我有一個資料集,每當我看到包含特定單詞的某個單詞時,我都想將特定值匹配到新列中。
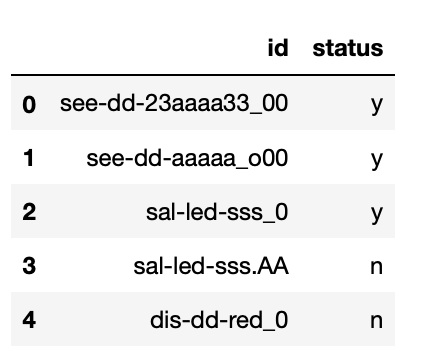
資料
id status
see-dd-23aaaa33_00 y
see-dd-aaaaa_o00 y
sal-led-sss_0 y
sal-led-sss.AA n
dis-dd-red_0 n
想要的
id status pw
see-dd-2333 y 14
see-dd-aaaaa y 14
sal-led-sss y 8
sal-led-sss n 8
dis-dd-red n 5
正在做
我想我可以使用字典。每當我看到'see-dd'的模式時,我想提供14的數值。當我看到包含'sal-led'的單詞時,我希望提供8的數值。每當我看到“dis-dd”時,我都想將其與 5 的值相匹配。
out= {
'see-dd': 14,
'sal-led': 8,
}
任何建議表示贊賞。
uj5u.com熱心網友回復:
試試 replace
out= {
'see-dd': 14,
'sal-led': 8,
'dis-dd':5
}
df['new'] = df.id.replace(out,regex=True)
df
id status new
0 see-dd-23aaaa33_00 y 14
1 see-dd-aaaaa_o00 y 14
2 sal-led-sss_0 y 8
3 sal-led-sss.AA n 8
4 dis-dd-red_0 n 5
uj5u.com熱心網友回復:
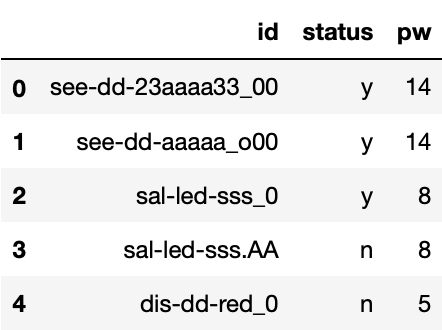
您可以采用以下資料框并根據 df 的模式字典“out”和“id”列應用匹配器函式。
out = {'see-dd': 14, 'sal-led': 8, 'dis-dd': 5}
def matcher(row_data):
for key, val in out.items():
if key in row_data:
return val
#This will create a new column 'pw' using your 'out' patterns and values
df['pw'] = df['id'].apply(matcher)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/316999.html
上一篇:是否有一個Numpy函式可以將一個元素轉換為與其他元素不同的型別?
下一篇:用Pandas列中的句點替換空格