演變程序
一. 單體應用架構
為什么要用單體架構?
單體架構的特點就是:所有的業務功能都在一個專案里面 邏輯也簡單 還不貴 適合于小型專案,
在以前計算機才剛剛普及的時候,那個時候基本上都是單體專案架構,因為簡單還實用,那個年代能上網的才有多少人無非都是家里有錢的或者是體制內的上個班以前是喝杯茶看看報紙現在是喝杯茶看看電腦,所以能夠真正上的了網的人很少,那么用單體應用架構完全夠了
那么單體架構又是什么呢?
一個典型的單體應用就是將所有的業務處理功能都放在一個工程中,最終經過編譯、打包,部署在一臺服務器上,
通俗點講就是你整個專案都運行在一個web應用服務器上,然后這整個web應用服務器又運行在一個服務器上
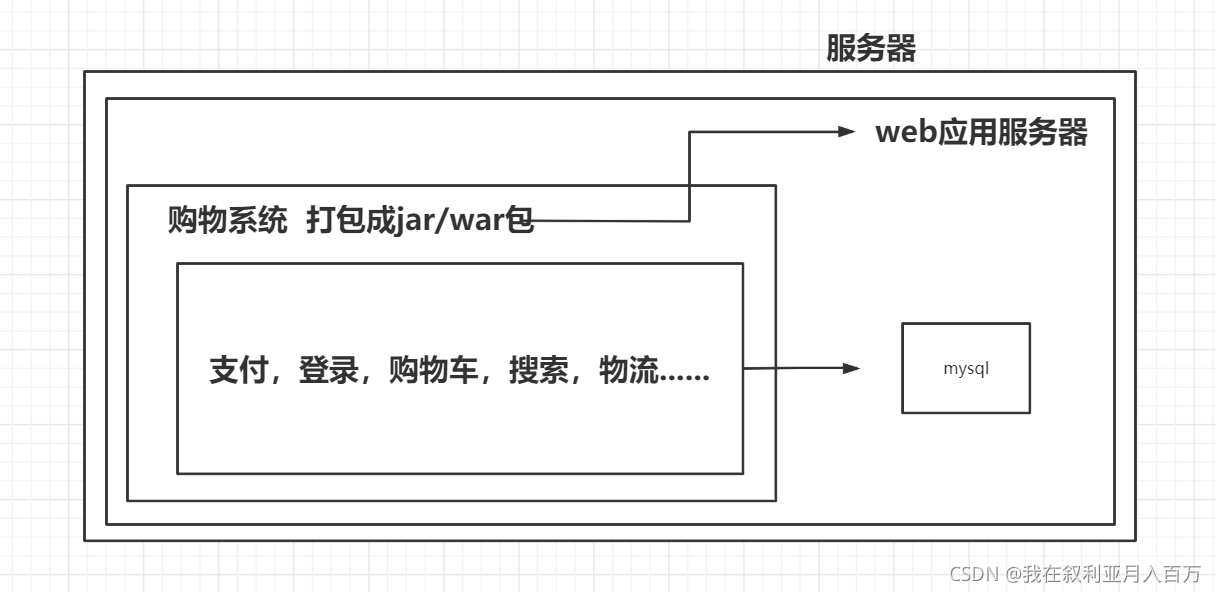
但是隨著時代的發展計算機的普及 越來越多的人有了可以上網的權力 這個時候 單體架構的弊端出來了
舉個栗子:
某企鵝 在它剛創建的那時候基本上是沒什么人用的大概頂多500應該,后面隨著越來越多人有電腦,在加上我們某馬哥堅持不懈的陪用戶聊天
某企鵝的使用用戶也越來越多了起來,但也隨之帶來的就是單體架構的弊端
用戶越來越多,訪問量越來越大,也就是CPU運行記憶體打滿,服務器回應緩慢,帶寬被用盡,一開始我們是采取的更新服務器硬體配置 和提升帶寬
帶寬是什么?
寬帶是一種相對的描述方式,頻帶的范圍愈大,也就是帶寬愈高時,能夠發送的資料也相對增加,譬如說在無線電通信上,頻率范圍比較窄的帶寬只能發送摩爾斯電碼,發送高質量的音樂就需要較大的帶寬,
比如說你這個服務器最大能接受的帶寬是多少 然后如果訪問量大于你這個臨界點就會404 或者 ○加載中
這個時候我們是怎么解決的呢?
垂直擴容 更新服務器配置和提升帶寬,
好解決完了老板非常開心給獎勵你5000獎金,然后你開開心心的拿著獎金開始摸魚了
但這只是能緩解我們的燃眉之急…
因為當時的服務器硬體配置也就那樣,就算你把服務器升到頂配也還是會有一個天花板 萬一你的訪問量到了天花板呢?超過了服務器所能承受的訪問量呢 假如1000萬人訪問會怎么樣怎么辦…
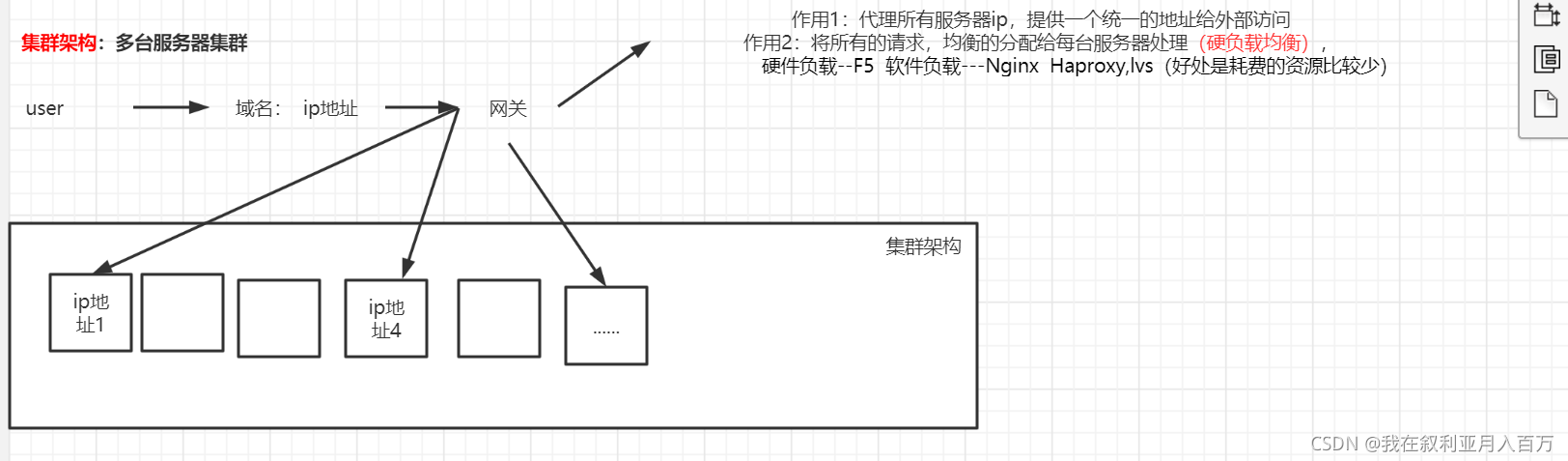
水平擴容(集群架構)
分流,將很多服務器集中起來一起進行同一種服務,在客戶端看來就像是只有一個服務器,主要是分散壓力,
相當于同一個工程代碼拷貝多份部署到多臺服務器,每臺服務器單獨獨立部署運行,
他是怎么解決我們的前面兩個問題的呢?
設定多臺服務器多臺服務器都擁有自己獨立的ip地址,那這肯定很麻煩如果是按照記ip地址才能訪問的話你肯定要記很多0.0.0.0 — 255.255.255.255
所以我們提供了一個東西叫 ”域名“ ,域名代理了所有服務器的IP地址,提供一個統一的訪問地址給外界進行訪問
但這個時候又有了一個問題所有的用戶都訪問我這一個域名 那我怎么進行分配呢?
負載均衡
負載均衡(Load
Balance)是分布式系統架構設計中必須考慮的因素之一,它通常是指,將請求/資料【均勻】分攤到多個操作單元上執行,負載均衡的關鍵在于【均勻】,
硬負載均衡又分為硬體負載均衡和軟體負載均衡
硬體負載均衡是靠負載均衡器來實作的
負載均衡設備:將用戶訪問的請求,根據負載均衡演算法,分發到集群中的一臺處理服務器,(一種把網路請求分散到一個服務器集群中的可用服務器上去的設備)
軟體負載均衡是靠軟體來的
指在服務器的作業系統上,安裝軟體,來實作負載均衡,如Nginx負載均衡,它的優點是基于特定環境、配置簡單、使用靈活、成本低廉,可以滿足大部分的負載均衡需求,
軟體負載均衡器有:Lvs ,Nginx,Haproxy
好解決完了老板非常開心給獎勵你1萬獎金,然后你開開心心的拿著獎金又開始摸魚了
但這個時候又有一個問題出來了假如我有一個億的用戶呢?
難不成還用這思想去解決問題?
那假如我一個億的用戶,市面上好的服務器我們來大概一下一臺好的服務器咱們就算他200萬好吧,一臺好的可以解決五百萬的用戶量,算算多少錢
這應該有幾個小目標了吧,這你 這錢都進老板兜里了難不成還讓他掏出來這他肯定是不愿意的吶對吧,
老板說 這你要搞不好你就可以走人了,怎么辦咱也沒辦法為了不被炒魷魚咱只能想辦法唄
SOA架構
什么是SOA架構這東西每個人的理解都不一樣但是每個人的理解都差不多比較抽象
我的理解來說就是
把一個專案按照功能來拆分成對多個獨立的專案,
在根據使用頻繁的業務服務來對其進行集群架構
這里支付用戶訪問量比其他的多的多所以我們就可以使用集群架構

但是你把每個實際業務都區分成獨立的專案時候,但各個業務總會有那么一些互動的區域 比如說你 用戶要看他這個用戶的訂單是不是用戶管理就和訂單管理互動起來了,
這些互動的區域相互呼叫非常凌亂,這個時候前輩開發了EJB EJB里面實踐了業務總線這個概念,這個經驗是非常寶貴的他幫助我們把這些互動的區域統一起來了,在EJB1版本到2版本的時候也可以算是不成功的但也又是成功的,不成功是因為性能不好業務總線太過笨重,好是他提供了寶貴的實際經驗,
好了這個時候你解決了集群架構的缺點 老板又又給你獎勵了你又又可以開開心心摸魚了
過了幾天由于業務總線太過于笨重有時候效率和不弄SOA差不多 老板又來找你了
你又開始了你那苦逼的生活…
分布式微服務架構
為了解決前面提到的業務總線過于笨重的問題,分布式微服務架構去掉了業務總線去掉了中心化,
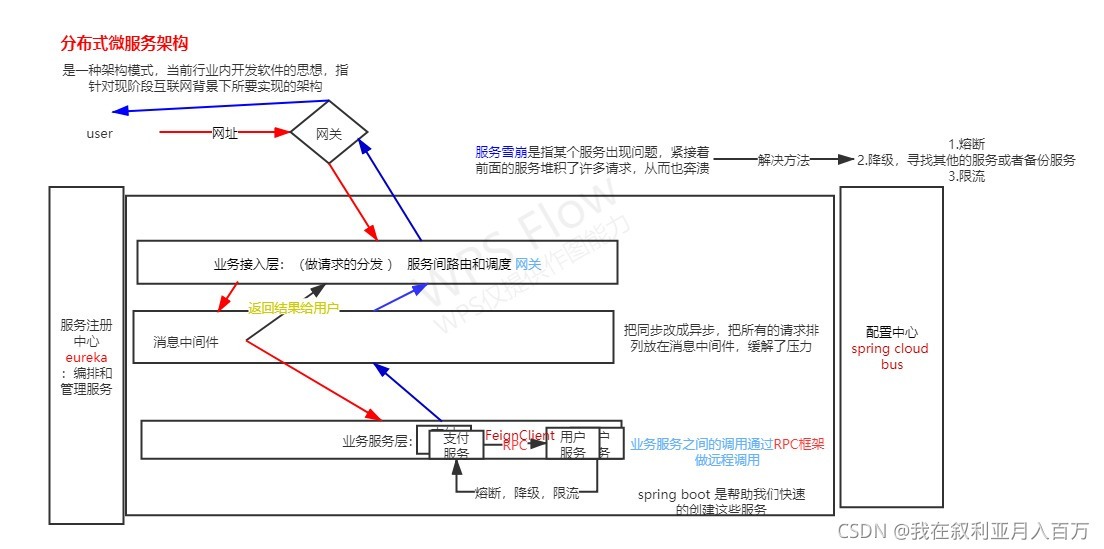
分布式微服務架構也是當前行內開發軟體的思想,指標對現階段互聯網背景下所需要的架構
而且相比于前面而言
微服務是真正的分布式的、去中心化的,把所有的“思考”邏輯包括路由、訊息決議等放在服務內部,去掉一個大一統的 ESB,服務間輕通信,是比SOA更徹底的拆分,
分布式微服務架構強調的重點是業務系統需要徹底的組件化和服務化,原有的單個業務系統會拆分為多個可以獨立開發,設計,運行和運維資料的小應用,這些小應用之間通過服務完成互動和集成,
可以分為六個組件
- 業務接入層:
(請求的分發):服務間路由和調度網關
- 業務服務層:
各個功能模塊服務 比如:支付,用戶,訂單
- 服務注冊中心:
提供服務的注冊和發現以及編排和管理的功能,維護一個可用分的服務串列,當你在服務層上線了一個服務后必須要先在服務注冊中心注冊一下 和我們簽到是一個意思 至于為什么后面會講 我在這里就不多說了
- RPC:
(遠程工程的呼叫):每個獨立的服務專案之間的呼叫
- 配置中心:
將配置的引數統一管理的場所
- 訊息中間介:
記錄用戶發起的請求,各個服務可以通過定時任務或者自由訪問訊息中間介中的請求,
服務器雪崩:
服務器雪崩是一個很嚴重的問題,是怎么來的呢?
由于你支付管理的這個服務器,天災人禍了 總而言之就是掛掉了沒了訪問不了,怎么辦你這個支付管掛掉了,那么需要請求支付管理來進行資料互動的時候就請求不到,假如是訂單管理購買個東西肯定有訂單 對吧肯定要支付但是你支付這個時候掛掉了怎么辦?
請求肯定是請求不到了,就和幾個月之前的b站一樣的結果
而然你這個時候還有可能重繪一下 沒有雪中送炭還來了一波補刀 你每重繪一次就多了一個請求在加上不可能就你一個訪問不到而是所有人都訪問不到那么請求就會越來越多越來越多 到最后訂單管理也撐不住了請求堆積太多了 超過了他所能接受的范圍 所以他也掛掉了,然后蝴蝶效應他后面的噼里啪啦也全部掛掉了 爽不爽起不起飛
那么有問題肯定就有解決的辦法,俗話說得好只要思想不滑坡,方法總比困難多 那么到底怎么解決呢?
三大劍客
- 熔斷
當他發現了某個服務器掛掉的時候就把他的電路斷開,不要讓他可以繼續訪問,也不讓正常的流程去訪問這個掛掉的服務
- 降級
找一個替代品 可以是支付管理的備份,也可以是其他正常的服務
- 限流
字面意思 主要是限制訪問數量 輔助前面兩個 來給服務器雪崩提供解決時間
分布式微服務框架
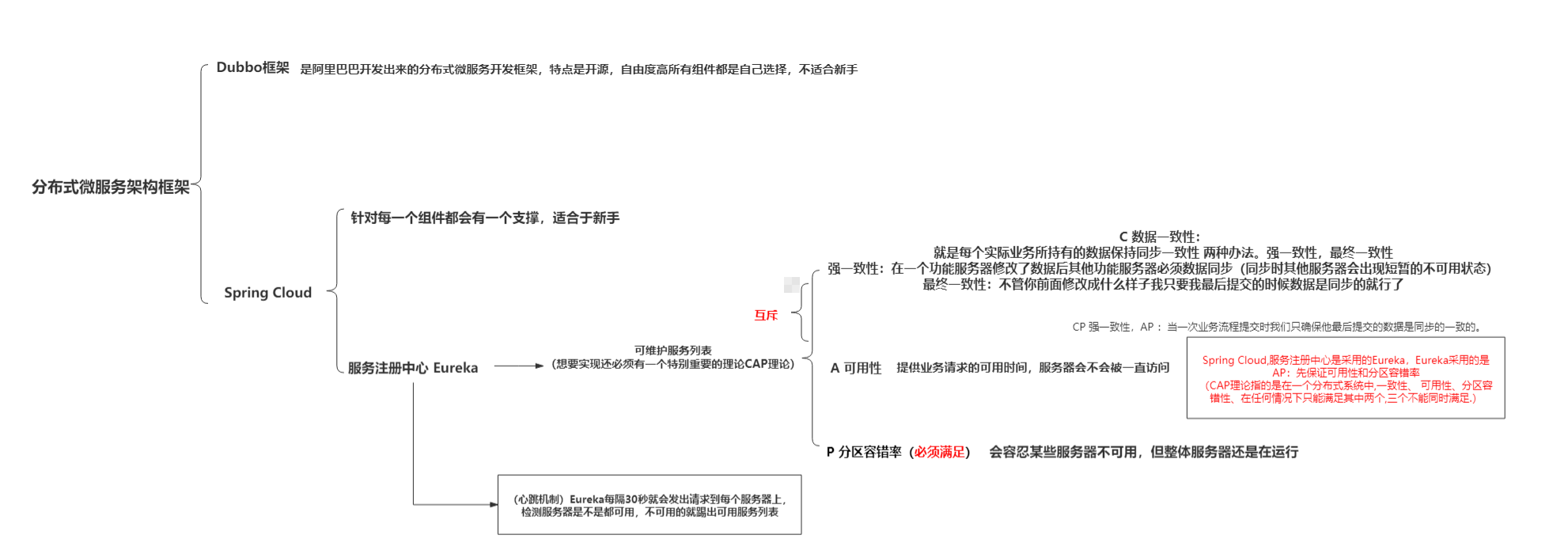
CAP理論是什么?為什么想實作可維護串列需要CAP
而也因為分布式微服務架構 是一個真正的分布式架構專案里的功能模塊都是獨立開來的包括資料也是獨立的,這就會造成什么結果資料不同步,假如我
用戶管理修改了年齡但由于我其他的功能模塊是獨立的資料所以就不同步這就是一個很嚴重的問題那么…
咱們就要用到CAP理論了
- C 資料一致性:
分為強資料一致性和最終資料一致性,強資料一致性就是當你在某個服務中修改了資料 那么其他服務就必須將資料同步(資料同步時會造成短暫的不可訪問狀態),最終一致性 字面意思 就是最終提交的資料我要他是資料同步
不管你前面改了啥 反正我最后提交的時候要資料同步提交
- A 可用性
提供業務訪問的可用時間,就是你服務是不是可用一直開著可用一直訪問
一般都是999 99999 這樣子 一個禮拜停那么一兩個小時或者一個月停那么一兩個小時 可以率99%
- P 磁區容錯率(必須滿足)
會容忍某個服務不可用 但是不影響整體服務器的運行
可以看出來 可用性和資料一致性 是互斥的 因為你想要資料一致性就必須要停一會服務 讓他資料同步 這樣就會降低可用性 所以我們一般都是在這兩個選擇一個 然后在選上一個必選的磁區容錯率
對于新手而已 Spring Cloud 他的服務注冊中心是用的Eureka 而Eureka 所選擇的是AP 也就是先可用性和磁區容錯率
我只是把我知道的總結出來當做筆記防止以后不記得了可以看看所以歡迎各位大哥指點小弟哪里寫的不好
有時間會持續更新…
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/339103.html
標籤:其他
上一篇:nginx簡介