我有一個奇怪的表現,我無法解釋。在我的網路訓練程序中,在我完成了訓練批次的計算之后,我也直接去驗證集,拿了一個批次并在上面測驗我的模型。因此,我的驗證不是在與訓練不同的步驟中完成的。但我只是運行了一批訓練,然后又運行了一批驗證。
我的代碼看起來與此相似:
for (data, targets) in tqdm(training_loader):
output = net(data)
log_p_y = log_softmax_fn(output)
loss = loss_fn(log_p_y, targets)
# Do backpropagationnext(val_data)
val_output = net(valdata)
log_p_yval = log_softmax_fn(val_output)
loss_val = loss_fn(log_p_yval, valtargets)
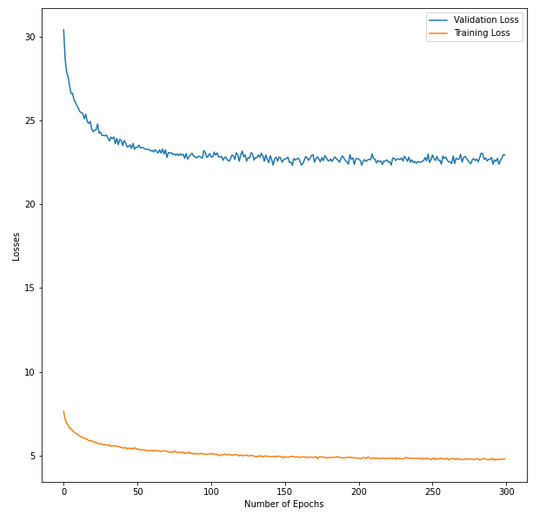
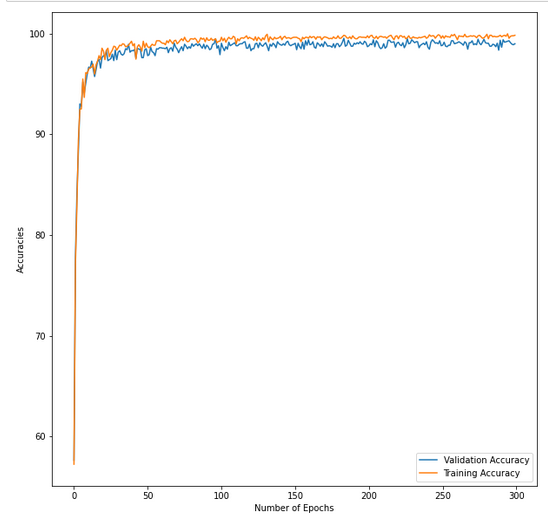
最后,我可以看到我的模型在每個 epochs 中都有很好的訓練和驗證準確率。然而,在測驗資料上,它卻沒有那么好。此外,驗證損失是訓練損失的兩倍。
。最后測驗準確率低的原因是什么?如果有人能解釋我所遇到的情況并推薦一些解決方案,我將非常高興。
這里有一張訓練和驗證損失的圖片。
這里有一張訓練和驗證準確率的圖片。
uj5u.com熱心網友回復:
我很確定,在不具代表性的驗證資料集中的原因。
不具代表性的驗證資料集意味著驗證資料集沒有提供足夠的資訊來評估模型的概括能力。 如果與訓練資料集相比,驗證資料集的例子太少,就可能發生這種情況。 請確保你的訓練和測驗資料是隨機挑選的,并盡可能準確地代表相同的分布和真實的分布。
uj5u.com熱心網友回復:
你用于訓練、測驗和驗證的資料集大小是多少?
過度擬合似乎是這里的問題,你可以通過使用L1、L2或Dropout等正則化技術來檢查。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/329659.html
標籤: