目錄
前言
正文
1、MySQL硬抗
2、分布式快取(Tair)硬抗
3、客戶端分布式快取
4、快取預熱
5、客戶端本地快取
6、訪問DB加鎖
7、熱點探測
8、限流
9、全鏈路壓測
10、預案
11、降級部分非核心功能
12、監控大盤
13、加機器
14、其他
最后
推薦閱讀
前言
又到一年雙11,相信大部分同學都曾經有這個疑問:支撐起淘寶雙11這么大的流量,需要用到哪些核心技術?性能優化系列的第二篇我想跟大家探討一下這個話題,
完整的雙11鏈路是非常長的,我當前也沒這個實力跟大家去探討完整的鏈路,本文只跟大家探討其中的一個核心環節:商品瀏覽,
商品瀏覽是整個鏈路中流量最大的或者至少是之一,這個大家應該不會有疑問,因為幾乎每個環節都需要商品瀏覽,
阿里云公布的2020年雙11訂單創建峰值是58.3萬筆/秒,而我們在下單前經常會點來點去看這個看那個的,因此商品瀏覽肯定至少在百萬QPS級別,
廢話不多說,直接開懟,
正文
1、MySQL硬抗
不知道有沒有老鐵想過用MySQL硬抗雙11百萬QPS,反正我是沒有,不過我們還是用資料來說說為什么不可能這么做,
根據MySQL官方的基準測驗,MySQL在通常模式下的性能如下圖所示:

當然這個資料僅供參考,實際性能跟使用的機器配置、資料量、讀寫比例啥的都有影響,
首先,淘寶的資料量肯定是比較大的,這個毋庸置疑,但是無論怎么分庫分表,由于成本等原因,肯定每個庫還是會有大量的資料,
我當前所在的業務剛好資料量也比較大,我們DBA給的建議是單庫QPS盡量控制在5000左右,實際上有可能到1萬也沒問題,但是此時可能存在潛在風險,
DBA給的這個建議值是比較穩健保守的,控制在這個值下基本不會出問題,因此我們盡量按DBA的建議來,畢竟他們在這方面會更專業一些,
如果按照單庫抗5000來算,即使多加幾個從庫,也就抗個十來萬QPS頂天了,要抗百萬QPS就根本不可能了,流量一進來,DB肯定馬上跪成一片灰燼,
有同學可能會想,能不能無限加從庫硬懟?
這個是不行的,因為從庫是需要占用主庫資源的,看過我之前MySQL面試題的同學應該知道,主庫需要不斷和從庫進行通信,傳輸binlog啥的,從庫多了主庫會受影響,無限加從庫最后的結果肯定是將主庫懟掛了,我們這邊的建議值是從庫數量盡量不要超過20個,超了就要想其他法子來優化,
2、分布式快取(Tair)硬抗
上分布式快取硬抗應該是大部分老哥會想到的,我們也用資料來分析一下可行性,
阿里用的分布式快取是自研的 Tair,不知道的可以理解為 Redis 吧,對外其實也是說的 Redis 企業版,
Tair官方自稱性能約為同規格社區版實體的3倍,阿里云官網上,Tair企業版性能增強-集群版當前的實體規格如下圖所示:
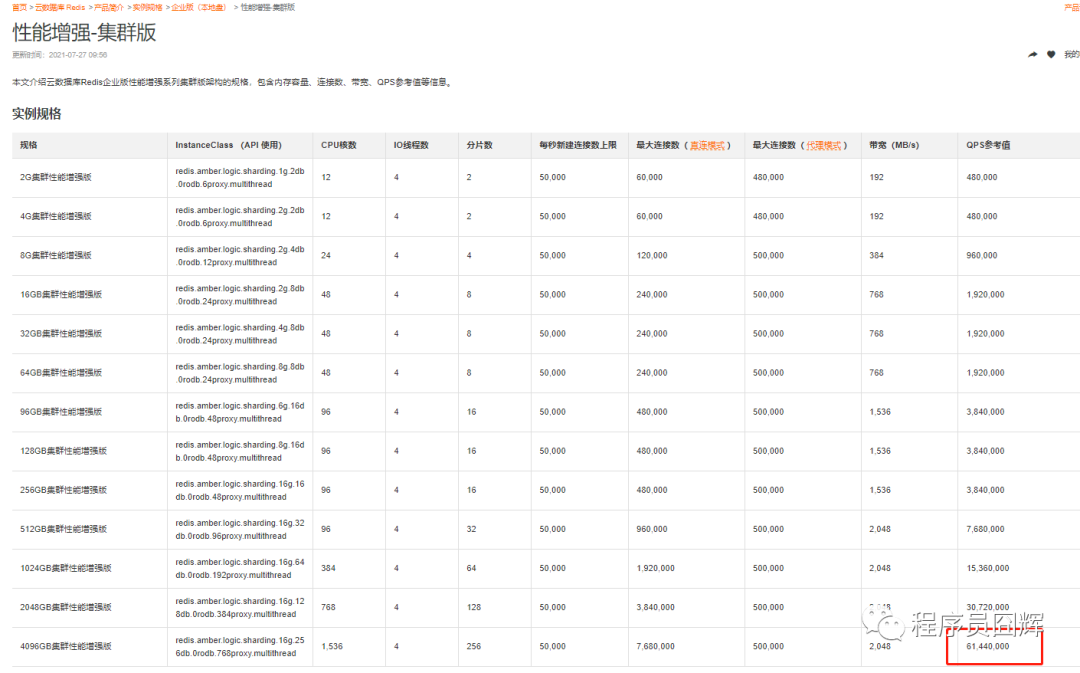
右下角最猛的【4096GB集群性能增強版】的QPS參考值超過6000萬+,沒錯,我數了好幾遍,就是6000萬,我的龜龜,太變態了,
直接把【4096GB集群性能增強版】懟上去就解決了,還要啥優化,如果一個解決不了,大不了就兩個嘛,
分布式快取確實是大多數情況下抗讀流量的主力,所以用Tair硬抗的方案肯定是沒大問題的,但是我們需要思考下是否存在以一些細節問題,例如:
-
分布式快取通常放在服務端,上游通過RPC來呼叫獲取商品資訊,百萬級的流量瞬間打進來,是否會直接將RPC的執行緒池打掛?
-
快取里的資訊通常是先查詢DB再寫到快取里,百萬級的流量瞬間打進來,是否會直接將DB打掛?
-
是否存在熱點商品,導致Tair單節點扛不住?
-
...
這些問題我們接下來一一討論,
3、客戶端分布式快取
分布式快取放在服務端,我們稱之為服務端分布式快取,但是要使用服務端分布式快取需要上游進行RPC呼叫,請求量太大會帶來隱患,同時帶來了額外的網路請求耗時,
為了解決這個問題,我們引入客戶端分布式快取,所謂客戶端分布式快取就是將請求Tair的流程集成在SDK里,如果Tair存在資料,則直接回傳結果,無需再請求到服務端,
這樣一來,商品資訊只要在Tair快取里,請求到客戶端就會結束流程,服務端的壓力會大大降低,同時實作也比較簡單,只是將服務端的Tair請求流程在SDK里實作一遍,
4、快取預熱
為了解決快取為空穿透到DB將DB打掛的風險,可以對商品進行預熱,提前將商品資料加載到Tair快取中,將請求直接攔截在Tair,避免大量商品資料同時穿透DB,打掛DB,
具體預熱哪些商品了?
這個其實不難選擇,將熱點商品統計出來即可,例如以下幾類:
1)在雙11零點付款前,大部分用戶都會將要買的商品放到購物車,因此可以對購物車的資料進行一個統計,將其中的熱點資料計算出來即可,
2)對一些有參與優惠或秒殺活動的商品進行統計,參與活動的商品一般也會被搶購的比較厲害,
3)最近一段時間銷量比較大的商品,或者瀏覽量比較大的商品,
4)有參與到首頁活動的商品,最近一段時間收藏夾的商品等等...
淘寶背后有各種各樣的資料,統計出需要預熱的商品并不難,
通過預熱,可以大大降低DB被穿透的風險,
5、客戶端本地快取
阿里云官網的資料【4096GB集群性能增強版】的QPS參考值超過6000萬+,但是這個值是在請求分布比較均勻的情況下的參考值,256個分片上每個分片二三十萬這樣,
通常個別分片高一點也沒事,五六十萬估計也ok,但是一般不能高太多,否則可能出現帶寬被打滿、節點處理不過來等情況,導致整個集群被打垮,
這個時候就需要祭出我們的最終神器了,也就是本地快取,本地快取的性能有多牛逼了,我們看下這張圖,
這張圖是caffeine(一個高性能Java快取框架)官方提供的本地測驗結果,并不是服務器上的測驗結果,
測驗運行在 MacBook Pro i7-4870HQ CPU @ 2.50GHz (4 core) 16 GB Yosemite系統,簡單來說,比較一般的配置,大部分服務器配置應該都會比這個高,
在這個基準測驗中, 8 執行緒對一個配置了最大容量的快取進行并發讀,
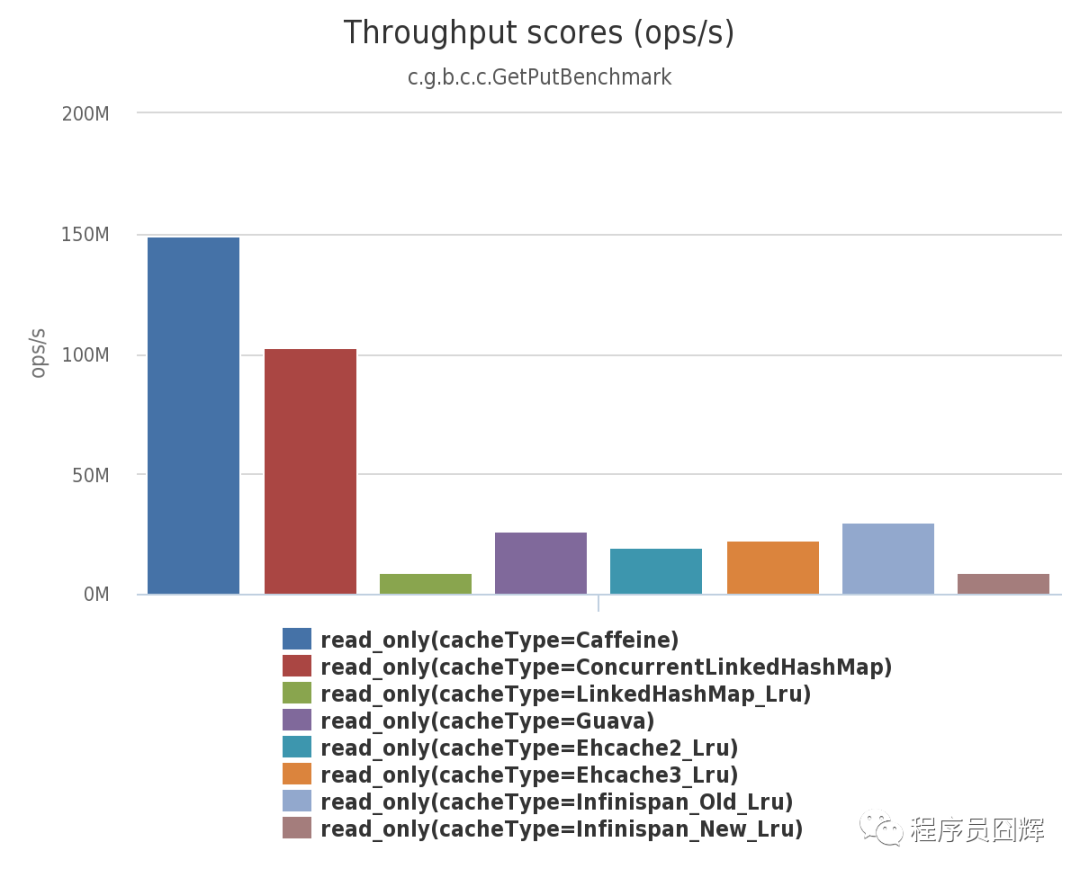
可以看到,caffeine支持每秒運算元差不多是1.5億,而另一個常見的快取框架Guava差不多也有2000多萬的樣子,
而在服務器上測驗結果如下:
服務器配置是單插槽 Xeon E5-2698B v3 @ 2.00GHz (16 核, 禁用超執行緒),224 GB,Ubuntu 15.04,
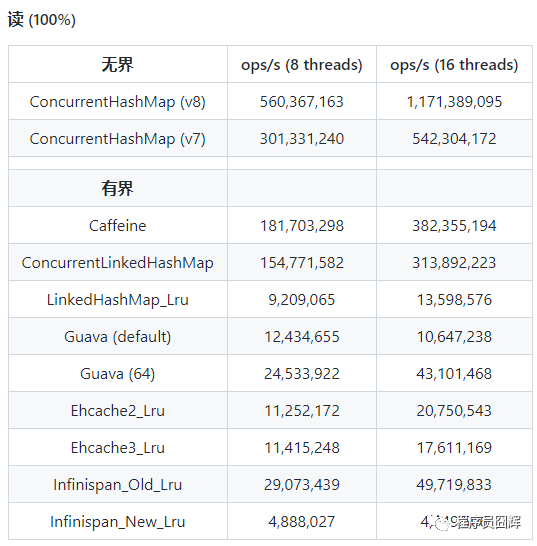
可以看到caffeine在使用16執行緒時支持每秒運算元已經達到3.8億次,其他的框架也基本都是千萬級以上,
通過上面的資料,大家應該都明白了,本地快取在抗讀流量上理論上是無敵的,當然本地快取有一些缺點,例如需要占用服務器的本地記憶體,因此通常我們只會存盤少量的熱點資料,嚴格配置好引數,控制好本地快取的占用記憶體上限,避免影響服務器本身的使用,
因此,我們會對之前的熱點資料,再進行一次篩選,選出“熱點中的熱點”,將這些資料提前預熱到本地快取中,
可能有同學會問,如果本地快取里的商品資料發生了變更,怎么辦?
一個辦法是使用類似ZK的監聽方式,當本地快取的商品發生變更時,觸發更新操作,本地快取去拉取最新資料,因為本地快取的商品數較少,所以ZK整體壓力不會太大,
另一個辦法是本地快取定期拉取最新資料,例如每隔N秒后,就主動查詢一次DB,將資料更新為最新資料,具體延遲幾秒,根據業務上能接受的來控制,
具體選哪種看業務的選擇吧,這些被篩選進入本地快取的資料基本都是最熱的那些商品,無論是商家還是運營都心里有數,肯定在活動前會再三確認,所以出現變更的幾率其實不大,
6、訪問DB加鎖
盡管我們對熱點資料進行了預熱,但是我們必須考慮到可能會有這么一些快取擊穿的場景:
1)某個熱點資料在快取里失效了,大量流量瞬間打到DB,導致DB被打垮,
2)某個商品并不屬于熱點商品,所以并沒有預熱,但是在活動開始后成為熱點商品,導致流量大量打到DB,DB被瞬間打垮,
等等,這些場景都可能會導致DB瞬間被打垮,DB是生命線,DB一掛就涼了,因此我們必須要有相應的措施來應對,
解決方案在之前講快取擊穿的文章里其實提過了,就是在訪問DB時加鎖,保證單臺服務器上對于同一個商品在同一時刻,只會有一個執行緒去請求DB,其他的全部原地阻塞等待該執行緒回傳結果,
注意,這邊我們是不會加分布式鎖的,只會加JVM鎖,因為JVM鎖保證了在單臺服務器上只有一個請求走到資料庫,通常來說已經足夠保證資料庫的壓力大大降低,同時在性能上比分布式鎖更好,這個在Guava中就有現成的實作,有興趣的可以看看,
7、熱點探測
我們上述所說的熱點商品都是基于已有資料的分析,屬于靜態資料,難免會有漏掉的,因此也需要有辦法能實時的探測出熱點資料,從而進行快取,保護系統穩定,
8、限流
無論你想的多么齊全,真正面臨線上考驗的時候,經常會出現一些你沒考慮到的情況,因此,我們必須要有最終的保護措施,
限流降級作為最后一道防御墻,不到萬不得已我們不希望使用到他,但是我們必須做好準備,萬一發生沒預料到的情況,可以保證大部分用戶不會受到影響,
9、全鏈路壓測
模擬雙11當天的流量進行測驗,系統到底能抗多少,只有壓測一下才知道,同時壓測出來的指標,也會作為我們設定限流值很重要的參考依據,
10、預案
預案是指根據評估分析或經驗,對潛在的或可能發生的突發事件的類別和影響程度而事先制定的應急處置方案,
簡單來說就是關鍵時刻一鍵拉閘,直接切換某些功能或者關閉降級某些功能,以保障核心功能不會受到影響,
11、降級部分非核心功能
在雙11高峰期將一些非核心功能進行降級,避免影響核心流程,例如我記得訂單是超過幾個月就不讓查,
12、監控大盤
各項核心指標都需要有監控和告警,例如:快取命中率、服務端請求QPS、DB讀寫QPS等等,
同時要設定合理的告警值,萬一出現例外可以及時感知及時解決,
同時要有一個核心業務監控大盤,放置最核心的業務指標監控,方便大家及時了解業務核心指標情況,
13、加機器
雖然很多人會看不起加機器解決,但是實際上加機器是必不可少的,簡單粗暴,花錢就能解決,
14、其他
以上列的只是我當前能想到的,實際上肯定比這要多的多,
最后
我是囧輝,一個堅持分享原創技術干貨的程式員,
由于本人實力有限難免會有錯誤,歡迎大家指教,如果有疑問,也歡迎留言探討,
推薦閱讀
Java 基礎高頻面試題(2021年最新版)
Java 集合框架高頻面試題(2021年最新版)
面試必問的 Spring,你懂了嗎?
面試必問的 MySQL,你懂了嗎?
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/335220.html
標籤:其他