我有一個 Pandas 資料框,可以說兩列,例如:
value boolean
0 1 0
1 5 1
2 0 0
3 3 0
4 9 1
5 12 0
6 4 0
7 7 1
8 8 1
9 2 0
10 17 0
11 15 1
12 6 0
現在我想添加具有以下條件的第三列 (new_boolean):我指定一個句點,對于此示例,句點 = 4。現在我查看所有布林值 == 1 的行。對于最大值,new_boolean 將為 1在最后一期行中。
例如,我的第 2 行有 boolean == 1。所以我查看最后一期的行。值為 [1, 5],5 是最大值,因此第 2 行中 new_boolean 的值為 1。
第二個示例:第 8 行(值 = 7):我得到值 [7, 4, 12, 9],12 是最大值,因此值為 12 的行中 new_boolean 的值將為 1
結果:
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
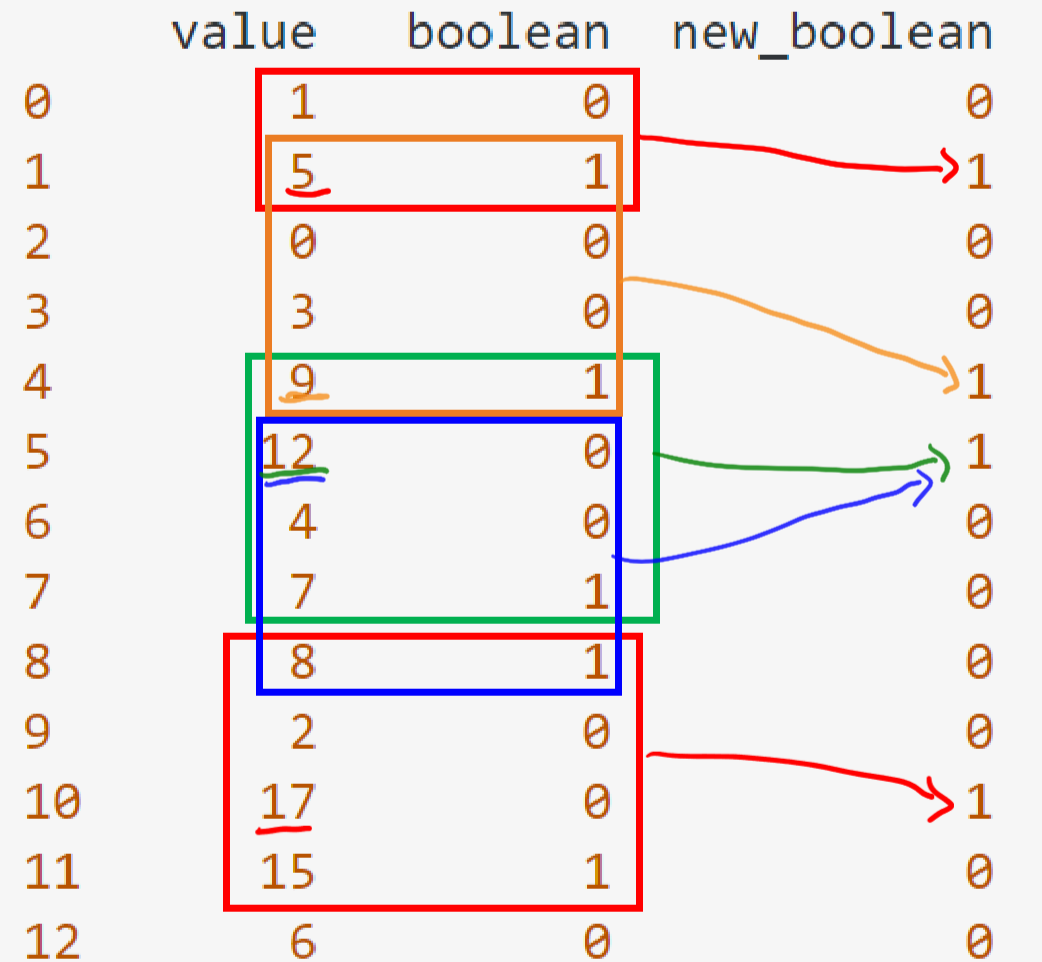
我怎樣才能在演算法上做到這一點?
uj5u.com熱心網友回復:
df.index與df.iloc和 一起使用df.idxmax:
In [182]: period = 4 # Define period to 4
In [183]: ix = df[df.boolean.eq(1)].index # Create a list of indexes where boolean = 1
In [213]: new_bool_ix = [] # empty list
# For every index in `ix`, take the last 4 rows and append the index of maximum `value`
In [215]: for i in ix:
...: new_bool_ix.append(df.iloc[:i 1].iloc[-period:]['value'].idxmax())
...:
In [225]: df['new_boolean'] = 0 # declare column new_boolean with default value `0`
In [227]: df.loc[new_bool_ix, 'new_boolean'] = 1 # Change the value to 1 for the indexes in new_bool_ix
In [228]: df
Out[228]:
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
uj5u.com熱心網友回復:
計算“值”列的滾動最大值
>>> rolling_max_value = df.rolling(window=4, min_periods=1)['value'].max()
>>> rolling_max_value
0 1.0
1 5.0
2 5.0
3 5.0
4 9.0
5 12.0
6 12.0
7 12.0
8 12.0
9 8.0
10 17.0
11 17.0
12 17.0
Name: value, dtype: float64
僅選擇相關值,即其中 'boolean' = 1
>>> on_values = rolling_max_value[df.boolean == 1].unique()
>>> on_values
array([ 5., 9., 12., 17.])
'new_boolean' = 1 的行是 'value' 所屬的行 on_values
>>> df['new_boolean'] = df.value.isin(on_values).astype(int)
>>> df
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
編輯:
OP提出了一個很好的觀點
如果我有多個具有相同值的列并且它們具有不同的布林值,這也有效嗎?
以前的解決方案沒有考慮到這一點。為了解決這個問題,我們不計算滾動最大值,而是收集與滾動最大值關聯的行標簽,即滾動argmax或idxmax。據我所知,Rolling物件沒有idxmax方法,但我們可以通過apply.
def idxmax(values):
return values.idxmax()
rolling_idxmax_value = (
df.rolling(min_periods=1, window=4)['value']
.apply(idxmax)
.astype(int)
)
on_idx = rolling_idxmax_value[df.boolean == 1].unique()
df['new_boolean'] = 0
df.loc[on_idx, 'new_boolean'] = 1
結果:
>>> rolling_idxmax_value
0 0
1 1
2 1
3 1
4 4
5 5
6 5
7 5
8 5
9 8
10 10
11 10
12 10
Name: value, dtype: int64
>>> on_idx
[ 1 4 5 10]
>>> df
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
uj5u.com熱心網友回復:
我分兩步完成,但我認為解決方案更清晰:
df = pd.read_csv(StringIO('''
id value boolean
0 1 0
1 5 1
2 0 0
3 3 0
4 9 1
5 12 0
6 4 0
7 7 1
8 8 1
9 2 0
10 17 0
11 15 1
12 6 0'''),delim_whitespace=True,index_col=0)
df['new_bool'] = df['value'].rolling(min_periods=1, window=4).max()
df['new_bool'] = df.apply(lambda x: 1 if ((x['value'] == x['new_bool']) & (x['boolean'] == 1)) else 0, axis=1)
df
結果:
value boolean new_bool
id
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 0
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 0
11 15 1 0
12 6 0 0
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/333426.html