TCP的四大機制
- 一、重傳機制
- 超時重傳
- TCP以下兩種情況會發生超時重傳
- 超時時間的設定
- 連續發生超時重傳
- 快速重傳
- SACK
- Duplicate SACK
- D-SACK的好處
- 二、滑動視窗
- 累計應答模式
- 視窗大小決定方
- 發送方的視窗
- 接收方的視窗
- 三、流量控制
- 作業系統緩沖區與滑動視窗的關系
- 視窗關閉
- 視窗關閉存在的問題
- 死鎖
- 視窗探測
- 糊涂視窗綜合癥
- 避免小視窗通知
- 接收方策略
- 發送方策略
- 四、擁塞控制
- 擁塞視窗
- 擁塞控制演算法
- 慢啟動
- 擁塞避免演算法
- 擁塞發生演算法
- 發生超時重傳的擁塞發生演算法
- 發生快速重傳的擁塞發生演算法
- 快速恢復
- 五、TCP延遲確認
一、重傳機制
TCP針對資料包丟失的情況,會用重傳機制解決,
超時重傳
超時重傳:就是在發送資料時,設定?個定時器,當超過指定的時間后,沒有收到對方的ACK確認應答報文,就會重發該資料,
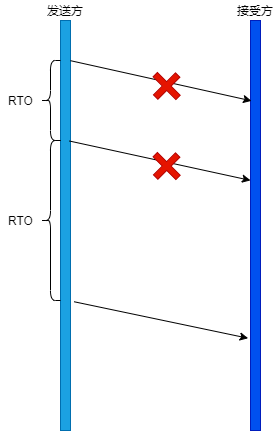
TCP以下兩種情況會發生超時重傳
- 資料包丟失
- ACK應答報文丟失
超時時間的設定
RTT:包的往返時間,
超時重傳時間是以RTO (Retransmission Timeout 超時重傳時間)表示,
- 當超時時間 RTO 較大時,重發就慢,丟了老半天才重發,沒有效率,性能差
- 當超時時間RTO較小時,會導致可能并沒有丟就重發,于是重發的就快,會增加網路擁塞,導致更多的超時,更多的超時導致更多的重發,
超時重傳時間RTO的值應該略大于報文往返RTT的值,
但是實際上,網路是波動的,所以RTT也是在變化的,那么也意味著RTO也應該是動態變化的,為此TCP通過采用資料進行處理
- 采樣RTT的時間,加權平均,算出一個平滑的RTT的值,這個值也在不斷變化
- 采樣RTT的波動范圍,
連續發生超時重傳
如果超時重發的資料,再次超時的時候,?需要重傳的時候,TCP的策略是超時間隔加倍, 也就是每當遇到?次超時重傳的時候,都會將下?次超時時間間隔設為先前值的兩倍,兩次超時,就說明網路環境差,不宜頻繁反復發送,
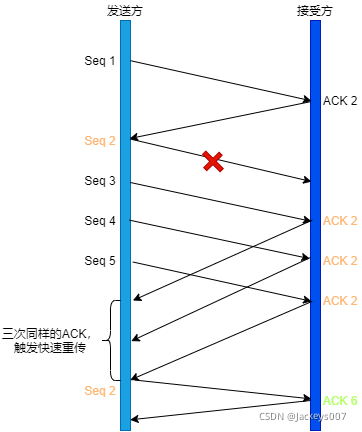
快速重傳
快速重傳的作業方式是當收到三個相同的ACK報文時,會在定時器過期之前,重傳丟失的報文段,
SACK
在TCP頭部選項欄位里加?個SACK的東西,它可以將快取的地圖發送給發送方,這樣發送方就可以知道哪些資料收到了,哪些資料沒收到,知道了這些資訊,就可以只重傳丟失的資料,
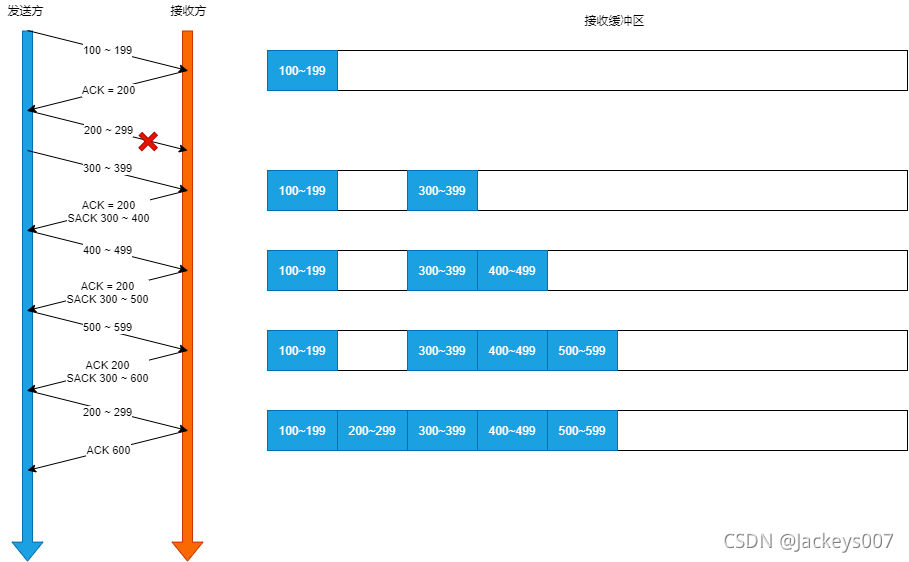
如果要支持SACK ,必須雙?都要支持,在 Linux 下,可以通過 net.ipv4.tcp_sack引數打開這個功能(Linux 2.4 后默認打開),
Duplicate SACK
Duplicate SACK稱D-SACK ,其主要使用了SACK來告訴發送方有哪些資料被重復接收了,
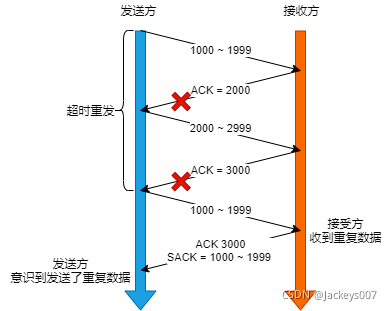
D-SACK的好處
- 可以方發送方知道,是發出的包丟了,還是接受方回應的ACK的包丟了
- 可以知道發送方的資料包被網路延遲了
- 可以知道網路中是不是把發送方的資料包給復制了
在 Linux 下可以通過 net.ipv4.tcp_dsack 引數開啟/關閉這個功能(Linux 2.4 后默認打開)
二、滑動視窗
資料包的往返時間越長,通信的效率就越低,那么有了視窗,就可以指定視窗大小,視窗大小就是指無需等待確認應答,而可以繼續發送資料的最?值,
累計應答模式
假設視窗大小為3個TCP 段,那么發送方就可以連續發送3個TCP段,并且中途若有ACK丟失,可以通過下?個確認應答進行確認,
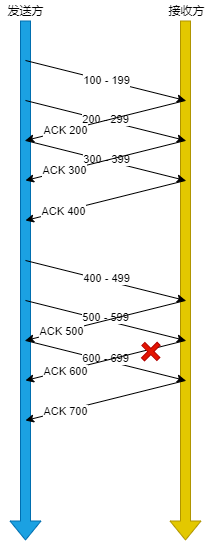
圖中即使ACK 600丟失了也沒關系,因為可以通過下?個確認應答進行確認,只要發送方收到了ACK 700 確認應答,就意味著 700 之前的所有資料接收方都收到了,這個模式就叫累計確認或者累計應答,
視窗大小決定方
TCP頭里有?個欄位叫Window ,也就是視窗大小,
這個欄位是接收端告訴發送端自己還有多少緩沖區可以接收資料,于是發送端就可以根據這個接收端的處理能力來發送資料,而不會導致接收端處理不過來,
所以,通常視窗的大小是由接收方的視窗大小來決定的, 發送方發送的資料大小不能超過接收方的視窗大小,否則接收方就無法正常接收到資料,
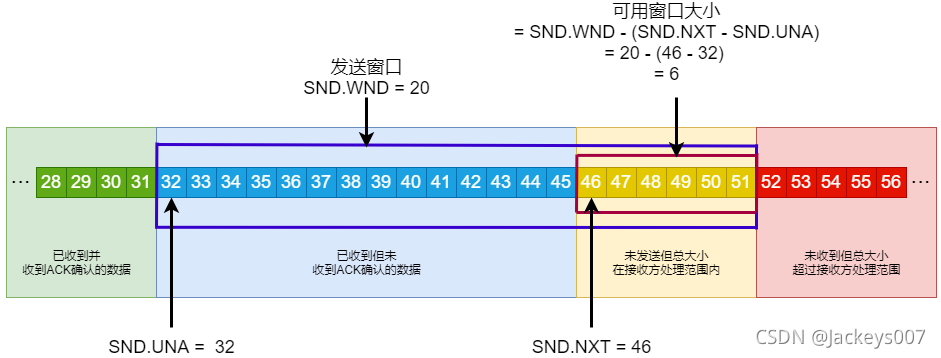
發送方的視窗
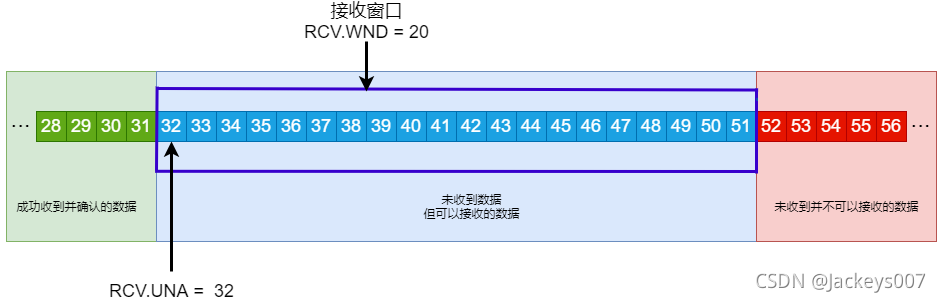
接收方的視窗
三、流量控制
流量控制主要是通過對視窗的大小的控制實作的,
作業系統緩沖區與滑動視窗的關系
假定了發送視窗和接收視窗是不變的,但是實際上,發送視窗和接收視窗中所存放的位元組數,都是放在作業系統記憶體緩沖區中的,而作業系統的緩沖區,會被作業系統調整,
TCP規定是不允許同時減少快取又收縮視窗的,而是采用先收縮視窗,過段時間再減少快取,這樣就可以避免了丟包情況,
視窗關閉
TCP 通過讓接收方指明希望從發送方接收的資料大小(視窗大小)來進行流量控制, 如果視窗大小為 0 時,就會阻止發送方給接收方傳遞資料,直到視窗變為非 0 為止,這就是視窗關閉,
視窗關閉存在的問題
死鎖
當發生視窗關閉時,接收方處理完資料后,會向發送方通告?個視窗非0的ACK報文,如果這個通告視窗的ACK報文在網路中丟失了,那麻煩就大了,這會導致發送方?直等待接收方的非0視窗通知,接收方也?直等待發送方的資料,如不采取措施,這種相互等待的程序,會造成了死鎖的現象,
視窗探測
為了解決這個問題,TCP為每個連接設有?個持續定時器,只要TCP連接一方收到對方的零視窗通知,就啟動持續計時器, 如果持續計時器超時,就會發送窗?探測 ( Window probe ) 報文,而對方在確認這個探測報文時,給出自己現在的接收視窗大小,
- 如果接收視窗仍然為0,那么收到這個報文的一方就會重新啟動持續計時器
- 如果接收視窗不是0,那么死鎖的局?就可以被打破了
視窗探測的次數?般為3次,每次大約 30-60 秒(不同的實作可能會不?樣),如果3次過后接收視窗還是0的話,有的 TCP 實作就會發 RST 報文來中斷連接,這些視窗探測報文以 3.4s、6.5s、13.5s 的間隔出現,說明超時時間會翻倍遞增,
糊涂視窗綜合癥
如果接收方太忙了,來不及取走接收視窗里的資料,那么就會導致發送方的發送視窗越來越小, 到最后,如果接收方騰出幾個位元組并告訴發送方現在有幾個位元組的視窗,而發送方會義無反顧地發送這幾個位元組, 這就是糊涂視窗綜合癥,
要知道,我們的TCP + IP頭有40個位元組,為了傳輸那幾個位元組的資料,要達上這么?的開銷,這太不經濟了,
避免小視窗通知
接收方策略
當視窗大小于min( MSS,快取空間/2 ) ,也就是小于MSS與1/2快取中的最小值時,就會向發送方通告視窗為0 ,也就阻止了發送方再發資料過來,等到接收方處理了?些資料后,視窗大小 >= MSS,或者接收方快取空間有?半可以使用,就可以把視窗打開讓發送方發送資料過來,
發送方策略
Nagle演算法:延時處理
- 等到視窗大小 >= MSS 或者資料大小 >= MSS
- 沒有已發送未確認報文時,立刻發送資料
只要沒滿足上面條件中的?條,發送方?直在囤積資料,直到滿足上面的發送條件,
四、擁塞控制
在網路出現擁堵時,如果繼續發送大量資料包,可能會導致資料包時延、丟失等,這時TCP就會重傳資料,但是?重傳就會導致網路的負擔更重,于是會導致更大的延遲以及更多的丟包,這個情況就會進?惡性回圈被不斷地放大…所以,TCP不能忽略網路上發生的事,它被設計成?個無私的協議,當網路發送擁塞時,TCP會自我犧牲,降低發送的資料量, 于是,就有了擁塞控制,控制的目的就是避免發送方的資料填滿整個網路,
擁塞視窗
擁塞視窗(cwnd)是發送方維護的?個的狀態變數,它會根據網路的擁塞程度動態變化的, 我們在前面提到過發送視窗(swnd) 和接收視窗(rwnd) 是約等于的關系,那么由于加入了擁塞視窗的概念后,此 時發送視窗的值是swnd = min(cwnd, rwnd),也就是擁塞視窗和接收視窗中的最小值,
擁塞視窗cwnd變化的規則:
- 只要網路中沒有出現擁塞, cwnd就會增大
- 但網路中出現了擁塞, cwnd就減少
網路是否擁塞 :只要發送方沒有在規定時間內接收到 ACK 應答報文,也就是發生了超時重傳,就會認為網路出現了擁塞,
擁塞控制演算法
慢啟動
慢啟動的演算法記住?個規則就行:當發送方每收到?個ACK,擁塞視窗 cwnd的大下就會加1,
可以看出慢啟動演算法,發包的個數是指數性的增長
那慢啟動漲到什么時候是個頭呢?
有?個叫慢啟動門限 ssthresh (slow start threshold)狀態變數,
- 當 cwnd < ssthresh 時,使用慢啟動演算法,
- 當 cwnd >= ssthresh 時,就會使用擁塞避免演算法
?般來說 ssthresh 的大小是 65535 位元組,
擁塞避免演算法
進入擁塞避免演算法后,它的規則是:每當收到?個 ACK 時,cwnd 增加 1/cwnd,我們可以發現,擁塞避免演算法就是將原本慢啟動演算法的指數增堆疊變成了線性增堆疊,還是增長階段,但是增長速度緩慢了?些, 就這么?直增?著后,網路就會慢慢進?了擁塞的狀況了,于是就會出現丟包現象,這時就需要對丟失的資料包進行重傳, 當觸發了重傳機制,也就進入了擁塞發生演算法,
擁塞發生演算法
發生超時重傳的擁塞發生演算法
- ssthresh設為cwnd/2
- cwnd重置為1
發生快速重傳的擁塞發生演算法
- cwnd = cwnd/2 ,也就是設定為原來的?半;
- ssthresh = cwnd,進?快速恢復演算法
快速恢復
- 擁塞視窗cwnd = ssthresh + 3 ( 3 的意思是確認有 3 個資料包被收到了)
- 重傳丟失的資料包
- 如果再收到重復的 ACK,那么 cwnd 增加 1
- 如果收到新資料的 ACK 后,把 cwnd 設定為第?步中的 ssthresh 的值,原因是該 ACK 確認了新的資料,說明從 duplicated ACK 時的資料都已收到,該恢復程序已經結束,可以回到恢復之前的狀態了,也即再次進入擁塞避免狀態
五、TCP延遲確認
為了解決 ACK 傳輸效率低問題,所以就衍?出了 TCP 延遲確認
TCP延遲確認的策略
- 當有回應資料要發送時,ACK 會隨著回應資料?起?刻發送給對方
- 當沒有回應資料要發送時,ACK 將會延遲?段時間,以等待是否有回應資料可以?起發送
- 如果在延遲等待發送 ACK期間,對方的第?個資料報文又到達了,這時就會立刻發送ACK
- TCP延遲確認可以在 Socket 設定 TCP_QUICKACK 選項來關閉這個演算法
當TCP 延遲確認和Nagle演算法混合使用時,會導致時耗增長
要解決這個問題,只有兩個辦法
- 要不發送方關閉Nagle演算法
- 要不接收方關閉TCP延遲確認
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/330258.html
標籤:其他