我有一個示例資料框,如下所示。
import pandas as pd
import numpy as np
NaN = np.nan
data = {'ID':['A', 'A', 'A', 'B','B','B'],
'Date':['2021-09-20 04:34:57', '2021-09-20 04:37:25', '2021-09-20 04:38:26', '2021-09-01
00:12:29','2021-09-01 11:20:58','2021-09-02 09:20:58'],
'Name':['xx','xx',NaN,'yy',NaN,NaN],
'Height':[174,174,NaN,160,NaN,NaN],
'Weight':[74,NaN,NaN,58,NaN,NaN],
'Gender':[NaN,'Male',NaN,NaN,'Female',NaN],
'Interests':[NaN,NaN,'Hiking,Sports',NaN,NaN,'Singing']}
df1 = pd.DataFrame(data)
df1
我想將同一日期的資料合并為一行。“日期”列采用時間戳格式。我已經為它寫了一個代碼。這是我的嘗試代碼:
嘗試:
df1['Date'] = pd.to_datetime(df1['Date'])
df_out = (df1.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.agg(lambda x: ''.join(x.dropna().astype(str)))
.reset_index()
).replace('', np.nan)
這給出了一個輸出,如果有多個相同值的條目,最終結果在同一行中有多個條目,如下所示。
獲得的輸出
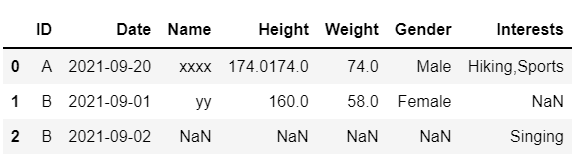 但是,如果有多個條目,我不希望重復這些值。最終輸出應如下圖所示。
但是,如果有多個條目,我不希望重復這些值。最終輸出應如下圖所示。
所需輸出
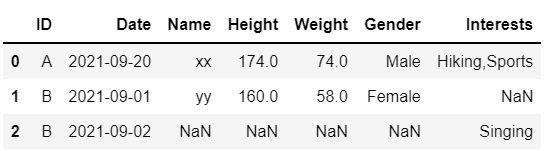
第一列不應有 'xx' 和 174.0 而不是 'xxxx' 和 '174.0 174.0'。
任何幫助是極大的贊賞。謝謝你。
uj5u.com熱心網友回復:
由于您只想為每個日期的每一列保留第一個可用值,因此您可以執行以下操作:
>>> df1.groupby(["ID", pd.Grouper(key='Date', freq='D')]).agg("first").reset_index()
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174.0 74.0 Male Hiking,Sports
1 B 2021-09-01 yy 160.0 58.0 Female None
2 B 2021-09-02 None NaN NaN None Singing
uj5u.com熱心網友回復:
在你的情況下替換agg join為first
df_out = (df1.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.first()
.reset_index()
).replace('', np.nan)
df_out
Out[113]:
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174.0 74.0 Male Hiking,Sports
1 B 2021-09-01 yy 160.0 58.0 Female None
2 B 2021-09-02 None NaN NaN None Singing
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/325874.html
上一篇:二進制DataFrame到字典