我正在嘗試從下載的 html 中獲取特定的表(通過 id)并決議它我嘗試了幾種方法,我的最后一個代碼是
var url = @"C:\Users\name\Plocha\web.html";
var doc = new HtmlDocument();
doc.Load(url);
string data = "";
int i = 2;
foreach (HtmlNode table in doc.DocumentNode.SelectNodes("//table"))
{
Console.WriteLine($"Found: {table.Id}");
if (table.Id == "formTbl")
{
foreach (HtmlNode row in table.SelectNodes("//tr"))
{
foreach (HtmlNode cell in row.SelectNodes("td"))
{
if (i == 1)
{
data = $"Column:{cell.InnerText}";
i = 2;
}
else if (i == 2)
{
data = $"Row: {cell.InnerText}";
Console.WriteLine(data);
data = "";
i = 1;
}
}
}
}
else
{
Console.WriteLine("Not what we want");
}
}
問題是它會列印網頁中的所有表格,即使我已指定僅在 id = formTbl 時才繼續。
資料在表上的外觀(沒有列名,只有兩行,第一行是列名,第二行是值)
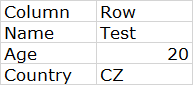
uj5u.com熱心網友回復:
SelectNodes()進行XPath查詢。這里有一些有用的例子。與您的案例相關的一個特定內容是://book- 選擇所有書籍元素,無論它們在檔案中的任何位置。
這意味著,與其使用"//tr"(搜索整個檔案),不如尋找"tr"是否要尊重范圍。
您甚至可以使用 xpath使用單個查詢進行id搜索和選擇<tr>下面的內容:
foreach (var row in doc.DocumentNode.SelectNodes("//table[@id='formTbl']/tr"))
{
// ...do <tr> stuff
foreach (var cell in row.SelectNodes("td"))
{
// ... do <td> stuff
}
}
uj5u.com熱心網友回復:
foreach (var table in doc.DocumentNode.SelectNodes("//table[@id='formTbl']"))
{
foreach (var row in table.SelectNodes("tbody/tr"))
{
Console.WriteLine(row.Id);
foreach (var cell in row.SelectNodes("td"))
{
Console.WriteLine(cell.InnerText);
}
}
}
問題是我沒有使用 tbody/tr
感謝@NPras
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/332891.html
標籤:C# html 数据库 html-agility-pack
上一篇:如何自動從多個表中選擇一列