1、MySQL 邏輯架構分層
把 MySQL 分成三層,跟客戶端對接的連接層,真正執行操作的服務層,和跟硬體打交道的存盤引擎層,
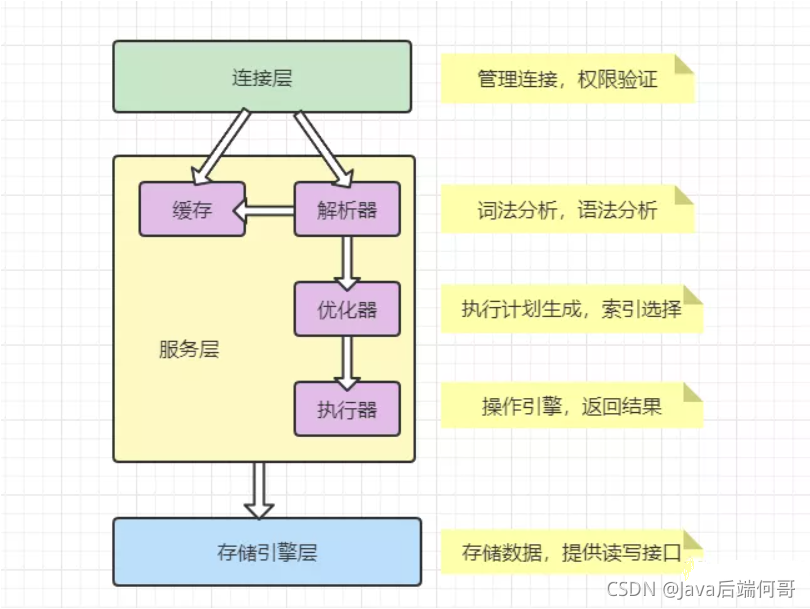 Mysql邏輯架構圖主要分三層:
Mysql邏輯架構圖主要分三層:
(1)第一層負責連接處理,授權認證,安全等等
(2)第二層負責編譯、語法分析并優化SQL
(3)第三層是存盤引擎,
連接層
我們的客戶端要連接到 MySQL 服務器 3306 埠,必須要跟服務端建立連接,那么管理所有的連接,驗證客戶端的身份和權限,這些功能就在連接層完成,
服務層
連接層會把 SQL 陳述句交給服務層,這里面又包含一系列的流程:
比如查詢快取的判斷、根據 SQL 呼叫相應的介面,對我們的 SQL 陳述句進行詞法和語法的決議(比如關鍵字怎么識別,別名怎么識別,語法有沒有錯誤等等),
然后就是優化器,MySQL 底層會根據一定的規則對我們的 SQL 陳述句進行優化,最后再交給執行器去執行,
存盤引擎
存盤引擎就是我們的資料真正存放的地方,在 MySQL 里面支持不同的存盤引擎,再往下就是記憶體或者磁盤,
2、一條SQL查詢陳述句在MySQL中如何執行的?
-
先檢查該陳述句是否有權限,如果沒有權限,直接回傳錯誤資訊,如果有權限會先查詢快取(MySQL8.0 版本以前),
-
如果沒有快取,分析器進行詞法分析,提取 sql 陳述句中 select 等關鍵元素,然后判斷 sql 陳述句是否有語法錯誤,比如關鍵詞是否正確等等,
-
最后優化器確定執行方案進行權限校驗,如果沒有權限就直接回傳錯誤資訊,如果有權限就會呼叫資料庫引擎介面,回傳執行結果,
3、MySQL查詢快取
MySQL 內部自帶了一個快取模塊,執行相同的查詢之后我們發現快取沒有生效,為什么?MySQL 的快取默認是關閉的,
show variables like 'query_cache%';
默認關閉的意思就是不推薦使用,為什么 MySQL 不推薦使用它自帶的快取呢?
主要是因為 MySQL 自帶的快取的應用場景有限:
第一個是它要求 SQL 陳述句必須一模一樣,中間多一個空格,字母大小寫不同都被認為是不同的的 SQL,
第二個是表里面任何一條資料發生變化的時候,這張表所有快取都會失效,所以對于有大量資料更新的應用,也不適合,
所以快取還是交給 ORM 框架(比如 MyBatis 默認開啟了一級快取),或者獨立的快取服務,比如 Redis 來處理更合適,
在 MySQL 8.0 中,查詢快取已經被移除了,
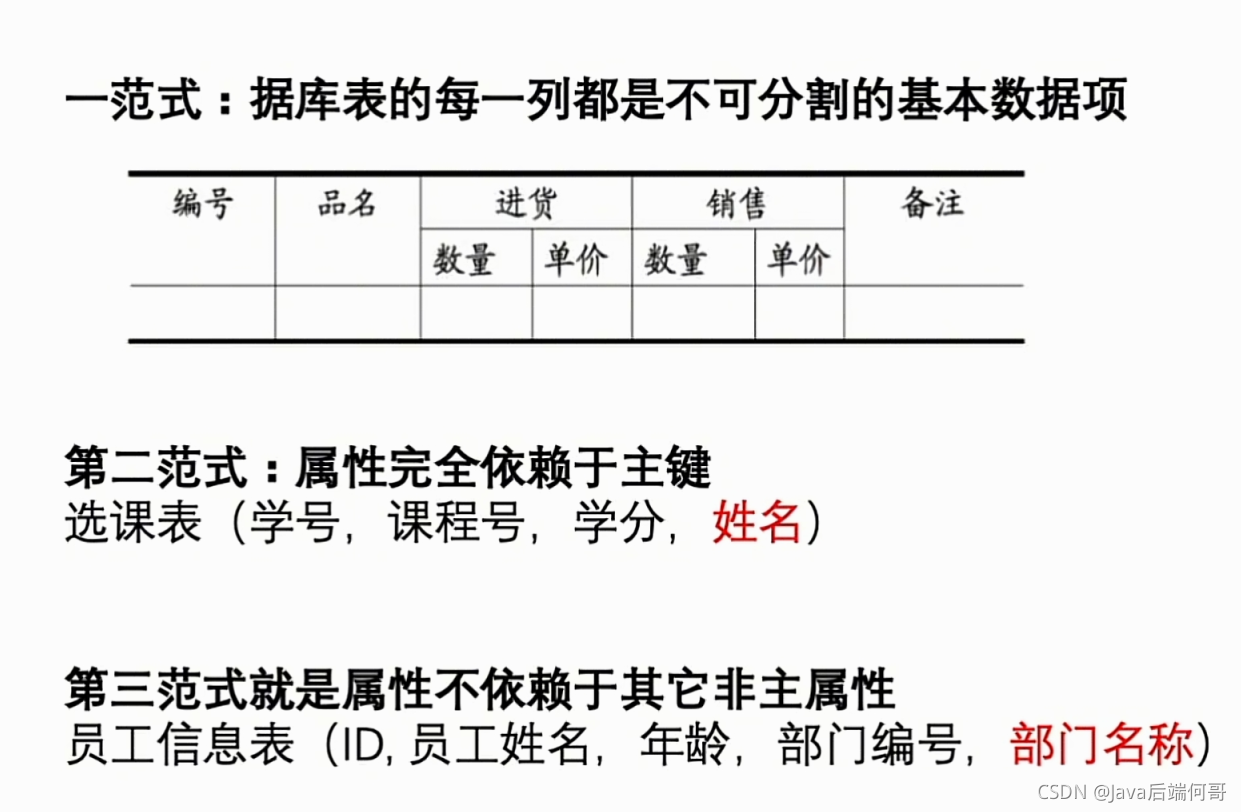
4、資料庫三大范式
5、能說下存盤引擎myisam 和 innodb的區別嗎?
myisam引擎是5.1版本之前的默認引擎,支持全文檢索、壓縮、空間函式等,但是不支持事務和行級鎖,所以一般用于有大量查詢少量插入的場景來使用,而且myisam不支持外鍵,并且索引和資料是分開存盤的,
innodb是基于聚簇索引建立的,和myisam相反它支持事務、行級鎖、外鍵,并且通過MVCC來支持高并發,索引和資料存盤在一起,
6、MySQL事務的四大特性
一般來說,事務是必須滿足4個條件(ACID):原子性(Atomicity,或稱不可分割性)、一致性(Consistency)、隔離性(Isolation,又稱獨立性)、持久性(Durability),
-
原子性(Atomicity):事務作為一個整體被執行,包含在其中的對資料庫的操作要么全部被執行,要么都不執行,
-
一致性(Consistency):指在事務開始之前和事務結束以后,資料不會被破壞,假如A賬戶給B賬戶轉10塊錢,不管成功與否,A和B的總金額是不變的,
-
隔離性(Isolation):多個事務并發訪問時,事務之間是相互隔離的,即一個事務不影響其它事務運行效果,簡言之,就是事務之間是井水不犯河水的,
-
持久性(Durability):表示事務完成以后,該事務對資料庫所作的操作更改,將持久地保存在資料庫之中,
7、事務的隔離級別有哪些?MySQL的默認隔離級別是什么?
Mysql默認的事務隔離級別是可重復讀(Repeatable Read),而大多數資料庫默認的事務隔離級別是Read committed,比如Sql Server , Orale,
(1)讀未提交(Read Uncommitted)
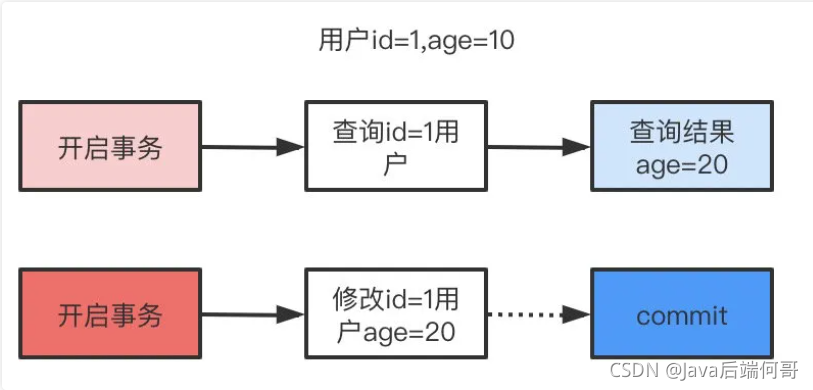
讀未提交,顧名思義,就是一個事務可以讀取另一個未提交事務的資料,
讀未提交可能會讀到其他事務未提交的資料,也叫做臟讀,用戶本來應該讀取到id=1的用戶 age應該是10,結果讀取到了其他事務還沒有提交的事務,結果讀取結果age=20,這就是臟讀,
?
(2) 讀已提交(Read Committed)
讀已提交,顧名思義,就是一個事務要等另一個事務提交后才能讀取資料,
讀已提交解決了臟讀的問題,他只會讀取已經提交的事務,
事例:程式員拿著信用卡去享受生活(卡里當然是只有3.6萬),當他埋單時(程式員事務開啟),收費系統事先檢測到他的卡里有3.6萬,就在這個時候!程式員的妻子要把錢全部轉出充當家用,并提交,當收費系統準備扣款時,再檢測卡里的金額,發現已經沒錢了(第二次檢測金額當然要等待妻子轉出金額事務提交完),程式員就會很郁悶,明明卡里是有錢的…
分析:這就是讀已提交,若有事務對資料進行更新(UPDATE)操作時,讀操作事務要等待這個更新操作事務提交后才能讀取資料,可以解決臟讀問題,但在這個事例中,出現了一個事務范圍內兩個相同的查詢卻回傳了不同資料,這就是不可重復讀,
那怎么解決可能的不可重復讀問題?Repeatable read !
(3) 可重復讀(Repeatable Read)
可重復復讀就是在開始讀取資料(事務開啟)時,不再允許修改操作,可以解決不可重復讀問題,但是可能出現幻讀,
可重復復讀是Mysql的默認事務隔離級別,就是每次讀取結果都一樣,但是有可能產生幻讀,
事例:程式員拿著信用卡去享受生活(卡里當然是只有3.6萬),當他埋單時(事務開啟,不允許其他事務的UPDATE修改操作),收費系統事先檢測到他的卡里有3.6萬,這個時候他的妻子不能轉出金額了,接下來收費系統就可以扣款了,
分析:重復讀可以解決不可重復讀問題,寫到這里,應該明白的一點就是,不可重復讀對應的是修改,即UPDATE操作,但是可能還會有幻讀問題,因為幻讀問題對應的是插入INSERT操作,而不是UPDATE操作,
什么時候會出現幻讀?
事例:程式員某一天去消費,花了2千元,然后他的妻子去查看他今天的消費記錄(全表掃描FTS,妻子事務開啟),看到確實是花了2千元,就在這個時候,程式員花了1萬買了一部電腦,即新增INSERT了一條消費記錄,并提交,當妻子列印程式員的消費記錄清單時(妻子事務提交),發現花了1.2萬元,似乎出現了幻覺,這就是幻讀,
(4) 串行化(Serializable)
Serializable 是最高的事務隔離級別,在該級別下,事務串行化順序執行,可以避免臟讀、不可重復讀與幻讀,但是這種事務隔離級別效率低下,比較耗資料庫性能,一般不使用,
串行,一般是不會使用的,他會給每一行讀取的資料加鎖,會導致大量超時和鎖競爭的問題,\
8、什么是幻讀,臟讀,不可重復讀呢?Innodb是怎么解決幻讀問題的?
(1) 什么是幻讀,臟讀,不可重復讀呢?
事務A、B交替執行,事務A被事務B干擾到了,因為事務A讀取到事務B未提交的資料,這就是臟讀,
在一個事務范圍內,兩個相同的查詢,讀取同一條記錄,卻回傳了不同的資料,這就是不可重復讀,
事務A查詢一個范圍的結果集,另一個并發事務B往這個范圍中插入/洗掉了資料,并靜悄悄地提交,然后事務A再次查詢相同的范圍,兩次讀取得到的結果集不一樣了,這就是幻讀,
(2) Innodb是怎么解決幻讀問題的?
在上面的事務隔離級別介紹中,我們了解到不同的事務隔離級別會引發不同的問題,如在 RR 級別下會出現幻讀,但如果將存盤引擎選為 InnoDB ,在 RR 級別下,幻讀的問題就會被解決,
InnoDB 為了在 RR 級別上解決該問題,引入了間隙鎖,雖然解決了幻讀的問題,但間隙鎖會降低并發率,增加死鎖情況的發生,而 next-key lock 其實就是行鎖(Record Lock)和間隙鎖的合集,
在業務不需要 RR 支持下,如果想提高并發率,可以將隔離級別設定成 RC 并將 binlog 格式設定成 row,
行鎖鎖住的是存在的記錄行,間隙鎖鎖住的是行之間的空隙,而 next-key lock 鎖住的是兩者之和,比如 select * from t for update 鎖住的就是 (-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum],
(-∞,0],由間隙鎖 (-∞,0]) 和行鎖 0 組成,其他類似,
+supremum 表示 InnoDB 給每個索引加了一個不存在的最大值,
推薦閱讀:幻讀在 InnoDB 中是被如何解決的?
9、那事務ACID特性靠什么保證的呢?
A原子性由undo log日志保證,它記錄了需要回滾的日志資訊,事務回滾時撤銷已經執行成功的sql
C一致性一般由代碼層面來保證
I隔離性由MVCC來保證
D持久性由記憶體+redo log來保證,mysql修改資料同時在記憶體和redo log記錄這次操作,事務提交的時候通過redo log刷盤,宕機的時候可以從redo log恢復
10、redo log,undo log,binlog的區別是什么?
(1)重做日志(redo log)作用
確保事務的持久性,防止在發生故障的時間點,尚有臟頁未寫入磁盤,在重啟mysql服務的時候,根據redo log進行重做,從而達到事務的持久性這一特性,
(2)回滾日志(undo log)作用
確保事務的原子性,保存了事務發生之前的資料的一個版本,可以用于回滾,同時可以提供多版本并發控制下的讀(MVCC),也即非鎖定讀
(3)二進制日志(binlog)作用
用于復制,在主從復制中,從庫利用主庫上的binlog進行重播,實作主從同步,
用于資料庫的基于時間點的還原,
11、 那你知道什么是覆寫索引和回表嗎?
覆寫索引指的是在一次查詢中,如果一個索引包含或者說覆寫所有需要查詢的欄位的值,我們就稱之為覆寫索引,而不再需要回表查詢,
而要確定一個查詢是否是覆寫索引,我們只需要explain sql陳述句看Extra的結果是否是“Using index”就能夠觸發索引覆寫,
12、聚集索引與非聚集索引的區別
可以按以下四個維度回答:
(1)一個表中只能擁有一個聚集索引,而非聚集索引一個表可以存在多個,
(2)如果表定義了PK,則PK就是聚集索引;如果表沒有定義PK,則第一個not NULL unique列是聚集索引;否則,InnoDB會創建一個隱藏的row-id作為聚集索引
(3)我們可以這么理解聚簇索引:索引的葉節點就是資料節點,而非聚簇索引的葉節點不存放具體的整行資料(葉子結點不直接指向資料頁),而是存盤的這一行的主鍵的值,
(4)非聚集索引需要回表查詢,先定位主鍵值,再定位行記錄,因為要掃描兩遍索引樹,它的性能較掃一遍索引樹更低,
13、為什么要用 B+ 樹,為什么不用普通二叉樹?
可以從幾個維度去看這個問題,查詢是否夠快,效率是否穩定,存盤資料多少,以及查找磁盤次數,為什么不是普通二叉樹,為什么不是平衡二叉樹,為什么不是B樹,而偏偏是 B+ 樹呢?
(1)為什么不是普通二叉樹?
如果二叉樹特殊化為一個鏈表,相當于全表掃描,平衡二叉樹相比于二叉查找樹來說,查找效率更穩定,總體的查找速度也更快,
(2)為什么不是平衡二叉樹呢?
我們知道,在記憶體比在磁盤的資料,查詢效率快得多,如果樹這種資料結構作為索引,那我們每查找一次資料就需要從磁盤中讀取一個節點,也就是我們說的一個磁盤塊,但是平衡二叉樹可是每個節點只存盤一個鍵值和資料的,如果是B樹,可以存盤更多的節點資料,樹的高度也會降低,因此讀取磁盤的次數就降下來啦,查詢效率就快啦,
(3)為什么不是 B 樹而是 B+ 樹呢?
B+ 樹非葉子節點上是不存盤資料的,僅存盤鍵值,而B樹節點中不僅存盤鍵值,也會存盤資料,innodb中頁的默認大小是16KB,如果不存盤資料,那么就會存盤更多的鍵值,相應的樹的階數(節點的子節點樹)就會更大,樹就會更矮更胖,如此一來我們查找資料進行磁盤的IO次數有會再次減少,資料查詢的效率也會更快,
B+ 樹索引的所有資料均存盤在葉子節點,而且資料是按照順序排列的,鏈表連著的,那么 B+ 樹使得范圍查找,排序查找,分組查找以及去重查找變得例外簡單,
14、鎖的型別有哪些呢?說說資料庫的樂觀鎖和悲觀鎖是什么以及它們的區別?MVCC 熟悉嗎,知道它的底層原理?
(1)鎖的型別有哪些呢?
mysql鎖分為共享鎖和排他鎖,也叫做讀鎖和寫鎖,
讀鎖是共享的,可以通過lock in share mode實作,這時候只能讀不能寫,
寫鎖是排他的,它會阻塞其他的寫鎖和讀鎖,從顆粒度來區分,可以分為表鎖和行鎖兩種,
表鎖會鎖定整張表并且阻塞其他用戶對該表的所有讀寫操作,比如alter修改表結構的時候會鎖表,
行鎖又可以分為樂觀鎖和悲觀鎖,悲觀鎖可以通過for update實作,樂觀鎖則通過版本號實作,
(2) 說說資料庫的樂觀鎖和悲觀鎖是什么以及它們的區別?
悲觀鎖:
悲觀鎖她專一且缺乏安全感了,她的心只屬于當前事務,每時每刻都擔心著它心愛的資料可能被別的事務修改,所以一個事務擁有(獲得)悲觀鎖后,其他任何事務都不能對資料進行修改啦,只能等待鎖被釋放才可以執行,
樂觀鎖:
樂觀鎖的“樂觀情緒”體現在,它認為資料的變動不會太頻繁,因此,它允許多個事務同時對資料進行變動,
實作方式:樂觀鎖一般會使用版本號機制或CAS演算法實作,
(3) MVCC 熟悉嗎,知道它的底層原理?
MVCC (Multiversion Concurrency Control),即多版本并發控制技術,
MVCC在MySQL InnoDB中的實作主要是為了提高資料庫并發性能,用更好的方式去處理讀-寫沖突,做到即使有讀寫沖突時,也能做到不加鎖,非阻塞并發讀,
15 、 那你說說什么是幻讀,什么是MVCC?
要說幻讀,首先要了解MVCC,MVCC叫做多版本并發控制,實際上就是保存了資料在某個時間節點的快照,
我們每行數實際上隱藏了兩列,創建時間版本號,過期(洗掉)時間版本號,每開始一個新的事務,版本號都會自動遞增,
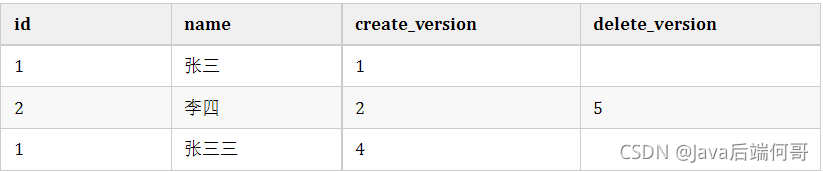
還是拿上面的user表舉例子,假設我們插入兩條資料,他們實際上應該長這樣,
 這時候假設小明去執行查詢,此時current_version=3
這時候假設小明去執行查詢,此時current_version=3
select * from user where id<=3;同時,小紅在這時候開啟事務去修改id=1的記錄,current_version=4
update user set name='張三三' where id=1;執行成功后的結果是這樣的

如果這時候還有小黑在洗掉id=2的資料,current_version=5,執行后結果是這樣的,
 由于MVCC的原理是查找創建版本小于或等于當前事務版本,洗掉版本為慷訓者大于當前事務版本,小明的真實的查詢應該是這樣
由于MVCC的原理是查找創建版本小于或等于當前事務版本,洗掉版本為慷訓者大于當前事務版本,小明的真實的查詢應該是這樣
select * from user where id<=3 and create_version<=3 and (delete_version>3 or delete_version is null);所以小明最后查詢到的id=1的名字還是'張三',并且id=2的記錄也能查詢到,這樣做是為了保證事務讀取的資料是在事務開始前就已經存在的,要么是事務自己插入或者修改的,
明白MVCC原理,我們來說什么是幻讀就簡單多了,舉一個常見的場景,用戶注冊時,我們先查詢用戶名是否存在,不存在就插入,假定用戶名是唯一索引,
-
小明開啟事務current_version=6查詢名字為'王五'的記錄,發現不存在,
-
小紅開啟事務current_version=7插入一條資料,結果是這樣:
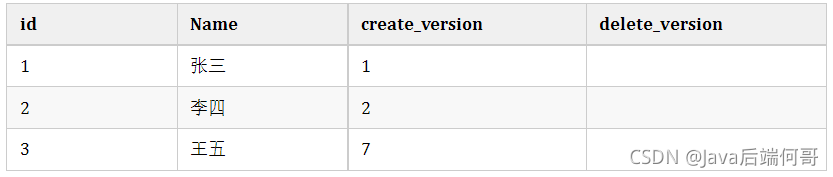 小明執行插入名字'王五'的記錄,發現唯一索引沖突,無法插入,這就是幻讀,
小明執行插入名字'王五'的記錄,發現唯一索引沖突,無法插入,這就是幻讀,
16、那你知道什么是間隙鎖嗎?
間隙鎖是可重復讀級別下才會有的鎖,結合MVCC和間隙鎖可以解決幻讀的問題,我們還是以user舉例,假設現在user表有幾條記錄
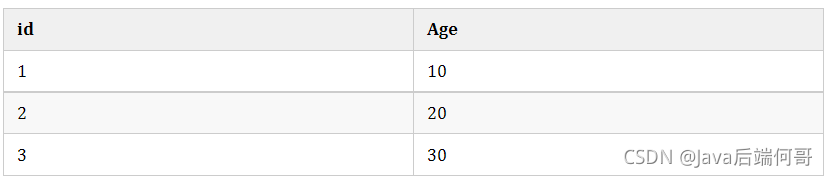
當我們執行:
begin;
select * from user where age=20 for update;
begin;
insert into user(age) values(10); #成功
insert into user(age) values(11); #失敗
insert into user(age) values(20); #失敗
insert into user(age) values(21); #失敗
insert into user(age) values(30); #失敗只有10可以插入成功,那么因為表的間隙mysql自動幫我們生成了區間(左開右閉)
(negative infinity,10],(10,20],(20,30],(30,positive infinity)
由于20存在記錄,所以(10,20],(20,30]區間都被鎖定了無法插入、洗掉,
如果查詢21呢?就會根據21定位到(20,30)的區間(都是開區間),
需要注意的是唯一索引是不會有間隙索引的,
17、說說mysql主從同步怎么做的吧
首先先了解mysql主從同步的原理
-
master提交完事務后,寫入binlog
-
slave連接到master,獲取binlog
-
master創建dump執行緒,推送binglog到slave
-
slave啟動一個IO執行緒讀取同步過來的master的binlog,記錄到relay log中繼日志中
-
slave再開啟一個sql執行緒讀取relay log事件并在slave執行,完成同步
-
slave記錄自己的binglog
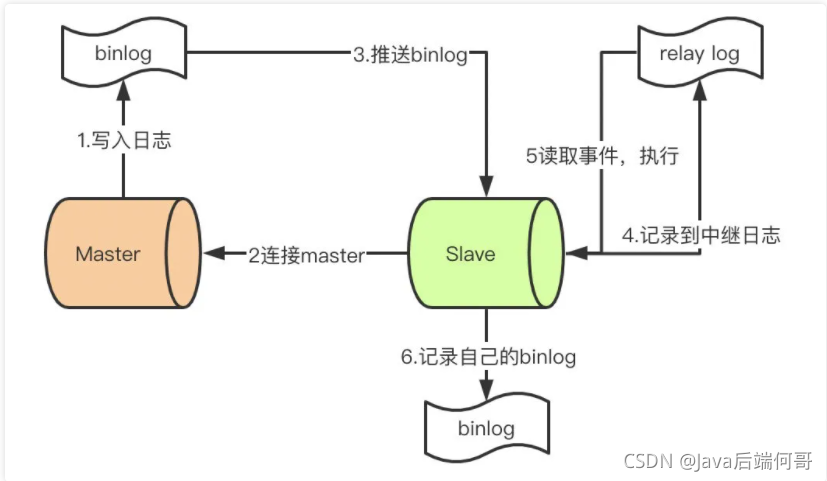
由于mysql默認的復制方式是異步的,主庫把日志發送給從庫后不關心從庫是否已經處理,這樣會產生一個問題就是假設主庫掛了,從庫處理失敗了,這時候從庫升為主庫后,日志就丟失了,由此產生兩個概念,
全同步復制
主庫寫入binlog后強制同步日志到從庫,所有的從庫都執行完成后才回傳給客戶端,但是很顯然這個方式的話性能會受到嚴重影響,
半同步復制
和全同步不同的是,半同步復制的邏輯是這樣,從庫寫入日志成功后回傳ACK確認給主庫,主庫收到至少一個從庫的確認就認為寫操作完成,
18、日常作業中你是怎么優化SQL的?
可以從這幾個維度回答這個問題:
(1) 優化表結構
(1)盡量使用數字型欄位
若只含數值資訊的欄位盡量不要設計為字符型,這會降低查詢和連接的性能,并會增加存盤開銷,這是因為引擎在處理查詢和連接時會逐個比較字串中每一個字符,而對于數字型而言只需要比較一次就夠了,
(2)盡可能的使用 varchar 代替 char
變長欄位存盤空間小,可以節省存盤空間,
(3)當索引列大量重復資料時,可以把索引洗掉掉
比如有一列是性別,幾乎只有男、女、未知,這樣的索引是無效的,
(2) 優化查詢
-
應盡量避免在 where 子句中使用!=或<>運算子
-
應盡量避免在 where 子句中使用 or 來連接條件
-
任何查詢也不要出現select *
-
避免在 where 子句中對欄位進行 null 值判斷
(3) 索引優化
-
對作為查詢條件和 order by的欄位建立索引
-
避免建立過多的索引,多使用組合索引
19、關心過業務系統里面的sql耗時嗎?統計過慢查詢嗎?對慢查詢都怎么優化過?
我們平時寫Sql時,都要養成用explain分析的習慣,慢查詢的統計,運維會定期統計給我們
優化慢查詢思路:
-
分析陳述句,是否加載了不必要的欄位/資料
-
分析 SQL 執行句話,是否命中索引等
-
如果 SQL 很復雜,優化 SQL 結構
-
如果表資料量太大,考慮分表
20、如果讓你做分庫與分表的設計,簡單說說你會怎么做?
分庫分表方案:
-
水平分庫:以欄位為依據,按照一定策略(hash、range等),將一個庫中的資料拆分到多個庫中,
-
水平分表:以欄位為依據,按照一定策略(hash、range等),將一個表中的資料拆分到多個表中,
-
垂直分庫:以表為依據,按照業務歸屬不同,將不同的表拆分到不同的庫中,
-
垂直分表:以欄位為依據,按照欄位的活躍性,將表中欄位拆到不同的表(主表和擴展表)中,
常用的分庫分表中間件:
-
sharding-jdbc
-
Mycat
分庫分表可能遇到的問題
-
事務問題:需要用分布式事務啦
-
跨節點Join的問題:解決這一問題可以分兩次查詢實作
-
跨節點的count,order by,group by以及聚合函式問題:分別在各個節點上得到結果后在應用程式端進行合并,
-
資料遷移,容量規劃,擴容等問題
-
ID問題:資料庫被切分后,不能再依賴資料庫自身的主鍵生成機制啦,最簡單可以考慮UUID
-
跨分片的排序分頁問題
21、你們資料量級多大?分庫分表怎么做的?
首先分庫分表分為垂直和水平兩個方式,一般來說我們拆分的順序是先垂直后水平,
垂直分庫
基于現在微服務拆分來說,都是已經做到了垂直分庫了
?
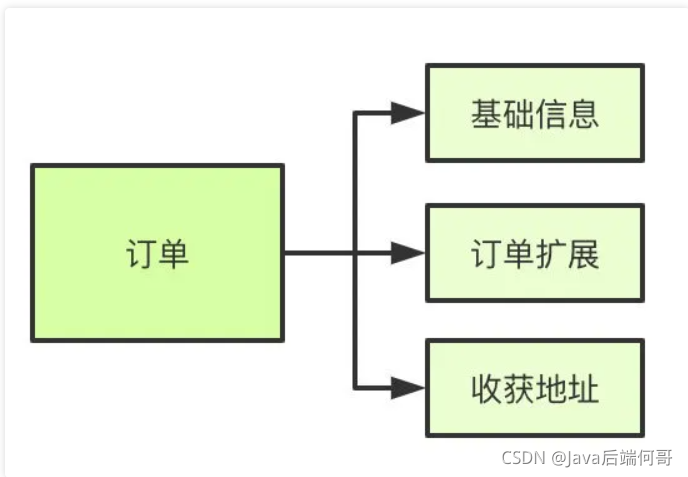
垂直分表
如果表欄位比較多,將不常用的、資料較大的等等做拆分
?
水平分表
首先根據業務場景來決定使用什么欄位作為分表欄位(sharding_key),比如我們現在日訂單1000萬,我們大部分的場景來源于C端,我們可以用user_id作為sharding_key,資料查詢支持到最近3個月的訂單,超過3個月的做歸檔處理,那么3個月的資料量就是9億,可以分1024張表,那么每張表的資料大概就在100萬左右,
比如用戶id為100,那我們都經過hash(100),然后對1024取模,就可以落到對應的表上了,
22、那分表后的ID怎么保證唯一性的呢?
因為我們主鍵默認都是自增的,那么分表之后的主鍵在不同表就肯定會有沖突了,有幾個辦法考慮:
-
設定步長,比如1-1024張表我們設定1024的基礎步長,這樣主鍵落到不同的表就不會沖突了,
-
分布式ID,自己實作一套分布式ID生成演算法或者使用開源的比如雪花演算法這種
-
分表后不使用主鍵作為查詢依據,而是每張表單獨新增一個欄位作為唯一主鍵使用,比如訂單表訂單號是唯一的,不管最終落在哪張表都基于訂單號作為查詢依據,更新也一樣,
23、MySQL資料庫cpu飆升的話,要怎么處理呢?
排查程序:
(1)使用top 命令觀察,確定是mysqld導致還是其他原因,(2)如果是mysqld導致的,show processlist,查看session情況,確定是不是有消耗資源的sql在運行,(3)找出消耗高的 sql,看看執行計劃是否準確, 索引是否缺失,資料量是否太大,
處理:
(1)kill 掉這些執行緒(同時觀察 cpu 使用率是否下降), (2)進行相應的調整(比如說加索引、改 sql、改記憶體引數) (3)重新跑這些 SQL,
其他情況:
也有可能是每個 sql 消耗資源并不多,但是突然之間,有大量的 session 連進來導致 cpu 飆升,這種情況就需要跟應用一起來分析為何連接數會激增,再做出相應的調整,比如說限制連接數等
24、MySQL 遇到過死鎖問題嗎,你是如何解決的?(重點去了解一下,好跟面試官造火箭)
遇到過,我排查死鎖的一般步驟是醬紫的:
(1)查看死鎖日志 show engine innodb status;
(2)找出死鎖Sql
(3)分析sql加鎖情況
(4)模擬死鎖案發
(5)分析死鎖日志
(6)分析死鎖結果
參考鏈接:
《我想進大廠》之mysql奪命連環13問
快問快答,MySQL面試奪命20問
幻讀在 InnoDB 中是被如何解決的?
徹底搞清分庫分表(垂直分庫,垂直分表,水平分庫,水平分表)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/337667.html
標籤:其他