我想過濾df_1符合以下兩個條件的行
行
df_1不應該在df_2或者
如果從行
df_1中df_2,那么它必須有一個值Yes在df_2
我試過的代碼,不起作用
import pandas as pd
df_1 = pd.DataFrame({'a': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]})
df_2 = pd.DataFrame({'a': [2, 4, 6, 8, 10], 'b': ['Yes', 'No', 'Yes', 'No', 'No']})
df = df_1[(~df_1.a.isin(df_2.a)) | (df_2.b=='Yes')]
輸出
a
0 1
2 3
4 5
6 7
8 9
預期產出
a
0 1
1 2
2 3
3 6
4 5
6 7
8 9
說明第 1、3、5、7、9 行不在,df_2因此它們是輸出的一部分 第 2 行和第 6 行在,df_2但有 b 列,Yes因此它們是輸出的一部分
uj5u.com熱心網友回復:
我認為您可以創建兩個框架并將其連接如下。
import pandas as pd
df_1 = pd.DataFrame({'a': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]})
df_2 = pd.DataFrame({'a': [2, 4, 6, 8, 10], 'b': ['Yes', 'No', 'Yes', 'No', 'No']})
df = [df_1[(~df_1.a.isin(df_2.a))]['a'],df_2[df_2.b=='Yes']['a']]
result = pd.concat(df).sort_values()
print(result)
輸出
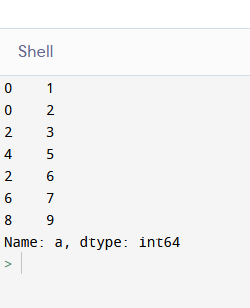
uj5u.com熱心網友回復:
您計算中的問題源于這樣一個事實,即df_1和df_2列之間的大小和邏輯運算子不相同是沒有意義的。如果您將您的值映射df_1到Yes,No或NaNusingdf_2那么您將擁有可以比較的相等長度的列
df_1[(~df_1["a"].isin(df_2["a"])) | (df_1["a"].map(df_2.set_index("a")["b"]) == "Yes")]
uj5u.com熱心網友回復:
您可以使用:
df = df_1.merge(df_2, how='left', on='a')
print(df[df.b.isin(['Yes', np.nan])][['a']])
OUTPUT
a
0 1
1 2
2 3
4 5
5 6
6 7
8 9
uj5u.com熱心網友回復:
這不是最快的解決方案,但這些步驟應該很容易讓您遵循。當使用聯合合并兩個資料框時,NaN會添加值來代替缺失的資料。之后您想保留這些行,因此您只需要洗掉那些具有 value 的行No。
import pandas as pd
df_1 = pd.DataFrame({'a': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]})
df_2 = pd.DataFrame({'a': [2, 4, 6, 8, 10], 'b': ['Yes', 'No', 'Yes', 'No', 'No']})
# Merge the dataframes using a union
df = df_1.merge(df_2, how='outer', on='a')
# Drop the rows where 'b' == 'No'
df.drop(df[df['b']=='No'].index, inplace=True)
# Drop column 'b'
df.drop('b', axis=1, inplace=True)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/333437.html