SQL優化-索引
- 索引的優勢和劣勢
- 索引的分類和索引命令陳述句
- 索引分類
- 基本語法
- 判斷是否適合建索引
- 適合建立索引的情況
- 不適合建立索引的情況
- 性能分析
- MySql Query Optimizer
- MySql 常見瓶頸
- EXPLAIN(查看執行計劃)
- 如何使用?
- 包含資訊
- EXPLAIN實際運用
- 單表
- 兩表連接
- 檢驗索引是否失效
索引的優勢和劣勢
索引簡單來說是排好序的資料結構,所以它能大幅度的提高查詢效率,降低資料排序的成本,降低資料庫的IO成本,
但是索引也同樣占用很大空間,通常是以索引檔案的形式存盤在磁盤上,并且更新資料的同時得更新相應的索引,
總的來說:索引能提高查詢效率,但降低更新效率,所以經常更新的表盡量不要加索引
索引的分類和索引命令陳述句
索引分類
- 單值索引:一個索引只包含單個列,一個表可以有多個單值索引,
- 唯一索引:索引列的值必須唯一,但允許有空值
- 復合索引:一個索引包含多個列
一張表建議建立索引不要超過五個
基本語法
- 創建:
(1)CREATE [UNIQUE] INDEX indexname ON mytable(columnname(length));
(2)ALTER mytable ADD [UNIQUE] INDEX [indexname] ON (columnname(length)); - 洗掉:DROP INDEX [indexname] ON mytable;
- 查看:SHOW INDEX FROM table_name\G;
(\G存在的情況下列形式顯示,不存在的情況下行形式顯示) - 使用ALTER命令:ALTER TABLE mytable ADD (PRIMARYKEY)((UNIQUE|INDEX|FULLTEXT)indexname)(column_list);
PRIMARYKEY:唯一索引(主鍵索引,一般自動添加),索引值唯一,且不能為null,
UNIQUE:唯一索引,索引值唯一,可出現null,且null可重復出現,
INDEX:普通索引,索引值可出現多次,
FULLTEXT:全文索引,
判斷是否適合建索引
適合建立索引的情況
- 主鍵自動建立唯一索引
- 頻繁作為查詢條件的欄位
- 查詢中與其它表關聯的欄位
- 查詢中排序的欄位
- 查詢中統計或分組的欄位
不適合建立索引的情況
- 頻繁更新的欄位(更新不止是更新記錄,還得更新索引)
- Where陳述句用不到的欄位
- 表的記錄不多
- 頻繁增刪改的表
- 資料列大量重復內容(如:性別,只有 男,女)
一般來說復合索引優于單值索引
性能分析
MySql Query Optimizer
MySql自帶的查詢優化器,MySql有專門負責優化SELECT陳述句的優化器模塊,
MySql 常見瓶頸
- CPU:CPU在飽和的時候,一般發生在資料裝入記憶體或者從磁盤讀取資料的時候,
- IO:磁盤I/O瓶頸常發生在裝入資料遠大于記憶體容量的時候,
- 服務器硬體問題,
EXPLAIN(查看執行計劃)
使用EXPLAIN關鍵字可以模擬優化器執行SQL查詢陳述句,從而知道MySql是如何處理你的SQL陳述句,從中得出如何優化你的SQL陳述句,
如何使用?
在SQL陳述句前+EXPLAIN關鍵字(如:explain select * from userdb)
包含資訊
- id:select查詢的序列號,表示操作順序,id相同的情況下順序由上到下,id不同的情況下順序由大到小,
- select_type:查詢型別,主要用于區別普通查詢,聯合查詢,嵌套查詢等的復合查詢,
- table:顯示這一行資料是關于哪張表
- type:從好到懷:system(表只有一行記錄,系統表)>const(通過一次索引就找到)>eq_ref(唯一索引掃描)>ref(非唯一索引掃描)>range(只索引給定范圍)>index(全索引掃描)>all(全表掃描) 一般來說要保證達到range級別
- possible_keys:可能用到的哪些索引
- key:實際用到的索引
- key_len:索引中使用的位元組數,在不損失精確性的情況下,越小越好,
- ref:顯示索引的哪些列被使用
- rows:查找到所需資料的行數
- extra: 加分項:USING index , 扣分項:USING filesort、USING temporary(有扣分項的情況下盡量優化)
EXPLAIN實際運用
單表
- 創建表
CREATE TABLE IF NOT EXISTS blogs(
id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
author_id INT(10) UNSIGNED NOT NULL,
category VARCHAR(20) NOT NULL,
views INT(20) NOT NULL,
assist INT(20) NOT NULL,
comments VARCHAR(20) NOT NULL,
title VARCHAR(255) NOT null,
content TEXT NOT NULL);
- 插入資料
INSERT INTO blogs(author_id,category,views,assist,comments,title,content)VALUES
(1,'java',821,100,'1','java','1'),
(2,'sql',534,100,'2','sql','1'),
(3,'c',1928,100,'3','c','1'),
(4,'c++',851,100,'4','c++','1'),
(5,'c#',89,50,'5','c#','1');
- 沒有建立索引的情況下用EXPLAIN:
EXPLAIN SELECT id, author_id from blogs where comments = '1' and views > 1 ORDER BY assist desc LIMIT 1;

- 查找表中的索引
show index from blogs;
這里只有sql自主建的主鍵索引

- 建立索引
create index idx_blogs_cva on blogs (comments,views,assist);
- 再查找表中的索引
show index from blogs

- 再用EXPLAIN查看性能
EXPLAIN SELECT id, author_id from blogs where comments = '1' and views > 1 ORDER BY assist desc LIMIT 1;

這里很明顯已經用到了索引,但是Extra里面出現了Using filesort,SQL需要優化
- 優化方式:洗掉索引,再建立comments,assist索引(具體原因,后面會說到)
Drop index idx_blogs_cva on blogs;
create index idx_blogs_ca on blogs(comments,assist);
EXPLAIN SELECT id, author_id from blogs where comments = '1' and views > 1 ORDER BY assist desc LIMIT 1;
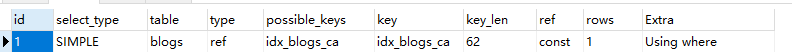
兩表連接
- 創建表
CREATE TABLE IF NOT EXISTS class(
class_id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
class_card INT(20) UNSIGNED NOT NULL
);
CREATE TABLE IF NOT EXISTS book(
book_id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
book_card INT(20) UNSIGNED NOT NULL
);
- 插入資料
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
INSERT INTO book(book_card) VALUES(FLOOR(1+(RAND()*10)));
- 在沒建索引的情況下用EXPLAIN查看兩表連接
EXPLAIN SELECT * FROM book RIGHT JOIN class ON class_card = book_card;

- 建立索引優化
ALTER TABLE book ADD INDEX idx_book_c (book_card);
- 再用EXPLLAIN查看
EXPLAIN SELECT * FROM book RIGHT JOIN class ON class_card = book_card;

- 建立class的索引,再用EXPLAIN
ALTER TABLE class ADD INDEX idx_class_c (class_card);
EXPLAIN SELECT * FROM book RIGHT JOIN class ON class_card = book_card;

-洗掉book索引,再用EXPLAIN
DROP index idx_book_c on book;
EXPLAIN SELECT * FROM book RIGHT JOIN class ON class_card = book_card;

很明顯效率不如添加book表的索引好
總結一下:right join (右連接) ,用左表建索引效果高于右表,left join (左連接) 同理,即:與連接相對的表建立索引效果較好, 盡量用小結果集驅動大結果集(如右連接,就是左表驅動右邊,在左表建立索引的效果要好于右表),
檢驗索引是否失效
- 首先建立表并插入一些資料,創建表,并用EXPLAIN查看索引是否失效
CREATE TABLE students(
id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
age INT(10) UNSIGNED NOT NULL DEFAULT 0,
grade INT(10) UNSIGNED NOT NULL DEFAULT 0,
pos VARCHAR(20) DEFAULT ''
);
INSERT INTO students(name,age,grade,pos) VALUES ('zs',20,97,'monitor');
INSERT INTO students(name,age,grade,pos) VALUES ('ls',22,74,'committee');
INSERT INTO students(name,age,grade,pos) VALUES ('ww',21,100,'committee');
INSERT INTO students(name,age,grade,pos) VALUES ('mw',21,59,'personal');
INSERT INTO students(name,age,grade,pos) VALUES ('zl',21,87,'personal');
ALTER TABLE students ADD INDEX idx_students_nap (name, age, pos);
EXPLAIN SELECT * FROM students WHERE name='zs';

EXPLAIN SELECT * FROM students WHERE name='zs' AND age=20;

EXPLAIN SELECT * FROM students WHERE name='zs' AND age=20 AND pos='monitor';

很明顯,三條陳述句依次是增加了精度,同時key_len也增加,但是都用到了索引
現在看看索引失效的情況:
EXPLAIN SELECT * FROM students WHERE age=20 AND pos='monitor';

EXPLAIN SELECT * FROM students WHERE pos='monitor';

EXPLAIN SELECT * FROM students WHERE age=20;

這三次效果一樣,都是全表掃描
由此得出:查詢應從索引的最左前列開始并且不跳過索引中的列(即最佳左前綴法則)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/3387.html
標籤:其他