我有一個像下面這樣的時間序列:
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5), datetime(2011, 1, 7), datetime(2011, 1, 8), datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.DataFrame({"a":np.random.randn(6),"b":np.random.randn(6)}, index=dates)
ts.iloc[2,0]=np.nan
ts.iloc[3,1]=np.nan
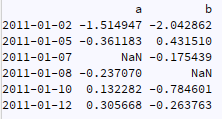
所以它發生在許多情況下,我們需要將其轉換為 numpy 陣列,具有非空值,并執行不同的程序,例如 NN 等...
ts.dropna().values
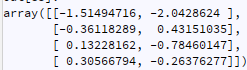
現在例如讓我們說一個新的列 c 是從 numpy 陣列計算(聚類,NN,...)生成的:
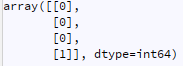
將其添加到原始 df 的最佳方法是什么,使其變為:
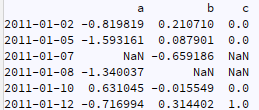
換句話說,在這個作業流程中:
1-從熊貓資料幀多特征時間序列開始
2-洗掉空值
3- 從 2 計算一個新陣列(分類,NN,...)
4- 將 3 中創建的陣列添加到步驟 1 中的原始資料幀(如何正確執行此操作?)
我知道有些人可能會說我們可以在整個程序中堅持使用 pandas,但是可以說該表是 3 維的,我們需要將其轉換為 numpy 陣列。
謝謝!
uj5u.com熱心網友回復:
嘗試isna/notna屏蔽您的資料,然后.loc分配回:
valids = ts.notna().all(axis=1)
# equivalent to ts.dropna().values
data = ts[valids].to_numpy()
# do stuff
preds = KMeans().fit_predict(data)
# preds = [0, 0, 0, 1]
# assign prediction back
# ravel in the case your predictions are 2D as shown
ts.loc[valids, 'pred'] = preds.ravel()
uj5u.com熱心網友回復:
- 從資料框中洗掉 NaN 并將索引分配給變數。
c使用此索引創建一個包含 的熊貓資料框- 左加入這個新的資料框到原來的
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/337999.html
下一篇:如何使用while回圈遍歷輸入?