上一期,我們講到集合的知識的初步了解,這次我們就來講解稍微完整版的
目錄
集合框架圖
定義以及介面的講解
詳細講解:
List集合子類特點:
Set集合概述和特點:
HashSet集合概述和特點:
哈希值:
TreeSet集合概述和特點:
TreeSet集合特點:
Comparator的使用:
泛型:
型別通配符:
Map集合概述和使用:
補充內容:
集合框架底層資料結構總結:
Collection
Map
如何選用集合?
特別注意事項:
List 和 Map 區別?(資料結構,存盤特點)
Arraylist與 LinkedList 異同:
HashMap 和 Hashtable 的區別:
ArrayList 與 Vector 的區別:
HaspMap與TreeMap的區別:
HashMap 和 HashSet區別
HashMap和Hashtable的區別
ArrayList和Vector的區別(是否有序、是否重復、資料結構、底層實作)
集合框架圖
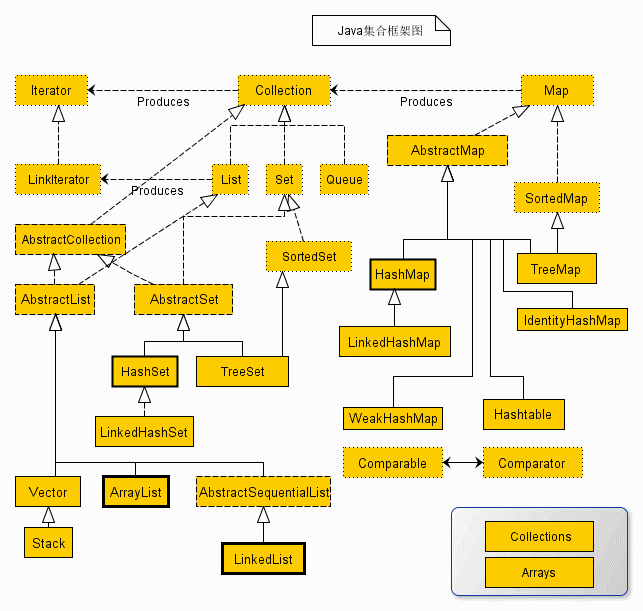
定義以及介面的講解
1、定義:Java集合類存放于java.util包,是存放物件的容器,長度可變,只能存放物件,可以存放不同的資料型別;
2、常用集合介面:
a、Collection介面:最基本的集合介面,存盤不唯一,無序的物件,List介面和Set介面的父介面;
b、List介面:一個有序、可以重復的集合,常用實作類ArrayList和LinkedList;
1 // 底層資料結構是陣列,查詢快,增刪慢,執行緒不安全,效率高
2 List arrayList = new ArrayList();
3 // 底層資料結構是陣列,查詢快,增刪慢,執行緒安全,效率低,耗性能
4 List vector = new Vector();
5 // 底層資料結構是鏈表,查詢慢,增刪快,執行緒不安全,效率高
6 List linkedList = new LinkedList();c、Set介面:一個無序、不可重復的集合,常用實作類HashSet、LinkedHashSet、TreeSet;
1 // 元素無序,不可重復,執行緒不安全,集合元素可以為 NULL
2 Set hashSet = new HashSet();
3 // 底層采用鏈表和哈希表的演算法,保證元素有序,唯一性(即不可以重復,有序),執行緒不安全
4 Set linkedHashSet = new LinkedHashSet();
5 // 底層使用紅黑樹演算法,擅長于范圍查詢,元素有序,不可重復,執行緒不安全
6 Set treeSet = new TreeSet();d、Map介面:key-value的鍵值對,key不允許重復,value可以,key-value通過映射關系關聯,常用實作類HashMap和TreeMap;
1 // 采用哈希表演算法,key無序且不允許重復,key判斷重復的標準是:key1和key2是否equals為true,并且hashCode相等
2 Map<String, String> hashMap = new HashMap<String, String>();
3 // 采用紅黑樹演算法,key有序且不允許重復,key判斷重復的標準是:compareTo或compare回傳值是否為0
4 Map<String, String> treeMap = new TreeMap<String, String>();3、Set和List的區別:
a、Set實體存盤是無序的,不重復的資料;List實體存盤的是有序的,可以重復的元素;
b、Set檢索效率低下,洗掉和插入效率高,洗掉和插入不會引起元素位置改變;
c、List可以根據存盤的資料長度自動增長List長度,查找元素效率高,插入洗掉效率低,插入和洗掉時會引起其他元素位置改變;
4、Map和Set的關系:
a、HashMap、HashSet 都采哈希表演算法,TreeMap、TreeSet 都采用紅黑樹演算法、LinkedHashMap、LinkedHashSet 都采用哈希表演算法和紅黑樹演算法;
b、分析Set的底層原始碼,Set 集合就是由Map集合的Key組成;
詳細講解:
List集合我們已經在上一篇文章里面講到了, 所以這次我們就講深入的知識,
List集合子類特點:
上面也提到了,這個是做的導圖里面的內容;

在這里我做了一個小小的測驗,將上面提到的6個特有方法都寫了一遍
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<String > LinkedList =new LinkedList<String >();
LinkedList.add("hello");
LinkedList.add("world");
LinkedList.add("java");
/* // public void addFirst(E e):在該串列開頭插入指定的元素
//public void addLast(E e):將指定元素追加到串列的末尾
LinkedList.addFirst("javaee");
LinkedList.addLast("hhh");q87yh
// public E getFirst() :回傳此串列中的第一個元素
// public E getLast(): 回傳此串列中的最后一個元素
System.out.println(LinkedList.getFirst());
System.out.println(LinkedList.getLast());
//public E removeFirst(); 洗掉并回傳第一個元素
//public E removeLast():洗掉并回傳最后一個元素
System.out.println(LinkedList.removeFirst());
System.out.println(LinkedList.removeLast());*/
System.out.println(LinkedList);
}
}大佬們也可以自己上機測驗測驗,方便理解其內容,
Set集合概述和特點:
set集合特點:1.不包含重復元素的集合
2.沒有帶索引的方法,所以不能使用普通for回圈遍歷
讓我們用代碼來觀察其特點, 不包含重復元素
public class SetDemo {
public static void main(String[] args) {
//創建集合物件
Set<String> set=new HashSet<String>();
//添加元素
set.add("hello");
set.add("world");
set.add("java");
//不包含重復元素
set.add("world");
//遍歷
for (String s:set){
System.out.println(s);
}
}
}控制臺輸出截圖:

講完了Set集合,讓我們來看看HashSet
HashSet集合概述和特點:
hashset集合特點:
①:底層的資料結構是哈希;
②:它對集合的迭代順序不作任何保證;特別是它不能保證訂單在一段時間內保持不變,這個類允許 null元素;
③:沒有帶索引的方法,所以不能使用普通for回圈遍歷
④:由于是set集合,所以是不包含重復元素的集合
hashset集合添加元素的程序:
如下圖所示:
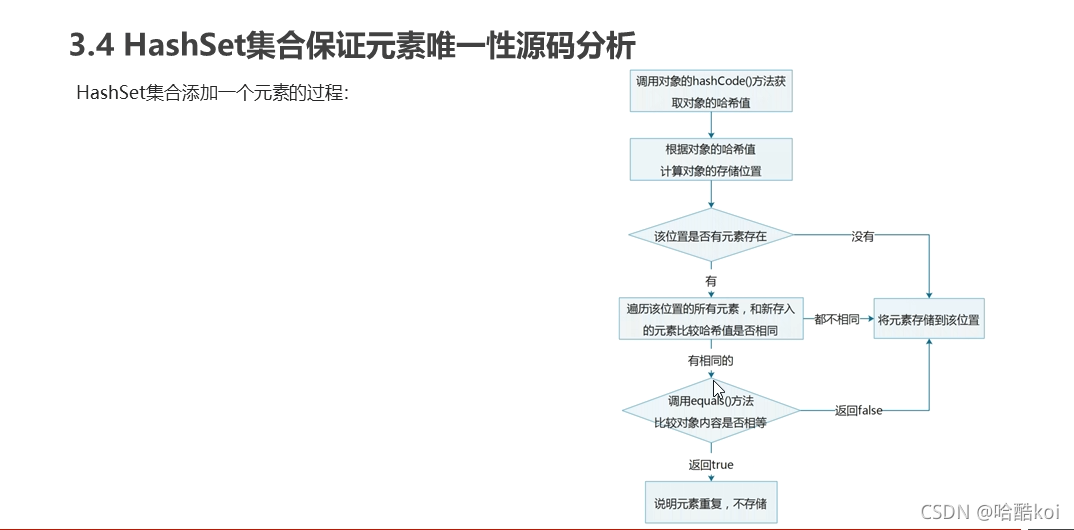
可能這個圖的字有點小,大家委屈一下自己,
代碼上機測驗:
public class HashSetDemo {
public static void main(String[] args) {
//創建集合物件
HashSet<String> hs=new HashSet<String>();
//添加元素
hs.add("hello");
hs.add("world");
hs.add("java");
hs.add("world"); //就算你輸入了兩個, 但是 他是不能重復的
for (String s:hs){
System.out.println(s);
}
}
}從上圖,我們看到的,hs.add 里面寫了倆個 world, 可是set集合的特點是不重復元素,并且得需要使用增強for來實作遍歷,輸出結果如下圖所示:
中間穿插一點小片段,上面講到了HashSet 所以我們來講講 哈希值,
哈希值:
1.定義:哈希值是JDK根據物件的地址或者字串或者數字算出來的int型別的數值;
2. public int hashCode():回傳物件的哈希值!!! 需要了解;
3.哈希值的特點:
①:同一個物件多次呼叫hashCode()方法回傳的哈希值是相同的;
②:默認情況下,不同的物件的哈希值是不同的,而重新hashCode()方法,可以實作讓不同物件的哈希值相同
下面我們將上機實際通過代碼測驗:
public class HashDemo {
public static void main(String[] args) {
//創建學生物件
Student s1=new Student("林青霞",30);
System.out.println(s1.hashCode());//22307196
System.out.println(s1.hashCode());//22307196
//同一個物件多次呼叫hashcode()方法回傳的哈希值是相同的
System.out.println("--------------");
//默認情況下,不同的物件的哈希值是不相同的
Student s2=new Student("林青霞",30);
System.out.println(s2.hashCode());//10568834
System.out.println(s2.hashCode());//10568834
System.out.println("-------------");
//通過方法重寫,可以實作不同物件的哈希值是相同的;
System.out.println("hello".hashCode());//99162322
System.out.println("world".hashCode());//113318802
System.out.println("java".hashCode());//3254818
System.out.println("world".hashCode());//113318802
System.out.println("重地".hashCode());//1179395
System.out.println("通話".hashCode());//1179395
}
}控制臺列印輸出:
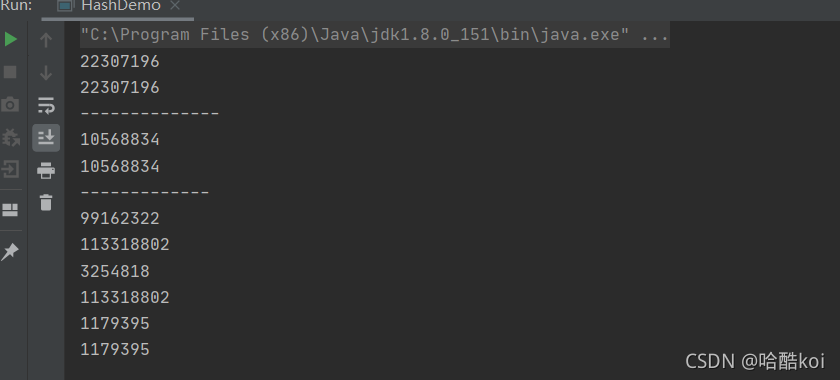
哈希值這個東西,大家可以多了解了解,蠻有趣的一個東西,
TreeSet集合概述和特點:
TreeSet集合特點:
①:元素有序,這里的順序不是指存盤和取出的順序,而是按照一定的規則進行排序,具體的排序方式取決于構造方法;
兩個方法:1.TreeSet():根據其元素的自然排序
2.TreeSet( Comparator comparator): 根據指定的比較器進行排序
②:沒有帶索引的方法,所以不能使用普通for回圈遍歷,但是可以用增強for進行遍歷;
③:由于是set集合,所以不包含重復元素的集合;
Comparator的使用:
1.自然排序Comparable的使用:
①:TreeSet集合存盤自定義物件,無參構造方法使用的是自然排序對元素進行排序的
②:自然排序,就是讓元素所屬的類實作Comparable介面,重新compareTo(T o)方法
③:重寫方法時,一定要注意排序規則必須按照要求的主要條件和次要條件來寫
2.比較器排序Comparator的使用:
①:用TreeSet集合存盤自定義物件,帶參構造方法使用的是比較器排序對元素進行排序的
②:比較器排序,就是讓集合構造方法接收Comparator的實作類物件,重寫compare(To1, To2) 方法
代碼上機測驗:
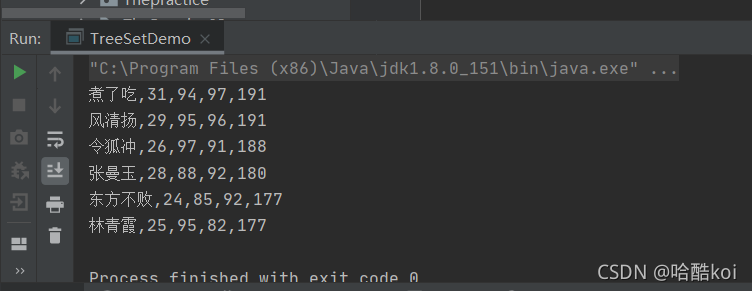
public class TreeSetDemo {
public static void main(String[] args) {
//通過創建TreeSet集合物件, 通過比較器排序進行排序
TreeSet<Student> ts=new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
//主要條件!!!
int num=(s2.getSum()-s1.getSum());
//次要條件
int num2=num==0?s1.getChinese()-s2.getChinese():num;
return num2;
}
});
//創建學生物件
Student s1=new Student("林青霞",25,95,82);
Student s2=new Student("張曼玉",28,88,92);
Student s3=new Student("令狐沖",26,97,91);
Student s4=new Student("風清揚",29,95,96);
Student s5=new Student("東方不敗",24,85,92);
Student s6=new Student("煮了吃",31,94,97);
Student s7=new Student("煮了吃",31,94,97);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
ts.add(s7);
for (Student s: ts){
System.out.println(s.getName()+","+s.getAge()+","+s.getChinese()+","+s.getMath()+","+s.getSum());
}
}
}代碼測驗結果如下:
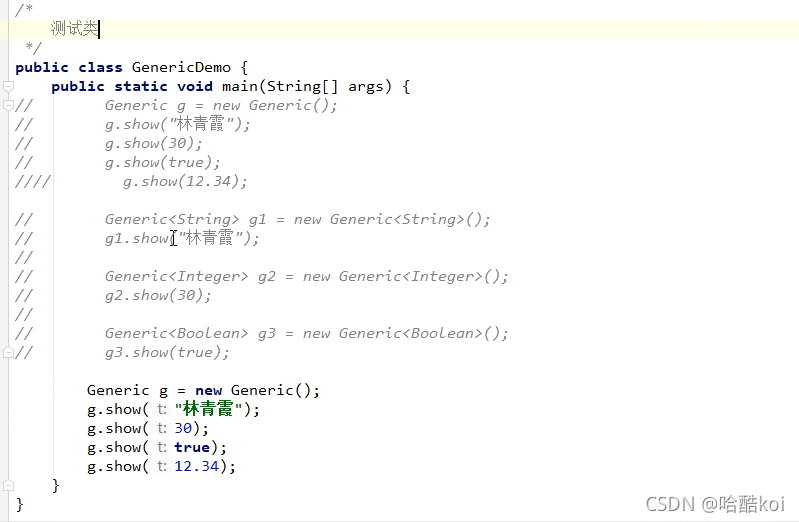
泛型:
泛型概述:它的本質是引數化型別, 顧名思義,就是將型別由原來的具體的型別引數化, 然后在使用/呼叫時傳入具體的型別;
泛型定義格式:
1.<型別>:指定一種型別的格式,這里的型別可以看成是形參;
2.<型別1, 型別2>:指定多種型別的格式, 多種型別直接用逗號隔開, 這里的型別可以看成是形參;
3.將來具體呼叫時候給定的型別可以看成是形參,并且實參的型別只能是參考資料型別
泛型的好處:1.把運行時期的問題提前到了編譯期間,2.避免了強制型別轉換;
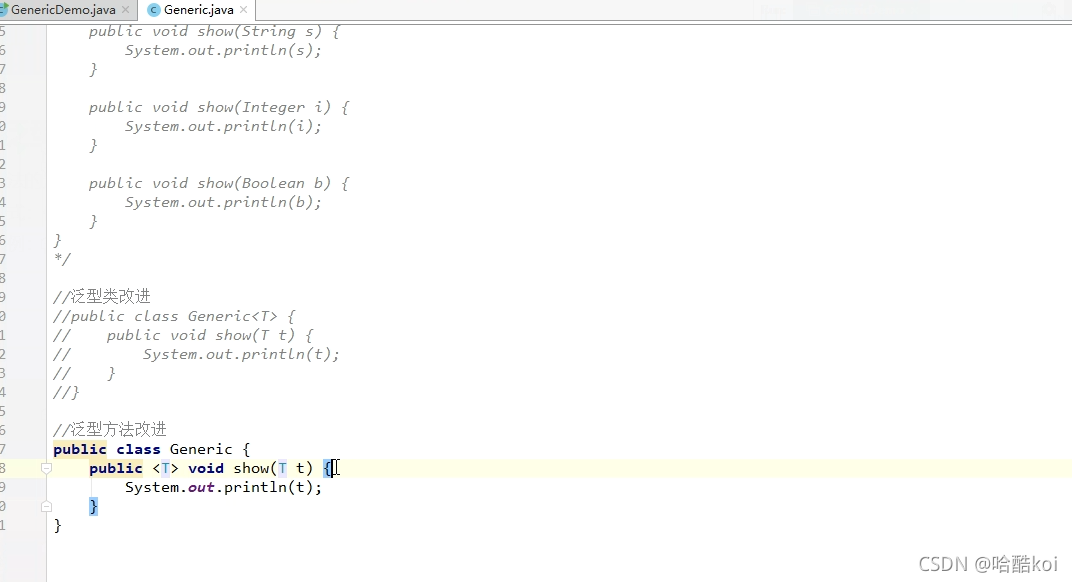
型別通配符:
不作具體的說,放上截圖

好捏看完了上面,接下來需要看一點小重點知識MAP!!!
Map集合概述和使用:
Map集合概述:Interface Map<K, V> K:鍵的型別; V: 值的型別; 將鍵映射到值的物件;不能包含重復的鍵;每個鍵可以映射到最多一個值
創建Map集合的物件(兩種方法):①多型的方式;②具體的實作類HashMap;
Map集合的基本功能:
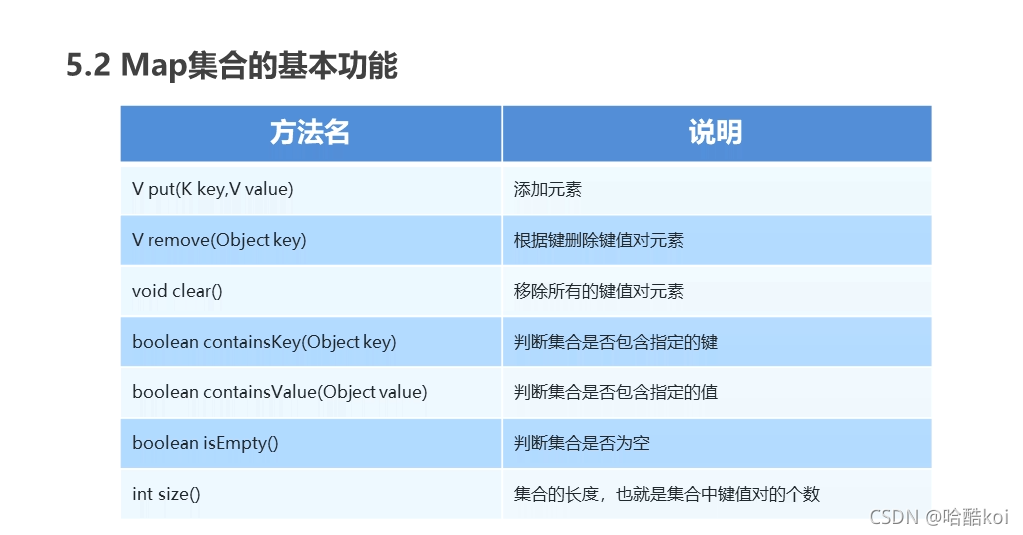
Map集合的獲取功能:
代碼上機測驗:
public class MapDemo03 {
public static void main(String[] args) {
Map<String ,String> map=new HashMap<String, String>();
//在map集合中, 前面的叫做鍵,后面的叫做值
map.put("張無忌","趙敏");
map.put("郭靖","黃蓉");
map.put("楊過","小龍女");
/* // v get(Object key):根據鍵獲取值
System.out.println(map.get("張無忌"));
//如果鍵里面不存在那個值,則回傳null
System.out.println(map.get("張三豐"));*/
/* //Set<K> keySet():獲取所有鍵的集合
Set<String> keySet=map.keySet();
for (String key: keySet) {
System.out.println(key);
}*/
//Collection<V> values(): 獲取所有值的集合
Collection<String > values=map.values();
for (String key:values){
System.out.println(key);
}
}
}這里我們只展示,最后輸出值的結果:
通過Set<Map.Entry<String ,String>> entrySet=map.entrySet();來獲取所有的鍵值的物件!!!
public class MapDemo05 {
public static void main(String[] args) {
Map<String ,String> map=new HashMap<String, String>();
//添加元素
map.put("張無忌","趙敏");
map.put("郭靖","黃蓉");
map.put("楊過","小龍女");
//獲取所有鍵值對物件的集合
Set<Map.Entry<String ,String>> entrySet=map.entrySet();
//遍歷鍵值對物件的集合,得到每一個鍵值對物件
for (Map.Entry<String ,String> me:entrySet){
String key=me.getKey();
String value=me.getValue();
System.out.println(key+","+value);
}
}
}

補充內容:
集合框架底層資料結構總結:
Collection
1. List
- Arraylist: Object陣列
- Vector: Object陣列
- LinkedList: 雙向鏈表(JDK1.6之前為回圈鏈表,JDK1.7取消了回圈)
2. Set
- HashSet(無序,唯一): 基于 HashMap 實作的,底層采用 HashMap 來保存元素
- LinkedHashSet: LinkedHashSet 繼承與 HashSet,并且其內部是通過 LinkedHashMap 來實作的,有點類似于我們之前說的LinkedHashMap 其內部是基于 Hashmap 實作一樣,不過還是有一點點區別的,
- TreeSet(有序,唯一): 紅黑樹(自平衡的排序二叉樹,)
Map
- HashMap: JDK1.8之前HashMap由陣列+鏈表組成的,陣列是HashMap的主體,鏈表則是主要為了解決哈希沖突而存在的(“拉鏈法”解決沖突),JDK1.8以后在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為8)時,將鏈表轉化為紅黑樹,以減少搜索時間
- LinkedHashMap: LinkedHashMap 繼承自 HashMap,所以它的底層仍然是基于拉鏈式散列結構即由陣列和鏈表或紅黑樹組成,另外,LinkedHashMap 在上面結構的基礎上,增加了一條雙向鏈表,使得上面的結構可以保持鍵值對的插入順序,同時通過對鏈表進行相應的操作,實作了訪問順序相關邏輯,詳細可以查看:《LinkedHashMap 原始碼詳細分析(JDK1.8)》
- Hashtable: 陣列+鏈表組成的,陣列是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的
- TreeMap: 紅黑樹(自平衡的排序二叉樹)
如何選用集合?
主要根據集合的特點來選用,比如我們需要根據鍵值獲取到元素值時就選用Map介面下的集合,需要排序時選擇TreeMap,不需要排序時就選擇HashMap,需要保證執行緒安全就選用ConcurrentHashMap.當我們只需要存放元素值時,就選擇實作Collection介面的集合,需要保證元素唯一時選擇實作Set介面的集合比如TreeSet或HashSet,不需要就選擇實作List介面的比如ArrayList或LinkedList,然后再根據實作這些介面的集合的特點來選用,
特別注意事項:
List 和 Map 區別?(資料結構,存盤特點)
這個要從兩個方面來回答,一方面是List和Map的資料結構,另一方面是存盤資料的特點,在資料結構方面,List存盤的是單列資料的集合,而Map存盤的是key、value型別的資料集合,在資料存盤方面,List存盤的資料是有序且可以重復的,而Map中存盤的資料是無序且key值不能重復(value值可以重復),
Arraylist與 LinkedList 異同:
- Arraylist 底層使用的是Object陣列;LinkedList 底層使用的是雙向回圈鏈表資料結構;
- ArrayList 采用陣列存盤,所以插入和洗掉元素的時間復雜度受元素位置的影響,插入末尾還好,如果是中間,則(add(int index, E element))接近O(n);LinkedList 采用鏈表存盤,所以插入,洗掉元素時間復雜度不受元素位置的影響,都是近似 O(1)而陣列為近似 O(n),對于隨機訪問get和set,ArrayList優于LinkedList,因為LinkedList要移動指標,
- LinkedList 不支持高效的隨機元素訪問,而ArrayList 實作了RandmoAccess 介面,所以有隨機訪問功能,快速隨機訪問就是通過元素的序號快速獲取元素物件(對應于get(int index)方法),所以ArrayList隨機訪問快,插入慢;LinkedList隨機訪問慢,插入快,
- ArrayList的空 間浪費主要體現在在list串列的結尾會預留一定的容量空間,而LinkedList的空間花費則體現在它的每一個元素都需要消耗比ArrayList更多的空間(因為要存放直接后繼和直接前驅以及資料),
HashMap 和 Hashtable 的區別:
相同點: 都是實作來Map介面(hashTable還實作了Dictionary 抽象類),
不同點:
- 歷史原因:Hashtable 是基于陳舊的 Dictionary 類的,HashMap 是 Java 1.2 引進的 Map 介面 的一個實作,HashMap把Hashtable 的contains方法去掉了,改成containsvalue 和containsKey,因為contains方法容易讓人引起誤解,
- 同步性:Hashtable 的方法是 Synchronize 的,執行緒安全;而 HashMap 是執行緒不安全的,不是同步的,所以只有一個執行緒的時候使用hashMap效率要高,
- 值:HashMap物件的key、value值均可為null,HahTable物件的key、value值均不可為null,
- 容量:HashMap的初始容量為16,Hashtable初始容量為11,兩者的填充因子默認都是0.75,
- HashMap擴容時是當前容量翻倍即:capacity * 2,Hashtable擴容時是容量翻倍+1 即:capacity * 2+1,
ArrayList 與 Vector 的區別:
共同點: 都實作了List介面,都是有序的集合,我們可以按位置的索引號取出元素,其中資料都是可以重復的,這是與hashSet最不同的,hashSet不可以按照索引號去檢索其中的元素,也不允許有重復的元素,
區別:
- 同步性:Vector是執行緒安全的,即執行緒同步,ArrayList是不安全的,如果有多個執行緒訪問到集合,最好使用Vector,因為不需要我們自己再去考慮和撰寫執行緒安全的代碼;如果只有一個執行緒會訪問到集合,那最好是使用ArrayList,因為它不考慮執行緒安全,效率會高些,
- 資料增長:ArrayList 與 Vector 都有一個初始的容量大小,當存盤進它們里面的元素的個數超過了容量時,就需要增加 ArrayList 與 Vector 的存盤空間,每次要增加存盤空間時,不是只增加一個存盤單元,而是增加多個存盤單元,每次增加的存盤單元的個數在記憶體空間利用與程式效率之間要取得一定的平衡,Vector 默認增長為原來兩倍,而 ArrayList 的增長策略在檔案中沒有明確規定(從源代碼看到的是增長為原來的 1.5 倍),ArrayList 與 Vector 都可以設定初始的空間大小,Vector 還可以設定增長的空間大小,而 ArrayList 沒有提供設定增長空間的方法,
HaspMap與TreeMap的區別:
- HashMap通過hashcode對其內容進行快速查找,而TreeMap中所有的元素都保持著某種固定的順序,如果你需要得到一個有序的結果你就應該使用TreeMap(HashMap中元素的排列順序是不固定的),
- 在Map 中插入、洗掉和定位元素,HashMap是最好的選擇,但如果您要按自然順序或自定義順序遍歷鍵,那么TreeMap會更好,使用HashMap要求添加的鍵類明確定義了hashCode()和 equals()的實作,
HashMap 和 HashSet區別
如果你看過 HashSet 原始碼的話就應該知道:HashSet 底層就是基于 HashMap 實作的,(HashSet 的原始碼非常非常少,因為除了 clone() 、writeObject()、readObject()是 HashSet 自己不得不實作之外,其他方法都是直接呼叫 HashMap 中的方法,

HashMap和Hashtable的區別
HashMap和Hashtable都實作了Map介面,并且都是key-value的資料結構,它們的不同點主要在三個方面:
第一,Hashtable是Java1.1的一個類,它基于陳舊的Dictionary類,而HashMap是Java1.2引進的Map介面的一個實作,
第二,Hashtable是執行緒安全的,也就是說是執行緒同步的,而HashMap是執行緒不安全的,也就是說在單執行緒環境下應該用HashMap,這樣效率更高,
第三,HashMap允許將null值作為key或value,但Hashtable不允許(會拋出NullPointerException),
ArrayList和Vector的區別(是否有序、是否重復、資料結構、底層實作)
ArrayList和Vector都實作了List介面,他們都是有序集合,并且存放的元素是允許重復的,它們的底層都是通過陣列來實作的,因此串列這種資料結構檢索資料速度快,但增刪改速度慢,
而ArrayList和Vector的區別主要在兩個方面:
第一,執行緒安全,Vector是執行緒安全的,而ArrayList是執行緒不安全的,因此在如果集合資料只有單執行緒訪問,那么使用ArrayList可以提高效率,而如果有多執行緒訪問你的集合資料,那么就必須要用Vector,因為要保證資料安全,
第二,資料增長,ArrayList和Vector都有一個初始的容量大小,當存盤進它們里面的元素超過了容量時,就需要增加它們的存盤容量,ArrayList每次增長原來的0.5倍,而Vector增長原來的一倍,ArrayList和Vector都可以設定初始空間的大小,Vector還可以設定增長的空間大小,而ArrayList沒有提供設定增長空間的方法,
Arraylist不是同步的,所以在不需要保證執行緒安全時時建議使用Arraylist,
感謝各位大佬的收看 謝謝各位大佬!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/337747.html
標籤:其他