2020全國大學生數學建模C題初嘗試——基于 PaddlePaddle LSTM 的中小微企業信貸決策模型
本文目錄
- 2020全國大學生數學建模C題初嘗試——基于 PaddlePaddle LSTM 的中小微企業信貸決策模型
- 專案地址
- 題目簡析
- C題題目
- 簡單決議
- 簡單說說 LSTM
- 專案代碼
- 資料預處理
- 資料的匯入與訓練
- 模型訓練效果驗證
- 未標注公司的評估
- 寫在最后
專案地址
https://aistudio.baidu.com/aistudio/projectdetail/906384
題目簡析
C題題目
首先讓我們來回顧一下題目:
在實際中,由于中小微企業規模相對較小,也缺少抵押資產,因此銀行通常是依據信貸政策、企業的交易票據資訊和上下游企業的影響力,向實力強、供求關系穩定的企業提供貸款,并可以對信譽高、信貸風險小的企業給予利率優惠,銀行首先根據中小微企業的實力、信譽對其信貸風險做出評估,然后依據信貸風險等因素來確定是否放貸及貸款額度、利率和期限等信貸策略,
某銀行對確定要放貸企業的貸款額度為 10 至 100 萬元;年利率為 4% 至 15%;貸款期限為 1 年,附件1~3 分別給出了123家有信貸記錄企業的相關資料、302 家無信貸記錄企業的相關資料和貸款利率與客戶流失率關系的 2019 年統計資料,該銀行請你們團隊根據實際和附件中的資料資訊,通過建立數學模型研究對中小微企業的信貸策略,主要解決下列問題:
(1) 對附件 1 中 123 家企業的信貸風險進行量化分析,給出該銀行在年度信貸總額固定時對這些企業的信貸策略,
(2) 在問題 1 的基礎上,對附件 2 中 302 家企業的信貸風險進行量化分析,并給出該銀行在年度信貸總額為1億元時對這些企業的信貸策略,
(3) 企業的生產經營和經濟效益可能會受到一些突發因素影響,而且突發因素往往對不同行業、不同類別的企業會有不同的影響,綜合考慮附件 2 中各企業的信貸風險和可能的突發因素(例如:新冠病毒疫情)對各企業的影響,給出該銀行在年度信貸總額為 1 億元時的信貸調整策略,
簡單決議
先讓我們看看附件 1 的資料
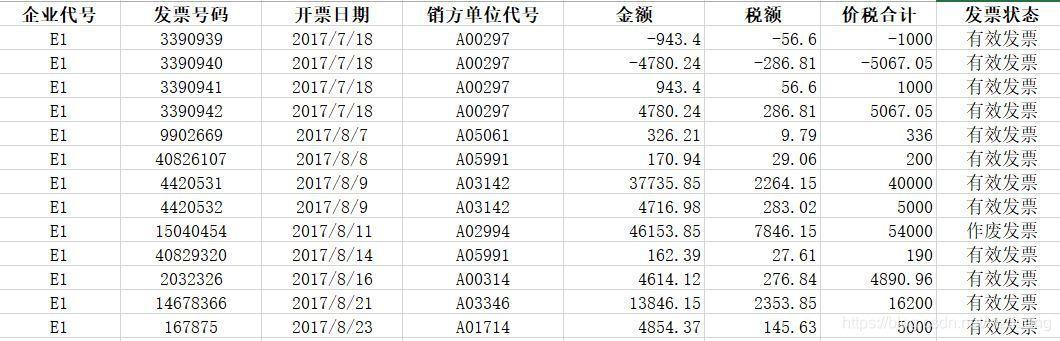
其中發票號碼,開票具體日期,銷方單位代號屬于無用信號,同時信號本身屬于時序信號,故需要選用適合處理時序資訊的神經網路,由于 RNN 在處理長依賴問題具有較為嚴重的局限性,故最終決定選用 LSTM,
簡單說說 LSTM
LSTM 的 全稱為 Long Short Term Memory networks,即長短期記憶網路,LSTM 是一種特殊的回圈神經網路(Recurrent Neural Networks),該網路設計出來是為了解決 RNN 未能解決的長依賴問題,
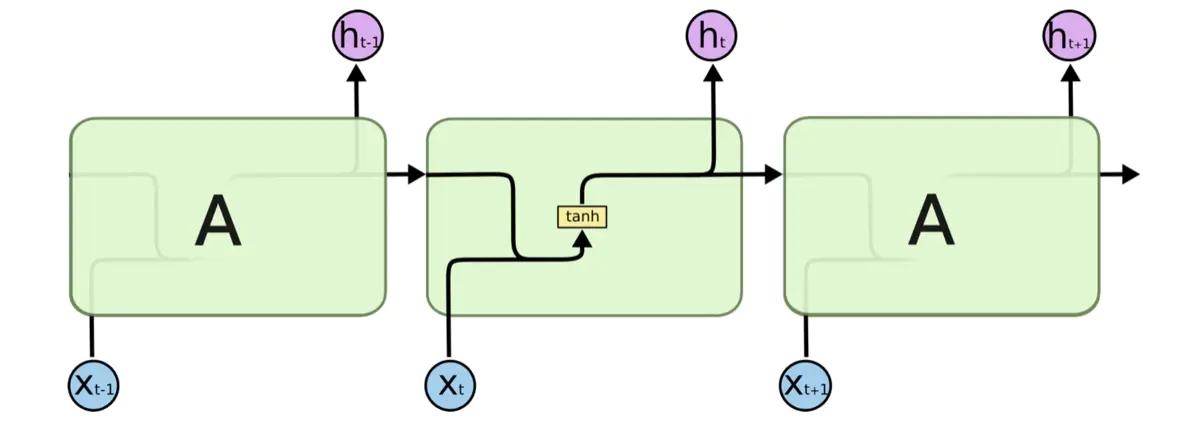
所有回圈神經網路都具有神經網路的重復模塊鏈的形式, 在標準的 RNN 中,該重復模塊將具有非常簡單的結構,例如單個 tanh 層,標準的 RNN 網路如下圖所示
LSTM 也具有這種鏈式結構,但是它的重復單元不同于標準 RNN 網路里的單元只有一個網路層,它的內部有四個網路層,同時具有遺忘門、輸入門和輸出門等幾個部分,LSTM 的結構如下圖所示
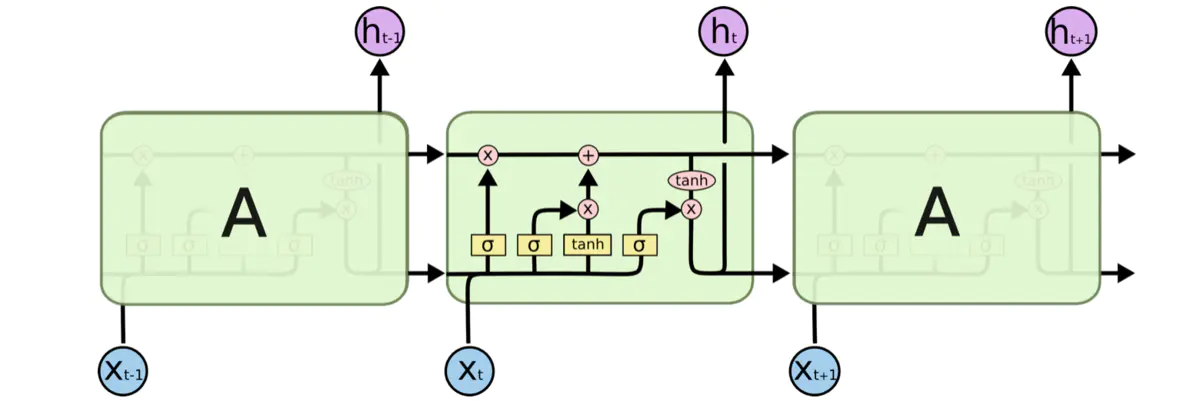
其中

專案代碼
筆者使用百度的 AIStudio 線上平臺進行模型的訓練,環境配置為 Python 2.7 與 PaddlePaddle 1.6.2
資料預處理
由于題目資料量較為龐大,資料預處理部分的作業比較繁雜,處理好的資料如下所示
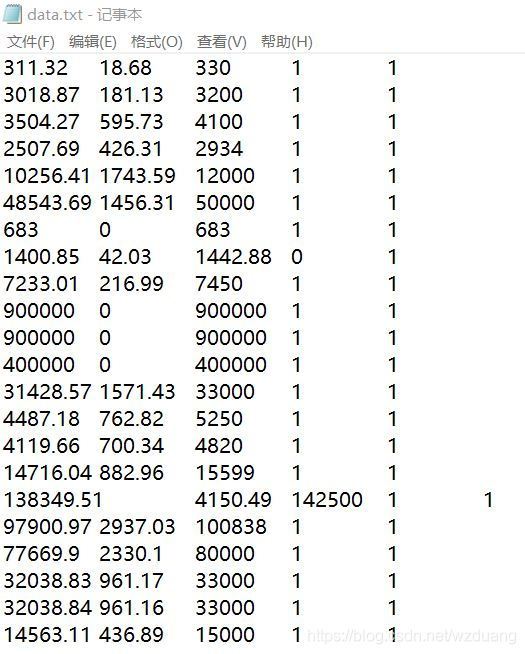
從左到右分別為金額,稅額,價稅合計與發票狀態(0 為有效發票,1 為作廢發票),標簽為公司評級ABCD,分別用1234表示
不想自己處理的小伙伴可以直接白嫖已經處理好的訓練資料,提取碼如下
鏈接:https://pan.baidu.com/s/1RLhF5N3EW_xkiO7QZvNH4A
提取碼:fit5
資料的匯入與訓練
參考庫檔案
import numpy as np
import math
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
from __future__ import print_function
檔案讀入
SAVE_DIRNAME = 'model'
f = open('work/data.txt') #修改資料集檔案路徑
df = f.readlines()
f.close()
data = []
for line in df:
data_raw = line.strip('\n').strip('\r').split('\t')
data.append(data_raw)
data = np.array(data, dtype='float32')
列印出來查看一下
print('資料型別:',type(data))
print('資料個數:', data.shape[0])
print('資料形狀:', data.shape)
print('資料第一行:', data[0])

劃分訓練集和驗證集,由于資料量較大,故將訓練集的比例劃分到 99%,剩余兩千左右的資料作為驗證
ratio = 0.99
DATA_NUM = len(data)
train_len = int(DATA_NUM * ratio)
test_len = DATA_NUM - train_len
train_data = data[:train_len]
test_data = data[train_len:]
資料歸一化,由于標簽值的解算較為特殊,故對歸一化公式做出一些改動
def normalization(data):
avg = np.mean(data, axis=0)
max_ = np.max(data, axis=0)
min_ = np.min(data, axis=0)
#result_data = (data - avg) / (max_- min_)
result_data = data / (max_- min_)
print(len(result_data))
print(result_data[:][4])
return result_data
train_data = normalization(train_data)
test_data = normalization(test_data)
構造 paddlepaddle 的 reader
def my_train_reader():
def reader():
for temp in train_data:
yield temp[:-1], temp[-1]
return reader
def my_test_reader():
def reader():
for temp in test_data:
yield temp[:-1], temp[-1]
return reader
定義 batch size 大小
# 定義batch
train_reader = paddle.batch(
my_train_reader(),
batch_size=30000)
搭建LSTM模型
DIM = 1
hid_dim2 = 1
x = fluid.layers.data(name='x', shape=[DIM], dtype='float32', lod_level=1)
label = fluid.layers.data(name='y', shape=[1], dtype='float32')
fc0 = fluid.layers.fc(input=x, size=DIM * 4)
fc1 = fluid.layers.fc(input=fc0, size=DIM * 4)
lstm_h, c = fluid.layers.dynamic_lstm(
input=fc1, size=DIM * 4, is_reverse=False)
# 最大池化
lstm_max = fluid.layers.sequence_pool(input=lstm_h, pool_type='max')
# 激活函式
lstm_max_tanh = fluid.layers.tanh(lstm_max)
# 全連接層
prediction = fluid.layers.fc(input=lstm_max_tanh, size=hid_dim2, act='tanh')
# 代價函式
cost = fluid.layers.square_error_cost(input=prediction, label=label)
avg_cost = fluid.layers.mean(x=cost)
# acc = fluid.layers.accuracy(input=prediction, label=label)
開始訓練,PASS_NUM 為輪數,這里設定為兩百
from paddle.utils.plot import Ploter
train_title = "Train cost"
test_title = "Test cost"
plot_cost = Ploter(train_title, test_title)
# 定義優化器
adam_optimizer = fluid.optimizer.Adam(learning_rate=0.002)
adam_optimizer.minimize(avg_cost)
# 使用CPU
#place = fluid.CPUPlace()
# 使用CUDA
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run( fluid.default_startup_program() )
feeder = fluid.DataFeeder(place=place, feed_list=[x, label])
def train_loop():
step = 0 # 畫圖
PASS_NUM = 200
for pass_id in range(PASS_NUM):
total_loss_pass = 0#初始化每一個epoch的損失值初始值為0
for data in train_reader(): #data表示batch大小的資料樣本
avg_loss_value, = exe.run(
fluid.default_main_program(),
feed= feeder.feed(data),
fetch_list=[avg_cost])
total_loss_pass += avg_loss_value
# 畫圖
plot_cost.append(train_title, step, avg_loss_value)
step += 1
plot_cost.plot()
fluid.io.save_inference_model(SAVE_DIRNAME, ['x'], [prediction], exe)
train_loop()
訓練誤差如圖
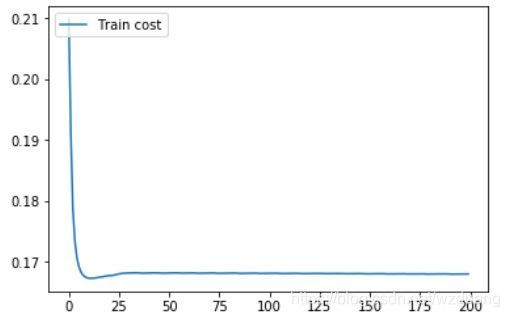
模型訓練效果驗證
def convert2LODTensor(temp_arr, len_list):
temp_arr = np.array(temp_arr)
temp_arr = temp_arr.flatten().reshape((-1, 1))
print(temp_arr.shape)
return fluid.create_lod_tensor(
data=temp_arr,
recursive_seq_lens =[len_list],
place=fluid.CPUPlace()
)
def get_tensor_label(mini_batch):
tensor = None
labels = []
temp_arr = []
len_list = []
for _ in mini_batch:
labels.append(_[1])
temp_arr.append(_[0])
len_list.append(len(_[0]))
tensor = convert2LODTensor(temp_arr, len_list)
return tensor, labels
my_tensor = None
labels = None
# 定義batch
test_reader = paddle.batch(
my_test_reader(),
batch_size=400000)
for mini_batch in test_reader():
my_tensor,labels = get_tensor_label(mini_batch)
# 選擇CPU或者CUDA進行驗證
#place = fluid.CPUPlace()
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
with fluid.scope_guard(inference_scope):
[inference_program, feed_target_names, fetch_targets] = (
fluid.io.load_inference_model(SAVE_DIRNAME, exe))
results = exe.run(inference_program,
feed= {'x': my_tensor},
fetch_list=fetch_targets)
最后繪制影像,由于標簽之前被歸一化了,這里我們需要對其進行解算
label = label*3 # 標簽解算
result_print = results[0].flatten()
result_print = 3*result_print # 預測結果解算
plt.figure()
plt.plot(list(range(len(labels))), labels, color='b') #藍線為真實值
plt.plot(list(range(len(result_print))), result_print, color='r') #紅線為預測值
plt.show()
驗證結果如下,其中藍色為真實評級,紅色為模型的預測評級
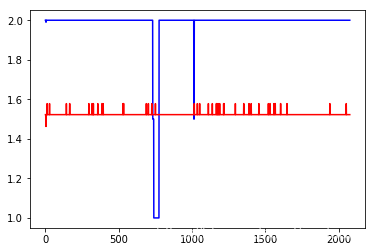
誤差不是很大,效果感徑訓可以
未標注公司的評估
由于資料量實在是太大了,導致圖片有些難以辨認
寫在最后
本人以后會發布一些關于機器學習模型演算法,自動控制演算法的其他文章,也會聊一聊自己做的一些小專案,希望讀者朋友們能夠喜歡,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/31793.html
標籤:其他
上一篇:python遍歷指定路徑下所有檔案,并按照時間區間檢索
下一篇:關于嵌入式軟體分層設計