我有一個 df,我想將 1 列與 df 中剩余的每一列進行比較,計算并計算比率。
import numpy as np
import pandas as pd
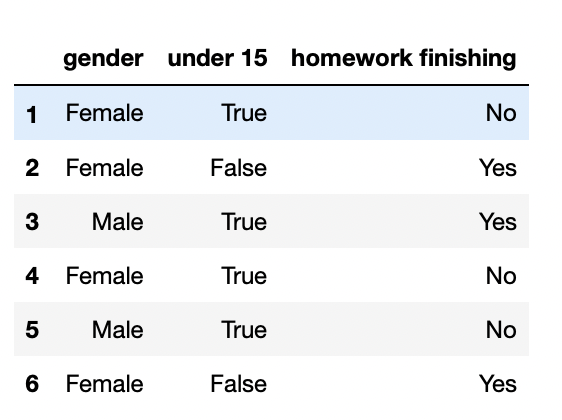
indices = (1,2,3,4,5,6)
col = ["gender", "under 15", "homework finishing"]
data = (["Female", True, "No"], ["Female", False, "Yes"], ["Male", True, "Yes"], ["Female", True, "No"],
["Male", True, "No"], ["Female", False, "Yes"])
df = pd.DataFrame(data, index = indices, columns = col)
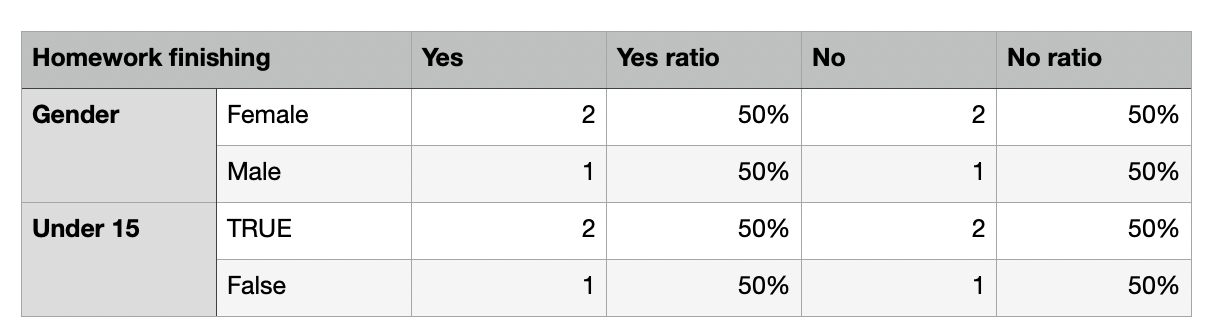
我希望結果是:
最初,我嘗試使用多索引但失敗了。或者我應該使用 groupby 嗎?
我想知道熊貓是否可以做到這一點?歡迎任何提示或幫助
uj5u.com熱心網友回復:
我不太確定您想如何劃分它,因為您的第一列同時具有Gender和Under 15作為索引,并且值以某種方式在它們之間分成兩半(它與您的第一個表格示例也沒有相加)。
但這種類似于你的例子:
>>> df.groupby(["gender", "homework finishing"]).size().unstack()
homework finishing No Yes
gender
Female 2 2
Male 1 1
>>> df.groupby(["under 15", "homework finishing"]).size().unstack()
homework finishing No Yes
under 15
False NaN 2.0
True 3.0 1.0
您當然仍然需要添加百分比除法,但我相信您可以做到這一點。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/325867.html