書和參考書,作者結合典型的使用場景,對Kafka整個技術體系進行了較為全面的講解,以便讀者能夠舉一反三,直接應用于實踐,同時,本書還對Kafka的設計原理及其流式處理組件進行了較深入的探討,并給出了翔實的案例,

11.ES
elasticsearch簡寫es,es是一個高擴展、開源的全文檢索和分析引擎,它可以準實時地快速存盤、搜索、分析海量的資料,
12.Dubbo
Dubbo是一個分布式服務框架,致力于提供高性能和透明化的RPC遠程服務呼叫方案,以及SOA服務治理方案,簡單的說,dubbo就是個服務框架
13.SpringCloud
Spring Cloud是一個微服務框架,Spring Cloud提供了全套的分布式系統解決方案,不僅對微服務基礎框架Netflix的多個開源組件進行了封裝,同時還實作了和云端平臺以及Spring Boot開發框架的集成,
什么是 spring cloud
spring cloud 是一系列框架的有序集合,它利用 spring boot 的開發便利性巧妙地簡化了分布式系統基礎設施的開發,如服務發現注冊、配置中心、訊息總線、負載均衡、斷路器、資料監控等,都可以用 spring boot 的開發風格做到一鍵啟動和部署,
spring cloud 的核心組件
Eureka:服務注冊于發現,
Feign:基于動態代理機制,根據注解和選擇的機器,拼接請求 url 地址,發起請求,
Ribbon:實作負載均衡,從一個服務的多臺機器中選擇一臺,
Hystrix:提供執行緒池,不同的服務走不同的執行緒池,實作了不同服務呼叫的隔離,避免了服務雪崩的問題,
Zuul:網關管理,由 Zuul 網關轉發請求給對應的服務,
斷路器的作用
在分布式架構中,斷路器模式的作用也是類似的,當某個服務單元發生故障(類似用電器發生短路)之后,通過斷路器的故障監控(類似熔斷保險絲),向呼叫方回傳一個錯誤回應,而不是長時間的等待,這樣就不會使得執行緒因呼叫故障服務被長時間占用不釋放,避免了故障在分布式系統中的蔓延,
配套資料
14.Nginx
Nginx是一個高性能的HTTP和反向代理服務器,具有占記憶體少和并發能力強的特點,
15.Netty
netty 是一個基于nio的客戶、服務器端編程框架,netty提供異步的,事件驅動的網路應用程式框架和工具,可以快速開發高可用的客戶端和服務器,
16.架構設計
好的架構從來不是設計出來的,而是演變出來的,所以我們在日常開發中就要不斷思考性能的優化,
下面拿如何設計一個百萬人抽獎系統舉例說明架構的演進,
V0——單體架構
如果現在讓你實作幾十人的抽獎系統,簡單死了吧,直接重拳出擊!
兩貓一豚走江湖,中獎入庫,調通知服務,查庫通知,完美!
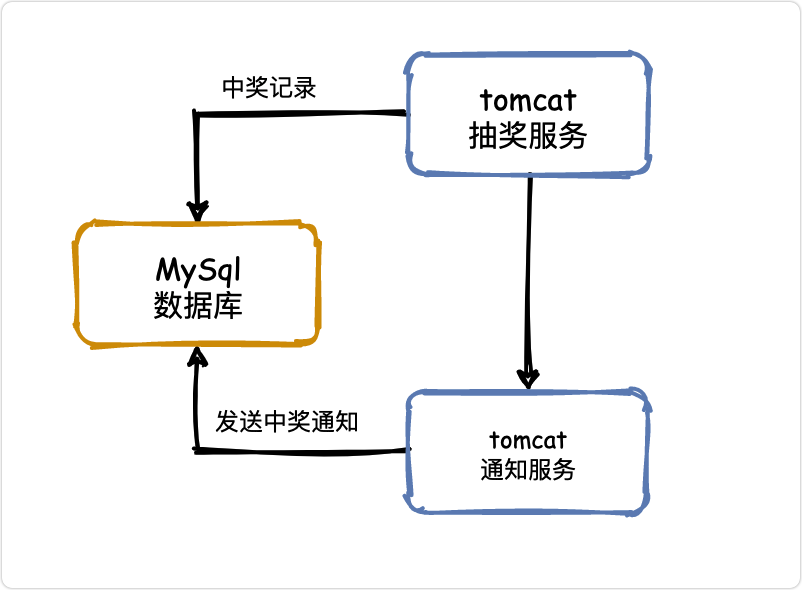
相信大家學java時可能都做過這種案例,思考🤔一下存在什么問題?
- 單體服務,一著不慎滿盤皆輸
- 抽了再抽,一個人就是一支軍隊
- 惡意腳本,沒有程式員中不了的獎
接下來就聊聊怎么解決這些問題?
V1——負載均衡
當一臺服務器的單位時間內的訪問量越大時,服務器壓力就越大,大到超過自身承受能力時,服務器就會崩潰,
為了避免服務器崩潰,讓用戶有更好的體驗,我們通過負載均衡的方式來分擔服務器壓力,
負載均衡就是建立很多很多服務器,組成一個服務器集群,當用戶訪問網站時,先訪問一個中間服務器,好比管家,由他在服務器集群中選擇一個壓力較小的服務器,然后將該訪問請求引入該服務器,
如此以來,用戶的每次訪問,都會保證服務器集群中的每個服務器壓力趨于平衡,分擔了服務器壓力,避免了服務器崩潰的情況,
負載均衡是用「反向代理」的原理實作的,具體負載均衡演算法及其實作方式我們下文再續,
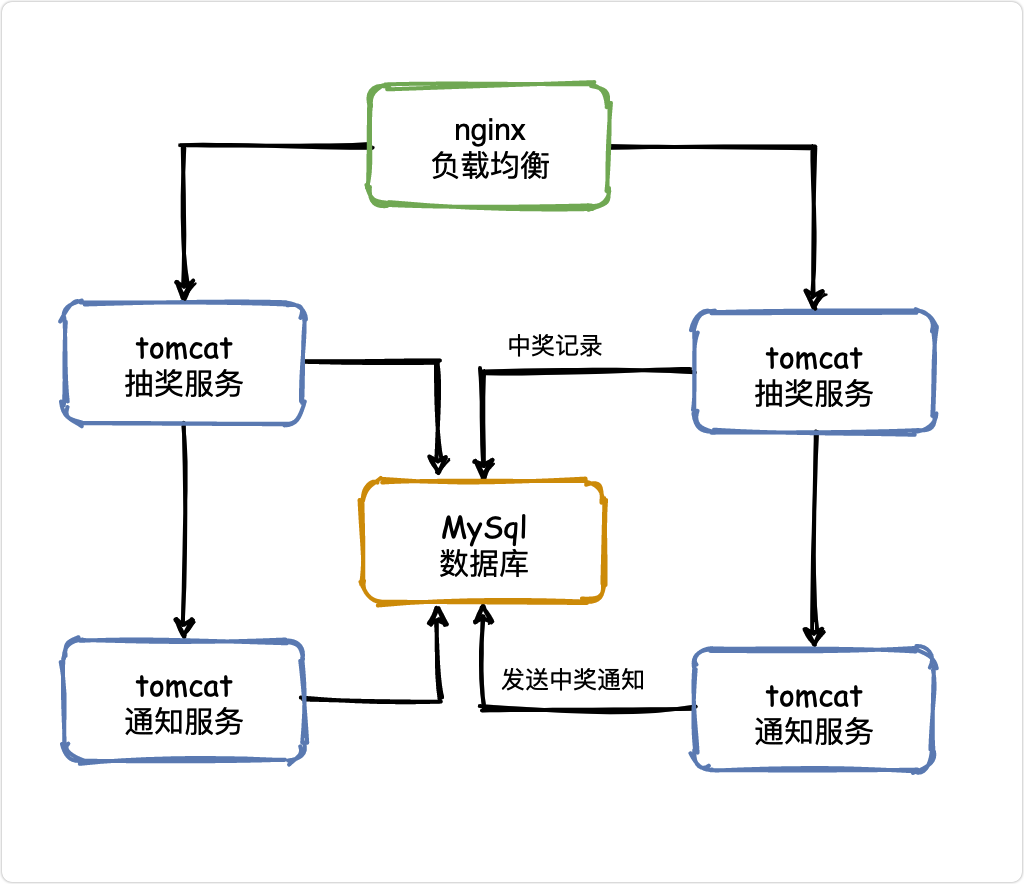
負載均衡雖然解決了單體架構一著不慎滿盤皆輸的問題,但服務器成本依然不能保護系統周全,我們必須想好一旦服務器宕機,如何保證用戶的體驗,
即如何緩解開獎一瞬間時的大量請求,
V2——服務限流
限流主要的作用是保護服務節點或者集群后面的資料節點,防止瞬時流量過大使服務和資料崩潰(如前端快取大量實效),造成不可用,
還可用于平滑請求,
在上一小節我們做好了負載均衡來保證集群的可用性,但公司需要需要考慮服務器的成本,不可能無限制的增加服務器數量,一般會經過計算保證日常的使用沒問題,
限流的意義就在于我們無法預測未知流量,比如剛提到的抽獎可能遇到的:
- 重復抽獎
- 惡意腳本
其他一些場景:
- 熱點事件(微博)
- 大量爬蟲
這些情況都是無法預知的,不知道什么時候會有10倍甚至20倍的流量打進來,如果真碰上這種情況,擴容是根本來不及的(彈性擴容都是虛談,一秒鐘你給我擴一下試試)
明確了限流的意義,我們再來看看如何實作限流
防止用戶重復抽獎
重復抽獎和惡意腳本可以歸在一起,同時幾十萬的用戶可能發出幾百萬的請求,
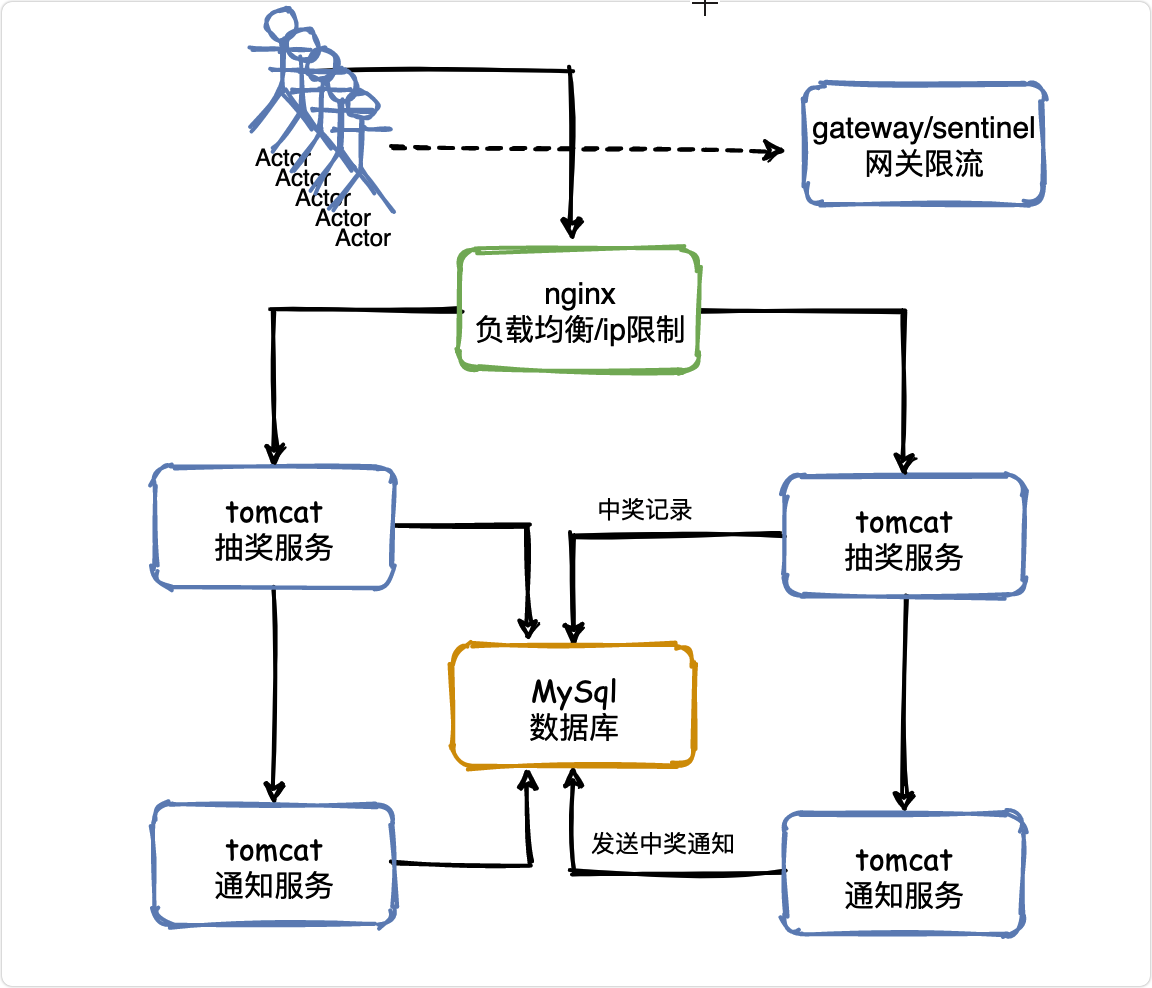
如果同一個用戶在1分鐘之內多次發送請求來進行抽獎,就認為是惡意重復抽獎或者是腳本在刷獎,這種流量是不應該再繼續往下請求的,在負載均衡層給直接屏蔽掉,
可以通過nginx配置ip的訪問頻率,或者在在網關層結合sentinel配置限流策略,
用戶的抽獎狀態可以通過redis來存盤,后面會說,
攔截無效流量
無論是抽獎還是秒殺,獎品和商品都是有限的,所以后面涌入的大量請求其實都是無用的,
舉個例子,假設50萬人抽獎,就準備了100臺手機,那么50萬請求瞬間涌入,其實前500個請求就把手機搶完了,后續的幾十萬請求就沒必要讓他再執行業務邏輯,直接暴力攔截回傳抽獎結束就可以了,
同時前端在按鈕置灰上也可以做一些文章,
那么思考一下如何才能知道獎品抽完了呢,也就是庫存和訂單之前的資料同步問題,
服務降級和服務熔斷
有了以上措施就萬無一失了嗎,不可能的,所以再服務端還有降級和熔斷機制,
在此簡單做個補充,詳細內容請持續關注作者,
有好多人容易混淆這兩個概念,通過一個小例子讓大家明白:
假設現在一條粉絲數突破100萬,沖上微博熱搜,粉絲甲和粉絲乙都打開微博觀看,但甲看到了一條新聞發布會的內容,乙卻看到”系統繁忙“,過了一會,乙也能看到內容了,
(請允許一潭訓想一下😎)
在上述程序中,首先是熱點時間造成大量請求,發生了服務熔斷,為了保證整個系統可用,犧牲了部分用戶乙,乙看到的”系統繁忙“就是服務降級(fallback),過了一會有恢復訪問,這也是熔斷器的一個特性(hystrix)
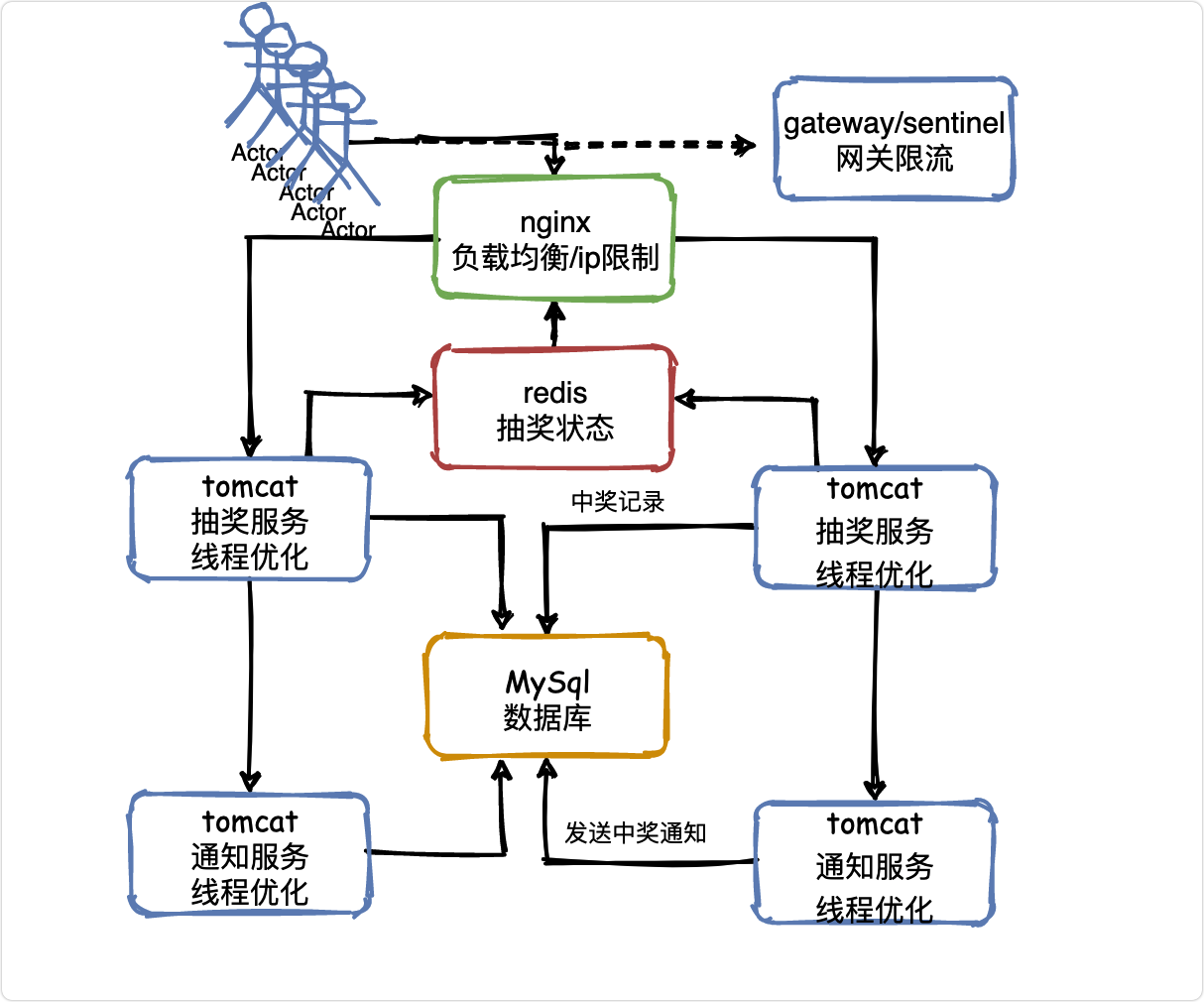
V3 同步狀態
接著回到上一節的問題,如何同步抽獎狀態?
這不得不提到redis,被廣泛用于高并發系統的快取資料庫,
我們可以基于Redis來實作這種共享抽獎狀態,它非常輕量級,很適合兩個層次的系統的共享訪問,
當然其實用ZooKeeper也是可以的,在負載均衡層可以基于zk客戶端監聽某個znode節點狀態,一旦抽獎結束,抽獎服務更新zk狀態,負載均衡層會感知到,
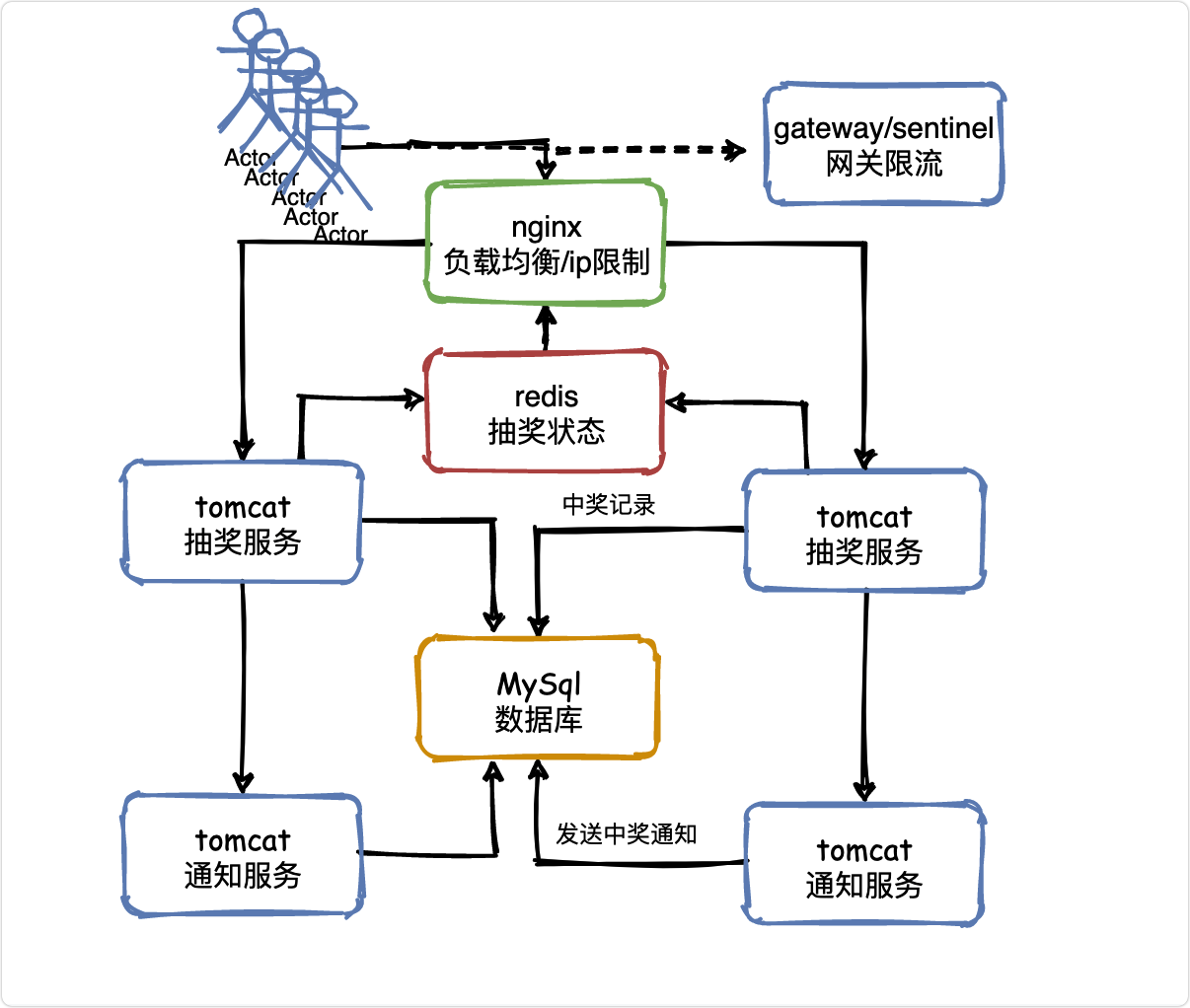
V4執行緒優化
對于線上環境,作業執行緒數量是一個至關重要的引數,需要根據自己的情況調節,
眾所周知,對于進入Tomcat的每個請求,其實都會交給一個獨立的作業執行緒來進行處理,那么Tomcat有多少執行緒,就決定了并發請求處理的能力,
但是這個執行緒數量是需要經過壓測來進行判斷的,因為每個執行緒都會處理一個請求,這個請求又需要訪問資料庫之類的外部系統,所以不是每個系統的引數都可以一樣的,需要自己對系統進行壓測,
但是給一個經驗值的話,Tomcat的執行緒數量不宜過多,因為執行緒過多,普通服務器的CPU是扛不住的,反而會導致機器CPU負載過高,最終崩潰,
同時,Tomcat的執行緒數量也不宜太少,因為如果就100個執行緒,那么會導致無法充分利用Tomcat的執行緒資源和機器的CPU資源,
所以一般來說,Tomcat執行緒數量在200~500之間都是可以的,但是具體多少需要自己壓測一下,不斷的調節引數,看具體的CPU負載以及執行緒執行請求的一個效率,
在CPU負載尚可,以及請求執行性能正常的情況下,盡可能提高一些執行緒數量,
但是如果到一個臨界值,發現機器負載過高,而且執行緒處理請求的速度開始下降,說明這臺機扛不住這么多執行緒并發執行處理請求了,此時就不能繼續上調執行緒數量了,
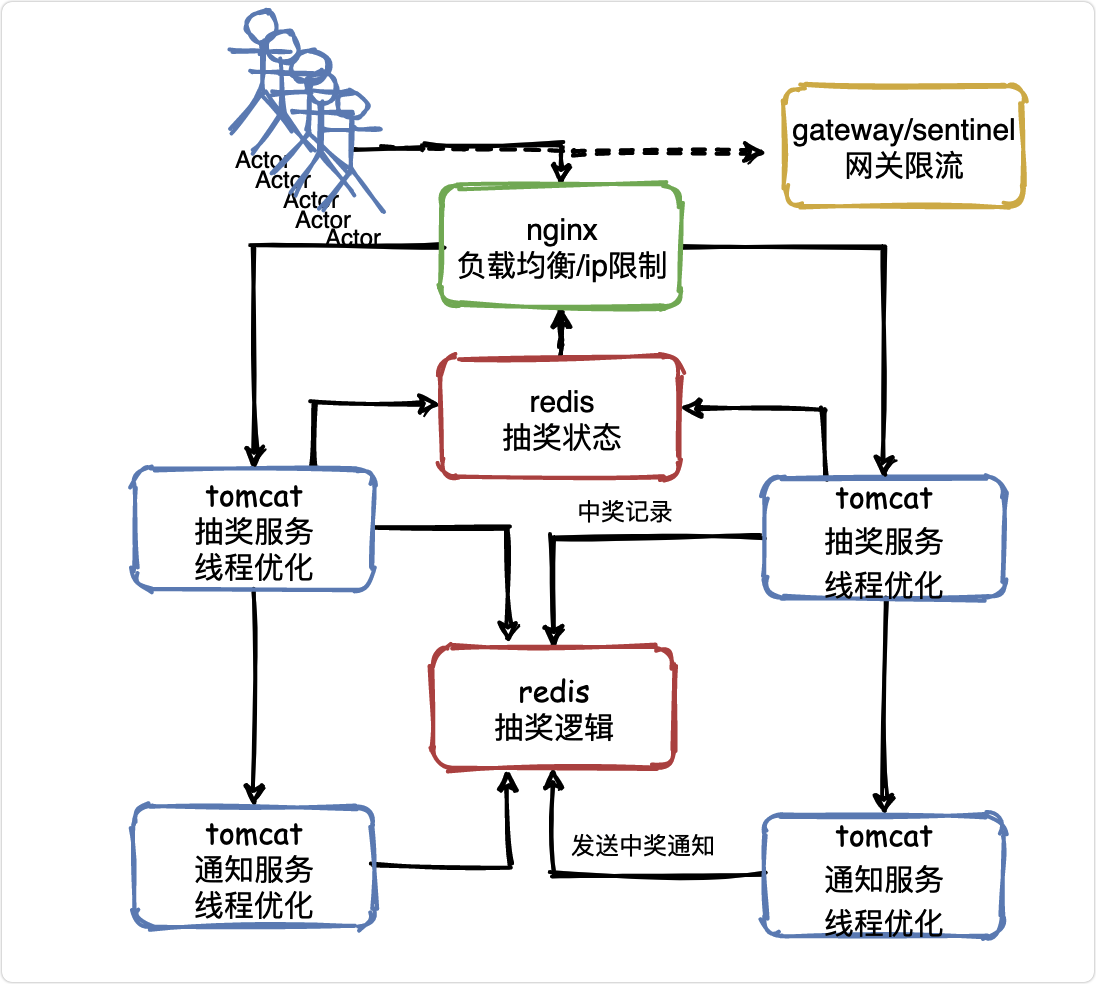
V5業務邏輯
抽獎邏輯怎么做?
好了,現在該研究一下怎么做抽獎了
在負載均衡那個層面,已經把比如50萬流量中的48萬都攔截掉了,但是可能還是會有2萬流量進入抽獎服務,
因為抽獎活動都是臨時服務,可以阿里云租一堆機器,也不是很貴,tomcat優化完了,服務器的問題也解決了,還剩啥呢?
Mysql,是的,你的Mysql能抗住2萬的并發請求嗎?
答案是很難,怎么辦呢?
把Mysql給替換成redis,單機抗2萬并發那是很輕松的一件事情,
而且redis的一種資料結構set很適合做抽獎,可以隨機選擇一個元素并剔除,
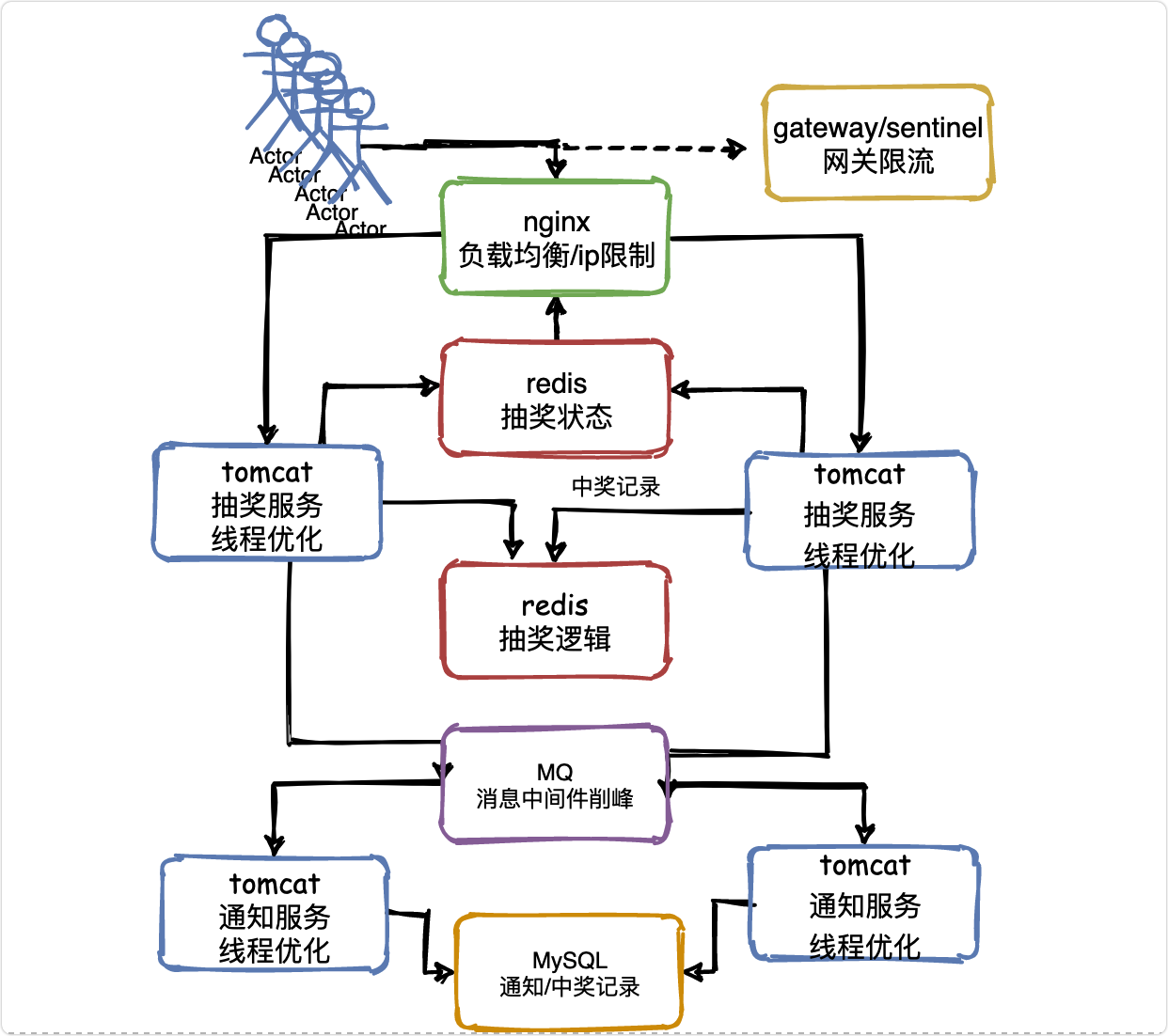
V6流量削峰
由上至下,還剩中獎通知部分沒有優化,
思考這個問題:假設抽獎服務在2萬請求中有1萬請求抽中了獎品,那么勢必會造成抽獎服務對禮品服務呼叫1萬次,
那也要和抽獎服務同樣處理嗎?
其實并不用,因為發送通知不要求及時性,完全可以讓一萬個請求慢慢發送,這時就要用到訊息中間件,進行限流削峰,
也就是說,抽獎服務把中獎資訊發送到MQ,然后通知服務慢慢的從MQ中消費中獎訊息,最終完成完禮品的發放,這也是我們會延遲一些收到中獎資訊或者物流資訊的原因,
假設兩個通知服務實體每秒可以完成100個通知的發送,那么1萬條訊息也就是延遲100秒發放完畢罷了,
同樣對MySQL的壓力也會降低,那么資料庫層面也是可以抗住的,
看一下最終結構圖:
17.Linux
作為Java程式員,不會用Linux會讓人笑掉大牙的,我們不必像運維兄弟一樣精通,基本的命令還是要熟練掌握,
- 理解一切皆檔案
- 檔案操作命令
- 權限管理命令
- 網路命令
- 系統磁盤命令
- ……
18.Git
網上經常傳出不會git被開除的新聞,所以還不學起來?
命令大全
200條Git命令大全
19.資料結構和演算法
問一下各位什么是程式?——資料結構+演算法,所以,學吧,刷題吧
排序演算法
《八大排序》原始碼](https://pan.baidu.com/s/1woTgwkVUT1xtgMB1ha36Uw),提取碼:5ehp
準備
古語云:“兵馬未動,糧草先行”,想跟著一條一塊把「排序演算法」弄明白的,建議先準備好以下代碼模板,
📢 觀看本教程需知道基本回圈語法、兩數交換、雙指標等前置知識,
📚 建議先看完代碼和逐步分析后再嘗試自己寫,
- 新建一個
Java工程,本文全篇也基于Java語言實作代碼, - 建立如下目錄結構
- 在
MainTest測驗類中撰寫測驗模板,
/**
* 測驗類
* Author:一條
* Date:2021/09/23
*/
public class MainTest {
public static void main(String[] args) {
//待排序序列
int[] array={6,10,4,5,2,8};
//呼叫不同排序演算法
// BubbleSort.sort(array);
// 創建有100000個隨機資料的陣列
int[] costArray=new int[100000];
for (int i = 0; i < 100000; i++) {
// 生成一個[0,100000) 的一個數
costArray[i] = (int) (Math.random() * 100000);
}
Date start = new Date();
//過長,先注釋掉逐步列印
//BubbleSort.sort(costArray);
Date end = new Date();
System.out.println("耗時:"+(end.getTime()-start.getTime())/1000+"s");
}
}
該段代碼內容主要有兩個功能:
- 呼叫不同的排序演算法進行測驗
- 測驗不同排序演算法將
10w個數排好序需要的時間,更加具象的理解時間復雜度的不同
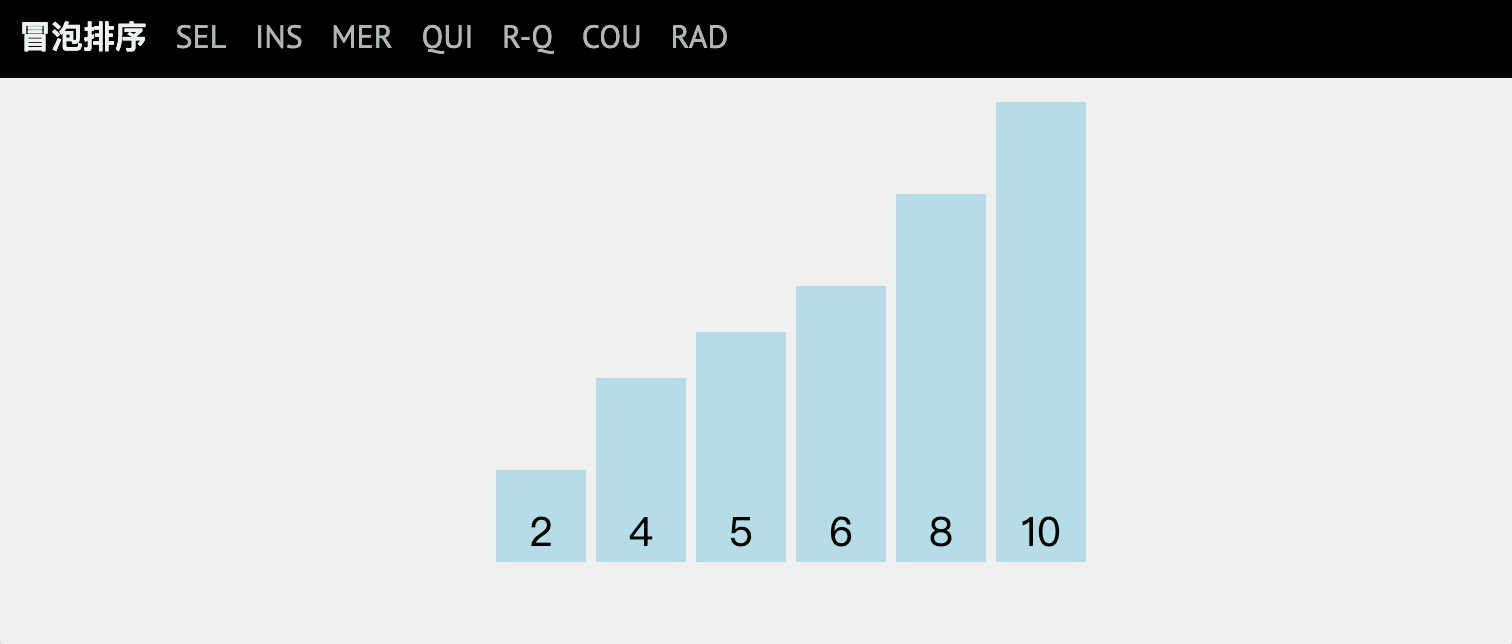
1.冒泡排序
基本思想
通過對亂序序列從前向后遍歷,依次比較相鄰元素的值,若發現逆序則交換,使值較大的元素逐漸從前移向后部,
像水底下的氣泡一樣逐漸向上冒一樣,

動圖講解
代碼實作
不理解的小伙伴可以用
debug模式逐步分析,
/**
* 冒泡排序
* Author:一條
* Date:2021/09/23
*/
public class BubbleSort{
public static int[] sort(int[] array){
for (int i = 0; i < array.length; i++) {
for (int j = 0; j < array.length-1; j++) {
//依次比較,將最大的元素交換到最后
if (array[j]>array[j+1]){
// 用臨時變數temp交換兩個值
int temp=array[j];
array[j]=array[j+1];
array[j+1]=temp;
}
}
//輸出每一步的排序結果
System.out.println(Arrays.toString(array));
}
return array;
}
}
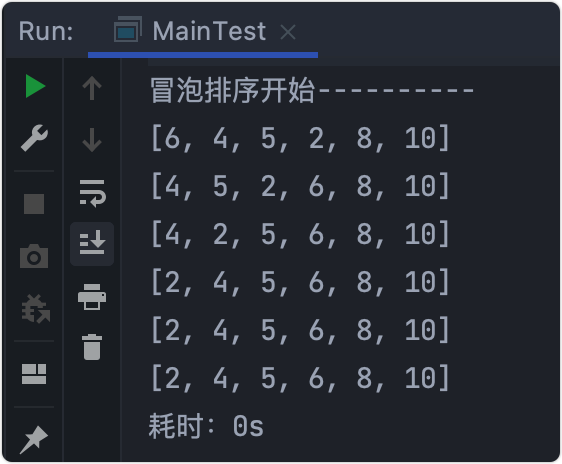
輸出結果
逐步分析
- 初始陣列:
[6,10,4,5,2,8] 6拿出來和后一個10比較,6<10,不用交換,- >j++;10拿出來和后一個4比較,10>4,交換,- >[6,4,10,5,2,8]- 依次執行
j++與后一個比較交換, - 第一層
i回圈完,列印第一行- >[6, 4, 5, 2, 8, 10],此時最后一位10在正確位置上, - >i++ - 從
4開始,繼續比較交換,倒數第二位8回到正確位置, - 如上回圈下去 - > ……
- 最終結果 - >
[2, 4, 5, 6, 8, 10]
這時再回去看動圖理解,
耗時測驗
記得先注釋掉排序類逐步列印代碼,
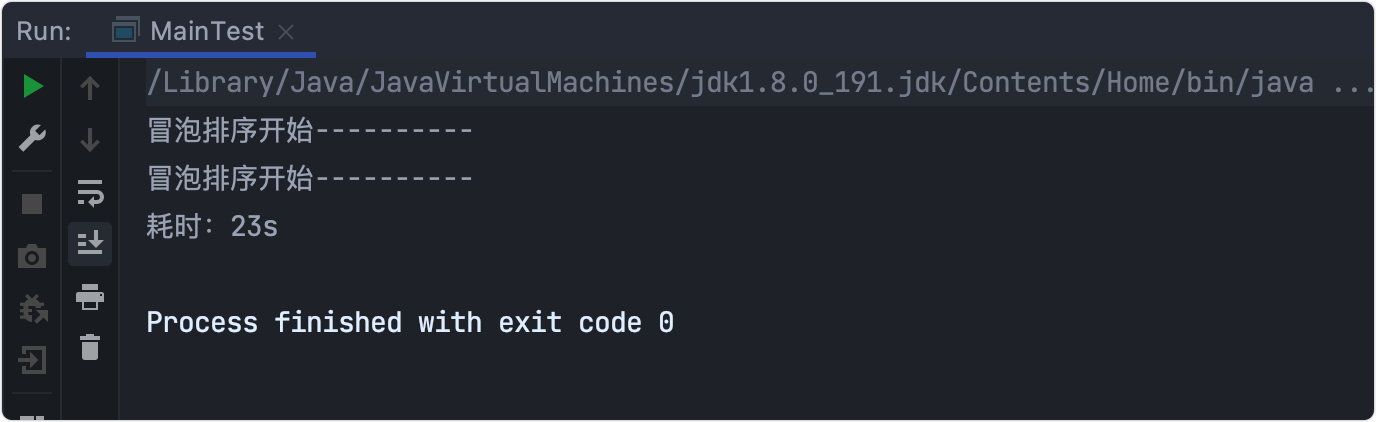
時間復雜度:O(n^2)
演算法優化
優化點一
外層第一次遍歷完,最后一位已經是正確的,j就不需要再比較,所以結束條件應改為j-i-1;,
優化點二
因為排序的程序中,各元素不斷接近自己的位置,如果一趟比較下來沒有進行過交換,就說明序列有序,因此要在排序程序中設定一個標志flag判斷元素是否進行過交換,從而減少不必要的比較,
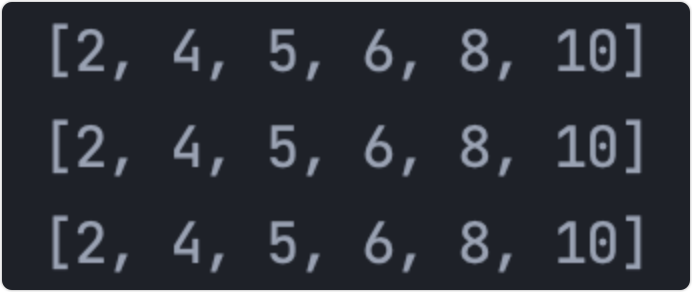
優化代碼
public static int[] sortPlus(int[] array){
System.out.println("優化冒泡排序開始----------");
for (int i = 0; i < array.length; i++) {
boolean flag=false;
for (int j = 0; j < array.length-i-1; j++) {
if (array[j]>array[j+1]){
flag=true;
int temp=array[j];
array[j]=array[j+1];
array[j+1]=temp;
}
}
if (flag==false){
break;
}
// System.out.println(Arrays.toString(array));
}
return array;
}
優化測驗
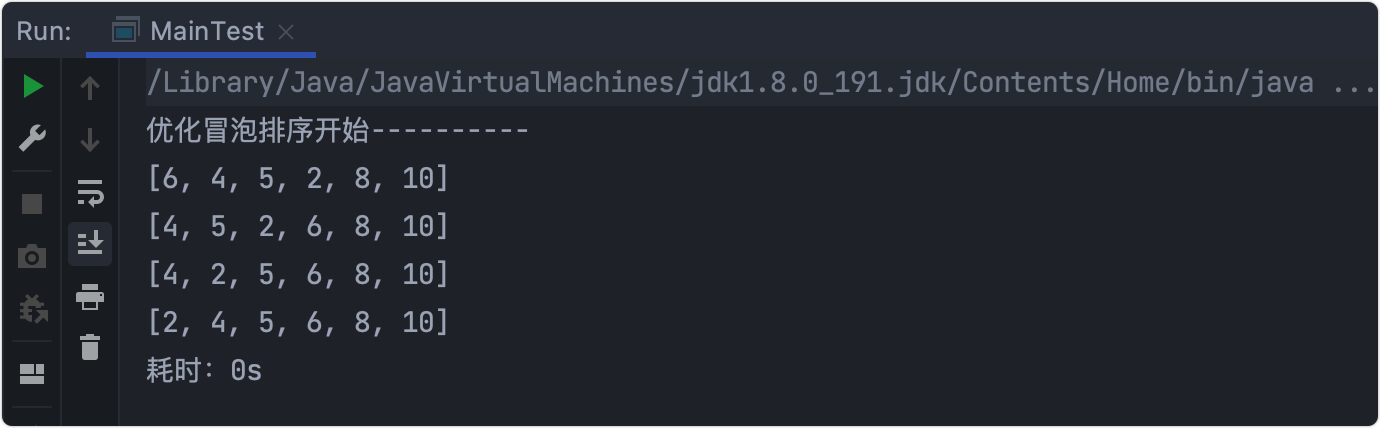
通過基礎測驗看到當序列已經排好序,即不發生交換后終止回圈,
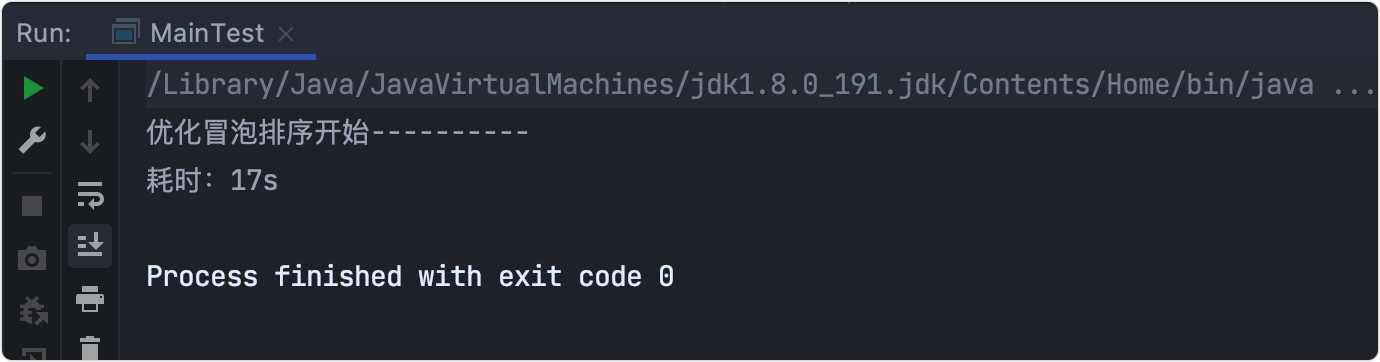
耗時測驗由27s優化到17s,
2.選擇排序
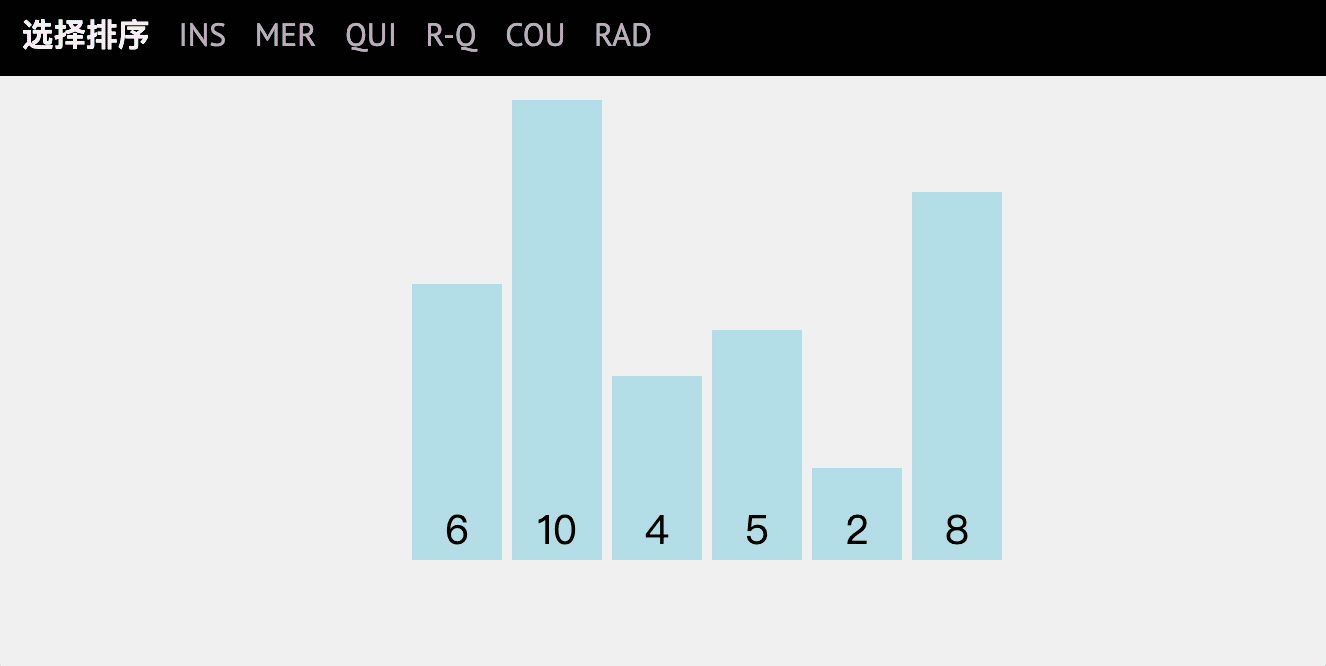
基本思想
選擇排序和冒泡排序很像,是從亂序序列的資料中,按指定的規則選出某一元素,再依規定交換位置后達到排序的目的,
動圖講解
代碼實作
public class SelectSort {
public static int[] sort(int[] array) {
System.out.println("選擇排序開始----------");
for (int i = 0; i < array.length; i++) {
//每個值只需與他后面的值進行比較,所以從開始
for (int j = i; j < array.length; j++) {
//注意此處是哪兩個值比較
if (array[i]>array[j]){
int temp=array[i];
array[i]=array[j];
array[j]=temp;
}
}
System.out.println(Arrays.toString(array));
}
return array;
}
}
輸出結果
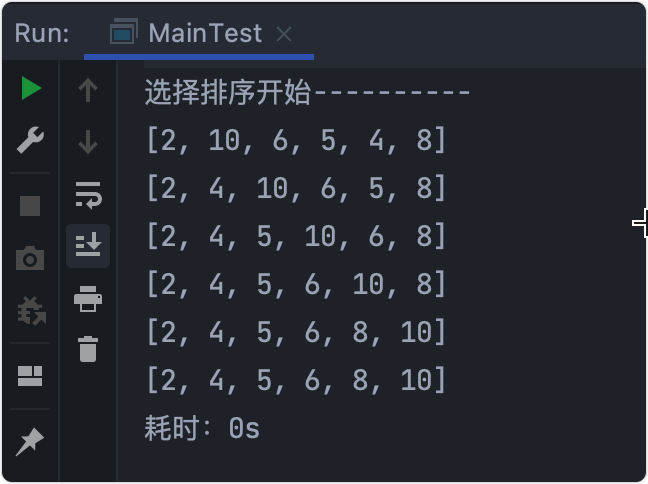
逐步分析
- 初始陣列:
[6,10,4,5,2,8] - 拿出
6與10比較,不交換 - >j++ 6與2比較,交換 - >j++- 注意此時是拿
2繼續比較,都不交換,確定第一位(最小的數)為2- >i++ - 回圈下去,依次找到第一小,第二小,……的數
- 最終結果 - >
[2, 4, 5, 6, 8, 10]
這時再回去看動圖理解,
耗時測驗
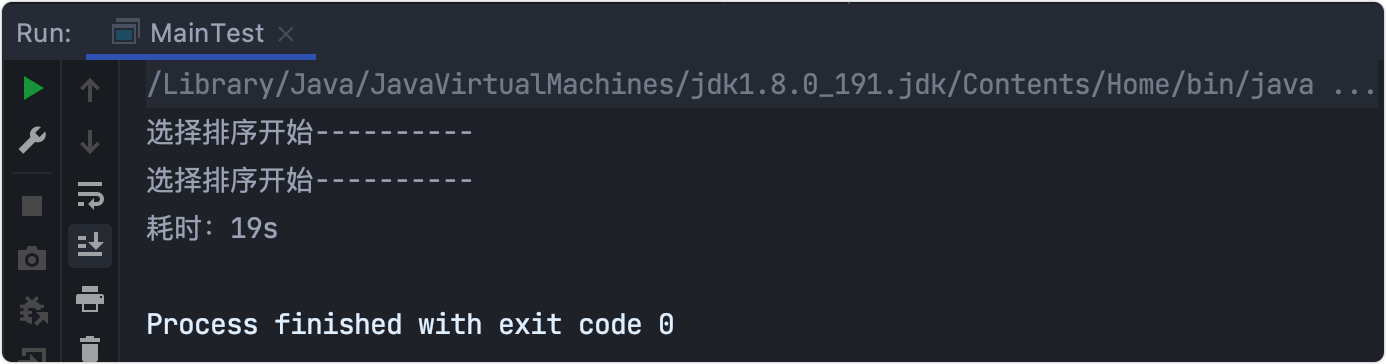
時間復雜度:O(n^2)
演算法優化
上訴代碼中使用交換的方式找到較小值,還可以通過移動的方式,即全部比較完只交換一次,
這種對空間的占有率會有些增益,但對時間的增益幾乎沒有,可忽略,亦不再演示,
3.插入排序
基本思想
把n個亂序的元素看成為一個有序表和一個無序表,開始時有序表中只包含一個元素,無序表中包含有n-1個元素,排序程序中通過不斷往有序表插入元素,獲取一個區域正確解,逐漸擴大有序序列的長度,直到完成排序,
動圖講解
代碼實作
/**
* 插入排序
* Author:一條
* Date:2021/09/23
*/
public class InsertSort {
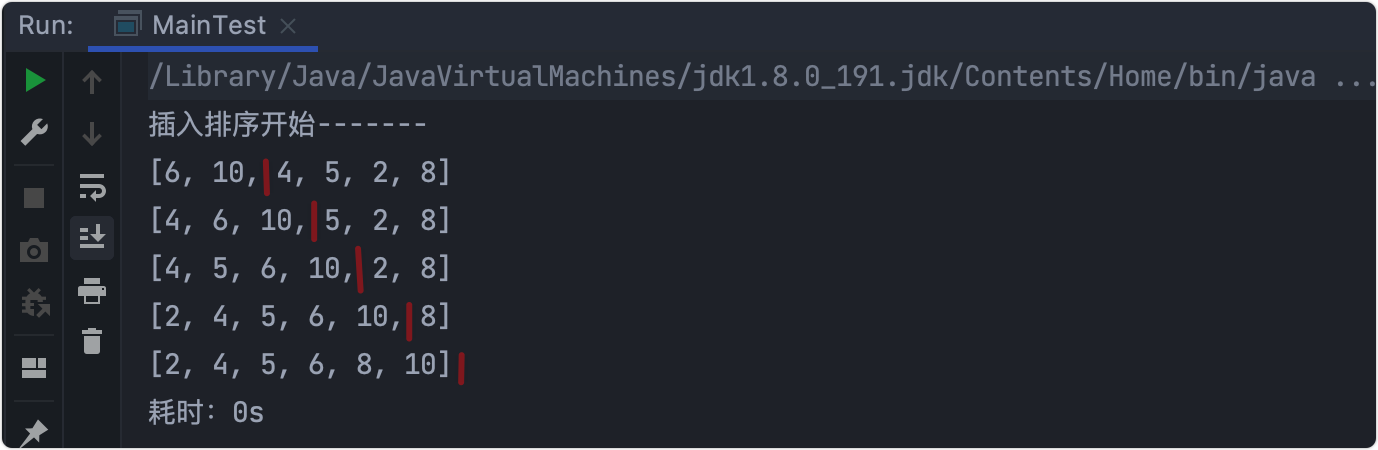
public static void sort(int[] array) {
for (int i = 1; i < array.length; i++) {
//插入有序序列,且將有序序列擴大
for (int j = i; j > 0; j--) {
if (array[j]>array[j-1]){
int temp=array[j];
array[j]=array[j-1];
array[j-1]=temp;
}
}
// System.out.println(Arrays.toString(array));
}
}
}
輸出結果
耗時測驗
演算法優化
見下方希爾排序,就是希爾對插入排序的優化,
4.希爾排序
希爾排序是插入排序的一個優化,思考往
[2,3,4,5,6]中插入1,需要將所有元素的位置都移動一遍,也就是說在某些極端情況下效率不高,也稱該演算法不穩定,希爾排序是插入排序經過改進之后的一個更高效的版本,也稱為縮小增量排序,
基本思想
希爾排序是把記錄按下標的一定增量分組,對每組使用插入排序;
隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個序列恰被分成一組,演算法便終止,
和插入排序一樣,從區域到全部,希爾排序是區域再區域,
動圖講解
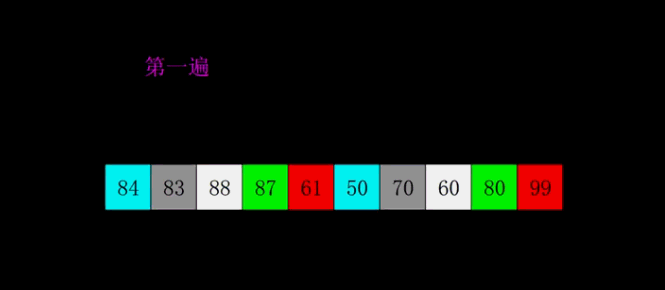
代碼實作
/**
* 希爾排序
* Author:一條
* Date:2021/09/23
*/
public class ShellSort {
public static void sort(int[] array) {
System.out.println("希爾排序開始--------");
//gap初始增量=length/2 逐漸縮小:gap/2
for (int gap = array.length/2; gap > 0 ; gap/=2) {
//插入排序 交換法
for (int i = gap; i < array.length ; i++) {
int j = i;
while(j-gap>=0 && array[j]<array[j-gap]){
//插入排序采用交換法
int temp = array[j];
array[j]=array[j-gap];
array[j-gap]=temp;
j-=gap;
}
}
System.out.println(Arrays.toString(array));
}
}
}
輸出結果
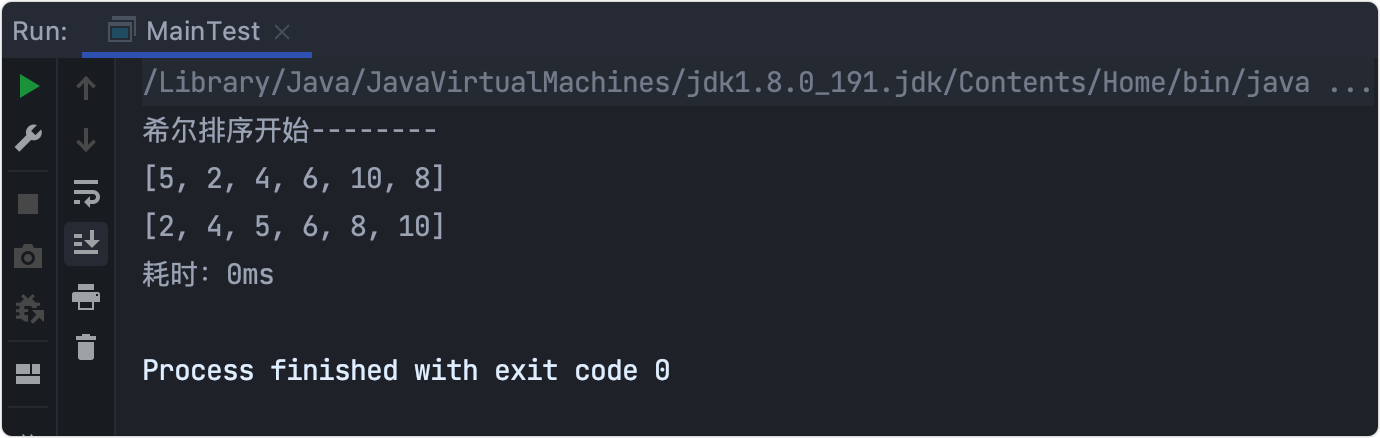
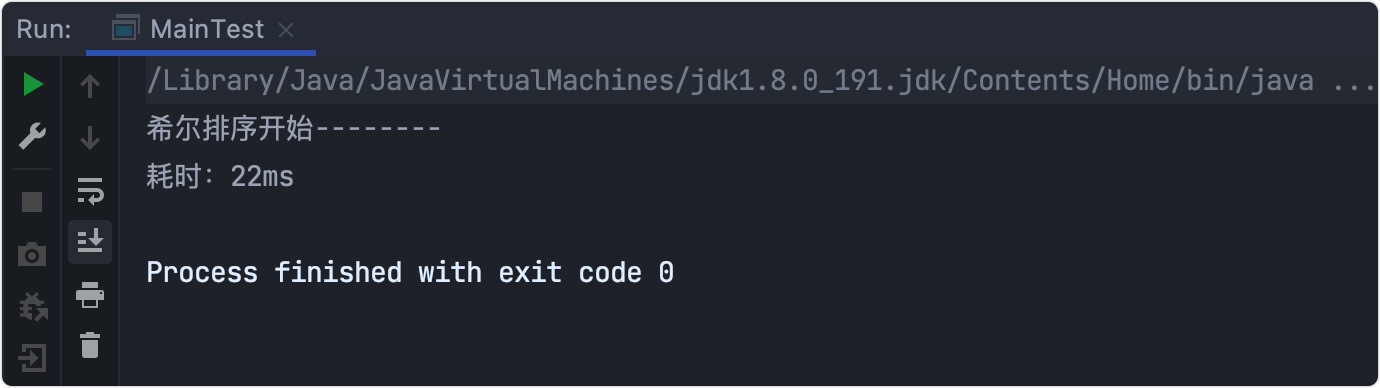
耗時測驗
演算法優化
無
5.快速排序
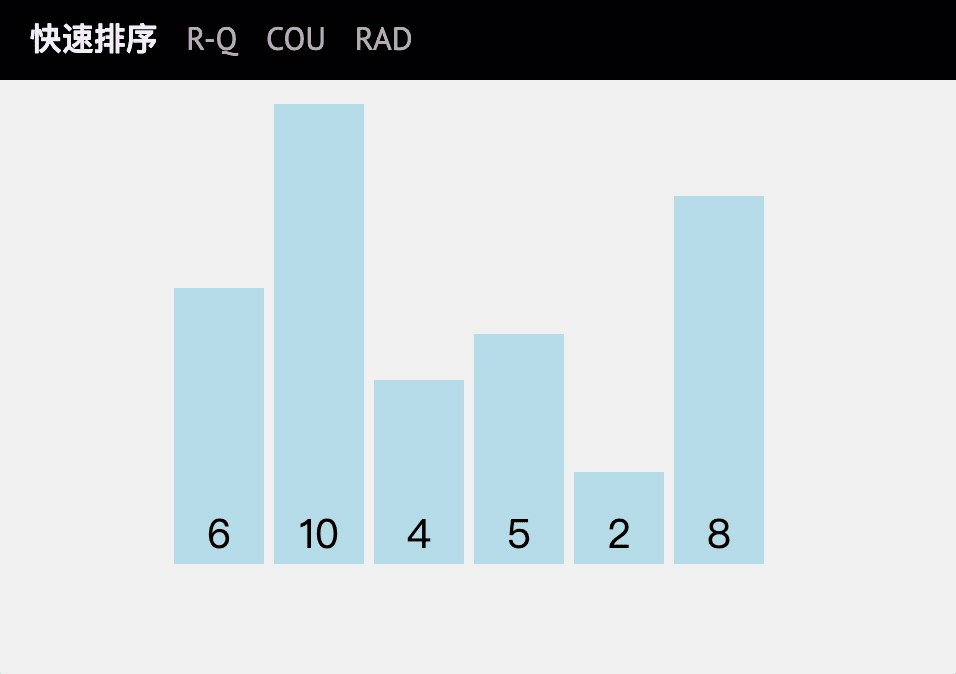
快速排序(Quicksort)是對冒泡排序的一種改進,相比冒泡排序,每次的交換都是跳躍式的,
基本思想
將要排序的資料分割成獨立的兩部分,其中一部分的所有資料都比另外一部分的所有資料都要小,然后再按此方法對這兩部分資料分別進行快速排序,整個排序程序可以遞回進行,以此達到整個資料變成有序序列,
體現出分治的思想,
動圖講解
代碼實作
思路如下:
- 首先在這個序列中找一個數作為基準數,為了方便可以取第一個數,
- 遍歷陣列,將小于基準數的放置于基準數左邊,大于基準數的放置于基準數右邊,此處可用雙指標實作,
- 此時基準值把陣列分為了兩半,基準值算是已歸位(找到排序后的位置),
- 利用遞回演算法,對分治后的子陣列進行排序,
public class QuickSort {
public static void sort(int[] array) {
System.out.println("快速排序開始---------");
mainSort(array, 0, array.length - 1);
}
private static void mainSort(int[] array, int left, int right) {
if(left > right) {
return;
}
//雙指標
int i=left;
int j=right;
//base就是基準數
int base = array[left];
//左邊小于基準,右邊大于基準
while (i<j) {
//先看右邊,依次往左遞減
while (base<=array[j]&&i<j) {
j--;
}
//再看左邊,依次往右遞增
while (base>=array[i]&&i<j) {
i++;
}
//交換
int temp = array[j];
array[j] = array[i];
array[i] = temp;
}
//最后將基準為與i和j相等位置的數字交換
array[left] = array[i];
array[i] = base;
System.out.println(Arrays.toString(array));
//遞回呼叫左半陣列
mainSort(array, left, j-1);
//遞回呼叫右半陣列
mainSort(array, j+1, right);
}
}
輸出結果
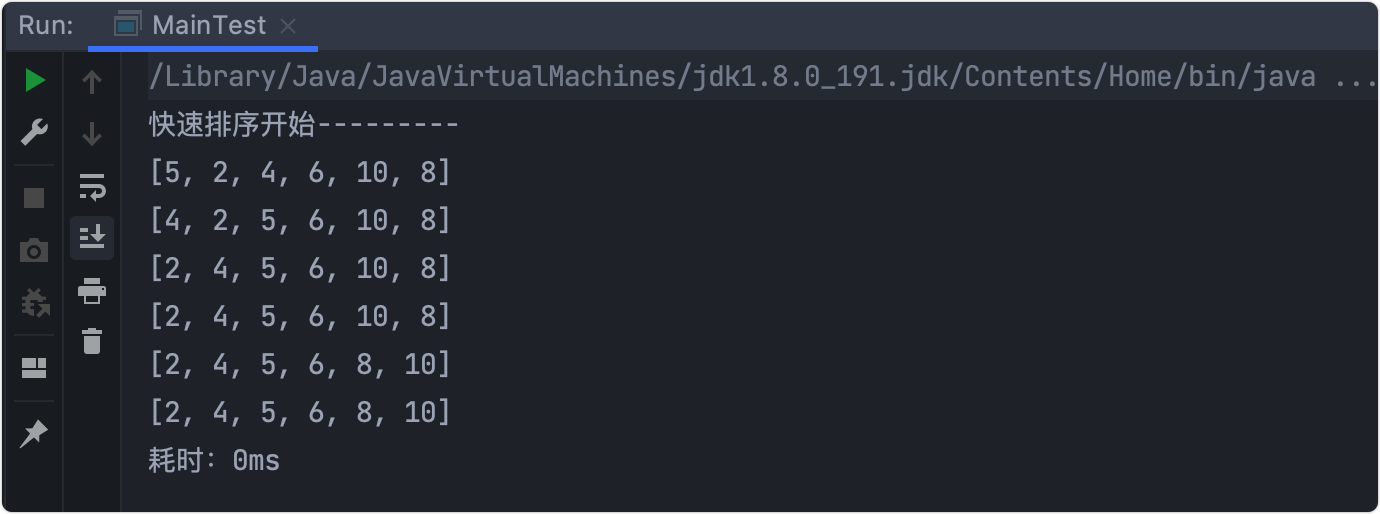
逐步分析
- 將
6作為基準數,利用左右指標使左邊的數<6,右邊的數>6, - 對左右兩邊遞回,即左邊用
5作為基準數繼續比較, - 直到
left > right結束遞回,
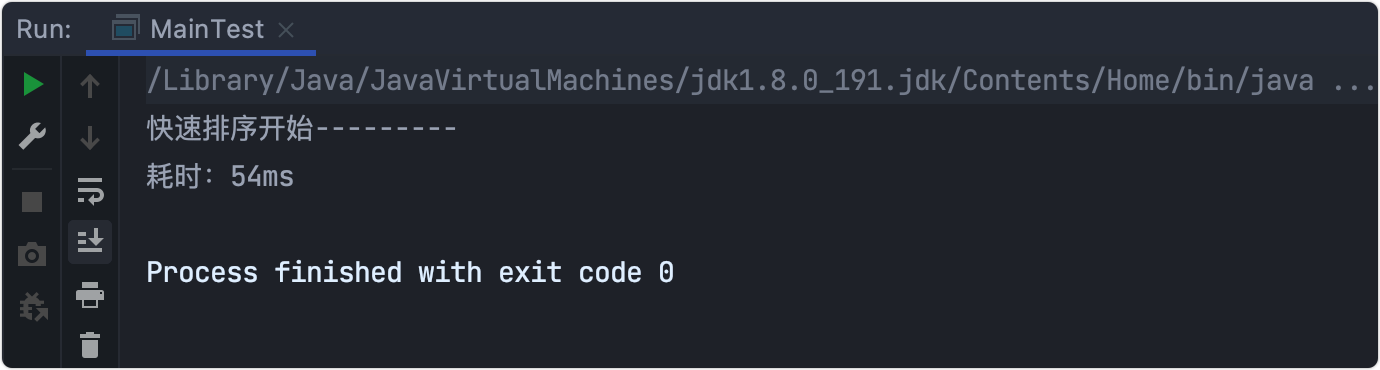
耗時測驗
演算法優化
優化一
三數取中(median-of-three):我們目前是拿第一個數作為基準數,對于部分有序序列,會浪費回圈,可以用三數取中法優化,感性的小伙伴可自行了解,
優化二
快速排序對于長序列非常快,但對于短序列不如插入排序,可以綜合使用,
完整文章
leetcode刷題
最長回文子串——滑動視窗
回文的意思是正著念和倒著念一樣,如:上海自來水來自海上
——leetcode此題熱評
在對聯中就有回文的手法,“上海自來水來自海上”,大家有下聯了嗎

前言
哈嘍,大家好,我是一條,
糊涂演算法,難得糊涂
今天來一道中等題,看看自己功力幾何?
Question
5. 最長回文子串
難度:中等
給你一個字串 s,找到 s 中最長的回文子串,
示例 1:
輸入:s = "babad" 輸出:"bab" 解釋:"aba" 同樣是符合題意的答案,示例 2:
輸入:s = "cbbd" 輸出:"bb"示例 3:
輸入:s = "a" 輸出:"a"示例 4:
輸入:s = "ac" 輸出:"a"提示:
1 <= s.length <= 1000
s 僅由數字和英文字母(大寫和/或小寫)組成
Solution
之前我們做過一道題是:最長不重復子串,當時使用的是
滑動視窗法,這道題增加了回文的約束,那么該怎么處理回文,可以在紙上寫一個回文串觀察一下,有什么特點呢?
從中心點向兩端發散
對吧,所以我們要滑動這個中心點,并對每一個中心點,進行左右擴展,判斷左右字符是否相等即可,
- 把
null和空字串的特殊情況處理掉 - 有一個可滑動且大小可變的視窗,視窗左端(start)不動,右端(end)向后移動
- 由于字串長度有奇數和偶數兩種,所以我們需要同時計算從一個字符開始擴展和從兩個字符之間開始擴展
- 找出兩種擴展中相對長的作為當前最大值
- 新的
start要從何處開始,如何擴展字串只需要考慮的問題
還有一種馬拉車演算法更加快速,但有一定難度,面試一般不會出現,感興趣的同學可以看一下
Code
所有
leetcode代碼已同步至github歡迎
star
/**
* @author yitiaoIT
*/
class Solution {
public String longestPalindrome(String s) {
if (s == null || s.length() < 1) return "";
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
int len1 = expandAroundCenter(s, i, i);
int len2 = expandAroundCenter(s, i, i + 1);
int len = Math.max(len1, len2);
if (len > end - start) {
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substring(start, end + 1);
}
private int expandAroundCenter(String s, int left, int right) {
int L = left, R = right;
while (L >= 0 && R < s.length() && s.charAt(L) == s.charAt(R)) {
L--;
R++;
}
return R - L - 1;
}
Result
復雜度分析
- 時間復雜度:O(N)

20.計算機網路
計算機基礎課,非科班學生提升必備,
21.作業系統
計算機基礎課,非科班學生提升必備,
22.計算機組成原理
計算機基礎課,非科班學生提升必備,
23.程式員英語
因為經常會看一些英文的檔案,四級水平時一定要達到的,
24.寫作能力
即使不做自媒體,寫檔案的能力也要培養起來,
25.演講能力
千萬不要小瞧了這個能力,升職答辯,年終述職必備,
26.管理能力
不可能搞一輩子技術的,總要帶團隊,走管理路線,
配套資料
1.阿里巴巴Java開發手冊
《阿里巴巴Java開發手冊》是阿里內部Java工程師所遵循的開發規范,涵蓋編程規約、單元測驗規約、例外日志規約、MySQL規約、工程規約、安全規約等,這是近萬名阿里Java技術精英的經驗總結,并經歷了多次大規模一線實戰檢驗及完善,這是阿里回饋給Java社區的一份禮物,希望能夠幫助企業開發團隊在Java開發上更高效、容錯、有協作性,提高代碼質量,降低專案維護成本,

2.程式員一條
3.Java核心知識點

4.204道全路線面試題合集
204道全路線面試題合集
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/316698.html
標籤:其他