反向代理
代理其實就是一個中介,A和B本來可以直連,中間插入一個C,C就是中介,根據代理的角色,可以分為正向代理,反向代理
正向代理即是客戶端代理, 代理客戶端, 服務端不知道實際發起請求的客戶端.
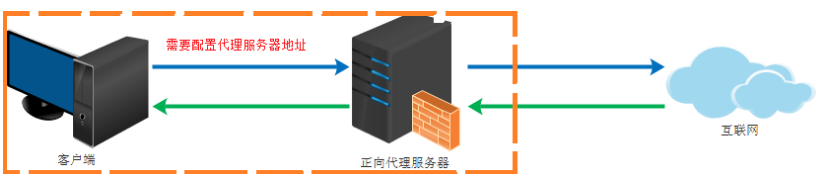
比如我們國內訪問谷歌,直接訪問訪問不到,我們可以通過一個正向代理服務器,請求發到代理服務器,代理服務器能夠訪問谷歌,這樣由代理去谷歌取到回傳資料,再回傳給我們,這樣我們就能訪問谷歌了
這個現實中可以類比為買票的黃牛
反向代理即是服務端代理, 代理服務端, 客戶端不知道實際提供服務的服務端
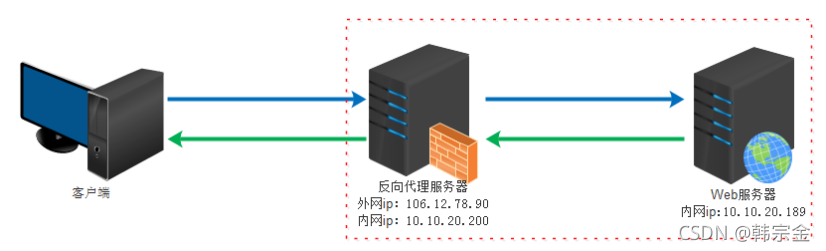
反向代理(Reverse Proxy)實際運行方式是指以代理服務器來接受internet上的連接請求,然后將請求轉發給內部網路上的服務器,并將從服務器上得到的結果回傳給internet上請求連接的客戶端,此時代理服務器對外就表現為一個服務器
反向代理的作用:
(1)保證內網的安全,阻止web攻擊,大型網站,通常將反向代理作為公網訪問地址,Web服務器是內網
(2)負載均衡,通過反向代理服務器來優化網站的負載
反向代理在現實中可以類比為租房的中介
Nginx
使用Nginx作為反向代理服務器
本機搭建域名環境
如果正式發布,需要購買域名什么的,測驗就在本地搭建,搭建步驟:
修改host檔案,是用于本地dns服務的,采用ip 域名的格式寫在一個文本檔案當中,其作用就是將一些常用的網址域名與其對應的IP地址建立一個關聯“資料庫”,當用戶在瀏覽器中輸入一個網址時,系統會首先自動從Hosts檔案中尋找對應的IP地址,一旦找到,系統會立即打開對應網頁,如果沒有找到,則系統再會將網址提交DNS域名決議服務器進行IP地址的決議,
這個檔案的位置在C:\Windows\System32\drivers\etc下
如果嫌每次修改麻煩,可以使用SwitchHosts,這個可以自己嘗試,我電腦使用這個容易死機,就先不用了
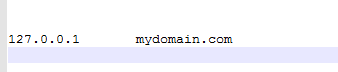
因為我在本地測驗的,所以把本地的localhost修改為一個域名,比如mydomain.com,如果有虛擬機或者其他環境,可以換成對應的ip
然后我訪問服務,http://127.0.0.1:7000/coupon/coupon/test,然后修改為對應域名
http://mydomain.com:7000/coupon/coupon/test
同樣可以訪問
Nginx配置
上邊演示的只是本地環境,如果在其他服務上,安裝nginx,這個域名對應那個nginx的ip地址,然后在nginx里邊對訪問進行分配,根據規則,對不同url分配不同的服務
Nginx下載解壓,然后在安裝目錄啟動命令列,運行nginx.exe,
E:\springbootLearn\nginx-1.20.1\nginx-1.20.1>nginx.exe
然后在瀏覽器輸入http://localhost:8080/,如果出現
說明啟動成功,然后打開conf目錄下的nginx.conf,在里邊進行配置,比如這里我訪問http://mydomain.com:9001/coupon/coupon/test,正式環境,這個域名對應的ip設定一下
server {
listen 9001;
server_name mydomain.com;
location ~ /coupon/ {
proxy_pass http://127.0.0.1:7000;
}
}
這樣訪問上一個url,請求里包含coupon,就可以跳轉到對應ip的地址,這個正式發布,127.0.0.1可以改為對應服務的地址
Nginx基本使用
負載均衡
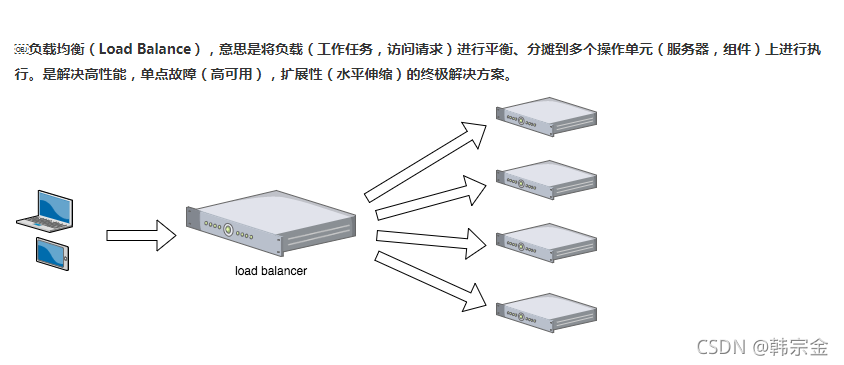
負載均衡,就是將負載分攤到多個服務器,有多種演算法,這個在nginx里邊配置,就需要配置多個服務器地址
nginx負載均衡
http {
upstream gulimail{
server 127.0.0.1:7000;
server 192.168.0.28:8002;
}
server {
listen 80;
server_name gulimail.com;
location / {
proxy_pass http://gulimail
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
}
gulimail是服務的域名或者專案的代號,然后設定這個proxy_set_header Host $host;原因是nginx會丟失Host,不加上,網關攔截host會失敗
專案中,gateWay網關可以設定為
- id: gulimail_host_route
uri: lb://gulimall-product
predicates:
- Host=**.gulimail.com,gulimail.com
攔截到這個gulimail.com,就會跳轉到商品服務
這種粗粒度的匹配最后放在最后,放在前邊,會直接攔截掉一些請求,走不到下邊配置的匹配
- id: product_route
uri: lb://gulimall-product
predicates:
- Path=/api/product/**
filters:
- RewritePath=/api/(?<segment>.*),/$\{segment}
像這樣的可能無法匹配,在前邊就被攔截了
按我的理解,總結一下流程,首先在本地新建域名,對應nginx的ip地址,然后再配置nginx,根據url來分配對應的服務
動靜分離
專案中,有些請求是需要后臺處理的(如:.jsp,.do等等),有些請求是不需要經過后臺處理的(如:css、html、jpg、js等等檔案),這些不需要經過后臺處理的檔案稱為靜態檔案,否則動態檔案,如果將靜態檔案也放在服務器,訪問時候性能會降低,可以把靜態資源放到另一個服務器,比如將靜態資源放到nginx中,動態資源轉發到tomcat服務器中,
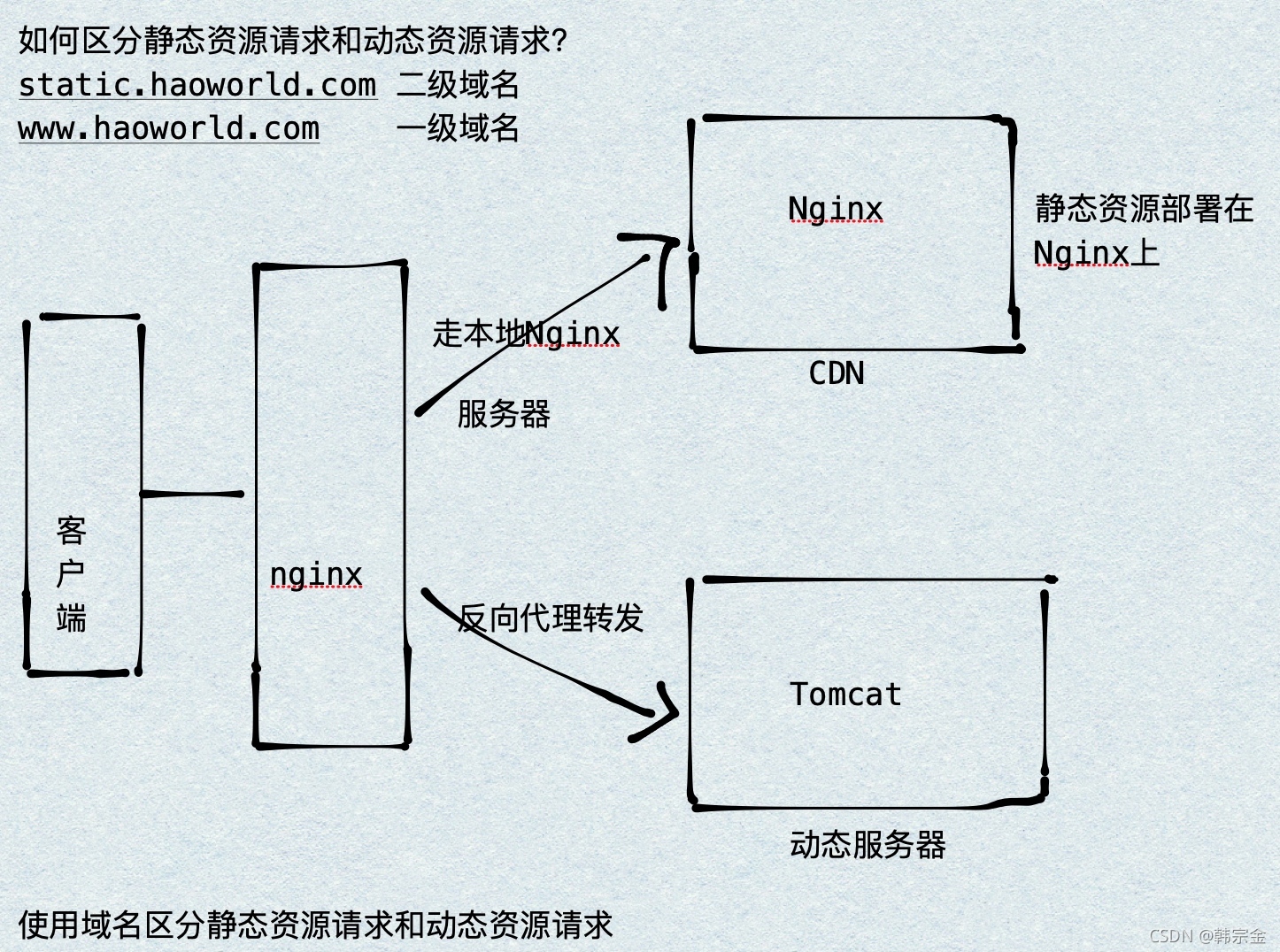
nginx配置
通過location對請求url進行匹配即可,在/Users/Hao/Desktop/Test(任意目錄)下創建 /static/imgs 配置如下
###靜態資源訪問
server {
listen 80;
server_name static.haoworld.com;
location /static/imgs {
root /Users/Hao/Desktop/Test;
index index.html index.htm;
}
}
###動態資源訪問
server {
listen 80;
server_name www.haoworld.com;
location / {
proxy_pass http://127.0.0.1:8080;
index index.html index.htm;
}
}
參考文章:
【Nginx】實作動靜分離
Nginx實作動靜分離
Nginx的動靜分離
快取
為了系統性能的提升, 我們一般都會將部分資料放入快取中, 加速訪問, 而 db 承擔資料落
盤作業,
哪些資料適合放入快取?
1.即時性、 資料一致性要求不高的
2. 訪問量大且更新頻率不高的資料(讀多, 寫少)
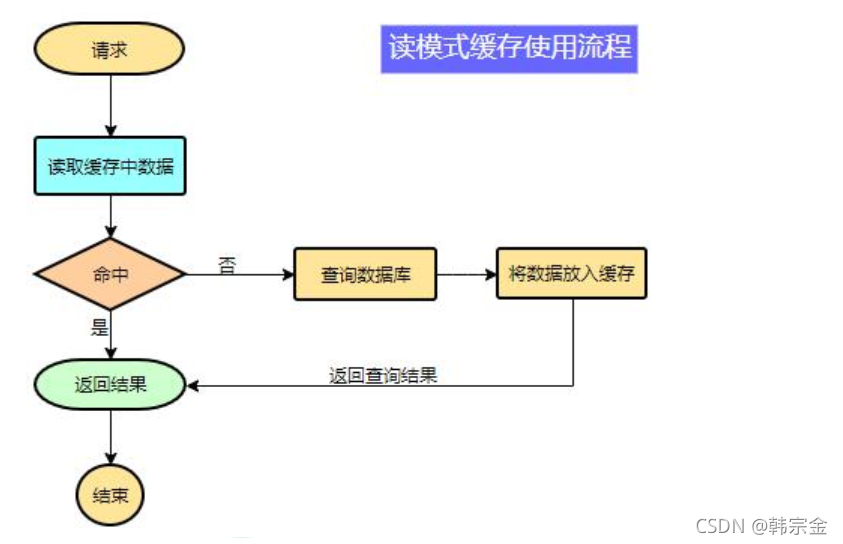
偽代碼:
data = cache.load(id);//從快取加載資料
If(data == null){
data = db.load(id);//從資料庫加載資料
cache.put(id,data);//保存到 cache 中
}
return data;
最簡單的快取是本地快取,在代碼里寫一個Map,然后查詢資料之前,查詢Map里是否包含資料,沒有就查詢資料庫,查詢出資料,保存一份到Map中,
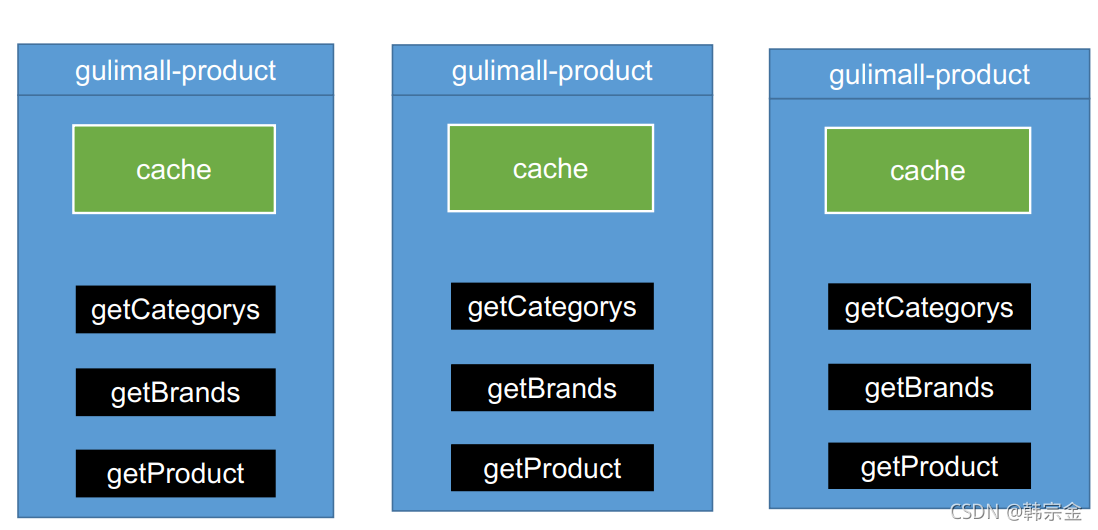
本地快取在分布式下會出現問題,負載均衡可能訪問A,B,C三臺服務器,有可能更改A服務器的快取,然后第二次到B服務器訪問,B服務器快取還是老的,沒辦法同步修改快取,保持資料一致性
分布式情況下,將快取提取出來,所有服務器訪問和操作同一快取
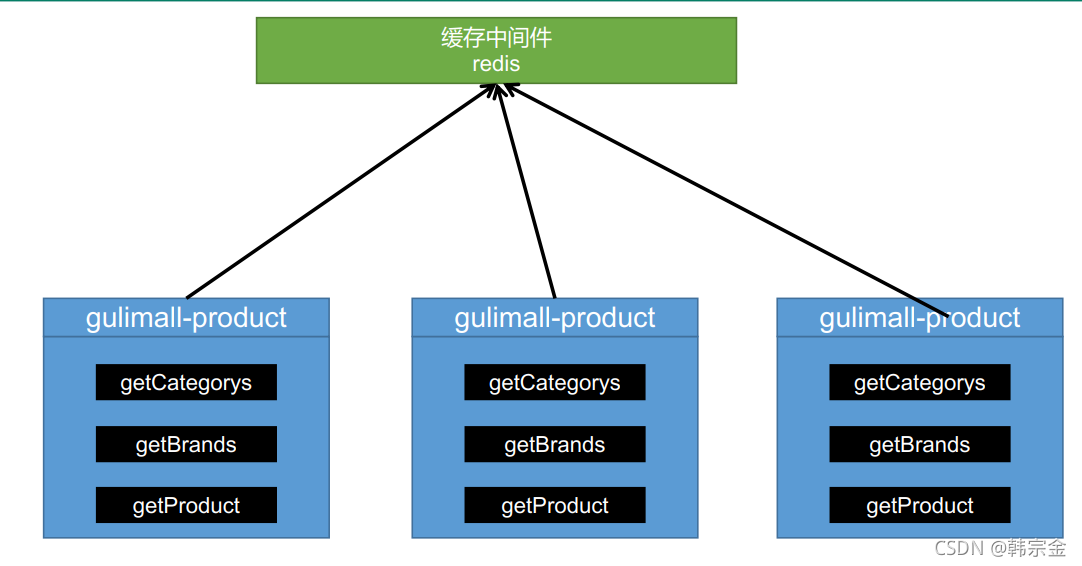 注意: 在開發中, 凡是放入快取中的資料我們都應該指定過期時間, 使其可以在系統即使沒有主動更新資料也能自動觸發資料加載進快取的流程, 避免業務崩潰導致的資料永久不一致問題
注意: 在開發中, 凡是放入快取中的資料我們都應該指定過期時間, 使其可以在系統即使沒有主動更新資料也能自動觸發資料加載進快取的流程, 避免業務崩潰導致的資料永久不一致問題
spring boot整合redis
pom.xml增加參考
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
application.yml中配置
redis:
host: 192.168.56.10
port: 6379
使用 RedisTemplate 操作 redis
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void testStringRedisTemplate(){
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
ops.set("hello","world_"+ UUID.randomUUID().toString());
String hello = ops.get("hello");
System.out.println(hello);
}
Idea搜索jar包中的檔案,快捷鍵是ctrl+N,搜索redisautoconfiguration,
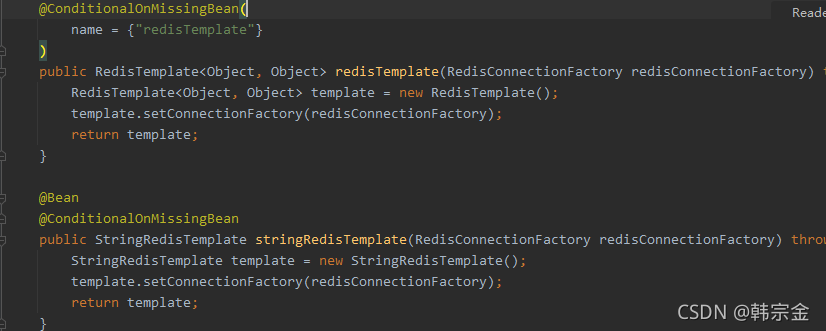
包含RedisTemplate和StringRedisTemplate,一個是任意型別的,另一個是方便操作字串的
在程式中加入快取邏輯
public Map<String, List<Catelog2Vo>> getCatelogJson2() {
//加入快取邏輯,快取中存的資料是JSON字串
//JSON跨語言,跨平臺兼容
//從快取中取出的資料要逆轉為能用的物件型別,序列化與發序列化
String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
//快取中沒有資料,查詢資料庫
Map<String, List<Catelog2Vo>> catelogJsonFromDb = getCatelogJsonFromDbWithRedisLock();
//查到的資料再放入快取,將物件轉為JSON放入快取中
String s = JSON.toJSONString(catelogJsonFromDb);
stringRedisTemplate.opsForValue().set("catalogJSON", s, 1, TimeUnit.DAYS);
return catelogJsonFromDb;
}
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
因為JSON是跨平臺的,所以redis里保存JSON字串,然后保存和取出都進行序列化和反序列化
壓力測驗發現,會產生堆外記憶體溢位(OutOfDirectMemoryError),這個是因為spring boot 2.0以后,默認使用lettuce操作Redis客戶端,它使用netty進行網路通信,lettuce的bug導致堆外記憶體溢位,解決方式有兩個,第一個是升級lettuce的客戶端,另一個是切換到jedis
切換jedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
lettuce和jedis是操作redis的底層客戶端,spring再次封裝redisTemplate,通過redisTemplate進行操作,不需要關心底層客戶端
高并發下快取會出現的問題
快取穿透

快取雪崩

快取擊穿

解決辦法:空結果快取,解決快取穿透問題,設定過期時間(加隨機值),解決快取雪崩問題,設定鎖,解決快取擊穿問題
加鎖
本地鎖(單體服務)
synchronized (this) {
String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
}
只要是同一把鎖,就能鎖住需要這個鎖的所有行程,synchronized(this):springboot所有的組件在容器中都是單例的,
本地鎖:synchronized,JUC(Lock),只能鎖住當前行程,在分布式情況下,想要鎖住所有,必須使用分布式鎖
使用本地鎖的時候,要把查詢資料庫和存放快取放在同一鎖內,如果放入快取在鎖外,高并發下,就會出現1號執行緒處理完邏輯,釋放鎖,2號執行緒獲取鎖,1號執行緒存入快取,在存快取的程序中,可能網路延遲等原因,2號執行緒讀取快取的時候,1號還沒有存入快取,查詢兩邊資料庫
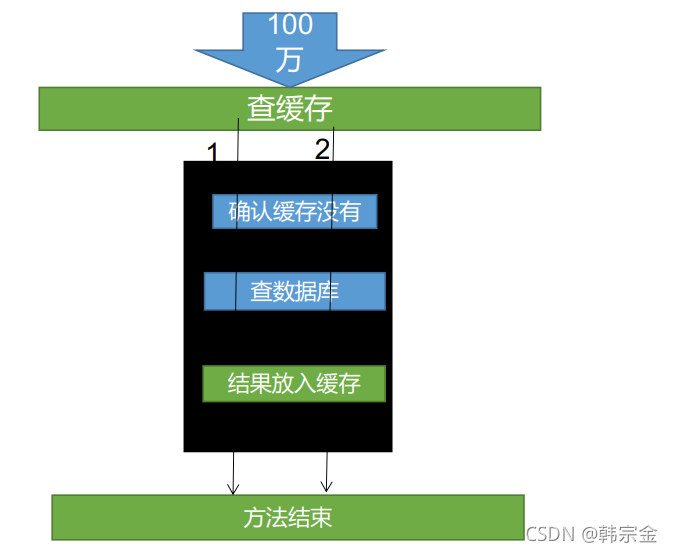
分布式鎖
分布式鎖演進原理:分布式鎖就是多個服務去占鎖,占住的執行邏輯,然后釋放鎖,在一個服務占鎖期間,其他服務只能等待,等待釋放鎖,然后再去占鎖,等待可以使用自旋方式
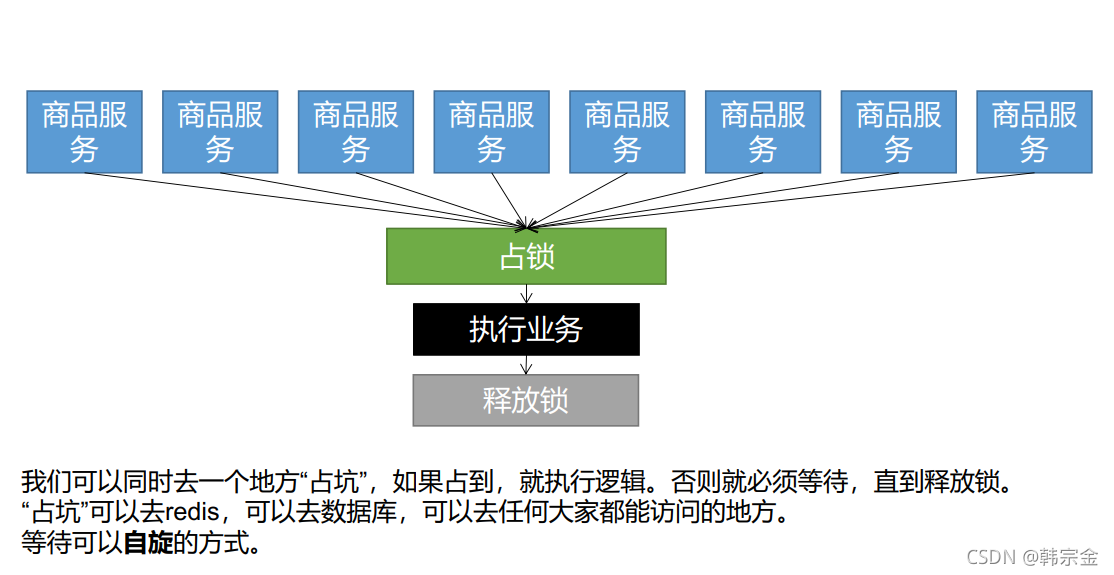
分布式程鎖Redis
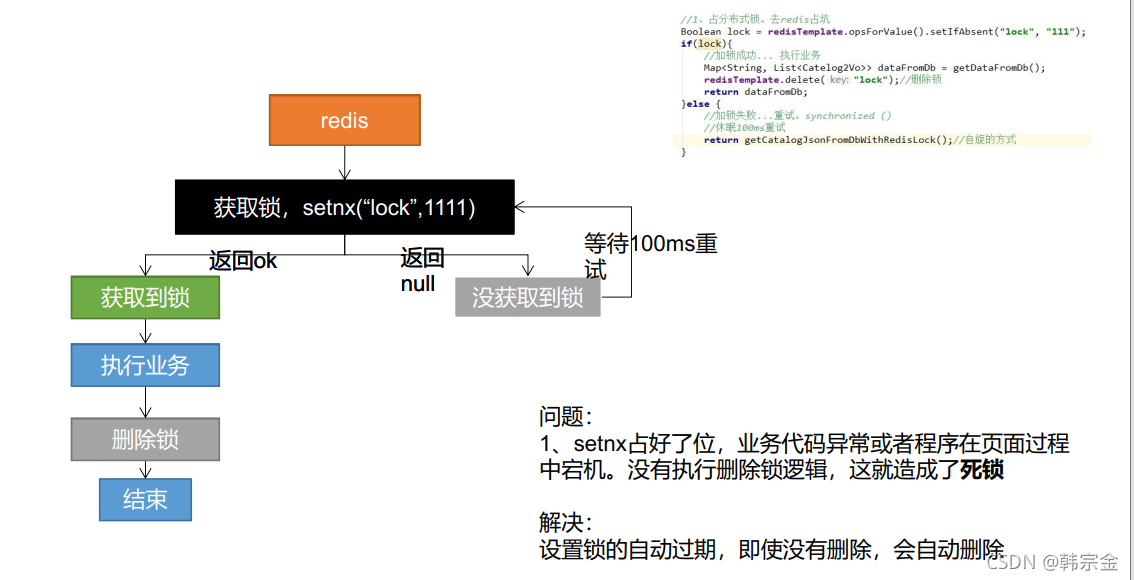
階段一:
階段二
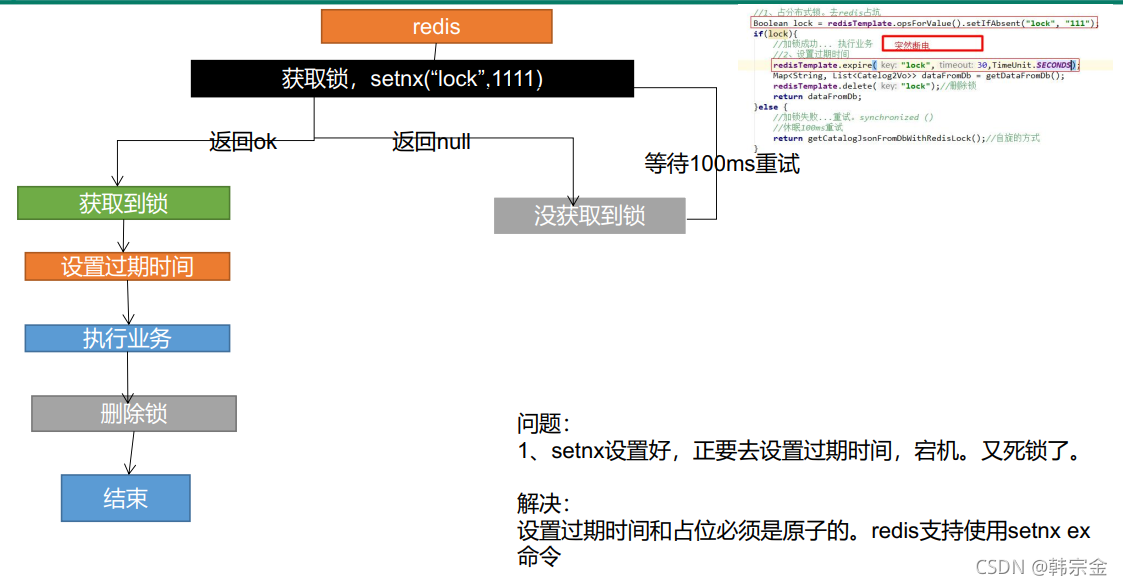
階段三
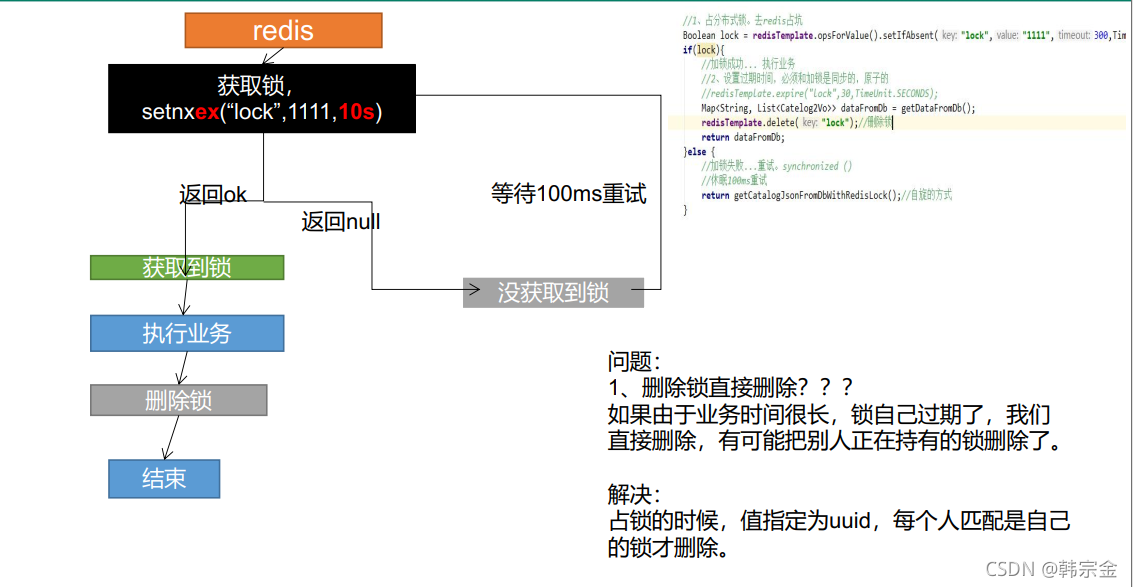
階段四
最終結果
//分布式程鎖Redis
public Map<String, List<Catelog2Vo>> getCatelogJsonFromDbWithRedisLock() {
//占分布式鎖,同時設定鎖過期時間,必須和加鎖同步原子操作
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111", 300, TimeUnit.SECONDS);
if (lock) {
//加鎖成功,執行業務
Map<String, List<Catelog2Vo>> dataFromDB;
try {
dataFromDB = getDataFromDB();
} finally {
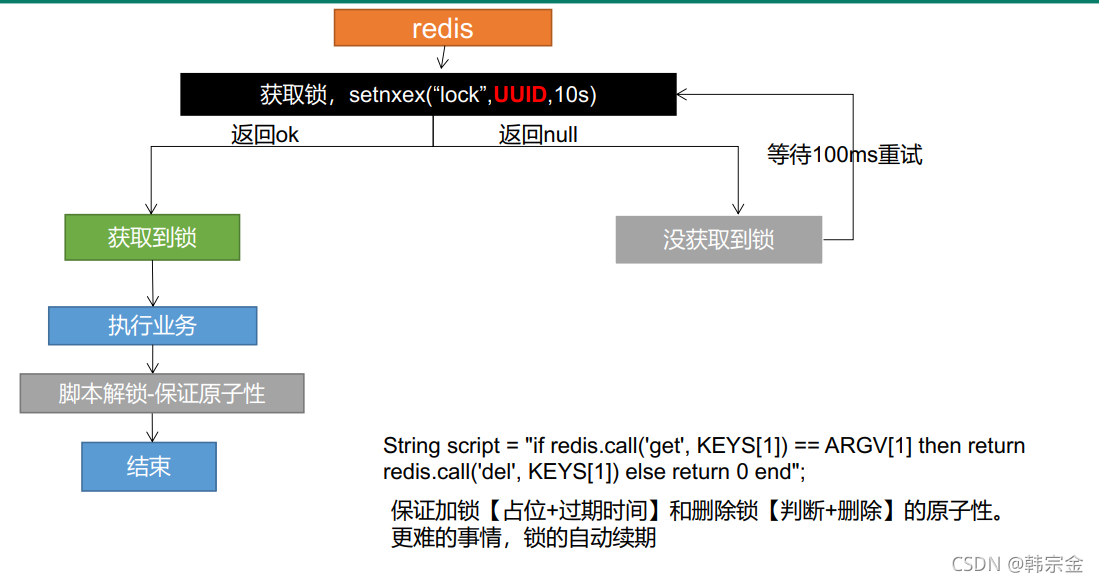
String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1])else return 0 end";
//洗掉鎖,Lua腳本
Long lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock", uuid));
}
return dataFromDB;
} else {
//加鎖失敗,休眠2秒,重試
try {
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
return getCatelogJsonFromDbWithRedisLock();//自旋
}
}
不要設定固定的字串,而是設定為隨機的大字串,可以稱為token,
通過腳本洗掉指定鎖的key,而不是DEL命令,
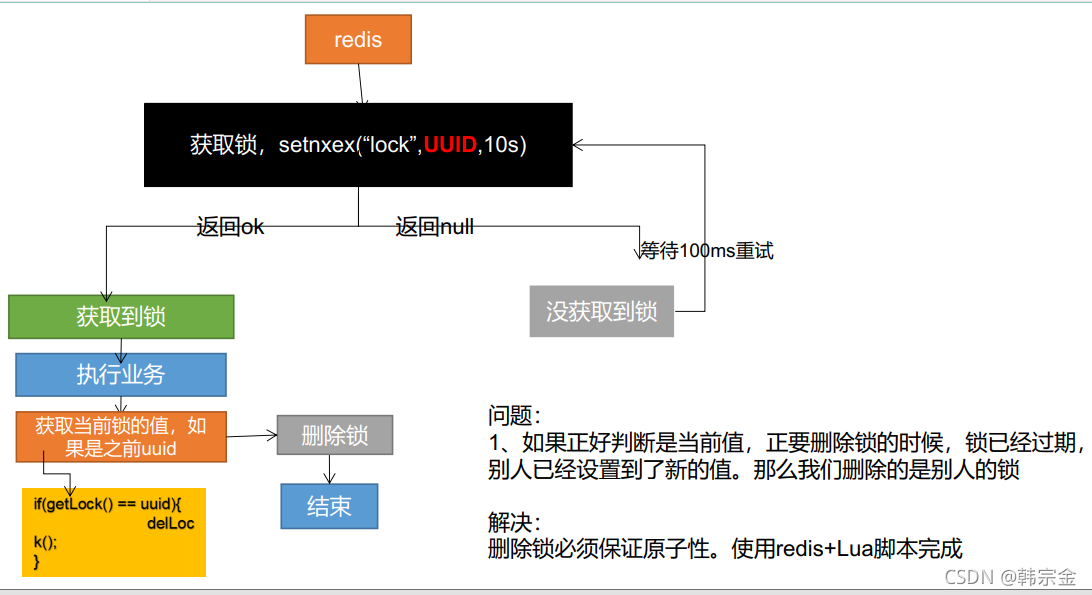
上述優化方法會避免下述場景:
a客戶端獲得的鎖(鍵key)已經由于過期時間到了被redis服務器洗掉,但是這個時候a客戶端還去執行DEL命令,而b客戶端已經在a設定的過期時間之后重新獲取了這個同樣key的鎖,那么a執行DEL就會釋放了b客戶端加好的鎖,
解鎖腳本的一個例子將類似于以下
if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end
核心就是原子加鎖,原子解鎖
Redisson
Redisson是Redis官方推薦的Java版的Redis客戶端,它提供的功能非常多,也非常強大,可以使用它來實作分布式鎖
Redisson
maven引入
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.3</version>
</dependency>
有中文檔案可以查看(Github網站經常訪問不通,,,,,)
Wiki Home
config目錄下,新建MyRedissonConfig
@Configuration
public class MyRedissonConfig {
@Bean(destroyMethod = "shutdown")
RedissonClient redisson() throws IOException{
Config config = new Config();
//集群模式
//config.useClusterServers().addNodeAddress("127.0.0.1:7004","127.0.0.1:7001");
//單節點模式
config.useSingleServer().setAddress("redis://192.168.56.10:6379");
return Redisson.create(config);
}
}
測驗redisson鎖
分布式鎖和同步器
@ResponseBody
@GetMapping("/hello")
public String hello() {
//只有鎖名字一樣,就是同一把鎖
RLock lock = redisson.getLock("my-lock");
//阻塞式等待,默認加的鎖都是30s時間,
//1)、鎖的自動續期,如果業務超長,運行期間自動給鎖續上新的30s,不用擔心業務時間長,鎖自動過期被刪掉
//2)、加鎖的業務只要運行完成,就不會給當前鎖續期,即使不手動解鎖,鎖默認在30s以后自動洗掉
lock.lock();
try {
System.out.println("加鎖測驗,執行業務..." + Thread.currentThread().getId());
Thread.sleep(10000);
} catch (Exception e) {
e.printStackTrace();
} finally {
//解鎖
System.out.println("釋放鎖" + Thread.currentThread().getId());
lock.unlock();
}
return "hello";
}
Redisson鎖的特點:有個看門狗機制,在鎖到期之前自動續期
//阻塞式等待,默認加的鎖都是30s時間,
//1)、鎖的自動續期,如果業務超長,運行期間自動給鎖續上新的30s,不用擔心業務時間長,鎖自動過期被刪掉
//2)、加鎖的業務只要運行完成,就不會給當前鎖續期,即使不手動解鎖,鎖默認在30s以后自動洗掉
如果自己指定解鎖時間,一定要大于業務時間,不會自動續期,可能在業務執行之前就已經解鎖了
// 加鎖以后10秒鐘自動解鎖
// 無需呼叫unlock方法手動解鎖
lock.lock(10, TimeUnit.SECONDS);
如果傳遞了鎖的超時時間,就發送給redis執行腳本,進行占鎖,默認時間就是我們制定的時間
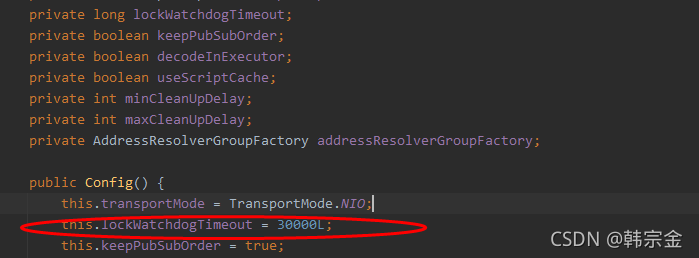
如果未指定鎖的超時時間,就是用30*1000[LockWatchdogTimeout看門狗的默認時間]
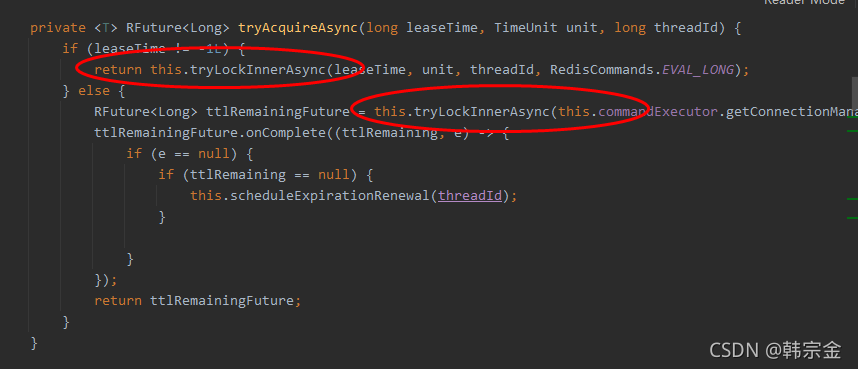
leaseTime!=-1L,說明自己指定了時間,進入

執行腳本
未指定時間,從配置拿,
this.tryLockInnerAsync(this.commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
只要占鎖成功,就會啟動一個定時任務,重新給鎖設定過期時間,新的過期時間就是看門狗的默認時間
this.internalLockLeaseTime = commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout();
...
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return this.commandExecutor.evalWriteAsync(this.getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN, "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('pexpire', KEYS[1], ARGV[1]); return 1; end; return 0;", Collections.singletonList(this.getName()), new Object[]{this.internalLockLeaseTime, this.getLockName(threadId)});
}
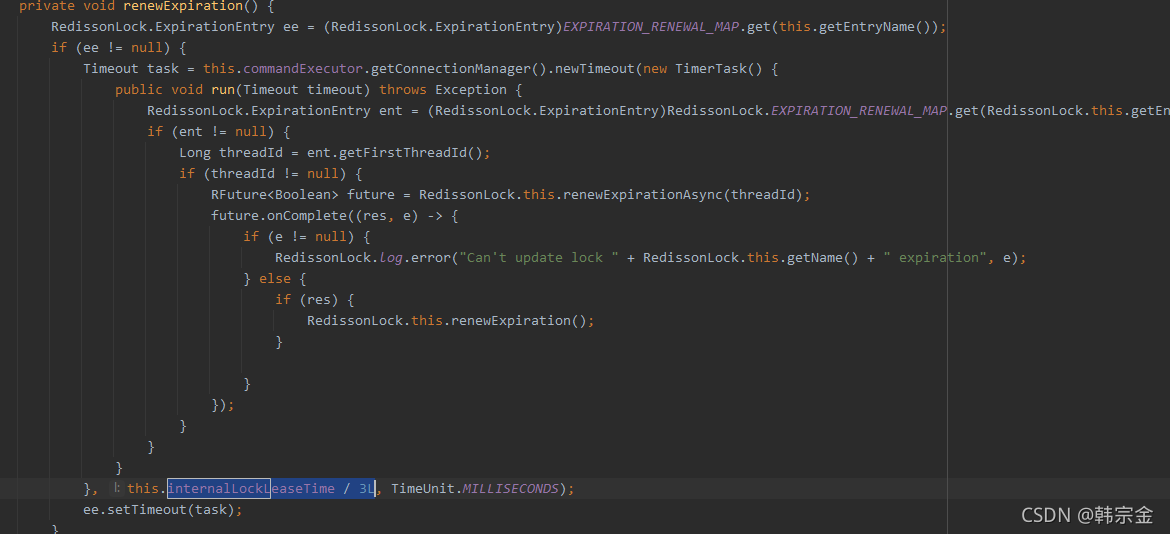
internalLockLeaseTime / 3L ,3分之一看門狗時間會自動續期,續到30s
最佳實戰:使用 lock.lock(30, TimeUnit.MINUTES);,省掉整個續期程序,手動解鎖
讀寫鎖
如果有寫操作,加寫鎖,其他讀取這個結果的都要等待,如果只是讀取,互不影響,如果都是寫,需要排隊等待
@GetMapping("/write")
@ResponseBody
public String writeValue() {
RReadWriteLock lock = redisson.getReadWriteLock("rw-lock");
String s = "";
//加寫鎖
RLock rLock = lock.writeLock();
try {
rLock.lock();
s = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue", s);
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
return s;
}
@GetMapping("/read")
@ResponseBody
public String redValue() {
RReadWriteLock lock = redisson.getReadWriteLock("rw-lock");
String s = "";
//獲取讀鎖,如果有其他的執行緒在寫操作, 則需要等到寫鎖釋放鎖以后才可進行讀的操作
RLock rLock = lock.readLock();
rLock.lock();
try {
s = redisTemplate.opsForValue().get("writeValue");
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
return s;
}
寫在操作的時候,讀等待,如果操作完成,寫釋放鎖,然后讀進行操作,獲得資料,讀寫鎖保證一定能讀到最新資料,修改期間,寫鎖是一個排他鎖(互斥鎖、獨享鎖),讀鎖是一個共享鎖,寫鎖沒釋放,讀就必須等待
讀+讀:相當于無鎖,并發讀,只會在redis中記錄好所有當前的讀鎖,同時加鎖成功
寫+讀:等待寫鎖釋放
寫+寫:阻塞方式
讀+寫:讀的時候,寫入資料,有讀鎖,寫也需要等待
只要有寫存在,都需要等待
信號量(Semaphore)
基于Redis的Redisson的分布式信號量(Semaphore)Java物件RSemaphore采用了與java.util.concurrent.Semaphore相似的介面和用法,同時還提供了異步(Async)、反射式(Reactive)和RxJava2標準的介面,
@GetMapping("/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore semaphore = redisson.getSemaphore("park");
// semaphore.acquire(); // 阻塞等待,獲取一個信號,獲取一個值,占一個車位
boolean flag = semaphore.tryAcquire();//不阻塞,獲取不到直接回傳false,可以做限流
if (flag) {
return "停車了!";
} else {
return "車庫滿了!";
}
}
@GetMapping("/go")
@ResponseBody
public String go() {
RSemaphore semaphore = redisson.getSemaphore("park");
semaphore.release();//釋放一個車位
return "車開走了!";
}
閉鎖(CountDownLatch)
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(3);//等待3個
latch.await();//等待閉鎖都完成
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();//計數減一
分布式鎖Redisson
public Map<String, List<Catelog2Vo>> getCatelogJsonFromDbWithRedissonLock() {
//鎖的名字,鎖的粒度,越細越快
RLock lock = redisson.getLock("catalogJson-lock");
lock.lock();
//加鎖成功,執行業務
Map<String, List<Catelog2Vo>> dataFromDB;
try {
dataFromDB = getDataFromDB();
} finally {
lock.unlock();
}
return dataFromDB;
}
快取資料一致性
雙寫模式
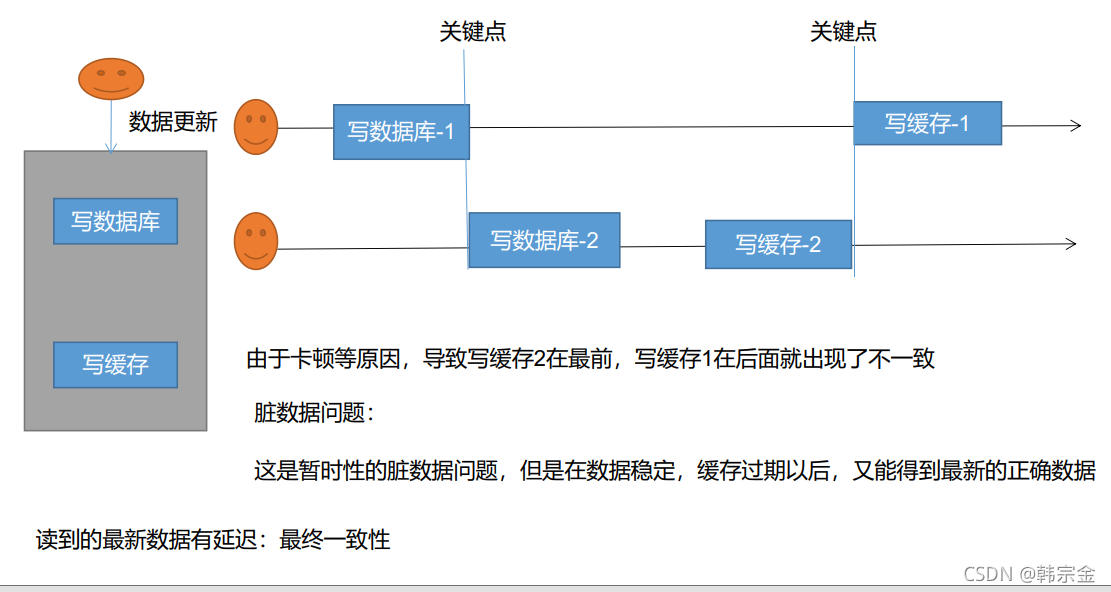
雙寫模式:寫入資料庫,同時寫入快取
失效模式
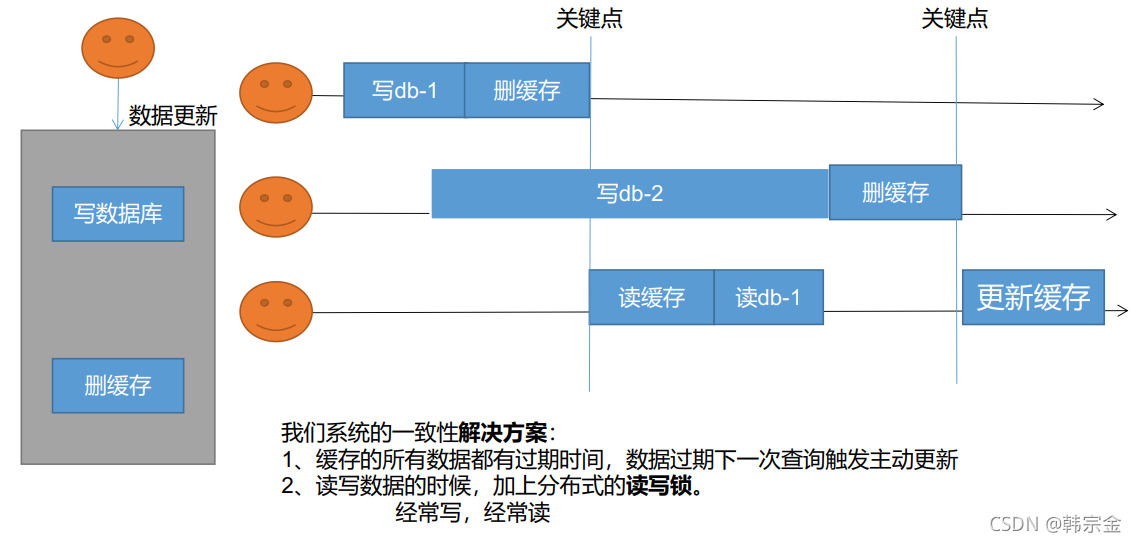
失效模式:讀取資料庫,然后洗掉快取,下一次看快取中沒有,重新從資料庫獲取,可能出現的問題:操作1寫資料庫db-1,然后刪掉快取,操作2寫入資料庫db-2,同時操作時間比較長,然后操作3讀快取,快取已經被操作1洗掉,操作3讀取db-1,然后操作2洗掉快取,操作3更新快取,結果快取中保存db-1的資料,加入讀寫鎖,如果經常寫,經常讀,會有一點影響性能,偶爾讀寫影響不大

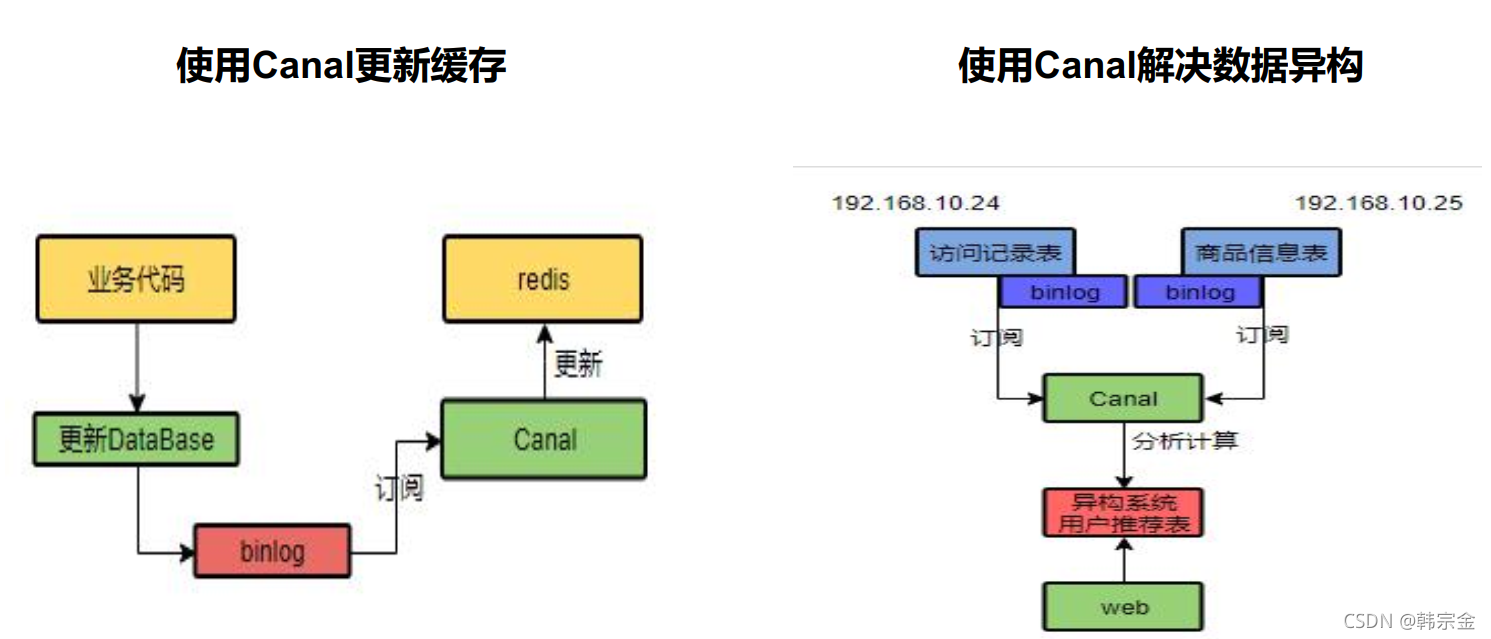
canal,譯意為水道/管道/溝渠,主要用途是基于 MySQL 資料庫增量日志決議,提供增量資料訂閱和消費,
超詳細的Canal入門,看這篇就夠了!
SpringCache快取簡化分布式快取的開發
整合springcache簡化快取開發
1) 、引入依賴
.spring-boot-starter-cache、 spring-boot-starter-data-redis2)
2)、寫配置
(i)、自動配置了哪些
CacheAuroConfiguration會匯入 RedisCacheConfiguration;
自動配好了快取管理器RedisCachcManager
( 2)、配置使用redis作為快取
spring.cache.type=redis
3)、測驗使用快取
@Cacheable: Triggers cache popuLation.:觸發將資料保存到快取的操作
@CacheEvict: Triggers cache eviction.:觸發將資料從快取洗掉的操作
@CachePut: Updates the cache without interfering with the method execution.:不影響方法執行更新快取
@Caching:Regroups multiple cache operations to be applied on a method.:組合以上多個操作
@CacheConfig: Shares some common cache-related settings at class-Level.:在類級別共享相同的快取配置
1)、開啟快取功能@EnabLeCaching
2) 、只需要使用注解就能完成快取操作
4) 、原理:
CacheAutoConfiguration -> RedisCacheConfiguration ->
自動配置了RedisCacheManager->初始化所有的快取->每個快取決定使用什么配置->如果redisCacheConfiguration有就用已有的,沒有就用默認配置
->想改快取的配置,只需要給容器中放一個RedisCacheConfiguration即可->就會應用到當前RedisCacheManager管理的所有快取磁區中
引入 pom依賴
<!-- 因為lettuce導致堆外記憶體溢位 這里暫時排除他 使用jedis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<!-- 分布式快取 需要和redis配合使用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
撰寫組態檔
# 配置使用redis作為快取
spring.cache.type=redis
# 以毫秒為單位 1小時
spring.cache.redis.time-to-live=3600000
# 配置快取名的前綴 如果沒配置則使用快取名作為前綴
# spring.cache.redis.key-prefix=CACHE_
# 配置前綴是否生效 默認為ture
#spring.cache.redis.use-key-prefix=false
# 是否快取空值 默認為true,防止快取穿透
spring.cache.redis.cache-null-values=true
#spring.cache.cache-names=
開啟快取
@EnableCaching
使用快取
1)@Cacheable: 觸發將資料寫入快取
/**
* 1、每一個需要快取的資料我們都要來指定放到哪個名字的快取;【按照業務型別來劃分取名】
*@Cacheable(value = {"category"})
* 代表當前方法的結果需要快取 如果快取中有,方法不呼叫;
* 如果快取中沒有,會呼叫該方法,最后將方法的結果放入快取
* 2、默認行為
* 1)如果快取中有,方法不呼叫
* 2)key默認自動生成,快取的名字::SimpleKey[](自動生成的key值)
* 3)快取的value值,默認使用jdk序列化機制,將序列化后的資料存到redis
* 4)默認ttl時間 -1
* 3、自定義
* 1)指定快取生成指定的key key屬性指定,接受一個spel
* 2)指定快取的過期時間 組態檔修改ttl
* 3)將快取的value保存為json格式
* 4、快取的三大問題
* 1)快取擊穿: springcache 默認是不加鎖的,需要設定sync = true
* 2)
*/
@Cacheable(value = {"category"}, key = "#root.method.name", sync = true)
public List<CategoryEntity> getLeve1Categorys() {
System.out.println("getLeve11categorys.....");
long l = System.currentTimeMillis();
List<CategoryEntity> categoryEntities = baseMapper.selectList(new Querywrapper<CategoryEntity>();
return categoryEntities;
}
@CacheEvict: 觸發將資料從快取中洗掉
/**
級聯更新所有關聯的資料
* cacheEvict:失效模式
*1、同時進行多種快取操作@caching
* 2、指定洗掉某個磁區下的所有資料ecacheEvict(valug,= "category" , alLEntries = true)*3、存盤同一型別的資料,都可以指定成同一個磁區,磁區名默認就是快取名
*@param category
*/
// @Caching(evict = {
// @CacheEvict(value = "category", key = "'getLeve1Categorys'"),
// @CacheEvict(value = "category", key = "'getCatalogJson'")
// })
// allEntries = true 洗掉category 磁區的所有快取 批量清除
// @CacheEvict(value = {"category"}, allEntries = true) //失效模式
@CachePut//雙寫模式
public void updateCascade(CategoryEntity category) {
}
@CachePut: 不影響方法執行更新快取
@Caching: 組合以上快取的操作
@Caching(evict = {
@CacheEvict(value = "category", key = "'getLeve1Categorys'"),
@CacheEvict(value = "category", key = "'getCatalogJson'")
})
@CacheConfig: 在類級別共享相同的快取配置
修改快取存盤的序列化器
@EnableConfigurationProperties(CacheProperties.class)
@EnableCaching
@Configuration
public class MyCacheConfig {
/**
組態檔中的東西沒有用上;
*
1、原來和組態檔系結的配置類是這樣子的
@ConfigurationProperties(prefix = "spring.cache")public cLass CacheProperties
*2、要讓他生效:@EnableConfigurationProperties(CacheProperties.class)
*@return
*/
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
// 修改默認的序列化器
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
Spring-Cache的不足;
1)、讀模式:
快取穿透:查詢一個null資料,解決:快取空資料; ache-null-values=true
快取擊穿:大量并發進來同時查詢一個正好過期的資料,解決,加鎖;springcache 默認是不加鎖的,需要設定sync = true
快取雪崩:大量的key同時過期,解決:加隨機時間,加上過期時間,: spring.cache.redis.time-to-live=3600000
2) 、寫模式:(快取與資料庫一致)
1)、讀寫加鎖,
2)、引入Canal,感知到MysQL的更新去更新資料庫
3)、讀多寫多,直接去資料庫查詢就行
總結:
常規資料(讀多寫少,即時性,- 致性要求不高的資料) ;完全可以使用Spring-Cache
特殊資料:特殊設計
I
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/330269.html
標籤:其他