我一直在使用 Python、Shapely、Numpy 和 Geopandas 來生成點密度圖。點密度圖點根據種族具有不同的顏色,因此可以了解整個城市的人口統計資料。
我一直在使用一些類似于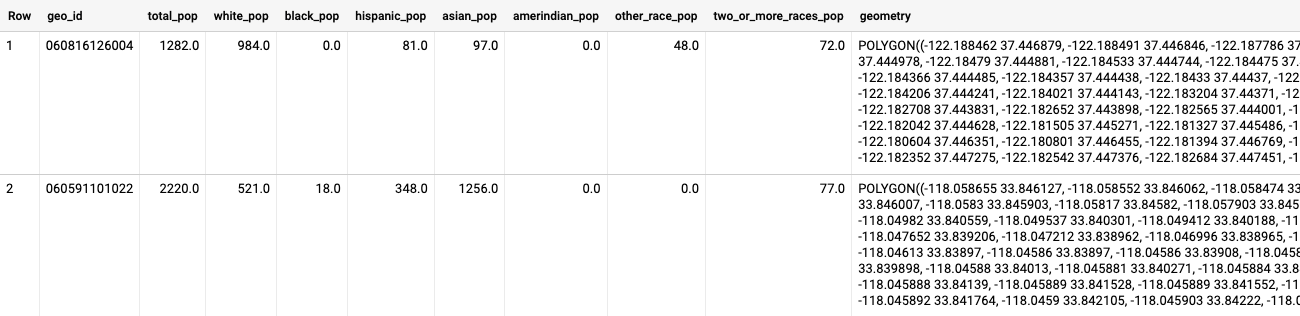
這是我運行以創建點的代碼:
pts_per_person = 5
epsg = 4326
seed = 10
list_of_point_categories = []
for field in ['white_pop','black_pop','hispanic_pop', 'asian_pop', 'amerindian_pop', 'other_race_pop', 'two_or_more_races_pop']:
ps = gpd.GeoDataFrame(gen_points_in_gdf_polys(geometry = gdf['geometry'], values=gdf[field],
points_per_value = pts_per_person, seed=seed))
ps['ethnicity'] = field
ps['year'] = i
list_of_point_categories.append(ps)
all_points=gpd.GeoDataFrame(pd.concat(list_of_point_categories))
all_points=all_points.reset_index(drop=True)
以下是功能:
def gen_random_points_poly(poly, num_points, seed = None):
"""
Returns a list of N randomly generated points within a polygon.
"""
min_x, min_y, max_x, max_y = poly.bounds
points = []
i=0
while len(points) < num_points:
s=RandomState(seed i) if seed else RandomState(seed)
random_point = Point([s.uniform(min_x, max_x), s.uniform(min_y, max_y)])
if random_point.within(poly):
points.append(random_point)
i =1
return points
def gen_points_in_gdf_polys(geometry, values, points_per_value = None, seed = None):
"""
Take a GeoSeries of Polygons along with a Series of values and returns randomly generated points within
these polygons. Optionally takes a "points_per_value" integer which indicates the number of points that
should be generated for each 1 value.
"""
if points_per_value:
new_values = (values/points_per_value).astype(int)
else:
new_values = values
new_values = new_values[new_values>0]
#print(new_values.size)
if(new_values.size > 0):
g = gpd.GeoDataFrame(data = {'vals':new_values}, geometry = geometry)
a = g.apply(lambda row: tuple(gen_random_points_poly(row['geometry'], row['vals'], seed)),1)
b = gpd.GeoSeries(a.apply(pd.Series).stack(), crs = geometry.crs)
b.name='geometry'
return b
但是我發現我最終得到了每個種族的多個重復點。緯度和經度值完全相同。
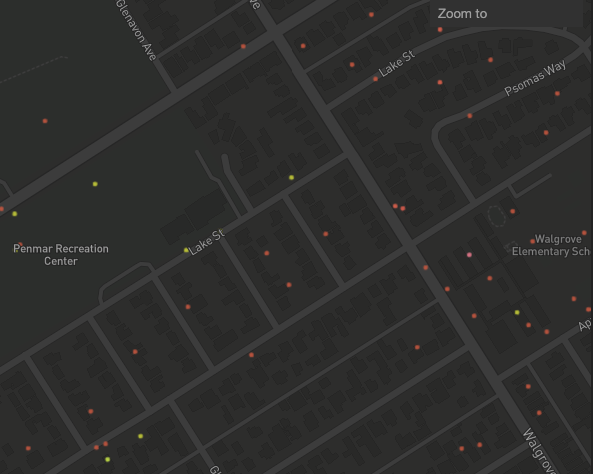
Duplicate points were getting stacked on top of each other. I had to change the s.uniform line to random_point = Point([s.uniform(min_x, max_x) round(random.uniform(.0001, .001),10), s.uniform(min_y, max_y) round(random.uniform(.0001, .001),10)]) in order to make it truly random. This had the desired effect of spreading the points out more randomly, there were no duplicates.
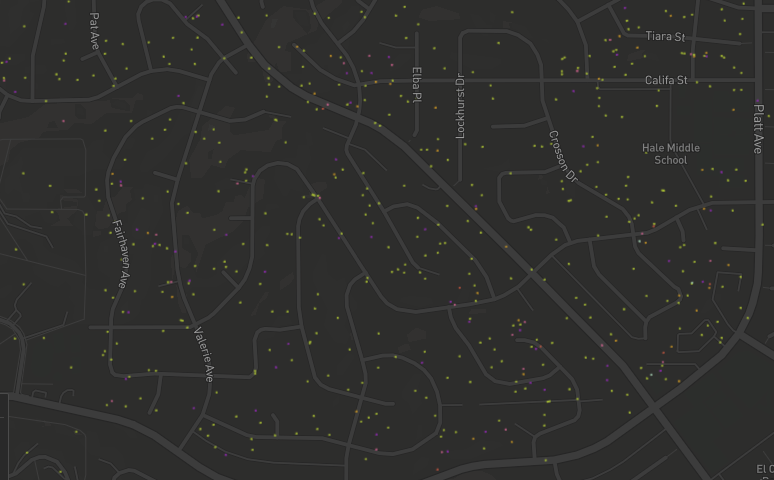
But something about this feels a bit hacky, like I'm not using .uniform right. Is this the right way to create random points within a polygon?
uj5u.com熱心網友回復:
問題似乎出while在gen_random_points_poly()函式中回圈的第一行。這行內容是:
s=RandomState(seed i) if seed else RandomState(seed)
這會在回圈的每次迭代中初始化亂數生成器。初始化取決于seed(固定) 的值和i(在回圈的每次迭代中遞增) 的值。實際上,如果gen_random_points_poly()多次呼叫該函式,則每次生成的點序列都將完全相同。這就是為什么為不同種族生成的點集合完全相同的原因。
如果您想獲得可重現的結果,您可以RandomState在gen_random_points_poly()函式之外創建一次物件。或者,您可以在每次呼叫此函式時提供不同的種子。在后一種情況下RandomState,在while回圈之前只創建一次物件仍然更有效率,而不是在每次迭代時重復創建它。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/316990.html
標籤:python numpy gis geopandas shapely