如何衡量一個演算法的好壞呢?
一個演算法如果寫的十分的短,是不是就非常的好呢?
例如斐波那契數列:

C++:
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
#define M_SQRT5 2.2360679774997896964091736687313
#define M_1pSQRT5_2 1.6180339887498948482045868343656
long double Fibo(size_t n)
{
return round((pow(M_1pSQRT5_2,n)-pow(1-M_1pSQRT5_2,n))/M_SQRT5);
}
int main(void)
{
for (long n=1;n<=100;n++)
cout<<n<<"\t= "<<setprecision(21)<<Fibo(n)<<endl;
cout << "... ..." << endl;
for (long n=1470;n<=1480;n++)
cout<<n<<"\t= "<<setprecision(21)<<Fibo(n)<<endl;
return 0;
}python:
def Fib(n:int)->int:
return 1 if n<3 else Fib(n-1)+Fib(n-2)以上代碼,c++和python的主體函式都只有一行return陳述句,一個是使用數列通項公式(又稱比內公式),一個使用遞回法;前者局限于long double的精度,后者局限于遞回層數的限制,
通常情況下,計算斐波那契數列多數會使用數列定義的遞推公式來遞回,但當n大于30時計算就非常吃力了;想要計算第100萬項的值基本上是不可能的了,
>>> from time import time
>>> for i in range(30,40):
t=time();n=Fib(i);print(i,time()-t)
30 0.42186927795410156
31 0.6874938011169434
32 1.1093668937683105
33 1.7812433242797852
34 2.8906190395355225
35 4.640621185302734
36 7.48436975479126
37 12.109369277954102
38 19.6406192779541
39 31.74999499320984用Fib(n-1)+Fib(n-2)遞回只能一項項往前推,太慢了;我樣可以這樣改進,用斐波數列的性質(如下所示)來遞回,效率明顯提升:計算第10萬項秒殺,第100萬項20秒以內,
由 F(1)=F(2)=1; F(n)=F(n-1)+F(n-2) 推匯出:
F(2n)=F(n+1)*F(n)+F(n)*F(n-1) ; F(2n+1)=F2(n+1)+F2(n)
>>> def Fib(n:int)->int:
if n<3: return 1
if n%2: return Fib(n//2)**2+Fib(n//2+1)**2
return Fib(n//2)*(Fib(n//2+1)+Fib(n//2-1))
>>> from time import time
>>> t=time();n=Fib(100);print(time()-t)
0.0
>>> t=time();n=Fib(1000);print(time()-t)
0.015600204467773438
>>> t=time();n=Fib(10000);print(time()-t)
0.062400102615356445
>>> t=time();n=Fib(100000);print(time()-t)
0.9536018371582031
>>> t=time();n=Fib(1000000);print(time()-t)
18.566032886505127此函式已知項只有F(1)、F(2)兩項,若增加已知項的項數也能提升一點效率,計算第100萬項的值只要3秒不到:
>>> def Fib(n:int)->int:
if n<11: return [0,1,1,2,3,5,8,13,21,34,55][n]
t=n//2
if n%2: return Fib(t)**2+Fib(t+1)**2
return Fib(t)*(Fib(t+1)+Fib(t-1))
>>> from time import time
>>> t=time();n=Fib(1000);print(time()-t)
0.0
>>> t=time();n=Fib(10000);print(time()-t)
0.017600059509277344
>>> t=time();n=Fib(100000);print(time()-t)
0.22040081024169922
>>> t=time();n=Fib(1000000);print(time()-t)
2.76320481300354
>>> 那么我們要用什么方式去衡量一個演算法的好壞,所以我們引進了時間復雜度和空間復雜度, 時間復雜度主要衡量一個演算法的運行快慢,而空間復雜度主要衡量一個演算法運行所占用空間,
時間復雜度
時間復雜度的概念
衡量一個演算法的運行時間快慢也就是時間復雜度,那么計量的單位是什么?如果用我們常用的時間單位例如:秒、毫秒,這就存在一個問題,不同機器由于配置不同時間會不相同,而且要想知道時間就必須上機跑代碼很麻煩,所以我們把演算法花費的時間與其中陳述句執行次數成正比,演算法中的基本操作執行個數,為演算法的時間復雜度,
>>> def fun(n:int)->None:
count = 0;
for i in range(n):
for j in range(n):
count += 1
for i in range(n*2):
count += 1
m = 10
while m:
count += 1
m -= 1
print(count)
>>> fun(10)
130
>>> fun(100)
10210
>>> 由這個函式中的全域變數count,我們很容易知道執行了F(N)=N^2+2*N+10
其實我們在計算精確的執行次數,而只需要大概執行次數,這里我們使用大O的漸進表示法,
大O的漸進表示法
大O符號(Big O notation):用于描述函式漸進行為的數學符號,常見復雜度如下:
| 復雜度 | 標記符號 | 描述 |
| 常量(Constant) | O(1) | 操作的數量為常數與輸入的資料的規模無關, |
| 對數(Logarithmic) | O(log2 n) | 操作的數量與資料的規模 n 的比例是 log2 (n), |
| 線性(Linear) | O(n) | 操作的數量與資料的規模 n 成正比, |
| 平方(Quadratic) | O(n2) | 操作的數量與資料的規模 n 的比例為二次方, |
| 立方(Cubic) | O(n3) | 操作的數量與資料的規模 n 的比例為三次方, |
| 指數(Exponential) | O(2n) O(n!) | 指數級的操作,快速的增長, |
大O復雜度運算元曲線:
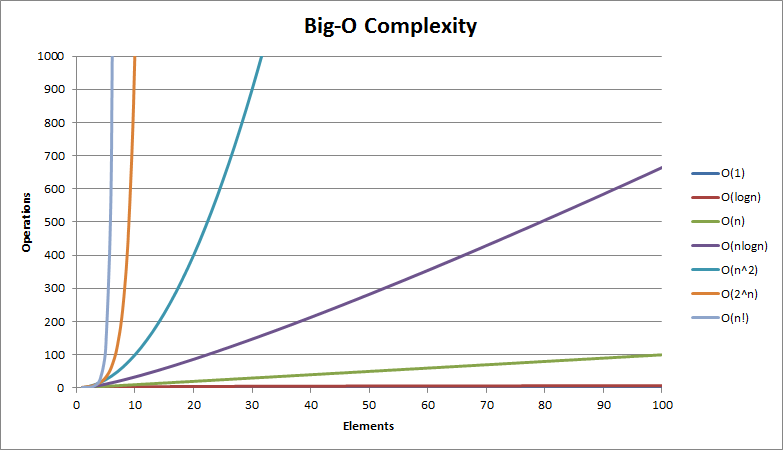
常見的時間復雜度舉例
例一:常量級
C++:
#include<iostream>
using namespace std;
int func(int n){
int i = 0;
for(int j=0;j<1000;i++,j++);
return i;
}
int main(void){
cout << func(100) << endl;
cout << func(1000) << endl;
return 0;
}python:
>>> def fun(n:int)->int:
i = 0
for j in range(1000):
i += 1
return i
>>> fun(100)
1000
>>> fun(1000)
1000時間復雜度為O(1000)但是如果為常數的話,時間復雜度可以直接寫為O(1)
例二:階乘之和 1!+2!+3!+...+n!
C++:
#include<iostream>
using namespace std;
long long func(int n){
long long sum = 1;
for(int i=n;i>1;i--){
sum *= i;
sum += 1;
}
return sum;
}
int main(void){
cout << func(10) << endl;
cout << func(20) << endl;
return 0;
}python:
def factSum(n):
Sum = 1
for i in range(n,1,-1):
Sum *= i
Sum += 1
return Sum
def factSum2(n):
Sum = 0
from math import factorial as fact
for i in range(1,n+1):
Sum+=fact(i)
return Sum時間復雜度為O(N)
例三:冒泡排序
C++:
#include<iostream>
#include<cmath>
using namespace std;
int main(void) {
double a[100];
int N;
int i = 0, j = 0;
cin >> N;
for (i = 0; i<N; i++)
cin >> a[i];
for (i = 0; i<N - 1; i++) {
for (j = 0; j<N - 1 - i; j++)
{
if (a[j]>a[j + 1]) {
int tmp;
tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
for (i = 0; i<N; i++){
cout << a[i] << " ";
}
cout << endl;
return 0;
}python:
>>> def Bubble(a:list)->None:
for i in range(len(a)-1):
for j in range(len(a)-1-i):
if a[j]<a[j+1]:
a[j],a[j+1]=a[j+1],a[j]
>>> b = [*range(1,6)]
>>> Bubble(b)
>>> b
[5, 4, 3, 2, 1]
>>> 由這個程式我們可以知道F(N)=N-1+N-2+.....+1=(N^2-N)/2
例四:二分查找
C++:
template<class T>
int Binary_Search(T *x, int N, T keyword)
{
int low = 0, high = N-1,mid;
while(low <= high)
{
mid = (low + high)/2;
if(x[mid] == keyword)
return mid;
if(x[mid] < keyword)
low = mid + 1;
else
high = mid -1;
}
return -1;
}
int Binary_Search2(int *a, int low, int high, int key)
{
if(low > hign)
return -1;
int mid = (low + high) / 2;
if(a[mid] == key)
return mid;
if(a[mid] > key)
return Binary_Search2(a, low, mid-1, key);
else
return Binary_Search2(a, mid+1, high, key);
}
python:
def binSearch(a:list,x:int):
left,right = 0,len(a)
while left<=right:
mid = (left+right)//2
if x>a[mid]:
left = mid+1
elif x<a[mid]:
right = mid-1
elif x==a[mid]:
return mid
return -1這個演算法對于每次查找,找不到就會將范圍縮小二倍,時間復雜度也就是O(log2 N)
例五:遞回階乘
C++:
#include<iostream>
using namespace std;
long long func(int n){
long long sum = 1;
for(int i=n;i>0;i--)
sum *= i;
return sum;
}
int main(void){
cout << func(10) << endl;
cout << func(20) << endl;
return 0;
}python:
>>> def F(n:int)->int:
if n: return F(n-1)*n
return 1
>>> F(0)
1
>>> F(1)
1
>>> F(2)
2
>>> F(3)
6
>>> F(4)
24
>>> F(5)
120
>>> 這個也非常簡單return的 值為F(N-1)*F(N-2)........F(0)一共是N+1個,所以中間的代碼也就執行了N+1次,所以時間復雜度是O(N)
例六:斐波那契數列
C++:
#include<iostream>
using namespace std;
long long func(int n){
if (n<3) return 1;
return func(n-1)+func(n-2);
}
int main(void){
cout << func(10) << endl;
cout << func(20) << endl;
return 0;
}python:
def F(n:int)->int:
if n<3: return 1
return F(n-1)+F(n-2)這個函式的時間復雜度很多文章都說它是指數級O(2?)的,但我還是用python全域變數法來測驗:
>>> def F1(n):
global count
count += 1
if n<3: return 1
return F1(n-1)+F1(n-2)
>>> count=0; F1(20),count
(6765, 13529)
>>> count=0; F1(25),count
(75025, 150049)
>>> count=0; F1(30),count
(832040, 1664079)
>>> 6765*2,75025*2,832040*2
(13530, 150050, 1664080)
>>> 6765*2-1,75025*2-1,832040*2-1
(13529, 150049, 1664079)
>>> 看全域變數n終值的測驗結果,可知: F(n)的運算次數 = 2*F(n) - 1,其中F(n)的通項公式(也就是比內公式)為:
再來使用cProfile庫函式Profile()來驗證一下:
>>> from cProfile import Profile
>>> def F(n:int)->int:
if n<3: return 1
return F(n-1)+F(n-2)
>>> cp = Profile()
>>> cp.enable(); n = F(30); cp.disable()
>>> cp.print_stats()
1664081 function calls (3 primitive calls) in 0.708 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1664079/1 0.708 0.000 0.708 0.708 <pyshell#7>:1(F)
1 0.000 0.000 0.000 0.000 rpc.py:614(displayhook)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
>>> 2*F(30)-1
1664079
>>> 2**30
1073741824
>>> 30**3
27000
>>> 結果cp.print_stats()輸出的function calls的值正好也等于2*F(30)-1,所以我認為這個函式的時間復雜度應在立方級O(n3)和指數級O(2?)之間,比O(n3)大好幾十倍但要比O(2?)小兩到三個數量級,實際上應該是這樣一個“數量級”:
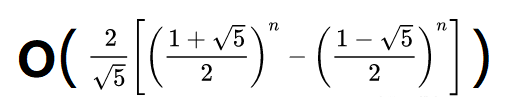
空間復雜度
空間復雜度也是一個數學運算式,是對一個演算法在運行程序中臨時占用儲存空間大小的度量,
空間復雜度不是程式占用了多少bytes空間,因為這個也沒太大意義,所以空間復雜度算的是變數的個數,也用O()來表示,
注意:函式運行所需要的堆疊空間在編譯的時候就已經確認好了,因此空間復雜度主要通過函式在運行時顯示申請的空間來確定,
例一:冒泡排序
源代碼略(參見上一節內容空間復雜度,以下同)實際上這里開辟的空間只有i,j 所以空間復雜度為O(1),
例二:階乘函式
答案是O(N)
這里如果對函式堆疊幀不是很了解的話,這個原理也就不會知道,函式堆疊幀可以簡單的理解為:函式每被呼叫一次,都會在堆疊區上開辟一塊空間,所以F(N)會呼叫F(N-1),F(N-1)會呼叫F(N-2)…同時會呼叫N個F,每個F都會開辟一塊空間,所以空間復雜度為:O(N),
示例三:斐波那契數列
通過上面的實體我們就可以知道斐波那契數列實際上開辟了N個Fib函式空間,只是這些函式空間會被重復利用,總共被運行2^n-1次,所以空間復雜度為:O(N),
(本篇完)
學習交流 Python 的群二維碼:
http://qr01.cn/FHYKEa

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/330886.html
標籤:其他
下一篇:perl的帶符號的日期時間減法