寫在前面
本篇文章主要講解函式指標和回呼函式的理解和使用,屬于較難的指標指標知識,如果想要學習指標簡單和陣列的相關知識,可以進入下面的傳送門,
🌀指標初階知識傳送門🌀
??陣列知識傳送門??
下來就是文章內容了,端上小板凳開始閱讀吧 🗿
文章目錄
- 字符指標
- 函式指標
- 函式指標陣列
- 回呼函式
- 指標筆試題(夯實基礎)
字符指標
在指標的型別中有一種指標型別為字符指標char*
一般使用方法:
使用字符指標指向字符變數進行讀寫操作
int main()
{
char c = 'w';
char* pc = &c;
*pc = 'w';
return 0;
}
另外一種使用方式:
int main()
{
char* pstr = "hello world";//這里是把一個字串的首地址放到pstr指標變數里
printf("%s\n", pstr);
return 0;
}
代碼char* pstr = "hello world";特別容易理解為是把字串hello world放到字符指標pstr里
了,但是其本質是把字串hello world的首字符h的地址放到了pstr中,
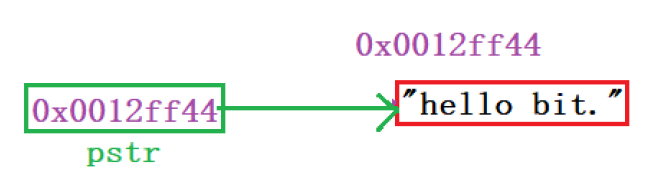
一道相應考點的面試題
#include <stdio.h>
int main()
{
char str1[] = "hello bit.";
char str2[] = "hello bit.";
char* str3 = "hello bit.";
char* str4 = "hello bit.";
if (str1 == str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if (str3 == str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}
輸出結果:

這里
str3和str4指向的是一個同一個常量字串,C/C++會把常量字串存盤到單獨的一個記憶體區域,當幾個指標指向同一個字串的時候,他們實際會指向同一塊記憶體,但是用相同的常量字串去初始化不同的陣列的時候就會開辟出不同的記憶體塊,所以str1和str2不同,str3和str4不同,
函式指標
首先看一段代碼:
#include <stdio.h>
void test()
{
printf("hehe\n");
}
int main()
{
printf("%p\n", test);
printf("%p\n", &test);
return 0;
}
輸出結果:
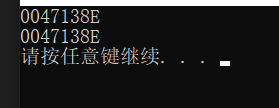
輸出的是兩個地址,這兩個地址是test 函式的地址, 那我們的函式的地址要想保存起來使用的話,怎么保存?這時候就需要函式指標保存函式地址了,
定義函式指標
觀察下面哪個有能力保存函式的地址,
void (*pfun1)();
void *pfun2();
這里pfun1先與*結合,所以pfun1是一個指標,指標指向的是一個函式,指向的函式無引數,回傳值型別為void,
pfun2先與()結合,表明這是一個函式,回傳值為void*,又因為它沒有函式體,所以它是函式的宣告,
使用函式指標
使用函式指標的時候,雖然可以寫成(*p)(),但是也同樣等價于p(),并且為了方便使用,硬性規定函式指標使用方法為p(),
有趣代碼加深理解
//代碼1
(*(void (*)())0)();
//代碼2
void (*signal(int , void(*)(int)))(int);
先說明代碼1:
- 根據優先級,可看出最先執行的是
*,說明這是指標,但卻沒有定義變數,說明是個型別, - 往后執行的
()表明這是個函式指標型別, - 然后對
0進行強制型別轉換,說明0是一個函式指標, - 最后解參考
0,表示通過函式指標呼叫函式,只是這里認為函式的地址為0,
代碼2:
signal先與()結合,說明signal是一個函式,第一個引數為int,第二個引數是一個函式指標,- 該函式的回傳值為引數為
int,回傳值為void的函式指標, - 但是該函式沒有函式體,說明這里是一個函式宣告,
代碼2太復雜,可以進行簡化:
typedef void(*pfun_t)(int);//函式指標型別重命名為pfun_t
pfun_t signal(int, pfun_t);//函式宣告
函式指標陣列
函式指標陣列的定義
例:
int(*parr[10])()
函式指標陣列的用途:轉移表
例子:(計算器)
#include<stdio.h>
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int mul(int a, int b)
{
return a * b;
}
int div1(int a, int b)
{
return a / b;
}
int main()
{
int x, y;
int input = 1;
int ret = 0;
do
{
printf("*************************\n");
printf(" 1:add 2:sub \n");
printf(" 3:mul 4:div \n");
printf("*************************\n");
printf("請選擇:");
scanf("%d", &input);
switch (input)
{
case 1:
printf("輸入運算元:");
scanf("%d %d", &x, &y);
ret = add(x, y);
printf("ret = %d\n", ret);
break;
case 2:
printf("輸入運算元:");
scanf("%d %d", &x, &y);
ret = sub(x, y);
printf("ret = %d\n", ret);
break;
case 3:
printf("輸入運算元:");
scanf("%d %d", &x, &y);
ret = mul(x, y);
printf("ret = %d\n", ret);
break;
case 4:
printf("輸入運算元:");
scanf("%d %d", &x, &y);
ret = div1(x, y);
printf("ret = %d\n", ret);
break;
case 0:
printf("退出程式\n");
break;
default:
printf("選擇錯誤\n");
break;
}
} while (input);
return 0;
}
使用函式指標陣列的實作:
int main()
{
int x, y;
int input = 1;
int ret = 0;
int(*p[5])(int x, int y) = { 0, add, sub, mul, div1 }; //轉移表
while (input)
{
printf("*************************\n");
printf(" 1:add 2:sub \n");
printf(" 3:mul 4:div \n");
printf("*************************\n");
printf("請選擇:");
scanf("%d", &input);
if ((input <= 4 && input >= 1))
{
printf("輸入運算元:");
scanf("%d %d", &x, &y);
ret = p[input](x, y);
printf("ret = %d\n", ret);
}
else
printf("輸入有誤\n");
}
system("pause");
return 0;
}
指向函式指標陣列的指標
void test(const char* str)
{
printf("%s\n", str);
}
int main()
{
//函式指標ptest
void(*ptest)(const char*) = test;
//函式指標的陣列ptestarr
void(*ptestarr[10])(const char*) = { ptest };
//指向函式指標陣列首元素的指標pptest
void(*(*pptest))(const char*) = ptestarr;
//指向整個函式指標陣列的指標pptest1
void(*(*pptest1)[10])(const char*) = &ptestarr;
return 0;
}
回呼函式
回呼函式就是一個通過函式指標呼叫的函式,如果你把函式的指標(地址)作為引數傳遞給另一個函式,當這個函式通過傳過來的指標被用來呼叫其所指向的函式時,我們就說這是回呼函式,回呼函式不是由該函式的實作方直接呼叫,而是在特定的事件或條件發生時由另外的一方呼叫的,用于對該事件或條件進行回應,
通過qsort講解回呼函式的使用
庫函式qsort就是回呼函式,看一下它的函式宣告:
void qsort (void* base, size_t num, size_t size, int (*compar)(const void*,const void*));
- 其中
base是無型別的指標,可以接受任何的指標型別,但是void*不能解參考,需要根據傳入的內容強轉成其他的型別進行操作, num是傳入陣列的元素個數,其型別是無符號整型,size是傳入陣列的元素大小(位元組個數),compar就是函式指標,用于呼叫其他函式,
代碼使用qsort
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
//回呼函式比較整型呼叫的函式
int CompInt(const void* xp, const void* yp)
{
assert(xp);
assert(yp);
return (*(int*)xp - *(int*)yp);
}
int main(void)
{
int arr1[] = { 123,74,724,654,85,946,24325,4363574,-23,-534,24,235,43 };
int n1 = sizeof(arr1) / sizeof(arr1[0]);
qsort(arr1, n1, sizeof(arr1[0]), CompInt);
for (int i = 0;i < n1;i++)
{
printf("%d ", arr1[i]);
}
printf("\n");
return 0;
}
運行結果:
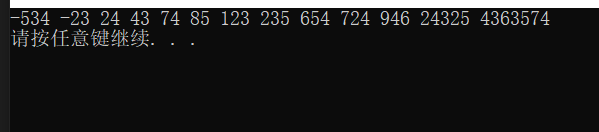
用冒泡排序實作回呼函式qsort
#include<stdio.h>
#include<windows.h>
#include<assert.h>
#include<stdlib.h>
//按位元組交換位置
void Swap(char* xp, char* yp, size_t size)
{
while (size--)
{
char temp = 0;
temp = *xp;
*xp = *yp;
*yp = temp;
++xp;
++yp;
}
}
//回呼函式比較整型呼叫的函式
int CompInt(const void* xp, const void* yp)
{
assert(xp);
assert(yp);
return (*(int*)xp - *(int*)yp);
}
//回呼函式比較浮點型呼叫的函式
int CompDouble(const void* xp, const void* yp)
{
assert(xp);
assert(yp);
const double* x = (const double*)xp;
const double* y = (const double*)yp;
if (*x - *y > 0)
{
return 1;
}
else if (*x - *y < 0)
{
return -1;
}
else
{
return 0;
}
}
//回呼函式比較字串呼叫的函式
int CompString(const void* xp, const void* yp)
{
assert(xp);
assert(yp);
//用char*保存字串時
const char* x = *(const char**)xp;
const char* y = *(const char**)yp;
while (*x || *y)
{
if (*x > * y)
{
return 1;
}
else
{
return -1;
}
x++;
y++;
}
return 0;
return strcmp(x, y);
}
//模仿qsort的功能實作一個通用的冒泡排序
void MyQsort(void* a, size_t n, size_t size, int(*comp)(const void* xp, const void* yp))
{
assert(a);
assert(comp);
char* p = (char*)a;
int s = 1;
for (size_t i = 0;i < n - 1; i++)
{
for (size_t j = 0;j < n - i - 1;j++)
{
if (comp(p + j * size, p + (j + 1) * size) > 0)//這里是位元組操作
{
Swap(p + j * size, p + (j + 1) * size, size);
s = 0;
}
}
if (s)
break;
}
}
int main(void)
{
int arr1[] = { 123,74,724,654,85,946,24325,4363574,-23,-534,24,235,43 };
int n1 = sizeof(arr1) / sizeof(arr1[0]);
//qsort(arr1, n1, sizeof(arr1[0]), CompInt);
MyQsort(arr1, n1, sizeof(arr1[0]), CompInt);
for (int i = 0;i < n1;i++)
{
printf("%d ", arr1[i]);
}
printf("\n");
double arr2[] = { 12.3,7.4,72.4,6.54,0.85,94.6,24.325,4363.574,-2.3,-53.4,24.567,235.555,4.3 };
int n2 = sizeof(arr2) / sizeof(arr2[0]);
//qsort(arr2, n2, sizeof(arr2[0]), CompDouble);
MyQsort(arr2, n2, sizeof(arr2[0]), CompDouble);
for (int i = 0;i < n2;i++)
{
printf("%.3f ", arr2[i]);
}
printf("\n");
char* arr3[] = {
"fxakssxb!",
"aadcasvaf",
"acvsvffd=",
"dasn2r32",
"3254376fsda",
"543654bsggs"
};
int n3 = sizeof(arr3) / sizeof(arr3[0]);
//qsort(arr3, n3, sizeof(arr3[0]), CompString);
MyQsort(arr3, n3, sizeof(arr3[0]), CompString);
for (int i = 0;i < n3;i++)
{
printf("%s\n", arr3[i]);
}
printf("\n");
system("pause");
return 0;
}
運行結果:
字串的大小比較是從第一個元素開始往后依次比較字符的ascii碼值大進行排序,只要其中有一個字符大,那么這個字串就比另一個大, 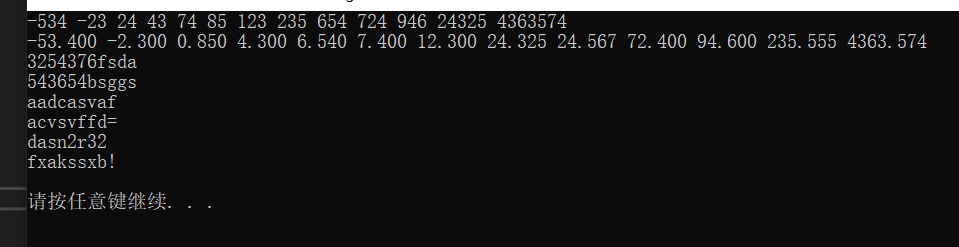
指標筆試題(夯實基礎)
筆試題1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
//程式的結果是什么?
結果為:
2 ,5
結果分析:
&a的型別是int[5] *,加一后指向整個陣列后跟陣列大小相同的空間的首位元組地址,并把地址傳給了ptr,由于ptr是int型,只向前移動四個位元組,所以指向陣列的最后的元素,
筆試題2
//結構體的大小是20個位元組
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假設p 的值為0x100000, 如下表運算式的值分別為多少?
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
結果為:
100014
100001
100004
結果分析:
p的型別是struct Test*,指標加一加上其所指向型別的大小,故加上結構體的大小20,轉換為地址的16進制輸出即為結果100014,- 把
p的型別強轉為unsigned long,加一即為數字之間的加法,故直接加上一,結果為100001,- 把
p的型別強轉為unsigned int*,指標加一加上其所指向型別的大小,故加上int的大小4,所以結果為100004,
筆試題3
int main()
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);
return 0;
}
結果為:
4,2000000
結果分析:
記憶體結構圖: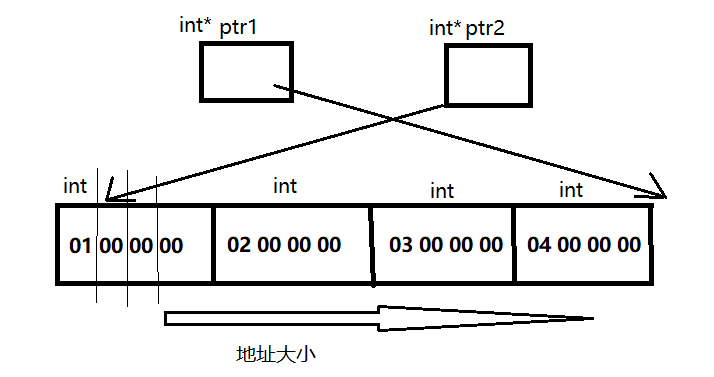
&a的型別是int[4] *,加一后指向整個陣列后跟陣列大小相同的空間的首位元組地址,并把地址傳給了ptr,由于ptr是int型,只向前移動四個位元組,所以指向陣列的最后的元素,- 將
a強轉為int型別加一就是值加一,所以就相當于地址值加了一,再強轉為int*型別傳給ptr2解參考后,小端取出的數值為02 00 00 00,若為大端,取出的數值為00 00 01 00,
筆試題4
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}
結果為:
1
結果分析:
a陣列的元素是型別為int[2]的一維陣列,p保存的是a首元素的地址,p[0]訪問的是a[0][0],通過逗號運算式可知,陣列初始化的內容是a[0][0] = 1,a[0][1] = 3,a[1][0] = 5,所以列印出的結果是1,
筆試題5
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
結果為:
ff ff ff fc,-4
結果分析:
a陣列的內部元素是int[5],即有5個int型的一維陣列,一共有5 * 5 = 25個int型的資料,p指標的型別是int[4] *,p指標保存了陣列的首位元組地址,元素p[4][2]前面有4 * 4 + 2 = 18個int的資料,元素a[4][2]前面有4 * 5 + 2 = 22個int的資料,&p[4][2] - &a[4][2]相減時,是兩個相同的指標型別相減,等于跨越的資料個數為18 - 22 = -4,-4以%p列印出來就是-4的補碼ff ff ff fc,以%d列印出來就是-4,
筆試題6
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
結果為:
10,5
結果分析:
&aa的型別是int[2][5] *,加一加上其指向型別的大小,所以ptr1指向整個陣列后跟陣列大小相同的空間的首位元組地址,由于ptr1的型別是int,所以往前移動了4個位元組,解參考后就是10,- 陣列
aa的元素型別是int[5],即具有5個int資料的一維陣列,加一指向后一個元素,把該地址傳給ptr2,由于ptr2是int型,往前移動四個位元組解參考就是5,
筆試題7
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
結果為:
at
結果分析:
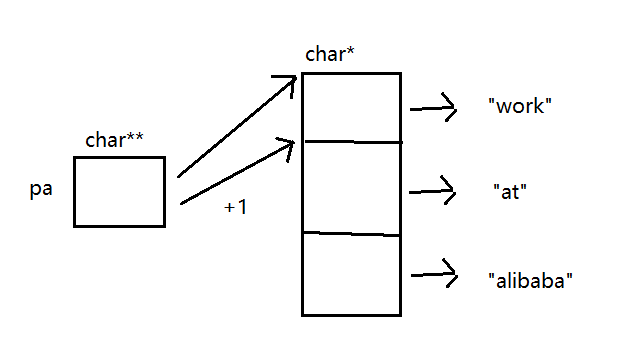
陣列
a元素型別是char*,保存的是三個字串的首地址,pa指向陣列首元素,pa++后指向陣列的第二個元素,解參考后列印出來就是字串at,
筆試題8
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
結果為:
POINT
ER
ST
EW
結果分析:
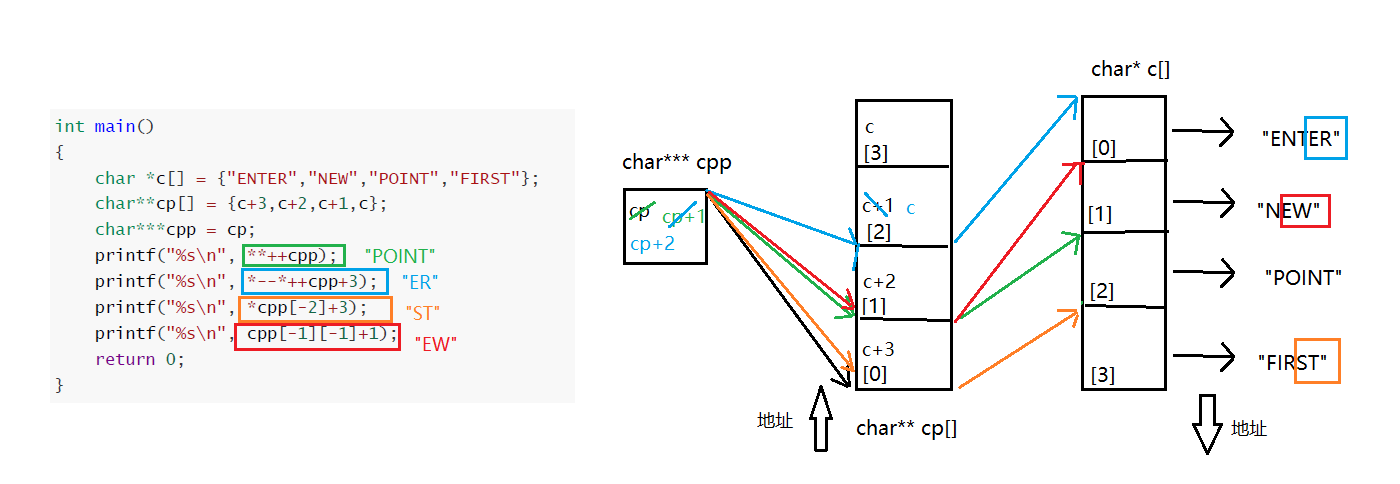
- 陣列
c中保存的是三個字串的首元素地址,陣列中cp保存的是陣列c元素的地址,注意初始化的時候重新賦了值,cpp中保存了cp的首元素地址,++cpp,改變了cpp里保存的地址,指向了cp[1],cp[1]指向c[2],解參考的時候就列印了"POINT"字串,++cpp,又改變了cpp里保存的地址,指向了cp[2],*++cpp訪問cp[2],--*++cpp使cp[2]指向c[0],*--*++cpp訪問c[0]空間,c[0]空間里保存的"ENTER"字串首元素地址+3后列印就是"ER",cpp[-2]訪問了cp[0],*cpp[-2]通過cp[0]里保存的地址訪問c[3],c[3]空間里保存的"FIRST"字串首元素地址+3后列印就是"ST",cpp[-1]訪問cp[1],cpp[-1][-1]通過cp[1]保存的地址訪問c[1],c[1]空間里保存的"NEW"字串首元素地址+1后列印就是"NW",
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/340478.html
標籤:其他