目錄
前言
一、梯度下降的思想與批梯度下降法
1.隨機梯度下降法
2.標準梯度下降法
3.批梯度下降法
二、經典的五類優化器
1.SGD
2.SGDM(SGD with momentum)
3.Adagrad
4.RMSProp
5.Adam
三、前沿方法
1.AMSGrad
2.AdaBound
3.SWAT
4.Cyclical LR/SGDR/One-cycle LR
5.RAdam
6.Lookahead
7.SGDWM/AdamW
8.一些幫助優化的方法
四、總結
前言
本文介紹了經典和前沿的深度學習中的優化器(優化演算法),文章整體思路、圖片、公式均源自李宏毅2020機器學習深度學習(完整版)國語_嗶哩嗶哩_bilibili,Optimization部分在網課中是由課程助教講解的選學課程,難度較大(我在第一次學習的時候甚至連Adam演算法都沒有理解,就匆匆跳過了課程),之所以整理出該文章,一方面用于以后自己經常回顧,一方面希望可以幫助向曾經的我一樣被直接勸退的朋友們,視頻中Adagrad、RMSProp等演算法等講解得過快,我在文中寫入了自己對不同演算法的理解、思考以及直觀上的分析,如果能恰好幫助你理解,并與網課視頻相互補充,那我將十分榮幸,
本文分為三個部分,第一個部分介紹梯度下降的思想及實際訓練模型常用的批梯度下降法,第二部分介紹了五種經典的演算法,第三部分介紹了一些前沿演算法,在第二三部分的介紹中,每種演算法在介紹時以演算法的優勢、步驟和直觀理解為主,不討論其理論性質的證明,
無論是DNN還是CNN,都追求模型預測值和真實值間的差異最小化,通常構造損失函式來度量這種差異(如回歸問題中的平方損失,分類問題中的交叉熵損失),損失函式是模型引數的函式,因此,我們一定會面臨一個最小化問題,目標函式是損失函式,決策變數是模型引數,于是,我們需要優化演算法來求解這個最小化問題,梯度下降法或者說它的思想貫穿著深度學習優化演算法的始終,
一、梯度下降的思想與批梯度下降法
梯度下降是經典的優化演算法,它的思想是:引數在更新時始終朝著目標函式(最小化問題)下降最快的方向移動,而這個方向就是梯度(梯度是上升最快的方向)的反方向,用公式可以表達為
是損失函式
對第
時刻的引數
的梯度,
學習率是一個超引數,需要人為設定,通常設為0.001、0.01等,
演算法的流程非常簡單:初始化引數向量,然后根據該公式不斷更新梯度,使得損失函式收斂到較低水平時停止,
基于梯度下降優化演算法的思想,通常有三種不同的模式來訓練模型,分別是:隨機梯度下降,標準梯度下降法,和批梯度下降法:
1.隨機梯度下降法
每次只使用一個訓練集樣本來更新引數,該方法的不足是引數更新不夠穩定,收斂速度較慢,這是因為一個樣本很難代表整體,每次更新只是減小了該樣本的損失函式值,卻可能造成在其他樣本上損失函式值的增大,
2.標準梯度下降法
每次利用全部訓練集樣本來更新引數,該方法雖然直觀上解決了上述問題,但通常深度學習問題的資料量龐大,一次性將全部資料丟計算機進行訓練幾乎是不可能的,其次,由于包括了所有樣本,不同樣本對引數更新的影響可能會相互抵消,使得引數每輪更新值都很小,
3.批梯度下降法
批梯度下降法是對上述兩種方法的集中,明顯規避了兩種方法的缺點,成為現在幾乎一定會使用的方法,該方法就是將資料集分成幾個批(batch),每個batch的資料量根據實際資料量的大小由自己定義,每次丟進一個batch進入模型進行訓練,
二、經典的五類優化器
1.SGD
見一,1,(雖然演算法名叫隨機梯度下降,但實際上,仍然采用的是mini-batch gradient descent,批梯度下降法,無論采用什么優化器,都需要用用mini-batch的方式訓練,)
2.SGDM(SGD with momentum)
隨機梯度下降法雖然有效,但容易陷入區域最小值點,甚至在駐點附近以及梯度值非常小的點附近時引數更新極為緩慢,為了改進這個缺點,引入物理中動量的概念,引數更新量,是當前梯度的方向
,和上一次引數更新方向
的線性組合,演算法如下:
①初始化引數;
②計算當前梯度:;
③更新引數移動量:
④更新引數:
⑤,回傳步驟②,直到達到某終止條件,
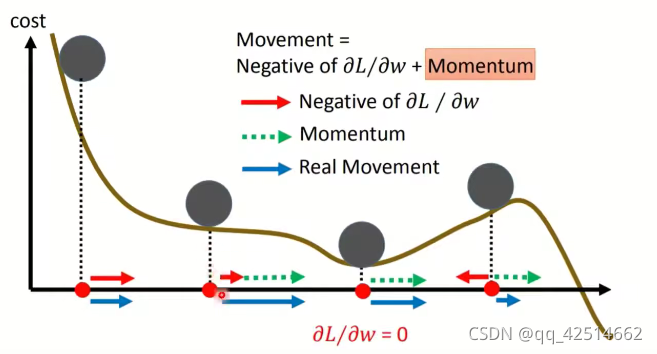
下圖是引數是以一維的情況下,動量法的直觀示意,可以看到在區域最小值點時,雖然真實的梯度為0,但由于慣性(上一時刻的動量方向)存在,引數仍然會朝著原有方向更新,也就有了沖出區域最小值的可能,
3.Adagrad
Adagrad演算法的公式更新如下:
①初始化引數;
②計算當前梯度:;更新引數:
③,回傳步驟②,直到達到某終止條件,
觀察步驟二引數更新公式中的式子
可以發現,除了第一次更新時的更新量為,其余時刻的更新量都小于
,是一個介于0到
之間的數,如果新的梯度很大,則更新量大(接近
),否則更新量小(接近0),
直觀上來講,更新量是新的梯度的平方占累積梯度平方和的比例開根號乘以,它的意義在于使得不同引數的更新處于同一維度之下,從下圖可以體現出來,
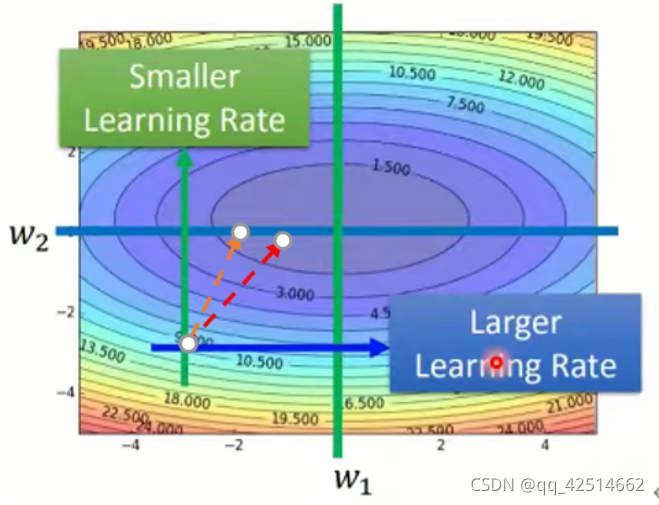
可以看出,在給定的引數點上,在方向上的導數大于
方向的導數,如果采用傳統的SGD方法,引數更新的方向將是橙色線的方向,而如果是采用Adagrad演算法,由于
方向上的累積導數和也很大,這使得兩個引數方向對最終的更新方向的貢獻幾乎相等,此時更新的方向大概是紅色線的方向,這是更符合我們直觀想法的,
4.RMSProp
Adagrad演算法和RMSProp演算法都稱為自適應演算法,自適應演算法的意思就是,學習率隨著更新次數而改變,Adagrad演算法雖然在上述簡單的例子中有直觀解釋,但實際的損失函式通常很復雜,且發現當t很大時,Adagrad下引數將幾乎不再更新,可以假設,對任意t,相同,此時引數的更新量將以
階減小,為了改變這一劣勢,提出RMSProp演算法,RMSProp演算法如下:
①初始化引數;
②計算:
;
③更新引數:
④,回傳步驟②,直到達到某終止條件,
將步驟二中的展開得到:
可以看到,與Adagrad相比,分母中過去的梯度值平方的權重已經由等權(權重均為1),變為指數加權,此時參,引數更新量的上界為,隨著更新次數的增加,對于相同的
,RMSProp演算法的引數更新量
大于Adagrad演算法,解決了過快收斂的問題,
5.Adam
Adam演算法是RMSProp演算法與SGDM演算法的結合,其既是有著自適應學習率,又能引入了動量機制在一定程度上減小引數陷入區域最有點的可能性,其是應用最為廣泛的深度學習優化器之一,演算法步驟如下:
①初始化引數:
②計算梯度:
③更新:
④更新:
⑤更新引數
其中,
,回傳步驟二,直到滿足某終止條件,
步驟④中的是
的估計量,其修正了偏差,以得到更好的理論性質;
是為了防止前幾次計算梯度為0時,引數更新量的分母為0,通常設定:
.
三、前沿方法
一些前沿方法相繼被提出,大部分是以上經典演算法的改進、組合等,
1.AMSGrad
演算法步驟上,在ADAM演算法基礎上進行了改進:
①初始化引數:
②計算梯度:
③更新:
④更新:
⑤更新引數
其中,
.
該演算法的改進點在于,可以看出AMSGrad法的
隨著t的增加一直在遞增,而Adam法中的
是有可能減小的,若
,則引數更新量約等于ADAM演算法;若
,則引數更新量小于ADAM演算法,
到后期,梯度值較小時,將保持不變,
是常數,此時更新量的大小只取決于
的大小,
2.AdaBound
方法提出者在測驗Adam演算法時發現在更新引數時,更新量要么很大要么很小,因此提出了一個Bound的方法,控制每次的更新量不超過某個范圍,
關鍵步驟為:
3.SWAT
一些研究發現,通常SGDM演算法收斂速度較慢但穩定,ADAM演算法收斂速度快但較不穩定,同時SGDM演算法的收斂結果要好于ADAM,也就是SGDM演算法雖然收斂得慢,但能夠得到更低得損失函式值,
因此,想到可以結合二者得優點,訓練時,先用ADAM演算法使得損失函式快速下降,再使用SGDM法尋找更低的損失函式,這就是SWAT法,但該方法并沒有給出一種通用的準則來決定:①何時切換兩種方法②切換到SGDM時,學習率如何設定,因此,該方法更多是一種思路,對于不同問題需要不斷嘗試,且嘗試成本較大,
4.Cyclical LR/SGDR/One-cycle LR
這一類方法的思想是,SGDM之所以更新引數速度較慢,是因為學習率恒定,因此嘗試在SGDM方法上加上一個人為的動態的學習率,典型的三種方法是Cyclical LR、SGDR和One-cycle LR,它們的學習率隨著迭代次數的變化的形狀依次見以下三幅圖,
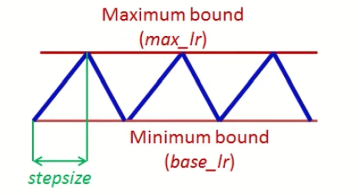
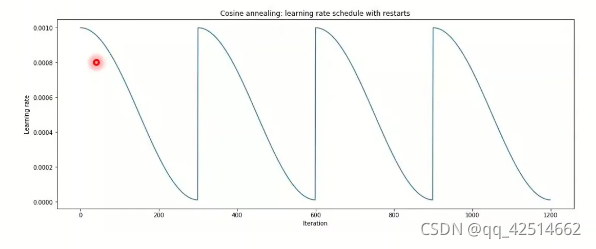
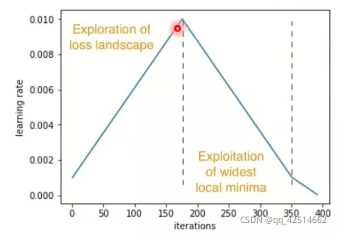
前兩種方法的學習率變化具有周期性,而最后一種不具有周期性,因此稱為One-cycle,
5.RAdam
有研究發現Adam演算法在前幾代,所有引數的梯度值的方差較大,而在中后期梯度值的分布逐漸趨于穩定,為了防止梯度值比較散亂時,引數在錯誤的方向上更新量過大,采用一種熱身(warm-up)的方法,在更新初期采用小的學習率,在后期采用大的學習率(One-cycle LR方法學習率影像中前期線性增長的部分就可以看作是一種warm-up),
RAdam方法的warm-up通過來控制,
逐漸從0增加到1,
的公式和影像分別為:
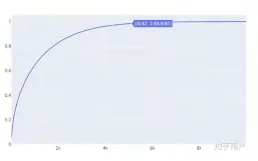
引數更新的公式為:
- 當
時,
- 當
時,
因為只有當時,
才存在,因此當
,
不存在時,先采用SGDM法更新引數,
對比一下RADAM和SWAT方法:
- 提出動機:RADAM的提出動機是,ADAM更新引數初期,
估計不準,導致
估計不準,因此采用warm-up的方法,用
乘原本的更新量,
- 具體做法:RADAM是先用SGDM(因為前期
- 切換點:RADAM演算法中,當
6.Lookahead
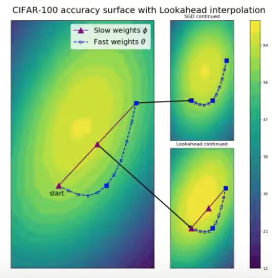
Lookahead方法是一種優化策略,可以與以上提出的任何一種優化方法相結合,該策略的思想是:向前走k步,向后退一步(k step forward,1step back),
正如同下面第一張圖的公式,首先,在外層回圈中設定快引數和慢引數
的初始值相同,然后利用某種優化演算法比如SGD演算法更新快引數k步(對應下面圖二中藍色虛線從左下到右上的路徑),接著更新慢引數,取慢引數為慢引數起始點和快引數終止點連線的中間某一點(對應下面圖二從左下到右上的紅色直線上的紅色三角),

下圖是訓練后期測驗集準確率隨訓練代數更新的變化,縱軸是測驗集準確率,橫軸是訓練代數,可以看到每個周期前k步,測驗集準確率將快速下降(在資料量較少的情況下,如果一直訓練,會過擬合的現象,到訓練后期時,雖然訓練集準確率可能不降低,但測驗集準確率會下降,如圖中每條藍線所示),而第k+1步由于回退,測驗集準確率保持在較高水平,
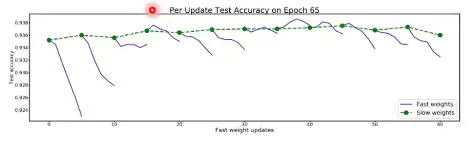
因此,我認為這個方法能很大程度延緩過擬合的到來,在與過擬合的“抗爭"與“拉扯”中,試圖找到更好的引數值,
7.SGDWM/AdamW
通常為了防止過擬合,我們會在原來的損失函式的基礎上加上二范數正則項
:
此時,引數在處的梯度由
變為
,
因此,在基于梯度下降法更新引數時,自然要利用新的梯度進行更新,但對于SGDM法和Adam法來說,和
的更新是否需要使用新的梯度呢?如果按照公式來講,理論上就應該是使用新的梯度,但2017年,有學者表明,在SGDM演算法更新
,以及Adam演算法更新
和
的程序中使用原梯度
(即不加正則項的梯度)效果會更好,
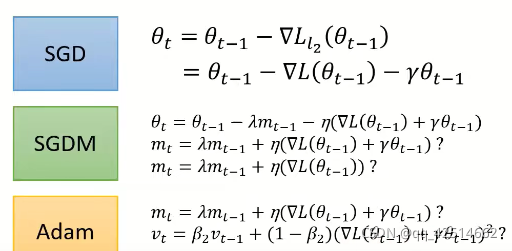
于是便有了SGDWM和AdamW演算法,如下圖所示:
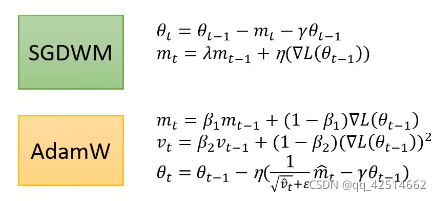
8.一些幫助優化的方法
- Shuffling:做mini-batch時每次打亂資料順序,保證batch樣本的隨機性,從而保證梯度更新的隨機性,
- Dropout:DNN中,使得一部分神經元隨機失活,
- Gradient noise:給梯度增加獨立的隨機正太噪聲,噪聲方差隨時間t的增加而減小,
- Warm-up:學習率逐漸增加,
- Curriculum learning:先用干凈資料訓練模型,再用復雜資料(有噪聲資料)訓練模型,
- Fine-tuning:好好調參...
- Normalization:批歸一化等,
四、總結
以上方法總結為下圖(NAG方法數學推導實在過于復雜,沒有進行介紹):
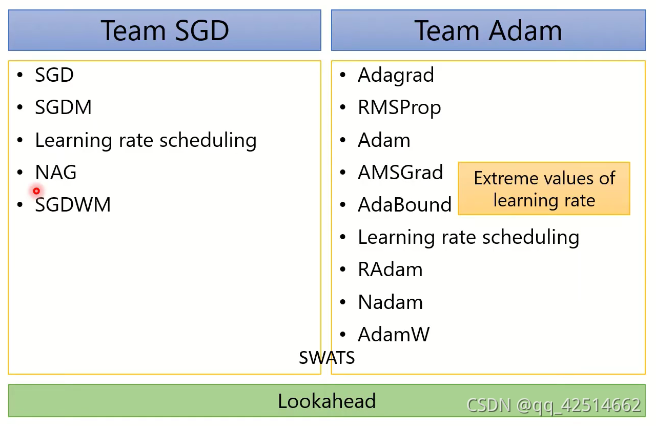
應用最為廣泛的兩種方法SGDM和Adam的不同應用領域:

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/333398.html
標籤:其他
上一篇:細!小白函式遞回大總結!碼住!