最近寫專利時看到了一種基于瀏覽記錄的反爬蟲方法,該方法基于 “在前端頁面中以埋點或者提取頁面日志的方式,獲取用戶的前端瀏覽記錄,計算用戶行為指標并進行人機驗證” ,
用戶行為指標
用戶行為指標的計算基于前端瀏覽記錄中的瀏覽地址與瀏覽時間,
- 根據所述瀏覽時間和所述地址數量計算預設單位時長內訪問次數;
- 根據所述地址數量與所述總瀏覽時長計算每個瀏覽地址的平均瀏覽時長;
- 利用預設的指標函式對所述地址數量、總瀏覽時長、平均瀏覽時長和預設單位時長訪問次數進行計算,得到用戶行為指標,
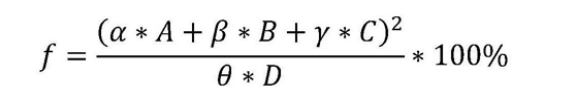
其中,f 為用戶行為指標,A為所述地址數量,B為所述總瀏覽時長,C為所述平均瀏覽時長,D為所述預設單位時長訪問次數,α、β、γ和θ為預設權重系數,
例如,用戶小明的在6點至7點的瀏覽地址為的www.xiaoshuo.com,在7點至9點瀏覽地址為www.gouwu.com,則確定用戶小明的地址數量為2,瀏覽總時長為3小時,用戶小明對每個瀏覽地址的平均瀏覽時長為1.5小時,當預設單位時長為3小時,預設單位時長內訪問次數為2,
由于非爬蟲用戶的作息方式較為固定,因此非爬蟲用戶的瀏覽習慣較為固定 ,該方法利用計算得到的用戶行為指標表示用戶為非爬蟲用戶的概率,并將用戶行為指標與預設閾值進行對比,當所述用戶行為指標大于預設閾值,確定該用戶為爬蟲,對所述用戶進行訪問限制,
然后根據所述反爬蟲驗證引數,構建所述用戶對所述目標網頁的訪問代價函式,并迭代所述訪問代價函式,得到訪問代價值,
所述訪問代價是指用戶通過用戶IP地址對資料進行訪問時,用戶IP地址對應的服務器的負載消耗,
所述訪問代價函式為:
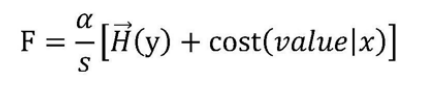
例如,用戶通過用戶IP地址對目標網頁進行訪問時,該用戶IP地址對應的服務器需要承擔每秒8000次的資料請求產生的負載消耗,則每秒8000次的資料請求產生的負載消耗即為用戶對所述目標網頁進行訪問的訪問代價,
所述對所述訪問代價函式進行迭代,是指利用所述訪問代價函式計算多個預設單位時長內,用戶通過用戶IP地址對資料進行訪問的單位訪問代價,并將該多個預設單位時長內單位訪問代價的均值作為所述訪問代價值,
判斷所述訪問代價值是否小于所述反爬蟲驗證引數,當所述訪問代價值小于所述反爬蟲驗證引數時,對所述用戶進行訪問限制,
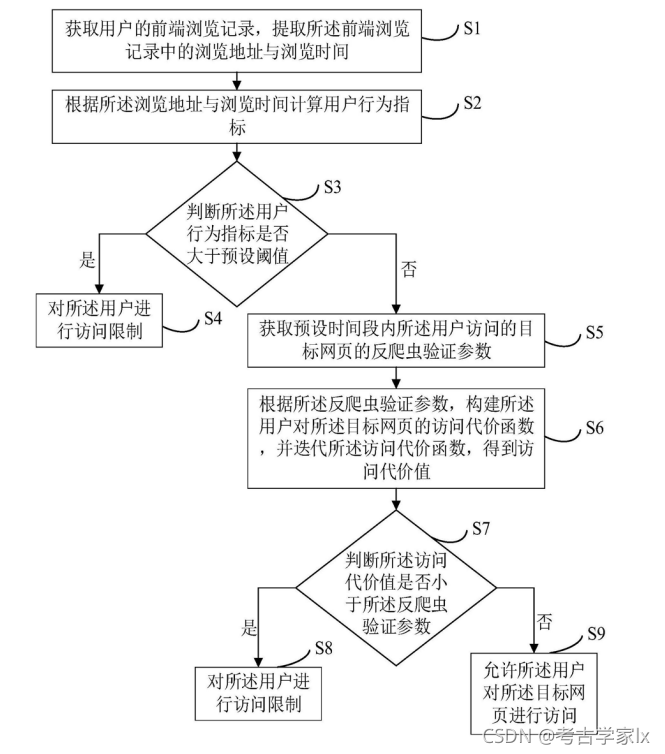
反爬流程圖
經驗分析
目前基于應用層的反爬已經數見不鮮,各大廠商都將反爬核心轉移到用戶行為和設備指紋上,
像本文的反爬蟲方法,適用于具有個人賬號或者穩定cookie的訪問來源,
比如在抖音和脈脈的風控上,該方法與其有著異曲同工之妙,
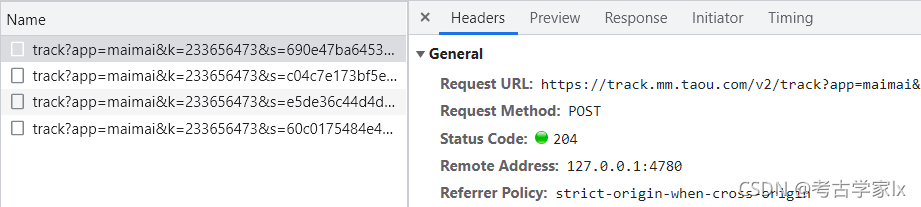
通過定時或者用戶操作時觸發行為記錄的POST請求,將行為記錄以日志形式發送給服務端進行校驗,
如果你單純的用請求庫去訪問介面,并沒有做相應的POST請求,當爬蟲請求達到一定閾值后會被服務端限制訪問,
反反爬策略
打造一個用于服務端檢測的環境,比如說啟動一個服務來發送行為記錄,維持和服務端的通信,或者開啟一個真實的應用,
就像在抖音的wss協議中,需要維持心跳,在正常的長連接時,去構造app_log一樣,
當然也不是說只要構建了環境就不會被限制,各大廠都有一套專用的爬蟲識別演算法,需要不斷測驗才能找到最好的解決方法,
比如在晚上11點后的檢測比白天嚴格,比如每周固定時間會對一周訪問記錄進行大型檢測,所以有時需要根據風控演算法去打造一套專用的采集演算法,
以上文的用戶行為指標公式為例,想要爬蟲增加訪問頻率和訪問量,則需要在行為記錄中去增加引數值,
因其他事 未完待續
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/317983.html
標籤:其他
上一篇:霍夫曼樹、霍夫曼編碼