背景
如果你使用傳統編程語言,比如Python,那么恭喜你,你可能需要解決大部分你不需要解決的問題,用Python你相當于拿到了零部件,而不是一輛能跑的汽車,你花了大量時間去組裝汽車,而不是去操控汽車去抵達自己的目的地,大部分非計算機專業的同學核心要解決的是資料操作問題,無論你是擺地攤,開餐館,或者在辦公室做個小職員,在政府機構做作業,你都需要基本的資料處理能力,這本質上是資訊處理能力, 但是在操作資料前,你必須要學習諸如變數,函式,執行緒,分布式等等各種僅僅和語言自身相關的特性,這就變得很沒有必要了,操作資料我們也可以使用 Excel(以及類似的軟體),但是Excel有Excel的限制,譬如你各種點點點,還是有點低效的,有很多較為復雜的邏輯也不太好做,資料規模也有限,那什么互動最快,可擴展性最好?語言,你和計算機系統約定好的一個語言,有了語言交流,總是比點點點更高效的,這個語言是啥呢?就是SQL,
但是SQL也有些毛病,首先他最早為了關系型資料庫設計的,適合查詢而非ETL,但是現在人們慢慢把他擴展到ETL, 流式處理,甚至AI上,他就有點吃力了, 第二個問題是,他是宣告式的,導致缺乏可編程性,所謂可編程性是指,我們應該具備創建小型、可理解、可重用的邏輯片段,并且這些邏輯片段還要被測驗、被命名、被組織成包,而這些包之后可以用來構造更多有用的邏輯片段,這樣的作業流程才是合理又便捷的,更進一步的,這些“高階”能力應該是可選的,我們總是希望用戶一開始去使用最簡單的方式來完成手頭的作業而不是顯擺一些高階技巧,
所以最后的結論是,我們希望:
- 保留SQL的所有原有優勢,簡潔易懂,上手就可以干活,
- 允許用戶進階,提供更多可編程能力,但是以一種SQL Style的方式提供,
保留原有SQL精髓
我們僅僅對SQL做了丟丟調整,在每條SQL 陳述句結尾增加了一個表名,也就是任何一條SQL陳述句的結果集都可以命名為一張新的表,
load hive.`raw.stripe_discounts` as discounts;
load hive.`raw.stripe_invoice_items` as invoice_items;
select
invoice_items.*,
case
when discounts.discount_type = 'percent'
then amount * (1.0 - discounts.discount_value::float / 100)
else amount - discounts.discount_value
end as discounted_amount
from invoice_items
left outer join discounts
on invoice_items.customer_id = discounts.customer_id
and invoice_items.invoice_date > discounts.discount_start
and (invoice_items.invoice_date < discounts.discount_end
or discounts.discount_end is null)as joined;
select
id,
invoice_id,
customer_id,
coalesce(discounted_amount, amount) as discounted_amount,
currency,
description,
created_at,
deleted_at
from joinedas final;
select * from final as output;
大家看到,每條SQL的執行結果都被取名為一張新表,然后下一條SQL可以參考前面SQL產生的表,相比傳統我們需要insert 然后再讀取,會簡單很多,也更自然,速度更快,而且對于資料處理,我們也無需在一條SQL陳述句里寫復雜的嵌套子查詢和Join了,我們可以將SQL展開來書寫,校本化,更加易于閱讀和使用,
支持更多資料源
傳統SQL是假定你在一個資料源中的,因為你只能按庫表方式去使用,在普通Web開發里,是你配置的資料庫,而在大資料里,一般是資料倉庫或者資料湖, 但是隨著聯邦查詢越來越多,越來越普及,我們希望給SQL提供更多的加載和保存多種資料源的能力,我們通過提供load陳述句來完成,
load excel.`./example-data/excel/hello_world.xlsx`
where header="true"
as hello_world;
select hello from hello_world as output;
在上面的示例可以看到,我們加載了一個excel檔案,然后映射成一張表,之后可以用標準的SQL進行處理,
如果要將結果保存到數倉也很簡單:
save overwrite hello_word as hive.`tmp.excel_table`;
變數
變數是一個編程語言里,一般你會接觸到的第一個概念,我們也給SQL增加了這種能力,比如:
-- It takes effect since the declaration in the same cell.
set world="world";
select "hello ${world}" as title
as output;
在可編程SQL中,變數支持多種型別,諸如sql,shell,conf,defaultParam等等去滿足各種需求和場景,下面是一個典型的例子:
set date=`select date_sub(CAST(current_timestamp() as DATE), 1) as dt`
where type="sql";
select "${date}" as dt as output;
后面我們會有更多變數的介紹,
呼叫外部模塊的代碼
傳統編程語言如Java,Python,他們的生態都是靠第三方模塊來提供的,第三方模塊會被打包成諸如如Jar ,Pip 然后讓其他專案參考, 原生的SQL是很難復用的,所以沒有形成類似的機制,更多的是隨用隨寫, 但是隨著SQL能力的擴展,在流,在批,在機器學習上的應用越來越多,能寫越來越復雜的邏輯,也慢慢有了更多的可復用訴求,
我們通過引入include 關鍵字,可以引入本專案或者github上的SQL代碼,https://github.com/allwefantasy/lib-core 是我們使用可編程SQL寫的一個第三方模塊,假設我們要參考里面定義的一個UDF 函式 hello,第一步是引入模塊:
include lib.`github.com/allwefantasy/lib-core`
where
-- libMirror="gitee.com" and -- 配置代理
-- commit="" and -- 配置commit點
alias="libCore";
第二步就是引入相應的udf包,然后在SQL中使用:
include local.`libCore.udf.hello`;
select hello() as name as output;
是不是很酷?
宏函式
函式是代碼復用的基礎,幾乎任何語言都有函式的概念,我們在SQL中也引入的宏函式的概念,但這個宏函式和 原生的SQL中的函式比如 split, concat 等等是不一樣的,他是SQL語言級別的函式,我們來看看示例:
set loadExcel = '''
load excel.`{0}`
where header="true"
as {1}
''';
!loadExcel ./example-data/excel/hello_world.xlsx helloTable;
在這段代碼中,
- 我們申明了一個變數 loadExcel,并且給他設定了一段代碼,
- loadExcel 有諸如 {0}, {1}的占位符,這些會被后續呼叫時的引數動態替換,
- 使用功能
!將loadExcel變數轉化為宏函式進行呼叫,引數傳遞類似命令列,
我們也支持命名引數:
set loadExcel = '''
load excel.`${path}`
where header="true"
as ${tableName}
''';
!loadExcel _ -path ./example-data/excel/hello_world.xlsx -tableName helloTable;
原生SQL函式的動態擴展
像傳統關系型資料庫,幾乎無法擴展SQL的內置函式,在Hive/Spark中,通常需要以Jar包形式提供,可能涉及到重啟應用,比較繁瑣,比較重, 現在,我們把SQL UDF 書寫變成和書寫SQL一樣, 我們來看一個例子:
register ScriptUDF.`` as arrayLast
where lang="scala"
and code='''def apply(a:Seq[String])={
a.last
}'''
and udfType="udf";
select arrayLast(array("a","b")) as lastChar as output;
在上面的代碼中,我們通過register語法注冊了一個函式叫 arrayLast,功能是拿到陣列的最后一個值, 我們使用scala代碼書寫這段邏輯,之后我們可以立馬在SQL中使用功能這個函式,是不是隨寫隨用?
當然,通過模塊的能力,你也可以把這些函式集中在一起,然后通過include引入,
分支語法
SQL最大的欠缺就是沒有分支陳述句,這導致了一個啥問題呢?他需要寄生在其他語言之中,利用其他語言的分支陳述句,現在,我們原生的給SQL 加上了這個能力, 看如下代碼:
set a = "wow,jack";
!if ''' split(:a,",")[0] == "jack" ''';
select 1 as a as b;
!else;
select 2 as a as b;
!fi;
select * from b as output;
在分支陳述句中的條件運算式中,你可以使用一切內置、或者我們擴展的原生函式,比如在上面的例子里,我們在if 陳述句中使用了 split函式,
還有一個大家用得非常多的場景,就是我先查一張表,根據條件決定接著執行什么樣的邏輯,這個有了分支語法以后也會變得很簡單,比如:
select 1 as a as mockTable;
set b_count=`select count(*) from mockTable ` where type="sql" and mode="runtime";
!if ''':b_count > 11 ''';
select 1 as a from b as final_table;
!else;
select 2 as a from b as final_table;
!fi;
select * from final_table as output;
在上面的代碼示例中,我們先查詢 mockTable里有多少資料,如果大于11條,執行 A陳述句,否則執行B 陳述句,執行完成后的結果繼續被后面的SQL 處理,
機器學習(內置演算法)
SQL表達機器學習其實是比較困難的,但是別忘了我們是可編程的SQL呀,我們來看看示例,第一步我們準備一些資料:
include project.`./src/common/mock_data.mlsql`;
-- create mock/validate/test dataset.
select vec_dense(features) as features, label as label from mock_data as mock_data;
select * from mock_data as mock_data_validate;
select * from mock_data as mock_data_test;
接著我們就可以引入一個內置的演算法來完成模型的訓練,
train mock_data as RandomForest.`/tmp/models/randomforest` where
keepVersion="true"
and evaluateTable="mock_data_validate"
and `fitParam.0.labelCol`="label"
and `fitParam.0.featuresCol`="features"
and `fitParam.0.maxDepth`="2"
;
這個陳述句表達的含義是什么呢? 對mock_data表的資料使用RandomForest進行訓練,訓練時的引數來自where陳述句中,訓練后的模型保存在路徑/tmp/models/randomforest 里,是不是非常naive!
之后你馬上可以進行批量預測:
predict mock_data_test as RandomForest.`/tmp/models/randomforest` as predicted_table;
或者將模型注冊成UDF函式,使用Select陳述句進行預測:
register RandomForest.`/tmp/models/randomforest` as model_predict;
select vec_array(model_predict(features)) as predicted_value from mock_data as output;
Python腳本支持
在可編程SQL里, SQL是一等公民, Python只是一些字串片段,下面是一段示例代碼:
select 1 as a as mockTable;
!python conf "schema=st(field(a,long))";
run command as Ray.`` where
inputTable="mockTable"
and outputTable="newMockTable"
and code='''
from pyjava.api.mlsql import RayContext
ray_context = RayContext.connect(globals(),None)
newrows = []
for row in ray_context.collect():
row["a"] = 2
newrows.append(row)
context.build_result(newrows)
''';
select * from newMockTable as output;
這段代碼,我們使用功能Ray 模塊執行Python腳本,這段Python腳本會對 mockTable表加工,把a欄位從1修改為2,然后處理的結果可以繼續被SQL處理,是不是很酷?隨時隨地寫Python處理資料或者做機器學習,資料獲取和加工則是標準的SQL來完成,
插件
可編程SQL無論語法還是內核功能應該是可以擴展的, 比如我需要一個可以產生測驗資料的功能,我只要執行如下指令就可以安裝具有這個功能的插件:
!plugin app add - "mlsql-mllib-3.0";
然后我就獲得了一個叫SampleDatasetExt的工具,他可以產生大量的測驗資料:
run command as SampleDatasetExt.``
where columns="id,features,label"
and size="100000"
and featuresSize="100"
and labelSize="2"
as mockData;
select * from mockData as output;
在上面的示例代碼中,我們通過SampleDatasetExt 產生了一個具有三列的表,表的記錄數為100000, 其中feature欄位陣列大小為100, label欄位的陣列大小為2,之后我們可以使用select陳述句進行查詢進一步加工,
更多編程小trick
比如下面一段代碼在實際生產里是常態:
select SUM( case when `id` is null or `id`='' then 1 else 0 end ) as id,
SUM( case when `diagnosis` is null or `diagnosis`='' then 1 else 0 end ) as diagnosis,
SUM( case when `radius_mean` is null or `radius_mean`='' then 1 else 0 end ) as radius_mean,
SUM( case when `texture_mean` is null or `texture_mean`='' then 1 else 0 end ) as texture_mean,
SUM( case when `perimeter_mean` is null or `perimeter_mean`='' then 1 else 0 end ) as perimeter_mean,
SUM( case when `area_mean` is null or `area_mean`='' then 1 else 0 end ) as area_mean,
SUM( case when `smoothness_mean` is null or `smoothness_mean`='' then 1 else 0 end ) as smoothness_mean,
SUM( case when `compactness_mean` is null or `compactness_mean`='' then 1 else 0 end ) as compactness_mean,
SUM( case when `concavity_mean` is null or `concavity_mean`='' then 1 else 0 end ) as concavity_mean,
SUM( case when `concave points_mean` is null or `concave points_mean`='' then 1 else 0 end ) as concave_points_mean,
SUM( case when `symmetry_mean` is null or `symmetry_mean`='' then 1 else 0 end ) as symmetry_mean,
SUM( case when `fractal_dimension_mean` is null or `fractal_dimension_mean`='' then 1 else 0 end ) as fractal_dimension_mean,
SUM( case when `radius_se` is null or `radius_se`='' then 1 else 0 end ) as radius_se,
SUM( case when `texture_se` is null or `texture_se`='' then 1 else 0 end ) as texture_se,
SUM( case when `perimeter_se` is null or `perimeter_se`='' then 1 else 0 end ) as perimeter_se,
SUM( case when `area_se` is null or `area_se`='' then 1 else 0 end ) as area_se,
SUM( case when `smoothness_se` is null or `smoothness_se`='' then 1 else 0 end ) as smoothness_se,
SUM( case when `compactness_se` is null or `compactness_se`='' then 1 else 0 end ) as compactness_se,
SUM( case when `concavity_se` is null or `concavity_se`='' then 1 else 0 end ) as concavity_se,
SUM( case when `concave points_se` is null or `concave points_se`='' then 1 else 0 end ) as concave_points_se,
SUM( case when `symmetry_se` is null or `symmetry_se`='' then 1 else 0 end ) as symmetry_se,
SUM( case when `fractal_dimension_se` is null or `fractal_dimension_se`='' then 1 else 0 end ) as fractal_dimension_se,
SUM( case when `radius_worst` is null or `radius_worst`='' then 1 else 0 end ) as radius_worst,
SUM( case when `texture_worst` is null or `texture_worst`='' then 1 else 0 end ) as texture_worst,
SUM( case when `perimeter_worst` is null or `perimeter_worst`='' then 1 else 0 end ) as perimeter_worst,
SUM( case when `area_worst` is null or `area_worst`='' then 1 else 0 end ) as area_worst,
SUM( case when `smoothness_worst` is null or `smoothness_worst`='' then 1 else 0 end ) as smoothness_worst,
SUM( case when `compactness_worst` is null or `compactness_worst`='' then 1 else 0 end ) as compactness_worst,
SUM( case when `concavity_worst` is null or `concavity_worst`='' then 1 else 0 end ) as concavity_worst,
SUM( case when `concave points_worst` is null or `concave points_worst`='' then 1 else 0 end ) as concave_points_worst,
SUM( case when `symmetry_worst` is null or `symmetry_worst`='' then 1 else 0 end ) as symmetry_worst,
SUM( case when `fractal_dimension_worst` is null or `fractal_dimension_worst`='' then 1 else 0 end ) as fractal_dimension_worst,
SUM( case when `_c32` is null or `_c32`='' then 1 else 0 end ) as _c32
from data as data_id;
寫的手累?那有么有辦法簡化呢?當然有啦, 我們畢竟是可編程是SQL呀,
一個有意思的解決方法如下:
select
#set($colums=["id","diagnosis","fractal_dimension_worst"])
#foreach( $column in $colums )
SUM( case when `$column` is null or `$column`='' then 1 else 0 end ) as $column,
#end
1 as a from newTable as output;
我們可以使用內置的 #foreach 回圈,先通過set設定所有欄位名稱,然后通過foreach回圈來生成sum陳述句,
這就完了?就如同茴字有好多寫法,我們還有其他的玩法,
set sum_tpl = '''
SUM( case when `{0}` is null or `{0}`='' then 1 else 0 end ) as {0}
''';
select ${template.get("sum_tpl","diagnosis")},
${template.get("sum_tpl","radius_mean")},
${template.get("sum_tpl","texture_mean")},
from data as output;
我們可以通過set 進行模板設定,然后在sql陳述句里通過template.get( 陳述句進行模板渲染, 對于一個很復雜的SQL 陳述句,里面可能存在多個類似sum /case when的重復陳述句,那么我們就可以使用這種方式了,而且可以做到一處修改,處處生效,不然萬一你 sum里的1要改成2,那可是要改好幾十個陳述句的,
恩,除了這些,還有非常多的好玩的玩法等待你的挖掘,SQL 再也不Boring了,
不是最后的最后
可以看到,我們給原生SQL擴展了變數,函式,多資料源支持,第三方模塊,原生SQL ,原生函式動態擴展,分支語法,機器學習,python腳本支持,插件等等諸多功能,就像TypeScript給JavaScript的增強一樣,大家也可以只用最基礎的SQL語法,但是一旦你有需要,你就可以使用更多高階功能滿足自己的訴求,
最后
這個可編程的SQL是還在夢想中么?當然不是! 它就在這里: https://mlsql.tech 我們提供了桌面版和在線試用版本,還不快來感受下,
真的最后了
MLSQL目前支持Web版,桌面版,包括Script,Notebook等多種互動模式,參考 MLSQL 2.1.0版本的技術白皮書
?
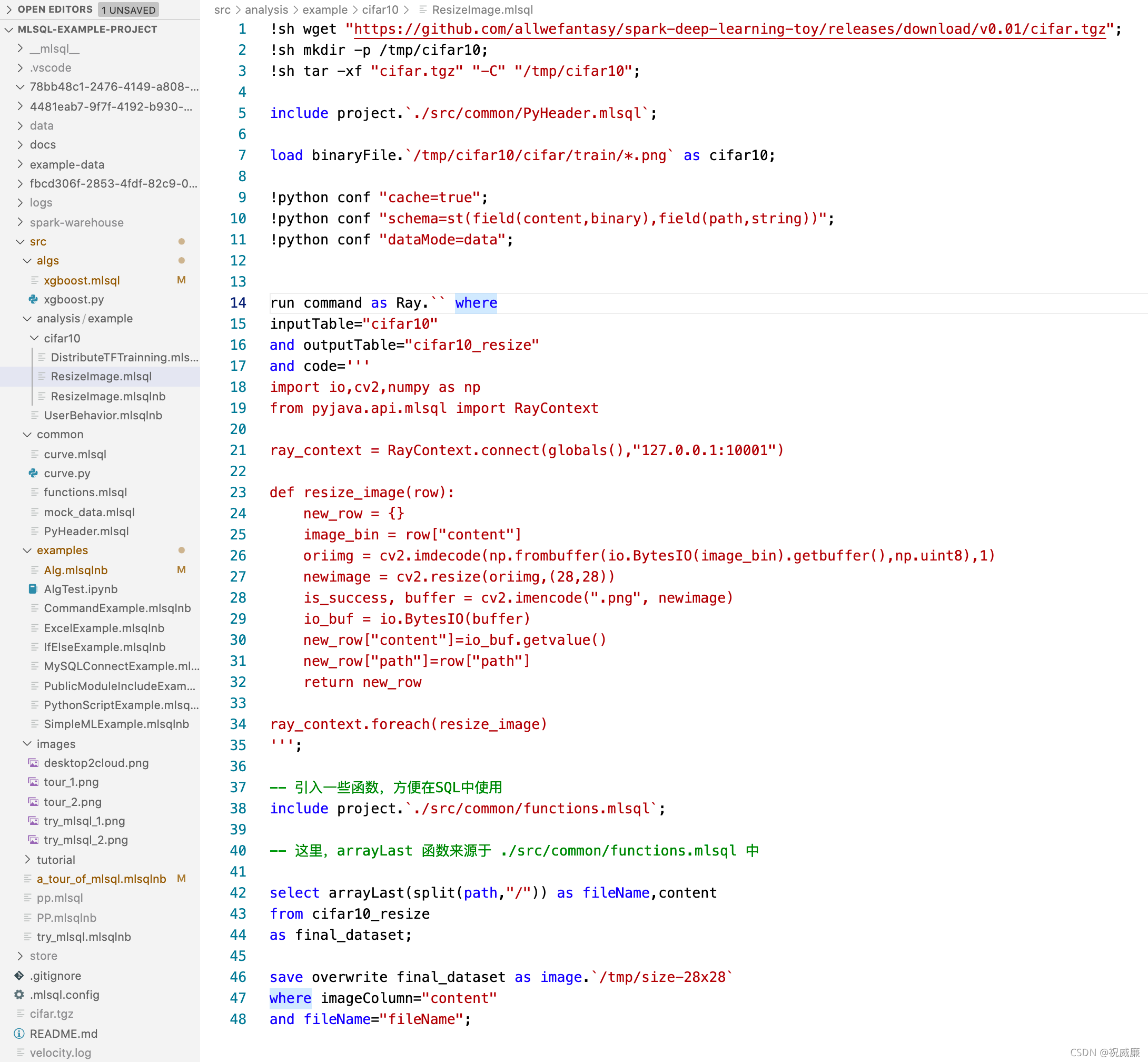
現在,讓我們看一段賞心悅目的MLSQL代碼
- 下載圖片tar包,并且解壓
- 設定python環境
- 加載圖片目錄為表
- 使用python進行分布式圖片處理
- 對檔案名進行處理
- 將表以二進制圖片包保存到物件存盤目錄中
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/339221.html
標籤:其他
上一篇:shell腳本經典題之函式應用