文章目錄
- 確定優化目標
- 網路性能工具
- 網路性能優化
- 應用程式
- 套接字
- 傳輸層
- 網路層
- 鏈路層
- 小結
確定優化目標
網路性能優化的目標是什么?換句話說,觀察到的網路性能指標,要達到多少才合適呢?
- 實際上,雖然網路性能優化的整體目標,是降低網路延遲(如 RTT)和提高吞吐量(如 BPS 和 PPS),但具體到不同應用中,每個指標的優化標準可能會不同,優先級順序也大相徑庭,
- NAT 網關通常需要達到或接近線性轉發,也就是說, PPS 是最主要的性能目標,
- 再如,對于資料庫、快取等系統,快速完成網路收發,即低延遲,是主要的性能目標,
- 對于我們經常訪問的 Web 服務來說,則需要同時兼顧吞吐量和延遲,
- 所以,為了更客觀合理地評估優化效果,首先應該明確優化的標準,即要對系統和應用程式進行基準測驗,得到網路協議堆疊各層的基準性能,
Linux 網路協議堆疊,是我們需要掌握的核心原理,它是基于 TCP/IP 協議族的分層結構
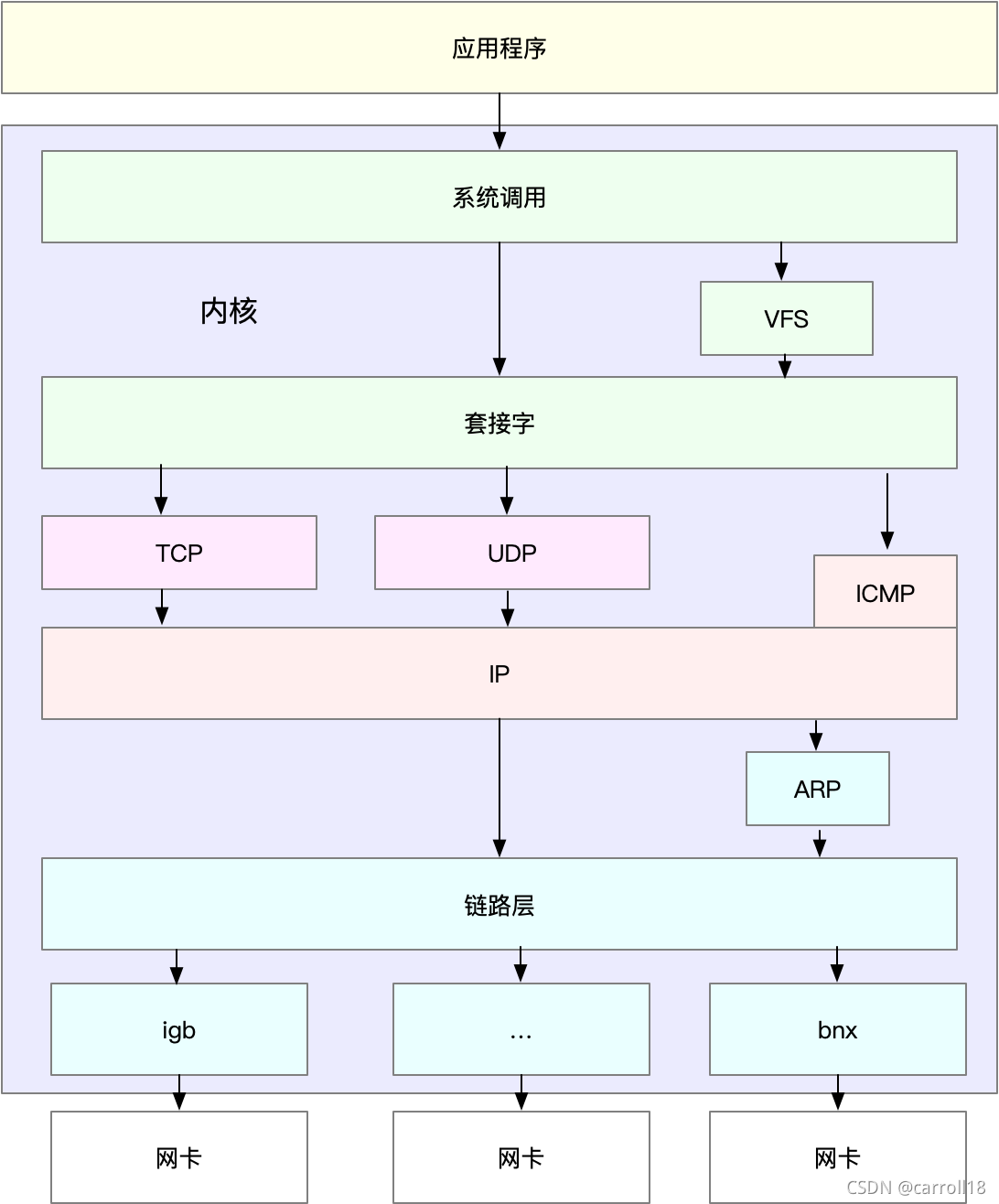
- 在進行基準測驗時,可以按照協議堆疊的每一層來測驗,由于底層是其上方各層的基礎,底層性能也就決定了高層性能,
- 首先是網路介面層和網路層,它們主要負責網路包的封裝、尋址、路由,以及發送和接收,每秒可處理的網路包數 PPS,就是它們最重要的性能指標(特別是在小包的情況下),你可以用內核自帶的發包工具
pktgen,來測驗 PPS 的性能, - 再向上到傳輸層的 TCP 和 UDP,它們主要負責網路傳輸,對它們而言,吞吐量(BPS)、連接數以及延遲,就是最重要的性能指標,你可以用
iperf或netperf,來測驗傳輸層的性能, - 不過要注意,網路包的大小,會直接影響這些指標的值,所以,通常,你需要測驗一系列不同大小網路包的性能,
- 最后,再往上到了應用層,最需要關注的是吞吐量(BPS)、每秒請求數以及延遲等指標,你可以用
wrk、ab等工具,來測驗應用程式的性能,
- 首先是網路介面層和網路層,它們主要負責網路包的封裝、尋址、路由,以及發送和接收,每秒可處理的網路包數 PPS,就是它們最重要的性能指標(特別是在小包的情況下),你可以用內核自帶的發包工具
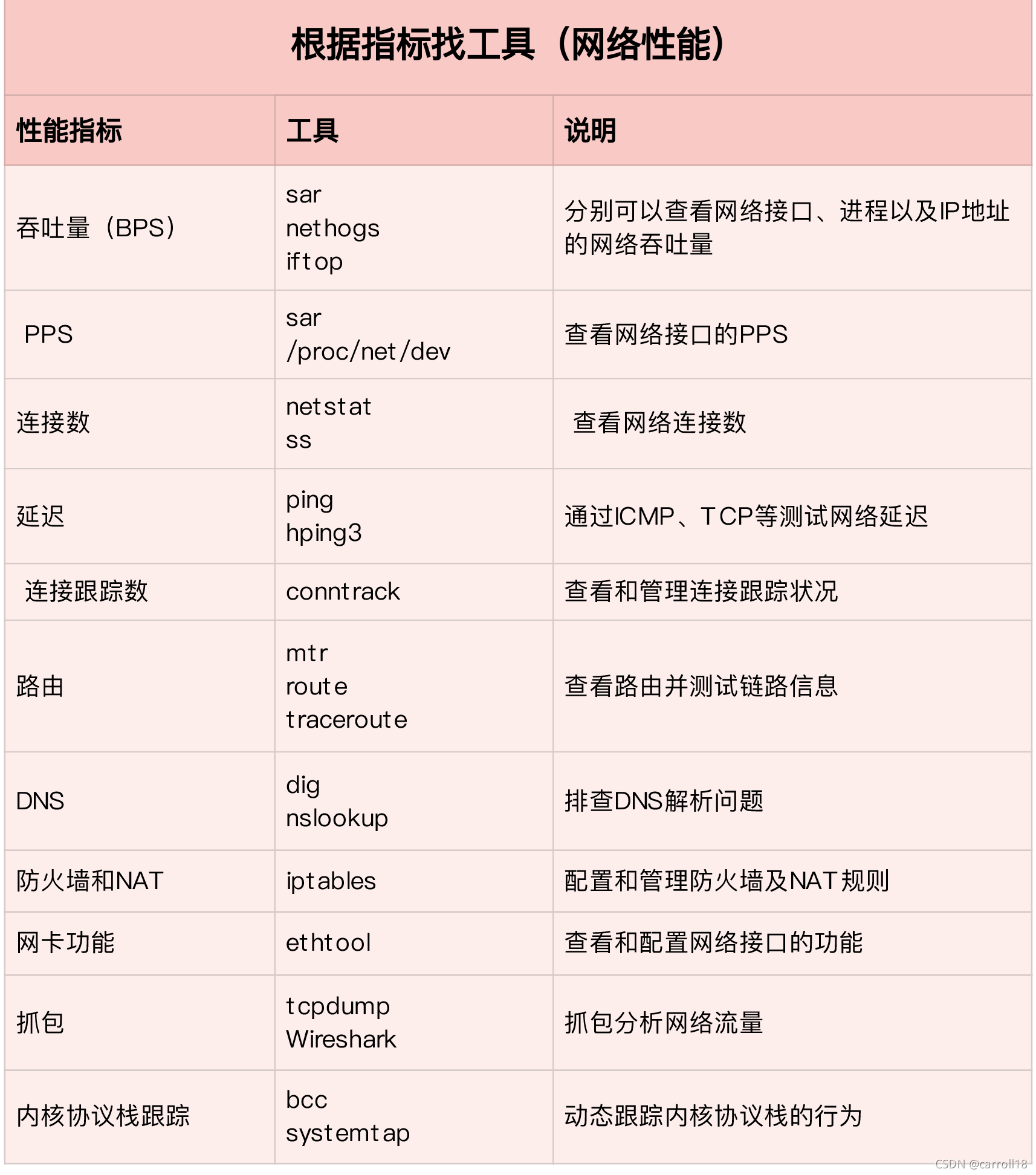
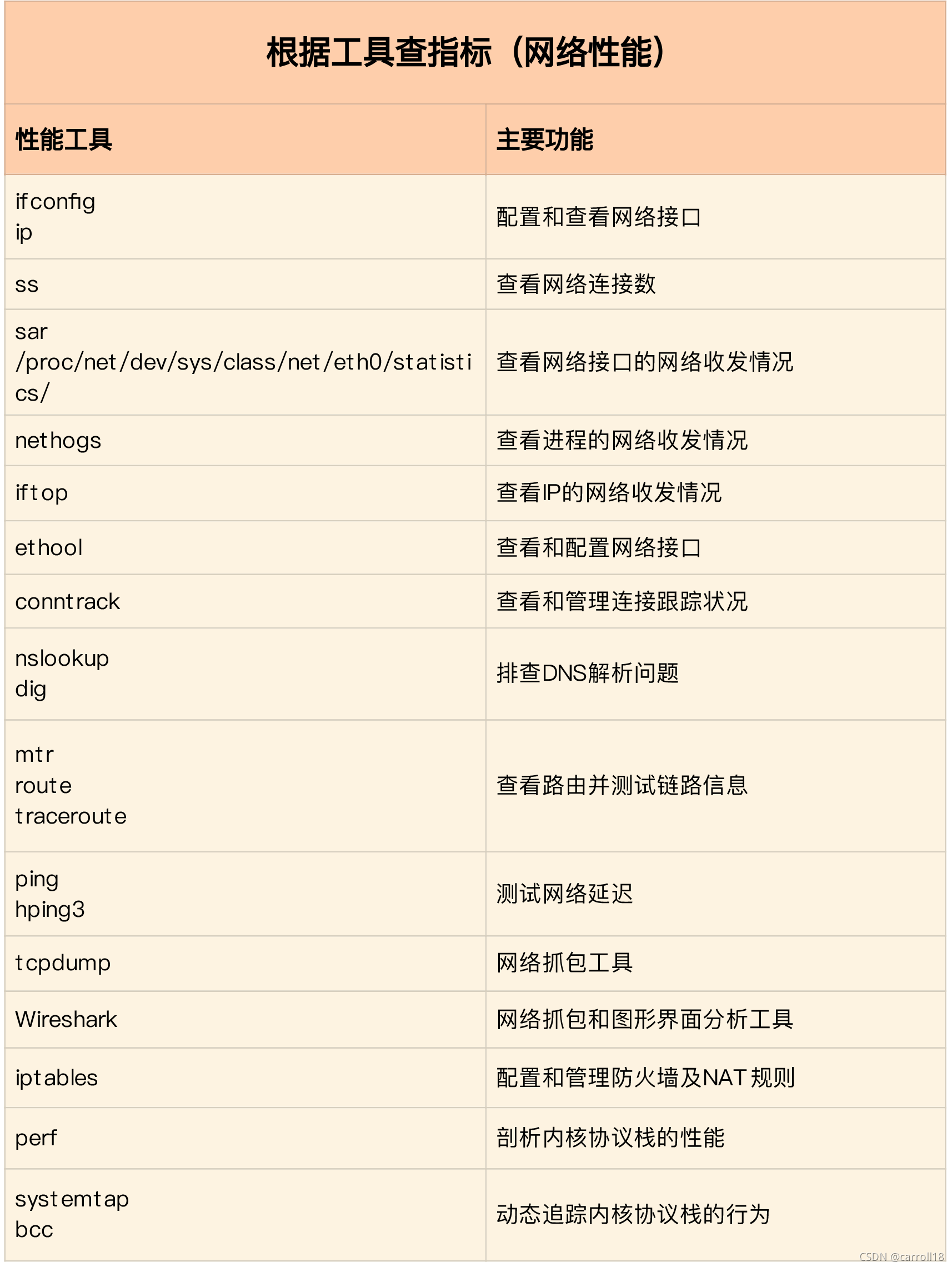
網路性能工具
網路性能優化
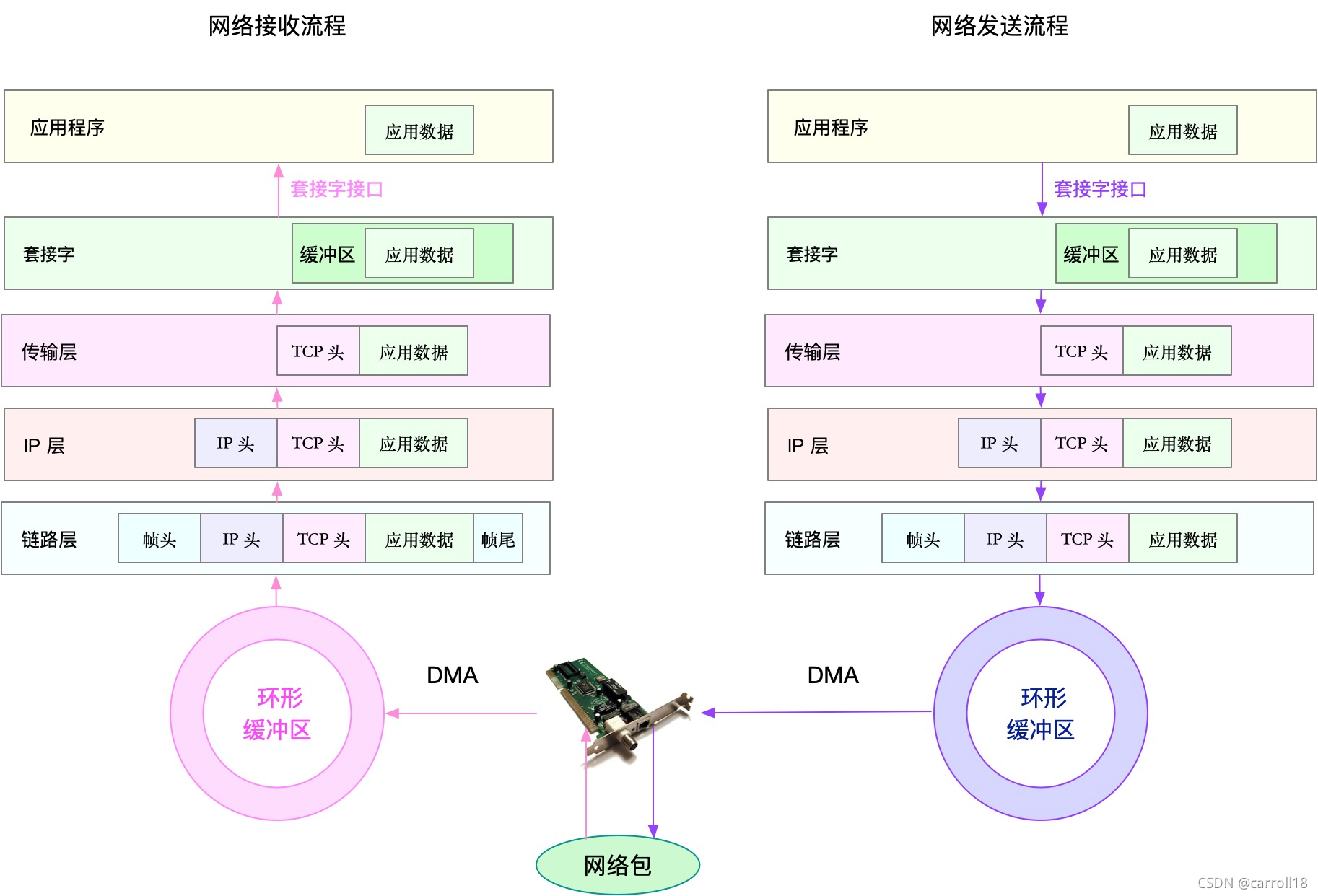
- 要優化網路性能,肯定離不開 Linux 系統的網路協議堆疊和網路收發流程的輔助,
應用程式
應用程式,通常通過套接字介面進行網路操作,由于網路收發通常比較耗時,所以應用程式的優化,主要就是對網路 I/O 和行程自身的作業模型的優化,
- 從網路 I/O 的角度來說,主要有下面兩種優化思路,
- 第一種是最常用的 I/O 多路復用技術 epoll,主要用來取代 select 和 poll,這其實是解決 C10K 問題的關鍵,也是目前很多網路應用默認使用的機制,
- 第二種是使用異步 I/O(Asynchronous I/O,AIO),AIO 允許應用程式同時發起很多 I/O 操作,而不用等待這些操作完成,等到 I/O 完成后,系統會用事件通知的方式,告訴應用程式結果,不過,AIO 的使用比較復雜,你需要小心處理很多邊緣情況,
- 從行程的作業模型來說,也有兩種不同的模型用來優化,
- 第一種,主行程 + 多個 worker 子行程,其中,主行程負責管理網路連接,而子行程負責實際的業務處理,這也是最常用的一種模型,
- 第二種,監聽到相同埠的多行程模型,在這種模型下,所有行程都會監聽相同介面,并且開啟 SO_REUSEPORT 選項,由內核負責,把請求負載均衡到這些監聽行程中去,
- 除了網路 I/O 和行程的作業模型外,應用層的網路協議優化,也是至關重要的一點,常見的幾種優化方法,
- 使用長連接取代短連接,可以顯著降低 TCP 建立連接的成本,在每秒請求次數較多時,這樣做的效果非常明顯,
- 使用記憶體等方式,來快取不常變化的資料,可以降低網路 I/O 次數,同時加快應用程式的回應速度,
- 使用 Protocol Buffer 等序列化的方式,壓縮網路 I/O 的資料量,可以提高應用程式的吞吐,
- 使用 DNS 快取、預取、HTTPDNS 等方式,減少 DNS 決議的延遲,也可以提升網路 I/O 的整體速度,
套接字
- 套接字可以屏蔽掉 Linux 內核中不同協議的差異,為應用程式提供統一的訪問介面,每個套接字,都有一個讀寫緩沖區,
- 讀緩沖區,快取了遠端發過來的資料,如果讀緩沖區已滿,就不能再接收新的資料,
- 寫緩沖區,快取了要發出去的資料,如果寫緩沖區已滿,應用程式的寫操作就會被阻塞,
- 所以,為了提高網路的吞吐量,通常需要調整這些緩沖區的大小,比如:
- 增大每個套接字的緩沖區大小 net.core.optmem_max;
- 增大套接字接識訓沖區大小 net.core.rmem_max 和發送緩沖區大小 net.core.wmem_max;
- 增大 TCP 接識訓沖區大小 net.ipv4.tcp_rmem 和發送緩沖區大小 net.ipv4.tcp_wmem,
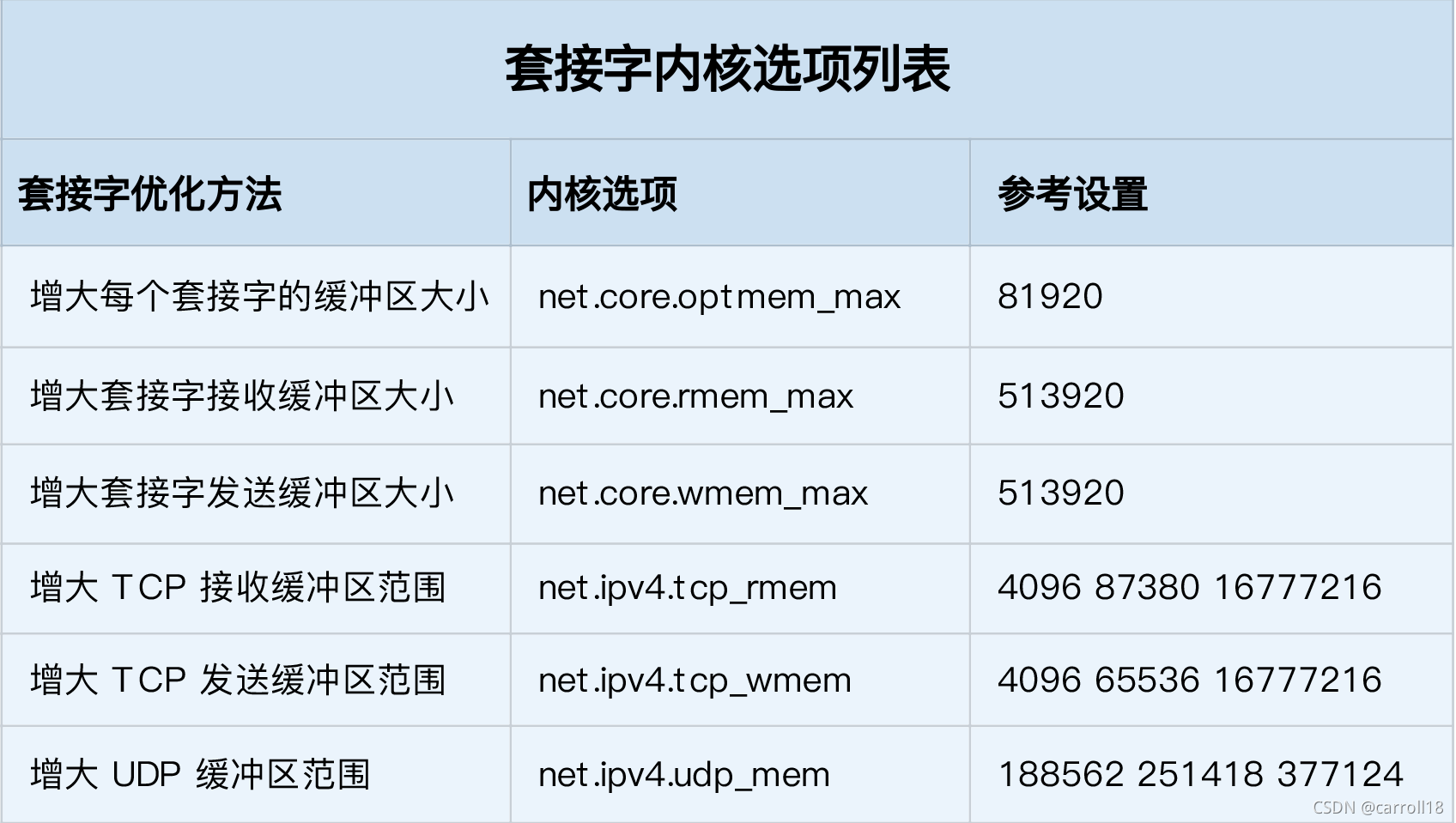
- 有幾點需要注意,
- tcp_rmem 和 tcp_wmem 的三個數值分別是 min,default,max,系統會根據這些設定,自動調整 TCP 接收 / 發送緩沖區的大小,
- udp_mem 的三個數值分別是 min,pressure,max,系統會根據這些設定,自動調整 UDP 發送緩沖區的大小,
- 套接字介面還提供了一些配置選項,用來修改網路連接的行為:
- 為 TCP 連接設定 TCP_NODELAY 后,就可以禁用 Nagle 演算法;
- 為 TCP 連接開啟 TCP_CORK 后,可以讓小包聚合成大包后再發送(注意會阻塞小包的發送);
- 使用 SO_SNDBUF 和 SO_RCVBUF ,可以分別調整套接字發送緩沖區和接識訓沖區的大小,
傳輸層
傳輸層最重要的是 TCP 和 UDP 協議,所以這兒的優化,其實主要就是對這兩種協議的優化,
TCP 協議的優化
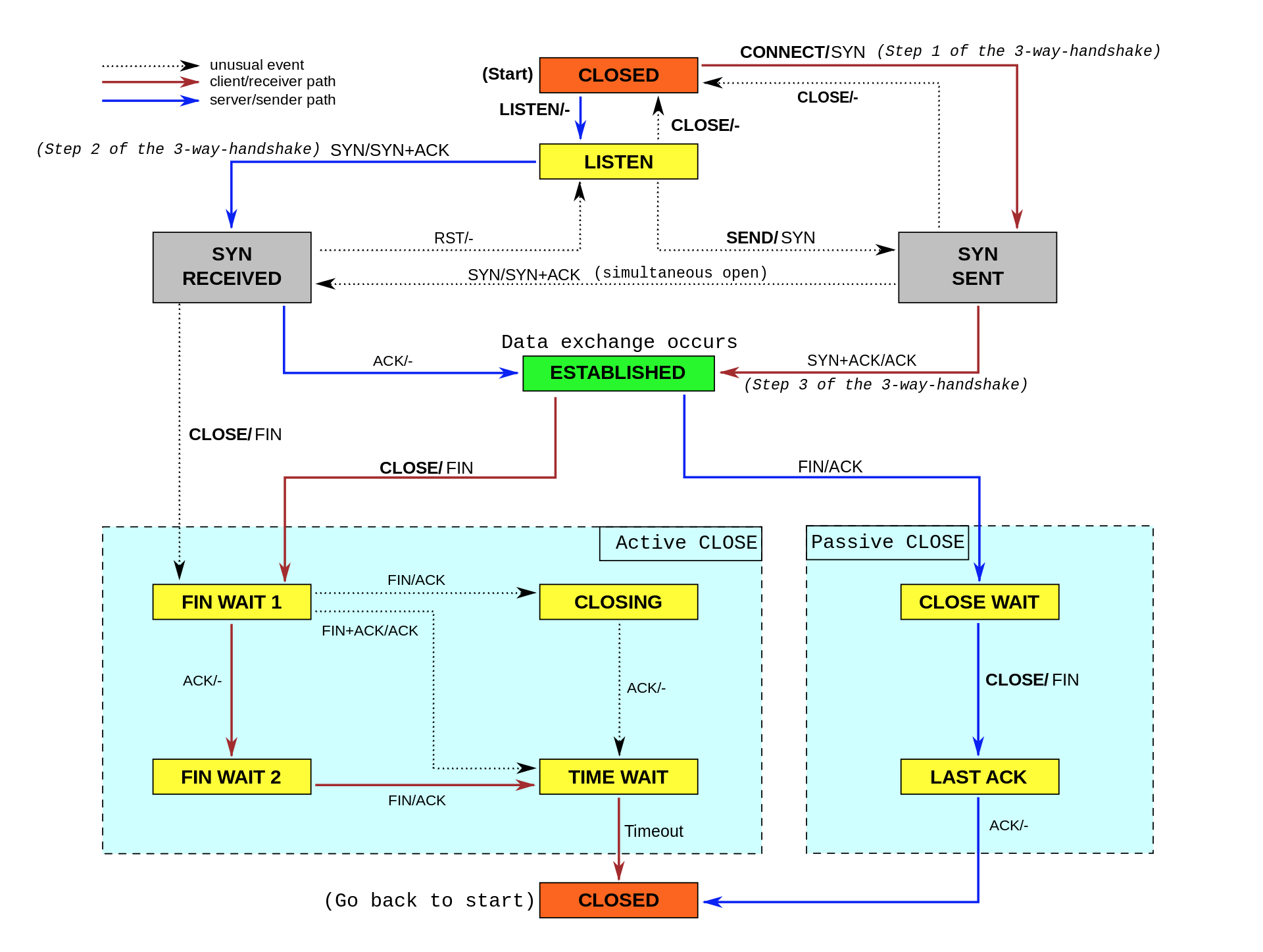
- TCP 提供了面向連接的可靠傳輸服務,要優化 TCP,我們首先要掌握 TCP 協議的基本原理,比如流量控制、慢啟動、擁塞避免、延遲確認以及狀態流圖(如下圖所示)等,
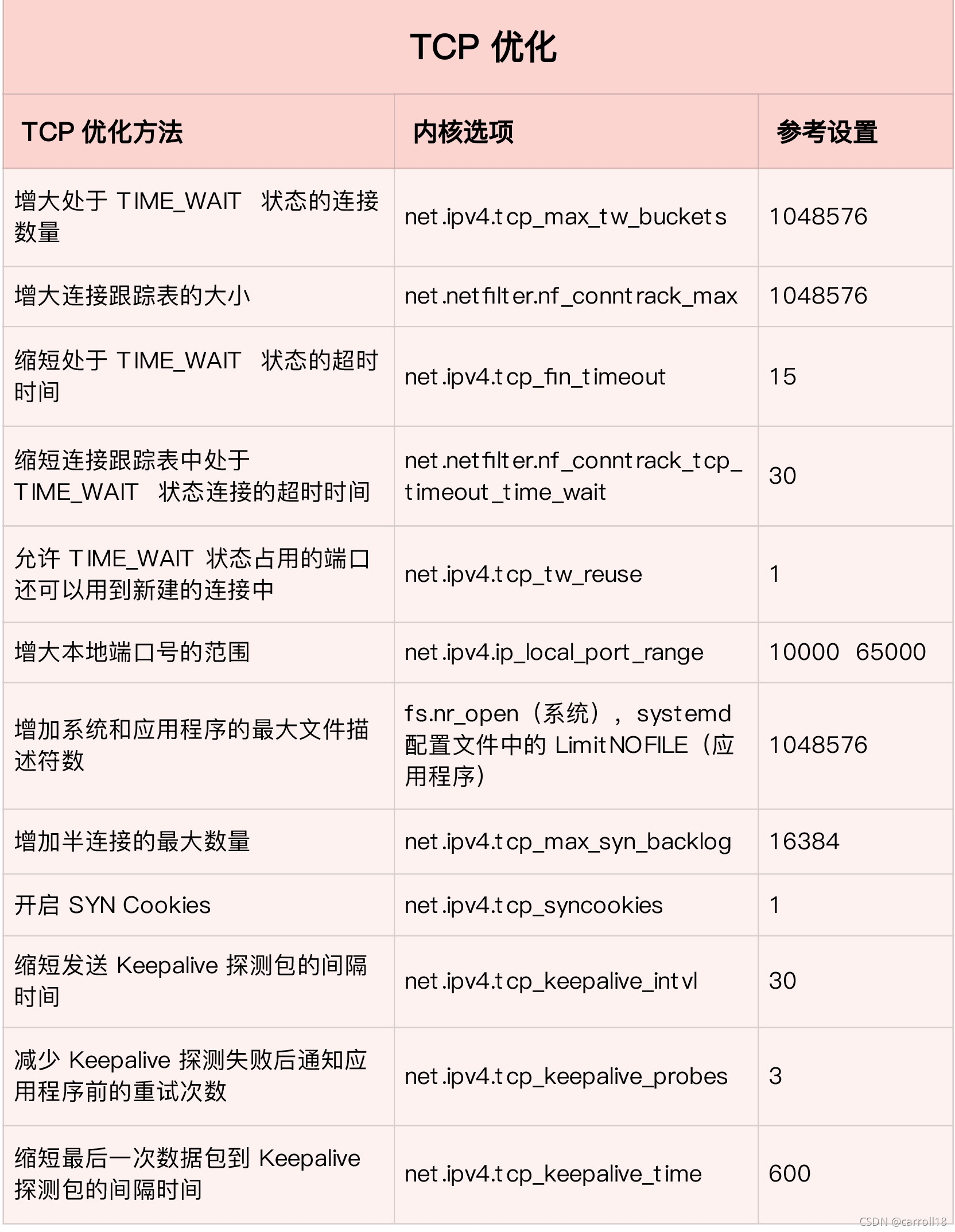
UDP的優化
- UDP 提供了面向資料報的網路協議,它不需要網路連接,也不提供可靠性保障,所以,UDP 優化,相對于 TCP 來說,要簡單得多,這里總結了常見的幾種優化方案,
- 跟套接字部分提到的一樣,增大套接字緩沖區大小以及 UDP 緩沖區范圍;
- 跟 TCP 部分提到的一樣,增大本地埠號的范圍;
- 根據 MTU 大小,調整 UDP 資料包的大小,減少或者避免分片的發生,
網路層
- 網路層,負責網路包的封裝、尋址和路由,包括 IP、ICMP 等常見協議,在網路層,最主要的優化,其實就是對路由、 IP 分片以及 ICMP 等進行調優,
- 第一種,從路由和轉發的角度出發,你可以調整下面的內核選項,
- 在需要轉發的服務器中,比如用作 NAT 網關的服務器或者使用 Docker 容器時,開啟 IP 轉發,即設定 net.ipv4.ip_forward = 1,
- 調整資料包的生存周期 TTL,比如設定 net.ipv4.ip_default_ttl = 64,注意,增大該值會降低系統性能,
- 開啟資料包的反向地址校驗,比如設定 net.ipv4.conf.eth0.rp_filter = 1,這樣可以防止 IP 欺騙,并減少偽造 IP 帶來的 DDoS 問題,
- 第二種,從分片的角度出發,最主要的是調整 MTU(Maximum Transmission Unit)的大小,
- 第三種,從 ICMP 的角度出發,為了避免 ICMP 主機探測、ICMP Flood 等各種網路問題,你可以通過內核選項,來限制 ICMP 的行為,
- 比如,你可以禁止 ICMP 協議,即設定 net.ipv4.icmp_echo_ignore_all = 1,這樣,外部主機就無法通過 ICMP 來探測主機,
- 或者,你還可以禁止廣播 ICMP,即設定 net.ipv4.icmp_echo_ignore_broadcasts = 1,
鏈路層
- 鏈路層負責網路包在物理網路中的傳輸,比如 MAC 尋址、錯誤偵測以及通過網卡傳輸網路幀等,自然,鏈路層的優化,也是圍繞這些基本功能進行的,接下來,從不同的幾個方面分別來看,
- 由于網卡收包后呼叫的中斷處理程式(特別是軟中斷),需要消耗大量的 CPU,所以,將這些中斷處理程式調度到不同的 CPU 上執行,就可以顯著提高網路吞吐量,這通常可以采用下面兩種方法,
- 可以為網卡硬中斷配置 CPU 親和性(smp_affinity),或者開啟 irqbalance 服務,
- 可以開啟 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),將應用程式和軟中斷的處理,調度到相同 CPU 上,這樣就可以增加 CPU 快取命中率,減少網路延遲,
- 另外,現在的網卡都有很豐富的功能,原來在內核中通過軟體處理的功能,可以卸載到網卡中,通過硬體來執行,
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 協議中直接發送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由網卡來完成 ,
- GSO(Generic Segmentation Offload):在網卡不支持 TSO/UFO 時,將 TCP/UDP 包的分段,延遲到進入網卡前再執行,這樣,不僅可以減少 CPU 的消耗,還可以在發生丟包時只重傳分段后的包,
- LRO(Large Receive Offload):在接收 TCP 分段包時,由網卡將其組裝合并后,再交給上層網路處理,不過要注意,在需要 IP 轉發的情況下,不能開啟 LRO,因為如果多個包的頭部資訊不一致,LRO 合并會導致網路包的校驗錯誤,
- GRO(Generic Receive Offload):GRO 修復了 LRO 的缺陷,并且更為通用,同時支持 TCP 和 UDP,
- RSS(Receive Side Scaling):也稱為多佇列接收,它基于硬體的多個接收佇列,來分配網路接收行程,這樣可以讓多個 CPU 來處理接收到的網路包,
- VXLAN 卸載:也就是讓網卡來完成 VXLAN 的組包功能,
- 最后,對于網路介面本身,也有很多方法,可以優化網路的吞吐量,
- 可以開啟網路介面的多佇列功能,這樣,每個佇列就可以用不同的中斷號,調度到不同 CPU 上執行,從而提升網路的吞吐量,
- 可以增大網路介面的緩沖區大小,以及佇列長度等,提升網路傳輸的吞吐量(注意,這可能導致延遲增大),
- 可以使用 Traffic Control 工具,為不同網路流量配置 QoS,
小結
- 在優化網路的性能時,我們可以結合 Linux 系統的網路協議堆疊和網路收發流程,從應用程式、套接字、傳輸層、網路層再到鏈路層等,對每個層次進行逐層優化,
- 實際上,我們分析和定位網路瓶頸,也是基于這些網路層進行的,而定位出網路性能瓶頸后,我們就可以根據瓶頸所在的協議層,進行優化,具體而言:
- 在應用程式中,主要是優化 I/O 模型、作業模型以及應用層的網路協議;
- 在套接字層中,主要是優化套接字的緩沖區大小;
- 在傳輸層中,主要是優化 TCP 和 UDP 協議;
- 在網路層中,主要是優化路由、轉發、分片以及 ICMP 協議;
- 最后,在鏈路層中,主要是優化網路包的收發、網路功能卸載以及網卡選項,
- 如果這些方法依然不能滿足你的要求,那就可以考慮,使用 DPDK 等用戶態方式,繞過內核協議堆疊;或者,使用 XDP,在網路包進入內核協議堆疊前進行處理,
你知道的越多,你不知道的越多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/330262.html
標籤:其他
上一篇:k8s部署express web應用(最新驗證,手把手教學)
下一篇:Web——面試題整理